
長期目標是讓 Shardy 成為完全獨立的元件,能夠與任何 MLIR 方言搭配使用。目前 Shardy 會直接依附 StableHLO,但我們正在透過各種抽象和介面,努力讓 Shardy 更具彈性。
分割規則
分割規則會編碼我們如何透過作業傳播。由於 Shardy 現已依附 StableHLO,因此會為每個 stablehlo 作業定義區隔規則。此外,Shardy 提供的 ShardingRuleOpInterface 可供方言擁有者在作業中使用,以便為各自的作業定義區隔規則。只要作業實作此介面,Shardy 就能透過此介面傳播。
def ShardingRuleOpInterface : OpInterface<"ShardingRuleOpInterface"> {
let methods = [
InterfaceMethod<
/*desc=*/[{
Returns the sharding rule of the op.
}],
/*retType=*/"mlir::sdy::OpShardingRuleAttr",
/*methodName=*/"getShardingRule"
>,
];
}
資料流作業
某些運算 (例如區域運算) 需要不同的方法,因為分割規則只會描述所有運算子和結果之間的維度對應關係,不足以處理這類運算。在這種情況下,Shardy 會定義 ShardableDataFlowOpInterface,讓方言擁有者可以透過其作業描述分割作業的傳播方式。這個介面提供方法,可透過擁有者取得每個資料流動邊緣的來源和目標,並取得及設定邊緣擁有者的分割作業。
def ShardableDataFlowOpInterface :
OpInterface<"ShardableDataFlowOpInterface"> {
(get|set)BlockArgumentEdgeOwnerShardings;
(get|set)OpResultEdgeOwnerShardings;
getBlockArgumentEdgeOwners;
getOpResultEdgeOwners;
getEdgeSources;
// ...
}
如要概略瞭解我們如何處理資料流作業,請參閱「資料流作業」。
尚未實作的介面
日後我們會新增更多介面和特徵,讓 Shardy 更具彈性且不受方言影響。以下列出這些項目。
常數分割
MLIR 中的大多數張量程式都會提供一個常數例項,而該例項會由需要該值的任何運算子重複使用。當所需常數相同時,這麼做就很合理。不過,為了讓程式達到最佳分割,我們希望每個常數的用途都能有各自的分割,且不會受到其他作業使用該常數的方式影響。
例如在下圖中,如果 add 已分割,則不應影響 divide 和 subtract (在運算的不同部分) 的分割方式。
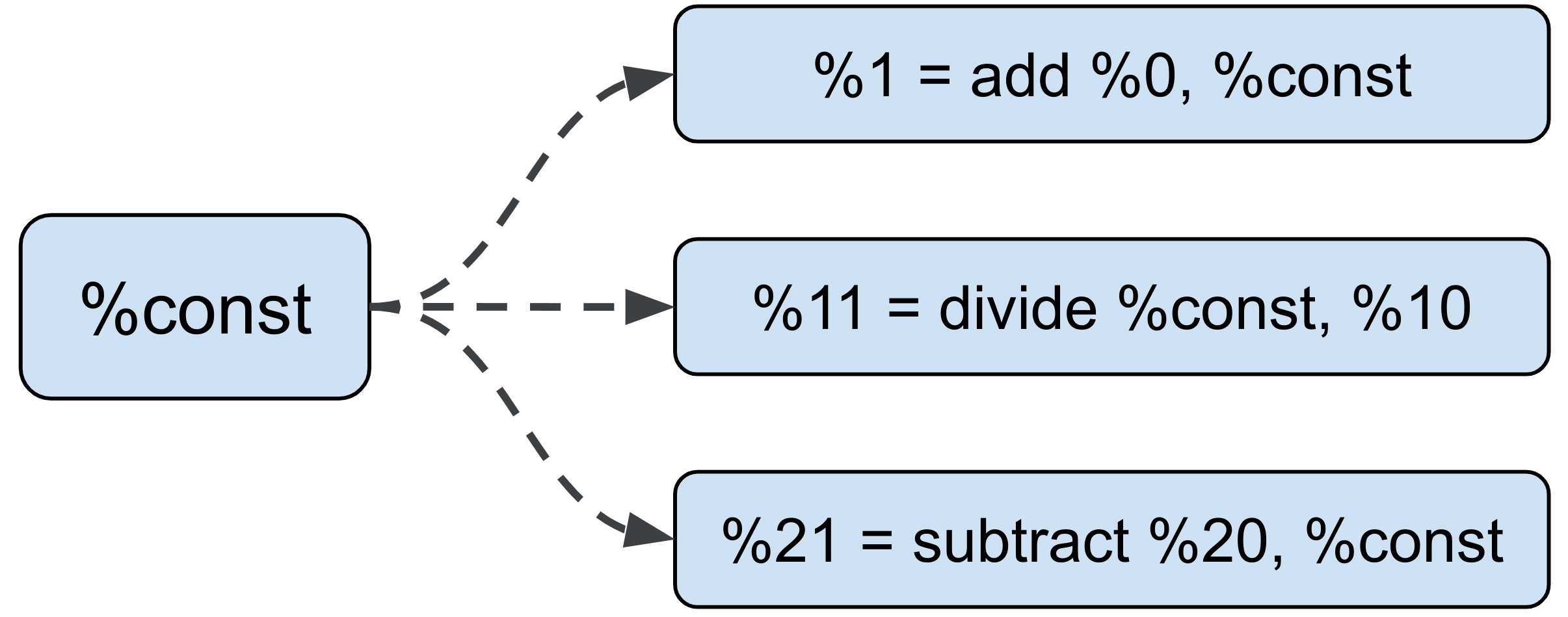
我們稱之為「錯誤的依附元件」:由於常數成本低廉,因此使用相同常數的運算作業之間並沒有真正的依附元件。因此,使用者可以決定要為常數 (和常數類似) 作業進行分割。每個常數的用途都會有不同的分割作業,可獨立傳播至常數子運算的副本。
為達成這項目標,Shardy 使用者需要定義以下項目:- your_dialect.constant -> sdy.constant 傳遞;- sdy::ConstantLike 特徵,例如 iota;- mlir::Elementwise 特徵,用於 add 和 multiply 等元素運算;- sdy::ConstantFoldable,用於 slice/broadcast 等運算。如果所有運算元/結果都是常數,這些運算作業在技術上可在編譯時計算。
作業優先順序
在 GSPMD 中,會先傳播元素運算,接著是 matmul 等運算。在 Shardy 中,我們希望允許使用者自行設定 op 優先順序,因為我們不瞭解其方言。因此,我們會要求他們依照希望 Shardy 傳播的順序,傳遞操作清單。
下圖顯示 GSPMD 如何使用優先順序,以正確的順序傳播作業。
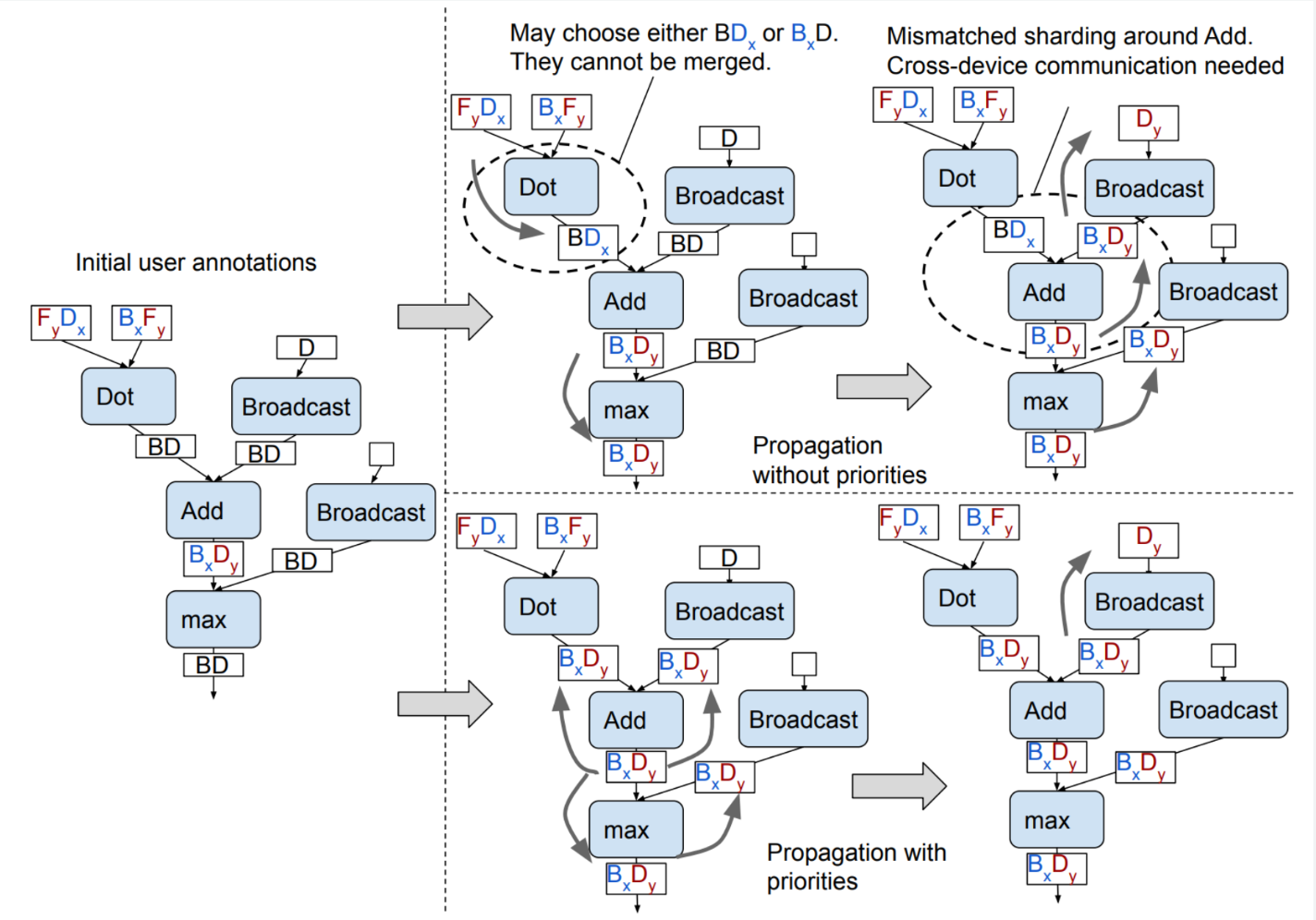
請參閱 GSPMD 論文,瞭解為何操作優先順序十分重要。
不受方言影響
只要您實作先前的介面、特徵和傳遞,Shardy 就能支援您的方言。我們正在努力讓 Shardy 更靈活且不受方言影響,敬請密切關注後續消息。