
Il existe trois façons de générer du code pour HLO dans XLA:GPU.
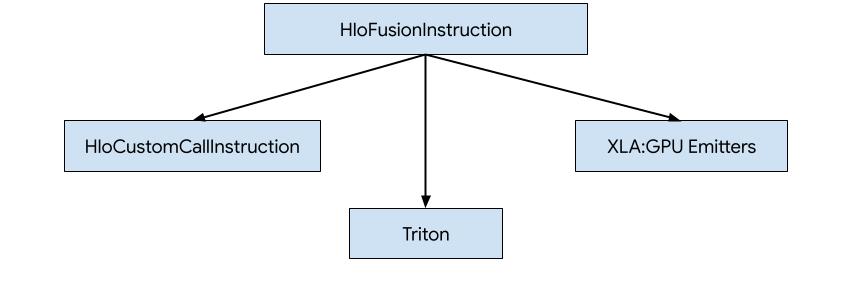
- Remplacer HLO par des appels personnalisés à des bibliothèques externes, par exemple NVidia cuBLAS, cuDNN.
- Tiling HLO au niveau du bloc, puis utilisation d'OpenAI Triton.
- Utilisation des émetteurs XLA pour abaisser progressivement le HLO vers LLVM IR.
Ce document se concentre sur les émetteurs XLA:GPU.
Génération de code basée sur les héros
XLA:GPU comporte sept types d'émetteurs. Chaque type d'émetteur correspond à un "héros" de la fusion, c'est-à-dire l'opération la plus importante dans le calcul fusionné qui façonne la génération de code pour l'ensemble de la fusion.
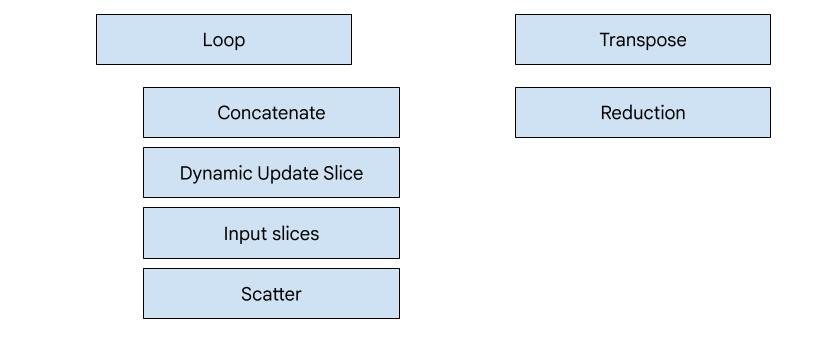
Par exemple, l'émetteur de transposition sera sélectionné s'il existe un HloTransposeInstruction dans la fusion qui nécessite l'utilisation de la mémoire partagée pour améliorer les modèles de lecture et d'écriture de la mémoire. L'émetteur de réduction génère des réductions à l'aide de shuffles et de mémoire partagée. L'émetteur de boucle est l'émetteur par défaut. Si une fusion ne comporte pas de héros pour lequel nous disposons d'un émetteur spécial, l'émetteur de boucle sera utilisé.
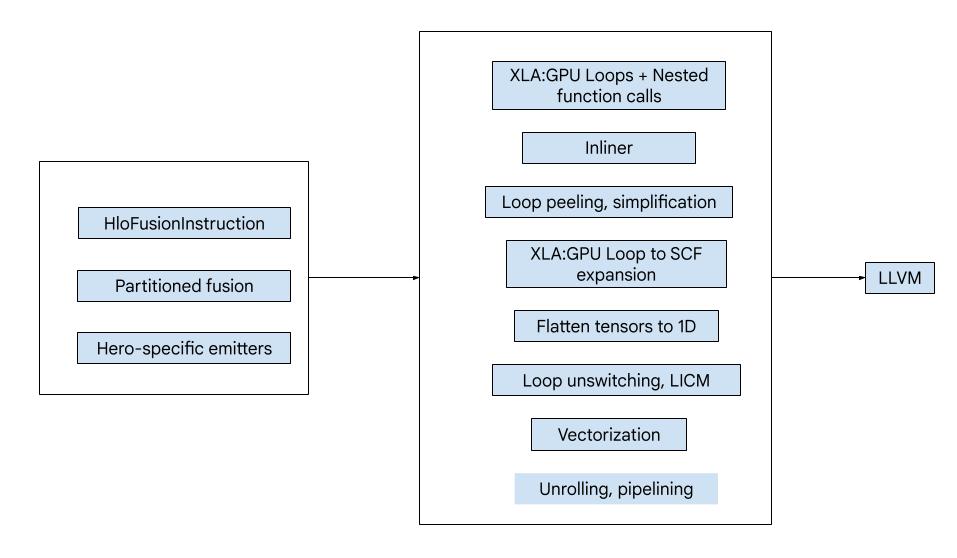
Présentation générale
Le code se compose des principaux blocs de construction suivants :
- Partitionneur de calcul : fractionnement d'un calcul de fusion HLO en fonctions
- Émetteurs : conversion de la fusion HLO partitionnée en MLIR (dialectes
xla_gpu,tensor,arith,math,scf) - Pipeline de compilation : optimise et réduit l'IR à LLVM
Partitionnement
Consultez computation_partitioner.h.
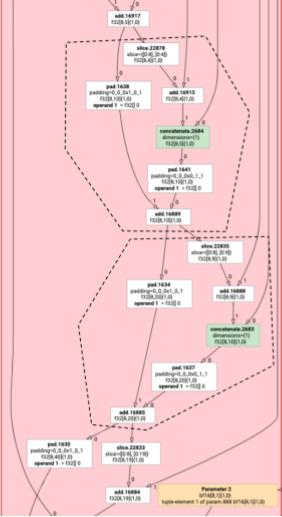
Les instructions HLO non élément par élément ne peuvent pas toujours être émises ensemble. Prenons l'exemple du graphique HLO suivant :
param
|
log
| \
| transpose
| /
add
Si nous émettons cela dans une seule fonction, le log sera accessible à deux index différents pour chaque élément du add. Les anciens émetteurs résolvent ce problème en générant log deux fois. Pour ce graphique en particulier, cela ne pose pas de problème, mais lorsque les divisions sont multiples, la taille du code augmente de manière exponentielle.
Ici, nous résolvons ce problème en partitionnant le graphique en éléments pouvant être émis de manière sécurisée en tant que fonction unique. Voici ces conditions :
- Les instructions qui n'ont qu'un seul utilisateur peuvent être émises avec leur utilisateur.
- Les instructions qui comportent plusieurs utilisateurs peuvent être émises avec leurs utilisateurs si elles sont accessibles par les mêmes index pour tous les utilisateurs.
Dans l'exemple ci-dessus, add et tranpose accèdent à différents index de log. Il n'est donc pas sûr de l'émettre avec eux.
Le graphique est donc partitionné en trois fonctions (chacune ne contenant qu'une seule instruction).
Il en va de même pour l'exemple suivant avec slice et pad de add.
Émission élémentaire
Consultez elemental_hlo_to_mlir.h.
L'émission élémentaire crée des boucles et des opérations mathématiques/arithmétiques pour HloInstructions. La plupart du temps, c'est simple, mais il y a quelques points intéressants à noter.
Transformations d'indexation
Certaines instructions (transpose, broadcast, reshape, slice, reverse et quelques autres) sont de pures transformations d'indices : pour produire un élément du résultat, nous devons produire un autre élément de l'entrée. Pour ce faire, nous pouvons réutiliser indexing_analysis de XLA, qui contient des fonctions permettant de produire le mappage de la sortie vers l'entrée d'une instruction.
Par exemple, pour un transpose de [20,40] à [40,20], il produira la carte d'indexation suivante (une expression affine par dimension d'entrée ; d0 et d1 sont les dimensions de sortie) :
(d0, d1) -> d1
(d0, d1) -> d0
Ainsi, pour ces instructions de transformation d'index pur, nous pouvons simplement obtenir le mappage, l'appliquer aux index de sortie et produire l'entrée à l'index résultant.
De même, l'opération pad utilise des mappages d'index et des contraintes pour la majeure partie de l'implémentation. pad est également une transformation d'indexation avec quelques vérifications supplémentaires pour déterminer si nous renvoyons un élément de l'entrée ou la valeur de remplissage.
Tuples
Nous n'acceptons pas les tuple internes. Nous n'acceptons pas non plus les sorties de tuples imbriquées. Tous les graphiques XLA qui utilisent ces fonctionnalités peuvent être convertis en graphiques qui ne les utilisent pas.
Collecter
Nous n'acceptons que les collectes canoniques produites par gather_simplifier.
Fonctions de sous-graphique
Pour un sous-graphe de calcul avec des paramètres %p0 à %p_n et des racines de sous-graphe avec des dimensions r et des types d'éléments (e0 à e_m), nous utilisons la signature de fonction MLIR suivante :
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Autrement dit, nous avons un Tensor d'entrée par paramètre de calcul, une entrée d'index par dimension de la sortie et un résultat par sortie.
Pour émettre une fonction, nous utilisons simplement l'émetteur élémentaire ci-dessus et émettons de manière récursive ses opérandes jusqu'à atteindre le bord du sous-graphe. Ensuite, nous émettons un tensor.extract pour les paramètres ou un func.call pour les autres sous-graphes.
Fonction d'entrée
Chaque type d'émetteur diffère dans la façon dont il génère la fonction d'entrée, c'est-à-dire la fonction pour le héros. La fonction d'entrée est différente des fonctions ci-dessus, car elle ne comporte aucun index en entrée (seulement les ID de thread et de bloc) et doit en fait écrire la sortie quelque part. Pour l'émetteur de boucle, c'est assez simple, mais les émetteurs de transposition et de réduction ont une logique d'écriture non triviale.
La signature du calcul de l'entrée est la suivante :
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Comme précédemment, les %pn sont les paramètres du calcul et les %rn sont les résultats du calcul. Le calcul des entrées prend les résultats sous forme de Tensors, met à jour les tensor.insert et les renvoie.
Aucune autre utilisation des Tensors de sortie n'est autorisée.
Pipeline de compilation
Émetteur de boucle
Consultez loop.h.
Étudions les passes les plus importantes du pipeline de compilation MLIR à l'aide du HLO pour la fonction GELU.
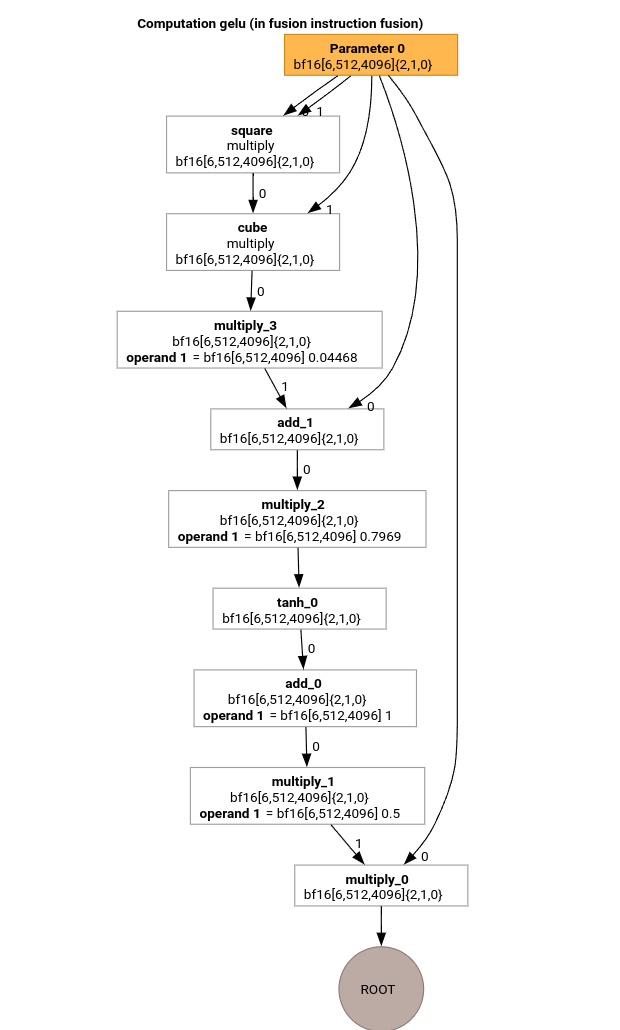
Ce calcul HLO ne comporte que des opérations élément par élément, des constantes et des diffusions. Il sera émis à l'aide de l'émetteur de boucle.
Conversion MLIR
Après la conversion en MLIR, nous obtenons un xla_gpu.loop qui dépend de %thread_id_x et %block_id_x et définit la boucle qui parcourt tous les éléments de la sortie de manière linéaire pour garantir des écritures coalescées.
À chaque itération de cette boucle, nous appelons
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
pour calculer les éléments de l'opération racine. Notez que nous n'avons qu'une seule fonction décrite pour @gelu, car le partitionneur n'a pas détecté de Tensor comportant deux schémas d'accès différents ou plus.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Une fois @gelu intégré, nous obtenons une seule fonction @main. Il peut arriver que la même fonction soit appelée deux fois ou plus. Dans ce cas, nous n'intégrons pas. Pour en savoir plus sur les règles d'intégration, consultez xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
Conversion de xla_gpu en scf
Consultez lower_xla_gpu_to_scf.cc.
xla_gpu.loop représente une imbrication de boucles avec une vérification des limites à l'intérieur. Si les variables d'induction de boucle sont hors limites du domaine de la carte d'indexation, cette itération est ignorée. Cela signifie que la boucle est convertie en une ou plusieurs opérations scf.for imbriquées avec un scf.if à l'intérieur.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Aplatir les Tensors
Consultez flatten_tensors.cc.
Les Tensors N-d sont projetés sur 1D. Cela simplifiera la vectorisation et l'abaissement vers LLVM, car chaque accès au Tensor correspond désormais à la façon dont les données sont alignées en mémoire.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vectorisation
Consultez vectorize_loads_stores.cc.
Le pass analyse les indices dans les opérations tensor.extract et tensor.insert. S'ils sont produits par xla_gpu.apply_indexing qui accède aux éléments de manière contiguë par rapport à %vector_index et que l'accès est aligné, tensor.extract est converti en vector.transfer_read et extrait de la boucle.
Dans ce cas particulier, une carte d'indexation (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) est utilisée pour calculer les éléments à extraire et à insérer dans une boucle scf.for de 0 à 4.
Par conséquent, tensor.extract et tensor.insert peuvent être vectorisés.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Déroulement de la boucle
Consultez optimize_loops.cc.
Le déroulement de boucle trouve les boucles scf.for qui peuvent être déroulées. Dans ce cas, la boucle sur les éléments du vecteur disparaît.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Conversion en LLVM
Nous utilisons principalement les abaisses LLVM standards, mais il existe quelques passes spéciales.
Nous ne pouvons pas utiliser les réductions memref pour les Tensors, car nous ne mettons pas en mémoire tampon l'IR et notre ABI n'est pas compatible avec l'ABI memref. Au lieu de cela, nous avons une réduction personnalisée directement des Tensors à LLVM.
- L'abaissement des Tensors est effectué dans lower_tensors.cc.
tensor.extractest abaissé àllvm.loadettensor.insertàllvm.storede manière évidente. - propagate_slice_indices et merge_pointers_to_same_slice implémentent ensemble un détail de l'attribution de mémoire tampon et de l'ABI de XLA : si deux Tensor partagent la même tranche de mémoire tampon, ils ne sont transmis qu'une seule fois. Ces passes dédupliquent les arguments de la fonction.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Transposer l'émetteur
Prenons un exemple un peu plus complexe.
![]()
L'émetteur de transposition ne diffère de l'émetteur de boucle que par la façon dont la fonction d'entrée est générée.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
Dans ce cas, nous générons deux opérations xla_gpu.loop. La première effectue des lectures fusionnées à partir de l'entrée et écrit le résultat dans la mémoire partagée.
Le Tensor de mémoire partagée est créé à l'aide de l'opération xla_gpu.allocate_shared.
Une fois les threads synchronisés à l'aide de xla_gpu.sync_threads, le deuxième xla_gpu.loop lit les éléments du Tensor de mémoire partagée et effectue des écritures coalescées dans la sortie.
Reproducteur
Pour afficher le code IR après chaque passe du pipeline de compilation, vous pouvez lancer run_hlo_module avec l'indicateur --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
où /tmp/gelu.hlo contient
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Liens vers le code
- Pipeline de compilation : emitter_base.h
- Passes d'optimisation et de conversion : backends/gpu/codegen/emitters/transforms
- Logique de partition : computation_partitioner.h
- Émetteurs basés sur des héros : backends/gpu/codegen/emitters
- Opérations XLA : GPU : xla_gpu_ops.td
- Tests de correction et tests littéraux : backends/gpu/codegen/emitters/tests