
การวิเคราะห์การจัดทำดัชนี HLO คือการวิเคราะห์โฟลว์ของข้อมูล ที่อธิบายว่าองค์ประกอบของเทนเซอร์หนึ่งๆ เกี่ยวข้องกับอีกเทนเซอร์หนึ่งผ่าน "การทำดัชนี แมป" อย่างไร เช่น วิธีที่ดัชนีของเอาต์พุตคำสั่ง HLO แมปกับดัชนีของตัวถูกดำเนินการของคำสั่ง HLO
ตัวอย่าง
สำหรับการออกอากาศจาก tensor<20xf32> ไปยัง tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
แผนที่การจัดทำดัชนีจากเอาต์พุตไปยังอินพุตคือ (i, j, k) -> (j) สำหรับ i in
[0, 10], j in [0, 20] และ k in [0, 30]
แรงจูงใจ
XLA ใช้โซลูชันที่กำหนดเองหลายอย่างเพื่อพิจารณาเกี่ยวกับการรวม การใช้ตัวถูกดำเนินการ และรูปแบบการแบ่งไทล์ (ดูรายละเอียดเพิ่มเติมด้านล่าง) เป้าหมายของการวิเคราะห์การจัดทำดัชนี คือการจัดหาคอมโพเนนต์ที่นำกลับมาใช้ซ้ำได้สำหรับกรณีการใช้งานดังกล่าว การวิเคราะห์การจัดทำดัชนี สร้างขึ้นบนโครงสร้างพื้นฐานของ Affine Map ของ MLIR และเพิ่มความหมายของ HLO
การรวม
การให้เหตุผลเกี่ยวกับการรวมหน่วยความจำจะทำได้ในกรณีที่ไม่ใช่กรณีที่ง่าย เมื่อเราทราบว่ามีการอ่านองค์ประกอบ/ชิ้นส่วนใดของอินพุตเพื่อคำนวณองค์ประกอบของเอาต์พุต
การใช้งานตัวถูกดำเนินการ
การใช้ตัวถูกดำเนินการใน XLA จะระบุว่าอินพุตแต่ละรายการของคำสั่ง ถูกใช้มากน้อยเพียงใด โดยสมมติว่าเอาต์พุตของคำสั่งนั้นถูกใช้อย่างเต็มที่ ปัจจุบันระบบยังไม่ได้คำนวณการใช้งานสำหรับกรณีทั่วไปด้วย การวิเคราะห์การจัดทำดัชนีช่วยให้เราคำนวณการใช้งานได้อย่างแม่นยำ
การแปลงรหัสวิดีโอโดยใช้ไทล์
ไทล์/ชิ้นคือเซตย่อยของเทนเซอร์แบบไฮเปอร์เรกแทงกูลาร์ที่กำหนดพารามิเตอร์โดยออฟเซ็ต ขนาด และระยะก้าวย่าง การเผยแพร่ไทล์เป็นวิธีคำนวณพารามิเตอร์ไทล์ของ ผู้ผลิต/ผู้บริโภคของ Op โดยใช้พารามิเตอร์การแบ่งไทล์ของ Op เอง มีไลบรารี ที่ทำฟังก์ชันนี้สำหรับ Softmax และ Dot อยู่แล้ว การเผยแพร่ไทล์สามารถทำได้ทั่วไปมากขึ้นและ มีประสิทธิภาพมากขึ้นหากแสดงผ่านแผนที่การจัดทำดัชนี
แผนที่การจัดทำดัชนี
แผนที่การจัดทำดัชนีคือการรวมกันของ
- ฟังก์ชันที่แสดงสัญลักษณ์ซึ่งแมปทุกองค์ประกอบของเทนเซอร์
Aกับ ช่วงขององค์ประกอบในเทนเซอร์B - ข้อจำกัดเกี่ยวกับอาร์กิวเมนต์ของฟังก์ชันที่ถูกต้อง รวมถึงโดเมนของฟังก์ชัน
อาร์กิวเมนต์ของฟังก์ชันแบ่งออกเป็น 3 หมวดหมู่เพื่อให้สื่อสารลักษณะของอาร์กิวเมนต์ได้ดียิ่งขึ้น
ตัวแปรมิติข้อมูลของเทนเซอร์
Aหรือตารางกริด GPU ที่เรากำลังแมป ค่าที่ทราบแบบคงที่ องค์ประกอบดัชนีเรียกอีกอย่างว่าตัวแปรมิติข้อมูลตัวแปรช่วง โดยจะกำหนดการแมปแบบหนึ่งต่อหลายรายการและระบุชุดองค์ประกอบใน
Bที่ใช้ในการคำนวณค่าเดียวของAซึ่งค่าต่างๆ จะทราบแบบคงที่ มิติข้อมูลการทำสัญญาของการคูณเมทริกซ์เป็นตัวอย่าง ของตัวแปรช่วงตัวแปรขณะรันไทม์ที่ทราบเฉพาะในระหว่างการดำเนินการ เช่น อาร์กิวเมนต์ดัชนีของgather การดำเนินการ
ผลลัพธ์ของฟังก์ชันคือดัชนีของเทนเซอร์เป้าหมาย B
กล่าวโดยย่อ ฟังก์ชันการจัดทำดัชนีจากเทนเซอร์ A ไปยังเทนเซอร์ B สำหรับการดำเนินการ x
คือ
map_ab(index in A, range variables, runtime variables) -> index in B
เราจะเขียนอาร์กิวเมนต์การแมปประเภทต่างๆ ดังนี้เพื่อให้แยกประเภทได้ดียิ่งขึ้น
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
ตัวอย่างเช่น ลองดูแผนที่การจัดทำดัชนีสำหรับการดำเนินการลด
f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
เพื่อแมปองค์ประกอบของ
inกับoutฟังก์ชันของเราสามารถแสดงเป็น(d0, d1, d2, d3) -> (d1, d2)ข้อจํากัดของตัวแปรd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]กําหนดโดย รูปร่างของinหากต้องการแมปองค์ประกอบของ
outกับin:outมีเพียง 2 มิติ และการลด จะสร้างตัวแปรช่วง 2 ตัวที่ครอบคลุมมิติข้อมูลที่ลดลง ดังนั้นฟังก์ชันการแมปคือ(d0, d1)[s0, s1] -> (s0, d0, d1, s1)โดยที่(d0, d1)คือดัชนีของouts0และs1คือช่วงที่กำหนดโดยความหมายของการดำเนินการและ ครอบคลุมมิติข้อมูล 0 และ 3 ของเทนเซอร์inข้อจำกัดมีดังนี้d0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15]
โปรดทราบว่าในสถานการณ์ส่วนใหญ่ เราสนใจที่จะแมปจากองค์ประกอบของเอาต์พุต สำหรับการคำนวณ
C = op1(A, B)
E = op2(C, D)
เราสามารถพูดถึง "การจัดทำดัชนีของ B" ซึ่งหมายถึง "การแมปองค์ประกอบของ E ไปยังองค์ประกอบของ B" ซึ่งอาจขัดกับสัญชาตญาณเมื่อเทียบกับการวิเคราะห์โฟลว์ข้อมูลประเภทอื่นๆ ที่ทำงานจากอินพุตไปยังเอาต์พุต
ข้อจํากัดในตัวแปรช่วยให้มีโอกาสในการเพิ่มประสิทธิภาพและช่วยในการ สร้างโค้ด ในเอกสารประกอบและข้อจํากัดในการใช้งานจะเรียกว่าโดเมนด้วย เนื่องจากโดเมนจะกําหนดชุดค่าผสมหรือค่าอาร์กิวเมนต์ที่ใช้ได้ทั้งหมดของฟังก์ชันการแมป สำหรับหลายๆ การดำเนินการ ข้อจำกัดจะอธิบายมิติของเทนเซอร์ แต่สำหรับการดำเนินการบางอย่าง ข้อจำกัดอาจซับซ้อนกว่านั้น ดูตัวอย่างด้านล่าง
การมีฟังก์ชันและข้อจำกัดของอาร์กิวเมนต์ที่แสดงออกในเชิงสัญลักษณ์ และการรวมฟังก์ชันและข้อจำกัดเข้าด้วยกันทำให้เราสามารถคำนวณการแมปการจัดทำดัชนีแบบกะทัดรัดสำหรับการคำนวณขนาดใหญ่โดยพลการ (ฟิวชัน)
ความสามารถในการแสดงฟังก์ชันและข้อจํากัดเชิงสัญลักษณ์คือความสมดุลระหว่าง ความซับซ้อนในการใช้งานและผลลัพธ์การเพิ่มประสิทธิภาพที่เราได้รับจากการมี การแสดงที่แม่นยำยิ่งขึ้น สำหรับการดำเนินการ HLO บางอย่าง เราจะบันทึกรูปแบบการเข้าถึงโดยประมาณเท่านั้น
การใช้งาน
เนื่องจากเราต้องการลดการคำนวณซ้ำ จึงต้องมีไลบรารีสำหรับการคำนวณเชิงสัญลักษณ์ XLA ขึ้นอยู่กับ MLIR อยู่แล้ว เราจึงใช้ mlir::AffineMap แทนที่จะเขียนไลบรารีการคำนวณเชิงสัญลักษณ์อีกไลบรารีหนึ่ง
AffineMap โดยทั่วไปจะมีลักษณะดังนี้
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap มีพารามิเตอร์ 2 ประเภท ได้แก่ มิติข้อมูลและสัญลักษณ์
มิติข้อมูลสอดคล้องกับตัวแปรมิติข้อมูล d สัญลักษณ์สอดคล้องกับ
ตัวแปรช่วง r และตัวแปรรันไทม์ rt AffineMap ไม่มี
ข้อมูลเมตาเกี่ยวกับข้อจำกัดของพารามิเตอร์ ดังนั้นเราจึงต้องระบุข้อมูลเหล่านั้น
แยกกัน
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ เข้ารหัสข้อจำกัดของกล่อง inclusive สำหรับตัวแปรมิติข้อมูล
d ของแผนที่การจัดทำดัชนี ซึ่งมักจะสอดคล้องกับ
รูปร่างของเทนเซอร์เอาต์พุตสำหรับ Op เช่น การสลับ การลด การดำเนินการระดับองค์ประกอบ จุด แต่
มีข้อยกเว้นบางอย่าง เช่น
HloConcatenateInstruction
range_vars_ ค่าทั้งหมดที่ตัวแปรช่วง s ใช้ ตัวแปรช่วง
จำเป็นเมื่อต้องใช้หลายค่าในการคำนวณองค์ประกอบเดียวของ
เทนเซอร์ที่เราแมปจาก เช่น สำหรับแมปการจัดทำดัชนีเอาต์พุต->อินพุตของการลด หรือแมปอินพุต->เอาต์พุตสำหรับการออกอากาศ
rt_vars_ เข้ารหัสค่าที่เป็นไปได้ในรันไทม์ เช่น ออฟเซ็ตจะ
เปลี่ยนแปลงได้สำหรับ 1D HloDynamicSliceInstruction RTVar ที่เกี่ยวข้องจะมีค่าที่เป็นไปได้ระหว่าง 0 ถึง tensor_size - slice_size - 1
constraints_ จับความสัมพันธ์ระหว่างค่าในรูปแบบ
<expression> in <range> เช่น d0 + s0 in [0, 20] โดยเมื่อใช้ร่วมกับ
Variable.bounds จะกำหนด "โดเมน" ของฟังก์ชันการจัดทำดัชนี
มาดูตัวอย่างเพื่อทำความเข้าใจความหมายของข้อมูลทั้งหมดข้างต้นกัน
การจัดทำดัชนี Maps สำหรับการดำเนินการแบบไม่ผสาน
Elementwise
สําหรับการดำเนินการระดับองค์ประกอบ แผนที่การจัดทําดัชนีคือเอกลักษณ์
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
เอาต์พุตไปยังแมปอินพุต output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
การแมปอินพุตกับเอาต์พุต p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
ออกอากาศ
การออกอากาศหมายความว่าระบบจะนำมิติข้อมูลบางอย่างออกเมื่อเราแมปเอาต์พุตกับอินพุต และจะเพิ่มเมื่อเราแมปอินพุตกับเอาต์พุต
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
แผนที่อินพุตไปยังเอาต์พุต
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
โปรดทราบว่าตอนนี้เรามีตัวแปรช่วง s ทางด้านขวาสำหรับการ
แมปอินพุตกับเอาต์พุต ซึ่งเป็นสัญลักษณ์ที่แสดงช่วงของค่า
เช่น ในกรณีนี้ องค์ประกอบทุกรายการของอินพุตที่มีดัชนี d0 จะ
แมปกับชิ้นเอาต์พุตขนาด 10x1x30
Iota
Iota ไม่มีตัวถูกดำเนินการของเทนเซอร์อินพุต จึงไม่มีอาร์กิวเมนต์ดัชนีอินพุต
iota = f32[2,4] iota(), dimensions={1}
การแมปเอาต์พุตกับอินพุต
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
การแมปอินพุตกับเอาต์พุต
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice มีออฟเซ็ตที่ทราบเฉพาะที่รันไทม์
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
การแมปเอาต์พุตกับอินพุตจาก ds ถึง src มีดังนี้
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
โปรดทราบว่าตอนนี้เรามี rt ทางด้านขวาสำหรับการแมปอินพุตกับเอาต์พุต
ซึ่งเป็นสัญลักษณ์ที่แสดงค่ารันไทม์ ตัวอย่างเช่น ในกรณีนี้ สำหรับทุกองค์ประกอบของเอาต์พุตที่มีดัชนี d0, d1, d2 เราจะเข้าถึงออฟเซ็ตของ Slice of1, of2 และ of3 เพื่อคำนวณดัชนีของอินพุต
ช่วงสำหรับตัวแปรรันไทม์ได้มาจากการสมมติว่าทั้ง
สไลซ์ยังคงอยู่ในขอบเขต
การแมปเอาต์พุตกับอินพุตสำหรับ of1, of2 และ of3
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
การแมปเอาต์พุตกับอินพุตสำหรับ src เป็นเรื่องง่าย คุณสามารถทำให้แม่นยำยิ่งขึ้นได้โดย
จำกัดโดเมนไว้ที่ดัชนีที่ไม่ได้อัปเดต แต่ตอนนี้การทำดัชนีแผนที่
ไม่รองรับข้อจำกัดความไม่เท่ากัน
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
การแมปเอาต์พุตกับอินพุตสำหรับ upd มีดังนี้
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
โปรดทราบว่าตอนนี้เรามี rt0 และ rt1 ที่แสดงค่ารันไทม์ ในกรณีนี้ สำหรับทุกองค์ประกอบของเอาต์พุตที่มีดัชนี d0, d1 เราจะเข้าถึงออฟเซ็ตของสไลซ์ of1 และ of2 เพื่อคำนวณดัชนีของอินพุต ระบบจะอนุมาน
ช่วงสำหรับตัวแปรขณะรันไทม์โดยถือว่าทั้ง
สไลซ์อยู่ในขอบเขต
การแมปเอาต์พุตกับอินพุตสำหรับ of1 และ of2 มีดังนี้
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
รวบรวม
รองรับเฉพาะการรวบรวมข้อมูลแบบง่าย ดู gather_simplifier.h
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
การแมปเอาต์พุตกับอินพุตสำหรับ operand มีดังนี้
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
โปรดทราบว่าตอนนี้เรามีสัญลักษณ์ rt ที่แสดงค่าขณะรันไทม์
การแมปเอาต์พุตกับอินพุตสำหรับ indices มีดังนี้
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
ตัวแปรช่วง s0 แสดงให้เห็นว่าเราต้องการทั้งแถว (d0, *) ของเทนเซอร์
indices เพื่อคำนวณองค์ประกอบของเอาต์พุต
เปลี่ยนคีย์
แผนที่การจัดทำดัชนีสำหรับการเปลี่ยนตำแหน่งคือการเรียงสับเปลี่ยนของมิติข้อมูลอินพุต/เอาต์พุต
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
แผนที่อินพุตไปยังเอาต์พุต
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
ย้อนกลับ
การจัดทำดัชนีแผนที่สำหรับการเปลี่ยนแปลงแบบย้อนกลับจะเปลี่ยนมิติข้อมูลที่ยกเลิกกลับเป็น upper_bound(d_i) -
d_i
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
แผนที่อินพุตไปยังเอาต์พุต
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
การลดแบบ Variadic มีอินพุตหลายรายการและค่าเริ่มต้นหลายค่า การแมปจาก เอาต์พุตไปยังอินพุตจะเพิ่มมิติข้อมูลที่ลดลง
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
การแมปเอาต์พุตกับอินพุตมีดังนี้
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
การแมปอินพุตกับเอาต์พุตมีดังนี้
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
การจัดทำดัชนีจากเอาต์พุตไปยังอินพุตสำหรับผลลัพธ์ของ Slice จะส่งผลให้เกิดแผนที่การจัดทำดัชนีแบบมีระยะก้าวย่าง ซึ่ง ใช้ได้กับทุกองค์ประกอบของเอาต์พุต การแมปจากอินพุตไปยังเอาต์พุต จำกัดเฉพาะช่วงขององค์ประกอบในอินพุตที่มีการเว้นระยะ
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
แผนที่อินพุตไปยังเอาต์พุต
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
ปรับรูปร่าง
Reshape มีหลายรูปแบบ
ยุบรูปร่าง
นี่คือการเปลี่ยนรูปร่างแบบ "เชิงเส้น" จาก N-D เป็น 1D
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
แผนที่อินพุตไปยังเอาต์พุต
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
ขยายรูปร่าง
นี่คือการดำเนินการ "ยุบรูปร่าง" แบบผกผัน ซึ่งจะเปลี่ยนรูปร่างอินพุต 1 มิติเป็นเอาต์พุต N มิติ
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
แผนที่อินพุตไปยังเอาต์พุต
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
การปรับรูปร่างทั่วไป
ซึ่งเป็นการดำเนินการเปลี่ยนรูปร่างที่ไม่สามารถแสดงเป็นรูปร่างเดียวที่ขยายหรือ ยุบได้ โดยจะแสดงเป็นองค์ประกอบของรูปร่างอย่างน้อย 2 รูปร่าง ขยายหรือยุบเท่านั้น
ตัวอย่างที่ 1: การแปลงเป็นเชิงเส้นและการแปลงกลับเป็นเชิงเส้น
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
การปรับรูปร่างนี้แสดงเป็นการรวมรูปร่างการยุบจาก
tensor<4x8xf32> เป็น tensor<32xf32> แล้วขยายรูปร่างเป็น
tensor<2x4x4xf32>
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
แผนที่อินพุตไปยังเอาต์พุต
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
ตัวอย่างที่ 2: รูปร่างย่อยที่ขยายและยุบ
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
การเปลี่ยนรูปร่างนี้สามารถแสดงเป็นการประกอบกันของการเปลี่ยนรูปร่าง 2 แบบ ปุ่มแรก
ยุบมิติข้อมูลนอกสุด tensor<4x8x12xf32> เป็น tensor<32x12xf32>
และปุ่มที่ 2 ขยายมิติข้อมูลในสุด tensor<32x12xf32> เป็น
tensor<32x3x4xf32>
การแมปเอาต์พุตกับอินพุตมีดังนี้
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
แผนที่อินพุตไปยังเอาต์พุต
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
การดำเนินการ Bitcast สามารถแสดงเป็นลำดับของการสลับเปลี่ยนรูปร่าง-เปลี่ยนรูปร่าง-สลับเปลี่ยนรูปร่าง ดังนั้น แผนที่การจัดทำดัชนีของลำดับจึงเป็นเพียงการรวมแผนที่การจัดทำดัชนีสำหรับลำดับนี้
เชื่อมต่อ
การแมปเอาต์พุตกับอินพุตสำหรับ concat จะกำหนดไว้สำหรับอินพุตทั้งหมด แต่มี โดเมนที่ไม่ทับซ้อนกัน กล่าวคือ จะใช้อินพุตเพียง 1 รายการในแต่ละครั้ง
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
การแมปเอาต์พุตกับอินพุตมีดังนี้
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
อินพุตไปยังแผนที่เอาต์พุต
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
การทำดัชนีแผนที่สำหรับจุดคล้ายกับการทำดัชนีแผนที่สำหรับลดมาก
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
การแมปเอาต์พุตกับอินพุตมีดังนี้
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
อินพุตไปยังแผนที่เอาต์พุต
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
การจัดทำดัชนีของ PadOp จะผกผันกับการจัดทำดัชนีของ SliceOp
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
การกำหนดค่าระยะห่าง 1_4_1x4_8_0 หมายถึง lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1
การแมปเอาต์พุตกับอินพุตมีดังนี้
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
ReduceWindow ใน XLA ยังทำการเพิ่มระยะขอบด้วย ดังนั้น การจัดทำดัชนีแผนที่จึงสามารถ คำนวณเป็นการจัดทำดัชนี ReduceWindow ที่ไม่มีการเพิ่มแพด และการจัดทำดัชนีของ PadOp
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
การแมปเอาต์พุตกับอินพุตมีดังนี้
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
การจัดทำดัชนีแผนที่สำหรับฟิวชัน
แผนที่การจัดทำดัชนีสำหรับการดำเนินการฟิวชันคือองค์ประกอบของแผนที่การจัดทำดัชนีสำหรับการดำเนินการทุกรายการในคลัสเตอร์ อินพุตบางรายการอาจอ่านหลายครั้งด้วยรูปแบบการเข้าถึงที่แตกต่างกัน
อินพุต 1 รายการ แผนที่การจัดทำดัชนีหลายรายการ
ตัวอย่างสำหรับ p0 + transpose(p0) มีดังนี้
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
การจับคู่การจัดทำดัชนีเอาต์พุตกับอินพุตสำหรับ p0 จะเป็น (d0, d1) -> (d0, d1) และ (d0, d1) -> (d1, d0) ซึ่งหมายความว่าในการคำนวณองค์ประกอบหนึ่ง
ของเอาต์พุต เราอาจต้องอ่านพารามิเตอร์อินพุต 2 ครั้ง
อินพุตเดียว แผนที่การจัดทำดัชนีที่กรองข้อมูลที่ซ้ำกัน
![]()
มีบางกรณีที่แผนที่การจัดทำดัชนีเหมือนกันจริงๆ แม้ว่าจะไม่ชัดเจนในทันทีก็ตาม
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
แผนที่การจัดทำดัชนีเอาต์พุตเป็นอินพุตสำหรับ p0 ในกรณีนี้คือ
(d0, d1, d2) -> (d2, d0, d1)
Softmax
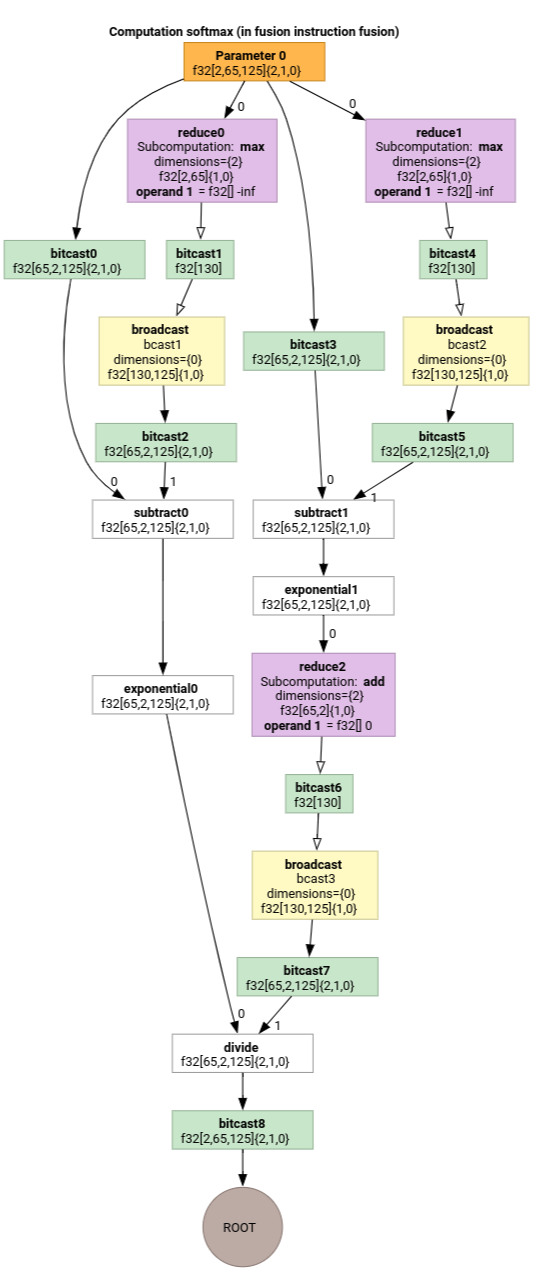
การแมปการจัดทำดัชนีเอาต์พุตกับอินพุตสำหรับ parameter 0 สำหรับ Softmax มีดังนี้
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
และ
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
โดย s0 หมายถึงมิติข้อมูลด้านในสุดของอินพุต
ดูตัวอย่างเพิ่มเติมได้ที่ indexing_analysis_test.cc
ตัวลดความซับซ้อนของแผนที่การจัดทำดัชนี
ตัวลดความซับซ้อนเริ่มต้นสำหรับสตรีมต้นทาง mlir::AffineMap จะไม่สามารถ
คาดเดาช่วงของมิติข้อมูล/สัญลักษณ์ได้ ดังนั้น จึงไม่สามารถ
ลดความซับซ้อนของนิพจน์ที่มี mod และ div ได้อย่างมีประสิทธิภาพ
เราสามารถใช้ความรู้เกี่ยวกับขอบเขตล่างและขอบเขตบนของ นิพจน์ย่อยในแมปแอฟฟินเพื่อลดความซับซ้อนของนิพจน์เหล่านั้นได้มากยิ่งขึ้น
ตัวย่อสามารถเขียนนิพจน์ต่อไปนี้ใหม่ได้
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)สำหรับ d ใน[0, 6] x [0, 14]จะกลายเป็น(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)สำหรับdi in [0, 9]จะกลายเป็น(d0, d1, d2) -> (d0, d1, d2)(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)สำหรับd_i in [0, 9]จะกลายเป็น(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8)(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)สำหรับ d ใน[0, 9] x [0, 10]จะกลายเป็น(d0, d1) -> (d0)
ตัวลดความซับซ้อนของแผนที่การจัดทำดัชนีช่วยให้เราทราบว่าการเปลี่ยนรูปร่างที่เชื่อมโยงกันบางส่วนใน HLO จะยกเลิกซึ่งกันและกัน
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
หลังจากสร้างแผนที่การจัดทำดัชนีและลดความซับซ้อนแล้ว เราจะได้
(d0, d1, d2) -> (d0, d1, d2)
การลดความซับซ้อนของแผนที่การจัดทำดัชนียังช่วยลดความซับซ้อนของข้อจำกัดด้วย
- ข้อจำกัดประเภท
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundจะ เขียนใหม่เป็นupdated_lower_bound <= affine_expr <= updated_upped_bound - ระบบจะตัดข้อจำกัดที่ตรงตามเงื่อนไขเสมอออก เช่น
d0 + s0 in [0, 20]สำหรับd0 in [0, 5]และs0 in [1, 3] - ระบบจะเพิ่มประสิทธิภาพนิพจน์เชิงเส้นในข้อจํากัดเป็นแผนที่เชิงเส้นของการจัดทําดัชนี ตามที่ระบุไว้ข้างต้น
ดูตัวอย่างเพิ่มเติมได้ที่ indexing_map_test.cc