
ต่อไปนี้จะอธิบายความหมายของการดำเนินการที่กำหนดไว้ในอินเทอร์เฟซ
XlaBuilder
โดยปกติแล้ว การดำเนินการเหล่านี้จะแมปแบบหนึ่งต่อหนึ่งกับการดำเนินการที่กำหนดไว้ใน
อินเทอร์เฟซ RPC ใน
xla_data.proto
หมายเหตุเกี่ยวกับคำศัพท์: ประเภทข้อมูลทั่วไปที่ XLA จัดการคืออาร์เรย์ N มิติที่มีองค์ประกอบของประเภทเดียวกัน (เช่น Float 32 บิต) ในเอกสารประกอบทั้งหมด เราใช้คำว่าอาร์เรย์เพื่อระบุอาร์เรย์ที่มีมิติข้อมูลใดก็ได้ เพื่อความสะดวก กรณีพิเศษจะมีชื่อที่เฉพาะเจาะจงและคุ้นเคยมากกว่า เช่น เวกเตอร์คืออาร์เรย์ 1 มิติ และเมทริกซ์คืออาร์เรย์ 2 มิติ
ดูข้อมูลเพิ่มเติมเกี่ยวกับโครงสร้างของ Op ในรูปร่างและเลย์เอาต์และ เลย์เอาต์แบบเรียงต่อกัน
หน้าท้อง
ดูเพิ่มเติม
XlaBuilder::Abs
ค่าสัมบูรณ์แบบองค์ประกอบต่อองค์ประกอบ x -> |x|
Abs(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - abs
เพิ่ม
ดูเพิ่มเติม
XlaBuilder::Add
ดำเนินการบวกแบบทีละองค์ประกอบของ lhs และ rhs
Add(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
สำหรับ Add จะมีตัวแปรอื่นที่รองรับการออกอากาศแบบหลายมิติ
Add(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - add
AddDependency
ดูเพิ่มเติม
HloInstruction::AddDependency
AddDependency อาจปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
AfterAll
ดูเพิ่มเติม
XlaBuilder::AfterAll
AfterAll รับโทเค็นจำนวนตัวแปรและสร้างโทเค็นเดียว โทเค็น
เป็นประเภทดั้งเดิมที่สามารถเชื่อมโยงระหว่างการดำเนินการที่มีผลข้างเคียงเพื่อ
บังคับใช้การจัดลำดับ AfterAll สามารถใช้เป็นตัวเชื่อมโทเค็นสำหรับการเรียงลำดับ
การดำเนินการหลังจากชุดการดำเนินการ
AfterAll(tokens)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
tokens |
เวกเตอร์ของ XlaOp |
จำนวนโทเค็นที่เปลี่ยนแปลงได้ |
ดูข้อมูล StableHLO ได้ที่ StableHLO - after_all
AllGather
ดูเพิ่มเติม
XlaBuilder::AllGather
ดำเนินการเชื่อมโยงในตัวจำลอง
AllGather(operand, all_gather_dimension, shard_count, replica_groups,
channel_id, layout, use_global_device_ids)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์ที่จะต่อกันในรีพลิกา |
all_gather_dimension |
int64 |
มิติข้อมูลการต่อกัน |
shard_count
|
int64
|
ขนาดของกลุ่ม จำลองแต่ละกลุ่ม |
replica_groups
|
เวกเตอร์ของเวกเตอร์ของ
int64 |
กลุ่มที่ทำการต่อกัน |
channel_id
|
ไม่บังคับ
ChannelHandle |
รหัสช่องที่ไม่บังคับสำหรับการสื่อสารข้ามโมดูล |
layout
|
ไม่บังคับ Layout
|
สร้างรูปแบบเลย์เอาต์ ที่จะจับภาพ เลย์เอาต์ที่ตรงกันใน อาร์กิวเมนต์ |
use_global_device_ids
|
ไม่บังคับ bool
|
แสดงค่าจริงหากรหัสในการกำหนดค่า ReplicaGroup แสดงรหัสส่วนกลาง |
replica_groupsคือรายการกลุ่มรีพลิคาระหว่างที่ทำการต่อกัน (ดึงรหัสรีพลิคาสำหรับรีพลิคาปัจจุบันได้โดยใช้ReplicaId) ลำดับของรีพลิคาในแต่ละกลุ่มจะกำหนด ลำดับที่อินพุตของรีพลิคาอยู่ในผลลัพธ์replica_groupsต้องว่างเปล่า (ในกรณีนี้ ตัวจำลองทั้งหมดจะอยู่ในกลุ่มเดียว เรียงจาก0ถึงN - 1) หรือมีจำนวนองค์ประกอบเท่ากับ จำนวนตัวจำลอง เช่นreplica_groups = {0, 2}, {1, 3}จะทำการ เชื่อมต่อระหว่างสำเนา0กับ2และ1กับ3shard_countคือขนาดของกลุ่มรีพลิกาทุกกลุ่ม เราต้องการข้อมูลนี้ในกรณีที่replica_groupsว่างเปล่าchannel_idใช้สำหรับการสื่อสารข้ามโมดูล โดยมีเพียงการดำเนินการall-gatherที่มีchannel_idเดียวกันเท่านั้นที่สื่อสารกันได้use_global_device_idsแสดงผลเป็นจริงหากรหัสในการกำหนดค่า ReplicaGroup แสดงรหัสส่วนกลางของ (replica_id * partition_count + partition_id) แทนรหัสจำลอง ซึ่งช่วยให้จัดกลุ่มอุปกรณ์ได้ยืดหยุ่นมากขึ้นหาก การลดทั้งหมดนี้เป็นทั้งแบบข้ามพาร์ติชันและข้ามสำเนา
รูปร่างเอาต์พุตคือรูปร่างอินพุตที่มีขนาดใหญ่ขึ้น all_gather_dimensionshard_count เท่า เช่น หากมีรีพลิกา 2 รายการและตัวถูกดำเนินการมีค่า [1.0, 2.5] และ [3.0, 5.25] ตามลำดับในรีพลิกาทั้ง 2 รายการ ค่าเอาต์พุตจาก Op นี้ที่ all_gather_dim เป็น 0 จะเป็น [1.0, 2.5, 3.0,5.25] ในรีพลิกาทั้ง 2 รายการ
API ของ AllGather จะแยกออกเป็นคำสั่ง HLO 2 รายการภายใน (AllGatherStart และ AllGatherDone)
ดูเพิ่มเติม
HloInstruction::CreateAllGatherStart
AllGatherStart, AllGatherDone ทำหน้าที่เป็นองค์ประกอบพื้นฐานใน HLO การดำเนินการเหล่านี้อาจ
ปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทาง
สร้างขึ้นด้วยตนเอง
ดูข้อมูล StableHLO ได้ที่ StableHLO - all_gather
AllReduce
ดูเพิ่มเติม
XlaBuilder::AllReduce
ทำการคำนวณที่กำหนดเองในรีพลิกาทั้งหมด
AllReduce(operand, computation, replica_groups, channel_id,
shape_with_layout, use_global_device_ids)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์หรือทูเพิลที่ไม่ว่างเปล่า ของอาร์เรย์ที่จะลดใน แบบจำลอง |
computation |
XlaComputation |
การคำนวณการลด |
replica_groups
|
ReplicaGroup เวกเตอร์
|
กลุ่มที่ใช้ในการ ลด |
channel_id
|
ไม่บังคับ
ChannelHandle |
รหัสช่องที่ไม่บังคับสำหรับการสื่อสารข้ามโมดูล |
shape_with_layout
|
ไม่บังคับ Shape
|
กำหนดเลย์เอาต์ของ ข้อมูลที่โอน |
use_global_device_ids
|
ไม่บังคับ bool
|
แสดงค่าจริงหากรหัสในการกำหนดค่า ReplicaGroup แสดงรหัสส่วนกลาง |
- เมื่อ
operandเป็นทูเพิลของอาร์เรย์ ระบบจะดำเนินการ all-reduce กับแต่ละ องค์ประกอบของทูเพิล replica_groupsคือรายการกลุ่มรีพลิคาระหว่างที่ทำการลด (ดึงข้อมูลรหัสรีพลิคาสำหรับรีพลิคาปัจจุบันได้โดยใช้ReplicaId)replica_groupsต้องว่างเปล่า (ในกรณีที่รีพลิคาทั้งหมดอยู่ในกลุ่มเดียว) หรือมีจำนวนองค์ประกอบเท่ากับจำนวนรีพลิคา ตัวอย่างเช่นreplica_groups = {0, 2}, {1, 3}ทำการลดระหว่างรีพลิคา0และ2รวมถึง1และ3channel_idใช้สำหรับการสื่อสารข้ามโมดูล โดยมีเพียงการดำเนินการall-reduceที่มีchannel_idเดียวกันเท่านั้นที่สื่อสารกันได้shape_with_layout: บังคับให้เลย์เอาต์ของ AllReduce เป็นเลย์เอาต์ที่กำหนด ใช้เพื่อรับประกันว่าเลย์เอาต์ของกลุ่มการดำเนินการ AllReduce ที่คอมไพล์แยกกันจะเหมือนกันuse_global_device_idsแสดงผลเป็นจริงหากรหัสในการกำหนดค่า ReplicaGroup แสดงรหัสส่วนกลางของ (replica_id * partition_count + partition_id) แทนรหัสจำลอง ซึ่งช่วยให้จัดกลุ่มอุปกรณ์ได้ยืดหยุ่นมากขึ้นหาก การลดทั้งหมดนี้เป็นทั้งแบบข้ามพาร์ติชันและข้ามสำเนา
รูปร่างเอาต์พุตจะเหมือนกับรูปร่างอินพุต ตัวอย่างเช่น หากมีรีพลิกา 2 รายการและตัวถูกดำเนินการมีค่า [1.0, 2.5] และ [3.0, 5.25]
ตามลำดับในรีพลิกาทั้ง 2 รายการ ค่าเอาต์พุตจาก Op นี้และการคำนวณ
การบวกจะเป็น [4.0, 7.75] ในรีพลิกาทั้ง 2 รายการ หากอินพุตเป็น
ทูเพิล เอาต์พุตจะเป็นทูเพิลด้วย
การคำนวณผลลัพธ์ของ AllReduce ต้องมีอินพุต 1 รายการจากแต่ละรีพลิก้า
ดังนั้นหากรีพลิก้าหนึ่งเรียกใช้โหนด AllReduce มากกว่ารีพลิก้าอื่น
รีพลิก้าแรกจะรอไปเรื่อยๆ เนื่องจากรีพลิก้าทั้งหมดเรียกใช้โปรแกรมเดียวกัน
จึงมีวิธีไม่มากนักที่จะทำให้เกิดเหตุการณ์ดังกล่าว แต่ก็เป็นไปได้เมื่อ
เงื่อนไขของลูป while ขึ้นอยู่กับข้อมูลจาก infeed และข้อมูลที่ infeed ทำให้ลูป while วนซ้ำในรีพลิก้าหนึ่งมากกว่าอีกรีพลิก้าหนึ่ง
API ของ AllReduce จะแยกออกเป็นคำสั่ง HLO 2 รายการภายใน (AllReduceStart และ AllReduceDone)
ดูเพิ่มเติม
HloInstruction::CreateAllReduceStart
AllReduceStart และ AllReduceDone ทำหน้าที่เป็นองค์ประกอบพื้นฐานใน HLO การดำเนินการเหล่านี้อาจ
ปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทาง
สร้างขึ้นด้วยตนเอง
CrossReplicaSum
ดูเพิ่มเติม
XlaBuilder::CrossReplicaSum
ดำเนินการ AllReduce ด้วยการคำนวณผลรวม
CrossReplicaSum(operand, replica_groups)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp | อาร์เรย์หรือทูเพิลที่ไม่ว่างของ อาร์เรย์ที่จะลดใน แบบจำลอง |
replica_groups
|
เวกเตอร์ของเวกเตอร์ของ
int64 |
กลุ่มที่ใช้ในการ ลด |
แสดงผลรวมของค่าตัวถูกดำเนินการภายในแต่ละกลุ่มย่อยของสำเนา สำเนาทั้งหมด จะป้อนข้อมูล 1 รายการไปยังผลรวม และสำเนาทั้งหมดจะได้รับผลรวมที่ได้ สำหรับแต่ละกลุ่มย่อย
AllToAll
ดูเพิ่มเติม
XlaBuilder::AllToAll
AllToAll เป็นการดำเนินการแบบกลุ่มที่ส่งข้อมูลจากทุกคอร์ไปยังทุกคอร์ โดยมี 2 เฟส ดังนี้
- เฟสการกระจาย ในแต่ละคอร์ ระบบจะแบ่งตัวถูกดำเนินการออกเป็น
split_countจำนวนบล็อกตามsplit_dimensionsและกระจายบล็อก ไปยังทุกคอร์ เช่น ระบบจะส่งบล็อกที่ i ไปยังคอร์ที่ i - เฟสรวบรวม แต่ละคอร์จะต่อบล็อกที่ได้รับตาม
concat_dimension
โดยสามารถกำหนดค่าแกนที่เข้าร่วมได้โดย
replica_groups: ReplicaGroup แต่ละรายการจะมีรายการรหัสของรีพลิก้า ที่เข้าร่วมในการคำนวณ (ดึงรหัสรีพลิก้าสำหรับรีพลิก้าปัจจุบันได้โดยใช้ReplicaId) ระบบจะใช้ AllToAll ภายในกลุ่มย่อยตามลำดับที่ระบุ เช่นreplica_groups = { {1,2,3}, {4,5,0} }หมายความว่าจะมีการใช้ AllToAll ภายในรีพลิก้า{1, 2, 3}และในระยะการรวบรวม ระบบจะต่อบล็อกที่ได้รับ ตามลำดับเดียวกันคือ 1, 2, 3 จากนั้นจะมีการใช้ AllToAll อีกครั้ง ภายในรีพลิก้า 4, 5, 0 และลำดับการต่อคือ 4, 5, 0 หากreplica_groupsว่างเปล่า รีพลิก้าทั้งหมดจะอยู่ในกลุ่มเดียว โดยมีลำดับการต่อตามลำดับที่ปรากฏ
สิ่งที่ต้องมีก่อน
- ขนาดมิติข้อมูลของตัวถูกดำเนินการใน
split_dimensionหารด้วยsplit_countได้ลงตัว - รูปร่างของตัวถูกดำเนินการไม่ใช่ Tuple
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups, layout, channel_id)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
split_dimension
|
int64
|
ค่าในช่วง
[0,n) ที่ตั้งชื่อ
มิติข้อมูลซึ่ง
ตัวถูกดำเนินการจะแยกตาม |
concat_dimension
|
int64
|
ค่าในช่วง
[0,n) ที่ตั้งชื่อ
มิติข้อมูลซึ่ง
บล็อกที่แยก
จะต่อกัน |
split_count
|
int64
|
จำนวนแกนที่
เข้าร่วมใน
การดำเนินการนี้ หาก
replica_groups ว่างเปล่า
ค่านี้ควรเป็นจำนวน
แบบจำลอง มิฉะนั้น
ค่านี้ควรเท่ากับ
จำนวนแบบจำลองในแต่ละ
กลุ่ม |
replica_groups
|
ReplicaGroupเวกเตอร์
|
แต่ละกลุ่มจะมีรายการ รหัสของรีเพล็กซ์ |
layout |
ไม่บังคับ Layout |
เลย์เอาต์หน่วยความจำที่ผู้ใช้ระบุ |
channel_id
|
ไม่บังคับ ChannelHandle
|
ตัวระบุที่ไม่ซ้ำกันสำหรับคู่ send/recv แต่ละคู่ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับรูปร่างและเลย์เอาต์ได้ที่ xla::shapes
ดูข้อมูล StableHLO ได้ที่ StableHLO - all_to_all
AllToAll - ตัวอย่างที่ 1
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(
x,
/*split_dimension=*/ 1,
/*concat_dimension=*/ 0,
/*split_count=*/ 4);
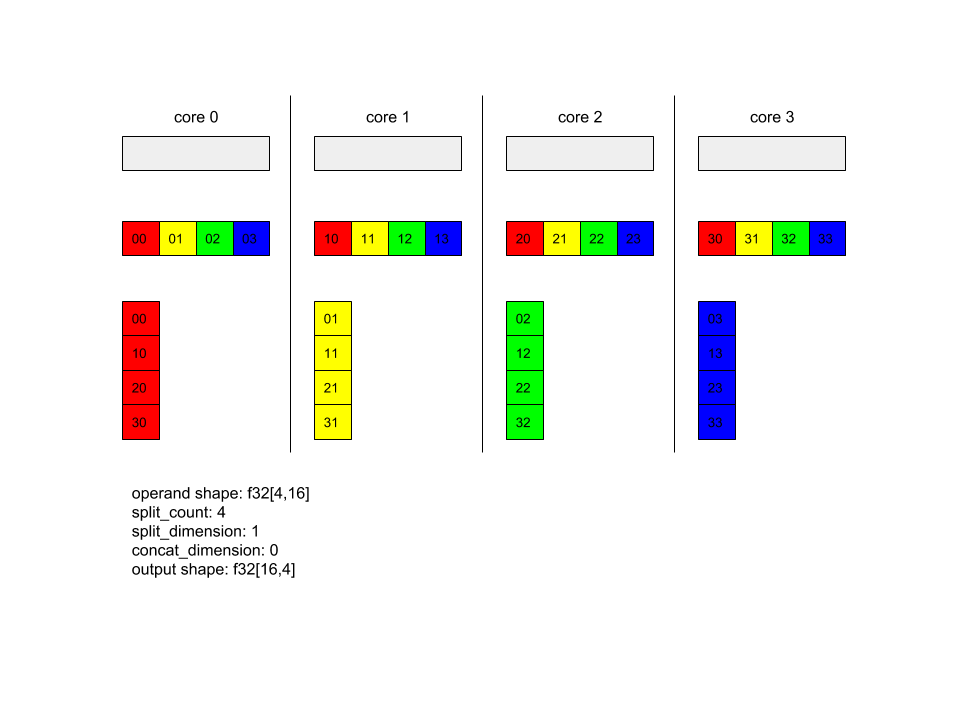
ในตัวอย่างด้านบน มี 4 คอร์ที่เข้าร่วมใน Alltoall ในแต่ละ คอร์ ระบบจะแบ่งตัวถูกดำเนินการออกเป็น 4 ส่วนตามมิติข้อมูลที่ 1 ดังนั้นแต่ละส่วนจะมี รูปร่าง f32[4,4] โดยจะกระจายชิ้นส่วนทั้ง 4 ไปยังคอร์ทั้งหมด จากนั้นแต่ละคอร์จะ ต่อชิ้นส่วนที่ได้รับตามมิติข้อมูล 0 ตามลำดับคอร์ 0-4 ดังนั้น เอาต์พุตในแต่ละแกนจึงมีรูปร่าง f32[16,4]
AllToAll - ตัวอย่างที่ 2 - StableHLO

ในตัวอย่างด้านบน มีรีพลิกา 2 รายการที่เข้าร่วมใน AllToAll ใน แต่ละรีพลิกา โอเปอแรนด์มีรูปร่าง f32[2,4] ตัวถูกดำเนินการจะแบ่งออกเป็น 2 ส่วน ตามมิติข้อมูลที่ 1 ดังนั้นแต่ละส่วนจะมีรูปร่าง f32[2,2] จากนั้นจะมีการแลกเปลี่ยน 2 ส่วนนี้ ในสำเนาตามตำแหน่งในกลุ่มสำเนา แต่ละรีพลิกาจะรวบรวมส่วนที่เกี่ยวข้องจากทั้งตัวถูกดำเนินการและต่อกันตามมิติที่ 0 ดังนั้น เอาต์พุตในแต่ละรีพลิกาจะมีรูปร่าง f32[4,2]
RaggedAllToAll
ดูเพิ่มเติม
XlaBuilder::RaggedAllToAll
RaggedAllToAll ดำเนินการแบบกลุ่มแบบทั้งหมดต่อทั้งหมด โดยที่อินพุตและเอาต์พุตเป็นเทนเซอร์แบบไม่สม่ำเสมอ
RaggedAllToAll(input, input_offsets, send_sizes, output, output_offsets,
recv_sizes, replica_groups, channel_id)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
input |
XlaOp |
อาร์เรย์ N ของประเภท T |
input_offsets |
XlaOp |
อาร์เรย์ N ของประเภท T |
send_sizes |
XlaOp |
อาร์เรย์ N ของประเภท T |
output |
XlaOp |
อาร์เรย์ N ของประเภท T |
output_offsets |
XlaOp |
อาร์เรย์ N ของประเภท T |
recv_sizes |
XlaOp |
อาร์เรย์ N ของประเภท T |
replica_groups
|
ReplicaGroup เวกเตอร์
|
แต่ละกลุ่มจะมีรายการรหัสรีเพล็กซ์ |
channel_id
|
ไม่บังคับ ChannelHandle
|
ตัวระบุที่ไม่ซ้ำกันสำหรับคู่ send/recv แต่ละคู่ |
เทนเซอร์แบบไม่สม่ำเสมอจะกำหนดโดยชุดเทนเซอร์ 3 รายการ ได้แก่
data:dataTensor เป็นแบบ “ไม่สม่ำเสมอ” ตามมิติข้อมูลด้านนอกสุด ซึ่งแต่ละองค์ประกอบที่จัดทำดัชนีจะมีขนาดแตกต่างกันoffsets': เทนเซอร์offsetsจะจัดทำดัชนีมิติข้อมูลด้านนอกสุดของเทนเซอร์dataและแสดงออฟเซ็ตเริ่มต้นขององค์ประกอบที่ไม่สม่ำเสมอแต่ละรายการของ เทนเซอร์datasizes: เทนเซอร์sizesแสดงขนาดขององค์ประกอบที่ไม่สม่ำเสมอแต่ละรายการของ เทนเซอร์dataโดยระบุขนาดในหน่วยขององค์ประกอบย่อย องค์ประกอบย่อยกำหนดเป็นคำต่อท้ายของรูปร่างเทนเซอร์ "data" ที่ได้จาก การนำมิติข้อมูล "ไม่สม่ำเสมอ" ที่อยู่นอกสุดออก- เทนเซอร์
offsetsและsizesต้องมีขนาดเท่ากัน
ตัวอย่างเทนเซอร์แบบไม่สม่ำเสมอ
data: [8,3] =
{ {a,b,c},{d,e,f},{g,h,i},{j,k,l},{m,n,o},{p,q,r},{s,t,u},{v,w,x} }
offsets: [3] = {0, 1, 4}
sizes: [3] = {1, 3, 4}
// Index 'data' at 'offsets'[0], 'sizes'[0]' // {a,b,c}
// Index 'data' at 'offsets'[1], 'sizes'[1]' // {d,e,f},{g,h,i},{j,k,l}
// Index 'data' at 'offsets'[2], 'sizes'[2]' // {m,n,o},{p,q,r},{s,t,u},{v,w,x}
output_offsets ต้องได้รับการแบ่งส่วนในลักษณะที่แต่ละรีพลิเคชันมีออฟเซ็ตใน
มุมมองเอาต์พุตรีพลิเคชันเป้าหมาย
สำหรับออฟเซ็ตเอาต์พุตที่ i เครื่องจำลองปัจจุบันจะส่ง
input[input_offsets[i]:input_offsets[i]+send_sizes[i]] อัปเดตไปยังเครื่องจำลองที่ i
ซึ่งจะเขียนไปยัง
output_i[output_offsets[i]:output_offsets[i]+send_sizes[i]] ในเครื่องจำลองที่ i
output
เช่น หากเรามีรีพลิกา 2 รายการ
replica 0:
input: [1, 2, 2]
output:[0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 2]
output_offsets: [0, 0]
recv_sizes: [1, 1]
replica 1:
input: [3, 4, 0]
output: [0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 1]
output_offsets: [1, 2]
recv_sizes: [2, 1]
// replica 0's result will be: [1, 3, 0, 0]
// replica 1's result will be: [2, 2, 4, 0]
HLO แบบไม่สม่ำเสมอแบบทั้งหมดต่อทั้งหมดมีอาร์กิวเมนต์ต่อไปนี้
input: เทนเซอร์ข้อมูลอินพุตแบบไม่สม่ำเสมอoutput: เทนเซอร์ข้อมูลเอาต์พุตแบบไม่สม่ำเสมอinput_offsets: เทนเซอร์ออฟเซ็ตอินพุตแบบไม่สม่ำเสมอsend_sizes: เทนเซอร์ขนาดการส่งที่ไม่สม่ำเสมอoutput_offsets: อาร์เรย์ของออฟเซ็ตแบบไม่สม่ำเสมอในเอาต์พุตของรีพลิเคาเป้าหมายrecv_sizes: เทนเซอร์ขนาด recv ที่ไม่สม่ำเสมอ
เทนเซอร์ *_offsets และ *_sizes ทั้งหมดต้องมีรูปร่างเดียวกัน
รองรับ 2 รูปร่างสำหรับเทนเซอร์ *_offsets และ *_sizes ดังนี้
[num_devices]ซึ่งการส่งแบบกระจายอาจส่งการอัปเดตได้สูงสุด 1 รายการไปยังอุปกรณ์ระยะไกลแต่ละเครื่องในกลุ่มรีเพลส เช่น
for (remote_device_id : replica_group) {
SEND input[input_offsets[remote_device_id]],
output[output_offsets[remote_device_id]],
send_sizes[remote_device_id] }
[num_devices, num_updates]ซึ่งการส่งแบบกระจายทั้งหมดอาจส่งการอัปเดตได้สูงสุดnum_updatesอุปกรณ์ระยะไกลเดียวกัน (แต่ละรายการมีออฟเซ็ตต่างกัน) สำหรับอุปกรณ์ระยะไกลแต่ละเครื่องในกลุ่มรีพลิกา
เช่น
for (remote_device_id : replica_group) {
for (update_idx : num_updates) {
SEND input[input_offsets[remote_device_id][update_idx]],
output[output_offsets[remote_device_id][update_idx]]],
send_sizes[remote_device_id][update_idx] } }
และ
ดูเพิ่มเติม
XlaBuilder::And
ดำเนินการ AND แบบทีละองค์ประกอบของเทนเซอร์ 2 ตัว ได้แก่ lhs และ rhs
And(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
มีตัวแปรอื่นที่รองรับการออกอากาศแบบหลายมิติ สำหรับ And ดังนี้
And(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - and
Async
ดู HloInstruction::CreateAsyncStart
HloInstruction::CreateAsyncUpdate
HloInstruction::CreateAsyncDone ด้วย
AsyncDone, AsyncStart และ AsyncUpdate เป็นคำสั่ง HLO ภายในที่ใช้
สำหรับการดำเนินการแบบอะซิงโครนัสและทำหน้าที่เป็นองค์ประกอบพื้นฐานใน HLO การดำเนินการเหล่านี้อาจปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
Atan2
ดูเพิ่มเติม
XlaBuilder::Atan2
ดำเนินการ atan2 แบบทีละองค์ประกอบใน lhs และ rhs
Atan2(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Atan2 มีตัวแปรทางเลือกที่รองรับการออกอากาศแบบหลายมิติ ดังนี้
Atan2(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - atan2
BatchNormGrad
ดูคำอธิบายโดยละเอียดของอัลกอริทึมได้ที่
XlaBuilder::BatchNormGrad
และเอกสารต้นฉบับเกี่ยวกับการปรับค่าปกติแบบกลุ่ม
คำนวณการไล่ระดับของ Batch Norm
BatchNormGrad(operand, scale, batch_mean, batch_var, grad_output, epsilon,
feature_index)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp | อาร์เรย์ n มิติที่จะทำให้เป็นค่าปกติ (x) |
scale |
XlaOp | อาร์เรย์ 1 มิติ (\(\gamma\)) |
batch_mean |
XlaOp | อาร์เรย์ 1 มิติ (\(\mu\)) |
batch_var |
XlaOp | อาร์เรย์ 1 มิติ (\(\sigma^2\)) |
grad_output |
XlaOp | การไล่ระดับสีที่ส่งไปยัง BatchNormTraining (\(\nabla y\)) |
epsilon |
float |
ค่า Epsilon (\(\epsilon\)) |
feature_index |
int64 |
ดัชนีเพื่อแสดงมิติข้อมูลใน operand |
สําหรับฟีเจอร์แต่ละรายการในมิติข้อมูลฟีเจอร์ (feature_index คือดัชนีสําหรับ
มิติข้อมูลฟีเจอร์ใน operand) การดําเนินการจะคํานวณการไล่ระดับสีโดยอิงตาม operand, offset และ scale ในมิติข้อมูลอื่นๆ ทั้งหมด feature_index ต้องเป็นดัชนีที่ถูกต้องสําหรับมิติข้อมูลฟีเจอร์ใน operand
การไล่ระดับสีทั้ง 3 แบบกำหนดโดยสูตรต่อไปนี้ (สมมติว่าอาร์เรย์ 4 มิติเป็น operand และมีดัชนีมิติข้อมูลฟีเจอร์ l, ขนาดกลุ่ม m และขนาดเชิงพื้นที่ w และ h)
\[ \begin{split} c_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) \\\\ d_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \\\\ \nabla x_{ijkl} &= \frac{\gamma_{l} }{\sqrt{\sigma^2_{l}+\epsilon} } \left( \nabla y_{ijkl} - d_l - c_l (x_{ijkl} - \mu_{l}) \right) \\\\ \nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon} } \right) \\\\\ \nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \end{split} \]
อินพุต batch_mean และ batch_var แสดงค่าโมเมนต์ในมิติข้อมูลกลุ่ม
และมิติข้อมูลเชิงพื้นที่
ประเภทเอาต์พุตคือ Tuple ของแฮนเดิล 3 รายการ
| เอาต์พุต | ประเภท | ความหมาย |
|---|---|---|
grad_operand
|
XlaOp | การไล่ระดับสีเทียบกับ
อินพุต operand
(\(\nabla x\)) |
grad_scale
|
XlaOp | การไล่ระดับสีที่เกี่ยวข้องกับ
อินพุต **scale **
(\(\nabla\gamma\)) |
grad_offset
|
XlaOp | การไล่ระดับสีที่เกี่ยวข้องกับ
อินพุต
offset(\(\nabla\beta\)) |
ดูข้อมูล StableHLO ได้ที่ StableHLO - batch_norm_grad
BatchNormInference
ดูคำอธิบายโดยละเอียดของอัลกอริทึมได้ที่
XlaBuilder::BatchNormInference
และเอกสารต้นฉบับเกี่ยวกับการทําให้เป็นปกติแบบกลุ่ม
ปรับอาร์เรย์ให้เป็นมาตรฐานในมิติข้อมูลแบบกลุ่มและเชิงพื้นที่
BatchNormInference(operand, scale, offset, mean, variance, epsilon,
feature_index)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp | อาร์เรย์ n มิติที่จะทำให้เป็นปกติ |
scale |
XlaOp | อาร์เรย์ 1 มิติ |
offset |
XlaOp | อาร์เรย์ 1 มิติ |
mean |
XlaOp | อาร์เรย์ 1 มิติ |
variance |
XlaOp | อาร์เรย์ 1 มิติ |
epsilon |
float |
ค่า Epsilon |
feature_index |
int64 |
ดัชนีเพื่อแสดงมิติข้อมูลใน operand |
สําหรับแต่ละฟีเจอร์ในมิติข้อมูลฟีเจอร์ (feature_index คือดัชนีสําหรับมิติข้อมูลฟีเจอร์ใน operand) การดําเนินการจะคํานวณค่าเฉลี่ยและความแปรปรวนในมิติข้อมูลอื่นๆ ทั้งหมด และใช้ค่าเฉลี่ยและความแปรปรวนเพื่อทําให้แต่ละองค์ประกอบใน operand เป็นปกติ feature_index ต้องเป็นดัชนีที่ถูกต้องสำหรับมิติข้อมูลฟีเจอร์ใน operand
BatchNormInference เทียบเท่ากับการเรียกใช้ BatchNormTraining โดยไม่ต้องคำนวณ mean และ variance สำหรับแต่ละกลุ่ม แต่จะใช้ข้อมูลนำเข้า mean และ variance แทนเป็นค่าประมาณ วัตถุประสงค์ของ Op นี้คือเพื่อลดเวลาในการตอบสนองในการอนุมาน จึงเป็นที่มาของชื่อ BatchNormInference
เอาต์พุตคืออาร์เรย์แบบ n มิติที่ได้รับการทำให้เป็นมาตรฐานและมีรูปร่างเหมือนกับอินพุต
operand
ดูข้อมูล StableHLO ได้ที่ StableHLO - batch_norm_inference
BatchNormTraining
ดูคำอธิบายโดยละเอียดเกี่ยวกับอัลกอริทึมได้ที่
XlaBuilder::BatchNormTraining
และ the original batch normalization paper
ปรับอาร์เรย์ให้เป็นมาตรฐานในมิติข้อมูลแบบกลุ่มและเชิงพื้นที่
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ n มิติที่จะทำให้เป็นค่าปกติ (x) |
scale |
XlaOp |
อาร์เรย์ 1 มิติ (\(\gamma\)) |
offset |
XlaOp |
อาร์เรย์ 1 มิติ (\(\beta\)) |
epsilon |
float |
ค่า Epsilon (\(\epsilon\)) |
feature_index |
int64 |
ดัชนีเพื่อแสดงมิติข้อมูลใน operand |
สําหรับแต่ละฟีเจอร์ในมิติข้อมูลฟีเจอร์ (feature_index คือดัชนีสําหรับมิติข้อมูลฟีเจอร์ใน operand) การดําเนินการจะคํานวณค่าเฉลี่ยและความแปรปรวนในมิติข้อมูลอื่นๆ ทั้งหมด และใช้ค่าเฉลี่ยและความแปรปรวนเพื่อทําให้แต่ละองค์ประกอบใน operand เป็นปกติ feature_index ต้องเป็นดัชนีที่ถูกต้องสำหรับมิติข้อมูลฟีเจอร์ใน operand
อัลกอริทึมมีดังนี้สำหรับแต่ละกลุ่มใน operand \(x\) ที่มีm
องค์ประกอบที่มี w และ h เป็นขนาดของมิติเชิงพื้นที่ (สมมติว่า operand
เป็นอาร์เรย์ 4 มิติ)
คำนวณค่าเฉลี่ยของกลุ่ม \(\mu_l\) สำหรับแต่ละฟีเจอร์
lในมิติข้อมูลฟีเจอร์ \(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\)คำนวณความแปรปรวนของกลุ่ม \(\sigma^2_l\): $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
การปรับให้เป็นมาตรฐาน การปรับขนาด และการเลื่อน \(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon} }+\beta_l\)
ระบบจะเพิ่มค่า epsilon ซึ่งมักจะเป็นตัวเลขขนาดเล็ก เพื่อหลีกเลี่ยงข้อผิดพลาดในการหารด้วย 0
ประเภทเอาต์พุตคือทูเพิลของ XlaOp 3 รายการ
| เอาต์พุต | ประเภท | ความหมาย |
|---|---|---|
output
|
XlaOp
|
อาร์เรย์ n มิติที่มีรูปร่างเหมือนกับอินพุต
operand (y) |
batch_mean |
XlaOp |
อาร์เรย์ 1 มิติ (\(\mu\)) |
batch_var |
XlaOp |
อาร์เรย์ 1 มิติ (\(\sigma^2\)) |
batch_mean และ batch_var คือโมเมนต์ที่คํานวณในมิติข้อมูลกลุ่มและมิติข้อมูลเชิงพื้นที่โดยใช้สูตรด้านบน
ดูข้อมูล StableHLO ได้ที่ StableHLO - batch_norm_training
Bitcast
ดูเพิ่มเติม
HloInstruction::CreateBitcast
Bitcast อาจปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
BitcastConvertType
ดูเพิ่มเติม
XlaBuilder::BitcastConvertType
คล้ายกับ tf.bitcast ใน TensorFlow ซึ่งดำเนินการ bitcast ระดับองค์ประกอบ
จากรูปร่างข้อมูลไปยังรูปร่างเป้าหมาย ขนาดอินพุตและเอาต์พุตต้องตรงกัน เช่น องค์ประกอบ s32 จะกลายเป็นองค์ประกอบ f32 ผ่านรูทีนการบิตแคสต์ และองค์ประกอบ s32 1 รายการจะกลายเป็นองค์ประกอบ s8 4 รายการ Bitcast ได้รับการติดตั้งใช้งานเป็นการแคสต์ระดับต่ำ ดังนั้นเครื่องที่มีการแทนค่าจุดลอยต่างกันจะให้ผลลัพธ์ที่แตกต่างกัน
BitcastConvertType(operand, new_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T ที่มีมิติ D |
new_element_type |
PrimitiveType |
ประเภท U |
ขนาดของตัวถูกดำเนินการและรูปร่างเป้าหมายต้องตรงกัน ยกเว้น มิติข้อมูลสุดท้ายซึ่งจะเปลี่ยนตามอัตราส่วนของขนาดดั้งเดิมก่อนและ หลังการแปลง
ประเภทองค์ประกอบต้นทางและปลายทางต้องไม่ใช่ Tuple
ดูข้อมูล StableHLO ได้ที่ StableHLO - bitcast_convert
Bitcast-converting to primitive type of different width
BitcastConvert คำสั่ง HLO รองรับกรณีที่ขนาดของประเภทองค์ประกอบเอาต์พุต
T' ไม่เท่ากับขนาดขององค์ประกอบอินพุต T เนื่องจากการดำเนินการทั้งหมดในเชิงแนวคิดคือบิตแคสต์และไม่ได้เปลี่ยนไบต์พื้นฐาน จึงต้องเปลี่ยนรูปร่างขององค์ประกอบเอาต์พุต สำหรับ B = sizeof(T), B' =
sizeof(T') อาจมี 2 กรณีดังนี้
ก่อนอื่น เมื่อ B > B' รูปร่างเอาต์พุตจะมีมิติข้อมูลใหม่ที่เล็กที่สุดซึ่งมีขนาดเป็น
B/B' เช่น
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
กฎสำหรับสเกลาร์ที่มีผลยังคงเหมือนเดิม ดังนี้
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
หรือสำหรับ B' > B คำสั่งกำหนดให้มิติข้อมูลเชิงตรรกะสุดท้าย
ของรูปร่างอินพุตเท่ากับ B'/B และระบบจะทิ้งมิติข้อมูลนี้ระหว่าง
การแปลง
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
โปรดทราบว่า Conversion ระหว่างบิตความกว้างที่แตกต่างกันไม่ใช่แบบทีละองค์ประกอบ
ประกาศ
ดูเพิ่มเติม
XlaBuilder::Broadcast
เพิ่มมิติข้อมูลลงในอาร์เรย์โดยการทำซ้ำข้อมูลในอาร์เรย์
Broadcast(operand, broadcast_sizes)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ที่จะทำซ้ำ |
broadcast_sizes |
ArraySlice<int64> |
ขนาดของมิติข้อมูลใหม่ |
ระบบจะแทรกมิติข้อมูลใหม่ทางด้านซ้าย กล่าวคือ หาก broadcast_sizes มีค่า {a0, ..., aN} และรูปร่างตัวถูกดำเนินการมีมิติข้อมูล {b0, ..., bM} รูปร่างของเอาต์พุตจะมีมิติข้อมูล {a0, ..., aN, b0, ..., bM}
ดัชนีมิติข้อมูลใหม่จะอยู่ในสำเนาของตัวถูกดำเนินการ กล่าวคือ
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
เช่น หาก operand เป็นสเกลาร์ f32 ที่มีค่า 2.0f และ
broadcast_sizes เป็น {2, 3} ผลลัพธ์จะเป็นอาร์เรย์ที่มีรูปร่าง
f32[2, 3] และค่าทั้งหมดในผลลัพธ์จะเป็น 2.0f
ดูข้อมูล StableHLO ได้ที่ StableHLO - broadcast
BroadcastInDim
ดูเพิ่มเติม
XlaBuilder::BroadcastInDim
ขยายขนาดและจำนวนมิติข้อมูลของอาร์เรย์โดยการทำซ้ำข้อมูล ในอาร์เรย์
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ที่จะทำซ้ำ |
out_dim_size
|
ArraySlice<int64>
|
ขนาดของมิติข้อมูล ของรูปร่างเป้าหมาย |
broadcast_dimensions
|
ArraySlice<int64>
|
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
คล้ายกับการออกอากาศ แต่ช่วยให้เพิ่มมิติข้อมูลได้ทุกที่และขยาย มิติข้อมูลที่มีอยู่ด้วยขนาด 1
operand จะออกอากาศไปยังรูปร่างที่อธิบายโดย out_dim_size
broadcast_dimensions จะแมปมิติข้อมูลของ operand กับมิติข้อมูลของ
รูปร่างเป้าหมาย กล่าวคือ มิติข้อมูลที่ i ของตัวถูกดำเนินการจะแมปกับ
มิติข้อมูลที่ broadcast_dimension[i] ของรูปร่างเอาต์พุต มิติข้อมูลของ
operand ต้องมีขนาด 1 หรือมีขนาดเท่ากับมิติข้อมูลในรูปร่างเอาต์พุต
ที่แมปด้วย มิติข้อมูลที่เหลือจะเติมด้วยมิติข้อมูลที่มีขนาด 1 จากนั้นการออกอากาศมิติข้อมูลที่ลดทอนจะออกอากาศตามมิติข้อมูลที่ลดทอนเหล่านี้เพื่อให้ได้รูปร่างเอาต์พุต อธิบายความหมายโดยละเอียดในหน้าการออกอากาศ
โทร
ดูเพิ่มเติม
XlaBuilder::Call
เรียกใช้การคำนวณด้วยอาร์กิวเมนต์ที่ระบุ
Call(computation, operands...)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
computation
|
XlaComputation
|
การคำนวณประเภท T_0, T_1, ...,
T_{N-1} -> S ที่มีพารามิเตอร์ N รายการ
ประเภทใดก็ได้ |
operands |
ลำดับของ N XlaOps |
อาร์กิวเมนต์ N ประเภทใดก็ได้ |
Arity และประเภทของ operands ต้องตรงกับพารามิเตอร์ของ
computation คุณไม่จำเป็นต้องมี operands
CompositeCall
ดูเพิ่มเติม
XlaBuilder::CompositeCall
แคปซูลการดำเนินการที่ประกอบด้วยการดำเนินการ StableHLO อื่นๆ โดยรับอินพุตและ composite_attributes และสร้างผลลัพธ์ ความหมายของ ตัวดำเนินการจะได้รับการติดตั้งใช้งานโดยแอตทริบิวต์การแยกส่วน สามารถแทนที่การดำเนินการแบบคอมโพสิตด้วยการแยกย่อยโดยไม่เปลี่ยนความหมายของโปรแกรม ในกรณีที่การแทรกการแยกย่อยไม่ได้ให้ความหมายของ Op เดียวกัน ให้ใช้ custom_call
ฟิลด์เวอร์ชัน (ค่าเริ่มต้นคือ 0) ใช้เพื่อระบุเมื่อมีการเปลี่ยนแปลงความหมายของคอมโพสิต
การดำเนินการนี้จะใช้เป็น kCall ที่มีแอตทริบิวต์ is_composite=true ฟิลด์
decomposition จะระบุโดยแอตทริบิวต์ computation แอตทริบิวต์ส่วนหน้า
จะจัดเก็บแอตทริบิวต์ที่เหลือซึ่งมีคำนำหน้าเป็น composite.
ตัวอย่างการดำเนินการ CompositeCall
f32[] call(f32[] %cst), to_apply=%computation, is_composite=true,
frontend_attributes = {
composite.name="foo.bar",
composite.attributes={n = 1 : i32, tensor = dense<1> : tensor<i32>},
composite.version="1"
}
CompositeCall(computation, operands..., name, attributes, version)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
computation
|
XlaComputation
|
การคำนวณประเภท T_0, T_1, ...,
T_{N-1} -> S ที่มีพารามิเตอร์ N รายการ
ประเภทใดก็ได้ |
operands |
ลำดับของ N XlaOps |
จำนวนค่าที่เปลี่ยนแปลงได้ |
name |
string |
ชื่อขององค์ประกอบ |
attributes
|
ไม่บังคับ string
|
พจนานุกรมสตริงของแอตทริบิวต์ (ไม่บังคับ) |
version
|
ไม่บังคับ int64
|
หมายเลขเป็นเวอร์ชันที่อัปเดตเป็น ความหมายของการดำเนินการแบบคอมโพสิต |
decomposition ของการดำเนินการไม่ใช่ฟิลด์ที่เรียกว่า แต่จะปรากฏเป็นแอตทริบิวต์ to_apply
ซึ่งชี้ไปยังฟังก์ชันที่มีการใช้งานระดับล่างกว่า
นั่นคือ to_apply=%funcname
ดูข้อมูลเพิ่มเติมเกี่ยวกับการรวมและการแยกย่อยได้ที่ข้อกำหนด StableHLO
Cbrt
ดูเพิ่มเติม
XlaBuilder::Cbrt
การดำเนินการรากที่สามแบบทีละองค์ประกอบ x -> cbrt(x)
Cbrt(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Cbrt ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Cbrt(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - cbrt
เพดาน
ดูเพิ่มเติม
XlaBuilder::Ceil
ฟังก์ชันเพดานแบบองค์ประกอบต่อองค์ประกอบ x -> ⌈x⌉
Ceil(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - ceil
Cholesky
ดูเพิ่มเติม
XlaBuilder::Cholesky
คำนวณ การแยกตัวประกอบ Cholesky ของเมทริกซ์บวกแน่นอนแบบสมมาตร (Hermitian) ในกลุ่ม
Cholesky(a, lower)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
a
|
XlaOp
|
อาร์เรย์ของประเภทเชิงซ้อนหรือประเภทจุดลอยตัวที่มีมิติ > 2 |
lower |
bool |
ว่าจะใช้สามเหลี่ยมด้านบนหรือด้านล่างของ a |
หาก lower เป็น true จะคำนวณเมทริกซ์สามเหลี่ยมล่าง l โดยที่ $a = l .
l^T$ หาก lower คือ false จะคำนวณเมทริกซ์สามเหลี่ยมบน u โดยที่
\(a = u^T . u\)
ระบบจะอ่านข้อมูลอินพุตจากสามเหลี่ยมล่าง/บนของ a เท่านั้น โดยขึ้นอยู่กับค่าของ lower ระบบจะไม่สนใจค่าจากสามเหลี่ยมอีกรูป ข้อมูลเอาต์พุตจะ
แสดงในสามเหลี่ยมเดียวกัน ส่วนค่าในสามเหลี่ยมอีกด้านหนึ่งจะ
ขึ้นอยู่กับการติดตั้งใช้งานและอาจเป็นค่าใดก็ได้
หาก a มีมิติข้อมูลมากกว่า 2 รายการ ระบบจะถือว่า a เป็นกลุ่มเมทริกซ์
โดยที่มิติข้อมูลทั้งหมด ยกเว้นมิติข้อมูล 2 รายการย่อยเป็นมิติข้อมูลกลุ่ม
หาก a ไม่สมมาตร (Hermitian) และเป็นบวกแน่นอน ผลลัพธ์จะขึ้นอยู่กับการใช้งาน
ดูข้อมูล StableHLO ได้ที่ StableHLO - cholesky
เครื่องมือบีบอัด
ดูเพิ่มเติม
XlaBuilder::Clamp
ยึดตัวถูกดำเนินการให้อยู่ในช่วงระหว่างค่าต่ำสุดและสูงสุด
Clamp(min, operand, max)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
min |
XlaOp |
อาร์เรย์ของประเภท T |
operand |
XlaOp |
อาร์เรย์ของประเภท T |
max |
XlaOp |
อาร์เรย์ของประเภท T |
เมื่อระบุตัวถูกดำเนินการ ค่าต่ำสุด และค่าสูงสุด ฟังก์ชันจะแสดงผลตัวถูกดำเนินการหากอยู่ในช่วงระหว่างค่าต่ำสุดและค่าสูงสุด หรือแสดงผลค่าต่ำสุดหากตัวถูกดำเนินการต่ำกว่าช่วงนี้ หรือแสดงผลค่าสูงสุดหากตัวถูกดำเนินการสูงกว่าช่วงนี้ กล่าวคือ clamp(a, x, b) = min(max(a, x), b)
อาร์เรย์ทั้ง 3 ต้องมีรูปร่างเหมือนกัน หรือในรูปแบบที่จำกัดของการออกอากาศ min และ/หรือ max อาจเป็นสเกลาร์ประเภท T
ตัวอย่างที่มีสเกลาร์ min และ max
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
ดูข้อมูล StableHLO ได้ที่ StableHLO - clamp
ยุบ
ดูเพิ่มเติม
XlaBuilder::Collapse
และtf.reshape
ยุบมิติข้อมูลของอาร์เรย์เป็นมิติข้อมูลเดียว
Collapse(operand, dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T |
dimensions |
int64 เวกเตอร์ |
ลำดับย่อยที่ต่อเนื่องกันของมิติข้อมูลของ T |
Collapse จะแทนที่เซ็ตย่อยของมิติข้อมูลของตัวถูกดำเนินการที่ระบุด้วยมิติข้อมูลเดียว
อาร์กิวเมนต์อินพุตคืออาร์เรย์ที่กำหนดเองของประเภท T และเวกเตอร์ค่าคงที่ที่คอมไพล์แล้วของดัชนีมิติข้อมูล ดัชนีมิติข้อมูลต้องเป็น
ชุดย่อยต่อเนื่องของมิติข้อมูลของ T
ตามลำดับ (หมายเลขมิติข้อมูลจากต่ำไปสูง) ดังนั้น {0, 1, 2}, {0, 1} หรือ {1, 2} จึงเป็นชุดมิติข้อมูลที่ถูกต้องทั้งหมด แต่ {1, 0} หรือ {0, 2} ไม่ถูกต้อง โดยระบบจะแทนที่ด้วยมิติข้อมูลใหม่รายการเดียวใน
ตำแหน่งเดียวกันในลําดับมิติข้อมูลกับมิติข้อมูลที่แทนที่ โดยมีขนาดมิติข้อมูลใหม่
เท่ากับผลคูณของขนาดมิติข้อมูลเดิม หมายเลขมิติข้อมูลที่ต่ำที่สุดใน dimensions คือมิติข้อมูลที่มีการเปลี่ยนแปลงช้าที่สุด (สำคัญที่สุด)
ในลูปซ้อนที่ยุบมิติข้อมูลเหล่านี้ และหมายเลขมิติข้อมูลที่สูงที่สุด
คือมิติข้อมูลที่มีการเปลี่ยนแปลงเร็วที่สุด (เล็กที่สุด) ดูตัวดำเนินการ tf.reshape หากต้องการ
การจัดลำดับการยุบโดยทั่วไปเพิ่มเติม
เช่น สมมติว่า v เป็นอาร์เรย์ที่มี 24 องค์ประกอบ
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
Clz
ดูเพิ่มเติม
XlaBuilder::Clz
นับเลข 0 นำหน้าแบบทีละองค์ประกอบ
Clz(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
CollectiveBroadcast
ดูเพิ่มเติม
XlaBuilder::CollectiveBroadcast
ออกอากาศข้อมูลในสำเนา ข้อมูลจะถูกส่งจากรหัสสำเนาแรกในแต่ละกลุ่มไปยังรหัสอื่นๆ ในกลุ่มเดียวกัน หากรหัสสำเนาไม่ได้อยู่ในกลุ่มสำเนาใดๆ เอาต์พุตในสำเนานั้นจะเป็น Tensor ที่ประกอบด้วย 0 ใน shape
CollectiveBroadcast(operand, replica_groups, channel_id)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
replica_groups
|
ReplicaGroupเวกเตอร์
|
แต่ละกลุ่มจะมีรายการ รหัสรีเพลส |
channel_id
|
ไม่บังคับ ChannelHandle
|
ตัวระบุที่ไม่ซ้ำกันสำหรับคู่ send/recv แต่ละคู่ |
ดูข้อมูล StableHLO ได้ที่ StableHLO - collective_broadcast
CollectivePermute
ดูเพิ่มเติม
XlaBuilder::CollectivePermute
CollectivePermute เป็นการดำเนินการแบบกลุ่มที่ส่งและรับข้อมูลในรีเพลส
CollectivePermute(operand, source_target_pairs, channel_id)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
source_target_pairs
|
<int64, int64> เวกเตอร์
|
รายการคู่ (source_replica_id, target_replica_id) สำหรับแต่ละคู่ ระบบจะส่งตัวถูกดำเนินการจาก รีเพลสต้นทางไปยังรีเพลสเป้าหมาย |
channel_id
|
ไม่บังคับ ChannelHandle
|
รหัสช่องที่ไม่บังคับสำหรับการสื่อสาร ข้ามโมดูล |
โปรดทราบว่าsource_target_pairs มีข้อจำกัดต่อไปนี้
- คู่ใดๆ 2 คู่ไม่ควรมีรหัสรีเพลสเป้าหมายเดียวกัน และไม่ควรมีรหัสรีเพลสต้นทางเดียวกัน
- หากรหัสตัวจำลองไม่ใช่เป้าหมายในคู่ใดๆ เอาต์พุตในตัวจำลองนั้นจะเป็น Tensor ที่ประกอบด้วย 0 ที่มีรูปร่างเดียวกับอินพุต
API ของการดำเนินการ CollectivePermute จะแยกออกเป็นคำสั่ง HLO 2 รายการภายใน (CollectivePermuteStart และ CollectivePermuteDone)
ดูเพิ่มเติม
HloInstruction::CreateCollectivePermuteStart
CollectivePermuteStart และ CollectivePermuteDone ทำหน้าที่เป็นองค์ประกอบพื้นฐานใน HLO
การดำเนินการเหล่านี้อาจปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
ดูข้อมูล StableHLO ได้ที่ StableHLO - collective_permute
เปรียบเทียบ
ดูเพิ่มเติม
XlaBuilder::Compare
ดำเนินการเปรียบเทียบแบบทีละองค์ประกอบของ lhs และ rhs ของรายการต่อไปนี้
Eq
ดูเพิ่มเติม
XlaBuilder::Eq
ทำการเปรียบเทียบเท่ากับแบบทีละองค์ประกอบของ lhs และ rhs
\(lhs = rhs\)
Eq(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
มีรูปแบบอื่นที่รองรับการออกอากาศแบบหลายมิติ สำหรับ Eq ดังนี้
Eq(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
รองรับยอดสั่งซื้อทั้งหมดที่มากกว่าจำนวนทศนิยมสำหรับ Eq โดยการบังคับใช้สิ่งต่อไปนี้
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
EqTotalOrder(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - เปรียบเทียบ
Ne
ดูเพิ่มเติม
XlaBuilder::Ne
ดำเนินการเปรียบเทียบไม่เท่ากับแบบทีละองค์ประกอบของ lhs และ rhs
\(lhs != rhs\)
Ne(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Ne มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Ne(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
รองรับยอดสั่งซื้อทั้งหมดที่มากกว่าตัวเลขทศนิยมสำหรับ Ne โดยการบังคับใช้สิ่งต่อไปนี้
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
NeTotalOrder(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - เปรียบเทียบ
Ge
ดูเพิ่มเติม
XlaBuilder::Ge
ดำเนินการเปรียบเทียบgreater-or-equal-thanแบบทีละองค์ประกอบของ lhs และ rhs
\(lhs >= rhs\)
Ge(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Ge มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Ge(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
รองรับคำสั่งซื้อทั้งหมดที่มากกว่าเลขทศนิยมสำหรับ Gt โดยการบังคับใช้สิ่งต่อไปนี้
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
GtTotalOrder(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - เปรียบเทียบ
Gt
ดูเพิ่มเติม
XlaBuilder::Gt
ดำเนินการเปรียบเทียบมากกว่าแบบทีละองค์ประกอบของ lhs และ rhs
\(lhs > rhs\)
Gt(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Gt มีตัวแปรอื่นที่รองรับการออกอากาศแบบหลายมิติ ดังนี้
Gt(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - เปรียบเทียบ
Le
ดูเพิ่มเติม
XlaBuilder::Le
ทำการเปรียบเทียบless-or-equal-thanแบบทีละองค์ประกอบของ lhs และ rhs
\(lhs <= rhs\)
Le(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ สำหรับ Le ดังนี้
Le(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
รองรับคำสั่งซื้อทั้งหมดที่มากกว่าจำนวนจุดทศนิยมสำหรับ Le โดยการบังคับใช้สิ่งต่อไปนี้
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LeTotalOrder(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - เปรียบเทียบ
Lt
ดูเพิ่มเติม
XlaBuilder::Lt
ดำเนินการเปรียบเทียบน้อยกว่าแบบทีละองค์ประกอบของ lhs และ rhs
\(lhs < rhs\)
Lt(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
มีตัวแปรอื่นที่รองรับการออกอากาศแบบหลายมิติสำหรับ Lt ดังนี้
Lt(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
รองรับคำสั่งซื้อทั้งหมดที่มากกว่าจำนวนจุดลอยตัวสำหรับ Lt โดยการบังคับใช้สิ่งต่อไปนี้
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LtTotalOrder(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - เปรียบเทียบ
ซับซ้อน
ดูเพิ่มเติม
XlaBuilder::Complex
ทำการแปลงค่าทีละองค์ประกอบเป็นค่าเชิงซ้อนจากคู่ค่าจริงและค่าจินตภาพ lhs และ rhs
Complex(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Complex มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Complex(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - complex
ConcatInDim (เชื่อมต่อ)
ดูเพิ่มเติม
XlaBuilder::ConcatInDim
Concatenate จะสร้างอาร์เรย์จากตัวถูกดำเนินการอาร์เรย์หลายรายการ อาร์เรย์มี จำนวนมิติข้อมูลเท่ากับตัวถูกดำเนินการของอาร์เรย์อินพุตแต่ละตัว (ซึ่งต้องมี จำนวนมิติข้อมูลเท่ากัน) และมีอาร์กิวเมนต์ตาม ลำดับที่ระบุ
Concatenate(operands..., dimension)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands
|
ลำดับของ N XlaOp
|
อาร์เรย์ N ประเภท T ที่มีมิติข้อมูล [L0, L1, ...]. ต้องมี N >= 1 |
dimension
|
int64
|
ค่าในช่วง [0, N) ที่
ตั้งชื่อมิติข้อมูลที่จะต่อกัน
ระหว่าง operands |
ยกเว้น dimension มิติข้อมูลทั้งหมดต้องเหมือนกัน เนื่องจาก XLA ไม่รองรับอาร์เรย์ "ไม่สม่ำเสมอ" โปรดทราบด้วยว่าค่า 0 มิติไม่สามารถต่อกันได้ (เนื่องจากตั้งชื่อมิติข้อมูลที่เกิดการต่อกันไม่ได้)
ตัวอย่าง 1 มิติ
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
//Output: {2, 3, 4, 5, 6, 7}
ตัวอย่าง 2 มิติ
let a = { {1, 2},
{3, 4},
{5, 6} };
let b = { {7, 8} };
Concat({a, b}, 0)
//Output: { {1, 2},
// {3, 4},
// {5, 6},
// {7, 8} }
แผนภาพ
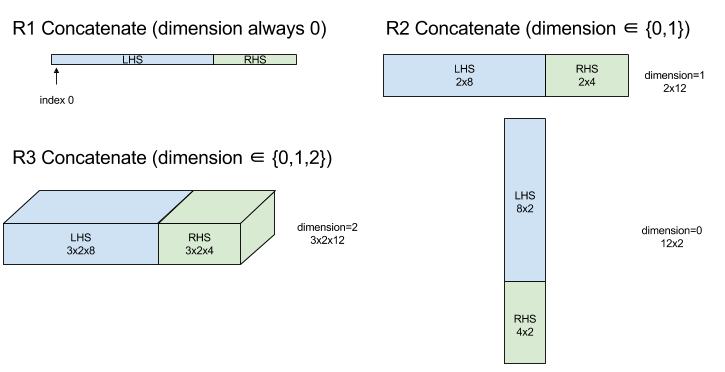
ดูข้อมูล StableHLO ได้ที่ StableHLO - concatenate
มีเงื่อนไข
ดูเพิ่มเติม
XlaBuilder::Conditional
Conditional(predicate, true_operand, true_computation, false_operand,
false_computation)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
predicate |
XlaOp |
สเกลาร์ของประเภท PRED |
true_operand |
XlaOp |
อาร์กิวเมนต์ของประเภท \(T_0\) |
true_computation |
XlaComputation |
XlaComputation ของประเภท \(T_0 \to S\) |
false_operand |
XlaOp |
อาร์กิวเมนต์ของประเภท \(T_1\) |
false_computation |
XlaComputation |
XlaComputation ของประเภท \(T_1 \to S\) |
เรียกใช้ true_computation หาก predicate เป็น true, false_computation หาก predicate เป็น false และแสดงผลลัพธ์
true_computation ต้องรับอาร์กิวเมนต์เดียวประเภท \(T_0\) และจะเรียกใช้ด้วย true_operand ซึ่งต้องเป็นประเภทเดียวกัน false_computation ต้องรับอาร์กิวเมนต์เดียวประเภท \(T_1\) และจะเรียกใช้ด้วย false_operand ซึ่งต้องเป็นประเภทเดียวกัน ประเภทของค่าที่แสดงผลของ true_computation และ false_computation ต้องเป็นประเภทเดียวกัน
โปรดทราบว่าระบบจะเรียกใช้เพียง true_computation หรือ false_computation เท่านั้น
โดยขึ้นอยู่กับค่าของ predicate
Conditional(branch_index, branch_computations, branch_operands)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
branch_index |
XlaOp |
สเกลาร์ของประเภท S32 |
branch_computations |
ลำดับของ N XlaComputation |
XlaComputations ของประเภท \(T_0 \to S , T_1 \to S , ..., T_{N-1} \to S\) |
branch_operands |
ลำดับของ N XlaOp |
อาร์กิวเมนต์ของประเภท \(T_0 , T_1 , ..., T_{N-1}\) |
เรียกใช้ branch_computations[branch_index] และแสดงผลลัพธ์ หาก branch_index เป็น S32 ซึ่งมีค่าน้อยกว่า 0 หรือมากกว่าหรือเท่ากับ N ระบบจะเรียกใช้ branch_computations[N-1]
เป็นกิ่งก้านเริ่มต้น
branch_computations[b] แต่ละรายการต้องรับอาร์กิวเมนต์เดียวประเภท \(T_b\) และ
จะเรียกใช้ด้วย branch_operands[b] ซึ่งต้องเป็นประเภทเดียวกัน
ประเภทของค่าที่แสดงผลของแต่ละ branch_computations[b] ต้องเหมือนกัน
โปรดทราบว่าระบบจะเรียกใช้เพียง 1 รายการใน branch_computations โดยขึ้นอยู่กับค่าของ branch_index
ดูข้อมูล StableHLO ได้ที่ StableHLO - if
ค่าคงที่
ดูเพิ่มเติม
XlaBuilder::ConstantLiteral
สร้าง output จากค่าคงที่ literal
Constant(literal)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
literal |
LiteralSlice |
มุมมองคงที่ของ Literal ที่มีอยู่ |
ดูข้อมูล StableHLO ได้ที่ StableHLO - constant
ConvertElementType
ดูเพิ่มเติม
XlaBuilder::ConvertElementType
ConvertElementType จะดำเนินการแปลงทีละองค์ประกอบจากรูปร่างข้อมูลไปยังรูปร่างเป้าหมาย เช่นเดียวกับ static_cast ใน C++
มิติข้อมูลต้องตรงกัน และ Conversion เป็นแบบทีละองค์ประกอบ เช่น s32
องค์ประกอบจะกลายเป็น f32 องค์ประกอบผ่านกิจวัตรการแปลงจาก s32 เป็น f32
ConvertElementType(operand, new_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T ที่มีมิติ D |
new_element_type |
PrimitiveType |
ประเภท U |
มิติข้อมูลของตัวถูกดำเนินการและรูปร่างเป้าหมายต้องตรงกัน ประเภทองค์ประกอบต้นทางและปลายทางต้องไม่ใช่ Tuple
Conversion เช่น T=s32 เป็น U=f32 จะเรียกใช้การแปลง int เป็น float แบบปกติ
เช่น การปัดเศษเป็นจำนวนคู่ที่ใกล้ที่สุด
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
ดูข้อมูล StableHLO ได้ที่ StableHLO - convert
Conv (Convolution)
ดูเพิ่มเติม
XlaBuilder::Conv
คำนวณการสังวัตนาการประเภทที่ใช้ในโครงข่ายประสาทเทียม ในที่นี้ คุณสามารถคิดว่า Convolution เป็นหน้าต่าง n มิติที่เคลื่อนที่ผ่านพื้นที่ฐาน n มิติ และมีการคำนวณสำหรับตำแหน่งที่เป็นไปได้แต่ละตำแหน่งของหน้าต่าง
Conv จัดคิวคำสั่งการแปลงแบบคอนโวลูชันในการคำนวณ ซึ่งใช้
หมายเลขมิติข้อมูลการแปลงแบบคอนโวลูชันเริ่มต้นโดยไม่มีการขยาย
โดยจะระบุการเพิ่มแพดดิ้งในรูปแบบย่อเป็น SAME หรือ VALID การเพิ่มแพดดิ้ง SAME
จะเพิ่ม 0 ให้กับอินพุต (lhs) เพื่อให้เอาต์พุตมีรูปร่างเหมือนกับอินพุต
เมื่อไม่พิจารณาการก้าวกระโดด การเพิ่มระยะห่างที่ถูกต้องหมายถึง
ไม่มีการเพิ่มระยะห่าง
Conv(lhs, rhs, window_strides, padding, feature_group_count,
batch_group_count, precision_config, preferred_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs
|
XlaOp
|
อาร์เรย์ (n+2) มิติของ อินพุต |
rhs
|
XlaOp
|
อาร์เรย์ (n+2) มิติของ น้ำหนักเคอร์เนล |
window_strides |
ArraySlice<int64> |
อาร์เรย์ n มิติของระยะก้าวกระโดดของเคอร์เนล |
padding |
Padding |
enum ของการเว้นวรรค |
feature_group_count
|
int64 | จำนวนกลุ่มฟีเจอร์ |
batch_group_count |
int64 | จำนวนกลุ่มแบทช์ |
precision_config
|
ไม่บังคับ
PrecisionConfig |
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ
PrimitiveType |
enum ของประเภทองค์ประกอบสเกลาร์ |
Conv มีการควบคุมในระดับต่างๆ ดังนี้
ให้ n เป็นจำนวนมิติเชิงพื้นที่ อาร์กิวเมนต์ lhs คืออาร์เรย์ (n+2) มิติที่อธิบายพื้นที่ฐาน ซึ่งเรียกว่าอินพุต
แม้ว่าแน่นอนว่า rhs ก็เป็นอินพุตเช่นกัน ในโครงข่ายระบบประสาทเทียม สิ่งเหล่านี้คือ
การเปิดใช้งานอินพุต มิติข้อมูล n+2 ตามลำดับมีดังนี้
batch: พิกัดแต่ละรายการในมิติข้อมูลนี้แสดงถึงอินพุตอิสระ ซึ่งมีการดำเนินการ Convolutionz/depth/features: ตำแหน่ง (y,x) แต่ละตำแหน่งในพื้นที่ฐานมีเวกเตอร์ ที่เชื่อมโยงอยู่ ซึ่งจะอยู่ในมิติข้อมูลนี้spatial_dims: อธิบายnมิติเชิงพื้นที่ที่กำหนดพื้นที่ฐาน ซึ่งหน้าต่างเคลื่อนที่ผ่าน
อาร์กิวเมนต์ rhs คืออาร์เรย์ (n+2) มิติที่อธิบายตัวกรอง/เคอร์เนล/หน้าต่างแบบ Convolutional
โดยมีมิติตามลำดับต่อไปนี้
output-z:zมิติข้อมูลของเอาต์พุตinput-z: ขนาดของมิติข้อมูลนี้คูณด้วยfeature_group_countควร เท่ากับขนาดของมิติข้อมูลzใน lhsspatial_dims: อธิบายnมิติเชิงพื้นที่ที่กำหนดหน้าต่าง n-d ซึ่งเคลื่อนที่ไปทั่วพื้นที่ฐาน
อาร์กิวเมนต์ window_strides ระบุระยะก้าวกระโดดของหน้าต่าง Convolution
ในมิติเชิงพื้นที่ ตัวอย่างเช่น หากระยะก้าวกระโดดในมิติเชิงพื้นที่แรกเป็น 3 ระบบจะวางหน้าต่างได้เฉพาะที่พิกัดซึ่งดัชนีเชิงพื้นที่แรกหารด้วย 3 ลงตัว
อาร์กิวเมนต์ padding ระบุจำนวนการเพิ่มค่า 0 ที่จะใช้กับพื้นที่ฐาน จำนวนการเพิ่มค่า 0 อาจเป็นค่าลบได้ โดยค่าสัมบูรณ์ของการเพิ่มค่า 0 ที่เป็นค่าลบจะระบุจำนวนองค์ประกอบที่จะนำออกจากมิติข้อมูลที่ระบุก่อนทำการ Convolution padding[0] ระบุการเพิ่มค่า 0 สำหรับมิติข้อมูล y และ padding[1] ระบุการเพิ่มค่า 0 สำหรับมิติข้อมูล x แต่ละคู่มีการเพิ่มค่า 0 ต่ำเป็นองค์ประกอบแรกและการเพิ่มค่า 0 สูงเป็นองค์ประกอบที่ 2 การเพิ่มค่า 0 ต่ำจะใช้ในทิศทางของดัชนีที่ต่ำกว่า ในขณะที่การเพิ่มค่า 0 สูงจะใช้ในทิศทางของดัชนีที่สูงกว่า ตัวอย่างเช่น หาก padding[1] เป็น (2,3) จะมีการเพิ่มค่า 0 จำนวน 2 ค่าทางด้านซ้ายและ 3 ค่าทางด้านขวาในมิติข้อมูลเชิงพื้นที่ที่ 2 การใช้การเพิ่มค่า 0 จะเทียบเท่ากับการแทรกค่า 0 เดียวกันเหล่านั้นลงในอินพุต (lhs) ก่อนทำการ Convolution
อาร์กิวเมนต์ lhs_dilation และ rhs_dilation จะระบุปัจจัยการขยายที่จะใช้กับ lhs และ rhs ตามลำดับในแต่ละมิติเชิงพื้นที่ หาก
ปัจจัยการขยายในมิติเชิงพื้นที่คือ d ระบบจะวางรู d-1 โดยนัย
ระหว่างรายการแต่ละรายการในมิตินั้น ซึ่งจะเพิ่มขนาดของ
อาร์เรย์ โดยจะเติมค่าที่ไม่มีการดำเนินการลงในช่องว่าง ซึ่งสำหรับการ Convolution จะหมายถึง
ค่า 0
การขยาย rhs เรียกอีกอย่างว่าการแปลงแบบ Atrous ดูรายละเอียดเพิ่มเติมได้ที่
tf.nn.atrous_conv2d การขยาย lhs เรียกอีกอย่างว่าการแปลงแบบ
Convolution ดูรายละเอียดเพิ่มเติมได้ที่ tf.nn.conv2d_transpose
อาร์กิวเมนต์ feature_group_count (ค่าเริ่มต้นคือ 1) ใช้ได้กับการ
คอนโวลูชันแบบจัดกลุ่ม feature_group_count ต้องเป็นตัวหารของทั้งมิติข้อมูลฟีเจอร์อินพุตและ
เอาต์พุต หาก feature_group_count มากกว่า 1 แสดงว่าในเชิงแนวคิด มิติข้อมูลฟีเจอร์อินพุตและเอาต์พุต รวมถึงrhs
มิติข้อมูลฟีเจอร์เอาต์พุตจะแยกออกเป็นหลายกลุ่ม feature_group_count
อย่างเท่าเทียมกัน โดยแต่ละกลุ่มประกอบด้วยลำดับย่อยของฟีเจอร์ที่ต่อเนื่องกัน มิติข้อมูลฟีเจอร์อินพุตของ rhs ต้องเท่ากับมิติข้อมูลฟีเจอร์อินพุต lhs
หารด้วย feature_group_count (จึงมีขนาดเท่ากับกลุ่มฟีเจอร์อินพุตอยู่แล้ว) ระบบจะใช้กลุ่มที่ i ร่วมกันเพื่อคำนวณ feature_group_count สำหรับคอนโวลูชันแยกกันหลายรายการ ผลลัพธ์ของคอนโวลูชันเหล่านี้จะต่อกันในมิติข้อมูลฟีเจอร์เอาต์พุต
สำหรับการผันแปรตามความลึก อาร์กิวเมนต์ feature_group_count จะได้รับการตั้งค่าเป็น
มิติข้อมูลฟีเจอร์อินพุต และตัวกรองจะได้รับการปรับรูปร่างจาก
[filter_height, filter_width, in_channels, channel_multiplier] เป็น
[filter_height, filter_width, 1, in_channels * channel_multiplier] ดูรายละเอียดเพิ่มเติมได้ที่ tf.nn.depthwise_conv2d
อาร์กิวเมนต์ batch_group_count (ค่าเริ่มต้นคือ 1) สามารถใช้กับตัวกรองที่จัดกลุ่ม
ระหว่างการแพร่ย้อนกลับได้ batch_group_count ต้องเป็นตัวหารของขนาดมิติข้อมูลกลุ่มของ lhs (อินพุต) หาก batch_group_count มากกว่า 1 แสดงว่ามิติข้อมูลกลุ่มเอาต์พุตควรมีขนาด input batch
/ batch_group_count batch_group_count ต้องเป็นตัวหารของขนาดฟีเจอร์เอาต์พุต
รูปร่างเอาต์พุตมีมิติข้อมูลต่อไปนี้ตามลำดับ
batch: ขนาดของมิติข้อมูลนี้คูณด้วยbatch_group_countควรเท่ากับขนาดของมิติข้อมูลbatchใน lhsz: ขนาดเดียวกับoutput-zในเคอร์เนล (rhs)spatial_dims: ค่า 1 ค่าสําหรับตําแหน่งที่ถูกต้องแต่ละตําแหน่งของหน้าต่าง Convolutional

รูปภาพด้านบนแสดงวิธีการทำงานของช่อง batch_group_count กล่าวคือ เราจะแบ่งกลุ่มชุดข้อมูล LHS แต่ละชุดออกเป็น batch_group_count กลุ่ม และทำเช่นเดียวกันกับฟีเจอร์เอาต์พุต จากนั้นสำหรับแต่ละกลุ่ม เราจะทำการสังวัตนาการแบบเป็นคู่และ
ต่อเอาต์พุตตามมิติข้อมูลฟีเจอร์เอาต์พุต ความหมายเชิงปฏิบัติการ
ของมิติข้อมูลอื่นๆ ทั้งหมด (ฟีเจอร์และเชิงพื้นที่) ยังคงเหมือนเดิม
การวางหน้าต่าง Convolution ที่ถูกต้องจะกำหนดโดย Strides และขนาดของพื้นที่ฐานหลังจากการเพิ่ม Padding
หากต้องการอธิบายว่า Convolution ทำอะไร ให้พิจารณา Convolution แบบ 2 มิติ แล้วเลือกพิกัด batch, z, y, x ที่คงที่ในเอาต์พุต จากนั้น (y,x) คือ
ตำแหน่งของมุมหน้าต่างภายในพื้นที่ฐาน (เช่น มุมซ้ายบน
ขึ้นอยู่กับวิธีตีความมิติเชิงพื้นที่) ตอนนี้เรามีหน้าต่าง 2 มิติ
ซึ่งนำมาจากพื้นที่ฐาน โดยแต่ละจุด 2 มิติจะเชื่อมโยงกับเวกเตอร์ 1 มิติ
เพื่อให้ได้กล่อง 3 มิติ จากเคอร์เนลแบบ Convolutional เนื่องจากเราแก้ไขพิกัดเอาต์พุต z เราจึงมีกล่อง 3 มิติด้วย กล่องทั้ง 2 มีขนาดเท่ากัน ดังนั้นเราจึงนำผลคูณแบบทีละองค์ประกอบระหว่างกล่องทั้ง 2 มาบวกกันได้ (คล้ายกับผลคูณแบบดอท) ซึ่งเป็นค่าเอาต์พุต
โปรดทราบว่าหาก output-z เป็น 5 เป็นต้น แต่ละตำแหน่งของหน้าต่างจะสร้างค่า 5 ค่าในเอาต์พุตลงในมิติข้อมูล z ของเอาต์พุต ค่าเหล่านี้แตกต่างกัน
ในส่วนของเคอร์เนล Convolutional ที่ใช้ โดยมีกล่อง 3 มิติแยกต่างหากของ
ค่าที่ใช้สำหรับพิกัด output-z แต่ละค่า ดังนั้น คุณอาจคิดว่าเป็นการทำ Convolution แยกกัน 5 ครั้งโดยใช้ฟิลเตอร์ที่แตกต่างกันสำหรับแต่ละครั้ง
ต่อไปนี้คือรหัสหลอกสำหรับการสังวัตนาการ 2 มิติที่มีการเพิ่มระยะขอบและการก้าวกระโดด
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
precision_config ใช้เพื่อระบุการกำหนดค่าความแม่นยำ ระดับจะกำหนดว่าฮาร์ดแวร์ควรพยายามสร้างคำสั่งรหัสเครื่องเพิ่มเติมเพื่อจำลอง dtype ได้แม่นยำยิ่งขึ้นเมื่อจำเป็นหรือไม่ (เช่น จำลอง f32 ใน TPU ที่รองรับเฉพาะ bf16 matmuls) ค่าอาจเป็น
DEFAULT, HIGH, HIGHEST รายละเอียดเพิ่มเติม
ในส่วน MXU
preferred_element_type เป็นองค์ประกอบสเกลาร์ของเอาต์พุตที่มีความแม่นยำสูง/ต่ำกว่า
ประเภทที่ใช้สำหรับการสะสม preferred_element_type แนะนำ
ประเภทการสะสมสำหรับการดำเนินการที่กำหนด แต่ไม่รับประกันว่าจะเป็นประเภทนั้น
ซึ่งช่วยให้แบ็กเอนด์ฮาร์ดแวร์บางรายการสะสมในประเภทอื่นแทนได้
และแปลงเป็นประเภทเอาต์พุตที่ต้องการ
ดูข้อมูล StableHLO ได้ที่ StableHLO - การสังวัตนาการ
ConvWithGeneralPadding
ดูเพิ่มเติม
XlaBuilder::ConvWithGeneralPadding
ConvWithGeneralPadding(lhs, rhs, window_strides, padding,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
เช่นเดียวกับ Conv ที่มีการกำหนดค่าการเพิ่มระยะขอบอย่างชัดเจน
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs
|
XlaOp
|
อาร์เรย์ (n+2) มิติของ อินพุต |
rhs
|
XlaOp
|
อาร์เรย์ (n+2) มิติของ น้ำหนักเคอร์เนล |
window_strides |
ArraySlice<int64> |
อาร์เรย์ n มิติของระยะก้าวกระโดดของเคอร์เนล |
padding
|
ArraySlice<
pair<int64,int64>> |
อาร์เรย์ n มิติของ (ต่ำ, สูง) การเพิ่มพื้นที่ |
feature_group_count
|
int64 | จำนวนกลุ่มฟีเจอร์ |
batch_group_count |
int64 | จำนวนกลุ่มแบทช์ |
precision_config
|
ไม่บังคับ
PrecisionConfig |
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ
PrimitiveType |
enum ของประเภทองค์ประกอบสเกลาร์ |
ConvWithGeneralDimensions
ดูเพิ่มเติม
XlaBuilder::ConvWithGeneralDimensions
ConvWithGeneralDimensions(lhs, rhs, window_strides, padding,
dimension_numbers, feature_group_count, batch_group_count, precision_config,
preferred_element_type)
เช่นเดียวกับ Conv ที่ระบุหมายเลขมิติข้อมูลอย่างชัดเจน
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs
|
XlaOp
|
อาร์เรย์อินพุต (n+2) มิติ |
rhs
|
XlaOp
|
อาร์เรย์ (n+2) มิติของ น้ำหนักเคอร์เนล |
window_strides
|
ArraySlice<int64>
|
อาร์เรย์ n-d ของ ระยะก้าวกระโดดของเคอร์เนล |
padding |
Padding |
enum ของการเว้นวรรค |
dimension_numbers
|
ConvolutionDimensionNumbers
|
จำนวน มิติข้อมูล |
feature_group_count
|
int64 | จำนวน กลุ่มฟีเจอร์ |
batch_group_count
|
int64 | จำนวน กลุ่มแบทช์ |
precision_config
|
ไม่บังคับ PrecisionConfig
|
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ PrimitiveType
|
enum ของประเภทองค์ประกอบสเกลาร์ |
ConvGeneral
ดูเพิ่มเติม
XlaBuilder::ConvGeneral
ConvGeneral(lhs, rhs, window_strides, padding, dimension_numbers,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
เช่นเดียวกับ Conv ที่มีการกำหนดหมายเลขมิติข้อมูลและการกำหนดค่าระยะห่างจากขอบอย่างชัดเจน
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs
|
XlaOp
|
อาร์เรย์อินพุต (n+2) มิติ |
rhs
|
XlaOp
|
อาร์เรย์ (n+2) มิติของ น้ำหนักเคอร์เนล |
window_strides
|
ArraySlice<int64>
|
อาร์เรย์ n-d ของ ระยะก้าวกระโดดของเคอร์เนล |
padding
|
ArraySlice<
pair<int64,int64>>
|
อาร์เรย์ n มิติของ (ต่ำ, สูง) การเว้นวรรค |
dimension_numbers
|
ConvolutionDimensionNumbers
|
จำนวน มิติข้อมูล |
feature_group_count
|
int64 | จำนวน กลุ่มฟีเจอร์ |
batch_group_count
|
int64 | จำนวน กลุ่มแบทช์ |
precision_config
|
ไม่บังคับ PrecisionConfig
|
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ PrimitiveType
|
enum ของประเภทองค์ประกอบสเกลาร์ |
ConvGeneralDilated
ดูเพิ่มเติม
XlaBuilder::ConvGeneralDilated
ConvGeneralDilated(lhs, rhs, window_strides, padding, lhs_dilation,
rhs_dilation, dimension_numbers, feature_group_count, batch_group_count,
precision_config, preferred_element_type, window_reversal)
เช่นเดียวกับ Conv ซึ่งมีการกำหนดค่าการเพิ่มระยะขอบ ค่าการขยาย และหมายเลขมิติข้อมูลอย่างชัดเจน
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs
|
XlaOp
|
อาร์เรย์อินพุต (n+2) มิติ |
rhs
|
XlaOp
|
อาร์เรย์ (n+2) มิติของ น้ำหนักเคอร์เนล |
window_strides
|
ArraySlice<int64>
|
อาร์เรย์ n-d ของ ระยะก้าวกระโดดของเคอร์เนล |
padding
|
ArraySlice<
pair<int64,int64>>
|
อาร์เรย์ n มิติของ (ต่ำ, สูง) การเว้นวรรค |
lhs_dilation
|
ArraySlice<int64>
|
อาร์เรย์แฟกเตอร์การขยาย lhs แบบ n มิติ |
rhs_dilation
|
ArraySlice<int64>
|
อาร์เรย์แฟกเตอร์การขยาย rhs แบบ n-d |
dimension_numbers
|
ConvolutionDimensionNumbers
|
จำนวน มิติข้อมูล |
feature_group_count
|
int64 | จำนวน กลุ่มฟีเจอร์ |
batch_group_count
|
int64 | จำนวน กลุ่มแบทช์ |
precision_config
|
ไม่บังคับ PrecisionConfig
|
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ PrimitiveType
|
enum ของประเภทองค์ประกอบสเกลาร์ |
window_reversal
|
ไม่บังคับ vector<bool>
|
flag used to logically reverse dimension before applying the convolution |
คัดลอก
ดูเพิ่มเติม
HloInstruction::CreateCopyStart
Copy จะแยกออกเป็นคำสั่ง HLO 2 รายการภายใน ได้แก่ CopyStart และ
CopyDone Copy รวมถึง CopyStart และ CopyDone ทำหน้าที่เป็นองค์ประกอบพื้นฐานใน
HLO การดำเนินการเหล่านี้อาจปรากฏในการดัมพ์ HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
Cos
ดูXlaBuilder::Cosด้วย
โคไซน์แบบองค์ประกอบต่อองค์ประกอบ x -> cos(x)
Cos(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Cos ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Cos(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - โคไซน์
Cosh
ดูเพิ่มเติม
XlaBuilder::Cosh
ไฮเพอร์โบลิกโคไซน์แบบองค์ประกอบต่อองค์ประกอบ x -> cosh(x)
Cosh(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Cosh ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Cosh(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
CustomCall
ดูเพิ่มเติม
XlaBuilder::CustomCall
เรียกใช้ฟังก์ชันที่ผู้ใช้ระบุภายในการคำนวณ
เอกสารประกอบเกี่ยวกับ CustomCall มีอยู่ใน รายละเอียดสำหรับนักพัฒนาซอฟต์แวร์ - XLA Custom Calls
ดูข้อมูล StableHLO ได้ที่ StableHLO - custom_call
Div
ดูเพิ่มเติม
XlaBuilder::Div
ทำการหารแบบทีละองค์ประกอบของตัวตั้ง lhs และตัวหาร rhs
Div(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
การล้นของการหารจำนวนเต็ม (การหาร/เศษที่ลงชื่อ/ไม่ได้ลงชื่อด้วย 0 หรือการหาร/เศษที่ลงชื่อของ INT_SMIN ด้วย -1) จะสร้างค่าที่กำหนดการใช้งาน
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Div มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Div(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - divide
โดเมน
ดูเพิ่มเติม
HloInstruction::CreateDomain
Domain อาจปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
จุด
ดูเพิ่มเติม
XlaBuilder::Dot
Dot(lhs, rhs, precision_config, preferred_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs |
XlaOp |
อาร์เรย์ของประเภท T |
rhs |
XlaOp |
อาร์เรย์ของประเภท T |
precision_config
|
ไม่บังคับ
PrecisionConfig |
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ
PrimitiveType |
enum ของประเภทองค์ประกอบสเกลาร์ |
ความหมายที่แน่นอนของการดำเนินการนี้ขึ้นอยู่กับอันดับของตัวถูกดำเนินการ
| อินพุต | เอาต์พุต | ความหมาย |
|---|---|---|
เวกเตอร์ [คำนาม] dot เวกเตอร์ [คำนาม] |
สเกลาร์ | ผลคูณสเกลาร์ของเวกเตอร์ |
เมทริกซ์ [m x k] dot เวกเตอร์
[k] |
เวกเตอร์ [m] | การคูณเมทริกซ์กับเวกเตอร์ |
เมทริกซ์ [m x k] dot เมทริกซ์
[k x n] |
เมทริกซ์ [m x n] | การคูณเมทริกซ์กับเมทริกซ์ |
การดำเนินการจะหาผลรวมของผลิตภัณฑ์ในมิติที่ 2 ของ lhs (หรือมิติแรกหากมี 1 มิติ) และมิติแรกของ rhs ซึ่งเป็นมิติข้อมูล "ที่ทำสัญญา" มิติข้อมูลที่หดตัวของ lhs และ rhs ต้องมีขนาดเท่ากัน
ในทางปฏิบัติ ฟังก์ชันนี้สามารถใช้เพื่อดำเนินการดอทโปรดักต์ระหว่าง
เวกเตอร์ การคูณเวกเตอร์/เมทริกซ์ หรือการคูณเมทริกซ์/เมทริกซ์
precision_config ใช้เพื่อระบุการกำหนดค่าความแม่นยำ ระดับ จะกำหนดว่าฮาร์ดแวร์ควรพยายามสร้างคำสั่งรหัสเครื่องเพิ่มเติมเพื่อจำลอง dtype ได้แม่นยำยิ่งขึ้นเมื่อจำเป็นหรือไม่ (เช่น จำลอง f32 ใน TPU ที่รองรับเฉพาะ bf16 matmuls) ค่าอาจเป็น
DEFAULT, HIGH, HIGHEST รายละเอียดเพิ่มเติม
ในส่วน MXU
preferred_element_type เป็นองค์ประกอบสเกลาร์ของเอาต์พุตที่มีความแม่นยำสูง/ต่ำกว่า
ประเภทที่ใช้สำหรับการสะสม preferred_element_type แนะนำ
ประเภทการสะสมสำหรับการดำเนินการที่กำหนด แต่ไม่รับประกันว่าจะเป็นประเภทนั้น
ซึ่งช่วยให้แบ็กเอนด์ฮาร์ดแวร์บางรายการสะสมในประเภทอื่นแทนได้
และแปลงเป็นประเภทเอาต์พุตที่ต้องการ
ดูข้อมูล StableHLO ได้ที่ StableHLO - dot
DotGeneral
ดูเพิ่มเติม
XlaBuilder::DotGeneral
DotGeneral(lhs, rhs, dimension_numbers, precision_config,
preferred_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs |
XlaOp |
อาร์เรย์ของประเภท T |
rhs |
XlaOp |
อาร์เรย์ของประเภท T |
dimension_numbers
|
DotDimensionNumbers
|
การทำสัญญาและหมายเลข มิติข้อมูลแบบกลุ่ม |
precision_config
|
ไม่บังคับ
PrecisionConfig |
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ
PrimitiveType |
enum ของประเภทองค์ประกอบสเกลาร์ |
คล้ายกับ Dot แต่ช่วยให้ระบุหมายเลขมิติข้อมูลแบบย่อและแบบกลุ่มได้ทั้งสำหรับ lhs และ rhs
| ฟิลด์ DotDimensionNumbers | ประเภท | ความหมาย |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | lhs หมายเลขมิติข้อมูล
การทำสัญญา |
rhs_contracting_dimensions
|
repeated int64 | rhs หมายเลขมิติข้อมูล
การทำสัญญา |
lhs_batch_dimensions
|
repeated int64 | lhs หมายเลข
มิติข้อมูลกลุ่ม |
rhs_batch_dimensions
|
repeated int64 | rhs หมายเลข
มิติข้อมูลกลุ่ม |
DotGeneral จะดำเนินการหาผลรวมของผลิตภัณฑ์ตามมิติข้อมูลการทำสัญญาที่ระบุใน
dimension_numbers
หมายเลขมิติข้อมูลการทำสัญญาที่เชื่อมโยงจาก lhs และ rhs ไม่จำเป็นต้อง
เหมือนกัน แต่ต้องมีขนาดมิติข้อมูลเดียวกัน
ตัวอย่างที่มีหมายเลขมิติข้อมูลที่ทำสัญญา
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { { 6.0, 12.0},
{15.0, 30.0} }
หมายเลขมิติข้อมูลกลุ่มที่เชื่อมโยงจาก lhs และ rhs ต้องมีขนาดมิติข้อมูลเดียวกัน
ตัวอย่างที่มีหมายเลขมิติข้อมูลกลุ่ม (ขนาดกลุ่ม 2, เมทริกซ์ 2x2)
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> {
{ {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| อินพุต | เอาต์พุต | ความหมาย |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | batch matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | batch matmul |
ดังนั้นหมายเลขมิติข้อมูลที่ได้จึงเริ่มต้นด้วยมิติข้อมูลกลุ่ม
จากนั้นเป็นมิติข้อมูลlhsที่ไม่ใช่สัญญา/ไม่ใช่กลุ่ม และสุดท้ายคือมิติข้อมูลrhs
ที่ไม่ใช่สัญญา/ไม่ใช่กลุ่ม
precision_config ใช้เพื่อระบุการกำหนดค่าความแม่นยำ ระดับ จะกำหนดว่าฮาร์ดแวร์ควรพยายามสร้างคำสั่งรหัสเครื่องเพิ่มเติมเพื่อจำลอง dtype ได้แม่นยำยิ่งขึ้นเมื่อจำเป็นหรือไม่ (เช่น จำลอง f32 ใน TPU ที่รองรับเฉพาะ bf16 matmuls) ค่าอาจเป็น
DEFAULT, HIGH, HIGHEST ดูรายละเอียดเพิ่มเติม
ได้ในส่วน MXU
preferred_element_type เป็นองค์ประกอบสเกลาร์ของเอาต์พุตที่มีความแม่นยำสูง/ต่ำกว่า
ประเภทที่ใช้สำหรับการสะสม preferred_element_type แนะนำ
ประเภทการสะสมสำหรับการดำเนินการที่กำหนด แต่ไม่รับประกันว่าจะเป็นประเภทนั้น
ซึ่งช่วยให้แบ็กเอนด์ฮาร์ดแวร์บางรายการสะสมในประเภทอื่นแทนได้
และแปลงเป็นประเภทเอาต์พุตที่ต้องการ
ดูข้อมูล StableHLO ได้ที่ StableHLO - dot_general
ScaledDot
ดูเพิ่มเติม
XlaBuilder::ScaledDot
ScaledDot(lhs, lhs_scale, rhs, rhs_scale, dimension_number,
precision_config,preferred_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs |
XlaOp |
อาร์เรย์ของประเภท T |
rhs |
XlaOp |
อาร์เรย์ของประเภท T |
lhs_scale |
XlaOp |
อาร์เรย์ของประเภท T |
rhs_scale |
XlaOp |
อาร์เรย์ของประเภท T |
dimension_number
|
ScatterDimensionNumbers
|
หมายเลขมิติข้อมูลสําหรับ การดำเนินการกระจาย |
precision_config
|
PrecisionConfig
|
enum สำหรับระดับความแม่นยำ |
preferred_element_type
|
ไม่บังคับ PrimitiveType
|
enum ของประเภทองค์ประกอบสเกลาร์ |
คล้ายกับ DotGeneral
สร้างการดำเนินการ dot ที่ปรับขนาดแล้วโดยมีตัวถูกดำเนินการเป็น "lhs", "lhs_scale", "rhs" และ "rhs_scale" โดยมีมิติข้อมูลการทำสัญญาและมิติข้อมูลกลุ่มที่ระบุใน "dimension_numbers"
RaggedDot
ดูเพิ่มเติม
XlaBuilder::RaggedDot
ดูรายละเอียดการRaggedDotคำนวณได้ที่
StableHLO - chlo.ragged_dot
DynamicReshape
ดูเพิ่มเติม
XlaBuilder::DynamicReshape
การดำเนินการนี้จะเหมือนกับ reshape โดยมีผลลัพธ์ shape ที่ระบุแบบไดนามิกผ่าน output_shape
DynamicReshape(operand, dim_sizes, new_size_bounds, dims_are_dynamic)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ N มิติของประเภท T |
dim_sizes |
เวกเตอร์ของ XlaOP |
ขนาดเวกเตอร์ N มิติ |
new_size_bounds |
เวกเตอร์ของ int63 |
เวกเตอร์ขอบเขต N มิติ |
dims_are_dynamic |
เวกเตอร์ของ bool |
มิติข้อมูลแบบไดนามิก N มิติ |
ดูข้อมูล StableHLO ได้ที่ StableHLO - dynamic_reshape
DynamicSlice
ดูเพิ่มเติม
XlaBuilder::DynamicSlice
DynamicSlice จะดึงอาร์เรย์ย่อยจากอาร์เรย์อินพุตที่ dynamic
start_indices ขนาดของชิ้นในแต่ละมิติข้อมูลจะส่งผ่านใน
size_indices ซึ่งระบุจุดสิ้นสุดของช่วงชิ้นแบบไม่รวมในแต่ละ
มิติข้อมูล: [start, start + size) รูปร่างของ start_indices ต้องเป็น
แบบ 1 มิติ โดยมีขนาดมิติเท่ากับจำนวนมิติของ
operand
DynamicSlice(operand, start_indices, slice_sizes)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ N มิติของประเภท T |
start_indices
|
ลำดับของ N XlaOp
|
รายการจำนวนเต็มสเกลาร์ N ที่มีดัชนีเริ่มต้นของ ชิ้นสำหรับแต่ละมิติข้อมูล ค่าต้องมากกว่าหรือเท่ากับ 0 |
size_indices
|
ArraySlice<int64>
|
รายการจำนวนเต็ม N ที่มี ขนาดชิ้นสำหรับแต่ละมิติข้อมูล แต่ละค่าต้องมากกว่า 0 อย่างเคร่งครัด และ start + size ต้องน้อยกว่าหรือเท่ากับขนาดของมิติข้อมูลเพื่อหลีกเลี่ยงการวนรอบขนาดมิติข้อมูล |
ดัชนีสไลซ์ที่มีผลจะคำนวณโดยใช้การแปลงต่อไปนี้
สำหรับดัชนีแต่ละรายการ i ใน [1, N) ก่อนที่จะทำการสไลซ์
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - slice_sizes[i])
ซึ่งจะช่วยให้มั่นใจได้ว่า Slice ที่ดึงออกมาจะอยู่ในขอบเขตของอาร์เรย์ตัวถูกดำเนินการเสมอ หากชิ้นอยู่ในขอบเขตก่อนที่จะใช้การเปลี่ยนรูป การเปลี่ยนรูปจะไม่มีผล
ตัวอย่าง 1 มิติ
let a = {0.0, 1.0, 2.0, 3.0, 4.0};
let s = {2};
DynamicSlice(a, s, {2});
// Result: {2.0, 3.0}
ตัวอย่าง 2 มิติ
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2});
//Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
ดูข้อมูล StableHLO ได้ที่ StableHLO - dynamic_slice
DynamicUpdateSlice
ดูเพิ่มเติม
XlaBuilder::DynamicUpdateSlice
DynamicUpdateSlice จะสร้างผลลัพธ์ซึ่งเป็นค่าของอาร์เรย์อินพุต
operand โดยเขียนทับสไลซ์ update ที่ start_indices
รูปร่างของ update จะกำหนดรูปร่างของอาร์เรย์ย่อยของผลลัพธ์ที่จะอัปเดต
รูปร่างของ start_indices ต้องเป็นแบบ 1 มิติ โดยมีขนาดมิติข้อมูลเท่ากับ
จำนวนมิติข้อมูลของ operand
DynamicUpdateSlice(operand, update, start_indices)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ N มิติของประเภท T |
update
|
XlaOp
|
อาร์เรย์ N มิติของประเภท T ที่มีการอัปเดตสไลซ์ แต่ละ มิติของรูปร่างการอัปเดตต้อง มากกว่า 0 อย่างเคร่งครัด และ start + update ต้องน้อยกว่า หรือเท่ากับขนาดตัวถูกดำเนินการสำหรับ แต่ละมิติเพื่อหลีกเลี่ยงการสร้าง ดัชนีการอัปเดตที่อยู่นอกขอบเขต |
start_indices
|
ลำดับของ N XlaOp
|
รายการจำนวนเต็มสเกลาร์ N ที่มีดัชนีเริ่มต้นของ ชิ้นสำหรับแต่ละมิติข้อมูล ค่าต้องมากกว่าหรือเท่ากับ 0 |
ดัชนีสไลซ์ที่มีผลจะคำนวณโดยใช้การแปลงต่อไปนี้
สำหรับดัชนีแต่ละรายการ i ใน [1, N) ก่อนที่จะทำการสไลซ์
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
ซึ่งจะช่วยให้มั่นใจได้ว่า Slice ที่อัปเดตแล้วจะอยู่ในขอบเขตของอาร์เรย์ตัวถูกดำเนินการเสมอ หากชิ้นอยู่ในขอบเขตก่อนที่จะใช้การเปลี่ยนรูป การเปลี่ยนรูปจะไม่มีผล
ตัวอย่าง 1 มิติ
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s)
// Result: {0.0, 1.0, 5.0, 6.0, 4.0}
ตัวอย่าง 2 มิติ
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s)
// Result:
// { {0.0, 1.0, 2.0},
// {3.0, 12.0, 13.0},
// {6.0, 14.0, 15.0},
// {9.0, 16.0, 17.0} }
ดูข้อมูล StableHLO ได้ที่ StableHLO - dynamic_update_slice
Erf
ดูเพิ่มเติม
XlaBuilder::Erf
ฟังก์ชันข้อผิดพลาดแบบทีละองค์ประกอบ x -> erf(x) โดยที่
\(\text{erf}(x) = \frac{2}{\sqrt{\pi} }\int_0^x e^{-t^2} \, dt\)
Erf(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Erf ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Erf(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
วันหมดอายุ
ดูเพิ่มเติม
XlaBuilder::Exp
เลขชี้กำลังธรรมชาติแบบทีละองค์ประกอบ x -> e^x
Exp(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Exp ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Exp(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - exponential
Expm1
ดูเพิ่มเติม
XlaBuilder::Expm1
เลขชี้กำลังธรรมชาติแบบทีละองค์ประกอบลบด้วย 1 x -> e^x - 1
Expm1(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ ฟังก์ชัน Expm1 ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Expm1(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - exponential_minus_one
Fft
ดูเพิ่มเติม
XlaBuilder::Fft
การดำเนินการ FFT ของ XLA จะใช้การแปลงฟูริเยร์ไปข้างหน้าและย้อนกลับสำหรับอินพุต/เอาต์พุตจริงและเชิงซ้อน รองรับ FFT แบบหลายมิติบนแกนสูงสุด 3 แกน
Fft(operand, ftt_type, fft_length)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์ที่เราจะแปลงฟูริเย |
fft_type |
FftType |
โปรดดูตารางด้านล่าง |
fft_length
|
ArraySlice<int64>
|
ความยาวโดเมนเวลา
ของแกนที่
กำลังแปลง ซึ่งจำเป็น
อย่างยิ่งสำหรับ
IRFFT เพื่อปรับขนาด
แกนในสุด เนื่องจาก
RFFT(fft_length=[16])
มีรูปร่างเอาต์พุต
เหมือนกับ
RFFT(fft_length=[17]) |
FftType |
ความหมาย |
|---|---|
FFT |
ส่งต่อ FFT จากจำนวนเชิงซ้อนเป็นจำนวนเชิงซ้อน รูปร่างไม่เปลี่ยนแปลง |
IFFT |
FFT จากจำนวนเชิงซ้อนเป็นจำนวนเชิงซ้อนแบบผกผัน รูปร่างไม่เปลี่ยนแปลง |
RFFT
|
FFT จากจำนวนจริงไปเป็นจำนวนเชิงซ้อนแบบส่งต่อ รูปร่างของแกนในสุดจะ
ลดลงเหลือ fft_length[-1] // 2 + 1 หาก fft_length[-1] เป็นค่า
ที่ไม่ใช่ 0 โดยละเว้นส่วนสังยุคที่กลับด้านของ
สัญญาณที่แปลงแล้วซึ่งอยู่นอกเหนือความถี่ไนควิสต์ |
IRFFT
|
FFT จากจำนวนเชิงซ้อนเป็นจำนวนจริงแบบผกผัน (เช่น รับจำนวนเชิงซ้อนและแสดงผลจำนวนจริง)
ระบบจะขยายรูปร่างของแกนในสุดเป็น fft_length[-1] หาก
fft_length[-1] เป็นค่าที่ไม่ใช่ 0 ซึ่งจะอนุมานส่วนของ
สัญญาณที่แปลงแล้วซึ่งอยู่นอกเหนือความถี่ Nyquist จากสังยุคผกผันของรายการ 1 ถึง fft_length[-1] // 2 + 1 |
ดูข้อมูล StableHLO ได้ที่ StableHLO - fft
FFT แบบหลายมิติ
เมื่อระบุ fft_length มากกว่า 1 รายการ จะเทียบเท่ากับการใช้การดำเนินการ FFT แบบเรียงซ้อนกับแต่ละแกนในสุด โปรดทราบว่าสำหรับกรณีจริง -> เชิงซ้อนและเชิงซ้อน -> จริง การแปลงแกนในสุดจะดำเนินการก่อน (RFFT; สุดท้ายสำหรับ IRFFT) ซึ่งเป็นเหตุผลที่แกนในสุดเป็นแกนที่มีการเปลี่ยนแปลงขนาด จากนั้นการแปลงแกนอื่นๆ จะเป็นเชิงซ้อน -> เชิงซ้อน
รายละเอียดการใช้งาน
FFT ของ CPU ใช้ TensorFFT ของ Eigen ส่วน FFT ของ GPU ใช้ cuFFT
ชั้น
ดูเพิ่มเติม
XlaBuilder::Floor
ฟังก์ชัน Floor แบบองค์ประกอบต่อองค์ประกอบ x -> ⌊x⌋
Floor(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - floor
ฟิวชั่น
ดูเพิ่มเติม
HloInstruction::CreateFusion
Fusion การดำเนินการแสดงถึงคำสั่ง HLO และทำหน้าที่เป็น Primitive ใน HLO
การดำเนินการนี้อาจปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้เพื่อให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
รวบรวม
การดำเนินการรวบรวม XLA จะรวมชิ้นหลายชิ้น (แต่ละชิ้นอาจมีออฟเซ็ตเวลาเรียกใช้ที่แตกต่างกัน) ของอาร์เรย์อินพุตเข้าด้วยกัน
ดูข้อมูล StableHLO ได้ที่ StableHLO - gather
ความหมายทั่วไป
ดูเพิ่มเติม
XlaBuilder::Gather
ดูคำอธิบายที่เข้าใจง่ายยิ่งขึ้นได้ที่ส่วน "คำอธิบายอย่างไม่เป็นทางการ" ด้านล่าง
gather(operand, start_indices, dimension_numbers, slice_sizes,
indices_are_sorted)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์ที่เรากำลังรวบรวม จาก |
start_indices
|
XlaOp
|
อาร์เรย์ที่มี ดัชนีเริ่มต้นของ ชิ้นที่เราเก็บรวบรวม |
dimension_numbers
|
GatherDimensionNumbers
|
มิติข้อมูลใน
start_indices ที่
"มี" ดัชนีเริ่มต้น ดู
คำอธิบายโดยละเอียดได้ที่ด้านล่าง |
slice_sizes
|
ArraySlice<int64>
|
slice_sizes[i] คือขอบเขตของชิ้นส่วนในมิติข้อมูล i |
indices_are_sorted
|
bool
|
ผู้โทรรับประกันว่าดัชนีจะเรียงตามลำดับหรือไม่ |
เพื่อความสะดวก เราจะติดป้ายกำกับมิติข้อมูลในอาร์เรย์เอาต์พุตที่ไม่ได้อยู่ใน offset_dims
เป็น batch_dims
เอาต์พุตคืออาร์เรย์ที่มีมิติข้อมูล batch_dims.size + offset_dims.size
operand.rank ต้องเท่ากับผลรวมของ offset_dims.size และ collapsed_slice_dims.size นอกจากนี้ slice_sizes.size ต้องเท่ากับ
operand.rank
หาก index_vector_dim เท่ากับ start_indices.rank เราจะถือว่า start_indices มีมิติข้อมูลต่อท้าย 1 โดยปริยาย (กล่าวคือ หาก start_indices มีรูปร่าง [6,7] และ index_vector_dim เป็น 2 เราจะถือว่ารูปร่างของ start_indices เป็น [6,7,1] โดยปริยาย)
ขอบเขตของอาร์เรย์เอาต์พุตตามมิติข้อมูล i จะคำนวณดังนี้
หาก
iอยู่ในbatch_dims(เช่น เท่ากับbatch_dims[k]สำหรับบางk) เราจะเลือกขอบเขตมิติข้อมูลที่สอดคล้องกันจากstart_indices.shapeโดยข้ามindex_vector_dim(เช่น เลือกstart_indices.shape.dims[k] หากk<index_vector_dimและstart_indices.shape.dims[k+1] ในกรณีอื่นๆ)หาก
iอยู่ในoffset_dims(เช่น เท่ากับoffset_dims[k] สำหรับkบางรายการ) เราจะเลือกขอบเขตที่สอดคล้องกันจากslice_sizesหลังจาก พิจารณาcollapsed_slice_dimsแล้ว (เช่น เราจะเลือกadjusted_slice_sizes[k] โดยที่adjusted_slice_sizesคือslice_sizesที่นำขอบเขตที่ดัชนีcollapsed_slice_dimsออกแล้ว)
ในรูปแบบที่เป็นทางการ ดัชนีตัวถูกดำเนินการ In ที่สอดคล้องกับดัชนีเอาต์พุตที่กำหนด Out จะคำนวณได้ดังนี้
ให้
G= {Out[k] forkinbatch_dims} ใช้Gเพื่อแบ่งเวกเตอร์Sออกเป็นส่วนๆ โดยที่S[i] =start_indices[Combine(G,i)] เมื่อ Combine(A, b) จะแทรก b ที่ตำแหน่งindex_vector_dimลงใน A โปรดทราบว่าการดำเนินการนี้จะกำหนดไว้อย่างดีแม้ว่าGจะว่างเปล่าก็ตาม หากGว่างเปล่าS=start_indicesสร้างดัชนีเริ่มต้น
Sinในoperandโดยใช้Sโดย กระจายSโดยใช้start_index_mapโดยมีรายละเอียดดังนี้Sin[start_index_map[k]] =S[k] ifk<start_index_map.size.Sin[_] =0มิเช่นนั้น
สร้างดัชนี
Oinลงในoperandโดยกระจายดัชนี ที่มิติข้อมูลออฟเซ็ตในOutตามชุดcollapsed_slice_dimsโดยมีรายละเอียดดังนี้Oin[remapped_offset_dims(k)] =Out[offset_dims[k]] ifk<offset_dims.size(remapped_offset_dimsis defined below).Oin[_] =0มิเช่นนั้น
InคือOin+Sinโดยที่ + คือการบวกแบบอิงตามองค์ประกอบ
remapped_offset_dims เป็นฟังก์ชันโมโนโทนิกที่มีโดเมน [0,
offset_dims.size) และช่วง [0, operand.rank) \ collapsed_slice_dims ดังนั้น
หากเช่น offset_dims.size คือ 4, operand.rank คือ 6 และ
collapsed_slice_dims คือ {0, 2} แล้ว remapped_offset_dims คือ {0→1,
1→3, 2→4, 3→5}
หากตั้งค่า indices_are_sorted เป็นจริง XLA จะถือว่าผู้ใช้ได้จัดเรียง start_indices
แล้ว (เรียงจากน้อยไปมาก หลังจากกระจายค่าตาม
start_index_map) หากไม่ได้จัดเรียงไว้ ความหมายจะเป็นไปตามที่การใช้งานกำหนด
คำอธิบายและตัวอย่างอย่างไม่เป็นทางการ
กล่าวอย่างไม่เป็นทางการคือ ดัชนี Out ทุกรายการในอาร์เรย์เอาต์พุตจะสอดคล้องกับองค์ประกอบ E
ในอาร์เรย์ตัวถูกดำเนินการ ซึ่งคำนวณได้ดังนี้
เราใช้มิติข้อมูลกลุ่มใน
Outเพื่อค้นหาดัชนีเริ่มต้นจากstart_indicesเราใช้
start_index_mapเพื่อแมปดัชนีเริ่มต้น (ซึ่งอาจมีขนาดน้อยกว่า operand.rank) กับดัชนีเริ่มต้น "เต็ม" ในoperandเราจะแบ่งส่วนแบบไดนามิกโดยใช้ขนาด
slice_sizesโดยใช้ดัชนีเริ่มต้นแบบเต็มเราปรับรูปร่างสไลซ์โดยการยุบ
collapsed_slice_dimsมิติข้อมูล เนื่องจากมิติข้อมูลสไลซ์ที่ยุบทั้งหมดต้องมีขอบเขตเป็น 1 การเปลี่ยนรูปร่างนี้จึง ถูกต้องเสมอเราใช้มิติข้อมูลออฟเซ็ตใน
Outเพื่อจัดทำดัชนีในชิ้นนี้เพื่อรับองค์ประกอบอินพุตEที่สอดคล้องกับดัชนีเอาต์พุตOut
index_vector_dim ตั้งค่าเป็น start_indices.rank - 1 ในตัวอย่างทั้งหมด
ที่ตามมา ค่าที่น่าสนใจมากขึ้นสำหรับ index_vector_dim do not change the
operation fundamentally, but make the visual representation more cumbersome.
หากต้องการทราบว่าองค์ประกอบทั้งหมดข้างต้นทำงานร่วมกันอย่างไร ให้ดูตัวอย่างที่รวบรวมชิ้นส่วน 5 ชิ้นที่มีรูปร่าง [8,6] จากอาร์เรย์ [16,11] ตำแหน่งของชิ้นส่วนในอาร์เรย์ [16,11] สามารถแสดงเป็นเวกเตอร์ดัชนีที่มีรูปร่าง S64[2] ดังนั้นชุดตำแหน่ง 5 ตำแหน่งจึงสามารถแสดงเป็นอาร์เรย์ S64[5,2] ได้
จากนั้นลักษณะการทำงานของการดำเนินการรวบรวมจะแสดงเป็นการเปลี่ยนดัชนี
ที่ใช้ [G,O0,O1] ซึ่งเป็นดัชนีใน
รูปร่างเอาต์พุต และแมปกับองค์ประกอบในอาร์เรย์อินพุตในลักษณะต่อไปนี้

เราจะเลือกเวกเตอร์ (X,Y) จากอาร์เรย์ดัชนีรวบรวมโดยใช้ G
จากนั้น องค์ประกอบในอาร์เรย์เอาต์พุตที่ดัชนี
[G,O0,O1] จะเป็นองค์ประกอบในอาร์เรย์อินพุต
ที่ดัชนี [X+O0,Y+O1]
slice_sizes คือ [8,6] ซึ่งกำหนดช่วงของ O0 และ O1 และจะกำหนดขอบเขตของสไลซ์
การดำเนินการรวบรวมนี้ทำหน้าที่เป็น Slice แบบไดนามิกแบบกลุ่มที่มี G เป็นมิติข้อมูลกลุ่ม
ดัชนีการรวบรวมอาจเป็นแบบหลายมิติ เช่น ตัวอย่างที่ทั่วไปกว่า
ของตัวอย่างด้านบนที่ใช้อาร์เรย์ "gather indices" ที่มีรูปร่าง [4,5,2]
จะแปลดัชนีดังนี้

อีกครั้งที่นี่จะทำหน้าที่เป็นกลุ่มสไลซ์แบบไดนามิก G0 และ
G1 เป็นมิติข้อมูลกลุ่ม ขนาดของชิ้นยังคงเป็น [8,6]
การดำเนินการรวบรวมใน XLA จะสรุปความหมายอย่างไม่เป็นทางการที่ระบุไว้ข้างต้นในลักษณะต่อไปนี้
เราสามารถกำหนดค่ามิติข้อมูลในรูปร่างเอาต์พุตซึ่งเป็นมิติข้อมูลออฟเซ็ต (มิติข้อมูลที่มี
O0,O1ในตัวอย่างสุดท้าย) มิติข้อมูลกลุ่มเอาต์พุต (มิติข้อมูลที่มีG0,G1ในตัวอย่างสุดท้าย) จะกำหนดให้เป็นมิติข้อมูลเอาต์พุตที่ไม่ใช่มิติข้อมูลออฟเซ็ตจำนวนมิติข้อมูลออฟเซ็ตเอาต์พุตที่แสดงอย่างชัดเจนในเอาต์พุต รูปร่างอาจน้อยกว่าจำนวนมิติข้อมูลอินพุต มิติข้อมูลที่ "ขาดหายไป" เหล่านี้ ซึ่งแสดงไว้อย่างชัดเจนเป็น
collapsed_slice_dimsต้องมี ขนาดชิ้นเป็น1เนื่องจากมีขนาดสไลซ์เป็น1ดัชนีที่ถูกต้องเพียงอย่างเดียว สำหรับดัชนีเหล่านั้นคือ0และการละดัชนีเหล่านั้นจะไม่ทำให้เกิดความคลุมเครือชิ้นที่ดึงมาจากอาร์เรย์ "รวบรวมดัชนี" ((
X,Y) ในตัวอย่างสุดท้าย อาจมีองค์ประกอบน้อยกว่าจำนวนมิติข้อมูลของอาร์เรย์อินพุต และการแมปที่ชัดเจนจะกำหนดวิธีขยายดัชนีเพื่อให้มีจำนวนมิติข้อมูลเท่ากับอินพุต
ตัวอย่างสุดท้าย เราใช้ (2) และ (3) เพื่อใช้ tf.gather_nd ดังนี้

G0 และ G1 ใช้เพื่อแบ่งดัชนีเริ่มต้น
จากอาร์เรย์ดัชนีรวบรวมตามปกติ ยกเว้นดัชนีเริ่มต้นที่มีองค์ประกอบเพียงรายการเดียว X ในทำนองเดียวกัน จะมีดัชนีออฟเซ็ตเอาต์พุตเพียงรายการเดียวที่มีค่า
O0 อย่างไรก็ตาม ก่อนที่จะใช้เป็นดัชนีในอาร์เรย์อินพุต
ระบบจะขยายดัชนีเหล่านี้ตาม "การแมปดัชนีรวบรวม" (start_index_map ใน
คำอธิบายอย่างเป็นทางการ) และ "การแมปออฟเซ็ต" (remapped_offset_dims ใน
คำอธิบายอย่างเป็นทางการ) เป็น [X,0] และ [0,O0] ตามลำดับ
รวมเป็น [X,O0] กล่าวอีกนัยหนึ่งคือ ดัชนีเอาต์พุต
[G0,G1,O0] จะแมปกับดัชนีอินพุต
[GatherIndices[G0,G1,0],O0]
ซึ่งทำให้เราได้ความหมายสำหรับ tf.gather_nd
slice_sizes สำหรับเคสนี้คือ [1,11] โดยสัญชาตญาณแล้ว หมายความว่าดัชนี X ทุกตัวในอาร์เรย์ดัชนีรวบรวมจะเลือกทั้งแถว และผลลัพธ์คือการ
ต่อกันของแถวทั้งหมดนี้
GetDimensionSize
ดูเพิ่มเติม
XlaBuilder::GetDimensionSize
แสดงผลขนาดของมิติข้อมูลที่ระบุของตัวถูกดำเนินการ ตัวถูกดำเนินการต้องมีรูปร่างเป็นอาร์เรย์
GetDimensionSize(operand, dimension)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
dimension
|
int64
|
ค่าในช่วง [0, n) ที่ระบุ
มิติข้อมูล |
ดูข้อมูล StableHLO ได้ที่ StableHLO - get_dimension_size
GetTupleElement
ดูเพิ่มเติม
XlaBuilder::GetTupleElement
ดัชนีในทูเพิลที่มีค่าคงที่ในเวลาคอมไพล์
ค่าต้องเป็นค่าคงที่ในเวลาคอมไพล์เพื่อให้การอนุมานรูปร่างกำหนดประเภทของค่าผลลัพธ์ได้
ซึ่งคล้ายกับ std::get<int N>(t) ใน C++ โดยในเชิงแนวคิดแล้ว
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
ดู tf.tuple เพิ่มเติม
GetTupleElement(tuple_data, index)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
tuple_data |
XlaOP |
ทูเพิล |
index |
int64 |
ดัชนีของรูปร่าง Tuple |
ดูข้อมูล StableHLO ได้ที่ StableHLO - get_tuple_element
Imag
ดูเพิ่มเติม
XlaBuilder::Imag
ส่วนจินตภาพของรูปร่างเชิงซ้อน (หรือจริง) แบบทีละองค์ประกอบ x -> imag(x) หาก
ตัวถูกดำเนินการเป็นประเภททศนิยม จะแสดงผล 0
Imag(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - imag
ในฟีด
ดูเพิ่มเติม
XlaBuilder::Infeed
Infeed(shape, config)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
shape
|
Shape
|
รูปร่างของข้อมูลที่อ่านจากอินเทอร์เฟซในฟีด ต้องตั้งค่าฟิลด์เลย์เอาต์ของรูปร่างให้ตรงกับเลย์เอาต์ของข้อมูลที่ส่ง ไปยังอุปกรณ์ ไม่เช่นนั้นลักษณะการทำงานจะ ไม่แน่นอน |
config |
ไม่บังคับ string |
การกำหนดค่าของ Op |
อ่านรายการข้อมูลรายการเดียวจากอินเทอร์เฟซการสตรีมในฟีดโดยนัยของ
อุปกรณ์ โดยตีความข้อมูลเป็นรูปร่างและเลย์เอาต์ที่กำหนด และส่งคืน
XlaOpของข้อมูล อนุญาตให้มีการดำเนินการ Infeed หลายรายการในการคำนวณ
แต่ต้องมีการเรียงลำดับการดำเนินการ Infeed ทั้งหมด ตัวอย่างเช่น 2
Infeed ในโค้ดด้านล่างมีลำดับรวมเนื่องจากมีการขึ้นต่อกัน
ระหว่างลูป while
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
ไม่รองรับรูปร่างทูเพิลที่ซ้อนกัน สำหรับรูปร่างทูเพิลที่ว่างเปล่า การดำเนินการ Infeed จะไม่มีผลและดำเนินการต่อโดยไม่ต้องอ่านข้อมูลใดๆ จาก Infeed ของอุปกรณ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - ในฟีด
Iota
ดูเพิ่มเติม
XlaBuilder::Iota
Iota(shape, iota_dimension)
สร้างค่าคงที่แบบอักษรบนอุปกรณ์แทนการโอนโฮสต์ที่อาจมีขนาดใหญ่
สร้างอาร์เรย์ที่มีรูปร่างที่ระบุและเก็บค่าที่เริ่มต้นที่
ศูนย์และเพิ่มขึ้นทีละหนึ่งตามมิติข้อมูลที่ระบุ สำหรับประเภทจุดลอยตัว
อาร์เรย์ที่สร้างขึ้นจะเทียบเท่ากับ ConvertElementType(Iota(...)) โดยที่
Iota เป็นประเภทจำนวนเต็มและการแปลงเป็นประเภทจุดลอยตัว
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
shape |
Shape |
รูปร่างของอาร์เรย์ที่สร้างโดย Iota() |
iota_dimension |
int64 |
มิติข้อมูลที่จะเพิ่มตาม |
เช่น Iota(s32[4, 8], 0) จะแสดงผล
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
ส่งคืนสินค้า Iota(s32[4, 8], 1)
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
ดูข้อมูล StableHLO ได้ที่ StableHLO - iota
IsFinite
ดูเพิ่มเติม
XlaBuilder::IsFinite
ทดสอบว่าแต่ละองค์ประกอบของ operand เป็นค่าจำกัดหรือไม่ กล่าวคือ ไม่ใช่ค่าอนันต์บวกหรือลบ และไม่ใช่ NaN แสดงผลอาร์เรย์ของค่า PRED ที่มีรูปร่างเหมือนกับอินพุต โดยแต่ละองค์ประกอบจะเป็น true ก็ต่อเมื่อองค์ประกอบอินพุตที่สอดคล้องกันเป็นค่าจำกัด
IsFinite(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - is_finite
บันทึก
ดูเพิ่มเติม
XlaBuilder::Log
ลอการิทึมธรรมชาติแบบทีละองค์ประกอบ x -> ln(x)
Log(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ ฟังก์ชัน Log ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Log(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - log
บันทึก1p
ดูเพิ่มเติม
XlaBuilder::Log1p
ลอการิทึมธรรมชาติที่เลื่อนทีละองค์ประกอบ x -> ln(1+x)
Log1p(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Log1p ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Log1p(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - log_plus_one
Logistic
ดูเพิ่มเติม
XlaBuilder::Logistic
การคำนวณฟังก์ชันโลจิสติกแบบทีละองค์ประกอบ x -> logistic(x)
Logistic(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ ฟังก์ชัน LOG ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Logistic(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - logistic
แผนที่
ดูเพิ่มเติม
XlaBuilder::Map
Map(operands..., computation, dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
ลำดับของ XlaOp จำนวน N |
อาร์เรย์ N ของประเภท T0..T{N-1} |
computation
|
XlaComputation
|
การคำนวณประเภท T_0, T_1,
.., T_{N + M -1} -> S โดยมีพารามิเตอร์ N
ประเภท T และ M ประเภท
ใดก็ได้ |
dimensions |
int64 อาร์เรย์ |
อาร์เรย์ของมิติข้อมูลแผนที่ |
static_operands
|
ลำดับของ N XlaOps
|
การดำเนินการแบบคงที่สำหรับ การดำเนินการของแผนที่ |
ใช้ฟังก์ชันสเกลาร์กับอาร์เรย์ operands ที่ระบุ ซึ่งจะสร้างอาร์เรย์ที่มีมิติข้อมูลเดียวกัน โดยแต่ละองค์ประกอบคือผลลัพธ์ของฟังก์ชันที่แมปซึ่งใช้กับองค์ประกอบที่สอดคล้องกันในอาร์เรย์อินพุต
ฟังก์ชันที่แมปคือการคำนวณโดยพลการที่มีข้อจำกัดว่าต้องมีอินพุต N รายการประเภทสเกลาร์ T และเอาต์พุตรายการเดียวที่มีประเภท S เอาต์พุตมี
มิติข้อมูลเดียวกับตัวถูกดำเนินการ ยกเว้นว่าประเภทองค์ประกอบ T จะถูกแทนที่
ด้วย S
เช่น Map(op1, op2, op3, computation, par1) จะจับคู่ elem_out <-
computation(elem1, elem2, elem3, par1) ที่ดัชนี (หลายมิติ) แต่ละรายการใน
อาร์เรย์อินพุตเพื่อสร้างอาร์เรย์เอาต์พุต
ดูข้อมูล StableHLO ได้ที่ StableHLO - map
สูงสุด
ดูเพิ่มเติม
XlaBuilder::Max
ดำเนินการหาค่าสูงสุดแบบทีละองค์ประกอบในเทนเซอร์ lhs และ rhs
Max(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Max มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ ดังนี้
Max(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่StableHLO - maximum
ต่ำสุด
ดูเพิ่มเติม
XlaBuilder::Min
ดำเนินการ min แบบทีละองค์ประกอบใน lhs และ rhs
Min(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ สำหรับ Min ดังนี้
Min(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - minimum
Mul
ดูเพิ่มเติม
XlaBuilder::Mul
ดำเนินการคูณแบบทีละองค์ประกอบของ lhs และ rhs
Mul(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Mul มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Mul(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - multiply
Neg
ดูเพิ่มเติม
XlaBuilder::Neg
การนิเสธแบบทีละองค์ประกอบ x -> -x
Neg(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - negate
ไม่ใช่
ดูเพิ่มเติม
XlaBuilder::Not
ตัวดำเนินการนิเสธเชิงตรรกะแบบทีละองค์ประกอบ x -> !(x)
Not(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - not
OptimizationBarrier
ดูเพิ่มเติม
XlaBuilder::OptimizationBarrier
บล็อกการเพิ่มประสิทธิภาพไม่ให้ย้ายการคำนวณข้ามขอบเขต
OptimizationBarrier(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ตรวจสอบว่ามีการประเมินอินพุตทั้งหมดก่อนโอเปอเรเตอร์ที่ขึ้นอยู่กับเอาต์พุตของ แบริเออร์
ดูข้อมูล StableHLO ได้ที่ StableHLO - optimization_barrier
หรือ
ดูเพิ่มเติม
XlaBuilder::Or
ดำเนินการ OR แบบทีละองค์ประกอบของ lhs และ rhs
Or(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Or มีตัวแปรอื่นที่รองรับการออกอากาศแบบหลายมิติ
Or(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - หรือ
ฟีดขาออก
ดูเพิ่มเติม
XlaBuilder::Outfeed
เขียนอินพุตไปยังเอาต์ฟีด
Outfeed(operand, shape_with_layout, outfeed_config)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T |
shape_with_layout |
Shape |
กำหนดเลย์เอาต์ของข้อมูลที่โอน |
outfeed_config |
string |
ค่าคงที่ของการกำหนดค่าสำหรับคำสั่ง Outfeed |
shape_with_layout สื่อถึงรูปร่างที่วางไว้ซึ่งเราต้องการแสดง
ดูข้อมูล StableHLO ได้ที่ StableHLO - outfeed
แผ่นรอง
ดูเพิ่มเติม
XlaBuilder::Pad
Pad(operand, padding_value, padding_config)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T |
padding_value
|
XlaOp
|
สเกลาร์ประเภท T เพื่อเติมใน
การเพิ่มระยะขอบ |
padding_config
|
PaddingConfig
|
จำนวนการเว้นวรรคที่ขอบทั้ง 2 ด้าน (ต่ำ สูง) และระหว่างองค์ประกอบของแต่ละ มิติ |
ขยายoperandอาร์เรย์ที่ระบุโดยการเพิ่มระยะห่างรอบอาร์เรย์และระหว่าง
องค์ประกอบของอาร์เรย์ด้วยpadding_valueที่ระบุ padding_config
ระบุจำนวนการเว้นขอบและการเว้นภายในสำหรับแต่ละ
มิติข้อมูล
PaddingConfig เป็นฟิลด์ที่ซ้ำของ PaddingConfigDimension ซึ่งมีฟิลด์ 3 รายการสำหรับแต่ละมิติข้อมูล ได้แก่ edge_padding_low, edge_padding_high และ interior_padding
edge_padding_low และ edge_padding_high ระบุจำนวนการเพิ่มระยะขอบ
ที่ด้านล่าง (ถัดจากดัชนี 0) และด้านบน (ถัดจากดัชนีสูงสุด) ของ
แต่ละมิติ ตามลำดับ จำนวนระยะขอบอาจเป็นค่าลบได้ โดยค่าสัมบูรณ์ของระยะขอบที่เป็นลบจะระบุจำนวนองค์ประกอบที่จะนำออกจากมิติที่ระบุ
interior_padding ระบุจำนวนระยะห่างจากเส้นขอบที่เพิ่มระหว่างองค์ประกอบ 2 รายการในแต่ละมิติข้อมูล โดยต้องไม่เป็นค่าลบ การเว้นระยะภายในจะเกิดขึ้น
ก่อนการเว้นระยะขอบตามตรรกะ ดังนั้นในกรณีของการเว้นระยะขอบเชิงลบ ระบบจะนำองค์ประกอบ
ออกจากตัวถูกดำเนินการที่มีการเว้นระยะภายใน
การดำเนินการนี้จะไม่มีผลหากคู่การเพิ่มระยะขอบทั้งหมดเป็น (0, 0) และค่าการเพิ่มระยะขอบภายในทั้งหมดเป็น 0 รูปภาพด้านล่างแสดงตัวอย่างค่า edge_padding และ interior_padding ที่แตกต่างกันสำหรับอาร์เรย์ 2 มิติ
ดูข้อมูล StableHLO ได้ที่ StableHLO - pad
พารามิเตอร์
ดูเพิ่มเติม
XlaBuilder::Parameter
Parameter แสดงถึงอินพุตอาร์กิวเมนต์ในการคำนวณ
PartitionID
ดูเพิ่มเติม
XlaBuilder::BuildPartitionId
สร้าง partition_id ของกระบวนการปัจจุบัน
PartitionID(shape)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
shape |
Shape |
รูปร่างของข้อมูล |
PartitionID อาจปรากฏในข้อมูลการทิ้ง HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
ดูข้อมูล StableHLO ได้ที่ StableHLO - partition_id
PopulationCount
ดูเพิ่มเติม
XlaBuilder::PopulationCount
คำนวณจำนวนบิตที่ตั้งค่าในแต่ละองค์ประกอบของ operand
PopulationCount(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - popcnt
Pow
ดูเพิ่มเติม
XlaBuilder::Pow
ดำเนินการยกกำลังแบบทีละองค์ประกอบของ lhs ด้วย rhs
Pow(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Pow มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Pow(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่StableHLO - power
จริง
ดูเพิ่มเติม
XlaBuilder::Real
ส่วนจริงของรูปร่างเชิงซ้อน (หรือจริง) แบบทีละองค์ประกอบ x -> real(x) หากตัวถูกดำเนินการเป็นประเภททศนิยม Real จะแสดงผลค่าเดียวกัน
Real(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - real
Recv
ดูเพิ่มเติม
XlaBuilder::Recv
Recv, RecvWithTokens และ RecvToHost เป็นการดำเนินการที่ทำหน้าที่เป็น
องค์ประกอบพื้นฐานของการสื่อสารใน HLO โดยปกติแล้วการดำเนินการเหล่านี้จะปรากฏในการดัมพ์ HLO เป็นส่วนหนึ่ง
ของการรับ/ส่งข้อมูลระดับต่ำหรือการโอนข้ามอุปกรณ์ แต่ไม่ได้มีไว้
ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
Recv(shape, handle)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
shape |
Shape |
รูปร่างของข้อมูลที่จะรับ |
handle |
ChannelHandle |
ตัวระบุที่ไม่ซ้ำกันสำหรับคู่การส่ง/รับแต่ละคู่ |
รับข้อมูลที่มีรูปร่างที่กำหนดจากSendคำสั่งใน
การคำนวณอื่นที่ใช้แฮนเดิลช่องเดียวกัน ส่งคืน
XlaOp สำหรับข้อมูลที่ได้รับ
ดูข้อมูล StableHLO ได้ที่ StableHLO - recv
RecvDone
ดูเพิ่มเติม
HloInstruction::CreateRecv และ HloInstruction::CreateRecvDone
เช่นเดียวกับ Send, Client API ของการดำเนินการ Recv แสดงถึงการสื่อสารแบบซิงโครนัส อย่างไรก็ตาม คำสั่งจะแยกย่อยภายในเป็นคำสั่ง HLO 2 รายการ (Recv และ RecvDone) เพื่อเปิดใช้การโอนข้อมูลแบบอะซิงโครนัส
Recv(const Shape& shape, int64 channel_id)
จัดสรรทรัพยากรที่จำเป็นเพื่อรับข้อมูลจากคำสั่ง Send
ที่มี channel_id เดียวกัน แสดงบริบทสำหรับทรัพยากรที่จัดสรร ซึ่งRecvDone คำสั่งต่อไปนี้ใช้เพื่อรอให้การโอนข้อมูลเสร็จสมบูรณ์ บริบทคือทูเพิลของ {บัฟเฟอร์รับ (รูปร่าง), ตัวระบุคำขอ (U32)} และใช้ได้เฉพาะคำสั่ง RecvDone เท่านั้น
เมื่อได้รับบริบทที่สร้างขึ้นจากRecvคำสั่งแล้ว ฟังก์ชันนี้จะรอให้การโอนข้อมูลเสร็จสมบูรณ์และส่งคืนข้อมูลที่ได้รับ
ลด (Reduce)
ดูเพิ่มเติม
XlaBuilder::Reduce
ใช้ฟังก์ชันการลดกับอาร์เรย์อย่างน้อย 1 รายการแบบขนาน
Reduce(operands..., init_values..., computation, dimensions_to_reduce)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands
|
ลำดับของ N XlaOp
|
อาร์เรย์ N ของประเภท T_0,...,
T_{N-1} |
init_values
|
ลำดับของ N XlaOp
|
สเกลาร์ N ประเภท
T_0,..., T_{N-1} |
computation
|
XlaComputation
|
การคำนวณประเภท
T_0,..., T_{N-1}, T_0,
...,T_{N-1} ->
Collate(T_0,...,
T_{N-1}) |
dimensions_to_reduce
|
int64 อาร์เรย์
|
อาร์เรย์ของมิติข้อมูลที่ไม่ได้เรียงลำดับ เพื่อลด |
สถานที่:
- N ต้องมากกว่าหรือเท่ากับ 1
- การคำนวณต้องเป็นแบบเชื่อมโยง "โดยประมาณ" (ดูด้านล่าง)
- อาร์เรย์อินพุตทั้งหมดต้องมีมิติข้อมูลเดียวกัน
- ค่าเริ่มต้นทั้งหมดต้องสร้างเอกลักษณ์ภายใต้
computation - หาก
N = 1Collate(T)คือT - หาก
N > 1,Collate(T_0, ..., T_{N-1})เป็นทูเพิลขององค์ประกอบNประเภทT
การดำเนินการนี้จะลดมิติข้อมูลอย่างน้อย 1 รายการของอาร์เรย์อินพุตแต่ละรายการให้เป็นสเกลาร์
จำนวนมิติข้อมูลของอาร์เรย์ที่แสดงผลแต่ละรายการคือ
number_of_dimensions(operand) - len(dimensions) เอาต์พุตของ Op คือ
Collate(Q_0, ..., Q_N) โดยที่ Q_i เป็นอาร์เรย์ประเภท T_i ซึ่งมี
มิติข้อมูลตามที่อธิบายไว้ด้านล่าง
อนุญาตให้แบ็กเอนด์ต่างๆ เชื่อมโยงการคำนวณการลดอีกครั้งได้ ซึ่งอาจทำให้เกิดความแตกต่างของตัวเลข เนื่องจากฟังก์ชันการลดบางอย่าง เช่น การบวก ไม่ใช่การเชื่อมโยงสำหรับจำนวนทศนิยม อย่างไรก็ตาม หากช่วงของข้อมูลถูกจำกัด การบวกเลขจุดลอยตัวจะใกล้เคียงพอที่จะเป็นแบบเชื่อมโยงสำหรับการใช้งานจริงส่วนใหญ่
ดูข้อมูล StableHLO ได้ที่ StableHLO - reduce
ตัวอย่าง
เมื่อลดตามมิติเดียวในอาร์เรย์ 1 มิติเดียวที่มีค่า [10, 11,
12, 13] โดยมีฟังก์ชันการลด f (ซึ่งก็คือ computation) ระบบจะคำนวณได้ดังนี้
f(10, f(11, f(12, f(init_value, 13)))
แต่ก็ยังมีอีกหลายกรณีที่เป็นไปได้ เช่น
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
ต่อไปนี้คือตัวอย่างรหัสเทียมคร่าวๆ ของวิธี การใช้การลด โดยใช้การบวกเป็นค่าเริ่มต้น ของการคำนวณการลดเป็น 0
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the number of dimensions of the result.
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
ต่อไปนี้เป็นตัวอย่างการลดอาร์เรย์ 2 มิติ (เมทริกซ์) รูปร่างมี 2 มิติ มิติที่ 0 ขนาด 2 และมิติที่ 1 ขนาด 3 ดังนี้
ผลลัพธ์ของการลดมิติข้อมูล 0 หรือ 1 ด้วยฟังก์ชัน "add"
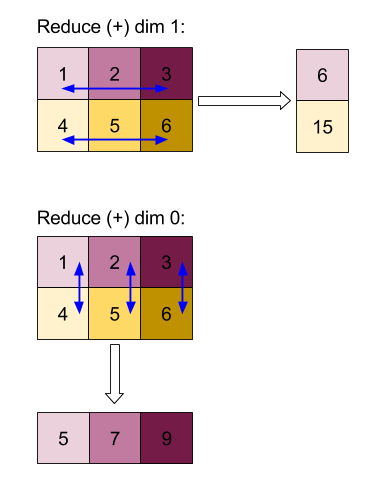
โปรดทราบว่าผลลัพธ์ของการลดทั้ง 2 แบบคืออาร์เรย์ 1 มิติ แผนภาพแสดงรายการหนึ่งเป็นคอลัมน์ และอีกรายการเป็นแถวเพื่อความสะดวกในการมองเห็น
ตัวอย่างที่ซับซ้อนมากขึ้นคืออาร์เรย์ 3 มิติ มีจํานวนมิติข้อมูล 3 มิติ มิติข้อมูล 0 ขนาด 4, มิติข้อมูล 1 ขนาด 2 และมิติข้อมูล 2 ขนาด 3 เพื่อความ ง่าย ค่า 1 ถึง 6 จะทำซ้ำในมิติข้อมูล 0
เช่นเดียวกับตัวอย่าง 2 มิติ เราสามารถลดมิติข้อมูลเพียงมิติเดียวได้ เช่น หากลด มิติข้อมูล 0 เราจะได้อาร์เรย์ 2 มิติที่ค่าทั้งหมดใน มิติข้อมูล 0 ถูกพับเป็นสเกลาร์
| 4 8 12 |
| 16 20 24 |
หากลดมิติข้อมูลที่ 2 เราจะได้อาร์เรย์ 2 มิติซึ่งค่าทั้งหมด ในมิติข้อมูลที่ 2 จะรวมกันเป็นสเกลาร์
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
โปรดทราบว่าลำดับสัมพัทธ์ระหว่างมิติข้อมูลที่เหลือในอินพุตจะยังคงอยู่ในเอาต์พุต แต่ระบบอาจกำหนดหมายเลขใหม่ให้กับมิติข้อมูลบางรายการ (เนื่องจากจำนวนมิติข้อมูลเปลี่ยนแปลง)
นอกจากนี้ เรายังลดมิติข้อมูลหลายรายการได้ด้วย การลดมิติข้อมูล 0 และ 1 จะสร้างอาร์เรย์ 1 มิติ [20, 28, 36]
การลดอาร์เรย์ 3 มิติในทุกมิติจะทำให้เกิดสเกลาร์ 84
Variadic Reduce
เมื่อ N > 1 ฟังก์ชันการลดจะมีความซับซ้อนมากขึ้นเล็กน้อย เนื่องจากจะ
ใช้กับอินพุตทั้งหมดพร้อมกัน ระบบจะส่งตัวถูกดำเนินการไปยัง
การคำนวณตามลำดับต่อไปนี้
- การเรียกใช้ค่าที่ลดลงสำหรับตัวถูกดำเนินการแรก
- ...
- การเรียกใช้ค่าที่ลดลงสำหรับตัวถูกดำเนินการที่ N
- ค่าอินพุตสำหรับตัวถูกดำเนินการแรก
- ...
- ค่าอินพุตสำหรับตัวถูกดำเนินการที่ N
ตัวอย่างเช่น ลองพิจารณาฟังก์ชันการลดต่อไปนี้ ซึ่งใช้เพื่อ คำนวณค่าสูงสุดและอาร์กิวเมนต์สูงสุดของอาร์เรย์ 1 มิติแบบขนานได้
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
สำหรับอาร์เรย์อินพุต 1 มิติ V = Float[N], K = Int[N] และค่าเริ่มต้น
I_V = Float, I_K = Int ผลลัพธ์ f_(N-1) ของการลดในมิติข้อมูลอินพุต
เพียงมิติเดียวจะเทียบเท่ากับการใช้แบบเรียกซ้ำต่อไปนี้
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
การใช้การลดนี้กับอาร์เรย์ของค่าและอาร์เรย์ของดัชนีตามลำดับ (เช่น iota) จะวนซ้ำพร้อมกันในอาร์เรย์ และแสดงผลทูเพิล ที่มีค่าสูงสุดและดัชนีที่ตรงกัน
ReducePrecision
ดูเพิ่มเติม
XlaBuilder::ReducePrecision
จำลองผลของการแปลงค่าทศนิยมเป็นรูปแบบที่มีความแม่นยำต่ำกว่า (เช่น IEEE-FP16) และแปลงกลับเป็นรูปแบบเดิม คุณระบุจำนวนบิตของเลขชี้กำลังและแมนทิสซาในรูปแบบที่มีความแม่นยำต่ำกว่าได้ตามต้องการ แม้ว่าการใช้งานฮาร์ดแวร์บางอย่างอาจไม่รองรับขนาดบิตทั้งหมดก็ตาม
ReducePrecision(operand, exponent_bits, mantissa_bits)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภทจุดลอยตัว T |
exponent_bits |
int32 |
จำนวนบิตเลขชี้กำลังในรูปแบบความแม่นยำต่ำ |
mantissa_bits |
int32 |
จำนวนบิตแมนทิสซาในรูปแบบความแม่นยำต่ำ |
ผลลัพธ์คืออาร์เรย์ประเภท T ระบบจะปัดค่าอินพุตให้เป็นค่าที่ใกล้เคียงที่สุด
ซึ่งแสดงได้ด้วยจำนวนบิตของแมนทิสซาที่กำหนด (ใช้ความหมายของ "ปัดเศษคู่")
และค่าใดๆ ที่เกินช่วงที่ระบุโดยจำนวนบิตของ
เลขชี้กำลังจะถูกจำกัดให้เป็นอนันต์บวกหรือลบ NaNจะยังคงอยู่
แม้ว่าอาจมีการแปลงเป็นค่า NaN ที่เป็นมาตรฐาน
รูปแบบที่มีความแม่นยำต่ำกว่าต้องมีบิตเลขชี้กำลังอย่างน้อย 1 บิต (เพื่อแยกค่าศูนย์ออกจากค่าอนันต์ เนื่องจากทั้ง 2 ค่ามีแมนทิสซาเป็นศูนย์) และต้องมีจำนวนบิตแมนทิสซาที่ไม่เป็นลบ จำนวนบิตของเลขชี้กำลังหรือ
แมนทิสซาอาจเกินค่าที่สอดคล้องกันสำหรับประเภท T จากนั้นส่วนที่สอดคล้องกันของ Conversion จะไม่มีการดำเนินการใดๆ
ดูข้อมูล StableHLO ได้ที่ StableHLO - reduce_precision
ReduceScatter
ดูเพิ่มเติม
XlaBuilder::ReduceScatter
ReduceScatter เป็นการดำเนินการแบบกลุ่มที่ทำ AllReduce ได้อย่างมีประสิทธิภาพ
จากนั้นจะกระจายผลลัพธ์โดยการแบ่งออกเป็นshard_count บล็อกตาม
scatter_dimension และรีพลิกากลุ่ม i จะได้รับ ith
ชาร์ด
ReduceScatter(operand, computation, scatter_dimension, shard_count,
replica_groups, channel_id, layout, use_global_device_ids)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์หรือทูเพิลที่ไม่ว่างเปล่า ของอาร์เรย์ที่จะลดใน แบบจำลอง |
computation |
XlaComputation |
การคำนวณการลด |
scatter_dimension |
int64 |
มิติข้อมูลที่จะกระจาย |
shard_count
|
int64
|
จำนวนบล็อกที่จะแยก
scatter_dimension |
replica_groups
|
ReplicaGroup เวกเตอร์
|
กลุ่มที่ใช้ในการ ลด |
channel_id
|
ไม่บังคับ
ChannelHandle |
รหัสช่องที่ไม่บังคับสำหรับการสื่อสารข้ามโมดูล |
layout
|
ไม่บังคับ Layout
|
เลย์เอาต์หน่วยความจำที่ผู้ใช้ระบุ |
use_global_device_ids |
ไม่บังคับ bool |
Flag ที่ผู้ใช้ระบุ |
- เมื่อ
operandเป็นทูเพิลของอาร์เรย์ ระบบจะดำเนินการลดแบบกระจายในแต่ละ องค์ประกอบของทูเพิล replica_groupsคือรายการกลุ่มรีพลิคาระหว่างที่การลดค่าจะดำเนินการ (ดึงข้อมูลรหัสรีพลิคาสำหรับรีพลิคาปัจจุบันได้โดยใช้ReplicaId) ลำดับของรีพลิคาในแต่ละกลุ่มจะกำหนด ลำดับที่จะกระจายผลลัพธ์การลดค่าทั้งหมดreplica_groupsต้องว่างเปล่า (ในกรณีนี้สำเนาทั้งหมดจะอยู่ในกลุ่มเดียว) หรือมีจำนวนองค์ประกอบเท่ากับจำนวนสำเนา เมื่อมีกลุ่มรีพลิกามากกว่า 1 กลุ่ม กลุ่มรีพลิกาทั้งหมดจะต้องมีขนาดเท่ากัน ตัวอย่างเช่นreplica_groups = {0, 2}, {1, 3}จะทำการลดระหว่างรีพลิกาทั้ง0และ2รวมถึง1และ3จากนั้นจะกระจายผลลัพธ์shard_countคือขนาดของกลุ่มรีพลิเคชันแต่ละกลุ่ม เราต้องใช้ข้อมูลนี้ในกรณีที่replica_groupsว่าง หากreplica_groupsไม่ว่างshard_countต้องเท่ากับขนาดของกลุ่มรีพลิเคชันแต่ละกลุ่มchannel_idใช้สำหรับการสื่อสารข้ามโมดูล โดยมีเพียงการดำเนินการreduce-scatterที่มีchannel_idเดียวกันเท่านั้นที่สื่อสารกันได้layoutดูข้อมูลเพิ่มเติมเกี่ยวกับเลย์เอาต์ได้ที่ xla::shapesuse_global_device_idsเป็นแฟล็กที่ผู้ใช้ระบุ เมื่อfalse(ค่าเริ่มต้น) ตัวเลขในreplica_groupsจะเป็นReplicaIdเมื่อtruereplica_groupsแสดงรหัสส่วนกลางของ (ReplicaID*partition_count+partition_id) เช่น- โดยมี 2 รีพลิกาและ 4 พาร์ติชัน
- replica_groups={ {0,1,4,5},{2,3,6,7} } and use_global_device_ids=true
- group[0] = (0,0), (0,1), (1,0), (1,1)
- group[1] = (0,2), (0,3), (1,2), (1,3)
- โดยแต่ละคู่คือ (replica_id, partition_id)
รูปร่างเอาต์พุตคือรูปร่างอินพุตที่มีขนาดเล็กลง scatter_dimension
shard_count เท่า เช่น หากมี 2 สำเนาและตัวถูกดำเนินการมีค่า [1.0, 2.25] และ [3.0, 5.25] ตามลำดับใน 2 สำเนา ค่าเอาต์พุตจาก Op นี้ที่ scatter_dim เป็น 0 จะเป็น [4.0] สำหรับสำเนาแรกและ [7.5] สำหรับสำเนาที่สอง
ดูข้อมูล StableHLO ได้ที่ StableHLO - reduce_scatter
ReduceScatter - ตัวอย่างที่ 1 - StableHLO

ในตัวอย่างด้านบน มีรีพลิกา 2 รายการที่เข้าร่วมใน ReduceScatter ในแต่ละรีพลิกา ตัวถูกดำเนินการมีรูปร่าง f32[2,4] การลดทั้งหมด (ผลรวม) จะดำเนินการในรีพลิกาต่างๆ ซึ่งจะสร้างค่าที่ลดลงของรูปร่าง f32[2,4] ในแต่ละรีพลิกา จากนั้นจะแยกค่าที่ลดลงนี้ออกเป็น 2 ส่วนตามมิติข้อมูล 1 เพื่อให้แต่ละส่วนมีรูปร่าง f32[2,2] แต่ละรีเพลสในกลุ่มกระบวนการจะได้รับส่วนที่สอดคล้องกับตำแหน่งของตนในกลุ่ม ด้วยเหตุนี้ เอาต์พุตใน แต่ละรีพลิกะจึงมีรูปร่าง f32[2,2]
ReduceWindow
ดูเพิ่มเติม
XlaBuilder::ReduceWindow
ใช้ฟังก์ชันการลดกับองค์ประกอบทั้งหมดในแต่ละหน้าต่างของลำดับอาร์เรย์หลายมิติ N รายการ โดยสร้างอาร์เรย์หลายมิติ N รายการเดียวหรือเป็นทูเพิลเป็นเอาต์พุต อาร์เรย์เอาต์พุตแต่ละรายการมีจำนวนองค์ประกอบเท่ากับ
จำนวนตำแหน่งที่ถูกต้องของหน้าต่าง เลเยอร์การรวมสามารถแสดงเป็น
ReduceWindow computation ที่ใช้จะส่งผ่านไปยัง init_values ทางด้านซ้ายมือเสมอ เช่นเดียวกับ Reduce
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands
|
N XlaOps
|
ลำดับของอาร์เรย์หลายมิติของประเภท T_0,..., T_{N-1} แต่ละรายการแสดงพื้นที่ฐานที่วางหน้าต่าง |
init_values
|
N XlaOps
|
ค่าเริ่มต้น N สำหรับ การลด โดยค่าเริ่มต้น 1 ค่าสำหรับตัวถูกดำเนินการ N ตัว ดูรายละเอียดได้ที่ลด |
computation
|
XlaComputation
|
ฟังก์ชันลดประเภท T_0,
..., T_{N-1}, T_0, ..., T_{N-1}
-> Collate(T_0, ..., T_{N-1})
เพื่อใช้กับองค์ประกอบในแต่ละ
หน้าต่างของตัวถูกดำเนินการ
อินพุตทั้งหมด |
window_dimensions
|
ArraySlice<int64>
|
อาร์เรย์ของจำนวนเต็มสำหรับค่ามิติข้อมูล หน้าต่าง |
window_strides
|
ArraySlice<int64>
|
อาร์เรย์ของจำนวนเต็มสำหรับค่า ระยะก้าวกระโดดของหน้าต่าง |
base_dilations
|
ArraySlice<int64>
|
อาร์เรย์ของจำนวนเต็มสำหรับค่า การขยายฐาน |
window_dilations
|
ArraySlice<int64>
|
อาร์เรย์ของจำนวนเต็มสำหรับค่าการขยาย หน้าต่าง |
padding
|
Padding
|
ประเภทการเพิ่มขอบสำหรับหน้าต่าง (Padding::kSame ซึ่งเพิ่มขอบเพื่อให้มีรูปร่างเอาต์พุตเหมือนกับอินพุตหากระยะก้าวยาว 1 หรือ Padding::kValid ซึ่งไม่ใช้การเพิ่มขอบและ "หยุด" หน้าต่าง เมื่อไม่พอดีอีกต่อไป) |
สถานที่:
- N ต้องมากกว่าหรือเท่ากับ 1
- อาร์เรย์อินพุตทั้งหมดต้องมีมิติข้อมูลเดียวกัน
- หาก
N = 1Collate(T)คือT - หาก
N > 1,Collate(T_0, ..., T_{N-1})เป็นทูเพิลขององค์ประกอบNประเภท(T0,...T{N-1})
ดูข้อมูล StableHLO ได้ที่ StableHLO - reduce_window
ReduceWindow - ตัวอย่าง 1
อินพุตคือเมทริกซ์ขนาด [4x6] และทั้ง window_dimensions และ window_stride_dimensions คือ [2x3]
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
Stride ที่มีค่า 1 ในมิติข้อมูลจะระบุว่าตำแหน่งของหน้าต่างในมิติข้อมูล อยู่ห่างจากหน้าต่างที่อยู่ติดกัน 1 องค์ประกอบ หากต้องการระบุว่าไม่มีหน้าต่างใดซ้อนทับกัน window_stride_dimensions ควรเท่ากับ window_dimensions รูปภาพด้านล่างแสดงการใช้ค่า Stride ที่แตกต่างกัน 2 ค่า การเพิ่มระยะขอบจะใช้กับแต่ละมิติข้อมูลของอินพุตและการคำนวณ จะเหมือนกับว่าอินพุตมีมิติข้อมูลหลังจาก การเพิ่มระยะขอบ
สำหรับตัวอย่างการเพิ่มระยะขอบที่ไม่ใช่แบบง่าย ให้พิจารณาการคำนวณค่าต่ำสุดของหน้าต่างลดขนาด
(ค่าเริ่มต้นคือ MAX_FLOAT) ที่มีมิติข้อมูล 3 และระยะก้าวย่าง 2 เหนืออาร์เรย์อินพุต [10000, 1000, 100, 10, 1] การเพิ่มระยะขอบ kValid จะคำนวณค่าต่ำสุดในหน้าต่างที่ใช้ได้ 2 หน้าต่าง ได้แก่ [10000, 1000, 100] และ [100, 10, 1] ซึ่งส่งผลให้ได้เอาต์พุต [100, 1] การเพิ่มระยะขอบ kSame จะเพิ่มระยะขอบอาร์เรย์ก่อนเพื่อให้รูปร่างหลังการลดขนาดหน้าต่างเหมือนกันกับอินพุตสำหรับระยะก้าวย่าง 1 โดยการเพิ่มองค์ประกอบเริ่มต้นทั้ง 2 ด้าน ซึ่งจะได้ [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE] การเรียกใช้การลดขนาดหน้าต่างเหนืออาร์เรย์ที่มีการเพิ่มระยะขอบจะดำเนินการในหน้าต่าง 3 หน้าต่าง ได้แก่ [MAX_VALUE, 10000, 1000], [1000, 100, 10], [10, 1, MAX_VALUE] และให้ผลลัพธ์เป็น [1000, 10, 1]
ลำดับการประเมินฟังก์ชันการลดทอนเป็นแบบกำหนดเองและอาจ
ไม่แน่นอน ดังนั้น ฟังก์ชันการลดจึงไม่ควรไวต่อการเชื่อมโยงใหม่มากเกินไป
ดูรายละเอียดเพิ่มเติมได้ที่การสนทนาเกี่ยวกับกฎการเปลี่ยนกลุ่มในบริบทของ Reduce
ReduceWindow - ตัวอย่าง 2 - StableHLO

ในตัวอย่างด้านบน
อินพุต) ตัวถูกดำเนินการมีรูปร่างอินพุตเป็น S32[3,2] โดยมีค่าเป็น
[[1,2],[3,4],[5,6]]
ขั้นตอนที่ 1) การขยายฐานที่มีปัจจัย 2 ตามมิติแถวจะแทรกรูระหว่างแต่ละแถวของตัวถูกดำเนินการ ระบบจะใช้ระยะห่างจากขอบ 2 แถวที่ด้านบนและ 1 แถวที่ด้านล่างหลังจากการขยาย ผลลัพธ์คือ Tensor จะสูงขึ้น
ขั้นตอนที่ 2) มีการกำหนดหน้าต่างที่มีรูปร่าง [2,1] โดยมีการขยายหน้าต่าง [3,1] ซึ่งหมายความว่าแต่ละหน้าต่างจะเลือก 2 องค์ประกอบจากคอลัมน์เดียวกัน แต่จะเลือกองค์ประกอบที่ 2 จาก 3 แถวใต้แถวแรกแทนที่จะเลือกจากแถวที่อยู่ใต้แถวแรกโดยตรง
ขั้นตอนที่ 3) จากนั้นเลื่อนหน้าต่างไปตามตัวถูกดำเนินการโดยมีระยะก้าวย่างเป็น [4,1] ซึ่งจะทำให้หน้าต่างเลื่อนลง 4 แถวในแต่ละครั้ง ขณะที่เลื่อน 1 คอลัมน์ในแต่ละครั้งในแนวนอน ระบบจะป้อนค่า init_value ลงในเซลล์การเพิ่มระยะขอบ (ในกรณีนี้คือ init_value = 0) และจะละเว้นค่าที่ "ตก" ลงในเซลล์การขยาย
เนื่องจากระยะก้าวย่างและการเพิ่มระยะขอบ หน้าต่างบางส่วนจึงทับซ้อนเฉพาะค่า 0 และช่องว่าง ขณะที่หน้าต่างอื่นๆ ทับซ้อนค่าอินพุตจริง
ขั้นตอนที่ 4) ภายในแต่ละหน้าต่าง ระบบจะรวมองค์ประกอบโดยใช้ฟังก์ชันการลด (a, b) → a + b โดยเริ่มจากค่าเริ่มต้น 0 หน้าต่าง 2 บานบนสุดจะเห็นเฉพาะการเว้นวรรคและรู ดังนั้นผลลัพธ์จึงเป็น 0 หน้าต่างด้านล่าง จะบันทึกค่า 3 และ 4 จากอินพุตและแสดงค่าเหล่านั้นเป็นผลลัพธ์
ผลลัพธ์) เอาต์พุตสุดท้ายมีรูปร่าง S32[2,2] โดยมีค่า [[0,0],[3,4]]
Rem
ดูเพิ่มเติม
XlaBuilder::Rem
ดำเนินการหาเศษของตัวตั้ง lhs และตัวหาร rhs ทีละองค์ประกอบ
เครื่องหมายของผลลัพธ์จะมาจากตัวตั้ง และค่าสัมบูรณ์ของ ผลลัพธ์จะน้อยกว่าค่าสัมบูรณ์ของตัวหารเสมอ
Rem(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Rem มีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Rem(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - remainder
ReplicaId
ดูเพิ่มเติม
XlaBuilder::ReplicaId
แสดงผลรหัสที่ไม่ซ้ำกัน (สเกลาร์ U32) ของรีเพล็กซ์
ReplicaId()
รหัสที่ไม่ซ้ำกันของแต่ละรีพลิกาคือจำนวนเต็มที่ไม่มีเครื่องหมายในช่วง [0, N) โดยที่ N คือจำนวนรีพลิกา เนื่องจากรีพลิกาทั้งหมดเรียกใช้โปรแกรมเดียวกัน การเรียกใช้ ReplicaId() ในโปรแกรมจะแสดงค่าที่แตกต่างกันในรีพลิกาแต่ละรายการ
ดูข้อมูล StableHLO ได้ที่ StableHLO - replica_id
ปรับรูปร่าง
ดูเพิ่มเติม
XlaBuilder::Reshape
และCollapse
เปลี่ยนรูปร่างมิติข้อมูลของอาร์เรย์เป็นการกำหนดค่าใหม่
Reshape(operand, dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T |
dimensions |
int64 เวกเตอร์ |
เวกเตอร์ของขนาดของมิติข้อมูลใหม่ |
ในเชิงแนวคิด ฟังก์ชัน Reshape จะแปลงอาร์เรย์ให้เป็นเวกเตอร์แบบ 1 มิติของค่าข้อมูลก่อน
แล้วจึงปรับเวกเตอร์นี้ให้เป็นรูปร่างใหม่ อาร์กิวเมนต์อินพุต
คืออาร์เรย์ที่กำหนดเองของประเภท T, เวกเตอร์คงที่ที่คอมไพล์แล้วของดัชนี
มิติข้อมูล และเวกเตอร์คงที่ที่คอมไพล์แล้วของขนาดมิติข้อมูลสำหรับผลลัพธ์
เวกเตอร์ dimensions จะกำหนดขนาดของอาร์เรย์เอาต์พุต ค่าที่ดัชนี 0 ใน dimensions คือขนาดของมิติข้อมูล 0 ค่าที่ดัชนี 1 คือขนาดของมิติข้อมูล 1 และอื่นๆ ผลคูณของมิติข้อมูล dimensions ต้องเท่ากับผลคูณของขนาดมิติข้อมูลของตัวถูกดำเนินการ เมื่อปรับอาร์เรย์ที่ยุบแล้วให้เป็นอาร์เรย์หลายมิติที่กำหนดโดย dimensions มิติข้อมูลใน dimensions จะเรียงลำดับจากมิติข้อมูลที่มีการเปลี่ยนแปลงช้าที่สุด (สำคัญที่สุด) ไปยังมิติข้อมูลที่มีการเปลี่ยนแปลงเร็วที่สุด (สำคัญน้อยที่สุด)
เช่น สมมติว่า v เป็นอาร์เรย์ที่มี 24 องค์ประกอบ
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
let v012_24 = Reshape(v, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
ในกรณีพิเศษ ฟังก์ชัน Reshape จะเปลี่ยนอาร์เรย์ที่มีองค์ประกอบเดียวเป็นสเกลาร์และ ในทางกลับกัน ตัวอย่างเช่น
Reshape(f32[1x1] { {5} }, {}) == 5;
Reshape(5, {1,1}) == f32[1x1] { {5} };
ดูข้อมูล StableHLO ได้ที่ StableHLO - reshape
ปรับรูปร่าง (ชัดเจน)
ดูเพิ่มเติม
XlaBuilder::Reshape
Reshape(shape, operand)
การดำเนินการ Reshape ที่ใช้รูปร่างเป้าหมายที่ชัดเจน
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
shape |
Shape |
รูปร่างเอาต์พุตของประเภท T |
operand |
XlaOp |
อาร์เรย์ของประเภท T |
Rev (ย้อนกลับ)
ดูเพิ่มเติม
XlaBuilder::Rev
Rev(operand, dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T |
dimensions |
ArraySlice<int64> |
มิติข้อมูลที่จะกลับ |
กลับลำดับขององค์ประกอบในอาร์เรย์ operand ตาม dimensions ที่ระบุ โดยสร้างอาร์เรย์เอาต์พุตที่มีรูปร่างเดียวกัน องค์ประกอบแต่ละรายการของอาร์เรย์ตัวถูกดำเนินการที่ดัชนีหลายมิติจะจัดเก็บไว้ในอาร์เรย์เอาต์พุตที่ดัชนีที่แปลงแล้ว ดัชนีหลายมิติจะได้รับการแปลงโดยการกลับดัชนีในแต่ละมิติที่จะกลับ (เช่น หากมิติที่มีขนาด N เป็นหนึ่งในมิติที่กลับ ดัชนี i จะได้รับการแปลงเป็น N - 1 - i)
การใช้งานการดำเนินการ Rev อย่างหนึ่งคือการกลับอาร์เรย์น้ำหนักการแปลงตามมิติข้อมูลหน้าต่าง 2 มิติระหว่างการคำนวณการไล่ระดับสีในโครงข่ายประสาทเทียม
ดูข้อมูล StableHLO ได้ที่ StableHLO - reverse
RngNormal
ดูเพิ่มเติม
XlaBuilder::RngNormal
สร้างเอาต์พุตที่มีรูปร่างที่กำหนดด้วยตัวเลขสุ่มที่สร้างขึ้นตาม \(N(\mu, \sigma)\) การแจกแจงแบบปกติ พารามิเตอร์ \(\mu\) และ \(\sigma\)รวมถึง รูปร่างเอาต์พุตต้องมีประเภทองค์ประกอบแบบจุดลอยตัว นอกจากนี้ พารามิเตอร์ต้องมีค่าสเกลาร์
RngNormal(mu, sigma, shape)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
mu |
XlaOp |
สเกลาร์ของประเภท T ที่ระบุค่าเฉลี่ยของตัวเลขที่สร้างขึ้น |
sigma
|
XlaOp
|
สเกลาร์ประเภท T ที่ระบุค่าเบี่ยงเบนมาตรฐานของ ที่สร้างขึ้น |
shape |
Shape |
รูปร่างเอาต์พุตของประเภท T |
ดูข้อมูล StableHLO ได้ที่ StableHLO - rng
RngUniform
ดูเพิ่มเติม
XlaBuilder::RngUniform
สร้างเอาต์พุตที่มีรูปร่างที่กำหนดด้วยเลขสุ่มที่สร้างขึ้นตาม การกระจายแบบเดียวกันในช่วง \([a,b)\)พารามิเตอร์และประเภทองค์ประกอบเอาต์พุต ต้องเป็นประเภทบูลีน ประเภทจำนวนเต็ม หรือประเภทจุดลอยตัว และประเภทต้องมีความสอดคล้อง ปัจจุบันแบ็กเอนด์ของ CPU และ GPU รองรับเฉพาะ F64, F32, F16, BF16, S64, U64, S32 และ U32 เท่านั้น นอกจากนี้ พารามิเตอร์ต้องเป็นค่าสเกลาร์ หาก \(b <= a\) ผลลัพธ์เป็นการกำหนดการใช้งาน
RngUniform(a, b, shape)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
a |
XlaOp |
สเกลาร์ประเภท T ที่ระบุขีดจำกัดล่างของช่วง |
b |
XlaOp |
สเกลาร์ของประเภท T ที่ระบุขีดจำกัดบนของช่วง |
shape |
Shape |
รูปร่างเอาต์พุตของประเภท T |
ดูข้อมูล StableHLO ได้ที่ StableHLO - rng
RngBitGenerator
ดูเพิ่มเติม
XlaBuilder::RngBitGenerator
สร้างเอาต์พุตที่มีรูปร่างที่กำหนดซึ่งเต็มไปด้วยบิตแบบสุ่มที่สม่ำเสมอโดยใช้อัลกอริทึมที่ระบุ (หรือค่าเริ่มต้นของแบ็กเอนด์) และส่งคืนสถานะที่อัปเดตแล้ว (มีรูปร่างเดียวกับสถานะเริ่มต้น) และข้อมูลแบบสุ่มที่สร้างขึ้น
สถานะเริ่มต้นคือสถานะเริ่มต้นของการสร้างตัวเลขสุ่มปัจจุบัน โดยรูปร่างที่จำเป็นและค่าที่ถูกต้องจะขึ้นอยู่กับอัลกอริทึมที่ใช้
เอาต์พุตรับประกันได้ว่าเป็นฟังก์ชันที่กำหนดได้ของสถานะเริ่มต้น แต่ไม่รับประกันว่าจะกำหนดได้ระหว่างแบ็กเอนด์และคอมไพเลอร์เวอร์ชันต่างๆ
RngBitGenerator(algorithm, initial_state, shape)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
algorithm |
RandomAlgorithm |
อัลกอริทึม PRNG ที่จะใช้ |
initial_state |
XlaOp |
สถานะเริ่มต้นสำหรับอัลกอริทึม PRNG |
shape |
Shape |
รูปร่างเอาต์พุตสำหรับข้อมูลที่สร้างขึ้น |
ค่าที่ใช้ได้สำหรับ algorithm มีดังนี้
rng_default: อัลกอริทึมเฉพาะแบ็กเอนด์ที่มีข้อกำหนดด้านรูปร่างเฉพาะแบ็กเอนด์rng_three_fry: อัลกอริทึม PRNG ที่อิงตามตัวนับ ThreeFryinitial_stateรูปร่างคือu64[2]ที่มีค่าใดก็ได้ Salmon et al. SC 2011 เลขสุ่มแบบขนาน: ง่ายเหมือนนับ 1, 2, 3rng_philox: อัลกอริทึม Philox เพื่อสร้างตัวเลขสุ่มแบบคู่ขนาน รูปร่างของinitial_stateคือu64[3]ที่มีค่าใดก็ได้ Salmon et al. SC 2011 เลขสุ่มแบบขนาน: ง่ายเหมือนนับ 1, 2, 3
ดูข้อมูล StableHLO ได้ที่ StableHLO - rng_bit_generator
RngGetAndUpdateState
ดูเพิ่มเติม
HloInstruction::CreateRngGetAndUpdateState
API ของRngการดำเนินการต่างๆ จะแยกย่อยเป็นการดำเนินการ HLO ภายใน ซึ่งรวมถึงRngGetAndUpdateState
RngGetAndUpdateState ทำหน้าที่เป็นองค์ประกอบพื้นฐานใน HLO การดำเนินการนี้อาจปรากฏในข้อมูลการทิ้งของ HLO แต่ไม่ได้มีไว้ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
ทรงกลม
ดูเพิ่มเติม
XlaBuilder::Round
การปัดเศษทีละองค์ประกอบ โดยปัดเศษค่าที่เท่ากันให้ห่างจากศูนย์
Round(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
RoundNearestAfz
ดูเพิ่มเติม
XlaBuilder::RoundNearestAfz
ดำเนินการปัดเศษตามองค์ประกอบเข้าหาจำนวนเต็มที่ใกล้ที่สุด โดยปัดเศษออกจาก 0
RoundNearestAfz(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - round_nearest_afz
RoundNearestEven
ดูเพิ่มเติม
XlaBuilder::RoundNearestEven
การปัดเศษทีละองค์ประกอบ โดยปัดเศษเท่ากันให้เป็นจำนวนคู่ที่ใกล้ที่สุด
RoundNearestEven(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - round_nearest_even
Rsqrt
ดูเพิ่มเติม
XlaBuilder::Rsqrt
ส่วนกลับแบบทีละองค์ประกอบของการดำเนินการรากที่สอง x -> 1.0 / sqrt(x)
Rsqrt(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Rsqrt ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Rsqrt(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - rsqrt
สแกน
ดูเพิ่มเติม
XlaBuilder::Scan
ใช้ฟังก์ชันการลดกับอาร์เรย์ในมิติข้อมูลที่กําหนด ซึ่งจะสร้าง สถานะสุดท้ายและอาร์เรย์ของค่ากลาง
Scan(inputs..., inits..., to_apply, scan_dimension,
is_reverse, is_associative)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
inputs |
ลำดับของ m XlaOp |
อาร์เรย์ที่จะสแกน |
inits |
ลำดับของ k XlaOp |
การถือบอลครั้งแรก |
to_apply |
XlaComputation |
การคำนวณประเภท i_0, ..., i_{m-1}, c_0, ..., c_{k-1} -> (o_0, ..., o_{n-1}, c'_0, ..., c'_{k-1}) |
scan_dimension |
int64 |
มิติข้อมูลที่จะสแกน |
is_reverse |
bool |
หากเป็นจริง ให้สแกนในลำดับย้อนกลับ |
is_associative |
bool (ไตรรัฐ) |
หากเป็นจริง การดำเนินการจะเป็นการเชื่อมโยง |
ฟังก์ชัน to_apply จะใช้กับองค์ประกอบใน inputs ตามลำดับตาม scan_dimension หาก is_reverse เป็นเท็จ ระบบจะประมวลผลองค์ประกอบตามลำดับ 0 ถึง N-1 โดยที่ N คือขนาดของ scan_dimension หาก is_reverse เป็น
จริง ระบบจะประมวลผลองค์ประกอบจาก N-1 ลงไปจนถึง 0
ฟังก์ชัน to_apply ใช้ตัวถูกดำเนินการ m + k รายการ
mองค์ประกอบปัจจุบันจากinputskมีค่าจากขั้นตอนก่อนหน้า (หรือinitsสำหรับองค์ประกอบแรก)
to_apply ฟังก์ชันจะแสดงผลทูเพิลของค่า n + k ดังนี้
nองค์ประกอบของoutputskมูลค่าใหม่ที่ยกมา
การดำเนินการสแกนจะสร้างทูเพิลของค่า n + k ดังนี้
nอาร์เรย์เอาต์พุตที่มีค่าเอาต์พุตสำหรับแต่ละขั้นตอนkสุดท้ายจะมีค่าหลังจากประมวลผลองค์ประกอบทั้งหมด
ประเภทของmอินพุตต้องตรงกับประเภทของmพารามิเตอร์แรกของ
to_applyที่มีมิติข้อมูลการสแกนเพิ่มเติม ประเภทของเอาต์พุต n ต้องตรงกับประเภทของค่าที่ส่งคืน n แรกของ to_apply โดยมีมิติข้อมูลการสแกนเพิ่มเติม มิติข้อมูลการสแกนเพิ่มเติมในอินพุตและเอาต์พุตทั้งหมดต้องมีขนาดเท่ากัน N ประเภทของพารามิเตอร์ k สุดท้ายและค่าที่ส่งคืนของ
to_apply รวมถึง k ใน init ต้องตรงกัน
ตัวอย่างเช่น (m, n, k == 1, N == 3) สำหรับการส่งต่อเริ่มต้น i ให้ป้อน [a, b, c], ฟังก์ชัน f(x, c) -> (y, c') และ scan_dimension=0, is_reverse=false
- ขั้นตอนที่ 0:
f(a, i) -> (y0, c0) - ขั้นตอนที่ 1:
f(b, c0) -> (y1, c1) - ขั้นตอนที่ 2:
f(c, c1) -> (y2, c2)
เอาต์พุตของ Scan คือ ([y0, y1, y2], c2)
แผนภูมิกระจาย
ดูเพิ่มเติม
XlaBuilder::Scatter
การดำเนินการกระจาย XLA จะสร้างลำดับผลลัพธ์ซึ่งเป็นค่า
ของอาร์เรย์อินพุต operands โดยมีการอัปเดตหลายชิ้น (ที่ดัชนีที่ระบุโดย
scatter_indices) ด้วยลำดับค่าใน updates โดยใช้
update_computation
Scatter(operands..., scatter_indices, updates..., update_computation,
dimension_numbers, indices_are_sorted, unique_indices)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
ลำดับของ N XlaOp |
อาร์เรย์ N ประเภท T_0, ..., T_N ที่จะกระจาย |
scatter_indices |
XlaOp |
อาร์เรย์ที่มีดัชนีเริ่มต้นของชิ้นส่วนที่ต้องกระจาย |
updates |
ลำดับของ N XlaOp |
อาร์เรย์ N ประเภท T_0, ..., T_N updates[i] มีค่าที่ต้องใช้สำหรับการกระจาย operands[i] |
update_computation |
XlaComputation |
การคำนวณที่จะใช้ในการรวมค่าที่มีอยู่ในอาร์เรย์อินพุตและการอัปเดตระหว่างการกระจาย การคำนวณนี้ควรเป็นประเภท T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N) |
index_vector_dim |
int64 |
มิติข้อมูลใน scatter_indices ที่มีดัชนีเริ่มต้น |
update_window_dims |
ArraySlice<int64> |
ชุดมิติข้อมูลในupdatesรูปร่างที่เป็นมิติข้อมูลระดับหน้าต่าง |
inserted_window_dims |
ArraySlice<int64> |
ชุดขนาดหน้าต่างที่ต้องแทรกลงในรูปร่าง updates |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
แผนที่มิติข้อมูลจากดัชนีการกระจายไปยังพื้นที่ดัชนีตัวถูกดำเนินการ ระบบจะตีความอาร์เรย์นี้เป็นการแมป i กับ scatter_dims_to_operand_dims[i] โดยต้องเป็นแบบหนึ่งต่อหนึ่งและครบถ้วน |
dimension_number |
ScatterDimensionNumbers |
หมายเลขมิติข้อมูลสำหรับการดำเนินการกระจาย |
indices_are_sorted |
bool |
ผู้โทรรับประกันว่าดัชนีจะได้รับการจัดเรียงหรือไม่ |
unique_indices |
bool |
ผู้โทรรับประกันว่าดัชนีจะไม่ซ้ำกันหรือไม่ |
สถานที่:
- N ต้องมากกว่าหรือเท่ากับ 1
operands[0], ...,operands[N-1] ต้องมีมิติข้อมูลเดียวกันทั้งหมดupdates[0], ...,updates[N-1] ต้องมีมิติข้อมูลเดียวกันทั้งหมด- หาก
N = 1Collate(T)คือT - หาก
N > 1,Collate(T_0, ..., T_N)เป็นทูเพิลขององค์ประกอบNประเภทT
หาก index_vector_dim เท่ากับ scatter_indices.rank เราจะถือว่า scatter_indices มีมิติข้อมูล1 ต่อท้าย
เรากำหนด update_scatter_dims ประเภท ArraySlice<int64> เป็นชุดของ
มิติข้อมูลในรูปร่าง updates ที่ไม่ได้อยู่ใน update_window_dims โดยเรียงจากน้อยไปมาก
อาร์กิวเมนต์ของฟังก์ชัน scatter ควรเป็นไปตามข้อจำกัดต่อไปนี้
อาร์เรย์
updatesแต่ละรายการต้องมีมิติข้อมูลupdate_window_dims.size + scatter_indices.rank - 1ขอบเขตของมิติข้อมูล
iในอาร์เรย์updatesแต่ละรายการต้องเป็นไปตามข้อกำหนดต่อไปนี้- หาก
iอยู่ในupdate_window_dims(เช่น เท่ากับupdate_window_dims[k] สำหรับkบางรายการ) ขอบเขตของมิติข้อมูลiในupdatesต้องไม่เกินขอบเขตที่สอดคล้องกันของoperandหลังจาก พิจารณาinserted_window_dimsแล้ว (เช่นadjusted_window_bounds[k] โดยที่adjusted_window_boundsมี ขอบเขตของoperandโดยนำขอบเขตที่ดัชนีinserted_window_dimsออก) - หาก
iอยู่ในupdate_scatter_dims(เช่น เท่ากับupdate_scatter_dims[k] สำหรับkบางรายการ) ขอบเขตของมิติข้อมูลiในupdatesต้องเท่ากับขอบเขตที่สอดคล้องกันของscatter_indicesโดยข้ามindex_vector_dim(เช่นscatter_indices.shape.dims[k] หากk<index_vector_dimและscatter_indices.shape.dims[k+1] ในกรณีอื่นๆ)
- หาก
update_window_dimsต้องเรียงตามลำดับจากน้อยไปมาก ต้องไม่มีหมายเลขมิติข้อมูลที่ซ้ำกัน และต้องอยู่ในช่วง[0, updates.rank)inserted_window_dimsต้องเรียงตามลำดับจากน้อยไปมาก ต้องไม่มีหมายเลขมิติข้อมูลที่ซ้ำกัน และต้องอยู่ในช่วง[0, operand.rank)operand.rankต้องเท่ากับผลรวมของupdate_window_dims.sizeและinserted_window_dims.sizescatter_dims_to_operand_dims.sizeต้องเท่ากับscatter_indices.shape.dims[index_vector_dim] และค่าต้องอยู่ใน ช่วง[0, operand.rank)
สำหรับดัชนี U ที่กำหนดในอาร์เรย์ updates แต่ละรายการ ดัชนี I ที่สอดคล้องกันใน
อาร์เรย์ operands ที่สอดคล้องกันซึ่งต้องใช้การอัปเดตนี้จะ
คำนวณได้ดังนี้
- กำหนดให้
G= {U[k] forkinupdate_scatter_dims} ใช้Gเพื่อค้นหา เวกเตอร์ดัชนีSในอาร์เรย์scatter_indicesโดยที่S[i] =scatter_indices[Combine(G,i)] โดยที่ Combine(A, b) จะแทรก b ที่ ตำแหน่งindex_vector_dimลงใน A - สร้างดัชนี
Sinลงในoperandโดยใช้Sด้วยการกระจายSโดยใช้แมปscatter_dims_to_operand_dimsในรูปแบบที่เป็นทางการมากขึ้นSin[scatter_dims_to_operand_dims[k]] =S[k] ifk<scatter_dims_to_operand_dims.size.Sin[_] =0มิเช่นนั้น
- สร้างดัชนี
Winลงในอาร์เรย์operandsแต่ละรายการโดยการกระจาย ดัชนีที่update_window_dimsในUตามinserted_window_dimsในรูปแบบที่เป็นทางการมากขึ้นWin[window_dims_to_operand_dims(k)] =U[k] ifkis inupdate_window_dims, wherewindow_dims_to_operand_dimsis the monotonic function with domain [0,update_window_dims.size) and range [0,operand.rank) \inserted_window_dims. (เช่น หากupdate_window_dims.sizeคือ4,operand.rankคือ6และinserted_window_dimsคือ {0,2} แล้วwindow_dims_to_operand_dimsคือ {0→1,1→3,2→4,3→5})Win[_] =0มิเช่นนั้น
IคือWin+Sinโดยที่ + คือการบวกแบบอิงตามองค์ประกอบ
โดยสรุปแล้ว การดำเนินการกระจายสามารถกำหนดได้ดังนี้
- เริ่มต้น
outputด้วยoperandsกล่าวคือ สำหรับดัชนีทั้งหมดJสำหรับดัชนีทั้งหมดOในอาร์เรย์operands[J]:
output[J][O] =operands[J][O] - สำหรับทุกดัชนี
Uในอาร์เรย์updates[J] และดัชนีที่สอดคล้องกันOในอาร์เรย์operand[J] หากOเป็นดัชนีที่ถูกต้องสำหรับoutput:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
ลำดับที่ใช้ในการอัปเดตจะไม่มีการกำหนด ดังนั้นเมื่อดัชนีหลายรายการใน updates อ้างอิงถึงดัชนีเดียวกันใน operands ค่าที่สอดคล้องกันใน output จะไม่มีการกำหนด
โปรดทราบว่าพารามิเตอร์แรกที่ส่งไปยัง update_computation จะเป็นค่าปัจจุบันจากอาร์เรย์ output เสมอ และพารามิเตอร์ที่สองจะเป็นค่าจากอาร์เรย์ updates เสมอ ซึ่งสำคัญอย่างยิ่งสำหรับกรณีที่ update_computationไม่สลับที่
หากตั้งค่า indices_are_sorted เป็น "จริง" XLA จะถือว่าผู้ใช้ได้จัดเรียง scatter_indices (ตามลำดับจากน้อยไปมาก หลังจากกระจายค่าตาม scatter_dims_to_operand_dims) แล้ว หากไม่ได้ระบุไว้ ความหมายจะขึ้นอยู่กับการใช้งาน
หากตั้งค่า unique_indices เป็นจริง XLA จะถือว่าองค์ประกอบทั้งหมดที่กระจายอยู่มีค่าที่ไม่ซ้ำกัน ดังนั้น XLA จึงสามารถใช้การดำเนินการที่ไม่ใช่แบบอะตอมได้ หากตั้งค่า unique_indices เป็นจริงและดัชนีที่กระจายอยู่มีค่าที่ไม่ซ้ำกัน ความหมายจะขึ้นอยู่กับการใช้งาน
โดยทั่วไปแล้ว การดำเนินการ Scatter สามารถมองได้ว่าเป็นการดำเนินการผกผันของการดำเนินการ Gather กล่าวคือ การดำเนินการ Scatter จะอัปเดตองค์ประกอบในอินพุตที่ดึงมาโดย การดำเนินการ Gather ที่สอดคล้องกัน
ดูคำอธิบายอย่างไม่เป็นทางการและตัวอย่างโดยละเอียดได้ที่ส่วน "คำอธิบายอย่างไม่เป็นทางการ" ในGather
ดูข้อมูล StableHLO ได้ที่ StableHLO - scatter
Scatter - ตัวอย่าง 1 - StableHLO

ในรูปภาพด้านบน แต่ละแถวของตารางคือตัวอย่างของดัชนีการอัปเดต ตัวอย่าง มาดูทีละขั้นตอนจากซ้าย(อัปเดตดัชนี) ไปขวา(ดัชนีผลลัพธ์) กัน
อินพุต) input มีรูปร่าง S32[2,3,4,2] scatter_indices มีรูปร่าง
S64[2,2,3,2] updates มีรูปร่าง S32[2,2,3,1,2]
อัปเดตดัชนี) เป็นส่วนหนึ่งของอินพุตที่เราได้รับ update_window_dims:[3,4] ซึ่ง
บอกเราว่ามิติข้อมูลที่ 3 และ 4 ของ updates คือมิติข้อมูลหน้าต่าง ซึ่งไฮไลต์เป็นสีเหลือง
ซึ่งช่วยให้เราทราบว่า update_scatter_dims = [0,1,2]
อัปเดตดัชนีกระจาย) แสดง updated_scatter_dims ที่แยกออกมาสำหรับแต่ละรายการ
(ไม่ใช่สีเหลืองของคอลัมน์ดัชนีการอัปเดต)
ดัชนีเริ่มต้น) เมื่อดูที่scatter_indicesเทนเซอร์รูปภาพ เราจะเห็นว่าค่าจากขั้นตอนก่อนหน้า (อัปเดตดัชนีการกระจาย) จะบอกตำแหน่งของดัชนีเริ่มต้น จาก index_vector_dim เรายังทราบมิติข้อมูลของ starting_indices ที่มีดัชนีเริ่มต้น ซึ่งสำหรับ scatter_indices คือมิติข้อมูลที่ 3 ที่มีขนาด 2
ดัชนีเริ่มต้นแบบเต็ม) scatter_dims_to_operand_dims = [2,1] บอกเราว่าองค์ประกอบแรก
ของเวกเตอร์ดัชนีจะไปที่มิติข้อมูล 2 ของตัวถูกดำเนินการ องค์ประกอบที่ 2 ของเวกเตอร์ดัชนีจะไปที่มิติข้อมูล 1 ของตัวถูกดำเนินการ ระบบจะป้อนมิติข้อมูลตัวถูกดำเนินการที่เหลือ
ด้วย 0
ดัชนีการจัดกลุ่มแบบเต็ม) เราจะเห็นพื้นที่ที่ไฮไลต์สีม่วงแสดงในคอลัมน์นี้(ดัชนีการจัดกลุ่มแบบเต็ม), คอลัมน์ดัชนีการกระจายการอัปเดต และคอลัมน์ดัชนีการอัปเดต
ดัชนีหน้าต่างแบบเต็ม) คำนวณจาก update_window_dimensions [3,4]
ดัชนีผลลัพธ์) การเพิ่มดัชนีเริ่มต้นแบบเต็ม ดัชนีการจัดกลุ่มแบบเต็ม และดัชนีหน้าต่างแบบเต็มในเทนเซอร์ operand โปรดสังเกตว่าภูมิภาคที่ไฮไลต์สีเขียวสอดคล้องกับรูปที่ operand ด้วย แถวสุดท้ายจะถูกข้ามเนื่องจากอยู่นอกเทนเซอร์ operand
เลือก
ดูเพิ่มเติม
XlaBuilder::Select
สร้างอาร์เรย์เอาต์พุตจากองค์ประกอบของอาร์เรย์อินพุต 2 รายการตาม ค่าของอาร์เรย์เพรดิเคต
Select(pred, on_true, on_false)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
pred |
XlaOp |
อาร์เรย์ของประเภท PRED |
on_true |
XlaOp |
อาร์เรย์ของประเภท T |
on_false |
XlaOp |
อาร์เรย์ของประเภท T |
อาร์เรย์ on_true และ on_false ต้องมีรูปร่างเดียวกัน ซึ่งเป็นรูปร่างของอาร์เรย์เอาต์พุตด้วย อาร์เรย์ pred ต้องมีมิติข้อมูลเดียวกับ
on_true และ on_false โดยมีประเภทองค์ประกอบเป็น PRED
สำหรับแต่ละองค์ประกอบ P ของ pred องค์ประกอบที่สอดคล้องกันของอาร์เรย์เอาต์พุตจะ
นำมาจาก on_true หากค่าของ P คือ true และจาก on_false หากค่าของ P คือ false ในรูปแบบที่จำกัดของการออกอากาศ
pred อาจเป็นสเกลาร์ของประเภท PRED ในกรณีนี้ อาร์เรย์เอาต์พุตจะนำมาจาก
on_true ทั้งหมดหาก pred คือ true และจาก on_false หาก pred คือ
false
ตัวอย่างที่มี pred ที่ไม่ใช่สเกลาร์
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
ตัวอย่างที่มีสเกลาร์ pred
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
ระบบรองรับการเลือกระหว่างทูเพิล ทูเพิลถือเป็นประเภทสเกลาร์
สำหรับวัตถุประสงค์นี้ หาก on_true และ on_false เป็นทูเพิล (ซึ่งต้องมีรูปร่างเดียวกัน) pred ต้องเป็นสเกลาร์ประเภท PRED
ดูข้อมูล StableHLO ได้ที่ StableHLO - select
SelectAndScatter
ดูเพิ่มเติม
XlaBuilder::SelectAndScatter
การดำเนินการนี้ถือเป็นการดำเนินการแบบคอมโพสิตที่คำนวณ ReduceWindow ในอาร์เรย์ operand ก่อนเพื่อเลือกองค์ประกอบจากแต่ละหน้าต่าง แล้วกระจายอาร์เรย์ source ไปยังดัชนีขององค์ประกอบที่เลือกเพื่อสร้างอาร์เรย์เอาต์พุตที่มีรูปร่างเหมือนกับอาร์เรย์ตัวถูกดำเนินการ ฟังก์ชันไบนารี
select ใช้เพื่อเลือกองค์ประกอบจากแต่ละหน้าต่างโดยการนำไปใช้
ในแต่ละหน้าต่าง และจะเรียกใช้กับพร็อพเพอร์ตี้ที่เวกเตอร์ดัชนีของพารามิเตอร์แรก
เล็กกว่าเวกเตอร์ดัชนีของพารามิเตอร์ที่สองตามลำดับพจนานุกรม
ฟังก์ชัน select จะแสดงผล true หากเลือกพารามิเตอร์แรก และแสดงผล false หากเลือกพารามิเตอร์ที่สอง และฟังก์ชันต้องมีคุณสมบัติการถ่ายทอด (กล่าวคือ หาก select(a, b) และ select(b, c) เป็น true แล้ว select(a, c) ก็จะเป็น true ด้วย) เพื่อให้องค์ประกอบที่เลือกไม่ขึ้นอยู่กับลำดับขององค์ประกอบที่ข้ามสำหรับหน้าต่างที่กำหนด
ฟังก์ชัน scatter จะใช้กับดัชนีที่เลือกแต่ละรายการในอาร์เรย์เอาต์พุต โดยจะ
ใช้พารามิเตอร์สเกลาร์ 2 รายการ ได้แก่
- ค่าปัจจุบันที่ดัชนีที่เลือกในอาร์เรย์เอาต์พุต
- ค่ากระจัดจาก
sourceที่ใช้กับดัชนีที่เลือก
โดยจะรวมพารามิเตอร์ทั้ง 2 รายการและแสดงผลค่าสเกลาร์ที่ใช้เพื่ออัปเดต
ค่าที่ดัชนีที่เลือกในอาร์เรย์เอาต์พุต ในตอนแรก ดัชนีทั้งหมดของอาร์เรย์เอาต์พุตจะตั้งค่าเป็น init_value
อาร์เรย์เอาต์พุตมีรูปร่างเหมือนกับอาร์เรย์ operand และอาร์เรย์ source ต้องมีรูปร่างเหมือนกับผลลัพธ์ของการใช้การดำเนินการ ReduceWindow กับอาร์เรย์ operand คุณใช้ SelectAndScatter เพื่อส่งต่อค่าการไล่ระดับสีสำหรับเลเยอร์การรวมในโครงข่ายระบบประสาทเทียมได้
SelectAndScatter(operand, select, window_dimensions, window_strides, padding,
source, init_value, scatter)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์ของประเภท T ที่หน้าต่างเลื่อน |
select
|
XlaComputation
|
การคำนวณไบนารีประเภท T, T
-> PRED เพื่อใช้กับองค์ประกอบทั้งหมดในแต่ละหน้าต่าง แสดงผล true หากเลือกพารามิเตอร์แรก และแสดงผล false หากเลือกพารามิเตอร์ที่สอง |
window_dimensions
|
ArraySlice<int64>
|
อาร์เรย์ของจำนวนเต็มสำหรับค่ามิติข้อมูล หน้าต่าง |
window_strides
|
ArraySlice<int64>
|
อาร์เรย์ของจำนวนเต็มสำหรับค่า ระยะก้าวกระโดดของหน้าต่าง |
padding
|
Padding
|
ประเภทการเพิ่มระยะขอบสำหรับหน้าต่าง (Padding::kSame หรือ Padding::kValid) |
source
|
XlaOp
|
อาร์เรย์ประเภท T ที่มีค่า ที่จะกระจาย |
init_value
|
XlaOp
|
ค่าสเกลาร์ของประเภท T สำหรับ ค่าเริ่มต้นของอาร์เรย์ เอาต์พุต |
scatter
|
XlaComputation
|
การคำนวณไบนารีประเภท T, T
-> T เพื่อใช้แต่ละองค์ประกอบแหล่งที่มาของ Scatter กับองค์ประกอบปลายทาง |
รูปภาพด้านล่างแสดงตัวอย่างการใช้ SelectAndScatter โดยมีฟังก์ชัน select
คำนวณค่าสูงสุดในพารามิเตอร์ โปรดทราบว่าเมื่อหน้าต่างซ้อนทับกัน ดังในรูปที่ (2) ด้านล่าง หน้าต่างต่างๆ อาจเลือกดัชนีของอาร์เรย์ operand หลายครั้ง ในรูปภาพ องค์ประกอบที่มีค่า 9 จะได้รับการเลือกโดยทั้งหน้าต่างด้านบน (สีน้ำเงินและสีแดง) และฟังก์ชันการบวกแบบไบนารี scatter จะสร้างองค์ประกอบเอาต์พุตที่มีค่า 8 (2 + 6)
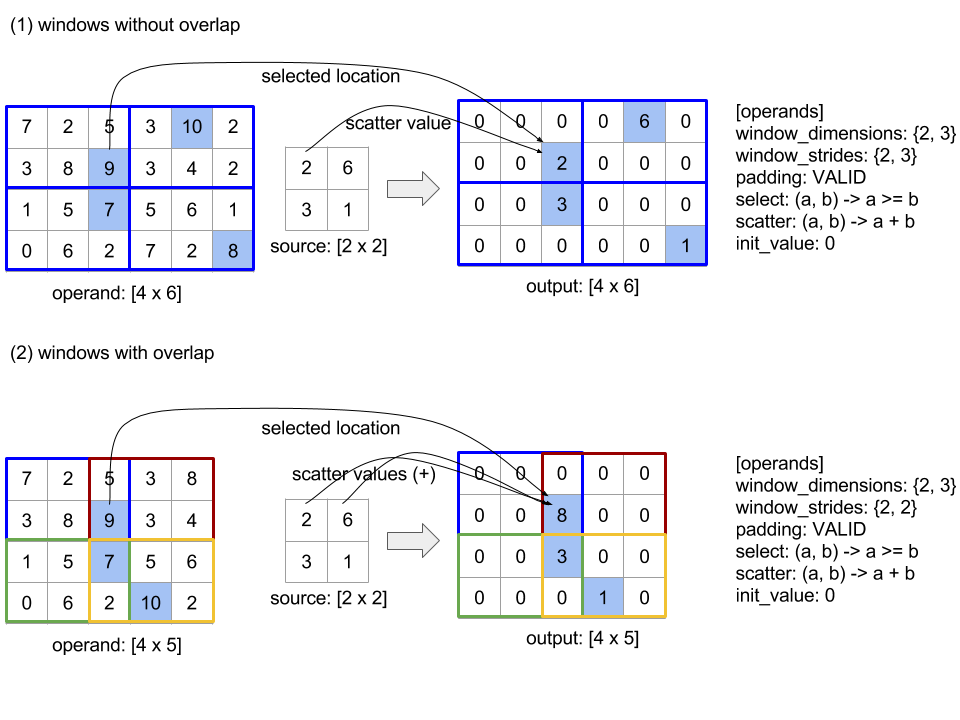
ลำดับการประเมินฟังก์ชัน scatter เป็นแบบกำหนดเองและอาจไม่แน่นอน ดังนั้นฟังก์ชัน scatter จึงไม่ควรไวต่อการเชื่อมโยงใหม่มากเกินไป ดูรายละเอียดเพิ่มเติมได้ที่การสนทนาเกี่ยวกับการเชื่อมโยงในบริบทของ Reduce
ดูข้อมูล StableHLO ได้ที่ StableHLO - select_and_scatter
ส่ง
ดูเพิ่มเติม
XlaBuilder::Send
Send, SendWithTokens และ SendToHost เป็นการดำเนินการที่ทำหน้าที่เป็น
องค์ประกอบพื้นฐานของการสื่อสารใน HLO โดยปกติแล้วการดำเนินการเหล่านี้จะปรากฏในการดัมพ์ HLO เป็นส่วนหนึ่ง
ของการรับ/ส่งข้อมูลระดับต่ำหรือการโอนข้ามอุปกรณ์ แต่ไม่ได้มีไว้
ให้ผู้ใช้ปลายทางสร้างขึ้นด้วยตนเอง
Send(operand, handle)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ข้อมูลที่จะส่ง (อาร์เรย์ของประเภท T) |
handle |
ChannelHandle |
ตัวระบุที่ไม่ซ้ำกันสำหรับคู่การส่ง/รับแต่ละคู่ |
ส่งข้อมูลตัวถูกดำเนินการที่ระบุไปยังคำสั่ง Recv ในการคำนวณอื่นที่ใช้แฮนเดิลช่องเดียวกัน ไม่แสดงผลข้อมูลใดๆ
เช่นเดียวกับการดำเนินการ Recv ไคลเอ็นต์ API ของการดำเนินการ Send
แสดงถึงการสื่อสารแบบซิงโครนัส และจะแยกออกเป็นคำสั่ง HLO 2 รายการ (Send และ SendDone) ภายในเพื่อเปิดใช้การโอนข้อมูลแบบอะซิงโครนัส ดู
เพิ่มเติม
HloInstruction::CreateSend และ HloInstruction::CreateSendDone
Send(HloInstruction operand, int64 channel_id)
เริ่มการโอนตัวถูกดำเนินการแบบไม่พร้อมกันไปยังทรัพยากรที่จัดสรรโดยคำสั่ง Recv ที่มีรหัสแชแนลเดียวกัน ส่งคืนบริบทซึ่งใช้โดยSendDoneคำสั่งต่อไปนี้เพื่อรอให้การโอนข้อมูลเสร็จสมบูรณ์ บริบทคือ Tuple ของ {ตัวถูกดำเนินการ (รูปร่าง), ตัวระบุคำขอ
(U32)} และใช้ได้เฉพาะในคำสั่ง SendDone
ดูข้อมูล StableHLO ได้ที่ StableHLO - send
SendDone
ดูเพิ่มเติม
HloInstruction::CreateSendDone
SendDone(HloInstruction context)
เมื่อได้รับบริบทที่สร้างขึ้นจากคำสั่ง Send แล้ว ฟังก์ชันนี้จะรอให้การโอนข้อมูลเสร็จสมบูรณ์
คำสั่งไม่แสดงข้อมูลใดๆ
การกำหนดเวลาคำสั่งของช่อง
ลำดับการดำเนินการของคำสั่ง 4 รายการสำหรับแต่ละช่อง (Recv, RecvDone,
Send, SendDone) เป็นดังนี้
Recvเกิดขึ้นก่อนSendSendเกิดขึ้นก่อนRecvDoneRecvเกิดขึ้นก่อนRecvDoneSendเกิดขึ้นก่อนSendDone
เมื่อคอมไพเลอร์แบ็กเอนด์สร้างกำหนดการเชิงเส้นสำหรับการคำนวณแต่ละรายการที่ สื่อสารผ่านคำสั่งของช่อง จะต้องไม่มีวงจรในการคำนวณ ตัวอย่างเช่น ตารางเวลาด้านล่างทำให้เกิดภาวะหยุดชะงัก
SetDimensionSize
ดูเพิ่มเติม
XlaBuilder::SetDimensionSize
ตั้งค่าขนาดแบบไดนามิกของมิติข้อมูลที่ระบุของ XlaOp ตัวถูกดำเนินการต้องมีรูปร่างเป็นอาร์เรย์
SetDimensionSize(operand, val, dimension)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
val |
XlaOp |
int32 ที่แสดงขนาดแบบไดนามิกของรันไทม์ |
dimension
|
int64
|
ค่าในช่วง [0, n) ที่ระบุ
มิติข้อมูล |
ส่งผ่านตัวถูกดำเนินการเป็นผลลัพธ์ โดยมีมิติข้อมูลแบบไดนามิกที่คอมไพเลอร์ติดตาม
การดำเนินการลดที่ดาวน์สตรีมจะไม่สนใจค่าที่เพิ่ม
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
ShiftLeft
ดูเพิ่มเติม
XlaBuilder::ShiftLeft
ดำเนินการเลื่อนบิตไปทางซ้ายทีละองค์ประกอบใน lhs ตามจำนวนบิต rhs
ShiftLeft(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
ShiftLeft มีตัวแปรอื่นที่รองรับการออกอากาศแบบหลายมิติ
ShiftLeft(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - shift_left
ShiftRightArithmetic
ดูเพิ่มเติม
XlaBuilder::ShiftRightArithmetic
ดำเนินการเลื่อนบิตไปทางขวาแบบเลขคณิตทีละองค์ประกอบใน lhs ตามจำนวนบิตใน rhs
ShiftRightArithmetic(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
ShiftRightArithmetic มีรูปแบบอื่นที่รองรับการออกอากาศแบบหลายมิติ
ShiftRightArithmetic(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - shift_right_arithmetic
ShiftRightLogical
ดูเพิ่มเติม
XlaBuilder::ShiftRightLogical
ดำเนินการเลื่อนบิตทางตรรกะไปทางขวาแบบทีละองค์ประกอบใน lhs ตามจำนวนบิต rhs
ShiftRightLogical(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
ShiftRightLogical มีตัวแปรทางเลือกที่รองรับการออกอากาศแบบหลายมิติ
ShiftRightLogical(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - shift_right_logical
เซ็น
ดูเพิ่มเติม
XlaBuilder::Sign
Sign(operand) การดำเนินการเครื่องหมายตามองค์ประกอบ x -> sgn(x) โดยที่
\[\text{sgn}(x) = \begin{cases} -1 & x < 0\\ -0 & x = -0\\ NaN & x = NaN\\ +0 & x = +0\\ 1 & x > 0 \end{cases}\]
โดยใช้ตัวดำเนินการเปรียบเทียบของประเภทองค์ประกอบ operand
Sign(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ดูข้อมูล StableHLO ได้ที่ StableHLO - sign
Sin
Sin(operand) ฟังก์ชันไซน์แบบองค์ประกอบต่อองค์ประกอบ x -> sin(x)
ดูเพิ่มเติม
XlaBuilder::Sin
Sin(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Sin ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Sin(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - sine
Slice
ดูเพิ่มเติม
XlaBuilder::Slice
การแบ่งส่วนจะดึงอาร์เรย์ย่อยจากอาร์เรย์อินพุต อาร์เรย์ย่อยมีจำนวนมิติข้อมูลเท่ากับอินพุตและมีค่าภายในกรอบล้อมรอบภายในอาร์เรย์อินพุต โดยมิติข้อมูลและดัชนีของกรอบล้อมรอบจะกำหนดเป็นอาร์กิวเมนต์ในการดำเนินการแบ่งส่วน
Slice(operand, start_indices, limit_indices, strides)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ N มิติของประเภท T |
start_indices
|
ArraySlice<int64>
|
รายการจำนวนเต็ม N ที่มี ดัชนีเริ่มต้นของสไลซ์สำหรับ แต่ละมิติ ค่าต้องมากกว่าหรือเท่ากับ 0 |
limit_indices
|
ArraySlice<int64>
|
รายการจำนวนเต็ม N ที่มี
ดัชนีสิ้นสุด (ไม่รวม)
สำหรับสไลซ์ของแต่ละมิติข้อมูล ค่าแต่ละค่าต้องมากกว่าหรือเท่ากับค่า start_indices ที่เกี่ยวข้องสำหรับมิติข้อมูล และน้อยกว่าหรือเท่ากับขนาดของมิติข้อมูล |
strides
|
ArraySlice<int64>
|
รายการของจำนวนเต็ม N ที่กำหนด
ระยะก้าวกระโดดของอินพุตของ Slice การแบ่งส่วนจะเลือกองค์ประกอบ strides[d] ทุกรายการในมิติข้อมูล d |
ตัวอย่าง 1 มิติ
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4})
// Result: {2.0, 3.0}
ตัวอย่าง 2 มิติ
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3})
// Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
ดูข้อมูล StableHLO ได้ที่ StableHLO - slice
จัดเรียง
ดูเพิ่มเติม
XlaBuilder::Sort
Sort(operands, comparator, dimension, is_stable)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
ArraySlice<XlaOp> |
ตัวถูกดำเนินการที่จะจัดเรียง |
comparator |
XlaComputation |
การคำนวณตัวเปรียบเทียบที่จะใช้ |
dimension |
int64 |
มิติข้อมูลที่จะจัดเรียง |
is_stable |
bool |
ดูว่าจะใช้การจัดเรียงที่เสถียรหรือไม่ |
หากระบุตัวถูกดำเนินการเพียงตัวเดียว
หากตัวถูกดำเนินการเป็น Tensor 1 มิติ (อาร์เรย์) ผลลัพธ์จะเป็นอาร์เรย์ที่จัดเรียงแล้ว หากต้องการจัดเรียงอาร์เรย์จากน้อยไปมาก ตัวเปรียบเทียบ ควรทำการเปรียบเทียบแบบน้อยกว่า กล่าวอย่างเป็นทางการคือ หลังจากจัดเรียงอาร์เรย์แล้ว จะถือว่าใช้ได้กับตำแหน่งดัชนีทั้งหมด
i, jที่มีi < jซึ่งเป็นcomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseหรือcomparator(value[i], value[j]) = trueหากตัวถูกดำเนินการมีมิติข้อมูลมากกว่า ระบบจะจัดเรียงตัวถูกดำเนินการตามมิติข้อมูลที่ระบุ ตัวอย่างเช่น สำหรับเทนเซอร์ 2 มิติ (เมทริกซ์) ค่ามิติข้อมูล
0จะจัดเรียงแต่ละคอลัมน์แยกกัน และค่ามิติข้อมูล1จะจัดเรียงแต่ละแถวแยกกัน หากไม่ได้ระบุหมายเลขมิติข้อมูล ระบบจะเลือกมิติข้อมูลสุดท้ายโดยค่าเริ่มต้น สําหรับมิติข้อมูล ที่จัดเรียง ระบบจะใช้ลําดับการจัดเรียงเดียวกันกับในกรณี 1 มิติ
หากระบุตัวถูกดำเนินการ n > 1
ตัวถูกดำเนินการทั้งหมดของ
nต้องเป็นเทนเซอร์ที่มีมิติข้อมูลเดียวกัน ประเภทองค์ประกอบ ของเทนเซอร์อาจแตกต่างกันระบบจะจัดเรียงตัวถูกดำเนินการทั้งหมดพร้อมกัน ไม่ใช่แยกกัน ในเชิงแนวคิด ตัวถูกดำเนินการ จะถือว่าเป็นทูเพิล เมื่อตรวจสอบว่าต้องสลับองค์ประกอบของตัวถูกดำเนินการแต่ละรายการที่ตำแหน่งดัชนี
iและjหรือไม่ ระบบจะเรียกใช้ตัวเปรียบเทียบด้วยพารามิเตอร์สเกลาร์2 * nโดยที่พารามิเตอร์2 * kสอดคล้องกับค่าที่ ตำแหน่งiจากตัวถูกดำเนินการk-thและพารามิเตอร์2 * k + 1สอดคล้องกับ ค่าที่ตำแหน่งjจากตัวถูกดำเนินการk-thโดยปกติแล้ว ตัวเปรียบเทียบ จะเปรียบเทียบพารามิเตอร์2 * kและ2 * k + 1กับพารามิเตอร์อื่นๆ และ อาจใช้คู่พารามิเตอร์อื่นๆ เป็นตัวตัดสินผลลัพธ์คือทูเพิลที่ประกอบด้วยตัวถูกดำเนินการตามลำดับที่เรียงแล้ว (ตามมิติข้อมูลที่ระบุ ดังที่กล่าวไว้ข้างต้น) ตัวถูกดำเนินการ
i-thของทูเพิลจะสอดคล้องกับตัวถูกดำเนินการi-thของ Sort
เช่น หากมีตัวถูกดำเนินการ 3 รายการ ได้แก่ operand0 = [3, 1],
operand1 = [42, 50], operand2 = [-3.0, 1.1] และตัวเปรียบเทียบจะเปรียบเทียบ
เฉพาะค่าของ operand0 กับน้อยกว่า ผลลัพธ์ของการจัดเรียงจะเป็น
ทูเพิล ([1, 3], [50, 42], [1.1, -3.0])
หากตั้งค่า is_stable เป็นจริง ระบบจะรับประกันว่าการจัดเรียงจะเสถียร นั่นคือ หากมีองค์ประกอบที่ตัวเปรียบเทียบถือว่าเท่ากัน ระบบจะรักษาลำดับสัมพัทธ์ของค่าที่เท่ากันไว้ องค์ประกอบ 2 รายการ e1 และ e2 จะเท่ากันก็ต่อเมื่อ comparator(e1, e2) = comparator(e2, e1) = false โดยค่าเริ่มต้น ระบบจะตั้งค่า is_stable เป็น false
ดูข้อมูล StableHLO ได้ที่ StableHLO - sort
Sqrt
ดูเพิ่มเติม
XlaBuilder::Sqrt
การดำเนินการรากที่สองแบบทีละองค์ประกอบ x -> sqrt(x)
Sqrt(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Sqrt ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Sqrt(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - sqrt
ย่อย
ดูเพิ่มเติม
XlaBuilder::Sub
ดำเนินการลบแบบทีละองค์ประกอบของ lhs และ rhs
Sub(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
สำหรับ Sub จะมีตัวเลือกอื่นที่รองรับการออกอากาศแบบหลายมิติ
Sub(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - subtract
แทน
ดูเพิ่มเติม
XlaBuilder::Tan
แทนเจนต์แบบทีละองค์ประกอบ x -> tan(x)
Tan(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Tan ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Tan(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - tan
Tanh
ดูเพิ่มเติม
XlaBuilder::Tanh
ไฮเพอร์โบลิกแทนเจนต์แบบองค์ประกอบต่อองค์ประกอบ x -> tanh(x)
Tanh(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
นอกจากนี้ Tanh ยังรองรับอาร์กิวเมนต์ result_accuracy ที่ไม่บังคับด้วย
Tanh(operand, result_accuracy)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
result_accuracy
|
ไม่บังคับ ResultAccuracy
|
ประเภทความแม่นยำที่ผู้ใช้ขอได้สำหรับ การดำเนินการแบบเอกภาคที่มีการ ใช้งานหลายรายการ |
ดูข้อมูลเพิ่มเติมเกี่ยวกับ result_accuracy ได้ที่
ความถูกต้องของผลลัพธ์
ดูข้อมูล StableHLO ได้ที่ StableHLO - tanh
TopK
ดูเพิ่มเติม
XlaBuilder::TopK
TopK ค้นหาค่าและดัชนีขององค์ประกอบที่ใหญ่ที่สุดหรือเล็กที่สุด k สำหรับ
มิติข้อมูลสุดท้ายของเทนเซอร์ที่กำหนด
TopK(operand, k, largest)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
เทนเซอร์ที่จะดึงองค์ประกอบ k อันดับแรก
Tensor ต้องมีมิติข้อมูลมากกว่าหรือเท่ากับหนึ่งมิติ ขนาดของมิติข้อมูลสุดท้ายของ
เทนเซอร์ต้องมากกว่าหรือเท่ากับ k |
k |
int64 |
จำนวนองค์ประกอบที่จะดึงข้อมูล |
largest
|
bool
|
เลือกว่าจะดึงองค์ประกอบ k
ที่ใหญ่ที่สุดหรือเล็กที่สุด |
สำหรับเทนเซอร์อินพุต 1 มิติ (อาร์เรย์) ฟังก์ชันนี้จะค้นหารายการที่ใหญ่ที่สุดหรือเล็กที่สุดkในอาร์เรย์ และแสดงผลทูเพิลของอาร์เรย์ 2 รายการ(values, indices) ดังนั้น
values[j] คือรายการที่ใหญ่/เล็กที่สุดอันดับที่ j ใน operand และดัชนีของรายการนี้คือ
indices[j]
สำหรับเทนเซอร์อินพุตที่มีมิติข้อมูลมากกว่า 1 รายการ จะคำนวณรายการ k อันดับแรก
ตามมิติข้อมูลสุดท้าย โดยจะรักษามิติข้อมูลอื่นๆ ทั้งหมด (แถว) ไว้ในเอาต์พุต
ดังนั้น สำหรับตัวถูกดำเนินการที่มีรูปร่าง [A, B, ..., P, Q] โดยที่ Q >= k เอาต์พุตจะเป็น
ทูเพิล (values, indices) โดยที่
values.shape = indices.shape = [A, B, ..., P, k]
หากองค์ประกอบ 2 รายการในแถวมีค่าเท่ากัน องค์ประกอบที่มีดัชนีต่ำกว่าจะปรากฏก่อน
เปลี่ยนคีย์
ดูการดำเนินการ tf.reshape ด้วย
Transpose(operand, permutation)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการที่จะเปลี่ยน |
permutation |
ArraySlice<int64> |
วิธีสลับมิติข้อมูล |
สลับมิติข้อมูลตัวถูกดำเนินการด้วยการสลับที่ระบุ
∀ i . 0 ≤ i < number of dimensions ⇒
input_dimensions[permutation[i]] = output_dimensions[i]
ซึ่งเหมือนกับ Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions))
ดูข้อมูล StableHLO ได้ที่ StableHLO - transpose
TriangularSolve
ดูเพิ่มเติม
XlaBuilder::TriangularSolve
แก้ระบบสมการเชิงเส้นที่มีเมทริกซ์สัมประสิทธิ์สามเหลี่ยมล่างหรือบน
โดยการแทนค่าไปข้างหน้าหรือย้อนกลับ การออกอากาศตามมิติชั้นนำ รูทีนนี้จะแก้ระบบเมทริกซ์ op(a) * x =
b หรือ x * op(a) = b สำหรับตัวแปร x เมื่อกำหนด a และ b โดยที่ op(a)
คือ op(a) = a หรือ op(a) = Transpose(a) หรือ
op(a) = Conj(Transpose(a))
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
a
|
XlaOp
|
อาร์เรย์ 2 มิติของจำนวนเชิงซ้อนหรือประเภทจุดลอยตัวที่มีรูปร่าง [..., M,
M] |
b
|
XlaOp
|
อาร์เรย์ 2 มิติประเภทเดียวกัน
ที่มีรูปร่าง [..., M, K] หาก left_side เป็น
จริง [..., K, M] มิฉะนั้น |
left_side
|
bool
|
ระบุว่าจะแก้ระบบของรูปแบบ op(a) * x = b (true) หรือ x *
op(a) = b (false) |
lower
|
bool
|
ว่าจะใช้สามเหลี่ยมด้านบนหรือด้านล่าง
ของ a |
unit_diagonal
|
bool
|
หาก true องค์ประกอบแนวทแยงของ a จะถือว่าเป็น 1 และจะไม่มีการเข้าถึง |
transpose_a
|
Transpose
|
ดูว่าจะใช้ a ตามเดิม สลับเมทริกซ์ หรือ
ใช้ทรานสโพสผูกพัน |
ระบบจะอ่านข้อมูลอินพุตจากสามเหลี่ยมล่าง/บนของ a เท่านั้น โดยขึ้นอยู่กับค่าของ lower ระบบจะไม่สนใจค่าจากสามเหลี่ยมอีกรูป ข้อมูลเอาต์พุตจะ
แสดงในสามเหลี่ยมเดียวกัน ส่วนค่าในสามเหลี่ยมอีกด้านหนึ่งจะ
ขึ้นอยู่กับการติดตั้งใช้งานและอาจเป็นค่าใดก็ได้
หากจำนวนมิติข้อมูลของ a และ b มากกว่า 2 ระบบจะถือว่ามิติข้อมูลเหล่านั้นเป็นกลุ่มเมทริกซ์ โดยที่มิติข้อมูลทั้งหมด ยกเว้นมิติข้อมูล 2 รายการที่เล็กที่สุดเป็นมิติข้อมูลกลุ่ม a และ b ต้องมีมิติข้อมูลกลุ่มเท่ากัน
ดูข้อมูล StableHLO ได้ที่ StableHLO - triangular_solve
ทูเพิล
ดูเพิ่มเติม
XlaBuilder::Tuple
ทูเพิลที่มีแฮนเดิลข้อมูลจํานวนตัวแปร ซึ่งแต่ละแฮนเดิลมีรูปร่างของตัวเอง
Tuple(elements)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
elements |
เวกเตอร์ของ XlaOp |
อาร์เรย์ N ของประเภท T |
ซึ่งคล้ายกับ std::tuple ใน C++ โดยในเชิงแนวคิดแล้ว
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
คุณสามารถแยกโครงสร้าง (เข้าถึง) ของทูเพิลได้โดยใช้การดำเนินการ GetTupleElement
ดูข้อมูล StableHLO ได้ที่ StableHLO - tuple
ในขณะที่
ดูเพิ่มเติม
XlaBuilder::While
While(condition, body, init)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
condition
|
XlaComputation
|
XlaComputation ประเภท T -> PRED ซึ่ง
กำหนดเงื่อนไขการสิ้นสุดของ
ลูป |
body
|
XlaComputation
|
XlaComputation ประเภท T -> T ซึ่ง
กำหนดเนื้อหาของลูป |
init
|
T
|
ค่าเริ่มต้นสำหรับพารามิเตอร์ของ
condition และ body |
เรียกใช้ body ตามลำดับจนกว่า condition จะล้มเหลว ซึ่งคล้ายกับ
ลูป while ทั่วไปในภาษาอื่นๆ อีกมากมาย ยกเว้นความแตกต่างและ
ข้อจำกัดที่ระบุไว้ด้านล่าง
- โหนด
Whileจะแสดงค่าประเภทTซึ่งเป็นผลลัพธ์จากการ ดำเนินการbodyครั้งล่าสุด - รูปร่างของประเภท
Tจะกำหนดแบบคงที่และต้องเหมือนกัน ในการทำซ้ำทั้งหมด
พารามิเตอร์ T ของการคำนวณจะเริ่มต้นด้วยค่า init ใน
การวนซ้ำครั้งแรก และจะอัปเดตเป็นผลลัพธ์ใหม่จาก body โดยอัตโนมัติ
ในการวนซ้ำครั้งต่อๆ ไป
กรณีการใช้งานหลักอย่างหนึ่งของโหนด While คือการใช้การดำเนินการซ้ำของ
การฝึกในโครงข่ายประสาทเทียม รหัสหลอกแบบง่ายแสดงอยู่ด้านล่างพร้อมกราฟ
ที่แสดงถึงการคำนวณ คุณดูโค้ดได้ใน
while_test.cc
ประเภท T ในตัวอย่างนี้คือ Tuple ซึ่งประกอบด้วย int32 สำหรับ
จำนวนการทำซ้ำและ vector[10] สำหรับตัวสะสม สำหรับการทำซ้ำ 1, 000 ครั้ง
ลูปจะเพิ่มเวกเตอร์คงที่ลงในตัวสะสม
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}
ดูข้อมูล StableHLO ได้ที่ StableHLO - while
Xor
ดูเพิ่มเติม
XlaBuilder::Xor
ดำเนินการ XOR แบบทีละองค์ประกอบของ lhs และ rhs
Xor(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบการออกอากาศเกี่ยวกับความหมายของรูปร่างที่ เข้ากันได้ ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลลัพธ์ของ การออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีอันดับต่างกัน เว้นแต่ว่าตัวถูกดำเนินการตัวใดตัวหนึ่งจะเป็นสเกลาร์
Xor มีตัวแปรอื่นที่รองรับการออกอากาศแบบหลายมิติ
Xor(lhs,rhs, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
| lhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| rhs | XlaOp | ตัวถูกดำเนินการด้านซ้าย: อาร์เรย์ของ ประเภท T |
| broadcast_dimension | ArraySlice |
มิติข้อมูลใดในรูปร่างเป้าหมาย ที่มิติข้อมูลแต่ละมิติของ รูปร่างตัวถูกดำเนินการสอดคล้องกัน |
ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีอันดับต่างกัน (เช่น การบวกเมทริกซ์กับเวกเตอร์)
ตัวถูกดำเนินการ broadcast_dimensions เพิ่มเติมคือ Slice ของจำนวนเต็มที่ระบุ มิติข้อมูลที่จะใช้ในการออกอากาศตัวถูกดำเนินการ ดูรายละเอียดความหมายได้ในหน้าการออกอากาศ
ดูข้อมูล StableHLO ได้ที่ StableHLO - xor