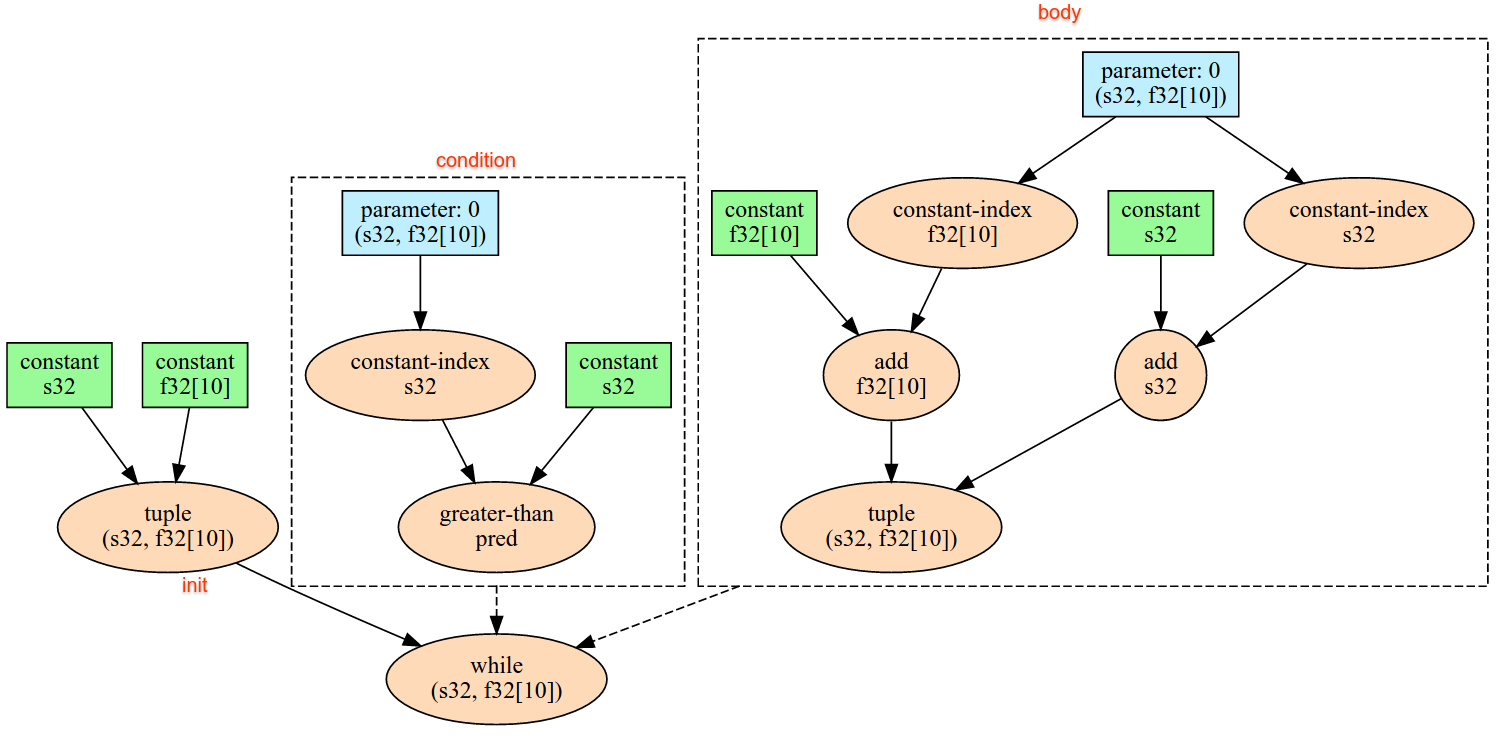
यहां XlaBuilder इंटरफ़ेस में बताए गए ऑपरेशन के सेमेटिक्स के बारे में बताया गया है. आम तौर पर, ये ऑपरेशन xla_data.proto में, आरपीसी इंटरफ़ेस में तय किए गए ऑपरेशन के साथ एक-एक करके मैप होते हैं.
नामकरण के बारे में एक जानकारी: XLA में काम करने वाला सामान्य डेटा टाइप, एक ऐसा N-डाइमेंशनल कलेक्शन होता है जिसमें एक जैसे टाइप (जैसे, 32-बिट वाला फ़्लोट) के एलिमेंट होते हैं. दस्तावेज़ में, कलेक्शन का इस्तेमाल, मनमुताबिक डाइमेंशन वाले कलेक्शन के लिए किया गया है. सुविधा के लिए, खास मामलों के लिए ज़्यादा सटीक और जाने-पहचाने नाम होते हैं. उदाहरण के लिए, वेक्टर एक डाइमेंशन वाला ऐरे होता है और मैट्रिक दो डाइमेंशन वाला ऐरे होता है.
AfterAll
XlaBuilder::AfterAll भी देखें.
AfterAll फ़ंक्शन, कई टोकन लेता है और एक टोकन बनाता है. टोकन, प्राइमटिव टाइप होते हैं. इन्हें ऑर्डर लागू करने के लिए, साइड-इफ़ेक्ट वाले ऑपरेशन के बीच थ्रेड किया जा सकता है. AfterAll का इस्तेमाल, सेट ऑपरेशन के बाद किसी ऑपरेशन को ऑर्डर करने के लिए, टोकन के जॉइन के तौर पर किया जा सकता है.
AfterAll(operands)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operands |
XlaOp |
टोकन की वैरिएबल संख्या |
AllGather
XlaBuilder::AllGather भी देखें.
सभी रेप्लिकेशन में कनेक्शन करता है.
AllGather(operand, all_gather_dim, shard_count, replica_group_ids,
channel_id)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand
|
XlaOp
|
सभी डुप्लीकेट कॉपी में एक साथ जोड़ने के लिए ऐरे |
all_gather_dim |
int64 |
कनेक्शन डाइमेंशन |
replica_groups
|
int64 के वेक्टर का वेक्टर |
वे ग्रुप जिनके बीच में कनकैनेटेशन किया जाता है |
channel_id
|
ज़रूरी नहीं int64
|
अलग-अलग मॉड्यूल के बीच कम्यूनिकेशन के लिए, चैनल आईडी (ज़रूरी नहीं) |
replica_groups, उन रेप्लिक ग्रुप की सूची होती है जिनके बीच में जोड़ने की कार्रवाई की जाती है. मौजूदा रेप्लिक का आईडी,ReplicaIdका इस्तेमाल करके वापस पाया जा सकता है. हर ग्रुप में रेप्लिक का क्रम तय करता है कि नतीजे में उनके इनपुट किस क्रम में मौजूद होंगे.replica_groupsया तो खाली होना चाहिए (इस मामले में, सभी रीप्लिक एक ही ग्रुप से जुड़े होते हैं, जिन्हें0सेN - 1तक क्रम में लगाया जाता है) या इसमें उतने ही एलिमेंट होने चाहिए जितने रीप्लिक हैं. उदाहरण के लिए,replica_groups = {0, 2}, {1, 3},0और2के साथ-साथ1और3के बीच, कॉन्कैनेटेशन करता है.shard_count, हर एक रेप्लिक ग्रुप का साइज़ है. हमें इसकी ज़रूरत उन मामलों में होती है जहांreplica_groupsखाली होते हैं.channel_idका इस्तेमाल, अलग-अलग मॉड्यूल के बीच कम्यूनिकेशन के लिए किया जाता है: सिर्फ़ एक हीchannel_idवालेall-gatherऑपरेशन, एक-दूसरे से कम्यूनिकेट कर सकते हैं.
आउटपुट आकार, इनपुट आकार का ही होता है. इसमें all_gather_dim को shard_count
गुना बड़ा किया जाता है. उदाहरण के लिए, अगर दो रिप्लिकेशन हैं और ऑपरेंड की वैल्यू, दोनों रिप्लिकेशन पर क्रमशः [1.0, 2.5] और [3.0, 5.25] है, तो इस ऑपरेशन से मिलने वाली आउटपुट वैल्यू, जहां all_gather_dim 0 है वह दोनों रिप्लिकेशन पर [1.0, 2.5, 3.0,
5.25] होगी.
AllReduce
XlaBuilder::AllReduce भी देखें.
सभी रेप्लिक में कस्टम कैलकुलेशन करता है.
AllReduce(operand, computation, replica_group_ids, channel_id)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand
|
XlaOp
|
सभी प्रतिकृति में घटाने के लिए, ऐरे या ऐरे का ऐसा टुपल जो खाली न हो |
computation |
XlaComputation |
उत्सर्जन में कमी का हिसाब लगाना |
replica_groups
|
int64 के वेक्टर का वेक्टर |
वे ग्रुप जिनके बीच कमी की जाती है |
channel_id
|
ज़रूरी नहीं int64
|
अलग-अलग मॉड्यूल के बीच कम्यूनिकेशन के लिए, चैनल आईडी (ज़रूरी नहीं) |
- जब
operand, ऐरे का ट्यूपल होता है, तो ट्यूपल के हर एलिमेंट पर ऑल-रिड्यूस किया जाता है. replica_groups, उन रीप्लिक ग्रुप की सूची होती है जिनके बीच डेटा कम किया जाता है. मौजूदा रीप्लिक का आईडी,ReplicaIdका इस्तेमाल करके वापस पाया जा सकता है.replica_groupsया तो खाली होना चाहिए (इस मामले में, सभी रीप्लिक एक ही ग्रुप से जुड़े होते हैं) या इसमें रीप्लिक की संख्या के बराबर एलिमेंट होने चाहिए. उदाहरण के लिए,replica_groups = {0, 2}, {1, 3},0और2के बीच और1और3के बीच डेटा को कम करता है.channel_idका इस्तेमाल, अलग-अलग मॉड्यूल के बीच कम्यूनिकेशन के लिए किया जाता है: सिर्फ़ एक हीchannel_idवालेall-reduceऑपरेशन, एक-दूसरे से कम्यूनिकेट कर सकते हैं.
आउटपुट का शेप, इनपुट के शेप जैसा ही होता है. उदाहरण के लिए, अगर दो रिप्लिकेशन हैं और दोनों रिप्लिकेशन में ऑपरेंड की वैल्यू [1.0, 2.5] और [3.0, 5.25] है, तो इस ऑपरेटर और योग के हिसाब से, दोनों रिप्लिकेशन में आउटपुट वैल्यू [4.0, 7.75] होगी. अगर इनपुट ट्यूपल है, तो आउटपुट भी ट्यूपल होगा.
AllReduce का नतीजा कैलकुलेट करने के लिए, हर एक रेप्लिक से एक इनपुट होना ज़रूरी है. इसलिए, अगर कोई रेप्लिक किसी AllReduce नोड को किसी दूसरे रेप्लिक से ज़्यादा बार चलाता है, तो पहला रेप्लिक हमेशा इंतज़ार करेगा. सभी प्रतिकृति एक ही प्रोग्राम चला रही हैं, इसलिए ऐसा होने के कई तरीके नहीं हैं. हालांकि, ऐसा तब हो सकता है, जब किसी 'जब तक' लूप की शर्त, इनफ़ीड के डेटा पर निर्भर हो और डाले गए डेटा की वजह से, 'जब तक' लूप किसी एक प्रतिकृति पर दूसरे की तुलना में ज़्यादा बार दोहराया जाए.
AllToAll
XlaBuilder::AllToAll भी देखें.
AllToAll एक सामूहिक ऑपरेशन है, जो सभी कोर से सभी कोर पर डेटा भेजता है. इसमें दो चरण होते हैं:
- स्कैटर फ़ेज़. हर कोर पर, ऑपरेंड को
split_dimensionsके साथsplit_countब्लॉक में बांटा जाता है और ब्लॉक सभी कोर में भेजे जाते हैं. उदाहरण के लिए, ith ब्लॉक को ith कोर पर भेजा जाता है. - इकट्ठा करने का चरण. हर कोर,
concat_dimensionके साथ मिले ब्लॉक को जोड़ता है.
जिन कोर को इस प्रोसेस में शामिल करना है उन्हें इन तरीकों से कॉन्फ़िगर किया जा सकता है:
replica_groups: हर ReplicaGroup में, कैलकुलेशन में हिस्सा लेने वाले रिप्लिक आईडी की सूची होती है. मौजूदा रिप्लिक का रिप्लिक आईडी,ReplicaIdका इस्तेमाल करके वापस पाया जा सकता है. AllToAll, सबग्रुप में तय किए गए क्रम में लागू किया जाएगा. उदाहरण के लिए,replica_groups = { {1,2,3}, {4,5,0} }का मतलब है कि इकट्ठा करने के फ़ेज़ में,{1, 2, 3}के रेप्लिक में एक-दूसरे से जुड़े सभी ब्लॉक लागू किए जाएंगे. साथ ही, मिले ब्लॉक को 1, 2, 3 के क्रम में जोड़ दिया जाएगा. इसके बाद, 4, 5, 0 वाले रिप्लिक में एक और AllToAll लागू किया जाएगा. साथ ही, कनकैनेटेशन का क्रम भी 4, 5, 0 होगा. अगरreplica_groupsखाली है, तो सभी रेप्लिक एक ग्रुप के होते हैं. ये ग्रुप, दिखने के क्रम में जोड़े जाते हैं.
ज़रूरी शर्तें:
split_dimensionपर ऑपरेंड का डाइमेंशन साइज़,split_countसे डिवाइड किया जा सकता है.- ऑपरेंड का शेप ट्यूपल नहीं है.
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
n डाइमेंशन वाला इनपुट ऐरे |
split_dimension
|
int64
|
इंटरवल [0,
n) में मौजूद वैल्यू, जो उस डाइमेंशन का नाम बताती है जिसके आधार पर ऑपरेंड को बांटा गया है |
concat_dimension
|
int64
|
इंटरवल [0,
n) में मौजूद वैल्यू, जो उस डाइमेंशन का नाम बताती है जिसके हिसाब से स्प्लिट किए गए ब्लॉक को जोड़ा जाता है |
split_count
|
int64
|
इस ऑपरेशन में हिस्सा लेने वाले कोर की संख्या. अगर replica_groups खाली है, तो यह वैल्यू, रीप्लिक की संख्या होनी चाहिए. अगर यह वैल्यू नहीं है, तो यह हर ग्रुप में मौजूद रीप्लिक की संख्या के बराबर होनी चाहिए. |
replica_groups
|
ReplicaGroup वेक्टर
|
हर ग्रुप में, डुप्लीकेट आईडी की सूची होती है. |
नीचे, सभी-सभी के उदाहरण दिए गए हैं.
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(x, /*split_dimension=*/1, /*concat_dimension=*/0, /*split_count=*/4);
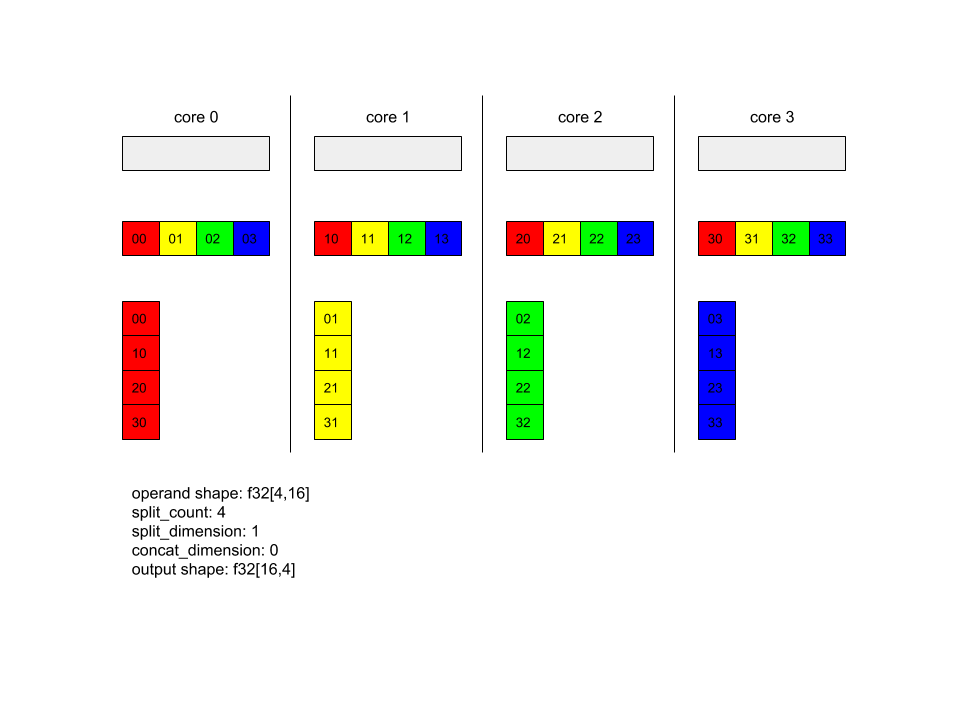
इस उदाहरण में, Alltoall में चार कोर शामिल हैं. हर कोर पर, ऑपरेंड को डाइमेंशन 1 के हिसाब से चार हिस्सों में बांटा जाता है. इसलिए, हर हिस्से का शेप f32[4,4] होता है. चार हिस्सों को सभी कोर में बांटा जाता है. इसके बाद, हर कोर, डाइमेंशन 0 के साथ मिले हिस्सों को कोर 0 से 4 के क्रम में जोड़ता है. इसलिए, हर कोर पर आउटपुट का साइज़ f32[16,4] होता है.
BatchNormGrad
एल्गोरिदम के बारे में ज़्यादा जानकारी के लिए, XlaBuilder::BatchNormGrad और ओरिजनल बैच नॉर्मलाइज़ेशन पेपर भी देखें.
बैच नॉर्म के ग्रेडिएंट की गणना करता है.
BatchNormGrad(operand, scale, mean, variance, grad_output, epsilon,
feature_index)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
n डाइमेंशन वाला वह ऐरे जिसे सामान्य बनाना है (x) |
scale |
XlaOp |
एक डाइमेंशन वाला ऐरे (γ) |
mean |
XlaOp |
एक डाइमेंशन वाला ऐरे (μ) |
variance |
XlaOp |
एक डाइमेंशन वाला ऐरे (σ2) |
grad_output |
XlaOp |
BatchNormTraining (∇y) को पास किए गए ग्रेडिएंट |
epsilon |
float |
एप्सिलॉन वैल्यू (ϵ) |
feature_index |
int64 |
operand में, फ़ीचर डाइमेंशन का इंडेक्स |
फ़ीचर डाइमेंशन में मौजूद हर फ़ीचर के लिए (feature_index, operand में फ़ीचर डाइमेंशन का इंडेक्स है), ऑपरेशन में बाकी सभी डाइमेंशन में operand, offset, और scale के हिसाब से ग्रेडिएंट का हिसाब लगाया जाता है. feature_index, operand में मौजूद सुविधा डाइमेंशन के लिए एक मान्य इंडेक्स होना चाहिए.
तीन ग्रेडिएंट को इन फ़ॉर्मूला के हिसाब से तय किया जाता है. इसमें, operand के तौर पर चार डाइमेंशन वाला ऐरे, फ़ीचर डाइमेंशन इंडेक्स l, बैच साइज़ m, और स्पेस साइज़ w और h का इस्तेमाल किया गया है:
cl=1mwhm∑i=1w∑j=1h∑k=1(∇yijklxijkl−μlσ2l+ϵ)dl=1mwhm∑i=1w∑j=1h∑k=1∇yijkl∇xijkl=γl√σ2l+ϵ(∇yijkl−dl−cl(xijkl−μl))∇γl=m∑i=1w∑j=1h∑k=1(∇yijklxijkl−μl√σ2l+ϵ) ∇βl=m∑i=1w∑j=1h∑k=1∇yijkl
इनपुट mean और variance, बैच और जगह के डाइमेंशन में, पल की वैल्यू दिखाते हैं.
आउटपुट टाइप, तीन हैंडल का टपल होता है:
| आउटपुट | टाइप | सिमैंटिक |
|---|---|---|
grad_operand
|
XlaOp
|
इनपुट operand के हिसाब से ग्रेडिएंट (∇x) |
grad_scale
|
XlaOp
|
इनपुट scale के हिसाब से ग्रेडिएंट (∇γ) |
grad_offset
|
XlaOp
|
इनपुट offset के हिसाब से ग्रेडिएंट(∇β) |
BatchNormInference
एल्गोरिदम के बारे में ज़्यादा जानकारी के लिए, XlaBuilder::BatchNormInference और ओरिजनल बैच नॉर्मलाइज़ेशन पेपर भी देखें.
बैच और स्पेस डाइमेंशन में मौजूद किसी ऐरे को सामान्य बनाता है.
BatchNormInference(operand, scale, offset, mean, variance, epsilon,
feature_index)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
n डाइमेंशन वाला ऐसा ऐरे जिसे सामान्य बनाना है |
scale |
XlaOp |
एक डाइमेंशन वाला ऐरे |
offset |
XlaOp |
एक डाइमेंशन वाला ऐरे |
mean |
XlaOp |
एक डाइमेंशन वाला ऐरे |
variance |
XlaOp |
एक डाइमेंशन वाला ऐरे |
epsilon |
float |
एप्सिलॉन वैल्यू |
feature_index |
int64 |
operand में, फ़ीचर डाइमेंशन का इंडेक्स |
फ़ीचर डाइमेंशन (feature_index, operand में फ़ीचर डाइमेंशन का इंडेक्स है) में मौजूद हर फ़ीचर के लिए, ऑपरेशन बाकी सभी डाइमेंशन में औसत और वैरिएंस का हिसाब लगाता है. साथ ही, operand में हर एलिमेंट को सामान्य बनाने के लिए, औसत और वैरिएंस का इस्तेमाल करता है. feature_index, operand में मौजूद फ़ीचर डाइमेंशन के लिए एक मान्य इंडेक्स होना चाहिए.
BatchNormInference, हर बैच के लिए mean और variance का हिसाब लगाए बिना, BatchNormTraining को कॉल करने के बराबर है. यह अनुमानित वैल्यू के तौर पर, इनपुट mean और
variance का इस्तेमाल करता है. इस ऑपरेशन का मकसद, अनुमान लगाने में लगने वाले समय को कम करना है. इसलिए, इसका नाम BatchNormInference है.
आउटपुट, n-डाइमेंशन वाला नॉर्मलाइज़ किया गया ऐरे होता है. यह ऐरे, इनपुट operand के आकार का होता है.
BatchNormTraining
एल्गोरिदम के बारे में ज़्यादा जानकारी के लिए, XlaBuilder::BatchNormTraining और the original batch normalization paper भी देखें.
बैच और स्पेस डाइमेंशन में मौजूद किसी ऐरे को सामान्य बनाता है.
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
n डाइमेंशन वाला वह ऐरे जिसे सामान्य बनाना है (x) |
scale |
XlaOp |
एक डाइमेंशन वाला ऐरे (γ) |
offset |
XlaOp |
एक डाइमेंशन वाला ऐरे (β) |
epsilon |
float |
एप्सिलॉन वैल्यू (ϵ) |
feature_index |
int64 |
operand में, फ़ीचर डाइमेंशन का इंडेक्स |
फ़ीचर डाइमेंशन (feature_index, operand में फ़ीचर डाइमेंशन का इंडेक्स है) में मौजूद हर फ़ीचर के लिए, ऑपरेशन बाकी सभी डाइमेंशन में औसत और वैरिएंस का हिसाब लगाता है. साथ ही, operand में हर एलिमेंट को सामान्य बनाने के लिए, औसत और वैरिएंस का इस्तेमाल करता है. feature_index, operand में मौजूद फ़ीचर डाइमेंशन के लिए एक मान्य इंडेक्स होना चाहिए.
operand x में मौजूद हर बैच के लिए, एल्गोरिदम इस तरह काम करता है. इसमें m एलिमेंट होते हैं, जिनमें स्पेस डाइमेंशन का साइज़ w और h होता है. यह मानते हुए कि operand एक चार डाइमेंशन वाला कलेक्शन है:
फ़ीचर डाइमेंशन में, हर फ़ीचर
lके लिए बैच का औसत μl कैलकुलेट करता है: μl=1mwh∑mi=1∑wj=1∑hk=1xijklबैच वैरिएंस का हिसाब लगाता है σ2l: $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
नॉर्मलाइज़, स्केल, और शिफ़्ट करता है: yijkl=γl(xijkl−μl)2√σ2l+ϵ+βl
आम तौर पर, शून्य से भाग देने से जुड़ी गड़बड़ियों से बचने के लिए, एप्सिलॉन वैल्यू जोड़ी जाती है. यह वैल्यू आम तौर पर छोटी होती है.
आउटपुट टाइप, तीन XlaOp के टुपल होता है:
| आउटपुट | टाइप | सिमैंटिक |
|---|---|---|
output
|
XlaOp
|
n डाइमेंशन वाला ऐरे, जिसका आकार इनपुट operand (y) जैसा हो |
batch_mean |
XlaOp |
एक डाइमेंशन वाला ऐरे (μ) |
batch_var |
XlaOp |
एक डाइमेंशन वाला ऐरे (σ2) |
batch_mean और batch_var, ऊपर दिए गए फ़ॉर्मूला का इस्तेमाल करके, बैच और जगह के डाइमेंशन में कैलकुलेट किए गए मोमेंट हैं.
BitcastConvertType
XlaBuilder::BitcastConvertType भी देखें.
TensorFlow में tf.bitcast की तरह ही, यह किसी डेटा शेप से टारगेट शेप में, एलिमेंट के हिसाब से बिटकस्ट ऑपरेशन करता है. इनपुट और आउटपुट का साइज़ एक जैसा होना चाहिए: उदाहरण के लिए, बिटकस्ट रूटीन की मदद से s32 एलिमेंट, f32 एलिमेंट में बदल जाते हैं. साथ ही, एक s32 एलिमेंट चार s8 एलिमेंट में बदल जाता है. बिटकस्ट को कम-लेवल कास्ट के तौर पर लागू किया जाता है. इसलिए, अलग-अलग फ़्लोटिंग-पॉइंट रिप्रज़ेंटेशन वाली मशीनें अलग-अलग नतीजे देंगी.
BitcastConvertType(operand, new_element_type)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
डाइमेंशन D वाला टाइप T का ऐरे |
new_element_type |
PrimitiveType |
टाइप U |
ऑपरेंड और टारगेट शेप के डाइमेंशन मैच होने चाहिए. हालांकि, आखिरी डाइमेंशन के लिए ऐसा ज़रूरी नहीं है. यह डाइमेंशन, कन्वर्ज़न से पहले और बाद में प्रिमाइटिव साइज़ के अनुपात के हिसाब से बदल जाएगा.
सोर्स और डेस्टिनेशन एलिमेंट टाइप, टुपल नहीं होने चाहिए.
अलग-अलग चौड़ाई के प्राइमिटिव टाइप में बिटकस्ट-कन्वर्टिंग
BitcastConvert HLO निर्देश तब काम करता है, जब आउटपुट एलिमेंट टाइप T' का साइज़, इनपुट एलिमेंट T के साइज़ से मेल न खाता हो. पूरी प्रोसेस को कॉन्सेप्ट के हिसाब से बिटकस्ट माना जाता है. इसमें, मौजूदा बाइट में कोई बदलाव नहीं होता. इसलिए, आउटपुट एलिमेंट का शेप बदलना पड़ता है. B = sizeof(T), B' =
sizeof(T') के लिए, दो संभावित मामले हैं.
सबसे पहले, जब B > B', तो आउटपुट आकार को साइज़ के सबसे छोटे नए डाइमेंशन
B/B' मिलता है. उदाहरण के लिए:
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
असरदार स्केलर के लिए नियम पहले जैसा ही रहेगा:
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
इसके अलावा, B' > B के लिए निर्देश में यह ज़रूरी है कि इनपुट शेप का आखिरी लॉजिकल डाइमेंशन, B'/B के बराबर हो. साथ ही, कन्वर्ज़न के दौरान इस डाइमेंशन को हटा दिया जाता है:
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
ध्यान दें कि अलग-अलग बिटविड्थ के बीच कन्वर्ज़न, एलिमेंट के हिसाब से नहीं होते.
ब्रॉडकास्ट करें
XlaBuilder::Broadcast भी देखें.
ऐरे में मौजूद डेटा का डुप्लीकेट बनाकर, ऐरे में डाइमेंशन जोड़ता है.
Broadcast(operand, broadcast_sizes)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
डुप्लीकेट किया जाने वाला ऐरे |
broadcast_sizes |
ArraySlice<int64> |
नए डाइमेंशन के साइज़ |
नए डाइमेंशन बाईं ओर डाले जाते हैं. इसका मतलब है कि अगर broadcast_sizes में वैल्यू {a0, ..., aN} है और ऑपरेंड के शेप में डाइमेंशन {b0, ..., bM} हैं, तो आउटपुट के शेप में डाइमेंशन {a0, ..., aN, b0, ..., bM} होंगे.
नए डाइमेंशन, ऑपरेंड की कॉपी में इंडेक्स होते हैं, जैसे कि
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
उदाहरण के लिए, अगर operand एक स्केलर f32 है, जिसकी वैल्यू 2.0f है और
broadcast_sizes {2, 3} है, तो नतीजा एक ऐरे होगा, जिसका शेप
f32[2, 3] होगा और नतीजे में सभी वैल्यू 2.0f होंगी.
BroadcastInDim
XlaBuilder::BroadcastInDim भी देखें.
ऐरे में मौजूद डेटा को डुप्लीकेट करके, ऐरे के डाइमेंशन का साइज़ और संख्या बढ़ाता है.
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
डुप्लीकेट किया जाने वाला ऐरे |
out_dim_size |
ArraySlice<int64> |
टारगेट किए गए आकार के डाइमेंशन के साइज़ |
broadcast_dimensions |
ArraySlice<int64> |
ऑपरेंड शेप का हर डाइमेंशन, टारगेट शेप के किस डाइमेंशन से मेल खाता है |
यह ब्रॉडकास्ट की तरह ही है. हालांकि, इसमें डाइमेंशन को कहीं भी जोड़ा जा सकता है और साइज़ 1 वाले मौजूदा डाइमेंशन को बड़ा किया जा सकता है.
operand को out_dim_size से बताए गए आकार पर ब्रॉडकास्ट किया जाता है.
broadcast_dimensions, operand के डाइमेंशन को टारगेट शेप के डाइमेंशन से मैप करता है. इसका मतलब है कि ऑपरेंड का i'th डाइमेंशन, आउटपुट शेप के broadcast_dimension[i]'th डाइमेंशन से मैप होता है. operand के डाइमेंशन का साइज़ 1 होना चाहिए या वह आउटपुट शेप में मौजूद डाइमेंशन के साइज़ के बराबर होना चाहिए. बाकी डाइमेंशन, साइज़ 1 के डाइमेंशन से भरे जाते हैं. इसके बाद, डीजनरेट-डाइमेंशन ब्रॉडकास्टिंग, आउटपुट शेप तक पहुंचने के लिए इन डीजनरेट डाइमेंशन के साथ ब्रॉडकास्ट करती है. ब्रॉडकास्टिंग पेज पर, सेमेटिक्स के बारे में पूरी जानकारी दी गई है.
कॉल करें
XlaBuilder::Call भी देखें.
दिए गए आर्ग्युमेंट के साथ कैलकुलेशन को शुरू करता है.
Call(computation, args...)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
computation |
XlaComputation |
किसी भी टाइप के N पैरामीटर के साथ T_0, T_1, ..., T_{N-1} -> S टाइप का हिसाब लगाना |
args |
N XlaOps का क्रम |
किसी भी टाइप के N आर्ग्युमेंट |
args की आर्टी और टाइप, computation के पैरामीटर से मेल खाने चाहिए. इसमें कोई args नहीं होना चाहिए.
CompositeCall
XlaBuilder::CompositeCall भी देखें.
यह अन्य StableHLO ऑपरेशन से बना (कंपोज़ किया गया) ऑपरेशन होता है. इसमें इनपुट और composite_attributes लेते हुए नतीजे मिलते हैं. ऑपरेशन के सिमेंटिक्स को डिकंपोज़िशन एट्रिब्यूट की मदद से लागू किया जाता है. प्रोग्राम के सेमेंटेटिक्स में बदलाव किए बिना, कॉम्पोज़िट ऑपरेशन को उसके डिकंपोज़िशन से बदला जा सकता है. जिन मामलों में डिकंपोज़िशन को इनलाइन करने से, ऑपरेशन के एक जैसे सेमेटिक्स नहीं मिलते उनमें custom_call का इस्तेमाल करें.
वर्शन फ़ील्ड (डिफ़ॉल्ट रूप से 0 पर सेट) का इस्तेमाल, यह बताने के लिए किया जाता है कि किसी कंपोजिट के सेमेंटेक्स में कब बदलाव हुआ.
इस ऑपरेशन को एट्रिब्यूट is_composite=true के साथ kCall के तौर पर लागू किया जाता है. decomposition फ़ील्ड की जानकारी, computation एट्रिब्यूट से मिलती है. फ़्रंटएंड एट्रिब्यूट, बाकी एट्रिब्यूट को composite. के साथ स्टोर करते हैं.
CompositeCall ऑपरेशन का उदाहरण:
f32[] call(f32[] %cst), to_apply=%computation, is_composite=true,
frontend_attributes = {
composite.name="foo.bar",
composite.attributes={n = 1 : i32, tensor = dense<1> : tensor<i32>},
composite.version="1"
}
Call(computation, args..., name, composite_attributes, version)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
inputs |
XlaOp |
वैरिएबल वैल्यू की संख्या |
name |
string |
कंपोज़िट का नाम |
composite_attributes |
ज़रूरी नहीं string |
एट्रिब्यूट की स्ट्रिंग वाली डिक्शनरी (ज़रूरी नहीं) |
decomposition |
XlaComputation |
किसी भी टाइप के N पैरामीटर के साथ T_0, T_1, ..., T_{N-1} -> S टाइप का हिसाब लगाना |
version |
int64. |
कॉम्पोज़िट ऑपरेशन के सेमेंटिक में, वर्शन के अपडेट की संख्या |
Cholesky
XlaBuilder::Cholesky भी देखें.
यह सिमेट्रिक (हर्मिटियन) पॉज़िटिव डेफ़ाइनाइट मैट्रिक्स के बैच का चोलस्की डिकंपोज़िशन करता है.
Cholesky(a, lower)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
a |
XlaOp |
दो से ज़्यादा डाइमेंशन वाला, कॉम्प्लेक्स या फ़्लोटिंग-पॉइंट टाइप का ऐरे. |
lower |
bool |
a के ऊपरी या निचले ट्रैंगल का इस्तेमाल करना है या नहीं. |
अगर lower, true है, तो l ऐसी लोअर-ट्राएंगल मैट्रिक्स कैलकुलेट करती है कि a=lहो.lT. अगर lower false है, तो ऊपरी-त्रिकोणीय मैट्रिक्स u का हिसाब लगाता है, ताकि
a=uT.u.
इनपुट डेटा को सिर्फ़ a के निचले/ऊपरी त्रिकोण से पढ़ा जाता है. यह lower की वैल्यू पर निर्भर करता है. दूसरे ट्राएंगल की वैल्यू को अनदेखा कर दिया जाता है. आउटपुट डेटा, उसी ट्राएंगल में दिखाया जाता है. दूसरे ट्राएंगल में मौजूद वैल्यू, लागू करने के तरीके के हिसाब से तय होती हैं और वे कुछ भी हो सकती हैं.
अगर a में दो से ज़्यादा डाइमेंशन हैं, तो a को मैट्रिक के बैच के तौर पर माना जाता है. इसमें, दो छोटे डाइमेंशन को छोड़कर सभी डाइमेंशन, बैच डाइमेंशन होते हैं.
अगर a, सिमिट्रिक (हर्मिटियन) पॉज़िटिव डेफ़ाइनिट नहीं है, तो नतीजा, लागू करने के तरीके के हिसाब से तय होता है.
क्लैंप करें
XlaBuilder::Clamp भी देखें.
ऑपरेंड को कम से कम और ज़्यादा से ज़्यादा वैल्यू की रेंज में क्लैंप करता है.
Clamp(min, operand, max)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
min |
XlaOp |
T टाइप का कलेक्शन |
operand |
XlaOp |
T टाइप का कलेक्शन |
max |
XlaOp |
T टाइप का कलेक्शन |
ऑपरेंड और कम से कम और ज़्यादा से ज़्यादा वैल्यू दी गई है. अगर ऑपरेंड, कम से कम और ज़्यादा से ज़्यादा वैल्यू के बीच की रेंज में है, तो ऑपरेंड दिखाता है. अगर ऑपरेंड इस रेंज से कम है, तो कम से कम वैल्यू दिखाता है. अगर ऑपरेंड इस रेंज से ज़्यादा है, तो ज़्यादा से ज़्यादा वैल्यू दिखाता है. इसका मतलब है कि clamp(a, x, b) = min(max(a, x), b).
तीनों ऐरे एक ही साइज़ के होने चाहिए. इसके अलावा, ब्रॉडकास्ट के पाबंदी वाले फ़ॉर्म के तौर पर, min और/या max, T टाइप का स्केलर हो सकता है.
स्केलर min और max के साथ उदाहरण:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
छोटा करें
XlaBuilder::Collapse और tf.reshape ऑपरेशन भी देखें.
किसी ऐरे के डाइमेंशन को एक डाइमेंशन में छोटा कर देता है.
Collapse(operand, dimensions)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का कलेक्शन |
dimensions |
int64 वेक्टर |
क्रम में, T के डाइमेंशन का लगातार सबसेट. |
'छोटा करें', ऑपरेंड के डाइमेंशन के दिए गए सबसेट को एक डाइमेंशन से बदल देता है. इनपुट आर्ग्युमेंट, टाइप T का कोई भी अरे और डाइमेंशन इंडेक्स का संकलन के समय का कॉन्स्टेंट वेक्टर होता है. डाइमेंशन इंडेक्स, T के डाइमेंशन के क्रम में (कम से ज़्यादा डाइमेंशन नंबर) और एक-दूसरे के बाद वाले सबसेट होने चाहिए. इसलिए, {0, 1, 2}, {0, 1} या {1, 2} सभी मान्य डाइमेंशन सेट हैं, लेकिन
{1, 0} या {0, 2} नहीं हैं. इनकी जगह एक नए डाइमेंशन को डाइमेंशन के क्रम में उसी जगह पर रखा जाता है जहां ये डाइमेंशन होते हैं. साथ ही, नए डाइमेंशन का साइज़, ओरिजनल डाइमेंशन के साइज़ के प्रॉडक्ट के बराबर होता है. dimensions में डाइमेंशन की सबसे कम संख्या, लूप नेस्ट में सबसे धीरे बदलने वाला डाइमेंशन (सबसे बड़ा) होता है. यह डाइमेंशन, इन डाइमेंशन को छोटा कर देता है. वहीं, डाइमेंशन की सबसे ज़्यादा संख्या, सबसे तेज़ी से बदलने वाला डाइमेंशन (सबसे छोटा) होता है. अगर आपको कॉलपस करने के लिए, सामान्य क्रम से ज़्यादा जानकारी चाहिए, तो tf.reshape ऑपरेटर देखें.
उदाहरण के लिए, मान लें कि v 24 एलिमेंट का ऐरे है:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
CollectivePermute
XlaBuilder::CollectivePermute भी देखें.
CollectivePermute एक ऐसा ऑपरेशन है जो डेटा को क्रॉस रिप्लिकेट में भेजता और पाता है.
CollectivePermute(operand, source_target_pairs)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
n डाइमेंशन वाला इनपुट ऐरे |
source_target_pairs |
<int64, int64> वेक्टर |
(source_replica_id, target_replica_id) पेयर की सूची. हर पेयर के लिए, ऑपरेंड को सोर्स रेप्लिक से टारगेट रेप्लिक पर भेजा जाता है. |
ध्यान दें कि source_target_pair पर ये पाबंदियां हैं:
- किसी भी दो पेयर का टारगेट रेप्लिक आईडी एक जैसा नहीं होना चाहिए. साथ ही, उनका सोर्स रेप्लिक आईडी भी एक जैसा नहीं होना चाहिए.
- अगर कोई रेप्लिका आईडी किसी भी पेयर में टारगेट नहीं है, तो उस रेप्लिका पर आउटपुट, 0(s) से बना एक टेंसर होता है. यह टेंसर, इनपुट के आकार का होता है.
स्ट्रिंग जोड़ना
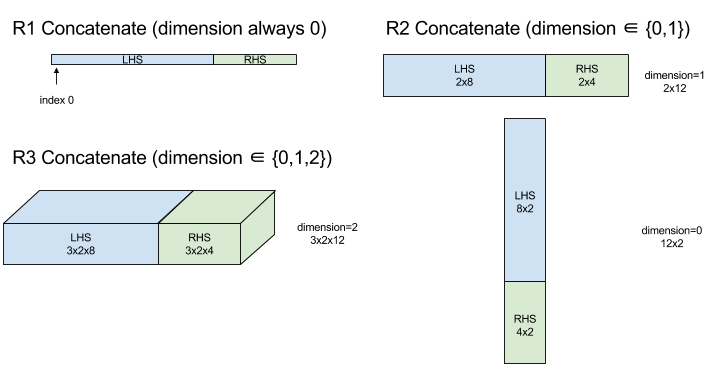
XlaBuilder::ConcatInDim भी देखें.
Concatenate फ़ंक्शन, कई ऐरे ऑपरेंड से एक ऐरे बनाता है. ऐरे में उतने ही डाइमेंशन होते हैं जितने इनपुट ऐरे ऑपरेंड में होते हैं. इनपुट ऐरे ऑपरेंड में भी एक जैसे डाइमेंशन होने चाहिए. साथ ही, ऐरे में आर्ग्युमेंट उसी क्रम में होते हैं जिस क्रम में उन्हें तय किया गया था.
Concatenate(operands..., dimension)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operands |
N XlaOp का क्रम |
डाइमेंशन [L0, L1, ...] वाले T टाइप के N ऐरे. इसके लिए, N >= 1 होना ज़रूरी है. |
dimension |
int64 |
[0, N) इंटरवल में मौजूद वैल्यू, जो operands के बीच जोड़े जाने वाले डाइमेंशन का नाम बताती है. |
dimension को छोड़कर, सभी डाइमेंशन एक जैसे होने चाहिए. ऐसा इसलिए है, क्योंकि XLA में "रैग्ड" ऐरे काम नहीं करते. यह भी ध्यान दें कि 0-डाइमेंशन वाली वैल्यू को आपस में जोड़ा नहीं जा सकता. ऐसा इसलिए, क्योंकि उस डाइमेंशन का नाम नहीं दिया जा सकता जिसमें वैल्यू को जोड़ा जाता है.
एक डाइमेंशन वाला उदाहरण:
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
>>> {2, 3, 4, 5, 6, 7}
दो डाइमेंशन वाला उदाहरण:
let a = {
{1, 2},
{3, 4},
{5, 6},
};
let b = {
{7, 8},
};
Concat({a, b}, 0)
>>> {
{1, 2},
{3, 4},
{5, 6},
{7, 8},
}
डायग्राम:
कंडीशनल
XlaBuilder::Conditional भी देखें.
Conditional(pred, true_operand, true_computation, false_operand,
false_computation)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
pred |
XlaOp |
PRED टाइप का स्केलर |
true_operand |
XlaOp |
T0टाइप का आर्ग्युमेंट |
true_computation |
XlaComputation |
T0→Sटाइप का XlaComputation |
false_operand |
XlaOp |
T1टाइप का आर्ग्युमेंट |
false_computation |
XlaComputation |
T1→Sटाइप का XlaComputation |
अगर pred true है, तो true_computation को और pred के false होने पर false_computation को लागू करता है. साथ ही, नतीजा दिखाता है.
true_computation में T0 टाइप का एक आर्ग्युमेंट होना चाहिए. साथ ही, इसे true_operand के साथ शुरू किया जाएगा, जो एक ही टाइप का होना चाहिए. false_computation को T1 टाइप का एक आर्ग्युमेंट लेना चाहिए. साथ ही, इसे false_operand के साथ शुरू किया जाएगा, जो एक ही टाइप का होना चाहिए. true_computation और false_computation की रिटर्न वैल्यू का टाइप एक ही होना चाहिए.
ध्यान दें कि pred की वैल्यू के आधार पर, true_computation और false_computation में से सिर्फ़ एक को ही लागू किया जाएगा.
Conditional(branch_index, branch_computations, branch_operands)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
branch_index |
XlaOp |
S32 टाइप का स्केलर |
branch_computations |
N XlaComputation का क्रम |
T0→S,T1→S,...,TN−1→Sटाइप के XlaComputations |
branch_operands |
N XlaOp का क्रम |
T0,T1,...,TN−1टाइप के आर्ग्युमेंट |
branch_computations[branch_index] को लागू करता है और नतीजा दिखाता है. अगर branch_index एक ऐसा S32 है जो < 0 या >= N है, तो branch_computations[N-1] को डिफ़ॉल्ट शाखा के तौर पर चलाया जाता है.
हर branch_computations[b] में Tb टाइप का एक आर्ग्युमेंट होना चाहिए. साथ ही, इसे branch_operands[b] के साथ शुरू किया जाएगा, जो एक ही टाइप का होना चाहिए. हर branch_computations[b] की रिटर्न की गई वैल्यू का टाइप एक ही होना चाहिए.
ध्यान दें कि branch_index की वैल्यू के आधार पर, branch_computations में से सिर्फ़ एक फ़ंक्शन लागू होगा.
Conv (कॉन्वोल्यूशन)
XlaBuilder::Conv भी देखें.
ConvWithGeneralPadding की तरह ही, लेकिन पैडिंग को कम शब्दों में SAME या VALID के तौर पर बताया गया है. SAME पैडिंग, इनपुट (lhs) को शून्य से पैड करती है, ताकि बिना स्ट्राइडिंग के आउटपुट का साइज़, इनपुट के साइज़ जैसा ही रहे. VALID पैडिंग का मतलब है कि कोई पैडिंग नहीं है.
ConvWithGeneralPadding (कंवोल्यूशन)
XlaBuilder::ConvWithGeneralPadding भी देखें.
न्यूरल नेटवर्क में इस्तेमाल होने वाले कन्वोल्यूशन का हिसाब लगाता है. यहां, कॉन्वोल्यूशन को n-डाइमेंशनल विंडो के तौर पर देखा जा सकता है, जो n-डाइमेंशनल बेस एरिया में चलती है. साथ ही, विंडो की हर संभावित स्थिति के लिए हिसाब लगाया जाता है.
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
lhs |
XlaOp |
इनपुट का (n+2)-डाइमेंशन वाला ऐरे |
rhs |
XlaOp |
(n+2)-डाइमेंशनल ऐरे, जिसमें कर्नेल वेट होते हैं |
window_strides |
ArraySlice<int64> |
कर्नेल की चौड़ाई के n-d ऐरे |
padding |
ArraySlice< pair<int64,int64>> |
(low, high) पैडिंग का n-d ऐरे |
lhs_dilation |
ArraySlice<int64> |
n-d lhs dilation factor array |
rhs_dilation |
ArraySlice<int64> |
n-d rhs dilation factor array |
feature_group_count |
int64 | सुविधा ग्रुप की संख्या |
batch_group_count |
int64 | बैच ग्रुप की संख्या |
मान लें कि n, स्पेस डाइमेंशन की संख्या है. lhs आर्ग्युमेंट, (n+2)-डाइमेंशन वाला ऐरे होता है, जिसमें बेस एरिया की जानकारी होती है. इसे इनपुट कहा जाता है,
भले ही, rhs भी एक इनपुट है. न्यूरल नेटवर्क में, ये इनपुट ऐक्टिवेशन होते हैं. n+2 डाइमेंशन इस क्रम में होते हैं:
batch: इस डाइमेंशन में मौजूद हर कोऑर्डिनेट, एक अलग इनपुट दिखाता है. इसके लिए, कॉन्वोल्यूशन किया जाता है.z/depth/features: बेस एरिया में हर (y,x) पोज़िशन से जुड़ा एक वेक्टर होता है, जो इस डाइमेंशन में जाता है.spatial_dims:nस्पेस डाइमेंशन के बारे में बताता है. इससे उस आधार क्षेत्र के बारे में पता चलता है जिस पर विंडो चलती है.
rhs आर्ग्युमेंट, (n+2)-डाइमेंशन वाला ऐरे होता है, जिसमें कॉन्वोल्यूशनल फ़िल्टर/कर्नल/विंडो की जानकारी होती है. डाइमेंशन इस क्रम में होते हैं:
output-z: आउटपुट काzडाइमेंशन.input-z: इस डाइमेंशन के साइज़ कोfeature_group_countसे गुणा करने पर, lhs में मौजूदzडाइमेंशन के साइज़ के बराबर होना चाहिए.spatial_dims:nस्पेस डाइमेंशन के बारे में बताता है. ये डाइमेंशन, बेस एरिया में चलने वाली n-d विंडो के बारे में बताते हैं.
window_strides आर्ग्युमेंट, स्पेस डाइमेंशन में कॉन्वोल्यूशनल विंडो की stride तय करता है. उदाहरण के लिए, अगर पहले स्पेस डाइमेंशन में स्ट्राइड 3 है, तो विंडो को सिर्फ़ उन निर्देशांक पर रखा जा सकता है जहां पहला स्पेस इंडेक्स 3 से भागा जा सकता है.
padding आर्ग्युमेंट से पता चलता है कि बेस एरिया में शून्य पैडिंग कितनी होनी चाहिए. पैडिंग की वैल्यू, नेगेटिव हो सकती है -- नेगेटिव पैडिंग की कुल वैल्यू से पता चलता है कि कॉन्वोल्यूशन करने से पहले, तय किए गए डाइमेंशन से कितने एलिमेंट हटाने हैं. padding[0], डाइमेंशन y के लिए पैडिंग तय करता है और padding[1], डाइमेंशन x के लिए पैडिंग तय करता है. हर जोड़े में, पहले एलिमेंट के तौर पर कम पैडिंग और दूसरे एलिमेंट के तौर पर ज़्यादा पैडिंग होती है. कम पैडिंग, इंडेक्स के निचले हिस्से में लागू होती है, जबकि ज़्यादा पैडिंग, इंडेक्स के ऊपरी हिस्से में लागू होती है. उदाहरण के लिए, अगर padding[1] (2,3) है, तो दूसरे स्पेस डाइमेंशन में बाईं ओर दो शून्य और दाईं ओर तीन शून्य पैडिंग होंगे. पैडिंग का इस्तेमाल करना, कॉन्वोल्यूशन करने से पहले इनपुट (lhs) में वही शून्य वैल्यू डालने के बराबर है.
lhs_dilation और rhs_dilation आर्ग्युमेंट से, हर स्पेस डाइमेंशन में, lhs और rhs पर लागू होने वाला डाइलेशन फ़ैक्टर तय होता है. अगर किसी स्पेस डाइमेंशन में डाइलेशन फ़ैक्टर d है, तो उस डाइमेंशन की हर एंट्री के बीच में d-1 होल अपने-आप दिखते हैं. इससे ऐरे का साइज़ बढ़ जाता है. छिद्रों को कोई कार्रवाई न करने वाली वैल्यू से भरा जाता है. कन्वोल्यूशन के लिए, इसका मतलब शून्य होता है.
दाईं ओर मौजूद वैल्यू को बड़ा करने की प्रोसेस को एट्रॉस कन्वोल्यूशन भी कहा जाता है. ज़्यादा जानकारी के लिए, tf.nn.atrous_conv2d देखें. बाईं ओर मौजूद मैट्रिक्स को बड़ा करने की प्रोसेस को ट्रांसपोज़्ड
कन्वोल्यूशन भी कहा जाता है. ज़्यादा जानकारी के लिए, tf.nn.conv2d_transpose देखें.
feature_group_count आर्ग्युमेंट (डिफ़ॉल्ट वैल्यू 1) का इस्तेमाल, ग्रुप किए गए कॉन्वोल्यूशन के लिए किया जा सकता है. feature_group_count को इनपुट और आउटपुट, दोनों फ़ीचर डाइमेंशन का डिविज़र होना चाहिए. अगर feature_group_count एक से ज़्यादा है, तो इसका मतलब है कि कॉन्सेप्ट के हिसाब से, इनपुट और आउटपुट फ़ीचर डाइमेंशन और rhs आउटपुट फ़ीचर डाइमेंशन को बराबर तौर पर कई feature_group_count ग्रुप में बांटा गया है. हर ग्रुप में, फ़ीचर का एक क्रम होता है. rhs की इनपुट फ़ीचर डाइमेंशन की वैल्यू, lhs की इनपुट फ़ीचर डाइमेंशन की वैल्यू को feature_group_count से भाग देने के बराबर होनी चाहिए. ऐसा इसलिए, क्योंकि इसमें इनपुट फ़ीचर के ग्रुप का साइज़ पहले से मौजूद होता है. कई अलग-अलग कॉन्वोल्यूशन के लिए feature_group_count का हिसाब लगाने के लिए, i-th ग्रुप का एक साथ इस्तेमाल किया जाता है. इन कॉन्वोल्यूशन के नतीजों को आउटपुट फ़ीचर डाइमेंशन में जोड़ दिया जाता है.
डेप्थ-वाइज़ कन्वोल्यूशन के लिए, feature_group_count आर्ग्युमेंट को इनपुट फ़ीचर डाइमेंशन पर सेट किया जाएगा. साथ ही, फ़िल्टर को [filter_height, filter_width, in_channels, channel_multiplier] से [filter_height, filter_width, 1, in_channels * channel_multiplier] में बदल दिया जाएगा. ज़्यादा जानकारी के लिए, tf.nn.depthwise_conv2d देखें.
बैकप्रोपगेशन के दौरान, ग्रुप किए गए फ़िल्टर के लिए batch_group_count (डिफ़ॉल्ट वैल्यू 1) आर्ग्युमेंट का इस्तेमाल किया जा सकता है. batch_group_count, lhs (इनपुट) बैच डाइमेंशन के साइज़ का Divisor होना चाहिए. अगर batch_group_count, 1 से ज़्यादा है, तो इसका मतलब है कि आउटपुट बैच डाइमेंशन का साइज़ input batch
/ batch_group_count होना चाहिए. batch_group_count, आउटपुट फ़ीचर के साइज़ का डिविज़र होना चाहिए.
आउटपुट आकार में ये डाइमेंशन इस क्रम में होते हैं:
batch: इस डाइमेंशन के साइज़ कोbatch_group_countसे गुणा करने पर, lhs में मौजूदbatchडाइमेंशन के साइज़ के बराबर होना चाहिए.z: यह साइज़, कर्नेल (rhs) पर मौजूदoutput-zके साइज़ के बराबर होना चाहिए.spatial_dims: कॉन्वोल्यूशनल विंडो के हर मान्य प्लेसमेंट के लिए एक वैल्यू.

ऊपर दिए गए इलस्ट्रेशन में दिखाया गया है कि batch_group_count फ़ील्ड कैसे काम करता है. हम हर lhs बैच को batch_group_count ग्रुप में बांटते हैं. साथ ही, आउटपुट फ़ीचर के लिए भी ऐसा ही करते हैं. इसके बाद, इनमें से हर ग्रुप के लिए, हम एक-दूसरे के साथ कॉन्वोल्यूशन करते हैं और आउटपुट की सुविधा के डाइमेंशन के साथ आउटपुट को जोड़ते हैं. अन्य सभी डाइमेंशन (सुविधा और स्पेस) के ऑपरेशनल सिमेंटिक में कोई बदलाव नहीं हुआ है.
कॉन्वोल्यूशनल विंडो की सही जगहें, पैडिंग के बाद आधार क्षेत्र के साइज़ और स्ट्राइड के हिसाब से तय की जाती हैं.
कॉन्वोल्यूशन क्या करता है, यह बताने के लिए 2D कॉन्वोल्यूशन का उदाहरण लें और आउटपुट में कुछ तय batch, z, y, x निर्देशांक चुनें. इसके बाद, (y,x), बेस एरिया में विंडो के कोने की पोज़िशन होती है. उदाहरण के लिए, ऊपरी बायां कोना, जो स्पेस डाइमेंशन के हिसाब से तय होता है. अब हमारे पास बेस एरिया से ली गई 2D विंडो है, जहां हर 2D पॉइंट, 1D वेक्टर से जुड़ा होता है. इससे हमें 3D बॉक्स मिलता है. कन्वोल्यूशनल कर्नेल से, हमने आउटपुट कोऑर्डिनेट z को ठीक किया है. इसलिए, हमारे पास 3D बॉक्स भी है. दोनों बॉक्स के डाइमेंशन एक जैसे हैं. इसलिए, हम दोनों बॉक्स के एलिमेंट के हिसाब से प्रॉडक्ट का योग (जैसे कि डॉट प्रॉडक्ट) कर सकते हैं. यह आउटपुट वैल्यू है.
ध्यान दें कि अगर output-z, है, तो विंडो की हर पोज़िशन, आउटपुट में z डाइमेंशन में पांच वैल्यू जनरेट करती है. ये वैल्यू, कॉन्वोल्यूशनल केरल के किस हिस्से का इस्तेमाल करती हैं, इस आधार पर अलग-अलग होती हैं - हर output-z कोऑर्डिनेट के लिए, वैल्यू का एक अलग 3D बॉक्स होता है. इसलिए, इसे पांच अलग-अलग कॉन्वोल्यूशन के तौर पर देखा जा सकता है. इनमें से हर कॉन्वोल्यूशन के लिए अलग फ़िल्टर का इस्तेमाल किया जाता है.
पैडिंग और स्ट्राइडिंग के साथ 2D कन्वोल्यूशन के लिए, यहां स्यूडो-कोड दिया गया है:
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
ConvertElementType
XlaBuilder::ConvertElementType भी देखें.
C++ में एलिमेंट के हिसाब से static_cast की तरह ही, यह भी डेटा शेप से टारगेट शेप में एलिमेंट के हिसाब से बदलाव करता है. डाइमेंशन एक जैसे होने चाहिए और कन्वर्ज़न, एलिमेंट के हिसाब से होना चाहिए. उदाहरण के लिए, s32 से f32 कन्वर्ज़न रूटीन की मदद से, s32 एलिमेंट f32 एलिमेंट बन जाते हैं.
ConvertElementType(operand, new_element_type)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
डाइमेंशन D वाला टाइप T का ऐरे |
new_element_type |
PrimitiveType |
टाइप U |
ऑपरेंड और टारगेट आकार के डाइमेंशन मेल खाने चाहिए. सोर्स और डेस्टिनेशन एलिमेंट टाइप, टुपल नहीं होने चाहिए.
T=s32 से U=f32 जैसे कन्वर्ज़न के लिए, सामान्य int-to-float कन्वर्ज़न रूटीन लागू होगा. जैसे, राउंड-टू-नियरेस्ट-ईवन.
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
CrossReplicaSum
यह फ़ंक्शन, योग के हिसाब से AllReduce करता है.
CustomCall
XlaBuilder::CustomCall भी देखें.
कैलकुलेशन में, उपयोगकर्ता से मिले फ़ंक्शन को कॉल करना.
CustomCall(target_name, args..., shape)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
target_name |
string |
फ़ंक्शन का नाम. इस सिंबल के नाम को टारगेट करने वाला कॉल निर्देश जारी किया जाएगा. |
args |
N XlaOps का क्रम |
किसी भी तरह के N आर्ग्युमेंट, जिन्हें फ़ंक्शन में पास किया जाएगा. |
shape |
Shape |
फ़ंक्शन का आउटपुट आकार |
फ़ंक्शन का सिग्नेचर एक जैसा होता है, भले ही आर्ग्युमेंट की संख्या या टाइप कुछ भी हो:
extern "C" void target_name(void* out, void** in);
उदाहरण के लिए, अगर CustomCall का इस्तेमाल इस तरह किया जाता है:
let x = f32[2] {1,2};
let y = f32[2x3] { {10, 20, 30}, {40, 50, 60} };
CustomCall("myfunc", {x, y}, f32[3x3])
myfunc को लागू करने का उदाहरण यहां दिया गया है:
extern "C" void myfunc(void* out, void** in) {
float (&x)[2] = *static_cast<float(*)[2]>(in[0]);
float (&y)[2][3] = *static_cast<float(*)[2][3]>(in[1]);
EXPECT_EQ(1, x[0]);
EXPECT_EQ(2, x[1]);
EXPECT_EQ(10, y[0][0]);
EXPECT_EQ(20, y[0][1]);
EXPECT_EQ(30, y[0][2]);
EXPECT_EQ(40, y[1][0]);
EXPECT_EQ(50, y[1][1]);
EXPECT_EQ(60, y[1][2]);
float (&z)[3][3] = *static_cast<float(*)[3][3]>(out);
z[0][0] = x[1] + y[1][0];
// ...
}
उपयोगकर्ता के दिए गए फ़ंक्शन का कोई साइड इफ़ेक्ट नहीं होना चाहिए. साथ ही, इसे एक बार से ज़्यादा बार लागू नहीं किया जाना चाहिए.
डॉट
XlaBuilder::Dot भी देखें.
Dot(lhs, rhs)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
lhs |
XlaOp |
T टाइप का कलेक्शन |
rhs |
XlaOp |
T टाइप का कलेक्शन |
इस ऑपरेशन का सटीक सेमेटिक्स, ऑपरेंड की रैंक पर निर्भर करता है:
| इनपुट | आउटपुट | सिमैंटिक |
|---|---|---|
vector [n] dot vector [n] |
स्केलर | वेक्टर का डॉट प्रॉडक्ट |
मैट्रिक्स [m x k] dot वेक्टर [k] |
वेक्टर [m] | मैट्रिक्स-वेक्टर का गुणन |
मैट्रिक्स [m x k] dot मैट्रिक्स [k x n] |
मैट्रिक्स [m x n] | मैट्रिक्स-मैट्रिक्स गुणन |
यह ऑपरेशन, lhs के दूसरे डाइमेंशन (या एक डाइमेंशन होने पर पहले डाइमेंशन) और rhs के पहले डाइमेंशन में मौजूद प्रॉडक्ट का कुल योग दिखाता है. ये "कॉन्ट्रैक्ट किए गए" डाइमेंशन हैं. lhs और rhs के कॉन्ट्रैक्ट किए गए डाइमेंशन एक जैसे होने चाहिए. इसका इस्तेमाल, सदिशों के बीच डॉट प्रॉडक्ट करने, सदिश/मैट्रिक्स के गुणन या मैट्रिक्स/मैट्रिक्स के गुणन के लिए किया जा सकता है.
DotGeneral
XlaBuilder::DotGeneral भी देखें.
DotGeneral(lhs, rhs, dimension_numbers)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
lhs |
XlaOp |
T टाइप का कलेक्शन |
rhs |
XlaOp |
T टाइप का कलेक्शन |
dimension_numbers |
DotDimensionNumbers |
कॉन्ट्रैक्टिंग और बैच डाइमेंशन नंबर |
यह बिंदु की तरह ही है. हालांकि, इसमें lhs और rhs, दोनों के लिए कॉन्ट्रैक्ट और बैच डाइमेंशन की संख्या तय की जा सकती है.
| DotDimensionNumbers फ़ील्ड | टाइप | सिमैंटिक |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | lhs कॉन्ट्रैक्टिंग डाइमेंशन के लिए
संख्याएं |
rhs_contracting_dimensions
|
repeated int64 | rhs कॉन्ट्रैक्टिंग डाइमेंशन के लिए
संख्याएं |
lhs_batch_dimensions
|
repeated int64 | lhs बैच डाइमेंशन के नंबर |
rhs_batch_dimensions
|
repeated int64 | rhs बैच डाइमेंशन के नंबर |
DotGeneral, dimension_numbers में बताए गए कॉन्ट्रैक्टिंग डाइमेंशन के हिसाब से प्रॉडक्ट का जोड़ करता है.
lhs और rhs से जुड़े कॉन्ट्रैक्टिंग डाइमेंशन नंबर एक जैसे होने ज़रूरी नहीं हैं. हालांकि, इनका डाइमेंशन साइज़ एक जैसा होना चाहिए.
डाइमेंशन की संख्या कम करने का उदाहरण:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { {6.0, 12.0},
{15.0, 30.0} }
lhs और rhs से जुड़े बैच डाइमेंशन नंबर के डाइमेंशन साइज़ एक जैसे होने चाहिए.
बैच डाइमेंशन नंबर (बैच साइज़ 2, 2x2 मैट्रिक्स) का उदाहरण:
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| इनपुट | आउटपुट | सिमैंटिक |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | बैच matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | batch matmul |
इससे पता चलता है कि नतीजे में दिखने वाले डाइमेंशन का नंबर, बैच डाइमेंशन से शुरू होता है. इसके बाद, lhs नॉन-कांट्रैक्टिंग/नॉन-बैच डाइमेंशन और आखिर में rhs नॉन-कांट्रैक्टिंग/नॉन-बैच डाइमेंशन आता है.
DynamicSlice
XlaBuilder::DynamicSlice भी देखें.
DynamicSlice, डाइनैमिक
start_indices पर इनपुट कलेक्शन से एक सब-कलेक्शन निकालता है. हर डाइमेंशन में स्लाइस का साइज़, size_indices में पास किया जाता है. यह हर डाइमेंशन में, एक्सक्लूज़िव स्लाइस इंटरवल के आखिरी पॉइंट की जानकारी देता है: [start, start + size). start_indices का आकार एक डाइमेंशन वाला होना चाहिए. साथ ही, डाइमेंशन का साइज़, operand के डाइमेंशन की संख्या के बराबर होना चाहिए.
DynamicSlice(operand, start_indices, size_indices)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का N डाइमेंशन वाला ऐरे |
start_indices |
N XlaOp का क्रम |
N स्केलर इंटिजर की सूची, जिसमें हर डाइमेंशन के लिए स्लाइस के शुरुआती इंडेक्स शामिल होते हैं. वैल्यू, शून्य से ज़्यादा या उसके बराबर होनी चाहिए. |
size_indices |
ArraySlice<int64> |
N पूर्णांकों की सूची, जिसमें हर डाइमेंशन के लिए स्लाइस का साइज़ शामिल होता है. हर वैल्यू, शून्य से ज़्यादा होनी चाहिए. साथ ही, शुरू + साइज़, डाइमेंशन के साइज़ से कम या उसके बराबर होना चाहिए, ताकि डाइमेंशन के साइज़ के हिसाब से रैपिंग न हो. |
स्लाइस करने से पहले, [1, N) में मौजूद हर इंडेक्स i पर यह ट्रांसफ़ॉर्मेशन लागू करके, असरदार स्लाइस इंडेक्स का हिसाब लगाया जाता है:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - size_indices[i])
इससे यह पक्का होता है कि निकाला गया स्लाइस, ऑपरेंड ऐरे के हिसाब से हमेशा इन-बाउंड में हो. अगर ट्रांसफ़ॉर्मेशन लागू होने से पहले स्लाइस इन-बाउंड है, तो ट्रांसफ़ॉर्मेशन का कोई असर नहीं पड़ता.
एक डाइमेंशन वाला उदाहरण:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let s = {2}
DynamicSlice(a, s, {2}) produces:
{2.0, 3.0}
दो डाइमेंशन वाला उदाहरण:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
DynamicUpdateSlice
XlaBuilder::DynamicUpdateSlice भी देखें.
DynamicUpdateSlice फ़ंक्शन एक नतीजा जनरेट करता है, जो इनपुट ऐरे operand की वैल्यू होती है. इसमें start_indices पर ओवरराइट की गई स्लाइस update होती है.
update का आकार, नतीजे के उस सब-ऐरे का आकार तय करता है जिसे अपडेट किया जाता है.
start_indices का आकार एक डाइमेंशनल होना चाहिए. साथ ही, डाइमेंशन का साइज़, operand के डाइमेंशन की संख्या के बराबर होना चाहिए.
DynamicUpdateSlice(operand, update, start_indices)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का N डाइमेंशन वाला ऐरे |
update |
XlaOp |
टाइप T का N डाइमेंशन वाला ऐरे, जिसमें स्लाइस अपडेट शामिल है. अपडेट शेप का हर डाइमेंशन, शून्य से ज़्यादा होना चाहिए. साथ ही, हर डाइमेंशन के लिए, शुरू + अपडेट, ऑपरेंड के साइज़ से कम या उसके बराबर होना चाहिए, ताकि अपडेट इंडेक्स की वैल्यू तय सीमा से बाहर न हो. |
start_indices |
N XlaOp का क्रम |
N स्केलर इंटिजर की सूची, जिसमें हर डाइमेंशन के लिए स्लाइस के शुरुआती इंडेक्स शामिल होते हैं. वैल्यू, शून्य से ज़्यादा या उसके बराबर होनी चाहिए. |
स्लाइस करने से पहले, [1, N) में मौजूद हर इंडेक्स i पर यह ट्रांसफ़ॉर्मेशन लागू करके, असरदार स्लाइस इंडेक्स का हिसाब लगाया जाता है:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
इससे यह पक्का होता है कि अपडेट किया गया स्लाइस, ऑपरेंड कलेक्शन के हिसाब से हमेशा सीमाओं के अंदर हो. अगर ट्रांसफ़ॉर्मेशन लागू होने से पहले स्लाइस इन-बाउंड है, तो ट्रांसफ़ॉर्मेशन का कोई असर नहीं पड़ता.
एक डाइमेंशन वाला उदाहरण:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s) produces:
{0.0, 1.0, 5.0, 6.0, 4.0}
दो डाइमेंशन वाला उदाहरण:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s) produces:
{ {0.0, 1.0, 2.0},
{3.0, 12.0, 13.0},
{6.0, 14.0, 15.0},
{9.0, 16.0, 17.0} }
एलिमेंट के हिसाब से बाइनरी अरिथमेटिक ऑपरेशन
XlaBuilder::Add भी देखें.
एलिमेंट के हिसाब से बाइनरी अंकगणितीय ऑपरेशन का एक सेट काम करता है.
Op(lhs, rhs)
यहां Op, Add (जोड़), Sub(घटाव), Mul
(गुणा), Div (भाग), Pow (पावर), Rem (बचे हुए), Max
(ज़्यादा से ज़्यादा), Min (कम से कम), And (लॉजिकल AND), Or (लॉजिकल
OR), Xor (लॉजिकल XOR), ShiftLeft (लेफ़्ट शिफ़्ट), ShiftRightArithmetic (अरिथमेटिक राइट शिफ़्ट), ShiftRightLogical (लॉजिकल
राइट शिफ़्ट), Atan2 (दो आर्ग्युमेंट वाला आर्कटेनजेंट) या Complex (रीयल और imaginnary पार्ट को जटिल संख्या में जोड़ता है) में से कोई एक है
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
lhs |
XlaOp |
बाईं ओर का ऑपरेंड: T टाइप का ऐरे |
rhs |
XlaOp |
दाईं ओर मौजूद ऑपरेंड: T टाइप का ऐरे |
आर्ग्युमेंट के आकार एक जैसे या काम के होने चाहिए. ब्रॉडकास्टिंग से जुड़ा दस्तावेज़ देखें. इसमें यह बताया गया है कि आकार के साथ काम करने का क्या मतलब है. किसी ऑपरेशन का नतीजा, दो इनपुट ऐरे को ब्रॉडकास्ट करने का नतीजा होता है. इस वैरिएंट में, अलग-अलग रैंक के ऐरे के बीच ऑपरेशन नहीं किए जा सकते. ऐसा तब तक नहीं किया जा सकता, जब तक कि ऑपरेंड में से कोई एक स्केलर न हो.
जब Op Rem होता है, तो नतीजे का चिह्न, डिवीडेंड से लिया जाता है. साथ ही, नतीजे की पूर्ण वैल्यू हमेशा, डिवीज़र की पूर्ण वैल्यू से कम होती है.
पूर्णांक के भागफल का ओवरफ़्लो (साइन वाला/बिना साइन वाला भागफल/शून्य से भागफल/INT_SMIN का साइन वाला/बिना साइन वाला भागफल/-1 का शेषफल) लागू करने पर, तय की गई वैल्यू मिलती है.
इन कार्रवाइयों के लिए, अलग-अलग डाइमेंशन में ब्रॉडकास्ट करने की सुविधा वाला वैकल्पिक वैरिएंट मौजूद है:
Op(lhs, rhs, broadcast_dimensions)
यहां Op वही है जो ऊपर दिया गया है. ऑपरेशन के इस वैरिएंट का इस्तेमाल, अलग-अलग रैंक के ऐरे के बीच अंकगणितीय ऑपरेशन के लिए किया जाना चाहिए. जैसे, किसी वेक्टर में मैट्रिक्स जोड़ना.
अतिरिक्त broadcast_dimensions ऑपरेंड, पूर्णांकों का एक स्लाइस होता है. इसका इस्तेमाल, कम डाइमेंशन वाले ऑपरेंड के डाइमेंशन की संख्या को ज़्यादा डाइमेंशन वाले ऑपरेंड के डाइमेंशन की संख्या तक बढ़ाने के लिए किया जाता है. broadcast_dimensions कम डाइमेंशन वाले आकार के डाइमेंशन को ज़्यादा डाइमेंशन वाले आकार के डाइमेंशन पर मैप करता है. बड़े किए गए आकार के उन डाइमेंशन को साइज़ एक के डाइमेंशन से भरा जाता है जिन्हें मैप नहीं किया गया है. इसके बाद, डीजनरेट-डाइमेंशन ब्रॉडकास्टिंग, दोनों ऑपरेंड के आकार को बराबर करने के लिए, इन डीजनरेट डाइमेंशन के साथ आकार ब्रॉडकास्ट करता है. सेमेटिक्स के बारे में ज़्यादा जानकारी, ब्रॉडकास्टिंग पेज पर दी गई है.
एलिमेंट के हिसाब से तुलना करने वाले ऑपरेशन
XlaBuilder::Eq भी देखें.
एलिमेंट के हिसाब से, बाइनरी तुलना करने वाले स्टैंडर्ड ऑपरेशन का एक सेट काम करता है. ध्यान दें कि फ़्लोटिंग-पॉइंट टाइप की तुलना करते समय, स्टैंडर्ड IEEE 754 फ़्लोटिंग-पॉइंट की तुलना के नियम लागू होते हैं.
Op(lhs, rhs)
यहां Op, Eq (बराबर है), Ne (बराबर नहीं है), Ge
(इससे ज़्यादा या इसके बराबर है), Gt (इससे ज़्यादा है), Le (इससे कम या इसके बराबर है), Lt
(इससे कम है) में से कोई एक है. ऑपरेटर का एक और सेट, EqTotalOrder, NeTotalOrder, GeTotalOrder,
GtTotalOrder, LeTotalOrder, और LtTotalOrder, एक जैसी सुविधाएं देता है. हालांकि, ये फ़्लोटिंग पॉइंट वाली संख्याओं के लिए, कुल क्रम की सुविधा भी देते हैं. इसके लिए, -NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN का इस्तेमाल किया जाता है.
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
lhs |
XlaOp |
बाईं ओर का ऑपरेंड: T टाइप का ऐरे |
rhs |
XlaOp |
दाईं ओर मौजूद ऑपरेंड: T टाइप का ऐरे |
आर्ग्युमेंट के आकार एक जैसे या काम के होने चाहिए. ब्रॉडकास्टिंग से जुड़ा दस्तावेज़ देखें. इसमें यह बताया गया है कि आकार के साथ काम करने का क्या मतलब है. किसी ऑपरेशन का नतीजा, एलिमेंट टाइप PRED के साथ दो इनपुट ऐरे को ब्रॉडकास्ट करने का नतीजा होता है. इस वैरिएंट में, अलग-अलग रैंक के ऐरे के बीच ऑपरेशन नहीं किए जा सकते. ऐसा तब तक नहीं किया जा सकता, जब तक कि ऑपरेंड में से कोई एक स्केलर न हो.
इन कार्रवाइयों के लिए, अलग-अलग डाइमेंशन में ब्रॉडकास्ट करने की सुविधा वाला वैकल्पिक वैरिएंट मौजूद है:
Op(lhs, rhs, broadcast_dimensions)
यहां Op वही है जो ऊपर दिया गया है. ऑपरेशन के इस वैरिएंट का इस्तेमाल, अलग-अलग रैंक के ऐरे के बीच तुलना करने के लिए किया जाना चाहिए. जैसे, किसी वेक्टर में मैट्रिक जोड़ना.
अतिरिक्त broadcast_dimensions ऑपरेंड, पूर्णांकों का एक स्लाइस होता है. इसमें ऑपरेंड को ब्रॉडकास्ट करने के लिए इस्तेमाल किए जाने वाले डाइमेंशन की जानकारी होती है. सेमेटिक्स के बारे में ज़्यादा जानकारी, ब्रॉडकास्टिंग पेज पर दी गई है.
एलिमेंट के हिसाब से यूनीऐरी फ़ंक्शन
XlaBuilder में, एलिमेंट के हिसाब से इन यूनीऐरी फ़ंक्शन का इस्तेमाल किया जा सकता है:
Abs(operand) एलिमेंट के हिसाब से एब्सोल्यूट वैल्यू x -> |x|.
Cbrt(operand) एलिमेंट के हिसाब से घनमूल निकालने का ऑपरेशन x -> cbrt(x).
Ceil(operand) एलिमेंट के हिसाब से सीईल x -> ⌈x⌉.
Clz(operand) एलिमेंट के हिसाब से, शुरुआत में मौजूद शून्य की गिनती करें.
Cos(operand) एलिमेंट के हिसाब से कोसाइन x -> cos(x).
Erf(operand) एलिमेंट के हिसाब से गड़बड़ी का फ़ंक्शन x -> erf(x), जहां
erf(x)=2√π∫x0e−t2dt.
Exp(operand) एलिमेंट के हिसाब से नेचुरल एक्सपोनेंशियल x -> e^x.
Expm1(operand) एलिमेंट के हिसाब से, नेचुरल एक्सपोनेंशियल माइनस वन
x -> e^x - 1.
Floor(operand) एलिमेंट के हिसाब से फ़्लोर x -> ⌊x⌋.
Imag(operand) कॉम्प्लेक्स (या रीयल) आकार के एलिमेंट के हिसाब से काल्पनिक हिस्सा. x -> imag(x). अगर ऑपरेंड फ़्लोटिंग पॉइंट टाइप का है, तो 0 दिखाता है.
IsFinite(operand) यह जांच करता है कि operand का हर एलिमेंट सीमित है या नहीं, यानी कि वह न तो अनंत है और न ही NaN. इनपुट के तौर पर दिए गए वैल्यू के क्रम के हिसाब से, PRED वैल्यू का एक कलेक्शन दिखाता है. इसमें हर एलिमेंट true होता है, लेकिन सिर्फ़ तब, जब इनपुट एलिमेंट सीमित हो.
Log(operand) एलिमेंट के हिसाब से नैचुरल लॉगारिद्म x -> ln(x).
Log1p(operand) एलिमेंट के हिसाब से शिफ़्ट किया गया नैचुरल लॉगारिद्म x -> ln(1+x).
Logistic(operand) एलिमेंट के हिसाब से लॉजिस्टिक फ़ंक्शन का हिसाब लगाना x ->
logistic(x).
Neg(operand) एलिमेंट के हिसाब से नेगेटिव x -> -x.
Not(operand) एलिमेंट के हिसाब से लॉजिकल नॉट x -> !(x).
PopulationCount(operand) operand के हर एलिमेंट में सेट किए गए बिट की संख्या का हिसाब लगाता है.
Real(operand) किसी कॉम्प्लेक्स (या रीयल) आकार के एलिमेंट के हिसाब से रीयल हिस्सा.
x -> real(x). अगर ऑपरेंड फ़्लोटिंग पॉइंट टाइप का है, तो वही वैल्यू दिखाता है.
Round(operand) एलिमेंट के हिसाब से राउंडिंग, शून्य से दूर होती है.
RoundNearestEven(operand) एलिमेंट के हिसाब से राउंड ऑफ़ करने की सुविधा, जो सबसे करीब के सम अंक पर सेट होती है.
Rsqrt(operand) एलिमेंट के हिसाब से वर्गमूल के ऑपरेशन का रिसिप्रोकल
x -> 1.0 / sqrt(x).
Sign(operand) एलिमेंट के हिसाब से साइन ऑपरेशन x -> sgn(x), जहां
sgn(x)={−1x<0−0x=−0NaNx=NaN+0x=+01x>0
operand एलिमेंट टाइप के तुलना ऑपरेटर का इस्तेमाल करके.
Sin(operand) एलिमेंट के हिसाब से साइन x -> sin(x).
Sqrt(operand) एलिमेंट के हिसाब से वर्गमूल निकालने की सुविधा x -> sqrt(x).
Tan(operand) एलिमेंट के हिसाब से टेंगेंट x -> tan(x).
Tanh(operand) एलिमेंट के हिसाब से हाइपरबोलिक टैंजेंट x -> tanh(x).
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
फ़ंक्शन का ऑपरेंड |
यह फ़ंक्शन, operand ऐरे के हर एलिमेंट पर लागू होता है. इससे एक ही शेप वाला ऐरे बनता है. operand को स्केलर (0-डाइमेंशनल) किया जा सकता है.
Fft
XLA FFT ऑपरेशन, रीयल और कॉम्प्लेक्स इनपुट/आउटपुट के लिए, फ़ोरवर्ड और इनवर्स फ़ुरिअर ट्रांसफ़ॉर्म लागू करता है. ज़्यादा से ज़्यादा तीन ऐक्सिस पर, मल्टीडाइमेंशनल एफ़एफ़टी का इस्तेमाल किया जा सकता है.
XlaBuilder::Fft भी देखें.
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
वह ऐरे जिसे फ़ोरियर ट्रांसफ़ॉर्म किया जा रहा है. |
fft_type |
FftType |
नीचे दी गई टेबल देखें. |
fft_length |
ArraySlice<int64> |
ट्रांसफ़ॉर्म किए जा रहे ऐक्सिस की टाइम-डोमेन लंबाई. यह खास तौर पर IRFFT के लिए ज़रूरी है, ताकि सबसे अंदर वाले ऐक्सिस का साइज़ सही हो. इसकी वजह यह है कि RFFT(fft_length=[16]) का आउटपुट शेप, RFFT(fft_length=[17]) जैसा ही होता है. |
FftType |
सिमैंटिक |
|---|---|
FFT |
फ़ॉरवर्ड कॉम्प्लेक्स-टू-कॉम्प्लेक्स एफ़टीटी. आकार में कोई बदलाव नहीं होता. |
IFFT |
कॉम्प्लेक्स-टू-कॉम्प्लेक्स एफ़एफ़टी का इनवर्स. आकार में कोई बदलाव नहीं होता. |
RFFT |
रीयल-टू-कॉम्प्लेक्स एफ़एफ़टी को फ़ॉरवर्ड करें. अगर fft_length[-1] की वैल्यू शून्य से ज़्यादा है, तो सबसे अंदर मौजूद ऐक्सिस का साइज़ fft_length[-1] // 2 + 1 तक कम हो जाता है. साथ ही, न्योक्विस्ट फ़्रीक्वेंसी के बाद, ट्रांसफ़ॉर्म किए गए सिग्नल के रिवर्स कॉंजुगेट हिस्से को हटा दिया जाता है. |
IRFFT |
रियल-टू-कॉम्प्लेक्स एफ़टी का उलटा (यानी कॉम्प्लेक्स लेता है, रियल दिखाता है). अगर fft_length[-1] की वैल्यू शून्य से ज़्यादा है, तो सबसे अंदर मौजूद ऐक्सिस का शेप fft_length[-1] तक बड़ा हो जाता है. इससे, 1 से fft_length[-1] // 2 + 1 एंट्री के रिवर्स कॉंजुगेट से, ट्रांसफ़ॉर्म किए गए सिग्नल के उस हिस्से का अनुमान लगाया जाता है जो न्योक्विस्ट फ़्रीक्वेंसी से परे है. |
मल्टीडाइमेंशनल एफ़एफ़टी
एक से ज़्यादा fft_length देने पर, यह सबसे अंदर मौजूद हर अक्ष पर एफ़एफ़टी ऑपरेशन का कैस्केड लागू करने के बराबर होता है. ध्यान दें कि रीयल->कॉम्प्लेक्स और कॉम्प्लेक्स->रीयल मामलों के लिए, सबसे अंदरूनी ऐक्सिस ट्रांसफ़ॉर्मेशन (असल में) सबसे पहले किया जाता है (RFFT; IRFFT के लिए आखिर में). यही वजह है कि सबसे अंदरूनी ऐक्सिस का साइज़ बदलता है. इसके बाद, अन्य ऐक्सिस ट्रांसफ़ॉर्म, मुश्किल->मुश्किल होंगे.
क्रियान्वयन विवरण
सीपीयू एफ़एफ़टी, Eigen के TensorFFT पर आधारित है. GPU FFT, cuFFT का इस्तेमाल करता है.
इकट्ठा करना
XLA इकट्ठा करने की प्रोसेस, इनपुट ऐरे के कई स्लाइस (हर स्लाइस, संभावित रूप से अलग रनटाइम ऑफ़सेट पर) को एक साथ जोड़ती है.
जनरल सिमेंटिक्स
XlaBuilder::Gather भी देखें.
ज़्यादा जानकारी के लिए, नीचे दिया गया "सामान्य जानकारी" सेक्शन देखें.
gather(operand, start_indices, offset_dims, collapsed_slice_dims,
slice_sizes, start_index_map)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
वह ऐरे जिसमें से डेटा इकट्ठा किया जा रहा है. |
start_indices |
XlaOp |
इकट्ठा की गई स्लाइस के शुरुआती इंडेक्स वाला कलेक्शन. |
index_vector_dim |
int64 |
start_indices में मौजूद वह डाइमेंशन जिसमें शुरुआती इंडेक्स "शामिल" हैं. ज़्यादा जानकारी के लिए नीचे देखें. |
offset_dims |
ArraySlice<int64> |
आउटपुट शेप में डाइमेंशन का सेट, जो ऑपरेंड से काटे गए ऐरे में ऑफ़सेट होता है. |
slice_sizes |
ArraySlice<int64> |
slice_sizes[i], डाइमेंशन i पर स्लाइस के लिए बाउंड है. |
collapsed_slice_dims |
ArraySlice<int64> |
हर स्लाइस में मौजूद उन डाइमेंशन का सेट जिन्हें छोटा किया गया है. इन डाइमेंशन का साइज़ 1 होना चाहिए. |
start_index_map |
ArraySlice<int64> |
एक मैप, जिसमें ऑपरेंड में start_indices के इंडेक्स को कानूनी इंडेक्स से मैप करने का तरीका बताया गया है. |
indices_are_sorted |
bool |
क्या इंडेक्स को कॉलर के हिसाब से क्रम में लगाने की गारंटी है. |
आपकी सुविधा के लिए, हम आउटपुट ऐरे में डाइमेंशन को offset_dims के बजाय batch_dims के तौर पर लेबल करते हैं.
आउटपुट, batch_dims.size + offset_dims.size डाइमेंशन वाला ऐरे होता है.
operand.rank, offset_dims.size और
collapsed_slice_dims.size के योग के बराबर होना चाहिए. साथ ही, slice_sizes.size का वैल्यू operand.rank के बराबर होनी चाहिए.
अगर index_vector_dim, start_indices.rank के बराबर है, तो हम start_indices में आखिर में 1 डाइमेंशन होने का अनुमान लगाते हैं. इसका मतलब है कि अगर start_indices का आकार [6,7] है और index_vector_dim 2 है, तो हम start_indices का आकार [6,7,1] मानते हैं.
डाइमेंशन i के साथ आउटपुट कलेक्शन के सीमाओं का हिसाब इस तरह लगाया जाता है:
अगर
i,batch_dimsमें मौजूद है (यानी कुछkके लिएbatch_dims[k]के बराबर है), तो हमstart_indices.shapeसे उससे जुड़े डाइमेंशन के बाउंड चुनते हैं. साथ ही,index_vector_dimको स्किप करते हैं. उदाहरण के लिए, अगरk<index_vector_dimहै, तोstart_indices.shape.dims[k] चुनें और अगर ऐसा नहीं है, तोstart_indices.shape.dims[k+1] चुनें.अगर
i,offset_dimsमें मौजूद है (यानी कुछkके लिएoffset_dims[k] के बराबर है), तो हमcollapsed_slice_dimsको ध्यान में रखते हुए,slice_sizesसे उससे जुड़ा बाउंड चुनते हैं. इसका मतलब है कि हमadjusted_slice_sizes[k] चुनते हैं, जहांadjusted_slice_sizes,slice_sizesहै और इंडेक्सcollapsed_slice_dimsके बाउंड हटा दिए गए हैं.
किसी आउटपुट इंडेक्स Out से जुड़े ऑपरेंड इंडेक्स In का हिसाब इस तरह लगाया जाता है:
मान लें कि
G= {Out[k] forkinbatch_dims}.Gका इस्तेमाल करके, वैक्टरSको काटें, ताकिS[i] =start_indices[Combine(G,i)] हो. यहां Combine(A, b), A मेंindex_vector_dimपोज़िशन पर b डालता है. ध्यान दें किGखाली होने पर भी, यह अच्छी तरह से तय किया गया है: अगरGखाली है, तोS=start_indices.Sका इस्तेमाल करके,operandमेंSinका शुरुआती इंडेक्स बनाएं. इसके लिए,start_index_mapका इस्तेमाल करकेSको अलग-अलग जगहों पर डालें. ज़्यादा सटीक तरीके से:Sin[start_index_map[k]] =S[k], अगरk<start_index_map.size.Sin[_] =0, अगर ऐसा नहीं है.
collapsed_slice_dimsसेट के हिसाब से,Outमें मौजूद ऑफ़सेट डाइमेंशन पर इंडेक्स को स्कैटर करके,operandमें इंडेक्सOinबनाएं. ज़्यादा सटीक तरीके से:अगर
k<offset_dims.sizeहै, तोOin[remapped_offset_dims(k)] =Out[offset_dims[k]] (remapped_offset_dimsकी परिभाषा नीचे दी गई है).Oin[_] =0, अगर ऐसा नहीं है.
In,Oin+Sinहै. यहां + का मतलब एलिमेंट के हिसाब से जोड़ना है.
remapped_offset_dims एक ऐसा फ़ंक्शन है जिसका डोमेन [0,
offset_dims.size) और रेंज [0, operand.rank) \ collapsed_slice_dims है. उदाहरण के लिए, अगर offset_dims.size, 4 है, operand.rank, 6 है, और
collapsed_slice_dims, {0, 2} है, तो remapped_offset_dims, {0→1,
1→3, 2→4, 3→5} है.
अगर indices_are_sorted को 'सही' पर सेट किया गया है, तो XLA यह मान सकता है कि उपयोगकर्ता ने start_indices को क्रम से लगाया है. start_indices को क्रम से लगाने के लिए, start_index_map के हिसाब से वैल्यू को स्प्रेड करने के बाद, उन्हें बढ़ते क्रम में लगाया जाता है. अगर ऐसा नहीं है, तो सेमेटिक्स को लागू करने के तरीके से तय किया जाता है.
सामान्य जानकारी और उदाहरण
आम तौर पर, आउटपुट कलेक्शन में मौजूद हर इंडेक्स Out, ऑपरेंड कलेक्शन में मौजूद किसी एलिमेंट E से मेल खाता है. इसकी गिनती इस तरह की जाती है:
हम
start_indicesसे शुरुआती इंडेक्स देखने के लिए,Outमें बैच डाइमेंशन का इस्तेमाल करते हैं.हम
start_index_mapका इस्तेमाल, शुरुआती इंडेक्स (जिसका साइज़, ऑपरेंड के रैंक से कम हो सकता है) कोoperandमें "पूरे" शुरुआती इंडेक्स में मैप करने के लिए करते हैं.हम शुरुआती इंडेक्स का इस्तेमाल करके,
slice_sizesसाइज़ का स्लाइस डाइनैमिक तौर पर काटते हैं.हम
collapsed_slice_dimsडाइमेंशन को छोटा करके, स्लाइस का आकार बदलते हैं. सभी छोटा किए गए स्लाइस डाइमेंशन का बाउंड 1 होना चाहिए. इसलिए, यह रीशेप हमेशा मान्य होता है.हम इस स्लाइस में इंडेक्स करने के लिए,
Outमें मौजूद ऑफ़सेट डाइमेंशन का इस्तेमाल करते हैं. इससे हमें आउटपुट इंडेक्सOutसे जुड़ा इनपुट एलिमेंटEमिलता है.
यहां दिए गए सभी उदाहरणों में, index_vector_dim को start_indices.rank - 1 पर सेट किया गया है. index_vector_dim के लिए ज़्यादा दिलचस्प वैल्यू, ऑपरेशन में कोई बदलाव नहीं करतीं. हालांकि, विज़ुअल को ज़्यादा मुश्किल बनाती हैं.
ऊपर बताई गई सभी चीज़ें एक साथ कैसे काम करती हैं, यह समझने के लिए एक उदाहरण देखें. इसमें, [16,11] कलेक्शन से [8,6] आकार के पांच स्लाइस इकट्ठा किए गए हैं. [16,11] कलेक्शन में किसी स्लाइस की पोज़िशन को S64[2] आकार के इंडेक्स वैक्टर के तौर पर दिखाया जा सकता है. इसलिए, पांच पोज़िशन के सेट को S64[5,2] कलेक्शन के तौर पर दिखाया जा सकता है.
इसके बाद, इकट्ठा करने की कार्रवाई के व्यवहार को इंडेक्स ट्रांसफ़ॉर्मेशन के तौर पर दिखाया जा सकता है. यह [G,O0,O1] को आउटपुट शेप में इंडेक्स के तौर पर लेता है और इसे इनपुट कलेक्शन के एलिमेंट पर इस तरह मैप करता है:

हम पहले G का इस्तेमाल करके, इकट्ठा किए गए इंडेक्स ऐरे से (X,Y) वेक्टर चुनते हैं.
आउटपुट ऐरे में इंडेक्स [G,O0,O1] पर मौजूद एलिमेंट, इनपुट ऐरे में इंडेक्स [X+O0,Y+O1] पर मौजूद एलिमेंट होता है.
slice_sizes, [8,6] है. इससे O0 और
O1 की रेंज तय होती है. साथ ही, इससे स्लाइस के बाउंड तय होते हैं.
यह इकट्ठा करने की कार्रवाई, बैच डाइनैमिक स्लाइस के तौर पर काम करती है. इसमें G, बैच डाइमेंशन के तौर पर काम करता है.
इकट्ठा किए गए इंडेक्स, कई डाइमेंशन वाले हो सकते हैं. उदाहरण के लिए, ऊपर दिए गए उदाहरण का ज़्यादा सामान्य वर्शन, आकार [4,5,2] के "इकट्ठा इंडेक्स" कलेक्शन का इस्तेमाल करके, इंडेक्स को इस तरह से ट्रांसलेट करेगा:

यह फिर से, एक बैच डाइनैमिक स्लाइस G0 और
G1 के तौर पर बैच डाइमेंशन के तौर पर काम करता है. स्लाइस का साइज़ अब भी [8,6] है.
XLA में इकट्ठा करने की कार्रवाई, ऊपर बताए गए अनौपचारिक सेमेटिक्स को इन तरीकों से सामान्य बनाती है:
हम यह कॉन्फ़िगर कर सकते हैं कि आउटपुट शेप में कौनसे डाइमेंशन ऑफ़सेट डाइमेंशन हैं. आखिरी उदाहरण में,
O0,O1वाले डाइमेंशन ऑफ़सेट डाइमेंशन हैं. आउटपुट बैच डाइमेंशन (पिछले उदाहरण मेंG0,G1वाले डाइमेंशन), ऐसे आउटपुट डाइमेंशन होते हैं जो ऑफ़सेट डाइमेंशन नहीं होते.आउटपुट आकार में साफ़ तौर पर मौजूद आउटपुट ऑफ़सेट डाइमेंशन की संख्या, इनपुट डाइमेंशन की संख्या से कम हो सकती है. इन "मौजूद नहीं" डाइमेंशन, जिन्हें साफ़ तौर पर
collapsed_slice_dimsके तौर पर सूची में शामिल किया गया है, का स्लाइस साइज़1होना चाहिए. इनका स्लाइस साइज़1है. इसलिए, इनके लिए सिर्फ़0मान्य इंडेक्स है. साथ ही, इन्हें हटाने से कोई समस्या नहीं होती."इकट्ठा करें इंडेक्स" ऐरे से निकाले गए स्लाइस में, इनपुट ऐरे के डाइमेंशन की संख्या से कम एलिमेंट हो सकते हैं. आखिरी उदाहरण में, (
X,Y) में ऐसा हो सकता है. साथ ही, साफ़ तौर पर मैपिंग करने से यह तय होता है कि इंडेक्स को कैसे बड़ा किया जाए, ताकि इनपुट के डाइमेंशन की संख्या इंडेक्स में भी हो.
आखिरी उदाहरण के तौर पर, हम tf.gather_nd को लागू करने के लिए, (2) और (3) का इस्तेमाल करते हैं:

G0 और G1 का इस्तेमाल, इंडेक्स इकट्ठा करने वाले कलेक्शन से, स्टार्टिंग इंडेक्स को काटने के लिए किया जाता है. हालांकि, स्टार्टिंग इंडेक्स में सिर्फ़ एक एलिमेंट, X होता है. इसी तरह, वैल्यू O0 वाला सिर्फ़ एक आउटपुट ऑफ़सेट इंडेक्स है. हालांकि, इनपुट कलेक्शन में इंडेक्स के तौर पर इस्तेमाल किए जाने से पहले, इन्हें "इकट्ठा करने के लिए इंडेक्स मैपिंग" (औपचारिक ब्यौरे में start_index_map) और "ऑफ़सेट मैपिंग" (औपचारिक ब्यौरे में remapped_offset_dims) के हिसाब से [X,0] और [0,O0] में बड़ा किया जाता है. इन दोनों को जोड़ने पर [X,O0] बनता है. दूसरे शब्दों में, आउटपुट इंडेक्स [G0,G1,O0] को इनपुट इंडेक्स [GatherIndices[G0,G1,0],O0] पर मैप किया जाता है. इससे हमें tf.gather_nd के लिए सेमेटिक्स मिलते हैं.
इस केस के लिए slice_sizes, [1,11] है. इसका मतलब है कि इकट्ठा किए गए इंडेक्स कलेक्शन में मौजूद हर इंडेक्स X, एक पूरी लाइन चुनता है. साथ ही, इन सभी लाइनों को जोड़कर नतीजा मिलता है.
GetDimensionSize
XlaBuilder::GetDimensionSize भी देखें.
ऑपरेंड के दिए गए डाइमेंशन का साइज़ दिखाता है. ऑपरेंड, ऐरे के तौर पर होना चाहिए.
GetDimensionSize(operand, dimension)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
n डाइमेंशन वाला इनपुट ऐरे |
dimension |
int64 |
इंटरवल [0, n) में मौजूद वह वैल्यू जो डाइमेंशन की जानकारी देती है |
SetDimensionSize
XlaBuilder::SetDimensionSize भी देखें.
XlaOp के दिए गए डाइमेंशन का डाइनैमिक साइज़ सेट करता है. ऑपरेंड, ऐरे के तौर पर होना चाहिए.
SetDimensionSize(operand, size, dimension)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
n डाइमेंशन वाला इनपुट ऐरे. |
size |
XlaOp |
रनटाइम के डाइनैमिक साइज़ को दिखाने वाला int32. |
dimension |
int64 |
इंटरवल [0, n) में मौजूद वैल्यू, जो डाइमेंशन की जानकारी देती है. |
ऑपरेंड को नतीजे के तौर पर पास करें. साथ ही, डाइनैमिक डाइमेंशन को कंपाइलर से ट्रैक करें.
डाउनस्ट्रीम में डेटा कम करने की प्रोसेस के दौरान, पैड की गई वैल्यू को अनदेखा कर दिया जाएगा.
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
GetTupleElement
XlaBuilder::GetTupleElement भी देखें.
कंपाइल के समय की कॉन्स्टेंट वैल्यू वाले ट्यूपल में इंडेक्स करता है.
वैल्यू, कंपाइल के समय की कॉन्स्टेंट होनी चाहिए, ताकि आकार का अनुमान लगाने की सुविधा, नतीजे की वैल्यू का टाइप तय कर सके.
यह C++ में std::get<int N>(t) के बराबर है. कॉन्सेप्ट के हिसाब से:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
tf.tuple भी देखें.
इनफ़ीड
XlaBuilder::Infeed भी देखें.
Infeed(shape)
| आर्ग्यूमेंट | टाइप | सिमैंटिक |
|---|---|---|
shape |
Shape |
इनफ़ीड इंटरफ़ेस से पढ़े गए डेटा का टाइप. आकार के लेआउट फ़ील्ड को डिवाइस पर भेजे गए डेटा के लेआउट से मैच करने के लिए सेट किया जाना चाहिए. ऐसा न करने पर, आकार का व्यवहार तय नहीं किया जा सकता. |
डिवाइस के इनफ़ीड स्ट्रीमिंग इंटरफ़ेस से एक डेटा आइटम पढ़ता है. साथ ही, डेटा को दिए गए शेप और उसके लेआउट के तौर पर समझता है और डेटा का XlaOp दिखाता है. कैलकुलेशन में एक से ज़्यादा इनफ़ीड ऑपरेशन की अनुमति है. हालांकि, इनफ़ीड ऑपरेशन के बीच क्रम होना चाहिए. उदाहरण के लिए, नीचे दिए गए कोड में दो इनफ़ीड का कुल क्रम है, क्योंकि while लूप के बीच एक-दूसरे पर निर्भरता है.
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
नेस्ट किए गए ट्यूपल शेप का इस्तेमाल नहीं किया जा सकता. खाली ट्यूपल शेप के लिए, इनफ़ीड ऑपरेशन का कोई असर नहीं होता. साथ ही, यह डिवाइस के इनफ़ीड से कोई डेटा पढ़े बिना आगे बढ़ता है.
आयोटा
XlaBuilder::Iota भी देखें.
Iota(shape, iota_dimension)
होस्ट से बड़े डेटा ट्रांसफ़र के बजाय, डिवाइस पर एक कॉन्स्टेंट लिटरल बनाता है. यह एक ऐसा अरे बनाता है जिसका शेप तय होता है और जिसमें वैल्यू शून्य से शुरू होती हैं और तय किए गए डाइमेंशन के साथ एक-एक करके बढ़ती जाती हैं. फ़्लोटिंग-पॉइंट टाइप के लिए, जनरेट किया गया कलेक्शन ConvertElementType(Iota(...)) के बराबर होता है, जहां Iota इंटिग्रल टाइप का होता है और कन्वर्ज़न, फ़्लोटिंग-पॉइंट टाइप में होता है.
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
shape |
Shape |
Iota() ने जो ऐरे बनाया है उसका शेप |
iota_dimension |
int64 |
वह डाइमेंशन जिसे बढ़ाना है. |
उदाहरण के लिए, Iota(s32[4, 8], 0) से
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
Iota(s32[4, 8], 1) का शुल्क देकर, प्रॉडक्ट को लौटाया जा सकता है
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
मैप
XlaBuilder::Map भी देखें.
Map(operands..., computation)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operands |
N XlaOps का क्रम |
T0..T{N-1} टाइप के N ऐरे |
computation |
XlaComputation |
टाइप T के N पैरामीटर और किसी भी टाइप के M पैरामीटर के साथ T_0, T_1, .., T_{N + M -1} -> S टाइप का हिसाब लगाना |
dimensions |
int64 ऐरे |
मैप डाइमेंशन का कलेक्शन |
यह दिए गए operands ऐरे पर स्केलर फ़ंक्शन लागू करता है. इससे, एक ही डाइमेंशन वाला ऐरे बनता है, जहां हर एलिमेंट, इनपुट ऐरे के एलिमेंट पर लागू किए गए मैप किए गए फ़ंक्शन का नतीजा होता है.
मैप किया गया फ़ंक्शन, एक ऐसा कैलकुलेशन है जिसमें स्केलर टाइप T के N इनपुट और टाइप S का एक आउटपुट होता है. आउटपुट में ऑपरेंड के जैसे ही डाइमेंशन होते हैं. हालांकि, एलिमेंट टाइप T को S से बदल दिया जाता है.
उदाहरण के लिए: आउटपुट ऐरे बनाने के लिए, Map(op1, op2, op3, computation, par1) इनपुट ऐरे में हर (मल्टी-डाइमेंशनल) इंडेक्स पर elem_out <-
computation(elem1, elem2, elem3, par1) को मैप करता है.
OptimizationBarrier
किसी भी ऑप्टिमाइज़ेशन पास को, गणनाओं को बैरियर के पार जाने से रोकता है.
यह पक्का करता है कि बाधा के आउटपुट पर निर्भर किसी भी ऑपरेटर से पहले, सभी इनपुट का आकलन किया जाए.
पैड
XlaBuilder::Pad भी देखें.
Pad(operand, padding_value, padding_config)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का कलेक्शन |
padding_value |
XlaOp |
जोड़ा गया पैडिंग भरने के लिए, T टाइप का स्केलर |
padding_config |
PaddingConfig |
दोनों किनारों (कम, ज़्यादा) और हर डाइमेंशन के एलिमेंट के बीच पैडिंग की रकम |
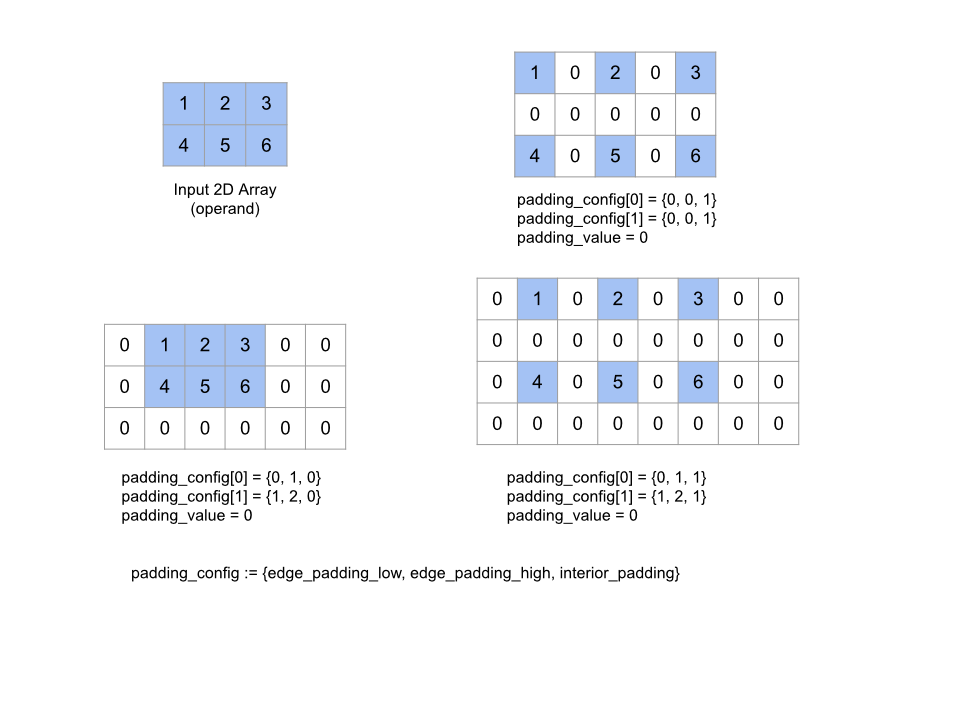
यह फ़ंक्शन, दिए गए operand ऐरे को बड़ा करता है. इसके लिए, ऐरे के चारों ओर और ऐरे के एलिमेंट के बीच में, दिए गए padding_value का इस्तेमाल करके पैडिंग की जाती है. padding_config
हर डाइमेंशन के लिए, किनारे की पैडिंग और अंदरूनी पैडिंग की मात्रा तय करता है.
PaddingConfig, PaddingConfigDimension का दोहराया गया फ़ील्ड है. इसमें हर डाइमेंशन के लिए तीन फ़ील्ड होते हैं: edge_padding_low, edge_padding_high, और
interior_padding.
edge_padding_low और edge_padding_high से पता चलता है कि हर डाइमेंशन के सबसे कम (इंडेक्स 0 के बगल में) और सबसे ज़्यादा (सबसे बड़े इंडेक्स के बगल में) आखिर में कितनी पैडिंग जोड़ी गई है. एज पैडिंग की वैल्यू नेगेटिव हो सकती है -- नेगेटिव पैडिंग की एब्सोल्यूट वैल्यू से पता चलता है कि दिए गए डाइमेंशन से कितने एलिमेंट हटाने हैं.
interior_padding से पता चलता है कि हर डाइमेंशन में, किसी भी दो एलिमेंट के बीच कितनी पैडिंग जोड़ी गई है. यह नेगेटिव नहीं हो सकती. अंदरूनी पैडिंग, एज पैडिंग से पहले होती है. इसलिए, नेगेटिव एज पैडिंग के मामले में, अंदरूनी पैडिंग वाले ऑपरेंड से एलिमेंट हटा दिए जाते हैं.
अगर किनारे के पैडिंग पेयर सभी (0, 0) हैं और अंदरूनी पैडिंग की वैल्यू सभी 0 हैं, तो यह कार्रवाई नहीं की जाती. नीचे दिए गए चित्र में, दो डाइमेंशन वाले कलेक्शन के लिए, अलग-अलग edge_padding और interior_padding वैल्यू के उदाहरण दिखाए गए हैं.
Recv
XlaBuilder::Recv भी देखें.
Recv(shape, channel_handle)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
shape |
Shape |
पाने के लिए डेटा का टाइप |
channel_handle |
ChannelHandle |
हर भेजने/पाने वाले पेयर के लिए यूनीक आइडेंटिफ़ायर |
यह किसी दूसरे कैलकुलेशन में, Send निर्देश से दिए गए शेप का डेटा पाता है. यह कैलकुलेशन, एक ही चैनल हैंडल का इस्तेमाल करता है. यह फ़ंक्शन, मिले डेटा के लिए एक
XlaOp दिखाता है.
Recv ऑपरेशन का क्लाइंट एपीआई, सिंक्रोनस कम्यूनिकेशन दिखाता है.
हालांकि, असाइनमेंट को अंदरूनी तौर पर दो एचएलओ निर्देशों (Recv और RecvDone) में बांटा जाता है, ताकि डेटा को अलग-अलग समय पर ट्रांसफ़र किया जा सके. HloInstruction::CreateRecv और HloInstruction::CreateRecvDone भी देखें.
Recv(const Shape& shape, int64 channel_id)
एक ही channel_id वाले Send निर्देश से डेटा पाने के लिए ज़रूरी संसाधनों को ऐलोकेट करता है. यह, ऐलोकेट किए गए रिसॉर्स के लिए एक कॉन्टेक्स्ट दिखाता है. इसका इस्तेमाल, डेटा ट्रांसफ़र पूरा होने का इंतज़ार करने के लिए, RecvDone निर्देश के बाद किया जाता है. कॉन्टेक्स्ट, {receive buffer (shape), request identifier
(U32)} का ट्यूपल है. इसका इस्तेमाल सिर्फ़ RecvDone निर्देश से किया जा सकता है.
RecvDone(HloInstruction context)
Recv निर्देश से बनाए गए संदर्भ में, डेटा ट्रांसफ़र के पूरी होने का इंतज़ार करता है और मिला डेटा दिखाता है.
Reduce
XlaBuilder::Reduce भी देखें.
एक या उससे ज़्यादा ऐरे पर, रिडक्शन फ़ंक्शन को एक साथ लागू करता है.
Reduce(operands..., init_values..., computation, dimensions)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operands |
N XlaOp का क्रम |
T_0, ..., T_{N-1} टाइप के N ऐरे. |
init_values |
N XlaOp का क्रम |
T_0, ..., T_{N-1} टाइप के N स्केलर. |
computation |
XlaComputation |
T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}) टाइप का कैलकुलेशन. |
dimensions |
int64 ऐरे |
कम किए जाने वाले डाइमेंशन का बिना क्रम वाला कलेक्शन. |
कहां:
- N की वैल्यू 1 या उससे ज़्यादा होनी चाहिए.
- कैलकुलेशन "लगभग" असोसिएटिव होना चाहिए (नीचे देखें).
- सभी इनपुट ऐरे के डाइमेंशन एक ही होने चाहिए.
- सभी शुरुआती वैल्यू,
computationके तहत एक पहचान बनानी चाहिए. - अगर
N = 1,Collate(T)Tहै. - अगर
N > 1,Collate(T_0, ..., T_{N-1}),Tटाइप केNएलिमेंट का ट्यूपल है.
इस ऑपरेशन से, हर इनपुट ऐरे के एक या एक से ज़्यादा डाइमेंशन, स्केलर में बदल जाते हैं.
दिखाए गए हर ऐरे में डाइमेंशन की संख्या number_of_dimensions(operand) - len(dimensions) होती है. ऑपरेशन का आउटपुट Collate(Q_0, ..., Q_N) होता है. यहां Q_i, T_i टाइप का ऐरे है. इसके डाइमेंशन के बारे में नीचे बताया गया है.
अलग-अलग बैकएंड, डेटा कम करने के तरीके को फिर से जोड़ सकते हैं. इससे संख्या में अंतर हो सकता है, क्योंकि जोड़ने जैसे कुछ फ़ंक्शन, फ़्लोट के लिए काम नहीं करते. हालांकि, अगर डेटा की रेंज सीमित है, तो ज़्यादातर काम के लिए, फ़्लोटिंग-पॉइंट जोड़ने की सुविधा, असोसिएटिव के बराबर होती है.
उदाहरण
[10, 11,
12, 13] वैल्यू वाले एक 1D ऐरे में, एक डाइमेंशन में घटाने पर, f (यह computation है) फ़ंक्शन का इस्तेमाल किया जाता है. इसका हिसाब इस तरह से लगाया जा सकता है
f(10, f(11, f(12, f(init_value, 13)))
हालांकि, इसके और भी कई तरीके हैं. जैसे:
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
यहां एक उदाहरण के तौर पर, घटाने की सुविधा को लागू करने का तरीका बताया गया है. इसमें शुरुआती वैल्यू 0 के साथ, घटाने की प्रक्रिया के तौर पर जोड़ने का इस्तेमाल किया गया है.
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the number of dimensions of the result.
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
यहां 2D ऐरे (मैट्रिक्स) को छोटा करने का उदाहरण दिया गया है. आकार में दो डाइमेंशन हैं, डाइमेंशन 0 का साइज़ 2 और डाइमेंशन 1 का साइज़ 3 है:
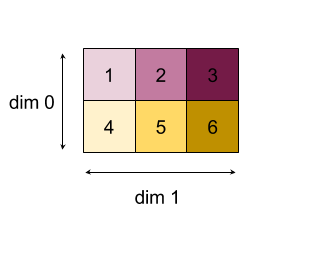
"जोड़ें" फ़ंक्शन की मदद से, डाइमेंशन को 0 या 1 घटाने से मिलने वाले नतीजे:
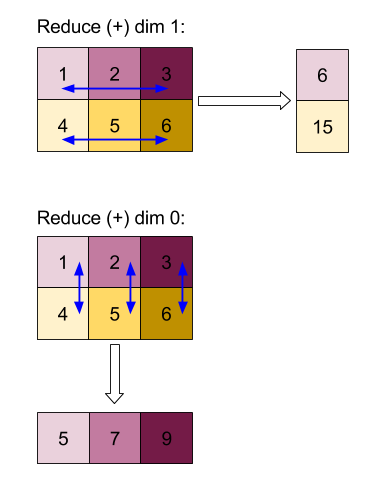
ध्यान दें कि घटाने के दोनों नतीजे 1D ऐरे हैं. इस डायग्राम में, एक को कॉलम और दूसरे को पंक्ति के तौर पर दिखाया गया है. ऐसा सिर्फ़ विज़ुअल के लिए किया गया है.
ज़्यादा मुश्किल उदाहरण के लिए, यहां एक 3D ऐरे दिया गया है. इसमें तीन डाइमेंशन हैं. डाइमेंशन 0 का साइज़ चार है, डाइमेंशन 1 का साइज़ दो है, और डाइमेंशन 2 का साइज़ तीन है. आसानी से समझने के लिए, 1 से 6 तक की वैल्यू को डाइमेंशन 0 में दोहराया गया है.
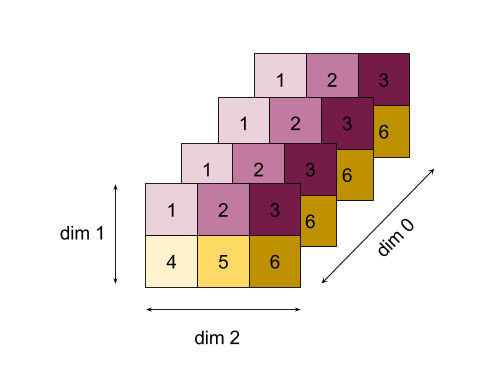
2D उदाहरण की तरह ही, हम सिर्फ़ एक डाइमेंशन कम कर सकते हैं. उदाहरण के लिए, अगर हम डाइमेंशन 0 को कम करते हैं, तो हमें एक दो डाइमेंशन वाला ऐरे मिलता है. इसमें डाइमेंशन 0 की सभी वैल्यू को स्केलर में फ़ोल्ड किया गया है:
| 4 8 12 |
| 16 20 24 |
अगर हम डाइमेंशन 2 को कम करते हैं, तो हमें दो डाइमेंशन वाला ऐरे भी मिलता है. इसमें डाइमेंशन 2 की सभी वैल्यू को स्केलर में फ़ोल्ड किया गया है:
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
ध्यान दें कि इनपुट में बचे हुए डाइमेंशन के बीच का रिलेटिव क्रम, आउटपुट में भी बना रहता है. हालांकि, कुछ डाइमेंशन को नई संख्याएं असाइन की जा सकती हैं, क्योंकि डाइमेंशन की संख्या बदल जाती है.
हम एक से ज़्यादा डाइमेंशन भी कम कर सकते हैं. डाइमेंशन 0 और 1 को जोड़ने से, 1D ऐरे [20, 28, 36] बनता है.
3D ऐरे को उसके सभी डाइमेंशन में कम करने पर, स्केलर 84 बनता है.
वैरिएडिक रिड्यूस
N > 1 के लिए, घटाने वाले फ़ंक्शन को लागू करना थोड़ा मुश्किल होता है, क्योंकि यह सभी इनपुट पर एक साथ लागू होता है. ऑपरेंड को कैलकुलेशन में इस क्रम में दिया जाता है:
- पहले ऑपरेंड के लिए कम की गई वैल्यू का इस्तेमाल करना
- ...
- Nवें ऑपरेंड के लिए, कम की गई वैल्यू का इस्तेमाल किया जा रहा है
- पहले ऑपरेंड के लिए इनपुट वैल्यू
- ...
- Nवें ऑपरेंड के लिए इनपुट वैल्यू
उदाहरण के लिए, यहां दिया गया REDUCE फ़ंक्शन देखें. इसका इस्तेमाल, एक डाइमेंशन वाले ऐरे में सबसे बड़ी वैल्यू और argmax को एक साथ कैलकुलेट करने के लिए किया जा सकता है:
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
1-D इनपुट ऐरे V = Float[N], K = Int[N] और शुरू में दी गई वैल्यू I_V = Float, I_K = Int के लिए, सिर्फ़ इनपुट डाइमेंशन में घटाने पर मिलने वाला नतीजा f_(N-1), बार-बार इस्तेमाल होने वाले इस फ़ंक्शन के नतीजे के बराबर होता है:
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
वैल्यू के ऐरे और क्रम से लगाए गए इंडेक्स (जैसे, iota) के ऐरे पर, इस रिडक्शन को लागू करने से, ऐरे पर एक साथ कार्रवाई की जाएगी. साथ ही, सबसे बड़ी वैल्यू और मैच करने वाले इंडेक्स वाला ट्यूपल दिखाया जाएगा.
ReducePrecision
XlaBuilder::ReducePrecision भी देखें.
यह फ़ंक्शन, फ़्लोटिंग-पॉइंट वैल्यू को कम सटीक फ़ॉर्मैट (जैसे, IEEE-FP16) में बदलने और फिर उन्हें ओरिजनल फ़ॉर्मैट में वापस लाने के असर का मॉडल बनाता है. कम सटीक फ़ॉर्मैट में, एक्सपोनेंट और मैन्टिसा बिट की संख्या को मनमुताबिक तय किया जा सकता है. हालांकि, हो सकता है कि सभी बिट साइज़, सभी हार्डवेयर पर काम न करें.
ReducePrecision(operand, mantissa_bits, exponent_bits)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
फ़्लोटिंग-पॉइंट टाइप T का ऐरे. |
exponent_bits |
int32 |
कम सटीक फ़ॉर्मैट में एक्सपोनेंट बिट की संख्या |
mantissa_bits |
int32 |
कम सटीक फ़ॉर्मैट में मैन्टिसा बिट की संख्या |
नतीजा, T टाइप का ऐरे होता है. इनपुट वैल्यू को, दिए गए मैन्टिसा बिट की संख्या के साथ दिखाई जा सकने वाली सबसे नज़दीकी वैल्यू पर राउंड किया जाता है. इसके लिए, "सम संख्या पर बराबर करें" सेमेटिक्स का इस्तेमाल किया जाता है. साथ ही, एक्सपोनेंट बिट की संख्या से तय की गई रेंज से ज़्यादा की वैल्यू को, अनंत के धनात्मक या ऋणात्मक वैल्यू पर क्लैंप किया जाता है. NaN वैल्यू को बरकरार रखा जाता है. हालांकि, इन्हें कैननिकल NaN वैल्यू में बदला जा सकता है.
कम सटीक फ़ॉर्मैट में कम से कम एक एक्सपोनेंट बिट होना चाहिए, ताकि शून्य वैल्यू को अनंत से अलग किया जा सके. ऐसा इसलिए है, क्योंकि दोनों में मैन्टिसा शून्य होता है. साथ ही, मैन्टिसा बिट की संख्या भी गैर-नेगेटिव होनी चाहिए. एक्सपोनेंट या मैनटिसा बिट की संख्या, टाइप T के लिए उससे जुड़ी वैल्यू से ज़्यादा हो सकती है. ऐसे में, कन्वर्ज़न का उससे जुड़ा हिस्सा सिर्फ़ कोई काम नहीं करता.
ReduceScatter
XlaBuilder::ReduceScatter भी देखें.
ReduceScatter एक ऐसा ग्रुप ऑपरेशन है जो असरदार तरीके से AllReduce करता है और फिर नतीजे को scatter_dimension के साथ shard_count ब्लॉक में बांटकर उसे स्कैटर करता है. साथ ही, रीप्लिक ग्रुप में रीप्लिक i को ith वाला शर्ड मिलता है.
ReduceScatter(operand, computation, scatter_dim, shard_count,
replica_group_ids, channel_id)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
सभी रेप्लिक में कम करने के लिए, ऐरे या ऐरे का कोई ऐसा टुपल जो खाली न हो. |
computation |
XlaComputation |
उत्सर्जन में कमी का हिसाब लगाना |
scatter_dimension |
int64 |
स्कैटर करने के लिए डाइमेंशन. |
shard_count |
int64 |
ब्लॉक की संख्या scatter_dimension |
replica_groups |
int64 के वेक्टर का वेक्टर |
जिन ग्रुप के बीच कमी की जाती है |
channel_id |
ज़रूरी नहीं int64 |
अलग-अलग मॉड्यूल के बीच कम्यूनिकेशन के लिए वैकल्पिक चैनल आईडी |
- जब
operand, ऐरे का ट्यूपल होता है, तो ट्यूपल के हर एलिमेंट पर, रिड्यूस-स्कैटर किया जाता है. replica_groups, उन रीप्लिक ग्रुप की सूची है जिनके बीच डेटा कम किया जाता है. मौजूदा रीप्लिक का रीप्लिक आईडी,ReplicaIdका इस्तेमाल करके वापस पाया जा सकता है. हर ग्रुप में रीप्लिक का क्रम तय करता है कि सभी रीप्लिक का डेटा किस क्रम में अलग-अलग जगहों पर भेजा जाएगा.replica_groupsया तो खाली होना चाहिए (इस मामले में सभी रेप्लिक एक ही ग्रुप से जुड़े होते हैं) या इसमें रेप्लिक की संख्या के बराबर एलिमेंट होने चाहिए. अगर एक से ज़्यादा डुप्लीकेट ग्रुप हैं, तो सभी ग्रुप का साइज़ एक जैसा होना चाहिए. उदाहरण के लिए,replica_groups = {0, 2}, {1, 3},0और2, और1और3के बीच डेटा को कम करता है. इसके बाद, वह नतीजे को स्कैटर करता है.shard_count, हर एक रेप्लिक ग्रुप का साइज़ है. हमें इसकी ज़रूरत उन मामलों में होती है जहांreplica_groupsखाली होते हैं. अगरreplica_groupsखाली नहीं है, तोshard_countहर रेप्लिक ग्रुप के साइज़ के बराबर होना चाहिए.channel_idका इस्तेमाल, अलग-अलग मॉड्यूल के बीच कम्यूनिकेशन के लिए किया जाता है: सिर्फ़ एक हीchannel_idवालेreduce-scatterऑपरेशन, एक-दूसरे के साथ कम्यूनिकेट कर सकते हैं.
आउटपुट आकार, इनपुट आकार का scatter_dimension गुना छोटा होता है.shard_count उदाहरण के लिए, अगर दो प्रतिकृति हैं और दोनों प्रतिकृति में ऑपरेंड की वैल्यू क्रमशः [1.0, 2.25] और [3.0, 5.25] है, तो इस ऑपरेशन से मिलने वाली आउटपुट वैल्यू, जहां scatter_dim 0 है, वह पहले रिप्लिक के लिए [4.0] और दूसरे रिप्लिक के लिए [7.5] होगी.
ReduceWindow
XlaBuilder::ReduceWindow भी देखें.
यह फ़ंक्शन, कई डाइमेंशन वाले N ऐरे के क्रम की हर विंडो में मौजूद सभी एलिमेंट पर, रिडक्शन फ़ंक्शन लागू करता है. साथ ही, आउटपुट के तौर पर कई डाइमेंशन वाले N ऐरे का एक या टपल बनाता है. हर आउटपुट कलेक्शन में उतने ही एलिमेंट होते हैं जितनी विंडो की मान्य पोज़िशन होती हैं. पूलिंग लेयर को ReduceWindow के तौर पर दिखाया जा सकता है. Reduce की तरह ही, लागू किया गया computation हमेशा बाईं ओर मौजूद init_values से पास किया जाता है.
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operands |
N XlaOps |
T_0,..., T_{N-1} टाइप के N मल्टी-डाइमेंशनल ऐरे का क्रम, जिसमें से हर ऐरे उस बेस एरिया को दिखाता है जिस पर विंडो को रखा गया है. |
init_values |
N XlaOps |
घटाने के लिए N शुरुआती वैल्यू, N ऑपरेंड में से हर एक के लिए एक. ज़्यादा जानकारी के लिए, कम करें देखें. |
computation |
XlaComputation |
T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}) टाइप का रिडक्शन फ़ंक्शन, जो सभी इनपुट ऑपरेंड की हर विंडो में मौजूद एलिमेंट पर लागू होता है. |
window_dimensions |
ArraySlice<int64> |
विंडो डाइमेंशन की वैल्यू के लिए, पूर्णांकों का कलेक्शन |
window_strides |
ArraySlice<int64> |
विंडो की स्ट्राइड वैल्यू के लिए, पूर्णांकों का कलेक्शन |
base_dilations |
ArraySlice<int64> |
बेस डाइलेशन वैल्यू के लिए, पूर्णांकों का कलेक्शन |
window_dilations |
ArraySlice<int64> |
विंडो डाइलेशन वैल्यू के लिए, पूर्णांकों का कलेक्शन |
padding |
Padding |
विंडो के लिए पैडिंग टाइप (Padding::kSame, जो पैड करता है, ताकि स्ट्राइड 1 होने पर आउटपुट का आकार इनपुट जैसा हो या Padding::kValid, जो पैडिंग का इस्तेमाल नहीं करता और विंडो के फ़िट न होने पर उसे "बंद" कर देता है) |
कहां:
- N की वैल्यू 1 या उससे ज़्यादा होनी चाहिए.
- सभी इनपुट ऐरे के डाइमेंशन एक ही होने चाहिए.
- अगर
N = 1,Collate(T)Tहै. - अगर
N > 1,Collate(T_0, ..., T_{N-1}),(T0,...T{N-1})टाइप केNएलिमेंट का ट्यूपल है.
नीचे दिए गए कोड और फ़ोटो में, ReduceWindow का इस्तेमाल करने का उदाहरण दिया गया है. इनपुट, [4x6] साइज़ का मैट्रिक्स है और window_dimensions और window_stride_dimensions, दोनों [2x3] हैं.
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
किसी डाइमेंशन में 1 का स्ट्राइड बताता है कि डाइमेंशन में किसी विंडो की पोज़िशन, उसके बगल में मौजूद विंडो से एक एलिमेंट दूर है. यह बताने के लिए कि कोई भी विंडो एक-दूसरे से ओवरलैप नहीं होती, window_stride_dimensions का वैल्यू, window_dimensions के बराबर होनी चाहिए. नीचे दी गई इमेज में, दो अलग-अलग स्ट्राइड वैल्यू के इस्तेमाल के बारे में बताया गया है. पैडिंग, इनपुट के हर डाइमेंशन पर लागू होती है. साथ ही, कैलकुलेशन वैसे ही होते हैं जैसे कि इनपुट, पैडिंग के बाद के डाइमेंशन के साथ आया हो.
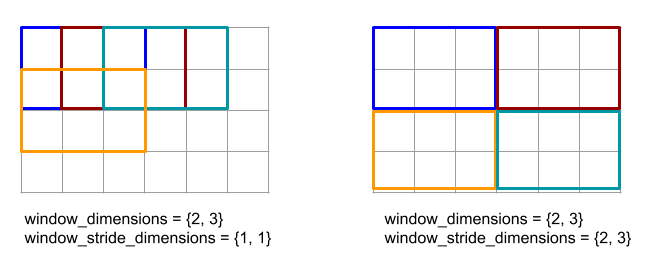
पैडिंग के सामान्य उदाहरण के लिए, इनपुट ऐरे [10000, 1000, 100, 10, 1] पर डाइमेंशन 3 और स्ट्राइड 2 के साथ, कम से कम रीड्यूस-विंडो (शुरुआती वैल्यू MAX_FLOAT) का हिसाब लगाएं. पैडिंग kValid, दो मान्य विंडो: [10000, 1000, 100] और [100, 10, 1] पर कम से कम वैल्यू का हिसाब लगाता है. इससे [100, 1] का आउटपुट मिलता है. पैडिंग kSame सबसे पहले ऐरे को पैड करता है, ताकि कम करने वाली विंडो के बाद, आकार [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE] के तौर पर, दोनों तरफ़ शुरुआती एलिमेंट जोड़कर, पहले चरण के इनपुट के जैसा हो. पैड किए गए ऐरे पर reduce-window फ़ंक्शन चलाने पर, यह तीन विंडो [MAX_VALUE, 10000, 1000], [1000, 100, 10], [10, 1, MAX_VALUE] पर काम करता है और [1000, 10, 1] दिखाता है.
रिडक्शन फ़ंक्शन का आकलन करने का क्रम मनमुताबिक होता है और यह तय नहीं होता. इसलिए, डेटा कम करने वाले फ़ंक्शन को फिर से असोसिएट करने के लिए ज़्यादा संवेदनशील नहीं होना चाहिए. ज़्यादा जानकारी के लिए, Reduce के संदर्भ में, असोसिएटिविटी के बारे में चर्चा देखें.
ReplicaId
XlaBuilder::ReplicaId भी देखें.
यह रिप्लिकेशन का यूनीक आईडी (U32 स्केलर) दिखाता है.
ReplicaId()
हर रेप्लिक का यूनीक आईडी, [0, N) के बीच का बिना साइन वाला पूर्णांक होता है,
जहां N रेप्लिक की संख्या है. सभी प्रतिकृति एक ही प्रोग्राम चला रही हैं, इसलिए प्रोग्राम में ReplicaId() कॉल करने पर, हर प्रतिकृति पर एक अलग वैल्यू दिखेगी.
आकार बदलना
XlaBuilder::Reshape और Collapse ऑपरेशन भी देखें.
किसी ऐरे के डाइमेंशन को नए कॉन्फ़िगरेशन में बदलता है.
Reshape(operand, dimensions)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का कलेक्शन |
dimensions |
int64 वेक्टर |
नए डाइमेंशन के साइज़ का वेक्टर |
कॉन्सेप्ट के हिसाब से, reshape फ़ंक्शन पहले किसी ऐरे को डेटा वैल्यू के एक-आयामी वेक्टर में फ़्लैट कर देता है. इसके बाद, इस वेक्टर को नए शेप में बदल देता है. इनपुट आर्ग्युमेंट, टाइप T का कोई भी ऐरे होता है. साथ ही, यह नतीजे के लिए डाइमेंशन इंडेक्स का कंपाइल-टाइम-कॉन्स्टेंट वेक्टर और डाइमेंशन साइज़ का कंपाइल-टाइम-कॉन्स्टेंट वेक्टर होता है.
dimensions वेक्टर से, आउटपुट ऐरे का साइज़ तय होता है. dimensions में इंडेक्स 0 पर मौजूद वैल्यू, डाइमेंशन 0 का साइज़ है. इंडेक्स 1 पर मौजूद वैल्यू, डाइमेंशन 1 का साइज़ है, और इसी तरह आगे भी. dimensions डाइमेंशन का प्रॉडक्ट, ऑपरेंड के डाइमेंशन साइज़ के प्रॉडक्ट के बराबर होना चाहिए. dimensions से तय किए गए कई डाइमेंशन वाले अरे में, छोटा किया गया अरे बेहतर बनाने पर, dimensions में डाइमेंशन का क्रम, सबसे धीरे बदलने वाले (सबसे ज़्यादा मेजर) से लेकर सबसे तेज़ी से बदलने वाले (सबसे ज़्यादा माइनर) तक होता है.
उदाहरण के लिए, मान लें कि v 24 एलिमेंट का ऐरे है:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
let v012_24 = Reshape(v, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
किसी खास मामले में, reshape फ़ंक्शन किसी एक एलिमेंट वाले ऐरे को स्केलर में बदल सकता है और स्केलर को ऐरे में बदल सकता है. उदाहरण के लिए,
Reshape(f32[1x1] { {5} }, {}) == 5;
Reshape(5, {1,1}) == f32[1x1] { {5} };
रिवर्स (उलटा)
XlaBuilder::Rev भी देखें.
Rev(operand, dimensions)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का कलेक्शन |
dimensions |
ArraySlice<int64> |
डाइमेंशन बदलने के लिए |
यह फ़ंक्शन, operand ऐरे में एलिमेंट के क्रम को, तय किए गए dimensions के हिसाब से उलट देता है. साथ ही, उसी आकार का आउटपुट ऐरे जनरेट करता है. मल्टीडाइमेंशनल इंडेक्स में ऑपरेंड कलेक्शन के हर एलिमेंट को, ट्रांसफ़ॉर्म किए गए इंडेक्स में आउटपुट कलेक्शन में स्टोर किया जाता है. मल्टीडाइमेंशनल इंडेक्स को बदलने के लिए, हर डाइमेंशन में मौजूद इंडेक्स को बदला जाता है. इसका मतलब है कि अगर साइज़ N का कोई डाइमेंशन, बदले जाने वाले डाइमेंशन में से एक है, तो उसका इंडेक्स i को N - 1 - i में बदल दिया जाता है.
Rev ऑपरेशन का एक इस्तेमाल, नेटवर्क में ग्रेडिएंट कैलकुलेशन के दौरान, दो विंडो डाइमेंशन के साथ-साथ कॉन्वोल्यूशन वेट कलेक्शन को उलटने के लिए किया जाता है.
RngNormal
XlaBuilder::RngNormal भी देखें.
N(μ,σ) नॉर्मल डिस्ट्रिब्यूशन के हिसाब से जनरेट किए गए यादृच्छिक नंबरों की मदद से, किसी दिए गए आकार का आउटपुट बनाता है. पैरामीटर μ और σऔर आउटपुट शेप का एलिमेंटल टाइप, फ़्लोटिंग पॉइंट होना चाहिए. इसके अलावा, पैरामीटर की वैल्यू स्केलर होनी चाहिए.
RngNormal(mu, sigma, shape)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
mu |
XlaOp |
जनरेट की गई संख्याओं का औसत बताने वाला, T टाइप का स्केलर |
sigma |
XlaOp |
जनरेट किए गए डेटा के स्टैंडर्ड डीविएशन की जानकारी देने वाला, T टाइप का स्केलर |
shape |
Shape |
टी टाइप का आउटपुट शेप |
RngUniform
XlaBuilder::RngUniform भी देखें.
किसी दिए गए आकार का आउटपुट बनाता है. इसके लिए, इंटरवल [a,b)में यूनिफ़ॉर्म डिस्ट्रिब्यूशन के हिसाब से जनरेट किए गए रैंडम नंबर का इस्तेमाल किया जाता है. पैरामीटर और आउटपुट एलिमेंट का टाइप, बूलियन टाइप, इंटिग्रल टाइप या फ़्लोटिंग पॉइंट टाइप होना चाहिए. साथ ही, टाइप एक जैसे होने चाहिए. फ़िलहाल, सीपीयू और जीपीयू बैकएंड में सिर्फ़ F64, F32, F16, BF16, S64, U64, S32, और U32 का इस्तेमाल किया जा सकता है. इसके अलावा, पैरामीटर की वैल्यू स्केलर होनी चाहिए. अगर b<=a नतीजा, लागू करने के तरीके से तय होता है.
RngUniform(a, b, shape)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
a |
XlaOp |
इंटरवल की निचली सीमा तय करने वाला T टाइप का स्केलर |
b |
XlaOp |
इंटरवल की ऊपरी सीमा बताने वाला T टाइप का स्केलर |
shape |
Shape |
टी टाइप का आउटपुट शेप |
RngBitGenerator
यह फ़ंक्शन, दिए गए आकार के साथ एक आउटपुट जनरेट करता है. इसमें, दिए गए एल्गोरिदम (या बैकएंड डिफ़ॉल्ट) का इस्तेमाल करके, एक जैसे रैंडम बिट भरे जाते हैं. साथ ही, यह अपडेट की गई स्थिति (शुरुआती स्थिति के जैसे आकार के साथ) और जनरेट किया गया रैंडम डेटा दिखाता है.
शुरुआती स्थिति, मौजूदा रैंडम नंबर जनरेशन की शुरुआती स्थिति होती है. यह और ज़रूरी आकार और मान्य वैल्यू, इस्तेमाल किए गए एल्गोरिदम पर निर्भर करती हैं.
यह पक्का है कि आउटपुट, शुरुआती स्थिति का डेटरमिनिस्टिक फ़ंक्शन होगा. हालांकि, यह नहीं पक्का है कि बैकएंड और कंपाइलर के अलग-अलग वर्शन के बीच आउटपुट डेटरमिनिस्टिक होगा.
RngBitGenerator(algorithm, key, shape)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
algorithm |
RandomAlgorithm |
इस्तेमाल किया जाने वाला पीआरएनजी एल्गोरिदम. |
initial_state |
XlaOp |
पीआरएनजी एल्गोरिदम के लिए शुरुआती स्थिति. |
shape |
Shape |
जनरेट किए गए डेटा का आउटपुट शेप. |
algorithm के लिए उपलब्ध वैल्यू:
rng_default: बैकएंड के हिसाब से तय किए गए आकार की ज़रूरतों के साथ बैकएंड के हिसाब से तय किया गया एल्गोरिदम.rng_three_fry: ThreeFry काउंटर पर आधारित पीआरएनजी एल्गोरिदम.initial_stateकेu64[2]आकार में, मनमुताबिक वैल्यू दी गई हैं. Salmon et al. SC 2011. पैरलल रैंडम नंबर: बेहद आसान.rng_philox: एक साथ कई रैंडम नंबर जनरेट करने के लिए, Philox एल्गोरिदम.initial_stateआकारu64[3]है, जिसमें मनमुताबिक वैल्यू दी गई हैं. Salmon et al. SC 2011. पैरलल रैंडम नंबर: बेहद आसान.
स्कैटर
XLA स्कैटर ऑपरेशन, नतीजों का एक क्रम जनरेट करता है. ये नतीजे, इनपुट ऐरे operands की वैल्यू होते हैं. साथ ही, इनमें कई स्लाइस (scatter_indices से तय किए गए इंडेक्स पर) होते हैं, जिन्हें update_computation का इस्तेमाल करके updates में वैल्यू के क्रम के साथ अपडेट किया जाता है.
XlaBuilder::Scatter भी देखें.
scatter(operands..., scatter_indices, updates..., update_computation,
index_vector_dim, update_window_dims, inserted_window_dims,
scatter_dims_to_operand_dims)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operands |
N XlaOp का क्रम |
T_0, ..., T_N टाइप के N ऐरे, जिन्हें अलग-अलग स्प्रेडशीट में बांटना है. |
scatter_indices |
XlaOp |
वह ऐरे जिसमें उन स्लाइस के शुरुआती इंडेक्स शामिल होते हैं जिन्हें अलग-अलग स्लाइस में बांटना है. |
updates |
N XlaOp का क्रम |
T_0, ..., T_N टाइप के N ऐरे. updates[i] में वे वैल्यू होती हैं जिनका इस्तेमाल स्कैटरिंग operands[i] के लिए किया जाना चाहिए. |
update_computation |
XlaComputation |
इनपुट ऐरे में मौजूद वैल्यू और स्कैटर के दौरान अपडेट को जोड़ने के लिए इस्तेमाल किया जाने वाला कैलकुलेशन. यह कैलकुलेशन T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N) टाइप का होना चाहिए. |
index_vector_dim |
int64 |
scatter_indices में मौजूद वह डाइमेंशन जिसमें शुरुआती इंडेक्स शामिल हैं. |
update_window_dims |
ArraySlice<int64> |
updates शेप में डाइमेंशन का सेट, जो विंडो डाइमेंशन हैं. |
inserted_window_dims |
ArraySlice<int64> |
विंडो डाइमेंशन का सेट, जिसे updates आकार में डालना है. |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
स्कैटर इंडेक्स से ऑपरेंड इंडेक्स स्पेस तक का डाइमेंशन मैप. इस ऐरे को i को scatter_dims_to_operand_dims[i] पर मैप करने के तौर पर समझा जाता है . यह एक-एक और कुल होना चाहिए. |
indices_are_sorted |
bool |
क्या इंडेक्स को कॉलर के हिसाब से क्रम में लगाने की गारंटी है. |
unique_indices |
bool |
क्या कॉलर ने यह पक्का किया है कि इंडेक्स यूनीक हैं. |
कहां:
- N की वैल्यू 1 या उससे ज़्यादा होनी चाहिए.
operands[0], ...,operands[N-1] में सभी डाइमेंशन एक जैसे होने चाहिए.updates[0], ...,updates[N-1] में सभी डाइमेंशन एक जैसे होने चाहिए.- अगर
N = 1,Collate(T)Tहै. - अगर
N > 1,Collate(T_0, ..., T_N)Tटाइप केNएलिमेंट का ट्यूपल है.
अगर index_vector_dim, scatter_indices.rank के बराबर है, तो हम यह मान लेते हैं कि scatter_indices में आखिर में 1 डाइमेंशन है.
हम ArraySlice<int64> टाइप के update_scatter_dims को, updates शेप में डाइमेंशन के ऐसे सेट के तौर पर परिभाषित करते हैं जो update_window_dims में नहीं हैं. साथ ही, ये डाइमेंशन बढ़ते हुए क्रम में होते हैं.
स्कैटर के आर्ग्युमेंट इन सीमाओं के मुताबिक होने चाहिए:
हर
updatesकलेक्शन मेंupdate_window_dims.size + scatter_indices.rank - 1डाइमेंशन होने चाहिए.हर
updatesकलेक्शन में डाइमेंशनiके बाउंड, इनके मुताबिक होने चाहिए:- अगर
i,update_window_dimsमें मौजूद है (यानी कुछkके लिएupdate_window_dims[k] के बराबर है), तोupdatesमें डाइमेंशनiका बाउंड,inserted_window_dimsको ध्यान में रखते हुएoperandके बाउंड से ज़्यादा नहीं होना चाहिए (यानीadjusted_window_bounds[k], जहांadjusted_window_boundsमेंoperandके बाउंड होते हैं और इंडेक्सinserted_window_dimsके बाउंड हटा दिए जाते हैं). - अगर
i,update_scatter_dimsमें मौजूद है (यानी कुछkके लिएupdate_scatter_dims[k] के बराबर है), तोupdatesमें डाइमेंशनiका बाउंड,scatter_indicesके उसी बाउंड के बराबर होना चाहिए. इसके लिए,index_vector_dimको स्किप किया जाना चाहिए. उदाहरण के लिए, अगरk<index_vector_dimहै, तोscatter_indices.shape.dims[k] और अगर ऐसा नहीं है, तोscatter_indices.shape.dims[k+1].
- अगर
update_window_dims, बढ़ते क्रम में होना चाहिए. इसमें कोई डाइमेंशन नंबर दोहराया नहीं जाना चाहिए. साथ ही, यह[0, updates.rank)की रेंज में होना चाहिए.inserted_window_dims, बढ़ते क्रम में होना चाहिए. इसमें कोई डाइमेंशन नंबर दोहराया नहीं जाना चाहिए. साथ ही, यह[0, operand.rank)की रेंज में होना चाहिए.operand.rankकी वैल्यू,update_window_dims.sizeऔरinserted_window_dims.sizeके योग के बराबर होनी चाहिए.scatter_dims_to_operand_dims.sizeका मान,scatter_indices.shape.dims[index_vector_dim] के बराबर होना चाहिए. साथ ही, इसकी वैल्यू,[0, operand.rank)की रेंज में होनी चाहिए.
हर updates कलेक्शन में मौजूद किसी इंडेक्स U के लिए, उससे जुड़े operands कलेक्शन में मौजूद इंडेक्स I का हिसाब इस तरह लगाया जाता है:
- मान लें कि
G= {U[k] forkinupdate_scatter_dims}.Gका इस्तेमाल करके,scatter_indicesकलेक्शन में इंडेक्स वेक्टरSको खोजें, ताकिS[i] =scatter_indices[Combine(G,i)] हो. यहां Combine(A, b), A मेंindex_vector_dimपोज़िशन पर b को डालता है. scatter_dims_to_operand_dimsमैप का इस्तेमाल करकेSको अलग-अलग जगहों पर भेजकर,Sका इस्तेमाल करकेoperandमें इंडेक्सSinबनाएं. फ़ॉर्मल तरीके से:Sin[scatter_dims_to_operand_dims[k]] =S[k], अगरk<scatter_dims_to_operand_dims.size.Sin[_] =0, अगर ऐसा नहीं है.
Uमेंupdate_window_dimsपर इंडेक्स कोinserted_window_dimsके हिसाब से बिखेरकर, हरoperandsऐरे में एक इंडेक्सWinबनाएं. फ़ॉर्मल तरीके से:Win[window_dims_to_operand_dims(k)] =U[k], अगरkupdate_window_dimsमें है. यहांwindow_dims_to_operand_dims, डोमेन [0,update_window_dims.size) और रेंज [0,operand.rank) \inserted_window_dimsवाला एक ऐसा फ़ंक्शन है जो एक ही दिशा में बढ़ता या घटता है. (उदाहरण के लिए, अगरupdate_window_dims.size4है,operand.rank6है, औरinserted_window_dims{0,2} है, तोwindow_dims_to_operand_dims{0→1,1→3,2→4,3→5} है).Win[_] =0, अगर ऐसा नहीं है.
I,Win+Sinहै. यहां + का मतलब एलिमेंट के हिसाब से जोड़ना है.
खास जानकारी के तौर पर, स्कैटर ऑपरेशन को इस तरह से परिभाषित किया जा सकता है.
outputकोoperandsसे शुरू करें. इसका मतलब है किoperands[J] कलेक्शन में मौजूद सभी इंडेक्सJके लिए, सभी इंडेक्सOके लिए:
output[J][O] =operands[J][O]updates[J] कलेक्शन में मौजूद हर इंडेक्सUऔरoperand[J] कलेक्शन में मौजूद उससे जुड़े इंडेक्सOके लिए, अगरOoutputके लिए मान्य इंडेक्स है, तो:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
अपडेट लागू करने का क्रम तय नहीं होता. इसलिए, जब updates में मौजूद कई इंडेक्स, operands में मौजूद एक ही इंडेक्स को रेफ़र करते हैं, तो output में मौजूद उस इंडेक्स की वैल्यू तय नहीं होगी.
ध्यान दें कि update_computation में पास किया गया पहला पैरामीटर, हमेशा output कलेक्शन की मौजूदा वैल्यू होगा और दूसरा पैरामीटर, हमेशा updates कलेक्शन की वैल्यू होगा. यह खास तौर पर उन मामलों के लिए ज़रूरी है जब update_computation कम्यूटेटिव नहीं है.
अगर indices_are_sorted को 'सही है' पर सेट किया जाता है, तो XLA यह मान सकता है कि उपयोगकर्ता ने scatter_indices को scatter_dims_to_operand_dims के हिसाब से वैल्यू को अलग-अलग करने के बाद, बढ़ते क्रम में क्रम से लगाया है. अगर ऐसा नहीं है, तो इसका मतलब है कि सेमेटिक्स को लागू करने के तरीके के हिसाब से तय किया जाता है.
अगर unique_indices को 'सही है' पर सेट किया जाता है, तो XLA यह मान सकता है कि अलग-अलग स्प्रेडशीट में मौजूद सभी एलिमेंट यूनीक हैं. इसलिए, XLA में ऐसे ऑपरेशन का इस्तेमाल किया जा सकता है जो एटॉमिक नहीं होते. अगर unique_indices को 'सही है' पर सेट किया गया है और जिन इंडेक्स में डेटा भेजा जा रहा है वे यूनीक नहीं हैं, तो सेमेनटिक्स को लागू करने के तरीके के हिसाब से तय किया जाता है.
स्कैटर ऑपरेशन को गैदर ऑपरेशन के इंवर्स के तौर पर देखा जा सकता है. इसका मतलब है कि स्कैटर ऑपरेशन, इनपुट में उन एलिमेंट को अपडेट करता है जिन्हें संबंधित गैदर ऑपरेशन से निकाला जाता है.
सामान्य जानकारी और उदाहरणों के लिए, Gather में "सामान्य जानकारी" सेक्शन देखें.
चुनें
XlaBuilder::Select भी देखें.
प्रीडिकेट ऐरे की वैल्यू के आधार पर, दो इनपुट ऐरे के एलिमेंट से एक आउटपुट ऐरे बनाता है.
Select(pred, on_true, on_false)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
pred |
XlaOp |
PRED टाइप का कलेक्शन |
on_true |
XlaOp |
T टाइप का कलेक्शन |
on_false |
XlaOp |
T टाइप का कलेक्शन |
ऐरे on_true और on_false का साइज़ एक जैसा होना चाहिए. यह आउटपुट ऐरे का भी आकार होता है. ऐरे pred की डाइमेंशनलिटी, on_true और on_false की डाइमेंशनलिटी के बराबर होनी चाहिए. साथ ही, इसमें PRED एलिमेंट टाइप होना चाहिए.
pred के हर एलिमेंट P के लिए, आउटपुट कलेक्शन का एलिमेंट on_true से लिया जाता है. ऐसा तब किया जाता है, जब P की वैल्यू true हो. वहीं, अगर P की वैल्यू false हो, तो on_false से लिया जाता है. ब्रॉडकास्टिंग के पाबंदी वाले फ़ॉर्म के तौर पर,
pred PRED टाइप का स्केलर हो सकता है. इस मामले में, अगर pred का वैल्यू true है, तो आउटपुट कलेक्शन को पूरी तरह से on_true से लिया जाता है. वहीं, अगर pred का वैल्यू false है, तो आउटपुट कलेक्शन को पूरी तरह से on_false से लिया जाता है.
स्केलर न होने वाले pred का उदाहरण:
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
स्केलर pred के साथ उदाहरण:
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
ट्यूपल के बीच से चुनने की सुविधा काम करती है. इस काम के लिए, ट्यूपल को स्केलर टाइप माना जाता है. अगर on_true और on_false ट्यूपल हैं (जिनका आकार एक जैसा होना चाहिए!), तो pred को PRED टाइप का स्केलर होना चाहिए.
SelectAndScatter
XlaBuilder::SelectAndScatter भी देखें.
इस ऑपरेशन को एक कॉम्पोज़िट ऑपरेशन माना जा सकता है, जो हर विंडो से एक एलिमेंट चुनने के लिए, पहले operand कलेक्शन पर ReduceWindow का हिसाब लगाता है. इसके बाद, चुने गए एलिमेंट के इंडेक्स में source कलेक्शन को स्कैटर करता है, ताकि ऑपरेंड कलेक्शन के जैसे आकार वाला आउटपुट कलेक्शन बनाया जा सके. बाइनरी
select फ़ंक्शन का इस्तेमाल, हर विंडो में इसे लागू करके, हर विंडो से एक एलिमेंट चुनने के लिए किया जाता है. साथ ही, इसे इस प्रॉपर्टी के साथ कॉल किया जाता है कि पहले
पैरामीटर का इंडेक्स वेक्टर, दूसरे पैरामीटर के इंडेक्स वेक्टर से, शब्दकोश के हिसाब से कम है. अगर पहला पैरामीटर चुना जाता है, तो select फ़ंक्शन true दिखाता है और अगर दूसरा पैरामीटर चुना जाता है, तो false दिखाता है. साथ ही, फ़ंक्शन में ट्रांज़िटिविटी (जैसे, अगर select(a, b) और select(b, c) true हैं, तो select(a, c) भी true है) होनी चाहिए, ताकि चुना गया एलिमेंट किसी दी गई विंडो के लिए, ट्रैवर्स किए गए एलिमेंट के क्रम पर निर्भर न हो.
फ़ंक्शन scatter, आउटपुट ऐरे में चुने गए हर इंडेक्स पर लागू होता है. इसमें दो स्केलर पैरामीटर होते हैं:
- आउटपुट कलेक्शन में चुने गए इंडेक्स की मौजूदा वैल्यू
sourceकी स्कैटर वैल्यू, जो चुने गए इंडेक्स पर लागू होती है
यह दो पैरामीटर को जोड़ता है और स्केलर वैल्यू दिखाता है. इसका इस्तेमाल, आउटपुट कलेक्शन में चुने गए इंडेक्स की वैल्यू को अपडेट करने के लिए किया जाता है. शुरुआत में, आउटपुट कलेक्शन के सभी इंडेक्स init_value पर सेट होते हैं.
आउटपुट ऐरे का शेप, operand ऐरे जैसा ही होना चाहिए. साथ ही, source ऐरे का शेप, operand ऐरे पर ReduceWindow ऑपरेशन लागू करने के नतीजे जैसा होना चाहिए. SelectAndScatter का इस्तेमाल, किसी न्यूरल नेटवर्क में पूलिंग लेयर के लिए ग्रेडिएंट वैल्यू को बैकप्रोपगेट करने के लिए किया जा सकता है.
SelectAndScatter(operand, select, window_dimensions, window_strides,
padding, source, init_value, scatter)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का ऐरे, जिस पर विंडो स्लाइड करती हैं |
select |
XlaComputation |
हर विंडो के सभी एलिमेंट पर लागू करने के लिए, T, T -> PRED टाइप का बाइनरी कैलकुलेशन; पहला पैरामीटर चुनने पर true दिखाता है और दूसरा पैरामीटर चुनने पर false दिखाता है |
window_dimensions |
ArraySlice<int64> |
विंडो डाइमेंशन की वैल्यू के लिए, पूर्णांकों का कलेक्शन |
window_strides |
ArraySlice<int64> |
विंडो की स्ट्राइड वैल्यू के लिए, पूर्णांकों का कलेक्शन |
padding |
Padding |
विंडो के लिए पैडिंग टाइप (Padding::kSame या Padding::kValid) |
source |
XlaOp |
स्कैटर करने के लिए वैल्यू वाला T टाइप का ऐरे |
init_value |
XlaOp |
आउटपुट कलेक्शन की शुरुआती वैल्यू के लिए, T टाइप की स्केलर वैल्यू |
scatter |
XlaComputation |
T, T -> T टाइप का बाइनरी कैलकुलेशन, ताकि हर स्कैटर सोर्स एलिमेंट को उसके डेस्टिनेशन एलिमेंट के साथ लागू किया जा सके |
नीचे दिए गए फ़्लो चार्ट में, SelectAndScatter का इस्तेमाल करने के उदाहरण दिए गए हैं. इसमें select फ़ंक्शन, अपने पैरामीटर में से सबसे बड़ी वैल्यू का हिसाब लगाता है. ध्यान दें कि जब विंडो ओवरलैप होती हैं, जैसा कि नीचे दिए गए चित्र (2) में दिखाया गया है, तो operand कलेक्शन के किसी इंडेक्स को अलग-अलग विंडो से कई बार चुना जा सकता है. इस इमेज में, सबसे ऊपर मौजूद दोनों विंडो (नीली और लाल) में वैल्यू 9 वाला एलिमेंट चुना गया है. साथ ही, बाइनरी जोड़ने वाला scatter फ़ंक्शन, वैल्यू 8 (2 + 6) वाला आउटपुट एलिमेंट दिखाता है.
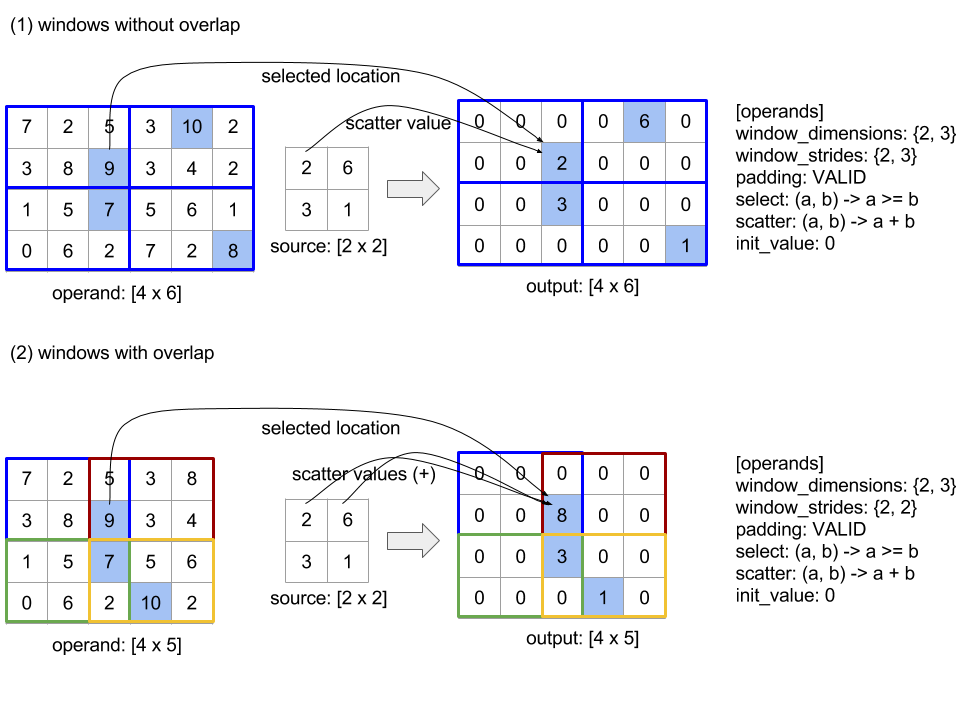
scatter फ़ंक्शन का आकलन करने का क्रम मनमुताबिक हो सकता है और यह क्रम तय नहीं होता. इसलिए, scatter फ़ंक्शन को फिर से असोसिएट करने के लिए ज़्यादा संवेदनशील नहीं होना चाहिए. ज़्यादा जानकारी के लिए, Reduce के संदर्भ में, असोसिएटिविटी के बारे में चर्चा देखें.
भेजें
XlaBuilder::Send भी देखें.
Send(operand, channel_handle)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
भेजा जाने वाला डेटा (T टाइप का कलेक्शन) |
channel_handle |
ChannelHandle |
हर भेजने/पाने वाले पेयर के लिए यूनीक आइडेंटिफ़ायर |
दिए गए ऑपरेंड डेटा को किसी दूसरे कैलकुलेशन में Recv निर्देश पर भेजता है, जो एक ही चैनल हैंडल को शेयर करता है. कोई डेटा नहीं दिखाता.
Recv ऑपरेशन की तरह ही, Send ऑपरेशन का क्लाइंट एपीआई, सिंक्रोनस कम्यूनिकेशन दिखाता है. साथ ही, असाइनॉन्स डेटा ट्रांसफ़र की सुविधा चालू करने के लिए, इसे अंदरूनी तौर पर दो एचएलओ निर्देशों (Send और SendDone) में बांटा जाता है. HloInstruction::CreateSend और HloInstruction::CreateSendDone भी देखें.
Send(HloInstruction operand, int64 channel_id)
ऑपरेंड को एक ही चैनल आईडी वाले Recv निर्देश से, तय किए गए संसाधनों में असाइनीशन ट्रांसफ़र शुरू करता है. एक कॉन्टेक्स्ट दिखाता है. इसका इस्तेमाल, डेटा ट्रांसफ़र के पूरा होने का इंतज़ार करने के लिए, SendDone निर्देश के बाद किया जाता है. कॉन्टेक्स्ट, {operand (shape), request identifier
(U32)} का ट्यूपल होता है. इसका इस्तेमाल सिर्फ़ SendDone निर्देश से किया जा सकता है.
SendDone(HloInstruction context)
Send निर्देश से बनाए गए कॉन्टेक्स्ट के आधार पर, डेटा ट्रांसफ़र होने का इंतज़ार करता है. निर्देश से कोई डेटा नहीं मिलता.
चैनल के लिए निर्देश शेड्यूल करना
हर चैनल (Recv, RecvDone,
Send, SendDone) के लिए, चार निर्देशों को लागू करने का क्रम यहां दिया गया है.
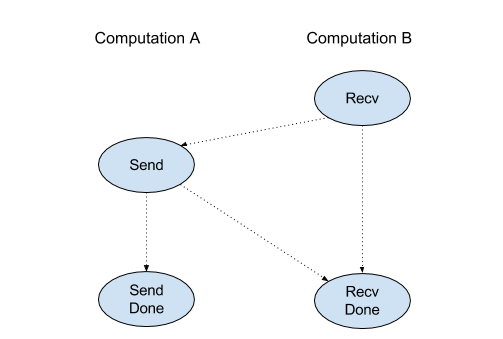
Recv,Sendसे पहले होता हैSend,RecvDoneसे पहले होता हैRecv,RecvDoneसे पहले होता हैSend,SendDoneसे पहले होता है
जब बैकएंड कंपाइलर, चैनल के निर्देशों के ज़रिए जानकारी देने वाले हर कैलकुलेशन के लिए लीनियर शेड्यूल जनरेट करते हैं, तो कैलकुलेशन में कोई साइकल नहीं होना चाहिए. उदाहरण के लिए, नीचे दिए गए शेड्यूल की वजह से डेडलॉक की समस्या आती है.
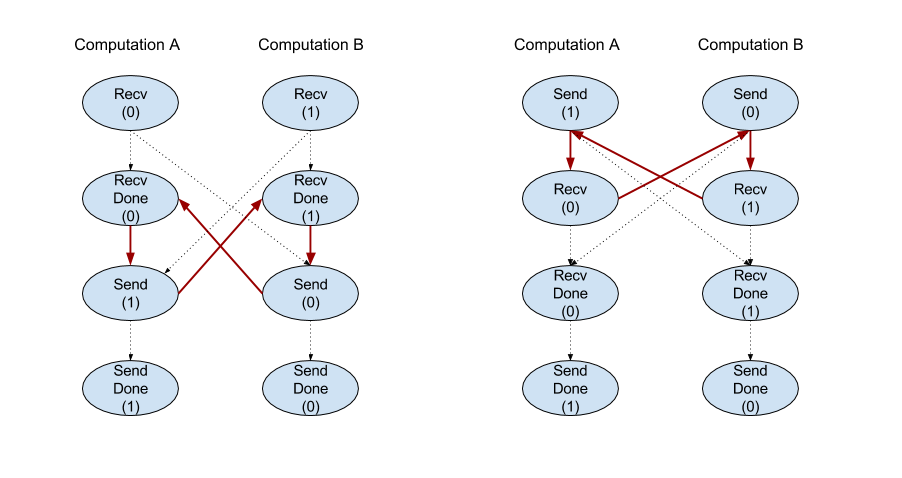
ध्यान दें कि निर्देशों पर लगी पाबंदी, सिर्फ़ रनटाइम के दौरान TPU पर लागू होती है. जीपीयू पर, send और recv, सोर्स और टारगेट डिवाइसों के बीच हैंडशेक होने तक, कोई भी असल डेटा ब्लॉक कर देंगे और नहीं भेजेंगे.
स्लाइस
XlaBuilder::Slice भी देखें.
स्लाइस करने से, इनपुट कलेक्शन से कोई सब-कलेक्शन निकाला जाता है. सब-ऐरे में डाइमेंशन की संख्या, इनपुट की संख्या के बराबर होती है. साथ ही, इसमें इनपुट ऐरे के बॉउंडिंग बॉक्स में वैल्यू होती हैं. बॉउंडिंग बॉक्स के डाइमेंशन और इंडेक्स, स्लाइस ऑपरेशन के लिए आर्ग्युमेंट के तौर पर दिए जाते हैं.
Slice(operand, start_indices, limit_indices, strides)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
T टाइप का N डाइमेंशन वाला ऐरे |
start_indices |
ArraySlice<int64> |
N पूर्णांकों की सूची, जिसमें हर डाइमेंशन के लिए स्लाइस के शुरुआती इंडेक्स शामिल होते हैं. वैल्यू, शून्य से ज़्यादा या उसके बराबर होनी चाहिए. |
limit_indices |
ArraySlice<int64> |
N पूर्णांकों की सूची, जिसमें हर डाइमेंशन के लिए स्लाइस के आखिरी इंडेक्स (एक्सक्लूज़िव) शामिल हैं. हर वैल्यू, डाइमेंशन के लिए तय की गई start_indices वैल्यू से ज़्यादा या उसके बराबर होनी चाहिए. साथ ही, यह डाइमेंशन के साइज़ से कम या उसके बराबर होनी चाहिए. |
strides |
ArraySlice<int64> |
N पूर्णांकों की सूची, जो स्लाइस के इनपुट स्ट्राइड का फ़ैसला करती है. स्लाइस, डाइमेंशन d में मौजूद हर strides[d] एलिमेंट को चुनता है. |
एक डाइमेंशन वाला उदाहरण:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4}) produces:
{2.0, 3.0}
दो डाइमेंशन वाला उदाहरण:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
क्रम से लगाएं
XlaBuilder::Sort भी देखें.
Sort(operands, comparator, dimension, is_stable)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operands |
ArraySlice<XlaOp> |
क्रम से लगाने के लिए ऑपरेंड. |
comparator |
XlaComputation |
इस्तेमाल करने के लिए तुलना करने वाला कैलकुलेशन. |
dimension |
int64 |
वह डाइमेंशन जिससे डेटा को क्रम से लगाना है. |
is_stable |
bool |
क्या स्टैबल क्रम से लगाने की सुविधा का इस्तेमाल करना है. |
अगर सिर्फ़ एक ऑपरेंड दिया गया है, तो:
अगर ऑपरेंड एक डाइमेंशन वाला टेंसर (ऐरे) है, तो नतीजा क्रम से लगाया गया ऐरे होता है. अगर आपको ऐरे को बढ़ते क्रम में लगाना है, तो तुलना करने वाले फ़ंक्शन को कम से कम की तुलना करनी चाहिए. असल में, ऐरे को क्रम से लगाने के बाद, यह
i < jके साथ सभी इंडेक्स पोज़िशनi, jके लिए मान्य होता है, जोcomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseयाcomparator(value[i], value[j]) = trueहो.अगर ऑपरेंड में ज़्यादा डाइमेंशन हैं, तो ऑपरेंड को दिए गए डाइमेंशन के हिसाब से क्रम में लगाया जाता है. उदाहरण के लिए, दो डाइमेंशन वाले टेंसर (मैट्रिक्स) के लिए,
0की डाइमेंशन वैल्यू हर कॉलम को अलग से क्रम से लगाएगी और1की डाइमेंशन वैल्यू हर लाइन को अलग से क्रम से लगाएगी. अगर कोई डाइमेंशन नंबर नहीं दिया गया है, तो डिफ़ॉल्ट रूप से आखिरी डाइमेंशन चुना जाता है. जिस डाइमेंशन को क्रम में लगाया गया है उसके लिए, क्रम से लगाने का वही क्रम लागू होता है जो एक डाइमेंशन वाले मामले में लागू होता है.
अगर n > 1 ऑपरेंड दिए गए हैं, तो:
सभी
nऑपरेंड, एक ही डाइमेंशन वाले टेंसर होने चाहिए. टेंसर के एलिमेंट टाइप अलग-अलग हो सकते हैं.सभी ऑपरेंड को एक साथ क्रम से लगाया जाता है, न कि अलग-अलग. कॉन्सेप्ट के हिसाब से, ऑपरेंड को ट्यूपल के तौर पर माना जाता है. इंडेक्स पोज़िशन
iऔरjपर मौजूद हर ऑपरेंड के एलिमेंट को स्वैप करने की ज़रूरत है या नहीं, यह जांचने के लिए तुलना करने वाले फ़ंक्शन को2 * nस्केलर पैरामीटर के साथ कॉल किया जाता है. इसमें पैरामीटर2 * k,k-thऑपरेंड की पोज़िशनiपर मौजूद वैल्यू से मेल खाता है और पैरामीटर2 * k + 1,k-thऑपरेंड की पोज़िशनjपर मौजूद वैल्यू से मेल खाता है. आम तौर पर, तुलना करने वाला टूल, पैरामीटर2 * kऔर2 * k + 1की तुलना एक-दूसरे से करता है. साथ ही, टाई ब्रेकर के तौर पर दूसरे पैरामीटर पेयर का इस्तेमाल कर सकता है.इसका नतीजा एक ट्यूपल होता है, जिसमें ऑपरेंड को क्रम से लगाया जाता है (जैसा कि ऊपर दिए गए डाइमेंशन के साथ). ट्यूपल का
i-thऑपरेंड, Sort फ़ंक्शन केi-thऑपरेंड से मेल खाता है.
उदाहरण के लिए, अगर तीन ऑपरेंड operand0 = [3, 1],
operand1 = [42, 50], operand2 = [-3.0, 1.1] हैं और तुलना करने वाला ऑपरेटर, कम-से-कम के साथ सिर्फ़ operand0 की वैल्यू की तुलना करता है, तो क्रम से लगाने का आउटपुट टुपल ([1, 3], [50, 42], [1.1, -3.0]) होगा.
अगर is_stable को 'सही' पर सेट किया जाता है, तो क्रम से लगाने की प्रोसेस स्थिर रहती है. इसका मतलब है कि अगर तुलना करने वाले टूल के हिसाब से कुछ एलिमेंट एक जैसे हैं, तो एक जैसी वैल्यू का क्रम नहीं बदलता. दो एलिमेंट e1 और e2 एक जैसे होंगे, सिर्फ़ तब जब comparator(e1, e2) = comparator(e2, e1) = false. डिफ़ॉल्ट रूप से, is_stable को 'गलत' पर सेट किया जाता है.
TopK
XlaBuilder::TopK भी देखें.
TopK, दिए गए टेंसर के आखिरी डाइमेंशन के लिए, k सबसे बड़े या सबसे छोटे एलिमेंट की वैल्यू और इंडेक्स ढूंढता है.
TopK(operand, k, largest)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
वह टेंसर जिससे k टॉप एलिमेंट निकालने हैं. टेंसर में एक या उससे ज़्यादा डाइमेंशन होने चाहिए. टेंसर के आखिरी डाइमेंशन का साइज़, k से ज़्यादा या उसके बराबर होना चाहिए. |
k |
int64 |
एक्सट्रैक्ट किए जाने वाले एलिमेंट की संख्या. |
largest |
bool |
सबसे बड़े या सबसे छोटे k एलिमेंट को निकालना है या नहीं. |
एक डाइमेंशन वाले इनपुट टेंसर (कलेक्शन) के लिए, कलेक्शन में k सबसे बड़ी या सबसे छोटी वैल्यू ढूंढता है. साथ ही, दो कलेक्शन (values, indices) का टुपल दिखाता है. इसलिए, values[j], operand में jवीं सबसे बड़ी/छोटी एंट्री है और इसका इंडेक्स indices[j] है.
एक से ज़्यादा डाइमेंशन वाले इनपुट टेंसर के लिए, आखिरी डाइमेंशन के साथ-साथ टॉप k एंट्री का हिसाब लगाता है. साथ ही, आउटपुट में अन्य सभी डाइमेंशन (लाइनें) को बनाए रखता है.
इसलिए, [A, B, ..., P, Q] आकार के ऑपरेंड के लिए, जहां Q >= k आउटपुट एक ट्यूपल (values, indices) है, जहां:
values.shape = indices.shape = [A, B, ..., P, k]
अगर किसी पंक्ति में दो एलिमेंट एक जैसे हैं, तो इंडेक्स में पहले आने वाला एलिमेंट पहले दिखता है.
ट्रांसपोज़ करना
tf.reshape ऑपरेशन भी देखें.
Transpose(operand)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
operand |
XlaOp |
ट्रांसपोज़ करने के लिए ऑपरेंड. |
permutation |
ArraySlice<int64> |
डाइमेंशन को बदलने का तरीका. |
ऑपरेंड डाइमेंशन को दिए गए क्रम में बदलता है, इसलिए
∀ i . 0 ≤ i < number of dimensions ⇒
input_dimensions[permutation[i]] = output_dimensions[i].
यह Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions)) के बराबर है.
TriangularSolve
XlaBuilder::TriangularSolve भी देखें.
फ़ॉरवर्ड या बैक-सबस्टिट्यूशन की मदद से, रैखिक समीकरणों की ऐसी प्रणाली हल करती है जिसमें नीचे या ऊपर की ओर त्रिकोणीय गुणांक वाली मैट्रिक्स होती हैं. लीडिंग डाइमेंशन के साथ ब्रॉडकास्ट करते हुए, यह रूटीन a और b के दिए गए वैरिएबल x के लिए, मैट्रिक्स सिस्टम op(a) * x =
b या x * op(a) = b में से किसी एक को हल करता है. यहां op(a), op(a) = a, op(a) = Transpose(a) या op(a) = Conj(Transpose(a)) हो सकता है.
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
a |
XlaOp |
[..., M, M] आकार वाला, कॉम्प्लेक्स या फ़्लोटिंग-पॉइंट टाइप का > 2 डाइमेंशन वाला ऐरे. |
b |
XlaOp |
अगर left_side सही है, तो [..., M, K] आकार वाला एक ही टाइप का > 2 डाइमेंशन वाला ऐरे, अन्यथा [..., K, M]. |
left_side |
bool |
यह बताता है कि op(a) * x = b (true) या x * op(a) = b (false) फ़ॉर्मैट में से किस सिस्टम को हल करना है. |
lower |
bool |
a के ऊपरी या निचले ट्रैंगल का इस्तेमाल करना है या नहीं. |
unit_diagonal |
bool |
अगर true है, तो a के डायगनल एलिमेंट को 1 माना जाता है और उन्हें ऐक्सेस नहीं किया जाता. |
transpose_a |
Transpose |
a को ऐसे ही इस्तेमाल करना है, ट्रांसपोज़ करना है या उसका कॉंजुगेट ट्रांसपोज़ लेना है. |
इनपुट डेटा को सिर्फ़ a के निचले/ऊपरी त्रिकोण से पढ़ा जाता है. यह lower की वैल्यू पर निर्भर करता है. दूसरे ट्राएंगल की वैल्यू को अनदेखा कर दिया जाता है. आउटपुट डेटा, उसी ट्राएंगल में दिखाया जाता है. दूसरे ट्राएंगल में मौजूद वैल्यू, लागू करने के तरीके के हिसाब से तय होती हैं और वे कुछ भी हो सकती हैं.
अगर a और b के डाइमेंशन की संख्या दो से ज़्यादा है, तो उन्हें मैट्रिक्स के बैच के तौर पर माना जाता है. इसमें दो छोटे डाइमेंशन को छोड़कर, सभी डाइमेंशन बैच डाइमेंशन होते हैं. a और b में बराबर बैच डाइमेंशन होने चाहिए.
टपल
XlaBuilder::Tuple भी देखें.
ऐसा ट्यूपल जिसमें अलग-अलग संख्या में डेटा हैंडल होते हैं. इनमें से हर एक का अपना आकार होता है.
यह C++ में std::tuple के बराबर है. कॉन्सेप्ट के हिसाब से:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
ट्यूपल को GetTupleElement ऑपरेशन की मदद से, अलग-अलग एलिमेंट में बांटा जा सकता है (ऐक्सेस किया जा सकता है).
हालांकि
XlaBuilder::While भी देखें.
While(condition, body, init)
| तर्क | टाइप | सिमैंटिक |
|---|---|---|
condition |
XlaComputation |
T -> PRED टाइप का XlaComputation, जो लूप के खत्म होने की शर्त तय करता है. |
body |
XlaComputation |
T -> T टाइप का XlaComputation, जो लूप के मुख्य हिस्से को तय करता है. |
init |
T |
condition और body पैरामीटर की शुरुआती वैल्यू. |
body को तब तक क्रम से लागू करता है, जब तक condition लागू नहीं हो जाता. यह कई अन्य भाषाओं में, सामान्य while लूप की तरह ही है. हालांकि, इसमें कुछ अंतर और पाबंदियां हैं, जिनके बारे में नीचे बताया गया है.
Whileनोड,Tटाइप की वैल्यू दिखाता है. यह वैल्यू,bodyके आखिरी एक्ज़ीक्यूशन का नतीजा होती है.Tटाइप का शेप, स्टैटिक तौर पर तय किया जाता है और यह सभी इटरेटेशन में एक जैसा होना चाहिए.
कैलकुलेशन के T पैरामीटर, पहले दोहराए जाने वाले चरण में init वैल्यू से शुरू किए जाते हैं. इसके बाद, हर दोहराए जाने वाले चरण में, ये पैरामीटर body से नए नतीजे पर अपने-आप अपडेट हो जाते हैं.
While नोड का इस्तेमाल मुख्य रूप से, न्यूरल नेटवर्क में ट्रेनिंग को बार-बार लागू करने के लिए किया जाता है. नीचे, कैलकुलेशन दिखाने वाले ग्राफ़ के साथ आसान बना हुआ स्यूडोकोड दिखाया गया है. कोड, while_test.cc में देखा जा सकता है.
इस उदाहरण में टाइप T एक Tuple है. इसमें, दो एलिमेंट होते हैं: एक, दोहराव की गिनती के लिए int32 और दूसरा, इकट्ठा करने वाले फ़ंक्शन के लिए vector[10]. 1,000 बार दोहराए जाने पर, लुूप एक कॉन्स्टेंट वेक्टर को इकट्ठा करने वाले फ़ंक्शन में जोड़ता रहता है.
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}