
Analisis pengindeksan HLO adalah analisis alur data yang menjelaskan hubungan elemen satu tensor dengan tensor lainnya melalui "peta pengindeksan". Misalnya, cara indeks output petakan instruksi HLO ke indeks operand instruksi HLO.
Contoh
Untuk siaran dari tensor<20xf32> ke tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
peta pengindeksan dari output ke input adalah (i, j, k) -> (j) untuk i in
[0, 10], j in [0, 20], dan k in [0, 30].
Motivasi
XLA menggunakan beberapa solusi khusus untuk menyimpulkan penggabungan, pemanfaatan operand, dan skema penataan (detail selengkapnya di bawah). Tujuan analisis pengindeksan adalah menyediakan komponen yang dapat digunakan kembali untuk kasus penggunaan tersebut. Analisis pengindeksan dibuat di infrastruktur Affine Map MLIR dan menambahkan semantik HLO.
Menggabungkan
Penalaran tentang penggabungan memori menjadi memungkinkan untuk kasus non-trivial, saat kita mengetahui elemen/slice input mana yang dibaca untuk menghitung elemen output.
Penggunaan Operand
Pemanfaatan operand di XLA menunjukkan seberapa banyak setiap input instruksi digunakan dengan asumsi outputnya digunakan sepenuhnya. Saat ini, pemanfaatan juga tidak dihitung untuk kasus umum. Analisis pengindeksan memungkinkan kita menghitung pemanfaatan secara akurat.
Susunan persegi
Petak/slice adalah subset tensor hiper-rektangular yang diparameterkan oleh offset, ukuran, dan langkah. Propagasi petak adalah cara untuk menghitung parameter petak produsen/konsumen operasi menggunakan parameter petak operasi itu sendiri. Sudah ada library yang melakukannya untuk softmax dan dot. Penyebaran petak dapat dibuat lebih generik dan andal jika dinyatakan melalui peta pengindeksan.
Peta pengindeksan
Peta pengindeksan adalah kombinasi dari
- fungsi yang dinyatakan secara simbolis yang memetakan setiap elemen dari satu tensor
Ake rentang elemen dalam tensorB; - batasan pada argumen fungsi yang valid, termasuk domain fungsi.
Argumen fungsi dibagi menjadi 3 kategori untuk mengomunikasikan sifatnya dengan lebih baik:
Variabel dimensi tensor
Aatau petak GPU yang dipetakan; nilai diketahui secara statis. Elemen indeks juga disebut variabel dimensi.Variabel rentang. Elemen ini menentukan pemetaan satu-ke-banyak dan menentukan sekumpulan elemen dalam
Byang digunakan untuk menghitung satu nilaiA; nilai diketahui secara statis. Dimensi kontraksi perkalian matriks adalah contoh variabel rentang.variabel runtime yang hanya diketahui selama eksekusi. Misalnya, argumen indeks dari operasi gather.
Hasil fungsi adalah indeks tensor B target.
Singkatnya, fungsi pengindeksan dari tensor A ke tensor B untuk operasi x
adalah
map_ab(index in A, range variables, runtime variables) -> index in B.
Untuk memisahkan jenis argumen pemetaan dengan lebih baik, kami menuliskannya sebagai:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Misalnya, mari kita lihat peta pengindeksan untuk operasi pengurangan
f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
untuk memetakan elemen
inkeout, fungsi kita dapat dinyatakan sebagai(d0, d1, d2, d3) -> (d1, d2). Batasan variabeld0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]ditentukan oleh bentukin.Untuk memetakan elemen
outkein:outhanya memiliki dua dimensi, dan pengurangan memperkenalkan dua variabel rentang yang mencakup pengurangan dimensi. Dengan demikian, fungsi pemetaan adalah(d0, d1)[s0, s1] -> (s0, d0, d1, s1), dengan(d0, d1)adalah indeksout.s0,s1adalah rentang yang ditentukan oleh semantik operasi dan dimensi rentang 0 dan 3 tensorin. Batasannya adalahd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
Penting untuk diperhatikan bahwa dalam sebagian besar skenario, kita tertarik untuk memetakan dari elemen output. Untuk komputasi
C = op1(A, B)
E = op2(C, D)
Kita dapat membahas "pengindeksan B" yang berarti "pemetaan elemen E ke dalam
elemen B". Hal ini mungkin berlawanan dengan intuisi dibandingkan dengan jenis
analisis alur data lainnya yang bekerja dari input ke output.
Batasan pada variabel memungkinkan peluang pengoptimalan dan membantu pembuatan kode. Dalam dokumentasi dan batasan penerapan juga disebut sebagai domain karena menentukan semua kombinasi atau nilai argumen yang valid dari fungsi pemetaan. Untuk banyak operasi, batasan hanya menjelaskan dimensi tensor, tetapi untuk beberapa operasi, batasan mungkin lebih rumit; lihat contoh di bawah.
Dengan memiliki fungsi dan batasan argumen yang dinyatakan secara simbolis dan dapat menggabungkan fungsi dan batasan, kita dapat menghitung pemetaan pengindeksan yang ringkas untuk komputasi besar yang arbitrer (penggabungan).
Ekspresivitas fungsi dan batasan simbolis adalah keseimbangan antara kompleksitas penerapan dan keuntungan pengoptimalan yang kita dapatkan dari representasi yang lebih presisi. Untuk beberapa operasi HLO, kami hanya memperkirakan pola akses.
Penerapan
Karena kita ingin meminimalkan penghitungan ulang, kita memerlukan library untuk penghitungan simbolis. XLA sudah bergantung pada MLIR, jadi kita menggunakan mlir::AffineMap daripada menulis library aritmatika simbolis lainnya.
AffineMap standar terlihat seperti
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap memiliki dua jenis parameter: dimensi dan simbol.
Dimensi sesuai dengan variabel dimensi d; simbol sesuai dengan
variabel rentang r dan variabel runtime rt. AffineMap tidak berisi
metadata apa pun tentang batasan parameter, jadi kita harus menyediakannya
secara terpisah.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ mengenkode batasan kotak inklusif untuk variabel dimensi d dari peta pengindeksan, yang biasanya bertepatan dengan bentuk tensor output untuk operasi seperti transpose, reduce, elementwise, dot, tetapi ada beberapa pengecualian seperti HloConcatenateInstruction.
range_vars_ semua nilai yang diambil oleh s variabel rentang. Variabel rentang diperlukan saat beberapa nilai diperlukan untuk menghitung satu elemen tensor yang dipetakan, misalnya, untuk peta pengindeksan output->input dari pengurangan atau peta input->output untuk siaran.
rt_vars_ mengenkode nilai yang memungkinkan saat runtime. Misalnya, offset bersifat
dinamis untuk HloDynamicSliceInstruction 1D. RTVar yang sesuai akan memiliki nilai yang mungkin antara 0 dan tensor_size - slice_size - 1.
constraints_ menangkap hubungan antar-nilai dalam bentuk
<expression> in <range>, misalnya d0 + s0 in [0, 20]. Bersama dengan
Variable.bounds, keduanya menentukan "domain" fungsi pengindeksan.
Mari kita pelajari contoh untuk memahami apa arti semua hal di atas.
Mengindeks Maps untuk Operasi yang Tidak Digabungkan
Elementwise
Untuk operasi per elemen, peta pengindeksan adalah identitas.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
Peta input ke output output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Peta input ke output p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Siaran
Penyiaran berarti beberapa dimensi akan dihapus saat kita memetakan output ke input dan ditambahkan saat kita memetakan input ke output.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
Peta output ke input:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
Peta input ke output:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Perhatikan bahwa sekarang kita memiliki variabel rentang s di sisi kanan untuk pemetaan input ke output. Itulah simbol yang merepresentasikan rentang nilai.
Misalnya, dalam kasus khusus ini, setiap elemen input dengan indeks d0 dipetakan ke slice output 10x1x30.
Iota
Iota tidak memiliki operand tensor input, sehingga tidak ada argumen indeks input.
iota = f32[2,4] iota(), dimensions={1}
Output ke peta input:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Peta input ke output:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice memiliki offset yang hanya diketahui saat runtime.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
Peta input ke output dari ds ke src:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Perhatikan bahwa sekarang kita memiliki rt di sisi kanan untuk pemetaan input ke output.
Itulah simbol yang merepresentasikan nilai runtime. Misalnya, dalam kasus
tertentu ini untuk setiap elemen output dengan indeks d0, d1, d2, kita
mengakses offset slice of1, of2, dan of3 untuk menghitung indeks input.
Interval untuk variabel runtime berasal dari asumsi bahwa seluruh slice tetap dalam batas.
Peta input ke output untuk of1, of2, dan of3:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
Peta output ke input untuk src tidak penting. Hal ini dapat dibuat lebih akurat dengan membatasi domain ke indeks yang tidak diperbarui, tetapi saat ini pemetaan pengindeksan tidak mendukung batasan ketidaksetaraan.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
Peta input ke output untuk upd:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Perhatikan bahwa sekarang kita memiliki rt0 dan rt1 yang merepresentasikan nilai runtime. Dalam kasus khusus ini, untuk setiap elemen output dengan indeks d0, d1, kita mengakses offset slice of1 dan of2 untuk menghitung indeks input. Interval
untuk variabel runtime berasal dari asumsi bahwa seluruh
slice tetap dalam batas.
Peta output ke input untuk of1 dan of2:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Berkumpul
Hanya pengumpulan yang disederhanakan yang didukung. Lihat gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
Peta input ke output untuk operand:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Perhatikan bahwa sekarang kita memiliki simbol rt yang merepresentasikan nilai runtime.
Peta input ke output untuk indices:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
Variabel rentang s0 menunjukkan bahwa kita memerlukan seluruh baris (d0, *) tensor
indices untuk menghitung elemen output.
Transpose
Peta pengindeksan untuk transposisi adalah permutasi dimensi input/output.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
Peta output ke input:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
Peta input ke output:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Terbalik
Peta pengindeksan untuk pembalikan mengubah dimensi yang dikembalikan ke upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
Peta output ke input:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
Peta input ke output:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
Pengurangan variadik memiliki beberapa input dan beberapa nilai awal, peta dari output ke input menambahkan dimensi yang dikurangi.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
Pemetaan output ke input:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Peta input ke output:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
Pengindeksan dari output ke input untuk slice menghasilkan peta pengindeksan berlangkah yang valid untuk setiap elemen output. Pemetaan dari input ke output dibatasi ke rentang elemen input yang berjarak.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
Peta output ke input:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
Peta input ke output:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Membentuk ulang
Pembentukan ulang hadir dalam berbagai jenis.
Menciutkan bentuk
Ini adalah perubahan bentuk "linearisasi" dari N-D ke 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
Peta output ke input:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Peta input ke output:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Memperluas bentuk
Ini adalah operasi "ciutkan bentuk" terbalik, yang mengubah bentuk input 1D menjadi output N-D.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
Peta output ke input:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Peta input ke output:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Pembentukan ulang generik
Ini adalah operasi pembentukan ulang yang tidak dapat direpresentasikan sebagai satu bentuk perluasan atau ciutkan. Komponen hanya dapat ditampilkan sebagai komposisi dari 2 atau lebih bentuk perluas atau ciutkan.
Contoh 1: Linearisasi-delinearisasi.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Pembentukan ulang ini dapat direpresentasikan sebagai komposisi bentuk ciut dari
tensor<4x8xf32> ke tensor<32xf32>, lalu perluasan bentuk ke
tensor<2x4x4xf32>.
Peta output ke input:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
Peta input ke output:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Contoh 2: Subbentuk yang diluaskan dan diciutkan
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Pembentukan ulang ini dapat direpresentasikan sebagai komposisi dua pembentukan ulang. Yang pertama menciutkan dimensi terluar tensor<4x8x12xf32> menjadi tensor<32x12xf32> dan yang kedua meluaskan dimensi terdalam tensor<32x12xf32> menjadi tensor<32x3x4xf32>.
Peta output ke input:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
Peta input ke output:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
Operasi bitcast dapat direpresentasikan sebagai urutan transpose-reshape-transpose. Oleh karena itu, peta pengindeksannya hanyalah komposisi peta pengindeksan untuk urutan ini.
Concatenate
Pemetaan output ke input untuk concat ditentukan untuk semua input, tetapi dengan domain yang tidak tumpang-tindih, yaitu hanya satu input yang akan digunakan dalam satu waktu.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
Pemetaan output ke input:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
Input ke peta output:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
Memetakan indeks untuk dot sangat mirip dengan indeks untuk reduce.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
Pemetaan output ke input:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
Input ke peta output:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
Pengindeksan PadOp adalah kebalikan dari pengindeksan SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
Konfigurasi padding 1_4_1x4_8_0 menunjukkan lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
Pemetaan output ke input:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
ReduceWindow di XLA juga melakukan padding. Oleh karena itu, peta pengindeksan dapat dihitung sebagai komposisi pengindeksan ReduceWindow yang tidak melakukan padding dan pengindeksan PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
Pemetaan output ke input:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Mengindeks Peta untuk Fusion
Peta pengindeksan untuk operasi penggabungan adalah komposisi peta pengindeksan untuk setiap operasi dalam cluster. Beberapa input dapat dibaca beberapa kali dengan pola akses yang berbeda.
Satu input, beberapa peta pengindeksan
Berikut adalah contoh untuk p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Pemetaan pengindeksan output ke input untuk p0 adalah (d0, d1) -> (d0, d1) dan
(d0, d1) -> (d1, d0). Artinya, untuk menghitung satu elemen
output, kita mungkin perlu membaca parameter input dua kali.
Satu input, peta pengindeksan yang dide-duplikasi
![]()
Terkadang peta pengindeksan sebenarnya sama, meskipun tidak langsung terlihat.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
Dalam hal ini, peta pengindeksan output-ke-input untuk p0 hanyalah
(d0, d1, d2) -> (d2, d0, d1).
Softmax
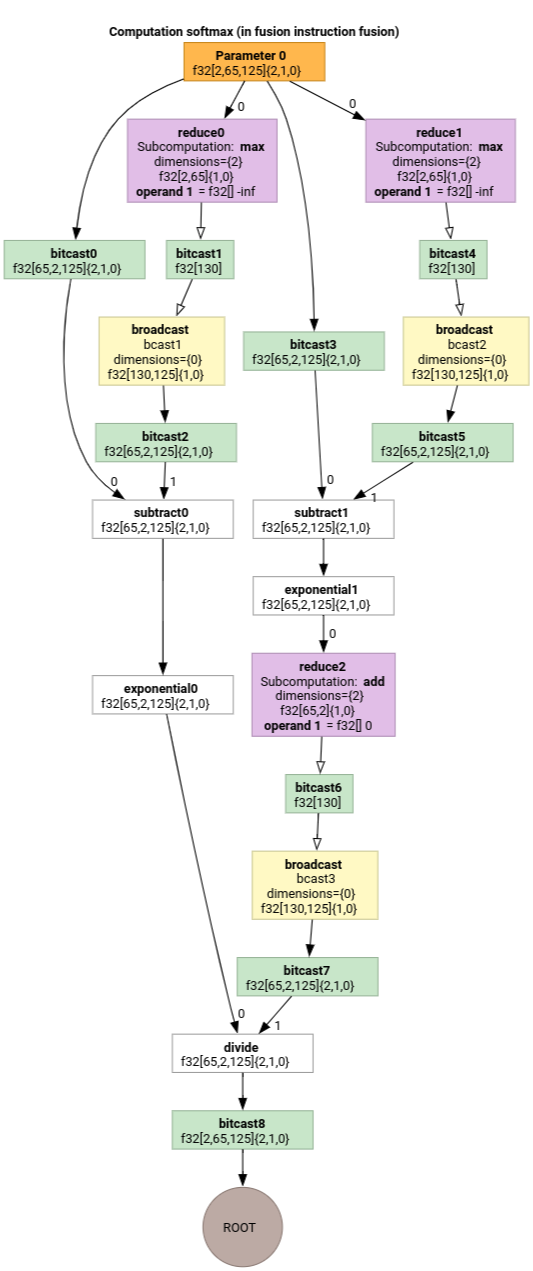
Pemetaan pengindeksan output ke input untuk parameter 0 untuk softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
dan
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
dengan s0 mengacu pada dimensi input paling dalam.
Untuk contoh lainnya, lihat indexing_analysis_test.cc.
Penyederhana Peta Pengindeksan
Penyederhana default untuk mlir::AffineMap di upstream tidak dapat membuat asumsi apa pun tentang rentang dimensi/simbol. Oleh karena itu, fungsi ini tidak dapat menyederhanakan ekspresi dengan mod dan div secara efisien.
Kita dapat memanfaatkan pengetahuan tentang batas bawah dan atas sub-ekspresi dalam peta affine untuk menyederhanakannya lebih lanjut.
Penyederhana dapat menulis ulang ekspresi berikut.
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)untuk d di[0, 6] x [0, 14]menjadi(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)untukdi in [0, 9]menjadi(d0, d1, d2) -> (d0, d1, d2).(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)untukd_i in [0, 9]menjadi(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8).(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)untuk d di[0, 9] x [0, 10]menjadi(d0, d1) -> (d0).
Penyederhanaan peta pengindeksan memungkinkan kita memahami bahwa beberapa perubahan bentuk yang dirantai di HLO saling membatalkan.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
Setelah komposisi peta pengindeksan dan penyederhanaannya, kita akan mendapatkan
(d0, d1, d2) -> (d0, d1, d2).
Penyederhanaan peta pengindeksan juga menyederhanakan batasan.
- Batasan jenis
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundditulis ulang sebagaiupdated_lower_bound <= affine_expr <= updated_upped_bound. - Batasan yang selalu terpenuhi, misalnya
d0 + s0 in [0, 20]untukd0 in [0, 5]dans0 in [1, 3]akan dihilangkan. - Ekspresi affine dalam batasan dioptimalkan sebagai peta affine pengindeksan di atas.
Untuk contoh lainnya, lihat indexing_map_test.cc.