
Ada tiga cara untuk membuat kode untuk HLO di XLA:GPU.
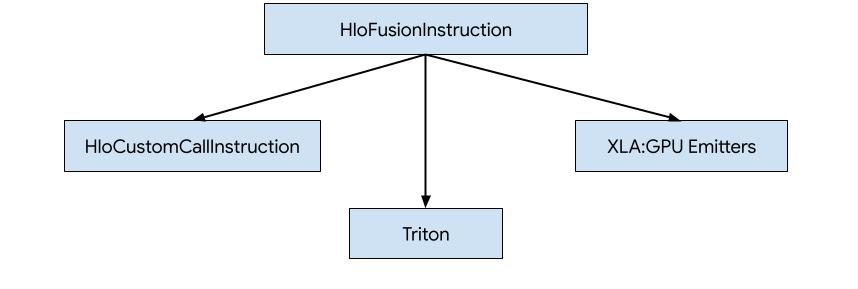
- Mengganti HLO dengan panggilan kustom ke library eksternal, misalnya NVidia cuBLAS, cuDNN.
- Mengatur HLO menjadi tingkat blok, lalu menggunakan OpenAI Triton.
- Menggunakan Pemancar XLA untuk menurunkan HLO secara progresif ke LLVM IR.
Dokumen ini berfokus pada Pemancar XLA:GPU.
Pembuatan kode berbasis hero
Ada 7 jenis emitter di XLA:GPU. Setiap jenis pemancar sesuai dengan "hero" penggabungan, yaitu operasi terpenting dalam komputasi gabungan yang membentuk pembuatan kode untuk seluruh penggabungan.
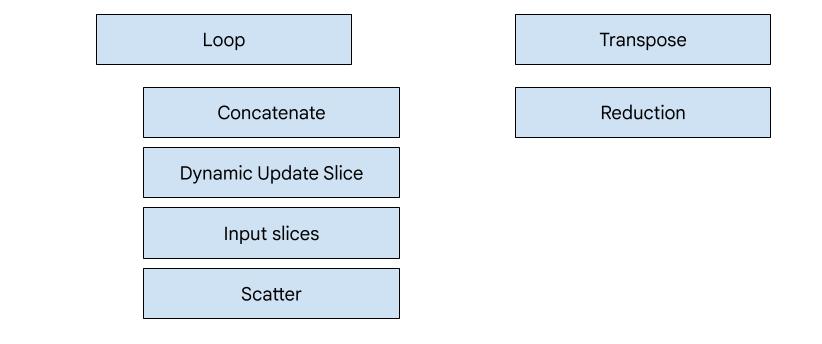
Misalnya, pemancar transpose akan dipilih jika ada
HloTransposeInstruction dalam penggabungan yang memerlukan penggunaan memori bersama untuk
meningkatkan pola baca dan tulis memori. Emitter pengurangan menghasilkan
pengurangan menggunakan pengacakan dan memori bersama. Pemancar loop adalah pemancar default. Jika fusi tidak memiliki hero yang memiliki pemancar khusus, pemancar loop akan digunakan.
Ringkasan umum
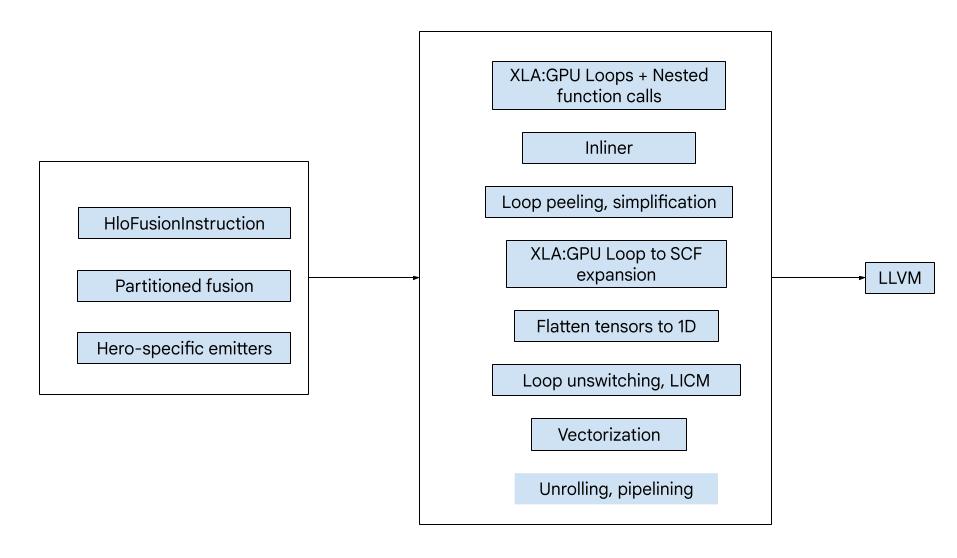
Kode ini terdiri dari blok bangunan besar berikut:
- Partisi komputasi - membagi komputasi penggabungan HLO menjadi fungsi
- Emitter - mengonversi gabungan HLO yang dipartisi ke MLIR (dialek
xla_gpu,tensor,arith,math,scf) - Pipeline kompilasi - mengoptimalkan dan menurunkan IR ke LLVM
Membuat partisi
Lihat computation_partitioner.h.
Instruksi HLO non-elementwise tidak selalu dapat dikeluarkan bersama. Pertimbangkan grafik HLO berikut:
param
|
log
| \
| transpose
| /
add
Jika kita memancarkan ini dalam satu fungsi, log akan diakses pada dua
indeks yang berbeda untuk setiap elemen add. Pemancar lama mengatasi masalah ini dengan menghasilkan log dua kali. Untuk grafik khusus ini, hal ini bukan
masalah, tetapi jika ada beberapa pemisahan, ukuran kode akan bertambah
secara eksponensial.
Di sini, kita menyelesaikan masalah ini dengan mempartisi grafik menjadi beberapa bagian yang dapat dikeluarkan dengan aman sebagai satu fungsi. Kriterianya adalah:
- Petunjuk yang hanya memiliki satu pengguna aman untuk dikeluarkan bersama dengan penggunanya.
- Petunjuk yang memiliki beberapa pengguna aman untuk dikeluarkan bersama dengan penggunanya jika diakses melalui indeks yang sama oleh semua pengguna.
Pada contoh di atas, add dan tranpose mengakses indeks log yang berbeda, sehingga tidak aman untuk memancarkannya bersama-sama.
Oleh karena itu, grafik dipartisi menjadi tiga fungsi (masing-masing hanya berisi satu instruksi).
Hal yang sama berlaku untuk contoh berikut dengan slice dan pad dari add.
Emisi unsur
Lihat elemental_hlo_to_mlir.h.
Emisi elemen membuat loop dan operasi matematika/aritmetika untuk HloInstructions. Sebagian besar, hal ini mudah dilakukan, tetapi ada beberapa hal menarik yang terjadi di sini.
Mengindeks transformasi
Beberapa petunjuk (transpose, broadcast, reshape, slice, reverse, dan
beberapa petunjuk lainnya) murni merupakan transformasi pada indeks: untuk menghasilkan elemen
hasil, kita perlu menghasilkan beberapa elemen input lainnya. Untuk itu, kita dapat
menggunakan kembali indexing_analysis XLA, yang memiliki
fungsi untuk menghasilkan pemetaan output ke input untuk sebuah instruksi.
Misalnya, untuk transpose dari [20,40] ke [40,20], peta pengindeksan berikut akan dihasilkan (satu ekspresi afine per dimensi input; d0 dan d1 adalah dimensi output):
(d0, d1) -> d1
(d0, d1) -> d0
Jadi, untuk petunjuk transformasi indeks murni ini, kita cukup mendapatkan peta, menerapkannya ke indeks output, dan menghasilkan input pada indeks yang dihasilkan.
Demikian pula, operasi pad menggunakan peta dan batasan pengindeksan untuk sebagian besar
penerapannya. pad juga merupakan transformasi pengindeksan dengan beberapa pemeriksaan tambahan untuk melihat apakah kita menampilkan elemen input atau nilai padding.
Tuple
Kami tidak mendukung tuple internal. Kami juga tidak mendukung output tuple
bertumpuk. Semua grafik XLA yang menggunakan fitur ini dapat dikonversi menjadi grafik yang tidak menggunakan fitur ini.
Mengumpulkan
Kami hanya mendukung pengumpulan kanonis yang dihasilkan oleh gather_simplifier.
Fungsi subgrafik
Untuk subgrafik komputasi dengan parameter %p0 hingga %p_n, dan akar subgrafik dengan dimensi r dan jenis elemen (e0 hingga e_m), kita menggunakan tanda tangan fungsi MLIR berikut:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Artinya, kita memiliki satu input tensor per parameter komputasi, satu input indeks per dimensi output, dan satu hasil per output.
Untuk memancarkan fungsi, kita cukup menggunakan pemancar elemen di atas, dan secara rekursif
memancarkan operandanya hingga kita mencapai tepi subgrafik. Kemudian, kita:memancarkan
tensor.extract untuk parameter atau memancarkan func.call untuk subgrafik lainnya
Fungsi entri
Setiap jenis pemancar berbeda dalam cara menghasilkan fungsi entri, yaitu fungsi untuk hero. Fungsi entri berbeda dengan fungsi di atas, karena tidak memiliki indeks sebagai input (hanya ID thread dan blok) dan sebenarnya perlu menulis output di suatu tempat. Untuk emitter loop, hal ini cukup sederhana, tetapi emitter transposisi dan reduksi memiliki logika penulisan yang tidak sepele.
Tanda tangan komputasi entri adalah:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Seperti sebelumnya, %pn adalah parameter komputasi, dan
%rn adalah hasil komputasi. Komputasi entri mengambil
hasil sebagai tensor, tensor.insert memperbaruinya, lalu menampilkannya.
Penggunaan tensor output lainnya tidak diizinkan.
Pipeline kompilasi
Pemancar loop
Lihat loop.h.
Mari pelajari pass terpenting dari pipeline kompilasi MLIR menggunakan HLO untuk fungsi GELU.
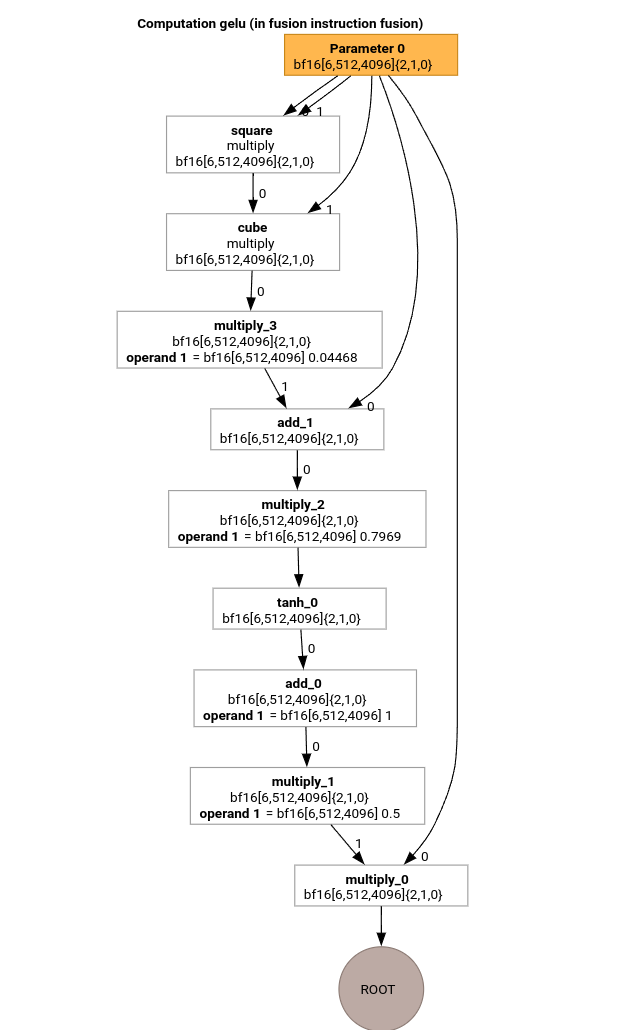
Komputasi HLO ini hanya memiliki operasi per elemen, konstanta, dan siaran. Data akan dipancarkan menggunakan pemancar loop.
Konversi MLIR
Setelah konversi ke MLIR, kita akan mendapatkan xla_gpu.loop yang bergantung pada
%thread_id_x dan %block_id_x serta menentukan loop yang melintasi semua
elemen output secara linear untuk menjamin penulisan yang digabungkan.
Pada setiap iterasi loop ini, kita memanggil
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
untuk menghitung elemen operasi root. Perhatikan bahwa kita hanya memiliki satu fungsi
yang diuraikan untuk @gelu, karena pemartisi tidak mendeteksi tensor yang memiliki 2
atau lebih pola akses yang berbeda.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Setelah @gelu di-inline, kita mendapatkan satu fungsi @main. Fungsi yang sama dapat dipanggil dua kali atau lebih. Dalam hal ini, kita tidak menyisipkan sebaris. Detail selengkapnya tentang aturan penyisipan dapat ditemukan di xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu ke scf konversi
Lihat lower_xla_gpu_to_scf.cc.
xla_gpu.loop merepresentasikan loop bertingkat dengan pemeriksaan batas di dalamnya. Jika variabel induksi loop berada di luar batas domain peta pengindeksan, iterasi ini akan dilewati. Artinya, loop dikonversi menjadi 1 atau lebih operasi scf.for bertingkat dengan scf.if di dalamnya.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Meratakan tensor
Lihat flatten_tensors.cc.
Tensor N-d diproyeksikan ke 1D. Hal ini akan menyederhanakan vektorisasi dan penurunan ke LLVM karena setiap akses tensor kini sesuai dengan cara data diselaraskan dalam memori.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vektorisasi
Lihat vectorize_loads_stores.cc.
Pass menganalisis indeks dalam operasi tensor.extract dan tensor.insert
dan jika dihasilkan oleh xla_gpu.apply_indexing yang mengakses elemen
secara berurutan sehubungan dengan %vector_index dan aksesnya selaras, maka
tensor.extract dikonversi menjadi vector.transfer_read dan diangkat keluar dari
loop.
Dalam kasus khusus ini, ada peta pengindeksan
(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) yang digunakan untuk
menghitung elemen yang akan diekstrak dan disisipkan dalam loop scf.for dari 0 hingga 4.
Oleh karena itu, tensor.extract dan tensor.insert dapat diubah menjadi vektor.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Pembukaan loop
Lihat optimize_loops.cc.
Loop unrolling menemukan loop scf.for yang dapat di-unroll. Dalam hal ini, loop
di atas elemen vektor akan hilang.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Konversi ke LLVM
Kami sebagian besar menggunakan penurunan LLVM standar, tetapi ada beberapa lintasan khusus.
Kita tidak dapat menggunakan penurunan memref untuk tensor, karena kita tidak melakukan buffer pada IR dan ABI kita tidak kompatibel dengan ABI memref. Sebagai gantinya, kita memiliki
penyusutan kustom langsung dari tensor ke LLVM.
- Penurunan tensor dilakukan di lower_tensors.cc.
tensor.extractditurunkan menjadillvm.load,tensor.insertmenjadillvm.store, dengan cara yang jelas. - propagate_slice_indices dan merge_pointers_to_same_slice bersama-sama menerapkan detail penetapan buffer dan ABI XLA: jika dua tensor berbagi slice buffer yang sama, tensor hanya akan diteruskan satu kali. Penerusan ini menghapus duplikat argumen fungsi.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Pemancar transpose
Mari kita lihat contoh yang sedikit lebih rumit.
![]()
Emitter transpose berbeda dari emitter loop hanya dalam cara fungsi entri dibuat.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
Dalam hal ini, kita membuat dua operasi xla_gpu.loop. Yang pertama melakukan
pembacaan gabungan dari input dan menulis hasilnya ke memori bersama.
Tensor memori bersama dibuat menggunakan operasi xla_gpu.allocate_shared.
Setelah thread disinkronkan menggunakan xla_gpu.sync_threads, xla_gpu.loop
kedua membaca elemen dari tensor memori bersama dan melakukan
penulisan gabungan ke output.
Reproducer
Untuk melihat IR setelah setiap langkah pipeline kompilasi, Anda dapat meluncurkan run_hlo_module dengan tanda --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
dengan /tmp/gelu.hlo berisi
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Link ke kode
- Pipeline kompilasi: emitter_base.h
- Pengoptimalan dan penerusan konversi: backends/gpu/codegen/emitters/transforms
- Logika partisi: computation_partitioner.h
- Emitter berbasis hero: backends/gpu/codegen/emitters
- XLA:GPU ops: xla_gpu_ops.td
- Uji kebenaran dan lit: backends/gpu/codegen/emitters/tests