
Es gibt drei Möglichkeiten, Code für HLO in XLA:GPU zu generieren.
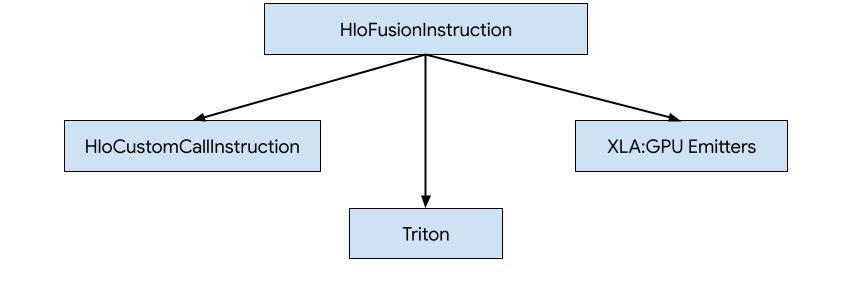
- Ersetzen von HLO durch benutzerdefinierte Aufrufe externer Bibliotheken, z.B. NVidia cuBLAS, cuDNN.
- HLO in Blöcke aufteilen und dann OpenAI Triton verwenden.
- XLA-Emitter verwenden, um HLO schrittweise in LLVM IR zu konvertieren.
In diesem Dokument geht es um XLA:GPU-Emitter.
Hero-basierte Codegenerierung
Es gibt sieben Emitter-Typen in XLA:GPU. Jeder Emittertyp entspricht einem „Hero“ der Fusion, d.h. dem wichtigsten Vorgang in der zusammengeführten Berechnung, der die Codegenerierung für die gesamte Fusion bestimmt.
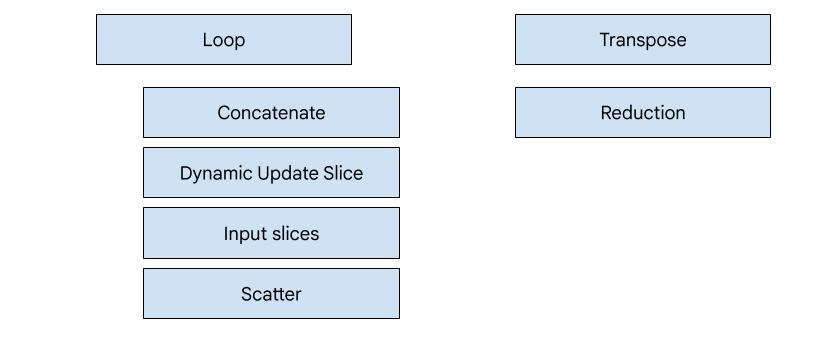
Der Transpose-Emitter wird beispielsweise ausgewählt, wenn in der Fusion ein HloTransposeInstruction vorhanden ist, für das der gemeinsame Speicher verwendet werden muss, um die Muster für das Lesen und Schreiben im Speicher zu optimieren. Der Reduction-Emitter generiert Reduzierungen mithilfe von Shuffles und gemeinsam genutztem Arbeitsspeicher. Der Loop-Emitter ist der Standard-Emitter. Wenn für eine Fusion kein Hero mit einem speziellen Emitter vorhanden ist, wird der Loop-Emitter verwendet.
Übersicht
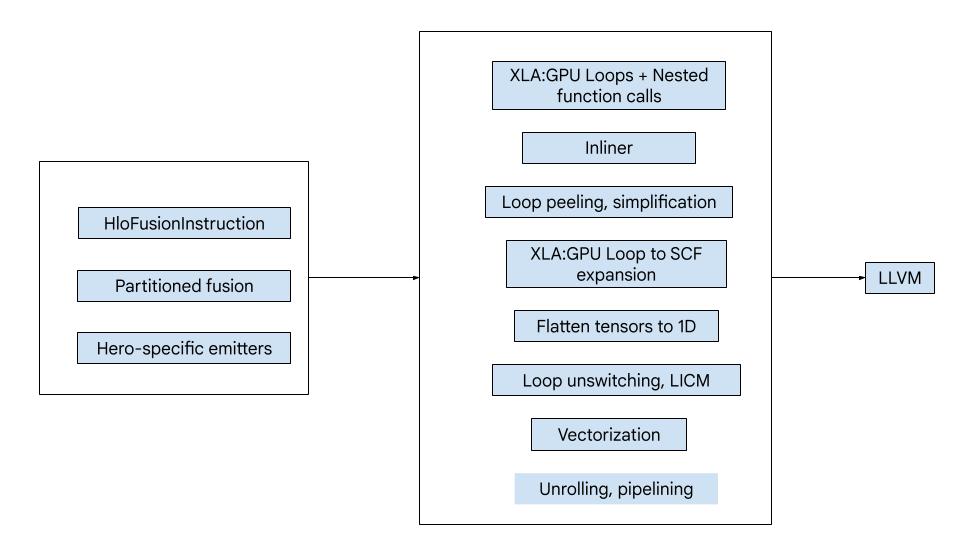
Der Code besteht aus den folgenden großen Bausteinen:
- Computation Partitioner: Aufteilen einer HLO-Fusion in Funktionen
- Emitters – Konvertieren von partitionierter HLO-Zusammenführung in MLIR (
xla_gpu-,tensor-,arith-,math- undscf-Dialekte) - Kompilierungspipeline – optimiert und reduziert IR zu LLVM
Partitionierung
Siehe computation_partitioner.h.
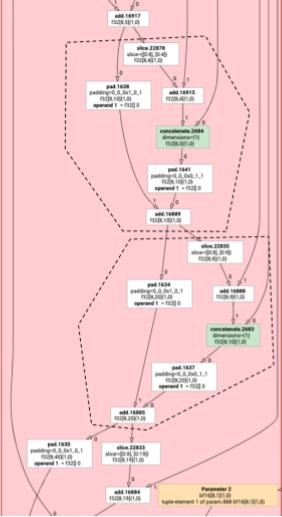
Nicht elementweise HLO-Anweisungen können nicht immer zusammen ausgegeben werden. Betrachten Sie das folgende HLO-Diagramm:
param
|
log
| \
| transpose
| /
add
Wenn wir dies in einer einzelnen Funktion ausgeben, wird für jedes Element des add auf das log an zwei verschiedenen Indexpositionen zugegriffen. Bei den alten Emitters wird dieses Problem gelöst, indem log zweimal generiert wird. Für dieses spezielle Diagramm ist das kein Problem, aber wenn es mehrere Aufteilungen gibt, wächst die Codegröße exponentiell.
Wir lösen dieses Problem, indem wir den Graphen in Teile unterteilen, die sicher als eine Funktion ausgegeben werden können. Folgende Kriterien müssen erfüllt sein:
- Anweisungen, die nur einen Nutzer haben, können zusammen mit dem Nutzer ausgegeben werden.
- Anleitungen mit mehreren Nutzern können zusammen mit ihren Nutzern ausgegeben werden, wenn alle Nutzer über dieselben Indexe darauf zugreifen.
Im obigen Beispiel greifen add und tranpose auf unterschiedliche Indexe von log zu. Daher ist es nicht sicher, sie zusammen mit log auszugeben.
Das Diagramm ist daher in drei Funktionen unterteilt, die jeweils nur eine Anweisung enthalten.
Das Gleiche gilt für das folgende Beispiel mit slice und pad von add.
Elementare Emission
Siehe elemental_hlo_to_mlir.h.
Durch die Elementarausgabe werden Schleifen und mathematische/arithmetische Operationen für HloInstructions erstellt. Das ist im Großen und Ganzen unkompliziert, aber es gibt einige interessante Dinge, die hier passieren.
Transformationen für die Indexierung
Einige Anweisungen (transpose, broadcast, reshape, slice, reverse und einige weitere) sind reine Transformationen von Indexen: Um ein Element des Ergebnisses zu erzeugen, müssen wir ein anderes Element der Eingabe erzeugen. Dazu können wir die indexing_analysis von XLA wiederverwenden, die Funktionen zum Erstellen der Ausgabe-zu-Eingabe-Zuordnung für eine Anleitung enthält.
Für ein transpose von [20,40] nach [40,20] wird beispielsweise die folgende Indexierungszuordnung erstellt (ein affiner Ausdruck pro Eingabedimension; d0 und d1 sind die Ausgabedimensionen):
(d0, d1) -> d1
(d0, d1) -> d0
Für diese reinen Index-Transformationsanweisungen können wir also einfach die Zuordnung abrufen, sie auf die Ausgabedaten anwenden und die Eingabe am resultierenden Index erzeugen.
Ähnlich verwendet der pad-Vorgang für den Großteil der Implementierung Indexierungszuordnungen und ‑beschränkungen. pad ist auch eine Indexierungstransformation mit einigen zusätzlichen Prüfungen, um festzustellen, ob ein Element der Eingabe oder der Padding-Wert zurückgegeben wird.
Tupel
Interne tuples werden nicht unterstützt. Verschachtelte Tupelausgaben werden ebenfalls nicht unterstützt. Alle XLA-Diagramme, in denen diese Funktionen verwendet werden, können in Diagramme konvertiert werden, in denen dies nicht der Fall ist.
Erfassen
Wir unterstützen nur kanonische Erfassungen, die von gather_simplifier erstellt wurden.
Untergraph-Funktionen
Für einen Teilgraphen einer Berechnung mit den Parametern %p0 bis %p_n und Teilgraphen-Roots mit r Dimensionen und Elementtypen (e0 bis e_m) verwenden wir die folgende MLIR-Funktionssignatur:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Das bedeutet, dass wir einen Tensoreingabe pro Berechnungsparameter, einen Indexeingabe pro Dimension der Ausgabe und ein Ergebnis pro Ausgabe haben.
Um eine Funktion auszugeben, verwenden wir einfach den oben genannten elementaren Emitter und geben die Operanden rekursiv aus, bis wir den Rand des Teilgraphen erreichen. Anschließend geben wir ein tensor.extract für Parameter oder ein func.call für andere Untergraphen aus.
Eingabefunktion
Die einzelnen Emittertypen unterscheiden sich darin, wie sie die Einstiegsfunktion, also die Funktion für den Hero, generieren. Die Einstiegsfunktion unterscheidet sich von den oben genannten Funktionen, da sie keine Indexe als Eingaben hat (nur die Thread- und Block-IDs) und die Ausgabe irgendwo schreiben muss. Für den Loop-Emitter ist das recht einfach, aber die Transpose- und Reduction-Emitter haben eine nicht triviale Schreiblogik.
Die Signatur der Berechnung des Eintrags lautet:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Dabei sind die %pns wie zuvor die Parameter der Berechnung und die %rns die Ergebnisse der Berechnung. Bei der Berechnung des Eintrags werden die Ergebnisse als Tensoren verwendet, tensor.insert-Aktualisierungen in sie eingefügt und dann zurückgegeben.
Andere Verwendungen der Ausgabetensoren sind nicht zulässig.
Kompilierungspipeline
Schleifensender
Weitere Informationen finden Sie unter loop.h.
Sehen wir uns die wichtigsten Durchläufe der MLIR-Kompilierungspipeline anhand des HLO für die GELU-Funktion an.
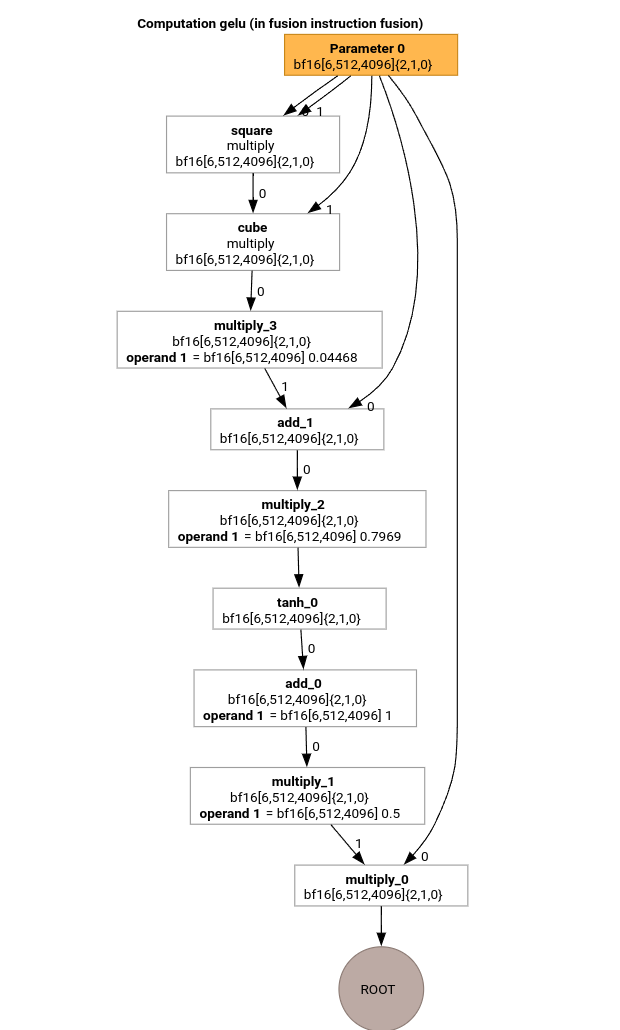
Diese HLO-Berechnung enthält nur elementweise Operationen, Konstanten und Broadcasts. Sie wird mit dem Schleifen-Emitter ausgegeben.
MLIR-Conversion
Nach der Konvertierung in MLIR erhalten wir ein xla_gpu.loop, das von %thread_id_x und %block_id_x abhängt und die Schleife definiert, die alle Elemente der Ausgabe linear durchläuft, um zusammengefasste Schreibvorgänge zu garantieren.
Bei jeder Iteration dieser Schleife rufen wir
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
um Elemente des Stammvorgangs zu berechnen. Beachten Sie, dass wir nur eine umrissene Funktion für @gelu haben, da der Partitionierer keinen Tensor mit mindestens zwei verschiedenen Zugriffsmustern erkannt hat.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Nachdem @gelu inline eingefügt wurde, erhalten wir eine einzelne @main-Funktion. Es kann vorkommen, dass dieselbe Funktion zweimal oder öfter aufgerufen wird. In diesem Fall wird nicht inline eingefügt. Weitere Informationen zu den Inlining-Regeln finden Sie unter xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu-zu-scf-Conversion
Weitere Informationen finden Sie unter lower_xla_gpu_to_scf.cc.
xla_gpu.loop stellt eine verschachtelte Schleife mit einer Grenzprüfung dar. Wenn die Variablen für die Schleifeninduktion außerhalb des Bereichs der Indexierungszuordnung liegen, wird diese Iteration übersprungen. Das bedeutet, dass die Schleife in einen oder mehrere verschachtelte scf.for-Vorgänge mit einem scf.if-Vorgang umgewandelt wird.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Tensoren zusammenfassen
Weitere Informationen finden Sie unter flatten_tensors.cc.
Die N-dimensionalen Tensoren werden auf 1D projiziert. Dies vereinfacht die Vektorisierung und die Umwandlung in LLVM, da jeder Tensorzugriff jetzt der Ausrichtung der Daten im Speicher entspricht.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vektorisierung
Weitere Informationen finden Sie unter vectorize_loads_stores.cc.
Der Pass analysiert die Indexe in den tensor.extract- und tensor.insert-Operationen. Wenn sie von xla_gpu.apply_indexing erzeugt werden, das sequenziell auf die Elemente in Bezug auf %vector_index zugreift und der Zugriff ausgerichtet ist, wird tensor.extract in vector.transfer_read konvertiert und aus der Schleife herausgezogen.
In diesem speziellen Fall wird eine Indexierungszuordnung (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) verwendet, um Elemente zu berechnen, die in einer scf.for-Schleife von 0 bis 4 extrahiert und eingefügt werden sollen.
Daher können sowohl tensor.extract als auch tensor.insert vektorisiert werden.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Entrollen von Schleifen
Weitere Informationen finden Sie unter optimize_loops.cc.
Beim Loop Unrolling werden scf.for-Schleifen gefunden, die entrollt werden können. In diesem Fall entfällt die Schleife über die Elemente des Vektors.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Konvertierung in LLVM
Wir verwenden hauptsächlich die standardmäßigen LLVM-Lowerings, aber es gibt einige spezielle Durchläufe.
Wir können die memref-Senkungen für Tensoren nicht verwenden, da wir das IR nicht puffern und unser ABI nicht mit dem memref-ABI kompatibel ist. Stattdessen haben wir eine benutzerdefinierte Absenkung direkt von Tensoren zu LLVM.
- Das Absenken von Tensoren erfolgt in lower_tensors.cc.
tensor.extractwird aufllvm.loadundtensor.insertaufllvm.storereduziert. - propagate_slice_indices und merge_pointers_to_same_slice implementieren zusammen ein Detail der Pufferzuweisung und des ABI von XLA: Wenn sich zwei Tensoren dieselbe Pufferaufteilung teilen, werden sie nur einmal übergeben. In diesen Durchläufen werden die Funktionsargumente dedupliziert.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Emitter transponieren
Sehen wir uns ein etwas komplexeres Beispiel an.
![]()
Der Transpose-Emitter unterscheidet sich vom Loop-Emitter nur in der Art und Weise, wie die Einstiegsfunktion generiert wird.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
In diesem Fall werden zwei xla_gpu.loop-Vorgänge generiert. Bei der ersten werden zusammengefasste Lesevorgänge aus der Eingabe ausgeführt und das Ergebnis in den gemeinsam genutzten Speicher geschrieben.
Der Tensor für den gemeinsam genutzten Speicher wird mit dem xla_gpu.allocate_shared-Vorgang erstellt.
Nachdem die Threads mit xla_gpu.sync_threads synchronisiert wurden, liest der zweite xla_gpu.loop die Elemente aus dem Tensor im gemeinsam genutzten Speicher und führt zusammengefasste Schreibvorgänge in die Ausgabe aus.
Reproducer
Um das IR nach jedem Durchlauf der Kompilierungspipeline zu sehen, kann man run_hlo_module mit dem Flag --xla_dump_emitter_re=mlir-fusion starten.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
Dabei enthält /tmp/gelu.hlo Folgendes:
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Links zu Code
- Kompilierungspipeline: emitter_base.h
- Optimierungs- und Conversion-Durchläufe: backends/gpu/codegen/emitters/transforms
- Partitionslogik: computation_partitioner.h
- Hero-basierte Emitter: backends/gpu/codegen/emitters
- XLA:GPU-Vorgänge: xla_gpu_ops.td
- Korrektheits- und Lit-Tests: backends/gpu/codegen/emitters/tests