
تحلیل شاخصگذاری HLO یک تحلیل جریان داده است که چگونگی ارتباط عناصر یک تانسور با تانسور دیگر را از طریق «نقشههای شاخصگذاری» توصیف میکند. برای مثال، چگونه شاخصهای خروجی یک دستورالعمل HLO به شاخصهای عملوندهای دستورالعمل HLO نگاشت میشوند.
مثال
برای پخش از tensor<20xf32> به tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
نقشه اندیسگذاری از خروجی به ورودی برای i in [0, 10] ، j in [0, 20] و k in [0, 30] (i, j, k) -> (j) است.
انگیزه
XLA از چندین راهحل سفارشی برای استدلال در مورد ادغام، استفاده از عملوند و طرحهای کاشیکاری استفاده میکند (جزئیات بیشتر در زیر آمده است). هدف از تحلیل شاخصگذاری، ارائه یک مؤلفه قابل استفاده مجدد برای چنین مواردی است. تحلیل شاخصگذاری بر اساس زیرساختهای سفارشی SymbolicExpr و SymbolicMap XLA ساخته شده و معانی HLO را اضافه میکند.
به هم پیوستن
استدلال در مورد ادغام حافظه برای موارد غیر بدیهی امکانپذیر میشود، زمانی که بدانیم چه عناصر/برشهایی از ورودیها برای محاسبه یک عنصر از خروجی خوانده میشوند.
استفاده از عملوند
میزان استفاده از عملوند در XLA نشان میدهد که هر ورودی دستورالعمل با فرض استفاده کامل از خروجی آن، چقدر استفاده میشود. در حال حاضر، میزان استفاده برای یک مورد کلی نیز محاسبه نمیشود. تجزیه و تحلیل اندیسگذاری به ما امکان میدهد میزان استفاده را دقیقاً محاسبه کنیم.
کاشی کاری
یک کاشی/برش، زیرمجموعهای فوقمستطیلی از یک تانسور پارامتری شده توسط آفستها، اندازهها و گامها است. انتشار کاشی روشی برای محاسبه پارامترهای کاشی تولیدکننده/مصرفکنندهی op با استفاده از پارامترهای کاشیکاری خود op است. در حال حاضر کتابخانهای وجود دارد که این کار را برای softmax و dot انجام میدهد. انتشار کاشی میتواند عمومیتر و قویتر شود اگر از طریق نقشههای اندیسگذاری بیان شود.
نقشه نمایه سازی
یک نقشه نمایه سازی ترکیبی از
- تابعی نمادین که هر عنصر از یک تنسور
Aرا به بازههایی از عناصر در تنسورBنگاشت میکند؛ - محدودیتهای مربوط به آرگومانهای معتبر تابع، از جمله دامنه تابع.
آرگومانهای تابع برای اینکه ماهیتشان بهتر منتقل شود، به ۳ دسته تقسیم میشوند:
متغیرهای بُعدِ تانسور
Aیا یک شبکه GPU که از آن نگاشت میکنیم؛ مقادیر به صورت ایستا شناخته میشوند. عناصر اندیس، متغیرهای بُعد نیز نامیده میشوند.متغیرهای محدوده . آنها یک نگاشت یک به چند را تعریف میکنند و مجموعهای از عناصر را در
Bمشخص میکنند که برای محاسبه یک مقدار واحد ازAاستفاده میشوند؛ مقادیر به صورت ایستا شناخته میشوند. بُعد قراردادی ضرب ماتریس، نمونهای از یک متغیر محدوده است.متغیرهای زمان اجرا که فقط در طول اجرا شناخته میشوند. به عنوان مثال، آرگومان indexها در عملیات جمع آوری .
نتیجه تابع، اندیسی از تانسور هدف B است.
به طور خلاصه، یک تابع اندیسگذاری از تنسور A به تنسور B برای عملیات x به صورت زیر است:
map_ab(index in A, range variables, runtime variables) -> index in B
برای تفکیک بهتر انواع آرگومانهای نگاشت، آنها را به صورت زیر مینویسیم:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
برای مثال، بیایید نگاهی به نقشههای اندیسگذاری برای عملیات کاهش f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3} :
برای نگاشت عناصر
inبهout، تابع ما میتواند به صورت(d0, d1, d2, d3) -> (d1, d2)بیان شود. محدودیتهای متغیرهایd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]با شکلinتعریف میشوند.برای نگاشت عناصر
outبهin:outفقط دو بعد دارد و reduce دو متغیر محدوده را معرفی میکند که ابعاد کاهش را پوشش میدهند. بنابراین تابع نگاشت به(d0, d1)[s0, s1] -> (s0, d0, d1, s1)است، که در آن(d0, d1)اندیسoutاست.s0وs1محدودههایی هستند که توسط معانی عملیات تعریف میشوند و ابعاد دهانه 0 و 3 تانسورinرا تشکیل میدهند. محدودیتها عبارتند ازd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
لازم به ذکر است که در بیشتر سناریوها، ما به نگاشت از عناصر خروجی علاقهمندیم. برای محاسبه
C = op1(A, B)
E = op2(C, D)
میتوانیم در مورد «ایندکسگذاری B» به معنای «نگاشت عناصر E به عناصر B » صحبت کنیم. این ممکن است در مقایسه با سایر انواع تحلیل جریان داده که از ورودی به سمت خروجیها کار میکنند، متناقض باشد.
محدودیتهای روی متغیرها، فرصتهای بهینهسازی را فراهم میکنند و به تولید کد کمک میکنند. در مستندات و پیادهسازی، به محدودیتها دامنه نیز گفته میشود، زیرا تمام ترکیبات معتبر یا مقادیر آرگومان تابع نگاشت را تعریف میکنند. برای بسیاری از عملیات، محدودیتها به سادگی ابعاد تانسورها را توصیف میکنند، اما برای برخی از عملیات ممکن است پیچیدهتر باشند؛ به مثالهای زیر مراجعه کنید.
با داشتن توابع و محدودیتهای آرگومان که به صورت نمادین بیان شدهاند و توانایی ترکیب توابع و محدودیتها، میتوانیم یک نگاشت اندیسگذاری فشرده برای یک محاسبه بزرگ دلخواه (فیوژن) محاسبه کنیم.
بیانپذیری تابع نمادین و محدودیتها، تعادلی بین پیچیدگی پیادهسازی و دستاوردهای بهینهسازی است که از داشتن یک نمایش دقیقتر به دست میآوریم. برای برخی از عملیات HLO، الگوهای دسترسی را فقط به صورت تقریبی ثبت میکنیم.
پیادهسازی
برای به حداقل رساندن محاسبات مجدد، به یک چارچوب برای محاسبات نمادین نیاز داریم. این چارچوب به صورت SymbolicExpr و SymbolicMap پیادهسازی شده است.
یک SymbolicMap معمولی به شکل زیر است:
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
SymbolicMap دو نوع پارامتر دارد: ابعاد و نمادها . ابعاد مربوط به متغیرهای بُعد d هستند؛ نمادها مربوط به متغیرهای محدوده r و متغیرهای زمان اجرا rt هستند. SymbolicMap هیچ ابردادهای در مورد محدودیتهای پارامترها ندارد، بنابراین باید آنها را جداگانه ارائه دهیم.
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
// struct Interval represents a closed interval [lower_bound, upper_bound].
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
SymbolicMap symbolic_map_;
// A dimension variable represents a dimension of a tensor or a GPU grid.
// Dimension variables correspond to the dimensions of the `symbolic_map_`.
std::vector<Variable> dim_vars_;
// A range variable represents a range of values, e.g. to compute a single
// element of the reduction's result we need a range of values from the input
// tensor. Range variables correspond to the front portion of the
// symbols in `symbolic_map_`.
std::vector<Variable> range_vars_;
// A runtime variable represents a runtime symbol, e.g. a dynamic offset in of
// a HLO dynamic-update-slice op. Runtime variables correspond to the back
// portion of the symbols in `symbolic_map_`.
std::vector<Variable> rt_vars_;
// Inequality constraints for symbolic expressions. They restrict the feasible
// set for the domain of the indexing map. It contains symbolic expressions
// other than SymbolicDimExpr and SymbolicSymbolExpr.
llvm::MapVector<SymbolicExpr, Interval> constraints_;
};
مرجع کد: indexing_map.h#L114
dim_vars_ محدودیتهای جعبهای فراگیر را برای متغیرهای بُعد d از نگاشت نمایهسازی کدگذاری میکند، که معمولاً با شکل تانسور خروجی برای عملیاتی مانند transpose، reduce، elementwise، dot مطابقت دارد، اما استثنائاتی مانند HloConcatenateInstruction نیز وجود دارد.
range_vars_ تمام مقادیری که متغیرهای محدوده میگیرند . متغیرهای محدوده زمانی مورد نیاز هستند که برای محاسبه یک عنصر از تانسوری که از آن نگاشت میکنیم، به چندین مقدار نیاز باشد، مثلاً برای نگاشت اندیسگذاری خروجی به ورودی کاهشها یا نگاشت ورودی به خروجی برای پخشها.
rt_vars_ مقادیر ممکن را در زمان اجرا کدگذاری میکند. برای مثال، آفست برای یک HloDynamicSliceInstruction یک بعدی پویا است. RTVar مربوطه مقادیر ممکنی بین 0 و tensor_size - slice_size - 1 خواهد داشت.
constraints_ روابط بین مقادیر را به شکل <expression> in <range> ثبت میکنند، مثلاً d0 + s0 in [0, 20] . آنها به همراه Variable.bounds "دامنه" تابع اندیسگذاری را تعریف میکنند.
بیایید با مثال بررسی کنیم تا بفهمیم همه موارد فوق در واقع به چه معناست.
فهرستبندی نقشهها برای عملیاتهای غیرمتمرکز
المنتوایز
برای عملیات عنصرمحور، نقشه نمایهسازی یک هویت است.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
خروجی به ورودی نگاشت output -> p0 :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
ورودی به خروجی را نگاشت میکند p0 -> output :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
پخش
پخش سراسری به این معنی است که برخی از ابعاد هنگام نگاشت خروجی به ورودی حذف و هنگام نگاشت ورودی به خروجی اضافه میشوند.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
نقشه خروجی به ورودی:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
نقشه ورودی به خروجی:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
توجه داشته باشید که اکنون متغیرهای محدوده s را در سمت راست برای نگاشت ورودی به خروجی داریم. اینها نمادهایی هستند که محدوده مقادیر را نشان میدهند. برای مثال، در این مورد خاص، هر عنصر ورودی با اندیس d0 به یک برش 10x1x30 از خروجی نگاشت میشود.
یوتا
آیوتا هیچ عملوند تانسور ورودی ندارد، بنابراین هیچ آرگومان ورودی برای اندیس وجود ندارد.
iota = f32[2,4] iota(), dimensions={1}
خروجی به نقشه ورودی:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
نقشه ورودی به خروجی:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
داینامیک اسلایس
DynamicSlice آفستهایی دارد که فقط در زمان اجرا شناخته میشوند.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
نگاشت خروجی به ورودی از ds به src :
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
توجه داشته باشید که اکنون rt را در سمت راست برای نگاشت ورودی به خروجی داریم. اینها نمادهایی هستند که مقادیر زمان اجرا را نشان میدهند. برای مثال، در این مورد خاص برای هر عنصر خروجی با اندیسهای d0, d1, d2 به آفستهای برش of1 ، of2 و of3 برای محاسبه اندیس ورودی دسترسی داریم. فواصل متغیرهای زمان اجرا با فرض اینکه کل برش در محدودهها باقی میماند، بدست میآیند.
نگاشت خروجی به ورودی برای of1 ، of2 و of3 :
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
داینامیک آپدیت اسلایس
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
نگاشت خروجی به ورودی برای src بدیهی است. میتوان با محدود کردن دامنه به شاخصهای بهروزرسانی نشده، آن را دقیقتر کرد، اما در حال حاضر، نگاشتهای شاخصگذاری از محدودیتهای نابرابری پشتیبانی نمیکنند.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
نگاشت خروجی به ورودی برای upd :
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
توجه داشته باشید که اکنون rt0 و rt1 داریم که مقادیر زمان اجرا را نشان میدهند. در این مورد خاص، برای هر عنصر خروجی با اندیسهای d0, d1 به آفستهای برش of1 و of2 برای محاسبه اندیس ورودی دسترسی داریم. فواصل متغیرهای زمان اجرا با فرض اینکه کل برش در محدوده باقی میماند، بدست میآیند.
نگاشت خروجی به ورودی برای of1 و of2 :
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
جمع آوری
فقط از collect سادهشده پشتیبانی میشود. به Gather_simplifier.h مراجعه کنید.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
نگاشت خروجی به ورودی برای operand :
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
توجه داشته باشید که اکنون نمادهای rt داریم که مقادیر زمان اجرا را نشان میدهند.
نقشه خروجی به ورودی برای indices :
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
متغیر محدوده s0 نشان میدهد که برای محاسبه یک عنصر از خروجی، به کل ردیف (d0, *) از تانسور indices نیاز داریم.
انتقال
نقشه اندیسگذاری برای ترانهاده، یک جایگشت از ابعاد ورودی/خروجی است.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
نقشه خروجی به ورودی:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
نقشه ورودی به خروجی:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
معکوس
نگاشت اندیسگذاری برای تغییر معکوس، ابعاد برگشتی را به upper_bound(d_i) - d_i تغییر میدهد:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
نقشه خروجی به ورودی:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
نقشه ورودی به خروجی:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(متغیر)کاهش
کاهش متغیر چندین ورودی و چندین مقدار اولیه دارد، نگاشت از خروجی به ورودی، ابعاد کاهشیافته را اضافه میکند.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
نقشههای خروجی به ورودی:
-
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
نقشههای ورودی به خروجی:
-
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
برش
اندیسگذاری از خروجی به ورودی برای برش، منجر به یک نقشه اندیسگذاری گامبهگام میشود که برای هر عنصر خروجی معتبر است. نگاشت از ورودی به خروجی به محدودهای گامبهگام از عناصر موجود در ورودی محدود میشود.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
نقشه خروجی به ورودی:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
نقشه ورودی به خروجی:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
تغییر شکل
تغییر شکلها طعمهای مختلفی دارند.
شکل جمع شونده
این یک تغییر شکل "خطی" از ND به 1D است.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
نقشه خروجی به ورودی:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
نقشه ورودی به خروجی:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
شکل را گسترش دهید
این یک عملیات معکوس «شکل فروپاشی» است که ورودی یک بعدی را به خروجی ND تغییر شکل میدهد.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
نقشه خروجی به ورودی:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
نقشه ورودی به خروجی:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
تغییر شکل عمومی
اینها گزینههای تغییر شکل هستند که نمیتوان آنها را به صورت یک شکل باز یا بسته نمایش داد. آنها فقط میتوانند به صورت ترکیبی از دو یا چند شکل باز یا بسته نمایش داده شوند.
مثال ۱: خطیسازی-خطزدایی.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
این تغییر شکل را میتوان به صورت ترکیبی از فروپاشی شکل tensor<4x8xf32> به tensor<32xf32> و سپس بسط شکل به tensor<2x4x4xf32> نمایش داد.
نقشه خروجی به ورودی:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
نقشه ورودی به خروجی:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
مثال ۲: زیرشکلهای باز و بسته
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
این تغییر شکل را میتوان به صورت ترکیبی از دو تغییر شکل نشان داد. اولی، بیرونیترین ابعاد tensor<4x8x12xf32> را به tensor<32x12xf32> تبدیل میکند و دومی، درونیترین بعد tensor<32x12xf32> را به tensor<32x3x4xf32> بسط میدهد.
نقشه خروجی به ورودی:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
نقشه ورودی به خروجی:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
بیتکست
یک عملیات بیتکست را میتوان به صورت دنبالهای از transpose-reshape-transpose نمایش داد. بنابراین، نقشههای اندیسگذاری آن فقط ترکیبی از نقشههای اندیسگذاری برای این دنباله هستند.
الحاق کردن
نگاشت خروجی به ورودی برای concat برای همه ورودیها تعریف شده است، اما با دامنههای غیر همپوشانی، یعنی فقط یکی از ورودیها در یک زمان استفاده خواهد شد.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
خروجی به ورودیها نگاشت میشوند:
-
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
ورودیها برای خروجی نقشهها:
-
outputp0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
نقطه
نقشههای فهرستبندی برای dot بسیار شبیه به نقشههای reduce هستند.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
خروجی به ورودیها نگاشت میشوند:
- خروجی -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- خروجی -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
ورودیها برای خروجی نقشهها:
- خروجی p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> خروجی:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
پد
نمایهسازی PadOp معکوس نمایهسازی SliceOp است.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
پیکربندی padding به صورت 1_4_1x4_8_0 نشان دهندهی lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1 است.
نقشههای خروجی به ورودی:
- خروجی -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- خروجی -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
کاهش پنجره
ReduceWindow در XLA نیز عمل padding را انجام میدهد. بنابراین، نقشههای نمایهسازی را میتوان به عنوان ترکیبی از نمایهسازی ReduceWindow که هیچ padding انجام نمیدهد و نمایهسازی PadOp محاسبه کرد.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
نقشههای خروجی به ورودی:
-
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
فهرستبندی نقشهها برای فیوژن
نقشه شاخصگذاری برای عملیات ترکیبی، ترکیبی از نقشههای شاخصگذاری برای هر عملیات در خوشه است. ممکن است برخی از ورودیها چندین بار با الگوهای دسترسی متفاوت خوانده شوند.
یک ورودی، چندین نقشه نمایهسازی
در اینجا مثالی برای p0 + transpose(p0) آورده شده است.
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
نگاشتهای اندیسگذاری خروجی به ورودی برای p0 (d0, d1) -> (d0, d1) و (d0, d1) -> (d1, d0) خواهد بود. این بدان معناست که برای محاسبه یک عنصر از خروجی، ممکن است لازم باشد پارامتر ورودی را دو بار بخوانیم.
یک ورودی، نقشه نمایهسازی بدون تکرار

مواردی وجود دارد که نقشههای نمایهسازی در واقع یکسان هستند، حتی اگر فوراً آشکار نباشند.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
نگاشت اندیسگذاری خروجی به ورودی برای p0 در این مورد فقط به صورت (d0, d1, d2) -> (d2, d0, d1) است.
سافت مکس
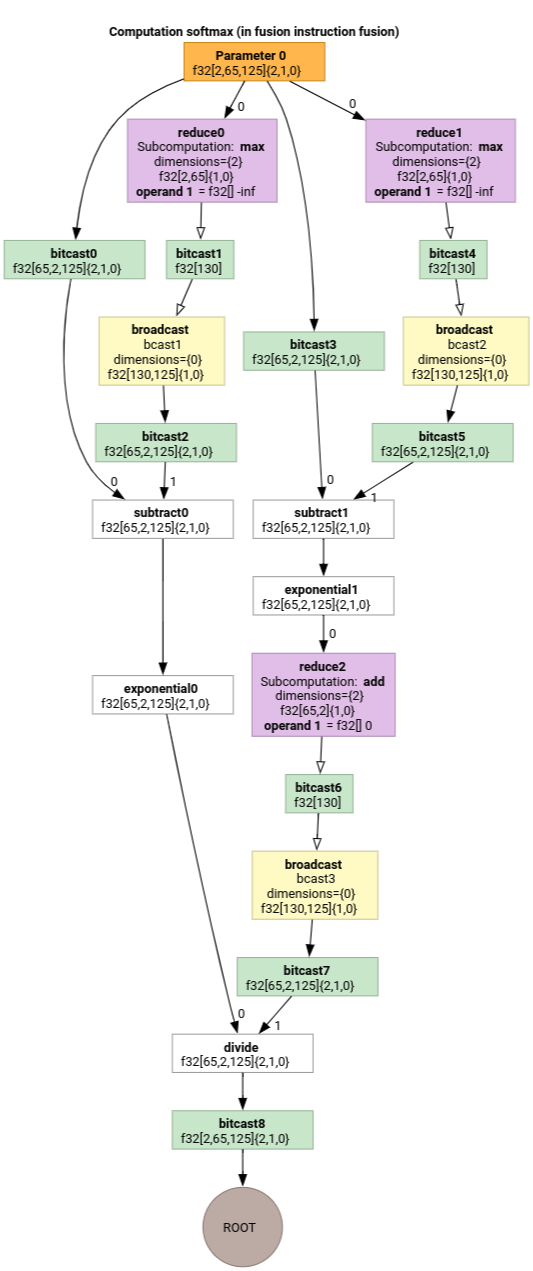
نگاشتهای اندیسگذاری خروجی به ورودی برای parameter 0 برای softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
و
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
که در آن s0 به درونیترین بُعد ورودی اشاره دارد.
برای مثالهای بیشتر به indexing_analysis_test.cc مراجعه کنید.
سادهسازی نقشه نمایهسازی
ما میتوانیم از دانش مربوط به کرانهای پایین و بالای زیرعبارات در نگاشتهای نمادین برای سادهسازی بیشتر آنها استفاده کنیم.
سادهسازی نقشه شاخصگذاری میتواند عبارات زیر را بازنویسی کند.
-
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)برای d در[0, 6] x [0, 14]میشود(d0, d1) -> (d0, d1) -
(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)برایdi in [0, 9]میشود(d0, d1, d2) -> (d0, d1, d2). -
(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)برایd_i in [0, 9]میشود(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8). -
(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)برای d در[0, 9] x [0, 10]میشود(d0, d1) -> (d0).
این به ما اجازه میدهد تا درک کنیم که برخی از تغییر شکلهای زنجیرهای در HLO یکدیگر را خنثی میکنند. برای مثال:
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
پس از ترکیب نقشههای نمایهسازی و سادهسازی آنها، نقشه زیر را خواهیم داشت:
(d0, d1, d2) -> (d0, d1, d2) .
سادهسازی نقشه شاخصگذاری، محدودیتها را نیز ساده میکند.
- محدودیتهایی از نوع
lower_bound <= symbolic_expr (floordiv, ceildiv, +, -, *, mod, min, max) constant <= upper_boundبه صورتupdated_lower_bound <= symbolic_expr <= updated_upped_boundبازنویسی میشوند. - محدودیتهایی که همیشه برقرار هستند، مثلاً
d0 + s0 in [0, 20]برایd0 in [0, 5]وs0 in [1, 3]حذف میشوند. - عبارات نمادین در محدودیتها به صورت نگاشت نمادین اندیسگذاری بالا بهینهسازی میشوند.
برای مثالهای بیشتر به indexing_map_test.cc مراجعه کنید.