
El análisis de indexación de HLO es un análisis de flujo de datos que describe cómo se relacionan los elementos de un tensor con otro a través de "mapas de indexación". Por ejemplo, cómo los índices de un mapa de salida de instrucciones HLO se asignan a los índices de operandos de instrucciones HLO.
Ejemplo
Para una transmisión de tensor<20xf32> a tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
El mapa de indexación de la salida a la entrada es (i, j, k) -> (j) para i in
[0, 10], j in [0, 20] y k in [0, 30].
Motivación
XLA usa varias soluciones personalizadas para razonar sobre la coalescencia, la utilización de operandos y los esquemas de segmentación (más detalles a continuación). El objetivo del análisis de indexación es proporcionar un componente reutilizable para esos casos de uso. El análisis de indexación se basa en la infraestructura de mapas afines de MLIR y agrega semántica de HLO.
Combinación
El razonamiento sobre la coalescencia de memoria se vuelve factible para casos no triviales cuando sabemos qué elementos o segmentos de las entradas se leen para calcular un elemento de la salida.
Utilización de operandos
La utilización de operandos en XLA indica cuánto se usa cada entrada de la instrucción, suponiendo que su salida se usa por completo. Actualmente, la utilización tampoco se calcula para un caso genérico. El análisis de indexación nos permite calcular la utilización con precisión.
Mosaico
Un segmento o división es un subconjunto hiperrectangular de un tensor parametrizado por desplazamientos, tamaños y pasos. La propagación de mosaicos es una forma de calcular los parámetros de mosaico del productor o consumidor de la operación usando los parámetros de mosaico de la operación en sí. Ya existe una biblioteca que lo hace para softmax y punto. La propagación de mosaicos puede ser más genérica y sólida si se expresa a través de mapas de indexación.
Mapa de indexación
Un mapa de indexación es una combinación de
- Una función expresada de forma simbólica que asigna cada elemento de un tensor
Aa rangos de elementos en el tensorB - Restricciones sobre argumentos de función válidos, incluido el dominio de la función
Los argumentos de las funciones se dividen en 3 categorías para comunicar mejor su naturaleza:
Variables de dimensión del tensor
Ao una cuadrícula de GPU desde la que se realiza la asignación; los valores se conocen de forma estática. Los elementos de índice también se denominan variables de dimensión.Variables de rango Definen una asignación de uno a varios y especifican un conjunto de elementos en
Bque se usan para calcular un solo valor deA; los valores se conocen de forma estática. La dimensión de contracción de una multiplicación de matrices es un ejemplo de una variable de rango.Variables de tiempo de ejecución que solo se conocen durante la ejecución. Por ejemplo, el argumento de índices de la operación gather.
El resultado de la función es un índice del tensor B objetivo.
En resumen, una función de indexación del tensor A al tensor B para la operación x es
map_ab(index in A, range variables, runtime variables) -> index in B.
Para separar mejor los tipos de argumentos de asignación, los escribimos de la siguiente manera:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Por ejemplo, veamos los mapas de indexación para la operación de reducción f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
Para asignar elementos de
inaout, nuestra función se puede expresar como(d0, d1, d2, d3) -> (d1, d2). Las restricciones de las variablesd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]se definen según la forma dein.Para asignar elementos de
outain:outtiene solo dos dimensiones, y la reducción introduce dos variables de rango que abarcan las dimensiones de reducción. Por lo tanto, la función de asignación es(d0, d1)[s0, s1] -> (s0, d0, d1, s1), donde(d0, d1)es el índice deout.s0ys1son rangos definidos por la semántica de la operación y abarcan las dimensiones 0 y 3 del tensorin. Las restricciones sond0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
Es importante tener en cuenta que, en la mayoría de los casos, nos interesa asignar elementos del resultado. Para el procesamiento
C = op1(A, B)
E = op2(C, D)
Podemos hablar de la "indexación de B" en el sentido de "asignación de elementos de E a los elementos de B". Esto podría ser contradictorio en comparación con otros tipos de análisis de flujo de datos que funcionan desde la entrada hacia las salidas.
Las restricciones en las variables permiten oportunidades de optimización y ayudan con la generación de código. En la documentación y las restricciones de implementación, también se hace referencia a ellas como dominio, ya que definen todas las combinaciones o los valores de argumentos válidos de la función de asignación. En muchas operaciones, las restricciones simplemente describen las dimensiones de los tensores, pero, en algunas, pueden ser más complicadas. Consulta los ejemplos a continuación.
Al tener funciones y restricciones de argumentos expresadas de forma simbólica, y poder combinar funciones y restricciones, podemos calcular una asignación de indexación compacta para un cálculo arbitrariamente grande (fusión).
La expresividad de las funciones y las restricciones simbólicas es un equilibrio entre la complejidad de la implementación y las ganancias de optimización que obtenemos por tener una representación más precisa. Para algunas operaciones de HLO, solo capturamos los patrones de acceso de forma aproximada.
Implementación
Como queremos minimizar el recálculo, necesitamos una biblioteca para los cálculos simbólicos. XLA ya depende de MLIR, por lo que usamos mlir::AffineMap en lugar de escribir otra biblioteca aritmética simbólica.
Un AffineMap típico se ve así:
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap tiene dos tipos de parámetros: dimensiones y símbolos.
Las dimensiones corresponden a las variables de dimensión d; los símbolos corresponden a las variables de rango r y las variables de tiempo de ejecución rt. AffineMap no contiene metadatos sobre las restricciones de los parámetros, por lo que debemos proporcionarlos por separado.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ codifica las restricciones de caja inclusivas para las variables de dimensión d del mapa de indexación, que suelen coincidir con la forma del tensor de salida para las operaciones como transponer, reducir, elemento a elemento, punto y, sin embargo, hay algunas excepciones como HloConcatenateInstruction.
range_vars_ todos los valores que toman las variables de rango s. Las variables de rango son necesarias cuando se requieren varios valores para calcular un solo elemento del tensor desde el que se asigna, p.ej., para el mapa de indexación de salida a entrada de las reducciones o el mapa de entrada a salida para las transmisiones.
rt_vars_ codifica los valores factibles en el tiempo de ejecución. Por ejemplo, el desplazamiento es dinámico para un HloDynamicSliceInstruction 1D. El RTVar correspondiente tendrá valores factibles entre 0 y tensor_size - slice_size - 1.
constraints_ captura relaciones entre valores en el formato <expression> in <range>, p.ej., d0 + s0 in [0, 20]. Junto con Variable.bounds, definen el "dominio" de la función de indexación.
Estudiemos con ejemplos para comprender qué significa todo lo anterior.
Indexación de Maps para operaciones sin fusionar
Operaciones elemento por elemento
Para las operaciones de elementos, el mapa de indexación es una identidad.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
El mapa de entrada a salida output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
El mapa de entrada a salida p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Anuncio
La transmisión significa que algunas de las dimensiones se quitarán cuando asignemos la salida a la entrada y se agregarán cuando asignemos la entrada a la salida.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
El mapa de entrada a salida:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
El mapa de entrada a salida:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Ten en cuenta que ahora tenemos variables de rango s en el lado derecho para la asignación de entrada a salida. Esos son los símbolos que representan rangos de valores.
Por ejemplo, en este caso particular, cada elemento de la entrada con el índice d0 se asigna a un segmento de 10 x 1 x 30 del resultado.
Iota
Iota no tiene ningún operando tensor de entrada, por lo que no hay argumentos de índice de entrada.
iota = f32[2,4] iota(), dimensions={1}
Salida al mapa de entrada:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Mapa de entrada a salida:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice tiene desplazamientos que solo se conocen en el tiempo de ejecución.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
El mapa de salida a entrada de ds a src:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Ten en cuenta que ahora tenemos rt en el lado derecho para la asignación de entrada a salida.
Esos son los símbolos que representan los valores de tiempo de ejecución. Por ejemplo, en este caso particular, para cada elemento de la salida con índices d0, d1, d2, accedemos a las compensaciones de segmentación of1, of2 y of3 para calcular el índice de la entrada.
Los intervalos de las variables de tiempo de ejecución se derivan suponiendo que toda la segmentación permanece dentro de los límites.
El mapa de entrada a salida para of1, of2 y of3:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
El mapa de entrada a salida para src es trivial. Se puede hacer más precisa si se restringe el dominio a los índices no actualizados, pero, en este momento, los mapas de indexación no admiten restricciones de desigualdad.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
El mapa de entrada a salida para upd es el siguiente:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Ten en cuenta que ahora tenemos rt0 y rt1 que representan valores de tiempo de ejecución. En este caso particular, para cada elemento de la salida con índices d0, d1, accedemos a las compensaciones de segmentación of1 y of2 para calcular el índice de la entrada. Los intervalos de las variables de tiempo de ejecución se derivan suponiendo que toda la división permanece dentro de los límites.
El mapa de salida a entrada para of1 y of2 es el siguiente:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
Solo se admite la recopilación simplificada. Consulta gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
El mapa de entrada a salida para operand es el siguiente:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Ten en cuenta que ahora tenemos símbolos rt que representan valores de tiempo de ejecución.
El mapa de entrada a salida para indices es el siguiente:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
La variable de rango s0 muestra que necesitamos toda la fila (d0, *) del tensor indices para calcular un elemento del resultado.
Transponer
El mapa de indexación para la transposición es una permutación de las dimensiones de entrada y salida.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
El mapa de entrada a salida:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
El mapa de entrada a salida:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Invertir
Mapa de indexación para la reversión: Cambia las dimensiones revertidas a upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
El mapa de entrada a salida:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
El mapa de entrada a salida:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
La reducción variádica tiene varias entradas y varios valores iniciales. El mapa de la salida a la entrada agrega las dimensiones reducidas.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
Los mapas de entrada y salida son los siguientes:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Las asignaciones de entrada a salida son las siguientes:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
La indexación de la salida a la entrada para los resultados de la segmentación genera un mapa de indexación con pasos que es válido para cada elemento de la salida. El mapeo de la entrada a la salida se restringe a un rango de elementos con pasos en la entrada.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
El mapa de entrada a salida:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
El mapa de entrada a salida:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Cambiar forma
Los cambios de forma vienen en diferentes versiones.
Forma de contraer
Se trata de un cambio de forma "linealizador" de N-D a 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
El mapa de entrada a salida:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
El mapa de entrada a salida:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Expandir forma
Esta es una operación inversa de "collapse shape"; cambia la forma de una entrada 1D a una salida N-D.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
El mapa de entrada a salida:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
El mapa de entrada a salida:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Cambio de forma genérico
Estas son las operaciones de cambio de forma que no se pueden representar como una sola forma de expansión o contracción. Solo se pueden representar como una composición de 2 o más formas de expansión o contracción.
Ejemplo 1: Linealización y deslinealización
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Este cambio de forma se puede representar como una composición del colapso de la forma de tensor<4x8xf32> a tensor<32xf32> y, luego, una expansión de la forma a tensor<2x4x4xf32>.
El mapa de entrada a salida:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
El mapa de entrada a salida:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Ejemplo 2: Subformas expandidas y contraídas
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Este cambio de forma se puede representar como una composición de dos cambios de forma. La primera contrae las dimensiones externas tensor<4x8x12xf32> a tensor<32x12xf32>, y la segunda expande la dimensión interna tensor<32x12xf32> a tensor<32x3x4xf32>.
El mapa de entrada a salida:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
El mapa de entrada a salida:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
Una operación de bitcast se puede representar como una secuencia de transposición-cambio de forma-transposición. Por lo tanto, sus mapas de indexación son solo una composición de los mapas de indexación de esta secuencia.
Concatenate
La asignación de salida a entrada para la concatenación se define para todas las entradas, pero con dominios que no se superponen, es decir, solo se usará una de las entradas a la vez.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
La asignación de la salida a las entradas es la siguiente:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
Las entradas para los mapas de salida son las siguientes:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Punto
Los mapas de indexación para dot son muy similares a los de reduce.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
La asignación de la salida a las entradas es la siguiente:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
Las entradas para los mapas de salida son las siguientes:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Almohadilla
La indexación de PadOp es la inversa de la indexación de SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
La configuración de padding 1_4_1x4_8_0 denota lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
Los mapas de entrada y salida son los siguientes:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
ReduceWindow en XLA también realiza el padding. Por lo tanto, los mapas de indexación se pueden calcular como una composición de la indexación de ReduceWindow que no realiza ningún padding y la indexación de PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
Los mapas de entrada y salida son los siguientes:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Indexación de mapas para Fusion
El mapa de indexación para la operación de fusión es una composición de los mapas de indexación para cada operación del clúster. Puede suceder que algunas entradas se lean varias veces con diferentes patrones de acceso.
Una entrada, varios mapas de indexación
Este es un ejemplo para p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Los mapas de indexación de salida a entrada para p0 serán (d0, d1) -> (d0, d1) y (d0, d1) -> (d1, d0). Esto significa que, para calcular un elemento de la salida, es posible que debamos leer el parámetro de entrada dos veces.
Un mapa de indexación con deduplicación de una entrada
![]()
Hay casos en los que los mapas de indexación son iguales, aunque no sea evidente de inmediato.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
En este caso, el mapa de indexación de salida a entrada para p0 es solo (d0, d1, d2) -> (d2, d0, d1).
Softmax
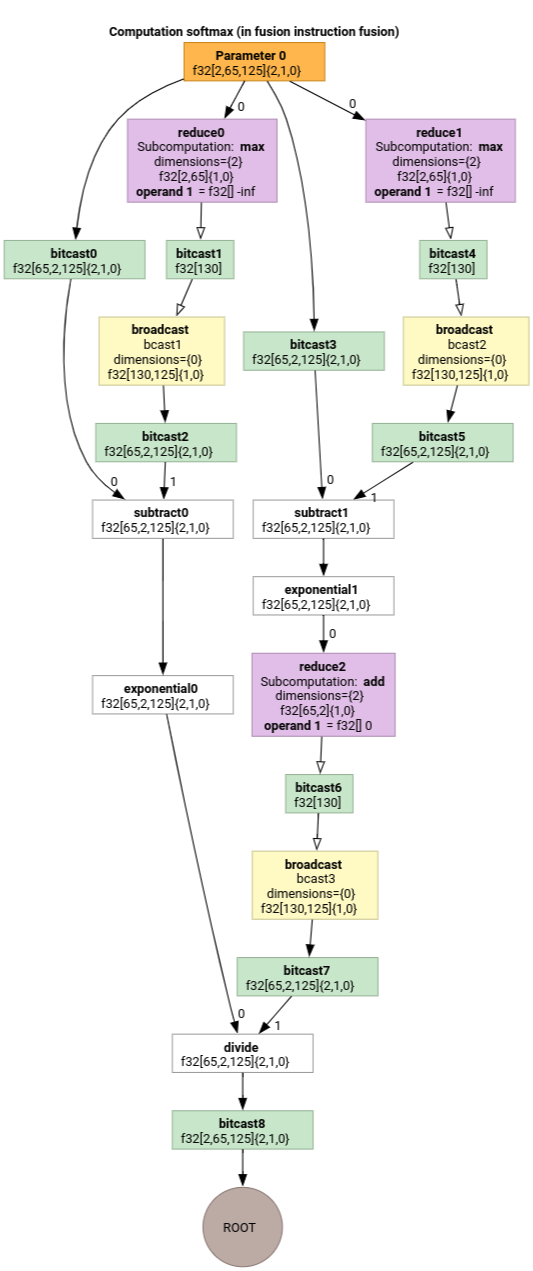
Las asignaciones de indexación de salida a entrada para parameter 0 para softmax son las siguientes:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
y
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
Aquí, s0 hace referencia a la dimensión más interna de la entrada.
Para obtener más ejemplos, consulta indexing_analysis_test.cc.
Indexing Map Simplifier
El simplificador predeterminado para mlir::AffineMap upstream no puede hacer suposiciones sobre los rangos de dimensiones o símbolos. Por lo tanto, no puede simplificar expresiones con mod y div de manera eficiente.
Podemos aprovechar el conocimiento sobre los límites inferior y superior de las subexpresiones en los mapas afines para simplificarlos aún más.
El simplificador puede reescribir las siguientes expresiones.
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)para d en[0, 6] x [0, 14]se convierte en(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)paradi in [0, 9]se convierte en(d0, d1, d2) -> (d0, d1, d2).(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)parad_i in [0, 9]se convierte en(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8).(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)para d en[0, 9] x [0, 10]se convierte en(d0, d1) -> (d0).
El simplificador del mapa de indexación nos permite comprender que algunos de los cambios de forma encadenados en HLO se cancelan entre sí.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
Después de la composición de los mapas de indexación y su simplificación, obtendremos
(d0, d1, d2) -> (d0, d1, d2).
La simplificación del mapa de indexación también simplifica las restricciones.
- Las restricciones de tipo
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundse reescriben comoupdated_lower_bound <= affine_expr <= updated_upped_bound. - Se eliminan las restricciones que siempre se satisfacen, p.ej.,
d0 + s0 in [0, 20]parad0 in [0, 5]ys0 in [1, 3]. - Las expresiones afines en las restricciones se optimizan como el mapa afín de indexación anterior.
Para obtener más ejemplos, consulta indexing_map_test.cc.