
我们的长期目标是将 Shardy 打造成一个完全独立的组件,能够与任何 MLIR 方言搭配使用。目前,Shardy 直接依赖于 StableHLO,但我们正在努力通过各种抽象和接口来提升这一点,以使 Shardy 更加灵活。
分片规则
分片规则用于编码我们如何通过操作进行传播。由于 Shardy 现在依赖于 StableHLO,因此它会为每个 stablehlo 操作定义分片规则。此外,Shardy 还提供了 ShardingRuleOpInterface,方言所有者可以在其操作中使用该函数为自己的操作定义分片规则。只要操作实现了此接口,Shardy 便可通过该接口进行传播。
def ShardingRuleOpInterface : OpInterface<"ShardingRuleOpInterface"> {
let methods = [
InterfaceMethod<
/*desc=*/[{
Returns the sharding rule of the op.
}],
/*retType=*/"mlir::sdy::OpShardingRuleAttr",
/*methodName=*/"getShardingRule"
>,
];
}
数据流操作
某些运算(例如基于区域的运算)需要采用不同的方法,仅描述所有运算数和结果之间的维度对应关系的分片规则是不够的。在这些情况下,Shardy 会定义 ShardableDataFlowOpInterface,以便方言所有者可以通过其操作描述分片的传播。此接口提供了一些方法,用于通过其所有者获取每个数据流边的来源和目标,以及获取和设置边所有者的分片。
def ShardableDataFlowOpInterface :
OpInterface<"ShardableDataFlowOpInterface"> {
(get|set)BlockArgumentEdgeOwnerShardings;
(get|set)OpResultEdgeOwnerShardings;
getBlockArgumentEdgeOwners;
getOpResultEdgeOwners;
getEdgeSources;
// ...
}
另请参阅数据流操作,简要了解我们如何处理数据流操作。
尚未实现的接口
未来,我们将添加更多接口和 trait,使 Shardy 更加灵活且不依赖于方言。我们在下方列出了这些问题。
常量拆分
MLIR 中的大多数张量程序都包含一个常量实例,该实例会被需要该值的任何操作重复使用。当所需的常量相同时,这种做法很有意义。不过,为了对程序进行最优的拆分,我们希望允许对常量的每次使用都有自己的拆分,并且不受其他操作对该常量的使用方式的影响。
例如,在下图中,如果 add 进行了分片,则不应影响 divide 和 subtract(在计算的不同部分)的分片方式。
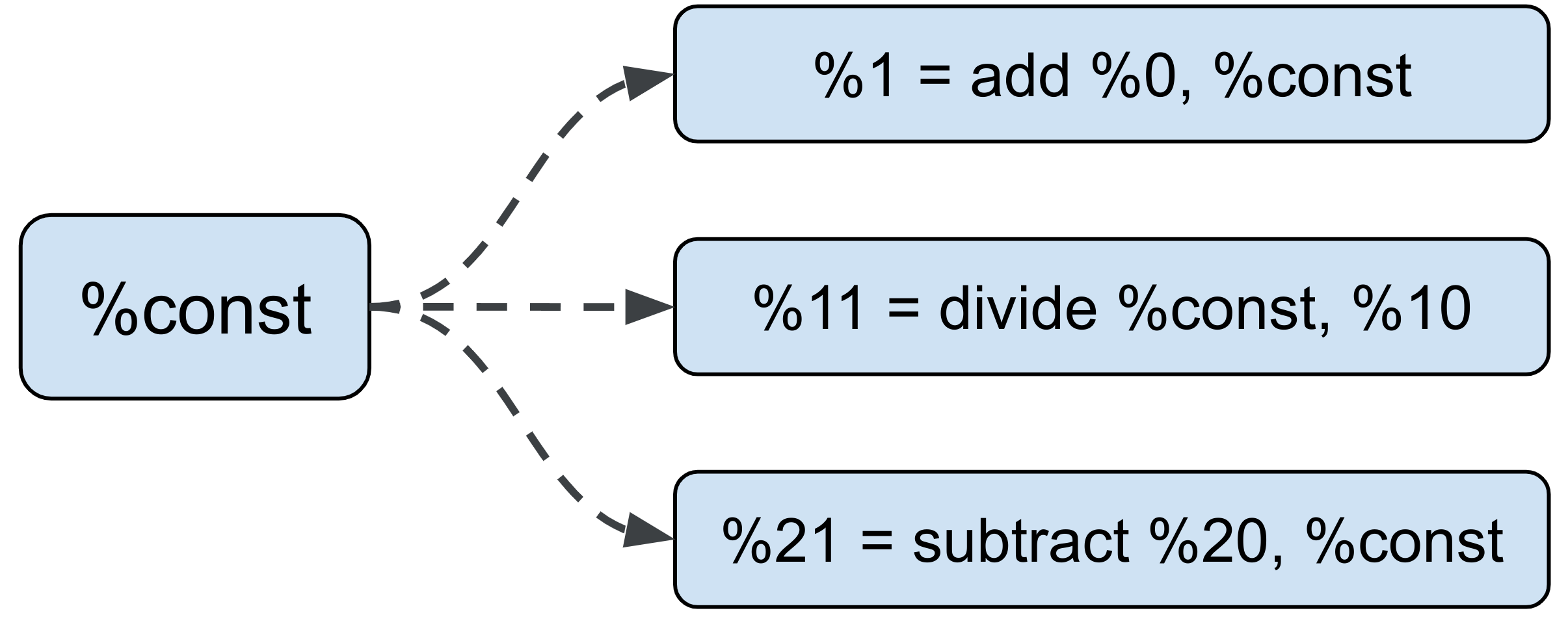
我们称之为虚假依赖项:由于常量开销很低,因此使用相同常量的运算之间没有真正的依赖项。因此,用户可以决定其常量(和类似常量)运算的分片方式。这样一来,对该常量的每次使用都可以采用不同的分片,这些分片可以独立传播到常量子计算的各个副本。
为此,Shardy 用户需要定义:- your_dialect.constant -> sdy.constant 传递;- sdy::ConstantLike trait,例如 iota;- 适用于 add 和 multiply 等元素级运算的 mlir::Elementwise trait;- 适用于 slice/broadcast 等运算的 sdy::ConstantFoldable。从技术层面上讲,如果所有运算数/结果都是常量,则可以在编译时计算这些运算。
操作优先级
在 GSPMD 中,首先传播按元素的运算,然后是 matmul 等运算。在 Shardy 中,我们希望允许用户设置自己的操作优先级,因为我们无法预先知道其方言。因此,我们会要求他们按希望 Shardy 传播操作的顺序传递操作列表。
下图展示了 GSPMD 中如何使用优先级以正确的顺序传播操作。
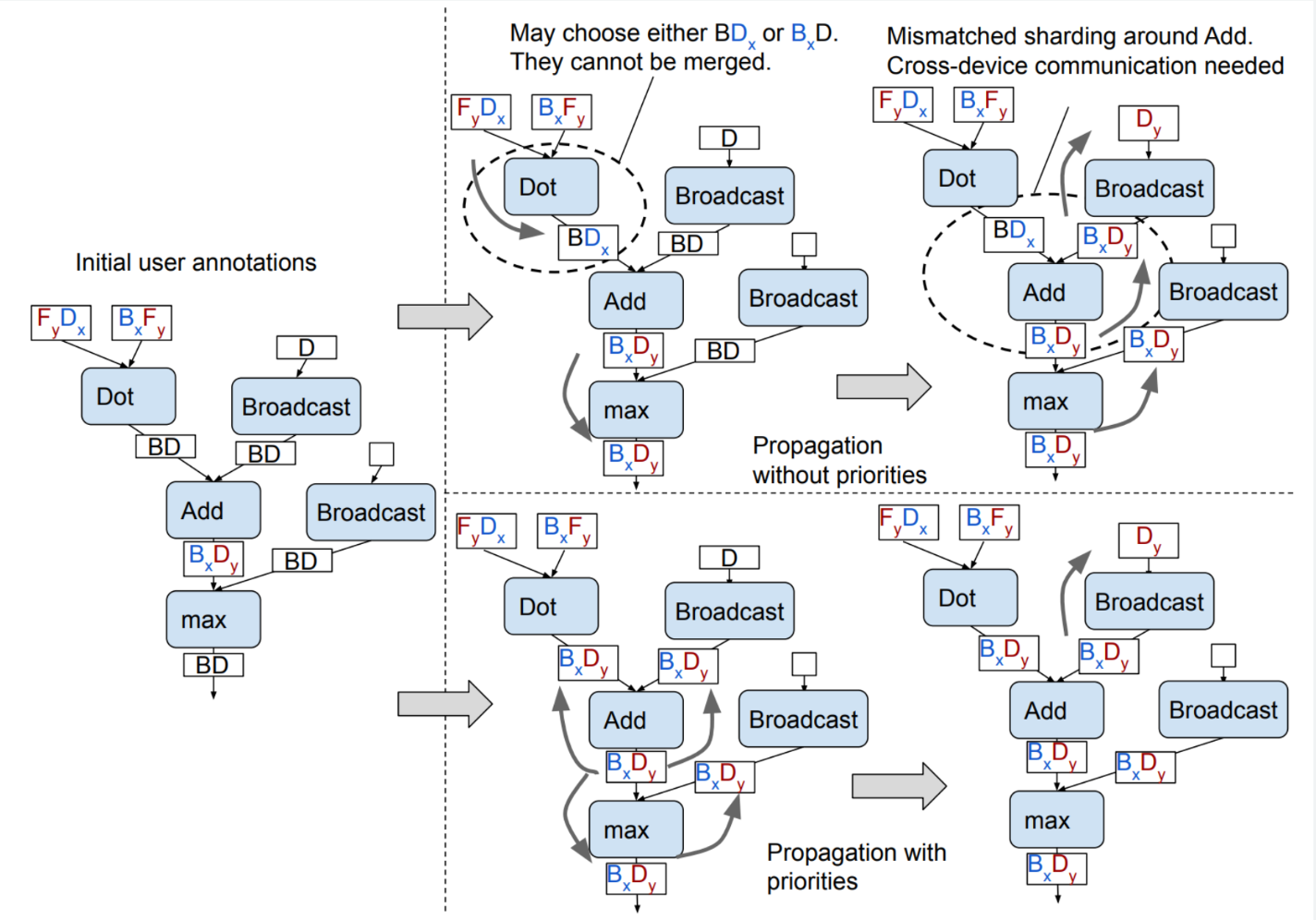
如需了解操作优先级的重要性,请参阅 GSPMD 论文。
与方言无关
只要您实现了之前的接口、trait 和传递,Shardy 便可用于您的方言。我们正在努力让 Shardy 变得更加灵活且不受方言影响,敬请期待后续动态。