
XLA:GPU-তে HLO-এর জন্য কোড তৈরি করার তিনটি উপায় রয়েছে।
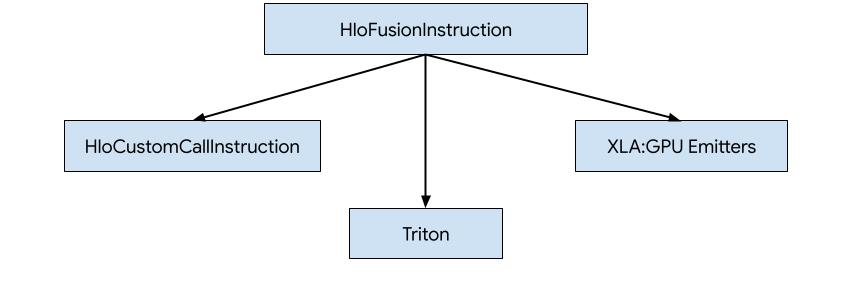
- HLO-কে বাহ্যিক লাইব্রেরি, যেমন NVidia cuBLAS , cuDNN- এর কাস্টম কল দ্বারা প্রতিস্থাপন করা।
- HLO-কে ব্লক-স্তরে টাইলিং করা এবং তারপর OpenAI Triton ব্যবহার করা।
- XLA এমিটার ব্যবহার করে HLO থেকে LLVM IR-এ ক্রমান্বয়ে হ্রাস করা।
এই নথিটি XLA:GPU Emitters-এর উপর আলোকপাত করে।
হিরো-ভিত্তিক কোডজেন
XLA:GPU-তে ৭ ধরনের এমিটার রয়েছে। প্রতিটি এমিটার টাইপ ফিউশনের একটি "হিরো"-র সাথে সম্পর্কিত, অর্থাৎ ফিউজড কম্পিউটেশনের সবচেয়ে গুরুত্বপূর্ণ অপারেশন যা পুরো ফিউশনের জন্য কোড জেনারেশনকে রূপ দেয়।
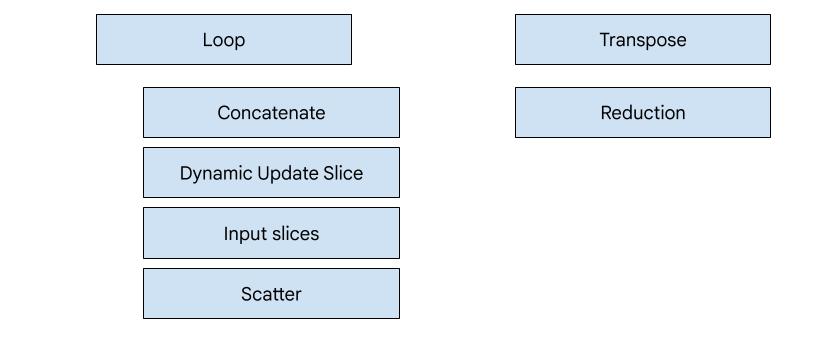
উদাহরণস্বরূপ, ফিউশনের মধ্যে যদি এমন কোনো HloTransposeInstruction থাকে যার মেমরি রিডিং এবং রাইটিং প্যাটার্ন উন্নত করার জন্য শেয়ার্ড মেমরি ব্যবহারের প্রয়োজন হয়, তাহলে ট্রান্সপোজ এমিটারটি নির্বাচিত হবে। রিডাকশন এমিটার শাফেল এবং শেয়ার্ড মেমরি ব্যবহার করে রিডাকশন তৈরি করে। লুপ এমিটার হলো ডিফল্ট এমিটার। যদি কোনো ফিউশনের এমন কোনো হিরো না থাকে যার জন্য আমাদের কোনো বিশেষ এমিটার আছে, তাহলে লুপ এমিটারটি ব্যবহৃত হবে।
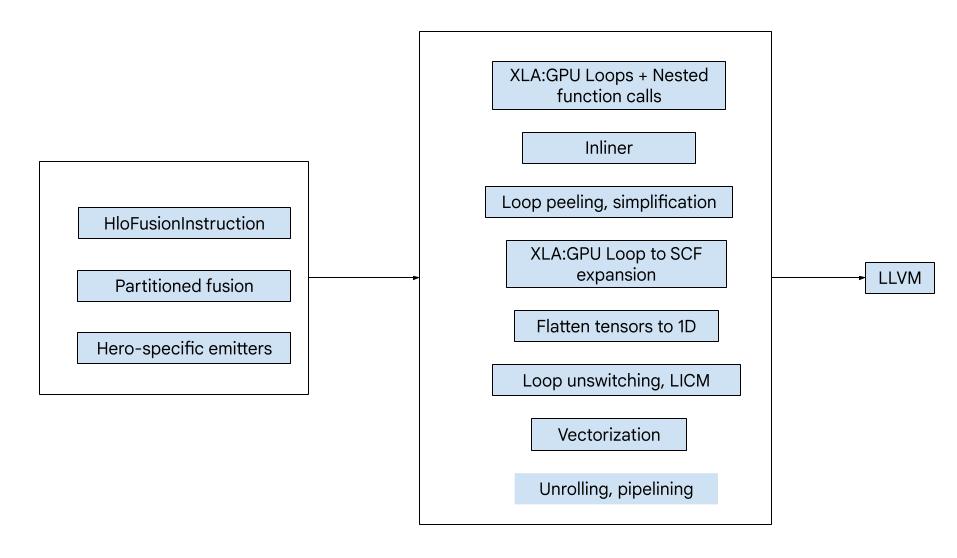
উচ্চ-স্তরের সংক্ষিপ্ত বিবরণ
কোডটি নিম্নলিখিত প্রধান উপাদানগুলো নিয়ে গঠিত:
- কম্পিউটেশন পার্টিশনার - একটি HLO ফিউশন কম্পিউটেশনকে ফাংশনে বিভক্ত করা
- এমিটার - পার্টিশন করা HLO ফিউশনকে MLIR-এ রূপান্তর করা (
xla_gpu,tensor,arith,math,scfডায়ালেক্ট) - কম্পাইলেশন পাইপলাইন - LLVM-এর জন্য IR অপ্টিমাইজ করে এবং কমিয়ে আনে
বিভাজন
computation_partitioner.h দেখুন।
নন-এলিমেন্টওয়াইজ HLO নির্দেশাবলী সবসময় একসাথে নির্গত করা যায় না। নিম্নলিখিত HLO গ্রাফটি বিবেচনা করুন:
param
|
log
| \
| transpose
| /
add
যদি আমরা এটিকে একটিমাত্র ফাংশনে নির্গত করি, তাহলে add এর প্রতিটি উপাদানের জন্য log দুটি ভিন্ন ইন্ডেক্স থেকে অ্যাক্সেস করা হবে। পুরোনো এমিটারগুলো log টি দুইবার তৈরি করে এই সমস্যার সমাধান করে। এই নির্দিষ্ট গ্রাফটির জন্য এটি কোনো সমস্যা নয়, কিন্তু যখন একাধিক স্প্লিট থাকে, তখন কোডের আকার দ্রুতগতিতে বাড়তে থাকে।
এখানে, আমরা গ্রাফটিকে এমন অংশে বিভক্ত করে এই সমস্যার সমাধান করি যা একটি ফাংশন হিসাবে নিরাপদে নির্গত করা যায়। শর্তগুলো হলো:
- যেসব নির্দেশাবলীর কেবল একজন ব্যবহারকারী থাকে, সেগুলো সেই ব্যবহারকারীর সাথেই নিরাপদে প্রেরণ করা যায়।
- যেসব নির্দেশাবলীর একাধিক ব্যবহারকারী রয়েছে, সেগুলো তাদের ব্যবহারকারীসহ নিরাপদে প্রেরণ করা যায়, যদি সকল ব্যবহারকারী একই ইনডেক্সের মাধ্যমে সেগুলো অ্যাক্সেস করে।
উপরের উদাহরণে, add এবং tranpose log এর ভিন্ন ভিন্ন ইন্ডেক্স অ্যাক্সেস করে, তাই এগুলোর সাথে একসাথে এটি এমিট করা নিরাপদ নয়।
সুতরাং গ্রাফটিকে তিনটি ফাংশনে বিভক্ত করা হয় (যার প্রতিটিতে কেবল একটি নির্দেশনা থাকে)।
add এর slice এবং pad সংক্রান্ত নিম্নলিখিত উদাহরণটির ক্ষেত্রেও একই কথা প্রযোজ্য।
মৌলিক নির্গমন
elemental_hlo_to_mlir.h দেখুন।
এলিমেন্টাল এমিশন HloInstructions জন্য লুপ এবং গাণিতিক/পাটিগণিতিক অপারেশন তৈরি করে। বেশিরভাগ ক্ষেত্রে, এটি বেশ সহজবোধ্য, কিন্তু এখানে কিছু আকর্ষণীয় বিষয় ঘটে থাকে।
সূচীকরণ রূপান্তর
কিছু নির্দেশাবলী ( transpose , broadcast , reshape , slice , reverse এবং আরও কয়েকটি) হলো নিছক ইনডেক্সের রূপান্তর: ফলাফলের একটি উপাদান তৈরি করতে, আমাদের ইনপুটের অন্য কোনো উপাদান তৈরি করতে হয়। এর জন্য, আমরা XLA-এর indexing_analysis পুনরায় ব্যবহার করতে পারি, যেটিতে একটি নির্দেশাবলীর জন্য আউটপুট থেকে ইনপুট ম্যাপিং তৈরি করার ফাংশন রয়েছে।
উদাহরণস্বরূপ, [20,40] থেকে [40,20] -তে transpose , এটি নিম্নলিখিত ইনডেক্সিং ম্যাপ তৈরি করবে (প্রতিটি ইনপুট ডাইমেনশনের জন্য একটি করে সিম্বলিক এক্সপ্রেশন; d0 এবং d1 হলো আউটপুট ডাইমেনশন):
(d0, d1) -> d1
(d0, d1) -> d0
সুতরাং এই বিশুদ্ধ সূচক রূপান্তর নির্দেশাবলীর জন্য, আমরা কেবল ম্যাপটি পেতে পারি, এটিকে আউটপুট সূচকগুলিতে প্রয়োগ করতে পারি এবং ফলস্বরূপ সূচকে ইনপুটটি তৈরি করতে পারি।
একইভাবে, pad op-টি তার বাস্তবায়নের বেশিরভাগ ক্ষেত্রে ইনডেক্সিং ম্যাপ এবং কনস্ট্রেইন্ট ব্যবহার করে। pad ও একটি ইনডেক্সিং ট্রান্সফরমেশন, তবে এতে কিছু অতিরিক্ত চেক যুক্ত করা হয় এটা দেখার জন্য যে আমরা ইনপুটের কোনো এলিমেন্ট রিটার্ন করছি নাকি প্যাডিং ভ্যালুটি।
টাপলস
আমরা অভ্যন্তরীণ tuple সমর্থন করি না। আমরা নেস্টেড টাপল আউটপুটও সমর্থন করি না। যে সমস্ত XLA গ্রাফ এই বৈশিষ্ট্যগুলি ব্যবহার করে, সেগুলিকে এমন গ্রাফে রূপান্তর করা যেতে পারে যেগুলি এই বৈশিষ্ট্যগুলি ব্যবহার করে না।
সংগ্রহ করুন
আমরা শুধুমাত্র gather_simplifier দ্বারা উৎপাদিত ক্যানোনিকাল গ্যাদার সমর্থন করি।
সাবগ্রাফ ফাংশন
%p0 থেকে %p_n প্যারামিটারযুক্ত কোনো গণনার সাবগ্রাফ এবং r মাত্রা ও e0 থেকে e_m উপাদান প্রকারের সাবগ্রাফ রুটের জন্য, আমরা নিম্নলিখিত MLIR ফাংশন সিগনেচার ব্যবহার করি:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
অর্থাৎ, আমাদের প্রতিটি গণনা প্যারামিটারের জন্য একটি টেনসর ইনপুট, আউটপুটের প্রতিটি ডাইমেনশনের জন্য একটি ইনডেক্স ইনপুট এবং প্রতিটি আউটপুটের জন্য একটি ফলাফল রয়েছে।
একটি ফাংশন এমিট করার জন্য, আমরা কেবল উপরের এলিমেন্টাল এমিটারটি ব্যবহার করি এবং সাবগ্রাফের প্রান্তে না পৌঁছানো পর্যন্ত এর অপারেন্ডগুলো রিকার্সিভলি এমিট করতে থাকি। তারপর, আমরা প্যারামিটারগুলোর জন্য একটি tensor.extract অথবা অন্যান্য সাবগ্রাফের জন্য একটি func.call এমিট করি।
এন্ট্রি ফাংশন
প্রতিটি এমিটার টাইপ তার এন্ট্রি ফাংশন, অর্থাৎ হিরোর জন্য ফাংশনটি, কীভাবে তৈরি করে, তার উপর নির্ভর করে ভিন্ন হয়। এন্ট্রি ফাংশনটি উপরের ফাংশনগুলো থেকে আলাদা, কারণ এর ইনপুট হিসেবে কোনো ইনডেক্স থাকে না (শুধু থ্রেড এবং ব্লক আইডি থাকে) এবং এর আউটপুটটি কোথাও লেখার প্রয়োজন হয়। লুপ এমিটারের জন্য এই বিষয়টি বেশ সহজবোধ্য, কিন্তু ট্রান্সপোজ এবং রিডাকশন এমিটারগুলোর রাইট লজিক বেশ জটিল।
এন্ট্রি গণনার স্বাক্ষরটি হলো:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
আগের মতোই, %pn গুলো হলো গণনার প্যারামিটার এবং %rn গুলো হলো গণনার ফলাফল। `computation` এন্ট্রিটি ফলাফলগুলোকে টেনসর হিসেবে গ্রহণ করে, tensor.insert কমান্ডের মাধ্যমে সেগুলোকে আপডেট করে এবং তারপর সেগুলো রিটার্ন করে। আউটপুট টেনসরগুলোর অন্য কোনো ব্যবহার অনুমোদিত নয়।
সংকলন পাইপলাইন
লুপ এমিটার
loop.h দেখুন।
চলুন, GELU ফাংশনের জন্য HLO ব্যবহার করে MLIR কম্পাইলেশন পাইপলাইনের সবচেয়ে গুরুত্বপূর্ণ ধাপগুলো অধ্যয়ন করি।
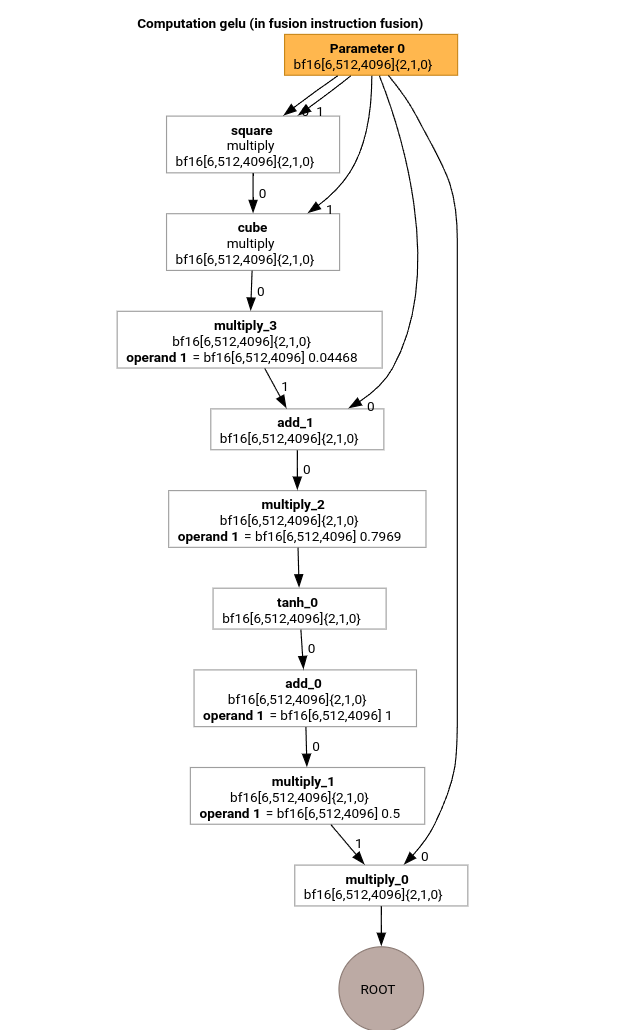
এই HLO কম্পিউটেশনে শুধুমাত্র এলিমেন্টওয়াইজ অপস, কনস্ট্যান্ট এবং ব্রডকাস্ট রয়েছে। এটি লুপ এমিটার ব্যবহার করে নির্গত হবে।
এমএলআইআর রূপান্তর
MLIR-এ রূপান্তরের পর আমরা একটি xla_gpu.loop পাই, যা %thread_id_x এবং %block_id_x উপর নির্ভরশীল এবং এমন একটি লুপকে সংজ্ঞায়িত করে যা একত্রিত রাইট নিশ্চিত করার জন্য আউটপুটের সমস্ত উপাদানকে রৈখিকভাবে অতিক্রম করে।
এই লুপের প্রতিটি পুনরাবৃত্তিতে আমরা কল করি
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
রুট অপারেশনের উপাদানগুলো গণনা করার জন্য। উল্লেখ্য যে, @gelu এর জন্য আমাদের কেবল একটিই বর্ণিত ফাংশন রয়েছে, কারণ পার্টিশনার এমন কোনো টেনসর শনাক্ত করতে পারেনি যার দুই বা ততোধিক বিভিন্ন অ্যাক্সেস প্যাটার্ন রয়েছে।
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
ইনলাইনার
@gelu ইনলাইন করার পর, আমরা একটিমাত্র @main ফাংশন পাই। এমন হতে পারে যে একই ফাংশন দুই বা ততোধিকবার কল করা হয়েছে। এই ক্ষেত্রে আমরা ইনলাইন করি না। ইনলাইনিং নিয়মাবলী সম্পর্কে আরও বিস্তারিত তথ্য xla_gpu_dialect.cc- তে পাওয়া যাবে।
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu থেকে scf রূপান্তর
lower_xla_gpu_to_scf.cc দেখুন।
xla_gpu.loop হলো একটি লুপ নেস্ট, যার ভেতরে একটি বাউন্ডারি চেক থাকে। যদি লুপের ইন্ডাকশন ভেরিয়েবলগুলো ইনডেক্সিং ম্যাপ ডোমেইনের সীমার বাইরে চলে যায়, তাহলে এই ইটারেশনটি বাদ দেওয়া হয়। এর মানে হলো, লুপটি ভেতরে একটি scf.if সহ এক বা একাধিক নেস্টেড scf.for অপস-এ রূপান্তরিত হয়।
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
টেনসর সমতল করুন
flatten_tensors.cc দেখুন।
এনডি টেনসরগুলোকে ১ডি-তে প্রজেক্ট করা হয়। এটি ভেক্টরাইজেশন এবং এলএলভিএম-এ রূপান্তরকে সহজ করবে, কারণ এখন প্রতিটি টেনসর অ্যাক্সেস মেমরিতে ডেটার বিন্যাসের সাথে সঙ্গতিপূর্ণ হয়।
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
ভেক্টরাইজেশন
vectorize_loads_stores.cc দেখুন।
এই ধাপটি tensor.extract এবং tensor.insert অপারেশনগুলোর মধ্যে থাকা ইনডেক্সগুলো বিশ্লেষণ করে এবং যদি সেগুলো xla_gpu.apply_indexing দ্বারা উৎপাদিত হয়, যা %vector_index সাপেক্ষে উপাদানগুলোকে অবিচ্ছিন্নভাবে অ্যাক্সেস করে এবং অ্যাক্সেসটি অ্যালাইনড হয়, তাহলে tensor.extract vector.transfer_read এ রূপান্তরিত করে লুপের বাইরে হোইস্ট করা হয়।
এই নির্দিষ্ট ক্ষেত্রে, একটি ইনডেক্সিং ম্যাপ (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) ব্যবহৃত হয়, যা একটি scf.for লুপের মধ্যে ০ থেকে ৪ পর্যন্ত এক্সট্র্যাক্ট এবং ইনসার্ট করার জন্য এলিমেন্টগুলো গণনা করে। সুতরাং, tensor.extract এবং tensor.insert উভয়কেই ভেক্টরাইজ করা যায়।
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
লুপ আনরোলিং
optimize_loops.cc দেখুন।
লুপ আনরোলিং scf.for লুপগুলো খুঁজে বের করে যেগুলো আনরোল করা যায়। এক্ষেত্রে, ভেক্টরের উপাদানগুলোর ওপর থাকা লুপটি অদৃশ্য হয়ে যায়।
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
এলএলভিএম-এ রূপান্তর
আমরা বেশিরভাগ ক্ষেত্রে স্ট্যান্ডার্ড LLVM লোয়ারিং ব্যবহার করি, তবে কয়েকটি বিশেষ পাসও রয়েছে। আমরা টেনসরের জন্য memref লোয়ারিং ব্যবহার করতে পারি না, কারণ আমরা IR বাফারাইজ করি না এবং আমাদের ABI, memref ABI-এর সাথে সামঞ্জস্যপূর্ণ নয়। এর পরিবর্তে, আমাদের টেনসর থেকে সরাসরি LLVM এ যাওয়ার জন্য একটি কাস্টম লোয়ারিং রয়েছে।
- টেনসর লোয়ারিং-এর কাজটি lower_tensors.cc ফাইলে করা হয়। স্বাভাবিকভাবেই,
tensor.extractকেllvm.loadএ এবংtensor.insertকেllvm.storeএ লোয়ার করা হয়। - propagate_slice_indices এবং merge_pointers_to_same_slice একসাথে বাফার অ্যাসাইনমেন্ট এবং XLA-এর ABI-এর একটি বিশেষ দিক বাস্তবায়ন করে: যদি দুটি টেনসর একই বাফার স্লাইস শেয়ার করে, তবে সেগুলোকে কেবল একবারই পাস করা হয়। এই পাসগুলো ফাংশন আর্গুমেন্টগুলোর পুনরাবৃত্তি রোধ করে।
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
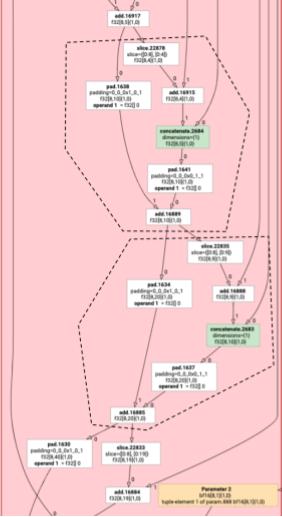
ট্রান্সপোজ এমিটার
চলুন আরেকটু জটিল একটি উদাহরণ বিবেচনা করা যাক।
![]()
এন্ট্রি ফাংশনটি কীভাবে তৈরি করা হয়, শুধু সেই দিক থেকেই ট্রান্সপোজ এমিটার এবং লুপ এমিটারের মধ্যে পার্থক্য।
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
এক্ষেত্রে, আমরা দুটি xla_gpu.loop অপস তৈরি করি। প্রথমটি ইনপুট থেকে কোয়েলেসড রিড সম্পাদন করে এবং ফলাফলটি শেয়ার্ড মেমরিতে লেখে।
xla_gpu.allocate_shared op ব্যবহার করে শেয়ার্ড মেমরি টেনসরটি তৈরি করা হয়।
xla_gpu.sync_threads ব্যবহার করে থ্রেডগুলো সিঙ্ক্রোনাইজ করার পর, দ্বিতীয় xla_gpu.loop শেয়ার্ড মেমরি টেনসর থেকে উপাদানগুলো পড়ে এবং আউটপুটে কোয়েলেসড রাইট সম্পাদন করে।
পুনরুৎপাদনকারী
কম্পাইলেশন পাইপলাইনের প্রতিটি ধাপের পরে আইআর (IR) দেখার জন্য, --xla_dump_emitter_re=mlir-fusion ফ্ল্যাগটি সহ run_hlo_module চালু করা যেতে পারে।
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
যেখানে /tmp/gelu.hlo তে রয়েছে
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
কোডের লিঙ্ক
- কম্পাইলেশন পাইপলাইন: emitter_base.h
- অপ্টিমাইজেশন এবং রূপান্তর পর্যায়: ব্যাকএন্ড/জিপিইউ/কোডজেন/এমিটার/ট্রান্সফর্ম
- পার্টিশন লজিক: computation_partitioner.h
- হিরো-ভিত্তিক এমিটার: ব্যাকএন্ড/জিপিইউ/কোডজেন/এমিটার
- XLA:GPU ops: xla_gpu_ops.td
- সঠিকতা এবং লিট পরীক্ষা: ব্যাকএন্ড/জিপিইউ/কোডজেন/এমিটার/পরীক্ষা