
HLO ইনডেক্সিং অ্যানালাইসিস হলো এক ধরনের ডেটাফ্লো বিশ্লেষণ যা "ইনডেক্সিং ম্যাপ"-এর মাধ্যমে বর্ণনা করে, কীভাবে একটি টেনসরের উপাদানগুলো অন্যটির সাথে সম্পর্কিত। উদাহরণস্বরূপ, একটি HLO ইন্সট্রাকশনের আউটপুটের ইনডেক্সগুলো কীভাবে HLO ইন্সট্রাকশনের অপারেন্ডগুলোর ইনডেক্সের সাথে ম্যাপ করে।
উদাহরণ
tensor<20xf32> থেকে tensor<10x20x30xf32> এ একটি সম্প্রচারের জন্য
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
আউটপুট থেকে ইনপুটে ইন্ডেক্সিং ম্যাপটি হলো (i, j, k) -> (j) যেখানে i in [0, 10] , j in [0, 20] এবং k in [0, 30] ।
অনুপ্রেরণা
XLA কোয়েলেসিং, অপারেন্ড ইউটিলাইজেশন এবং টাইলিং স্কিম সম্পর্কে যুক্তি প্রদানের জন্য বেশ কিছু বিশেষায়িত সমাধান ব্যবহার করে (নিচে আরও বিস্তারিত)। ইনডেক্সিং অ্যানালাইসিসের লক্ষ্য হলো এই ধরনের ব্যবহারের ক্ষেত্রগুলোর জন্য একটি পুনঃব্যবহারযোগ্য কম্পোনেন্ট প্রদান করা। ইনডেক্সিং অ্যানালাইসিস XLA-এর নিজস্ব SymbolicExpr এবং SymbolicMap পরিকাঠামোর উপর নির্মিত এবং এতে HLO সিম্যান্টিকস যুক্ত করা হয়েছে।
একত্রিত হওয়া
গুরুত্বপূর্ণ ক্ষেত্রগুলির জন্য মেমরি কোয়েলেসিং সম্পর্কে যুক্তি প্রদান করা সম্ভব হয়, যখন আমরা জানি যে আউটপুটের একটি উপাদান গণনা করার জন্য ইনপুটগুলির কোন উপাদান বা অংশগুলি পড়া হয়।
অপারেন্ড ব্যবহার
XLA-তে অপারেন্ড ইউটিলাইজেশন নির্দেশ করে যে, কোনো ইন্সট্রাকশনের আউটপুট সম্পূর্ণরূপে ব্যবহৃত হয়েছে ধরে নিয়ে তার প্রতিটি ইনপুট কী পরিমাণে ব্যবহৃত হয়েছে। বর্তমানে, একটি জেনেরিক ক্ষেত্রের জন্য ইউটিলাইজেশন গণনা করা হয় না। ইনডেক্সিং অ্যানালাইসিস আমাদের নির্ভুলভাবে ইউটিলাইজেশন গণনা করার সুযোগ দেয়।
টাইলস
একটি টাইল/স্লাইস হলো একটি টেনসরের হাইপার-রেক্ট্যাঙ্গুলার সাবসেট যা অফসেট, সাইজ এবং স্ট্রাইড দ্বারা প্যারামিটারাইজড। টাইল প্রোপাগেশন হলো কোনো অপ-এর নিজস্ব টাইলিং প্যারামিটার ব্যবহার করে তার প্রডিউসার/কনজিউমারের টাইল প্যারামিটার গণনা করার একটি উপায়। সফটম্যাক্স এবং ডট-এর জন্য এই কাজটি করার একটি লাইব্রেরি ইতিমধ্যেই রয়েছে। টাইল প্রোপাগেশনকে ইনডেক্সিং ম্যাপের মাধ্যমে প্রকাশ করা হলে এটিকে আরও জেনেরিক এবং শক্তিশালী করা যেতে পারে।
সূচীকরণ মানচিত্র
একটি ইনডেক্সিং ম্যাপ হলো একটি সংমিশ্রণ
- একটি প্রতীকীভাবে প্রকাশিত ফাংশন যা একটি টেনসর
Aএর প্রতিটি উপাদানকে টেনসরBএর উপাদানগুলোর পরিসরে ম্যাপ করে; - বৈধ ফাংশন আর্গুমেন্টের উপর সীমাবদ্ধতা, যার মধ্যে ফাংশনের ডোমেনও অন্তর্ভুক্ত।
ফাংশন আর্গুমেন্টগুলোর প্রকৃতি আরও ভালোভাবে বোঝানোর জন্য সেগুলোকে ৩টি শ্রেণীতে ভাগ করা হয়েছে:
টেনসর
Aবা যে GPU গ্রিড থেকে আমরা ম্যাপিং করছি, তার ডাইমেনশন ভেরিয়েবল; এগুলোর মান স্থিরভাবে জানা থাকে। ইনডেক্স এলিমেন্টগুলোকেও ডাইমেনশন ভেরিয়েবল বলা হয়।রেঞ্জ ভেরিয়েবল। এগুলি একটি এক-থেকে-অনেক ম্যাপিং সংজ্ঞায়িত করে এবং
Aএর একটি একক মান গণনা করতে ব্যবহৃতBএর উপাদানগুলির একটি সেট নির্দিষ্ট করে; মানগুলি স্থিরভাবে জানা থাকে। একটি ম্যাট্রিক্স গুণনের সংকোচনশীল মাত্রা হলো রেঞ্জ ভেরিয়েবলের একটি উদাহরণ।রানটাইম ভেরিয়েবল যা শুধুমাত্র এক্সিকিউশনের সময় জানা যায়। উদাহরণস্বরূপ, গ্যাদার অপারেশনের ইনডেক্স আর্গুমেন্ট।
ফাংশনের ফলাফল হলো টার্গেট B টেনসরের একটি সূচক।
সংক্ষেপে, x অপারেশনের জন্য টেনসর A থেকে টেনসর B তে একটি ইন্ডেক্সিং ফাংশন হলো
map_ab(index in A, range variables, runtime variables) -> index in B .
ম্যাপিং আর্গুমেন্টগুলোর প্রকারভেদ আরও ভালোভাবে আলাদা করার জন্য আমরা সেগুলোকে এভাবে লিখি:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
উদাহরণস্বরূপ, f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3} এই reduce অপারেশনের জন্য ইন্ডেক্সিং ম্যাপগুলো দেখা যাক:
inউপাদানগুলোকেoutম্যাপ করার জন্য আমাদের ফাংশনটিকে(d0, d1, d2, d3) -> (d1, d2)আকারে প্রকাশ করা যায়।d0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]—এই চলকগুলোর সীমাবদ্ধতাinআকৃতি দ্বারা সংজ্ঞায়িত করা হয়।outউপাদানগুলোকেinম্যাপ করার জন্য:outকেবল দুটি ডাইমেনশন আছে, এবং রিডাকশন দুটি রেঞ্জ ভ্যারিয়েবল যোগ করে যা রিডিউসিং ডাইমেনশনগুলোকে অন্তর্ভুক্ত করে। সুতরাং ম্যাপিং ফাংশনটি হলো(d0, d1)[s0, s1] -> (s0, d0, d1, s1), যেখানে(d0, d1)হলোoutইন্ডেক্স।s0,s1হলো অপারেশনের সেম্যান্টিকস দ্বারা সংজ্ঞায়িত রেঞ্জ এবং এগুলোinটেনসরের ডাইমেনশন ০ এবং ৩ জুড়ে থাকে। সীমাবদ্ধতাগুলো হলোd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15]।
এটা মনে রাখা গুরুত্বপূর্ণ যে বেশিরভাগ ক্ষেত্রে আমরা আউটপুটের উপাদানগুলো থেকে ম্যাপিং করতে আগ্রহী। গণনার জন্য
C = op1(A, B)
E = op2(C, D)
আমরা "B-এর সূচীকরণ" বলতে " E এর উপাদানগুলোকে B এর উপাদানগুলোতে ম্যাপ করা" বোঝাতে পারি। ইনপুট থেকে আউটপুটের দিকে কাজ করে এমন অন্যান্য ধরনের ডেটা-ফ্লো বিশ্লেষণের তুলনায় এটি কিছুটা স্বজ্ঞাবিরোধী মনে হতে পারে।
ভেরিয়েবলের উপর সীমাবদ্ধতা অপটিমাইজেশনের সুযোগ তৈরি করে এবং কোড জেনারেশনে সাহায্য করে। ডকুমেন্টেশন এবং ইমপ্লিমেন্টেশনে সীমাবদ্ধতাকে ডোমেইন হিসেবেও উল্লেখ করা হয়, কারণ এটি ম্যাপিং ফাংশনের সমস্ত বৈধ সংমিশ্রণ বা আর্গুমেন্ট মান নির্ধারণ করে। অনেক অপারেশনের জন্য, সীমাবদ্ধতা কেবল টেনসরের মাত্রা বর্ণনা করে, কিন্তু কিছু অপারেশনের জন্য তা আরও জটিল হতে পারে; নিচের উদাহরণগুলো দেখুন।
ফাংশন এবং আর্গুমেন্টের সীমাবদ্ধতাগুলোকে প্রতীকীভাবে প্রকাশ করে এবং ফাংশন ও সীমাবদ্ধতাগুলোকে একত্রিত করতে পারার মাধ্যমে আমরা যেকোনো বৃহৎ গণনার (ফিউশন) জন্য একটি সংক্ষিপ্ত ইনডেক্সিং ম্যাপিং নির্ণয় করতে পারি।
প্রতীকী ফাংশন এবং সীমাবদ্ধতার প্রকাশক্ষমতা হলো বাস্তবায়ন জটিলতা এবং আরও সুনির্দিষ্ট উপস্থাপনা থেকে প্রাপ্ত অপ্টিমাইজেশন সুবিধার মধ্যে একটি ভারসাম্য। কিছু HLO অপারেশনের ক্ষেত্রে আমরা অ্যাক্সেস প্যাটার্নগুলো কেবল আনুমানিকভাবেই ধারণ করতে পারি।
বাস্তবায়ন
পুনঃগণনা কমানোর জন্য, আমাদের সাংকেতিক গণনার একটি কাঠামো প্রয়োজন। এটি SymbolicExpr এবং SymbolicMap হিসেবে বাস্তবায়িত হয়।
একটি সাধারণ SymbolicMap দেখতে এইরকম:
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
SymbolicMap দুই ধরনের প্যারামিটার রয়েছে: ডাইমেনশন এবং সিম্বল । ডাইমেনশনগুলো d নামক ডাইমেনশন ভ্যারিয়েবলের সাথে সম্পর্কিত; সিম্বলগুলো r নামক রেঞ্জ ভ্যারিয়েবল এবং rt নামক রানটাইম ভ্যারিয়েবলের সাথে সম্পর্কিত। SymbolicMap প্যারামিটারগুলোর সীমাবদ্ধতা সম্পর্কিত কোনো মেটাডেটা থাকে না, তাই আমাদের সেগুলো আলাদাভাবে সরবরাহ করতে হয়।
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
// struct Interval represents a closed interval [lower_bound, upper_bound].
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
SymbolicMap symbolic_map_;
// A dimension variable represents a dimension of a tensor or a GPU grid.
// Dimension variables correspond to the dimensions of the `symbolic_map_`.
std::vector<Variable> dim_vars_;
// A range variable represents a range of values, e.g. to compute a single
// element of the reduction's result we need a range of values from the input
// tensor. Range variables correspond to the front portion of the
// symbols in `symbolic_map_`.
std::vector<Variable> range_vars_;
// A runtime variable represents a runtime symbol, e.g. a dynamic offset in of
// a HLO dynamic-update-slice op. Runtime variables correspond to the back
// portion of the symbols in `symbolic_map_`.
std::vector<Variable> rt_vars_;
// Inequality constraints for symbolic expressions. They restrict the feasible
// set for the domain of the indexing map. It contains symbolic expressions
// other than SymbolicDimExpr and SymbolicSymbolExpr.
llvm::MapVector<SymbolicExpr, Interval> constraints_;
};
কোড রেফারেন্স: indexing_map.h#L114
dim_vars_ ইনডেক্সিং ম্যাপের ডাইমেনশন ভ্যারিয়েবল d- এর জন্য ইনক্লুসিভ বক্স কনস্ট্রেইন্টগুলোকে এনকোড করে, যা সাধারণত transpose, reduce, elementwise, dot-এর মতো অপারেশনগুলোর ক্ষেত্রে আউটপুট টেনসরের আকারের সাথে মিলে যায়, কিন্তু HloConcatenateInstruction-এর মতো কিছু ব্যতিক্রমও আছে।
range_vars_ হলো রেঞ্জ ভেরিয়েবলগুলোর সমস্ত মান। যখন আমরা যে টেনসর থেকে ম্যাপিং করছি তার একটিমাত্র উপাদান গণনা করার জন্য একাধিক মানের প্রয়োজন হয়, তখন রেঞ্জ ভেরিয়েবলগুলোর দরকার পড়ে; যেমন, রিডাকশনের আউটপুট->ইনপুট ইনডেক্সিং ম্যাপের জন্য অথবা ব্রডকাস্টের ইনপুট->আউটপুট ম্যাপের জন্য।
rt_vars_ রানটাইমে সম্ভাব্য মানগুলোকে এনকোড করে। উদাহরণস্বরূপ, একটি 1D HloDynamicSliceInstruction এর জন্য অফসেটটি ডাইনামিক হয়। সংশ্লিষ্ট RTVar সম্ভাব্য মানগুলো 0 এবং tensor_size - slice_size - 1 এর মধ্যে থাকবে।
constraints_ মানগুলির মধ্যে সম্পর্ককে <expression> in <range> আকারে প্রকাশ করে, যেমন d0 + s0 in [0, 20] । এটি Variable.bounds সাথে মিলে ইনডেক্সিং ফাংশনের "ডোমেইন" নির্ধারণ করে।
উপরের সবকিছুর প্রকৃত অর্থ কী, তা বোঝার জন্য চলুন উদাহরণের মাধ্যমে বিষয়টি অধ্যয়ন করি।
অসংযুক্ত অপস-এর জন্য সূচীকরণ মানচিত্র
উপাদান অনুসারে
এলিমেন্টওয়াইজ অপারেশনের ক্ষেত্রে ইনডেক্সিং ম্যাপটি একটি আইডেন্টিটি।
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
ইনপুট ম্যাপ output -> p0 :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
ইনপুট থেকে আউটপুট ম্যাপ p0 -> output :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
সম্প্রচার
ব্রডকাস্টিং মানে হলো, যখন আমরা আউটপুটকে ইনপুটে ম্যাপ করি তখন কিছু ডাইমেনশন বাদ দেওয়া হবে এবং যখন আমরা ইনপুটকে আউটপুটে ম্যাপ করি তখন কিছু ডাইমেনশন যোগ করা হবে।
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
ইনপুট ম্যাপে আউটপুট:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
ইনপুট থেকে আউটপুট ম্যাপ:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
লক্ষ্য করুন, এখন ইনপুট-টু-আউটপুট ম্যাপিংয়ের জন্য ডানদিকে আমাদের রেঞ্জ ভ্যারিয়েবল s আছে। এই প্রতীকগুলো মানের পরিসরকে বোঝায়। উদাহরণস্বরূপ, এই নির্দিষ্ট ক্ষেত্রে, d0 ইনডেক্সযুক্ত ইনপুটের প্রতিটি উপাদানকে আউটপুটের একটি 10x1x30 স্লাইসে ম্যাপ করা হয়েছে।
আইওটা
Iota-র কোনো ইনপুট টেনসর অপারেন্ড নেই, তাই এর কোনো ইনপুট ইনডেক্স আর্গুমেন্টও নেই।
iota = f32[2,4] iota(), dimensions={1}
ইনপুট ম্যাপে আউটপুট:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
ইনপুট থেকে আউটপুট ম্যাপ:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
ডাইনামিকস্লাইস
DynamicSlice-এর অফসেটগুলো শুধুমাত্র রানটাইমেই জানা যায়।
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
ds থেকে src তে আউটপুট ও ইনপুটের ম্যাপ:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
লক্ষ্য করুন, এখন ইনপুট-টু-আউটপুট ম্যাপিংয়ের জন্য ডানদিকে rt রয়েছে। এই প্রতীকগুলো রানটাইম ভ্যালু নির্দেশ করে। উদাহরণস্বরূপ, এই নির্দিষ্ট ক্ষেত্রে d0, d1, d2 ইন্ডেক্সযুক্ত আউটপুটের প্রতিটি উপাদানের জন্য আমরা ইনপুটের ইন্ডেক্স গণনা করতে of1 , of2 এবং of3 এর স্লাইস অফসেট অ্যাক্সেস করি। রানটাইম ভেরিয়েবলগুলোর ব্যবধিগুলো এই অনুমানের ভিত্তিতে নির্ধারণ করা হয় যে, সম্পূর্ণ স্লাইসটি সীমার মধ্যে থাকে।
of1 , of2 এবং of3 এর জন্য ইনপুট ম্যাপের আউটপুট:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
ডাইনামিকআপডেটস্লাইস
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
src এর জন্য আউটপুট থেকে ইনপুট ম্যাপ তৈরি করা খুবই সহজ। ডোমেইনকে আপডেট না হওয়া ইনডেক্সগুলোর মধ্যে সীমাবদ্ধ করে এটিকে আরও সুনির্দিষ্ট করা যেতে পারে, কিন্তু বর্তমানে ইনডেক্সিং ম্যাপগুলো অসমতা সীমাবদ্ধতা সমর্থন করে না।
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
upd জন্য আউটপুট থেকে ইনপুট ম্যাপ:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
লক্ষ্য করুন, এখন আমাদের কাছে rt0 এবং rt1 আছে যা রানটাইম মান নির্দেশ করে। এই নির্দিষ্ট ক্ষেত্রে d0, d1 সূচকবিশিষ্ট আউটপুটের প্রতিটি উপাদানের জন্য আমরা ইনপুটের সূচক গণনা করতে of1 এবং of2 স্লাইস অফসেট ব্যবহার করি। রানটাইম ভেরিয়েবলগুলোর ব্যবধি এই অনুমানের ভিত্তিতে নির্ণয় করা হয় যে সম্পূর্ণ স্লাইসটি সীমার মধ্যে থাকে।
of1 এবং of2 জন্য ইনপুট ম্যাপের আউটপুট:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
সংগ্রহ করুন
শুধুমাত্র সরলীকৃত gather সমর্থিত। gather_simplifier.h দেখুন।
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
operand জন্য আউটপুট থেকে ইনপুট ম্যাপ:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
লক্ষ্য করুন যে এখন আমাদের কাছে rt প্রতীক রয়েছে যা রানটাইম মান উপস্থাপন করে।
indices জন্য আউটপুট থেকে ইনপুট ম্যাপ:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
রেঞ্জ ভ্যারিয়েবল s0 নির্দেশ করে যে, আউটপুটের কোনো একটি উপাদান গণনা করার জন্য আমাদের indices টেনসরের সম্পূর্ণ সারি (d0, *) প্রয়োজন।
স্থান পরিবর্তন করুন
ট্রান্সপোজের জন্য ইনডেক্সিং ম্যাপ হলো ইনপুট/আউটপুট ডাইমেনশনগুলোর একটি বিন্যাস।
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
ইনপুট ম্যাপে আউটপুট:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
ইনপুট থেকে আউটপুট ম্যাপ:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
বিপরীত
বিপরীতকরণের জন্য ইনডেক্সিং ম্যাপ বিপরীত মাত্রাগুলিকে upper_bound(d_i) - d_i তে পরিবর্তন করে:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
ইনপুট ম্যাপে আউটপুট:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
ইনপুট থেকে আউটপুট ম্যাপ:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(ভেরিয়াডিক) হ্রাস
ভ্যারিয়েডিক রিডাকশনের একাধিক ইনপুট এবং একাধিক প্রাথমিক মান থাকে, আউটপুট থেকে ইনপুটে ম্যাপিংটি হ্রাসকৃত মাত্রাগুলো যোগ করে।
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
ইনপুট ম্যাপগুলিতে আউটপুট:
-
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
ইনপুট থেকে আউটপুট ম্যাপ:
-
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
স্লাইস
স্লাইসের ক্ষেত্রে আউটপুট থেকে ইনপুটে ইন্ডেক্সিং করার ফলে একটি স্ট্রাইডেড ইন্ডেক্সিং ম্যাপ তৈরি হয়, যা আউটপুটের প্রতিটি উপাদানের জন্য বৈধ। ইনপুট থেকে আউটপুটে ম্যাপিং ইনপুটের উপাদানগুলোর একটি স্ট্রাইডেড পরিসরের মধ্যে সীমাবদ্ধ থাকে।
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
ইনপুট ম্যাপে আউটপুট:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
ইনপুট থেকে আউটপুট ম্যাপ:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
পুনর্গঠন
নতুন আকার বিভিন্ন ধরনের হয়ে থাকে।
ভেঙে পড়া আকৃতি
এটি এনডি থেকে ১ডি-তে একটি 'লিনিয়ারাইজিং' রিশেপ।
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
ইনপুট ম্যাপে আউটপুট:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
ইনপুট থেকে আউটপুট ম্যাপ:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
আকৃতি প্রসারিত করুন
এটি একটি বিপরীত 'কোল্যাপ্স শেপ' অপারেশন, যা একটি ১ডি ইনপুটকে এনডি আউটপুটে রূপান্তরিত করে।
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
ইনপুট ম্যাপে আউটপুট:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
ইনপুট থেকে আউটপুট ম্যাপ:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
জেনেরিক পুনর্গঠন
এগুলো হলো সেইসব রিশেপ অপারেশন, যেগুলোকে একটিমাত্র এক্সপ্যান্ড বা কলাপস শেপ হিসেবে উপস্থাপন করা যায় না। এগুলোকে শুধুমাত্র ২ বা ততোধিক এক্সপ্যান্ড বা কলাপস শেপের সমন্বয়েই উপস্থাপন করা যায়।
উদাহরণ ১: রৈখিকীকরণ-অরৈখিকীকরণ।
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
এই পুনর্গঠনটিকে tensor<4x8xf32> আকৃতিকে সংকুচিত করে tensor<32xf32> পরিণত করা এবং তারপর আকৃতিকে প্রসারিত করে tensor<2x4x4xf32> পরিণত করার সংমিশ্রণ হিসেবে উপস্থাপন করা যেতে পারে।
ইনপুট ম্যাপে আউটপুট:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
ইনপুট থেকে আউটপুট ম্যাপ:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
উদাহরণ ২: প্রসারিত এবং সংকুচিত উপ-আকৃতি
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
এই রিশেপটিকে দুটি রিশেপের সংমিশ্রণ হিসেবে উপস্থাপন করা যেতে পারে। প্রথমটি সর্ববহিঃস্থ মাত্রা tensor<4x8x12xf32> কে সংকুচিত করে tensor<32x12xf32> এ পরিণত করে এবং দ্বিতীয়টি সর্বঅন্তঃস্থ মাত্রা tensor<32x12xf32> কে প্রসারিত করে tensor<32x3x4xf32> এ পরিণত করে।
ইনপুট ম্যাপে আউটপুট:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
ইনপুট থেকে আউটপুট ম্যাপ:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
বিটকাস্ট
একটি বিটকাস্ট অপকে ট্রান্সপোজ-রিশেপ-ট্রান্সপোজ এর একটি অনুক্রম হিসেবে উপস্থাপন করা যায়। সুতরাং, এর ইন্ডেক্সিং ম্যাপগুলো হলো এই অনুক্রমের ইন্ডেক্সিং ম্যাপগুলোর একটি সংমিশ্রণ মাত্র।
সংযুক্ত করুন
concat-এর জন্য আউটপুট-টু-ইনপুট ম্যাপিং সমস্ত ইনপুটের জন্য সংজ্ঞায়িত করা হয়েছে, তবে ডোমেইনগুলো ওভারল্যাপ করবে না, অর্থাৎ একবারে শুধুমাত্র একটি ইনপুট ব্যবহৃত হবে।
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
আউটপুট থেকে ইনপুট ম্যাপ:
-
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
আউটপুট ম্যাপের ইনপুটগুলো:
-
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
বিন্দু
ডট-এর জন্য ইন্ডেক্সিং ম্যাপগুলো রিডিউস-এর ইন্ডেক্সিং ম্যাপগুলোর সাথে খুবই সাদৃশ্যপূর্ণ।
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
আউটপুট থেকে ইনপুট ম্যাপ:
- আউটপুট -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- আউটপুট -> পি১:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
আউটপুট ম্যাপের ইনপুটগুলো:
- p0 -> আউটপুট:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> আউটপুট:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
প্যাড
PadOp-এর ইন্ডেক্সিং হলো SliceOp-এর ইন্ডেক্সিং-এর বিপরীত।
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
প্যাডিং কনফিগারেশন 1_4_1x4_8_0 lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1 বোঝানো হয়।
ইনপুট ম্যাপগুলিতে আউটপুট:
- আউটপুট -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- আউটপুট -> পি১:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
রিডিউসউইন্ডো
XLA-এর ReduceWindow প্যাডিংও সম্পাদন করে। সুতরাং, ইনডেক্সিং ম্যাপগুলো এমন ReduceWindow ইনডেক্সিং (যা কোনো প্যাডিং করে না) এবং PadOp-এর ইনডেক্সিং-এর সংমিশ্রণ হিসেবে গণনা করা যেতে পারে।
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
ইনপুট ম্যাপগুলিতে আউটপুট:
-
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
ফিউশনের জন্য সূচীকরণ মানচিত্র
ফিউশন অপ-এর জন্য ইনডেক্সিং ম্যাপ হলো ক্লাস্টারের প্রতিটি অপ-এর ইনডেক্সিং ম্যাপগুলোর একটি সংমিশ্রণ। এমনটা হতে পারে যে কিছু ইনপুট বিভিন্ন অ্যাক্সেস প্যাটার্ন ব্যবহার করে একাধিকবার পড়া হয়।
একটি ইনপুট, একাধিক ইনডেক্সিং ম্যাপ
এখানে p0 + transpose(p0) এর একটি উদাহরণ দেওয়া হলো।
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
p0 এর জন্য আউটপুট-থেকে-ইনপুট ইন্ডেক্সিং ম্যাপ হবে (d0, d1) -> (d0, d1) এবং (d0, d1) -> (d1, d0) । এর মানে হলো, আউটপুটের একটি উপাদান গণনা করার জন্য আমাদের ইনপুট প্যারামিটারটি দুইবার পড়ার প্রয়োজন হতে পারে।
একটি ইনপুট, ডুপ্লিকেট-মুক্ত ইনডেক্সিং ম্যাপ
![]()
এমনও ক্ষেত্র রয়েছে যখন ইনডেক্সিং ম্যাপগুলো আসলে একই হয়, যদিও তা তাৎক্ষণিকভাবে স্পষ্ট হয় না।
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
এই ক্ষেত্রে p0 এর জন্য আউটপুট-টু-ইনপুট ইন্ডেক্সিং ম্যাপটি হলো (d0, d1, d2) -> (d2, d0, d1) ।
সফটম্যাক্স
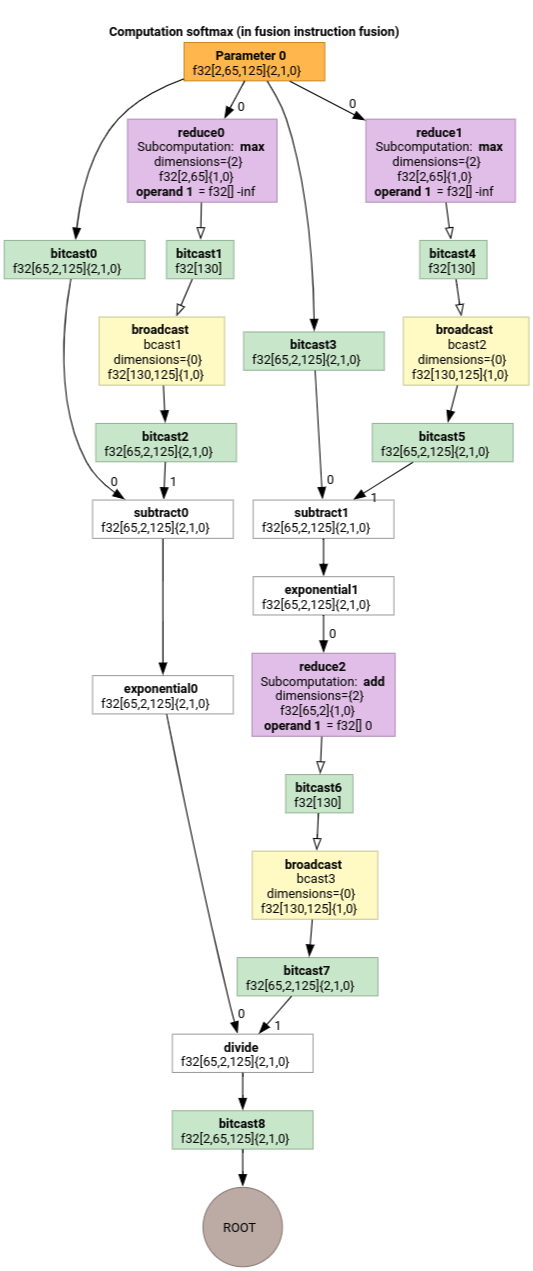
সফটম্যাক্সের parameter 0 এর জন্য আউটপুট-টু-ইনপুট ইন্ডেক্সিং ম্যাপগুলো হলো:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
এবং
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
যেখানে s0 বলতে ইনপুটের সবচেয়ে ভেতরের মাত্রাকে বোঝায়।
আরও উদাহরণের জন্য indexing_analysis_test.cc দেখুন।
সূচীকরণ মানচিত্র সরলীকরণ
প্রতীকী মানচিত্রের উপ-অভিব্যক্তিগুলোর নিম্ন ও ঊর্ধ্ব সীমা সম্পর্কিত জ্ঞানকে কাজে লাগিয়ে আমরা সেগুলোকে আরও সরল করতে পারি।
ইনডেক্সিং ম্যাপ সরলীকরণের মাধ্যমে নিম্নলিখিত রাশিমালাগুলোকে পুনরায় লেখা যায়।
-
[0, 6] x [0, 14]এর মধ্যে d এর জন্য(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)হয়ে যায়(d0, d1) -> (d0, d1) -
di in [0, 9]জন্য(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)হয়ে যায়(d0, d1, d2) -> (d0, d1, d2)। -
d_i in [0, 9]এর জন্য(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)হয়ে যায়(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8)। -
[0, 9] x [0, 10]এর মধ্যে d এর জন্য(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)হয়ে যায়(d0, d1) -> (d0)।
এর মাধ্যমে আমরা বুঝতে পারি যে HLO-তে কিছু শৃঙ্খলিত রিসেপ পরস্পরকে বাতিল করে দেয়। উদাহরণস্বরূপ:
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
ইনডেক্সিং ম্যাপগুলোর সংযোজন এবং সরলীকরণের পর আমরা নিম্নলিখিত ম্যাপটি পাব:
(d0, d1, d2) -> (d0, d1, d2) ।
ইনডেক্সিং ম্যাপ সরলীকরণ সীমাবদ্ধতাগুলোকেও সরল করে।
-
lower_bound <= symbolic_expr (floordiv, ceildiv, +, -, *, mod, min, max) constant <= upper_boundটাইপের কনস্ট্রেইন্টগুলোকেupdated_lower_bound <= symbolic_expr <= updated_upped_boundহিসেবে পুনরায় লেখা হয়। - যেসব শর্ত সর্বদা পূরণ হয়, যেমন
d0 in [0, 5]এবংs0 in [1, 3]হলেd0 + s0 in [0, 20], সেগুলো বাদ দেওয়া হয়। - সীমাবদ্ধতাগুলির মধ্যে থাকা প্রতীকী রাশিগুলিকে উপরের সূচীকরণ প্রতীকী মানচিত্র অনুসারে অপ্টিমাইজ করা হয়।
আরও উদাহরণের জন্য indexing_map_test.cc দেখুন।