
Existen tres formas de generar código para HLO en XLA:GPU.
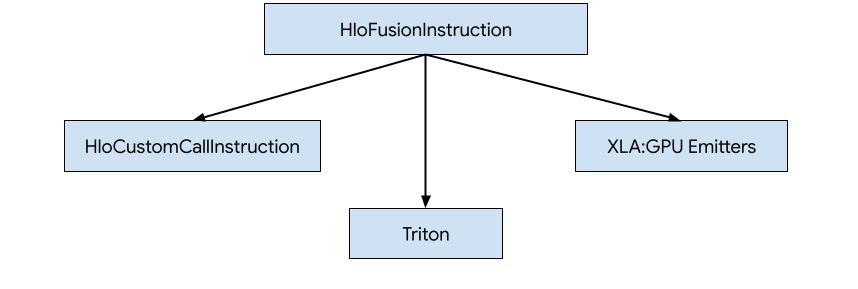
- Reemplazar HLO con llamadas personalizadas a bibliotecas externas, p. ej., NVidia cuBLAS, cuDNN
- Se divide el HLO en bloques y, luego, se usa OpenAI Triton.
- Usa emisores de XLA para reducir progresivamente el HLO al IR de LLVM.
Este documento se centra en los emisores de XLA:GPU.
Generación de código basada en héroes
Hay 7 tipos de emisores en XLA:GPU. Cada tipo de emisor corresponde a un "héroe" de la fusión, es decir, la operación más importante en el cálculo fusionado que da forma a la generación de código para toda la fusión.
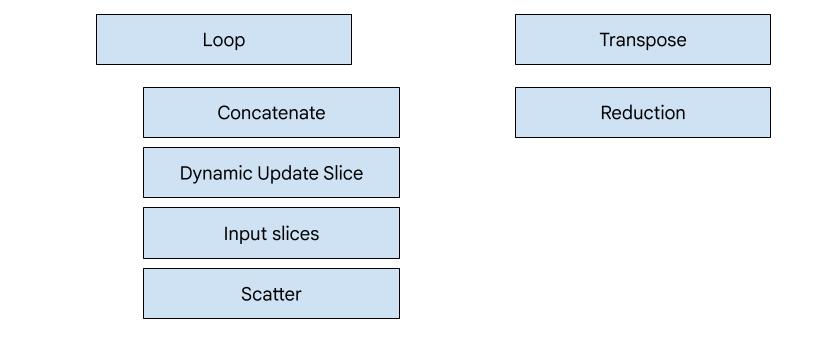
Por ejemplo, se seleccionará el emisor de transposición si hay un HloTransposeInstruction dentro de la fusión que requiere el uso de memoria compartida para mejorar los patrones de lectura y escritura de la memoria. El emisor de reducción genera reducciones con combinaciones aleatorias y memoria compartida. El emisor de bucle es el emisor predeterminado. Si una fusión no tiene un héroe para el que tenemos un emisor especial, se usará el emisor de bucle.
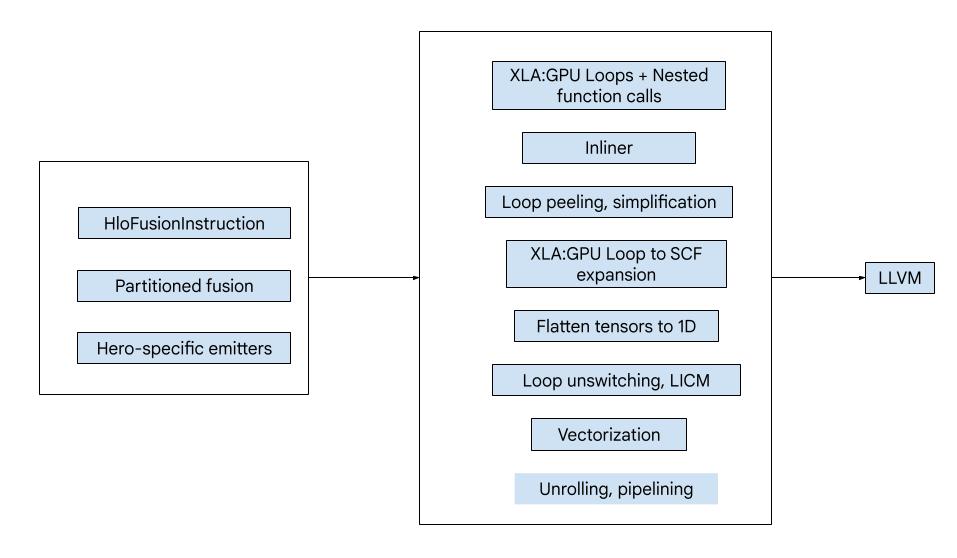
Descripción general
El código consta de los siguientes componentes básicos:
- Particionador de procesamiento: Divide un procesamiento de fusión de HLO en funciones
- Emisores: Conversión de la fusión de HLO particionada a MLIR (dialectos
xla_gpu,tensor,arith,mathyscf) - Canalización de compilación: Optimiza y reduce la representación intermedia a LLVM
Partición
Consulta computation_partitioner.h.
Las instrucciones de HLO que no son a nivel de los elementos no siempre se pueden emitir juntas. Considera el siguiente gráfico de HLO:
param
|
log
| \
| transpose
| /
add
Si emitimos esto en una sola función, se accederá a log en dos índices diferentes para cada elemento de add. Los emisores anteriores resuelven este problema generando el log dos veces. Para este gráfico en particular, esto no es un problema, pero cuando hay varias divisiones, el tamaño del código crece de forma exponencial.
Aquí, resolvemos este problema particionando el gráfico en partes que se pueden emitir de forma segura como una sola función. Los criterios son:
- Las instrucciones que tienen solo un usuario se pueden emitir de forma segura junto con su usuario.
- Las instrucciones que tienen varios usuarios son seguras para emitirse junto con sus usuarios si todos los usuarios acceden a ellas a través de los mismos índices.
En el ejemplo anterior, add y tranpose acceden a diferentes índices de log, por lo que no es seguro emitirlo junto con ellos.
Por lo tanto, el gráfico se particiona en tres funciones (cada una contiene solo una instrucción).
Lo mismo se aplica al siguiente ejemplo con slice y pad de add.
Emisión elemental
Consulta elemental_hlo_to_mlir.h.
La emisión elemental crea bucles y operaciones matemáticas o aritméticas para HloInstructions. En su mayor parte, esto es sencillo, pero hay algunas cosas interesantes que suceden aquí.
Transformaciones de indexación
Algunas instrucciones (transpose, broadcast, reshape, slice, reverse y algunas más) son transformaciones puras en índices: para producir un elemento del resultado, necesitamos producir algún otro elemento de la entrada. Para ello, podemos reutilizar el indexing_analysis de XLA, que tiene funciones para producir la asignación de salida a entrada para una instrucción.
Por ejemplo, para un transpose de [20,40] a [40,20], se producirá el siguiente mapa de indexación (una expresión afín por dimensión de entrada; d0 y d1 son las dimensiones de salida):
(d0, d1) -> d1
(d0, d1) -> d0
Por lo tanto, para estas instrucciones de transformación de índice puro, podemos simplemente obtener el mapa, aplicarlo a los índices de salida y producir la entrada en el índice resultante.
Del mismo modo, la operación pad usa mapas y restricciones de indexación para la mayor parte de la implementación. pad también es una transformación de indexación con algunas verificaciones adicionales para ver si devolvemos un elemento de la entrada o el valor de padding.
Tuplas
No admitimos tuple internos. Tampoco admitimos salidas de tuplas anidadas. Todos los gráficos de XLA que usan estas funciones se pueden convertir en gráficos que no las usan.
Recopila
Solo admitimos las recopilaciones canónicas producidas por gather_simplifier.
Funciones de subgrafos
Para un subgrafo de un cálculo con parámetros %p0 a %p_n y raíces de subgrafo con dimensiones y tipos de elementos r (e0 a e_m), usamos la siguiente firma de función de MLIR:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Es decir, tenemos un tensor de entrada por parámetro de cálculo, un índice de entrada por dimensión de la salida y un resultado por salida.
Para emitir una función, simplemente usamos el emisor elemental anterior y emitimos sus operandos de forma recursiva hasta que llegamos al borde del subgrafo. Luego, emitimos un tensor.extract para los parámetros o un func.call para otros subgrafos.
Función de entrada
Cada tipo de emisor difiere en la forma en que genera la función de entrada, es decir, la función del héroe. La función de entrada es diferente de las anteriores, ya que no tiene índices como entradas (solo los IDs de subproceso y bloque) y, en realidad, necesita escribir el resultado en algún lugar. Para el emisor de bucle, esto es bastante sencillo, pero los emisores de transposición y reducción tienen una lógica de escritura no trivial.
La firma del cálculo de la entrada es la siguiente:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Como antes, las %pn son los parámetros del cálculo y las %rn son los resultados del cálculo. El cálculo de la entrada toma los resultados como tensores, tensor.insert los actualiza y, luego, los devuelve.
No se permiten otros usos de los tensores de salida.
Canalización de compilación
Emisor de bucle
Consulta loop.h.
Estudiemos los pases más importantes de la canalización de compilación de MLIR con el HLO para la función GELU.
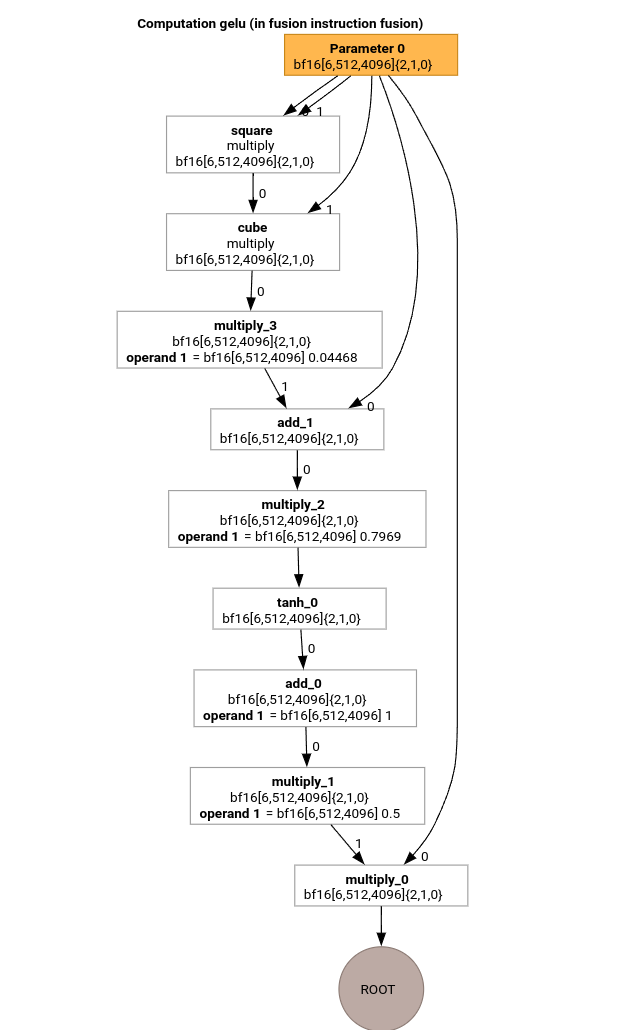
Este cálculo de HLO solo tiene operaciones elementales, constantes y transmisiones. Se emitirá con el emisor de bucle.
Conversión de MLIR
Después de la conversión a MLIR, obtenemos un xla_gpu.loop que depende de %thread_id_x y %block_id_x, y define el bucle que recorre todos los elementos de la salida de forma lineal para garantizar escrituras fusionadas.
En cada iteración de este bucle, llamamos a
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
para calcular los elementos de la operación raíz. Ten en cuenta que solo tenemos una función delineada para @gelu, ya que el particionador no detectó un tensor que tenga 2 o más patrones de acceso diferentes.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Después de que @gelu se inserta en línea, obtenemos una sola función @main. Puede suceder que se llame a la misma función dos o más veces. En este caso, no insertamos el contenido de forma intercalada. Puedes encontrar más detalles sobre las reglas de inserción en xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
Conversión de xla_gpu a scf
Consulta lower_xla_gpu_to_scf.cc.
xla_gpu.loop representa un bucle anidado con una verificación de límite en el interior. Si las variables de inducción del bucle están fuera de los límites del dominio del mapa de indexación, se omite esta iteración. Esto significa que el bucle se convierte en 1 o más operaciones scf.for anidadas con una operación scf.if dentro.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Compactar tensores
Consulta flatten_tensors.cc.
Los tensores N-dimensionales se proyectan en 1D. Esto simplificará la vectorización y la reducción a LLVM, ya que cada acceso a un tensor ahora corresponde a cómo se alinean los datos en la memoria.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vectorización
Consulta vectorize_loads_stores.cc.
El pase analiza los índices en las operaciones tensor.extract y tensor.insert, y, si los produce xla_gpu.apply_indexing, que accede a los elementos de forma contigua con respecto a %vector_index y el acceso está alineado, entonces tensor.extract se convierte en vector.transfer_read y se eleva fuera del bucle.
En este caso particular, hay un mapa de indexación (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) que se usa para calcular los elementos que se extraerán y se insertarán en un bucle scf.for de 0 a 4.
Por lo tanto, tanto tensor.extract como tensor.insert se pueden vectorizar.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Desenrollado de bucles
Consulta optimize_loops.cc.
El desenrollado de bucles encuentra bucles scf.for que se pueden desenrollar. En este caso, el bucle sobre los elementos del vector desaparece.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Conversión a LLVM
En su mayoría, usamos las reducciones estándar de LLVM, pero hay algunos pases especiales.
No podemos usar las reducciones de memref para los tensores, ya que no almacenamos en búfer el IR y nuestra ABI no es compatible con la ABI de memref. En cambio, tenemos una reducción personalizada directamente de los tensores a LLVM.
- La reducción de tensores se realiza en lower_tensors.cc.
tensor.extractse reduce allvm.loadytensor.insertallvm.storede la manera obvia. - propagate_slice_indices y merge_pointers_to_same_slice implementan juntos un detalle de la asignación de búferes y la ABI de XLA: si dos tensores comparten el mismo segmento de búfer, solo se pasan una vez. Estos pases eliminan los argumentos de la función duplicados.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
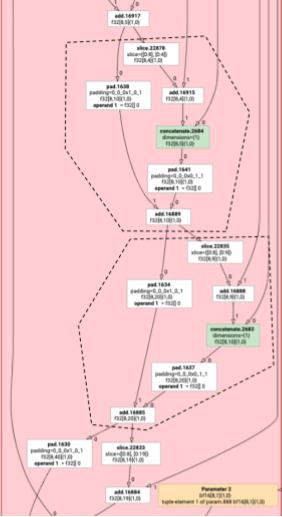
Emisor de transposición
Consideremos un ejemplo un poco más complejo.
![]()
El emisor de transposición solo se diferencia del emisor de bucle en la forma en que se genera la función de entrada.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
En este caso, generamos dos operaciones xla_gpu.loop. El primero realiza lecturas fusionadas desde la entrada y escribe el resultado en la memoria compartida.
El tensor de memoria compartida se crea con la operación xla_gpu.allocate_shared.
Después de que los subprocesos se sincronizan con xla_gpu.sync_threads, el segundo xla_gpu.loop lee los elementos del tensor de memoria compartida y realiza escrituras fusionadas en la salida.
Reproductor
Para ver la RI después de cada paso de la canalización de compilación, se puede iniciar run_hlo_module con la marca --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
donde /tmp/gelu.hlo contiene
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Vínculos al código
- Canalización de compilación: emitter_base.h
- Pases de optimización y conversión: backends/gpu/codegen/emitters/transforms
- Lógica de partición: computation_partitioner.h
- Emisores basados en héroes: backends/gpu/codegen/emitters
- XLA:Operaciones de GPU: xla_gpu_ops.td
- Pruebas de corrección y de literal: backends/gpu/codegen/emitters/tests