
背景
シャーディング表現の目的は、使用可能なデバイスのセットに応じてテンソルがシャーディングされる方法を指定することです。
シャーディング表現は次のいずれかです。
- 入力、出力、中間体に対するシャーディング制約としてユーザーが手動で指定します。
- シャーディング伝播プロセスでオペレーションごとに変換されます。
概要
基本構造
論理メッシュは、軸名とサイズのリストによって定義される、デバイスの多次元ビューです。
提案されているシャーディング表現は、名前で特定の論理メッシュにバインドされ、そのメッシュの軸名のみを参照できます。テンソルのシャーディングでは、テンソルの各ディメンションがシャーディングされる軸(特定の論理メッシュの軸)を、メジャーからマイナーまでの順序で指定します。テンソルは、メッシュの他のすべての軸に沿って複製されます。
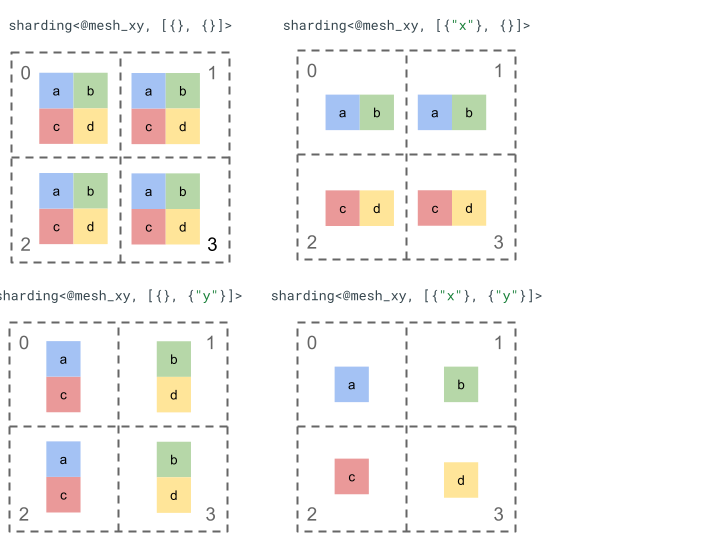
簡単なランク 2 テンソルと 4 つのデバイスを使用して、シャーディング表現について説明します。
まず、4 つのデバイス [0, 1, 2, 3] を 2 次元配列 [[0, 1], [2,
3]] に変更して、2 つの軸を持つメッシュを作成します。
@mesh_xy = <["x"=2, "y"=2]>
次のように、次のランク 2 テンソル [[a, b], [c, d]] をシャーディングできます。
その他の主要コンポーネント
- オープン/クローズ ディメンション - ディメンションはオープン(使用可能な軸でさらにシャーディング可能)またはクローズ(固定され、変更不可)のいずれかです。
- 明示的に複製される軸 - ディメンションのシャーディングに使用されていない軸はすべて暗黙的に複製されますが、シャーディングでは明示的に複製される軸を指定できます。この軸は、後でディメンションのシャーディングに使用できません。
- 軸の分割とサブ軸 - メッシュ軸(完全)は複数のサブ軸に分割できます。これらのサブ軸は、ディメンションのシャーディングに個別に使用したり、明示的に複製したりできます。
- 複数の論理メッシュ - 異なるシャーディングを異なる論理メッシュにバインドできます。論理メッシュには異なる軸や、論理デバイス ID の順序が異なる場合があります。
- 優先度 - プログラムを段階的にパーティショニングするには、ディメンション シャーディングに優先度を適用します。これにより、ディメンションごとのシャーディング制約がモジュール全体に伝播される順序を決定できます。
- ディメンション シャーディングによる分割 - サイズの積がディメンションのサイズで割り切れない軸でディメンションをシャーディングできます。
詳細な設計
このセクションでは、基本構造と各主要コンポーネントについて説明します。
基本構造
ディメンション シャーディングは、テンソルの各ディメンションについて、どの軸(またはサブ軸)に沿ってメジャーからマイナーにシャーディングされるかを示します。ディメンションをシャーディングしない他のすべての軸は、暗黙的に複製されます(または明示的に複製されます)。
簡単な例から始め、追加機能を説明しながら拡張していきます。
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st tensor dimension is sharded along axis "x" and the 2nd tensor dimension is
// sharded along axis "z" then further along axis "y". The local shape of this tensor (i.e. the shape on a single device), would be tensor<2x1xf32>.
sharding<@mesh_xy, [{"x"}, {"z", "y"}]> : tensor<4x8xf32>
不変量
- ディメンション シャーディングの数は、テンソルのランクと一致している必要があります。
- すべての軸名は、参照されるメッシュ内に存在する必要があります。
- 軸またはサブ軸は、シャーディング表現で 1 回だけ使用できます(各軸はディメンションをシャーディングするか、明示的に複製されます)。
オープン/クローズド ディメンション
テンソルの各ディメンションは、オープンまたはクローズドのいずれかです。
開く
オープン ディメンションは、追加の軸に沿ってさらにシャーディングするために伝播できます。つまり、指定されたディメンション シャーディングが、そのディメンションの最終的なシャーディングである必要はありません。これは GSPMD の unspecified_dims に似ていますが、まったく同じではありません。
ディメンションがオープンの場合は、ディメンションがすでにシャーディングされている軸の後に ? を追加します(下の例を参照)。
クローズ
クローズド ディメンションは、シャーディングをさらに追加するために伝播できないディメンションです。つまり、指定されたディメンション シャーディングがそのディメンションの最終的なシャーディングであり、変更できません。たとえば、GSPMD が通常、モジュールの入出力引数を変更しない、または jax.jit でユーザーが指定した in_shardings が静的である(変更できない)場合などです。
上記の例を拡張して、オープン ディメンションとクローズド ディメンションを作成できます。
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st dimension is closed, therefore it can't be further sharded and {"x"}
// will remain its sharding. The 2nd dimension is open, and can therefore be
// further sharded during propagation, e.g. by "y".
sharding<@mesh_xy, [{"x"}, {"z", ?}]> : tensor<4x8xf32>
明示的に複製された軸
テンソルが複製される明示的な軸のセット。軸でシャーディングされていないテンソルがその軸で暗黙的に複製されていると判断できます(現在の jax.sharding.PartitionSpec など)。明示的に指定することで、これらの軸を使用して、これらの軸でオープン ディメンションをさらにシャーディングできないようにします。暗黙のレプリケーションを使用すると、テンソルをさらに分割できます。ただし、明示的なレプリケーションでは、その軸に沿ってテンソルをパーティショニングすることはできません。
複製された軸の順序は、テンソルのデータの保存方法には影響しません。ただし、整合性を確保するため、軸は最上位メッシュで指定された順序で保存されます。たとえば、メッシュが次の場合:
@mesh_xy = <["c"=2, "a"=2, "b"=2]>
軸 "a" と "c" を明示的に複製する場合、順序は次のようになります。
replicated={"c", "a"}
上記の例を拡張して、明示的にレプリケートされた軸を作成できます。
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// Since "y" is explicitly replicated, it can't be used to shard the 2nd
// dimension that is open. However, "z" is implicitly replicated so it can be
// used to shard that dimension. The local shape of this tensor (i.e. the
// shape on a single device), would be tensor<2x8xf32>.
sharding<@mesh_xyz, [{"x"}, {?}], replicated={"y"}> : tensor<4x8xf32>
軸の分割とサブ軸
n 軸の論理メッシュは、デバイスの 1 次元配列を n 次元配列に再形成することで作成されます。各ディメンションは、ユーザー定義の名前を持つ軸を形成します。
コンパイラでも同じプロセスを実行して、サイズ k の軸をさらに m サブ軸に分割できます。この場合、メッシュを [...,k,...] から [...,k1,...,km,...] に変更します。
目的
軸を分割する理由を理解するために、次の例を見てみましょう。
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 : (tensor<8xf32>) -> tensor<2x4xf32>
通信を回避する方法(つまり、データをそのままにする)で、再構成の結果をシャーディングする必要があります。"x" のサイズは結果の 1 つ目のディメンションよりも大きいため、軸をサイズ 2 の 2 つのサブ軸 "x.0" と "x.1" に分割し、1 つ目のディメンションを "x.0" に、2 つ目のディメンションを "x.1" にシャーディングする必要があります。
関数の入出力シャーディング
伝播中に、メイン関数の入力または出力がサブ軸に沿ってシャーディングされる可能性があります。これは、このようなシャーディングを表現してユーザーに返すことができない場合、一部のフレームワークで問題になる可能性があります(JAX では、jax.sharding.NamedSharding でサブ軸を表現できません)。
このようなケースに対処するには、いくつかの方法があります。
- シャーディングを許可し、別の形式(JAX の
jax.sharding.NamedShardingではなくjax.sharding.PositionalShardingなど)で返します。 - 入力/出力をシャーディングするサブ軸を禁止し、オールギャザーします。
現在、伝播パイプラインの入力/出力にサブ軸を使用できます。無効にする方法をご希望の場合は、お知らせください。
表現
メッシュから特定の完全な軸を名前で参照するのと同じように、特定のサブ軸をサイズと、左側の(それらに属する)すべてのサブ軸(同じ軸名の)サイズの積で参照できます。
サイズ n の完全な軸 "x" からサイズ k の特定のサブ軸を抽出するには、(メッシュ内の)サイズ n を効果的に [m, k, n/(m*k)] に変更し、2 番目のディメンションをサブ軸として使用します。サブ軸は 2 つの数値(m と k)で指定できます。サブ軸は "x":(m)k という簡潔な表記で表します。
m>=1は、このサブ軸のプリサイズです(mはnの除数である必要があります)。プリサイズは、このサブ軸の左側(このサブ軸より大きい)のすべてのサブ軸サイズの積です(1 の場合、サブ軸が存在しないことを意味します。1 より大きい場合は、単一または複数のサブ軸に対応します)。k>1は、このサブ軸の実際のサイズです(kはnの除数にする必要があります)。n/(m*k)は投稿後のサイズです。このサブ軸の右側(サブ軸より小さい)にあるすべてのサブ軸のサイズの積です(1 の場合、サブ軸が存在しないことを意味します。1 より大きい場合は、1 つ以上のサブ軸に対応します)。
ただし、特定のサブ軸 "x":(m)k を使用する場合、他のサブ軸の数は関係ありません。また、ディメンションをシャーディングしていないか、明示的に複製されている場合、他のサブ軸をテンソル シャーディングで参照する必要はありません。
動機のセクションの例に戻ると、結果を次のようにシャーディングできます。
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 {sdy.sharding_per_value=<[<@mesh_x, [{"x":(1)2}, {"x":(2)2}]>]>}
: (tensor<8xf32>) -> tensor<2x4xf32>
以下に、サブ軸の一部のみが使用されている分割軸の例を示します。
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Axis "y" is effectively split into 3 sub-axes denoted as
// "y":(1)2, "y":(2)2, "y":(4)2
// in order, but only "y":(2)2 is used, to shard the 2nd dimension. The local
// shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x4xf32>.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}]> : tensor<4x8xf32>
同様に、次の 2 つのシャーディングは意味的に同等です。mesh_xy は mesh_full の分割と考えることができます。
@mesh_full = <"devices"=8>
@mesh_xy = <"x"=4, "y"=2>
sharding<@mesh_xy, [{"x"},{ "y"}]> : tensor<4x4xf32>
sharding<@mesh_full, [{"devices":(1)4}, {"devices":(4)2}]> : tensor<4x4xf32>
明示的に複製されたサブ軸
サブ軸は、ディメンションのシャーディングに使用されるだけでなく、明示的に複製されているものとしてマークすることもできます。サブ軸は完全な軸と同じように動作するため、この表現で許可されています。つまり、軸 "x" のサブ軸に沿ってディメンションをシャーディングすると、"x" の他のサブ軸が暗黙的に複製されます。したがって、サブ軸が複製されたままでディメンションのシャーディングに使用できないことを示すために、明示的に複製できます。
次に例を示します。
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Sub-axis "y":(1)2 is explicitly replicated and "y":(4)2 is implicitly replicated.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}], replicated={"y":(1)2}> : tensor<4x8xf32>
同じ完全軸の複製サブ軸は、事前サイズの昇順で並べ替える必要があります。次に例を示します。
replicated={"y":(4)2, "x", "y":(1)2} ~> replicated={"x", "y":(1)2, "y":(4)2}
不変量
テンソル シャーディングで参照されるサブ軸は重複してはなりません(例:
"x":(1)4と"x":(2)4が重複している)。テンソル シャーディングで参照されるサブ軸は、できるだけ大きくする必要があります。つまり、ディメンション シャーディングに 2 つの隣接するサブ軸 A と B が順番に含まれている場合、またはサブ軸 A と B が明示的に複製されている場合は、連続してはいけません(
"x":(1)2と"x":(2)4など)。これは、単一の"x":(1)8に置き換えることができるためです。
複数の論理メッシュ
1 つの論理メッシュは、デバイスの多次元ビューです。特に任意のデバイス割り当ての場合は、シャーディングを表すためにデバイスの複数のビューが必要になることがあります。
たとえば、jax.sharding.PositionalSharding には 1 つの共通の論理メッシュがありません。GSPMD は現在、HloSharding でこれをサポートしています。この場合、デバイスとディメンション サイズの順序付きリストで表すことができますが、これは上記の軸分割では表せません。
この制限を克服し、既存の特殊なケースを処理するには、プログラムの最上位レベルで複数の論理メッシュを定義します。各メッシュには、異なる名前の異なる数の軸を設定できます。また、同じデバイスセットに独自の任意の割り当てを設定することもできます。つまり、各メッシュは(一意の論理 ID で)同じデバイスセットを参照しますが、GSPMD 表現と同様に任意の順序で参照します。
各シャーディング表現は特定の論理メッシュにリンクされているため、そのメッシュの軸のみを参照します。
1 つの論理メッシュに割り当てられたテンソルは、宛先メッシュに合わせてテンソルを単純に再シャーディングすることで、別のメッシュに割り当てられたオペレーションで使用できます。GSPMD では、通常、競合するメッシュを解決するためにこれが行われます。
ユーザーは、デバイスの順序が同じで、名前の異なる軸を持つ複数のメッシュを指定できます(例: jax.sharding.NamedSharding を使用)。次の例では、<@mesh_0, "b"> は <@mesh_1, "z"> と同じです。
@mesh_0 = {<["a"=4, "b"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
@mesh_1 = {<["x"=2, "y"=2, "z"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
優先事項
優先度は、特定のパーティショニングと伝播の決定を他の決定よりも優先する方法であり、プログラムの増分パーティショニングを可能にします。
優先度は、シャーディング表現の一部のディメンションまたはすべてのディメンションに適用される値です(レプリケートされた軸には優先度がありません)。
次に例を示します。
@mesh_xy = <["w"=6, "x"=2, "y"=4, "z"=2]>
// |-> y is implicitly p0
%arg4 : sharding<@mesh_xy, [{"x"}p1, {"y"}, {"z",?}p2], replicated={} }>
優先度を使用すると、伝播をよりきめ細かく制御できます。たとえば、最初にバッチ並列処理、次に megatron、最後に ZeRO シャーディングを実行できます。これにより、パーティショニングされる内容について強力な保証が可能になり、よりきめ細かいシャーディング戦略によってデバッグしやすくなります(メガトロンのみを分離した後のプログラムの状態を確認できます)。
各ディメンション シャーディングに優先度を割り当てることができます(デフォルトは 0)。優先度 <i のシャーディングは、優先度 i のシャーディングよりも先にプログラム全体に伝播されます。
シャーディングに優先度の低いオープン ディメンション({"z",?}p2: 伝播中に優先度の高い別のテンソル シャーディングによってオーバーライドされることはありません。ただし、このようなオープン ディメンションは、優先度の高いシャーディングがすべて伝播された後に、さらにシャーディングできます。
つまり、優先順位は、どのディメンション シャーディングが他よりも重要であるかに関するものNOT。これは、ディメンション シャーディングをプログラム全体に伝播する個別のグループの順序と、アノテーションのない中間テンソル上の競合を解決する方法です。
不変量
優先度は 0(最高優先度)から始まり、順に増加します(ユーザーが優先度を簡単に追加、削除できるように、優先度の間にギャップがあってもかまいません。たとえば、p0 と p2 は使用しても、p1 は使用しないなど)。
空の閉じたディメンション シャーディング(
{})には優先度を設定しないでください。優先度を設定しても効果はありません。
ディメンション シャーディングによる分割
サイズが d のディメンションは、サイズの積が n の軸に沿ってシャーディングできます。この場合、d は n で割り切れません(実際には、ディメンションにパディングが必要になります)。
次に例を示します。
@mesh_xy = <["x"=8, "y"=2, "z"=3]>
sharding<@mesh_xy, [{"x"}, {"y"}, {"z"}]> : tensor<7x3x8xf32>
文法
各論理メッシュは次のように定義されます。
@mesh_name = <mesh_axis_1,...,mesh_axis_n>
mesh_axis ::= axis_name=axis_size
axis_name ::= str
axis_size ::= int
ランク r のテンサーの場合、シャーディング表現の構造は次のようになります。
sharding<@mesh_name, dim_shardings, replicated=replicated_axes}
mesh_name ::= str
dim_shardings ::= [dim_sharding_1,...,dim_sharding_r]
replicated_axes ::= {axis_1,...,axis_m}
dim_sharding ::=
{axis_1,...,axis_k} | // closed dimension
{axis_1,...,axis_k,?} // open dimension
axis ::=
axis_name | // a full axis
sub_axis // a sub axis
axis_name ::= str
sub_axis ::= axis_name:(pre_size)size
pre_size ::= int
size ::= int