
Berikut ini menjelaskan semantik operasi yang ditentukan dalam antarmuka
XlaBuilder. Biasanya, operasi ini dipetakan satu-ke-satu ke operasi yang ditentukan dalam
antarmuka RPC di
xla_data.proto.
Catatan tentang nomenklatur: jenis data umum yang ditangani XLA adalah array N dimensi yang menyimpan elemen dari beberapa jenis seragam (seperti float 32-bit). Di seluruh dokumentasi, array digunakan untuk menunjukkan array berdimensi arbitrer. Untuk mempermudah, kasus khusus memiliki nama yang lebih spesifik dan umum; misalnya, vektor adalah array 1 dimensi dan matriks adalah array 2 dimensi.
Pelajari lebih lanjut struktur Op di Bentuk dan tata letak dan Tata Letak Berpetak.
Perut
Lihat juga
XlaBuilder::Abs.
Absolut per elemen x -> |x|.
Abs(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - abs.
Tambahkan
Lihat juga
XlaBuilder::Add.
Melakukan penambahan per elemen lhs dan rhs.
Add(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi berbeda tersedia untuk Tambahkan:
Add(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk mengetahui informasi StableHLO, lihat StableHLO - add.
AddDependency
Lihat juga
HloInstruction::AddDependency.
AddDependency dapat muncul dalam dump HLO, tetapi tidak dimaksudkan untuk
dibuat secara manual oleh pengguna akhir.
AfterAll
Lihat juga
XlaBuilder::AfterAll.
AfterAll mengambil sejumlah token variadik dan menghasilkan satu token. Token
adalah jenis primitif yang dapat di-thread di antara operasi yang memengaruhi efek samping untuk
menerapkan pengurutan. AfterAll dapat digunakan sebagai gabungan token untuk mengurutkan
operasi setelah serangkaian operasi.
AfterAll(tokens)
| Argumen | Jenis | Semantik |
|---|---|---|
tokens |
vektor XlaOp |
jumlah token variadik |
Untuk informasi StableHLO, lihat StableHLO - after_all.
AllGather
Lihat juga
XlaBuilder::AllGather.
Melakukan penggabungan di seluruh replika.
AllGather(operand, all_gather_dimension, shard_count, replica_groups,
channel_id, layout, use_global_device_ids)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp
|
Array untuk menggabungkan di seluruh replika |
all_gather_dimension |
int64 |
Dimensi penggabungan |
shard_count
|
int64
|
Ukuran setiap grup replika |
replica_groups
|
vektor vektor
int64 |
Grup yang akan digabungkan |
channel_id
|
opsional
ChannelHandle |
ID channel opsional untuk komunikasi lintas modul |
layout
|
opsional Layout
|
Membuat pola tata letak yang akan mengambil tata letak yang cocok dalam argumen |
use_global_device_ids
|
opsional bool
|
Menampilkan benar jika ID dalam konfigurasi ReplicaGroup merepresentasikan ID global |
replica_groupsadalah daftar grup replika yang di antaranya penggabungan dilakukan (ID replika untuk replika saat ini dapat diambil menggunakanReplicaId). Urutan replika di setiap grup menentukan urutan inputnya dalam hasil.replica_groupsharus kosong (dalam hal ini semua replika termasuk dalam satu grup, diurutkan dari0hinggaN - 1), atau berisi jumlah elemen yang sama dengan jumlah replika. Misalnya,replica_groups = {0, 2}, {1, 3}melakukan penggabungan antara replika0dan2, serta1dan3.shard_countadalah ukuran setiap grup replika. Kami memerlukan ini jikareplica_groupskosong.channel_iddigunakan untuk komunikasi lintas modul: hanya operasiall-gatherdenganchannel_idyang sama yang dapat berkomunikasi satu sama lain.use_global_device_idsMenampilkan benar jika ID dalam konfigurasi ReplicaGroup merepresentasikan ID global (replica_id * partition_count + partition_id) bukan ID replika. Hal ini memungkinkan pengelompokan perangkat yang lebih fleksibel jika all-reduce ini bersifat lintas partisi dan lintas replika.
Bentuk output adalah bentuk input dengan all_gather_dimension yang dibuat shard_count kali lebih besar. Misalnya, jika ada dua replika dan operand masing-masing memiliki nilai [1.0, 2.5] dan [3.0, 5.25] pada kedua replika, maka nilai output dari operasi ini dengan all_gather_dim adalah 0 akan menjadi [1.0, 2.5, 3.0,5.25] pada kedua replika.
API AllGather secara internal diuraikan menjadi 2 instruksi HLO
(AllGatherStart dan AllGatherDone).
Lihat juga
HloInstruction::CreateAllGatherStart.
AllGatherStart, AllGatherDone berfungsi sebagai primitif di HLO. Operasi ini mungkin muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Untuk informasi StableHLO, lihat StableHLO - all_gather.
AllReduce
Lihat juga
XlaBuilder::AllReduce.
Melakukan komputasi kustom di seluruh replika.
AllReduce(operand, computation, replica_groups, channel_id,
shape_with_layout, use_global_device_ids)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp
|
Array atau tuple array yang tidak kosong untuk merampingkan di seluruh replika |
computation |
XlaComputation |
Penghitungan pengurangan |
replica_groups
|
ReplicaGroup vektor
|
Grup yang menjadi tujuan pengurangan |
channel_id
|
opsional
ChannelHandle |
ID channel opsional untuk komunikasi lintas modul |
shape_with_layout
|
opsional Shape
|
Menentukan tata letak data yang ditransfer |
use_global_device_ids
|
opsional bool
|
Menampilkan benar jika ID dalam konfigurasi ReplicaGroup merepresentasikan ID global |
- Jika
operandadalah tuple array, all-reduce akan dilakukan pada setiap elemen tuple. replica_groupsadalah daftar grup replika yang di antaranya pengurangan dilakukan (ID replika untuk replika saat ini dapat diambil menggunakanReplicaId).replica_groupsharus kosong (jika semua replika termasuk dalam satu grup), atau berisi jumlah elemen yang sama dengan jumlah replika. Misalnya,replica_groups = {0, 2}, {1, 3}melakukan pengurangan antara replika0dan2, serta1dan3.channel_iddigunakan untuk komunikasi lintas modul: hanya operasiall-reducedenganchannel_idyang sama yang dapat berkomunikasi satu sama lain.shape_with_layout: memaksa tata letak AllReduce ke tata letak yang diberikan. Ini digunakan untuk menjamin tata letak yang sama untuk sekelompok operasi AllReduce yang dikompilasi secara terpisah.use_global_device_idsMenampilkan benar jika ID dalam konfigurasi ReplicaGroup merepresentasikan ID global (replica_id * partition_count + partition_id) bukan ID replika. Hal ini memungkinkan pengelompokan perangkat yang lebih fleksibel jika all-reduce ini bersifat lintas partisi dan lintas replika.
Bentuk output sama dengan bentuk input. Misalnya, jika ada dua replika dan operand memiliki nilai [1.0, 2.5] dan [3.0, 5.25]
masing-masing pada kedua replika, maka nilai output dari operasi ini dan
penjumlahan akan menjadi [4.0, 7.75] pada kedua replika. Jika inputnya adalah
tuple, outputnya juga berupa tuple.
Menghitung hasil AllReduce memerlukan satu input dari setiap replika,
jadi jika satu replika menjalankan node AllReduce lebih banyak daripada replika lain, maka
replika pertama akan menunggu selamanya. Karena semua replika menjalankan program
yang sama, tidak banyak cara agar hal itu terjadi, tetapi hal itu mungkin terjadi saat
kondisi loop while bergantung pada data dari infeed dan data yang
infeed menyebabkan loop while beriterasi lebih banyak pada satu replika daripada
replika lainnya.
API AllReduce secara internal diuraikan menjadi 2 instruksi HLO
(AllReduceStart dan AllReduceDone).
Lihat juga
HloInstruction::CreateAllReduceStart.
AllReduceStart dan AllReduceDone berfungsi sebagai primitif di HLO. Operasi ini mungkin muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
CrossReplicaSum
Lihat juga
XlaBuilder::CrossReplicaSum.
Melakukan AllReduce dengan penghitungan penjumlahan.
CrossReplicaSum(operand, replica_groups)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp | Array atau tuple array yang tidak kosong untuk mengurangi di seluruh replika |
replica_groups
|
vektor vektor
int64 |
Grup yang menjadi tujuan pengurangan |
Menampilkan jumlah nilai operand dalam setiap subgrup replika. Semua replika memberikan satu input ke jumlah dan semua replika menerima jumlah yang dihasilkan untuk setiap subgrup.
AllToAll
Lihat juga
XlaBuilder::AllToAll.
AllToAll adalah operasi kolektif yang mengirim data dari semua core ke semua core. Proses ini memiliki dua fase:
- Fase sebar. Pada setiap core, operand dibagi menjadi
split_countjumlah blok di sepanjangsplit_dimensions, dan blok-blok tersebut disebar ke semua core, misalnya, blok ke-i dikirim ke core ke-i. - Fase pengumpulan. Setiap core menggabungkan blok yang diterima di sepanjang
concat_dimension.
Core yang berpartisipasi dapat dikonfigurasi oleh:
replica_groups: setiap ReplicaGroup berisi daftar ID replika yang berpartisipasi dalam komputasi (ID replika untuk replika saat ini dapat diambil menggunakanReplicaId). AllToAll akan diterapkan dalam subgrup dalam urutan yang ditentukan. Misalnya,replica_groups = { {1,2,3}, {4,5,0} }berarti AllToAll akan diterapkan dalam replika{1, 2, 3}, dan dalam fase pengumpulan, dan blok yang diterima akan digabungkan dalam urutan yang sama, yaitu 1, 2, 3. Kemudian, AllToAll lain akan diterapkan dalam replika 4, 5, 0, dan urutan penggabungannya juga 4, 5, 0. Jikareplica_groupskosong, semua replika termasuk dalam satu grup, dalam urutan penggabungan kemunculannya.
Prasyarat:
- Ukuran dimensi operand pada
split_dimensiondapat dibagi dengansplit_count. - Bentuk operand bukan tuple.
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups, layout, channel_id)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array input dimensi n |
split_dimension
|
int64
|
Nilai dalam interval
[0,n) yang memberi nama
dimensi yang digunakan untuk membagi
operan |
concat_dimension
|
int64
|
Nilai dalam interval
[0,n) yang memberi nama
dimensi yang
blok pemisahannya
digabungkan |
split_count
|
int64
|
Jumlah core yang
berpartisipasi dalam
operasi ini. Jika
replica_groups kosong,
ini harus berupa jumlah
replika; jika tidak, ini
harus sama dengan
jumlah replika di setiap
grup. |
replica_groups
|
ReplicaGroupvektor
|
Setiap grup berisi daftar ID replika. |
layout |
opsional Layout |
Tata letak memori yang ditentukan pengguna |
channel_id
|
opsional ChannelHandle
|
ID unik untuk setiap pasangan kirim/terima |
Lihat xla::shapes untuk mengetahui informasi selengkapnya tentang bentuk dan tata letak..
Untuk informasi StableHLO, lihat StableHLO - all_to_all.
AllToAll - Contoh 1.
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(
x,
/*split_dimension=*/ 1,
/*concat_dimension=*/ 0,
/*split_count=*/ 4);
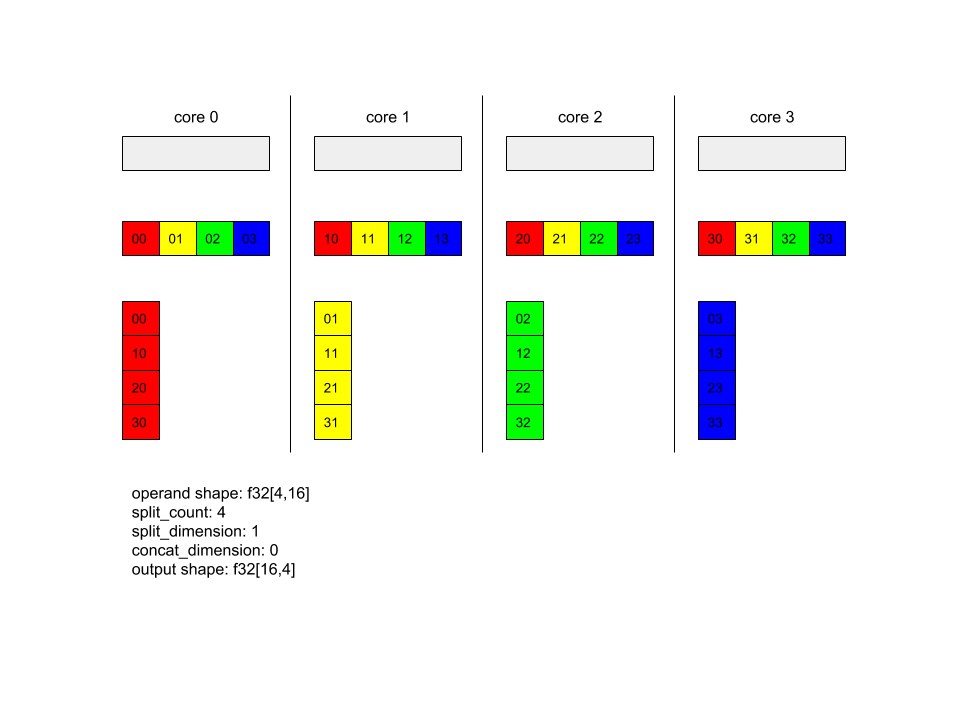
Dalam contoh di atas, ada 4 core yang berpartisipasi dalam Alltoall. Pada setiap core, operand dibagi menjadi 4 bagian di sepanjang dimensi 1, sehingga setiap bagian memiliki bentuk f32[4,4]. Keempat bagian tersebut tersebar ke semua core. Kemudian, setiap core menggabungkan bagian yang diterima di sepanjang dimensi 0, dalam urutan core 0-4. Jadi, output di setiap core memiliki bentuk f32[16,4].
AllToAll - Contoh 2 - StableHLO

Pada contoh di atas, ada 2 replika yang berpartisipasi dalam AllToAll. Di setiap replika, operand memiliki bentuk f32[2,4]. Operand dibagi menjadi 2 bagian di sepanjang dimensi 1, sehingga setiap bagian memiliki bentuk f32[2,2]. Kedua bagian tersebut kemudian dipertukarkan di seluruh replika sesuai dengan posisinya dalam grup replika. Setiap replika mengumpulkan bagian yang sesuai dari kedua operand dan menggabungkannya di sepanjang dimensi 0. Hasilnya, output di setiap replika memiliki bentuk f32[4,2].
RaggedAllToAll
Lihat juga
XlaBuilder::RaggedAllToAll.
RaggedAllToAll melakukan operasi semua-ke-semua kolektif, dengan input dan output berupa tensor tidak beraturan.
RaggedAllToAll(input, input_offsets, send_sizes, output, output_offsets,
recv_sizes, replica_groups, channel_id)
| Argumen | Jenis | Semantik |
|---|---|---|
input |
XlaOp |
Array N berjenis T |
input_offsets |
XlaOp |
Array N berjenis T |
send_sizes |
XlaOp |
Array N berjenis T |
output |
XlaOp |
Array N berjenis T |
output_offsets |
XlaOp |
Array N berjenis T |
recv_sizes |
XlaOp |
Array N berjenis T |
replica_groups
|
ReplicaGroup vektor
|
Setiap grup berisi daftar ID replika. |
channel_id
|
opsional ChannelHandle
|
ID unik untuk setiap pasangan kirim/terima |
Tensor tidak beraturan ditentukan oleh serangkaian tiga tensor:
data: tensordata“tidak beraturan” di sepanjang dimensi terluarnya, yang di sepanjangnya setiap elemen yang diindeks memiliki ukuran yang bervariasi.offsets': tensoroffsetsmengindeks dimensi terluar tensordata, dan merepresentasikan offset awal setiap elemen tidak beraturan dari tensordata.sizes: tensorsizesmerepresentasikan ukuran setiap elemen tidak beraturan dari tensordata, dengan ukuran yang ditentukan dalam satuan sub-elemen. Sub-elemen ditentukan sebagai akhiran bentuk tensor 'data' yang diperoleh dengan menghapus dimensi “tidak beraturan” terluar.- Tensor
offsetsdansizesharus memiliki ukuran yang sama.
Contoh tensor tidak beraturan:
data: [8,3] =
{ {a,b,c},{d,e,f},{g,h,i},{j,k,l},{m,n,o},{p,q,r},{s,t,u},{v,w,x} }
offsets: [3] = {0, 1, 4}
sizes: [3] = {1, 3, 4}
// Index 'data' at 'offsets'[0], 'sizes'[0]' // {a,b,c}
// Index 'data' at 'offsets'[1], 'sizes'[1]' // {d,e,f},{g,h,i},{j,k,l}
// Index 'data' at 'offsets'[2], 'sizes'[2]' // {m,n,o},{p,q,r},{s,t,u},{v,w,x}
output_offsets harus di-shard sedemikian rupa sehingga setiap replika memiliki offset dalam
perspektif output replika target.
Untuk offset output ke-i, replika saat ini akan mengirimkan update input[input_offsets[i]:input_offsets[i]+send_sizes[i]] ke replika ke-i yang akan ditulis ke output_i[output_offsets[i]:output_offsets[i]+send_sizes[i]] di replika ke-i output.
Misalnya, jika kita memiliki 2 replika:
replica 0:
input: [1, 2, 2]
output:[0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 2]
output_offsets: [0, 0]
recv_sizes: [1, 1]
replica 1:
input: [3, 4, 0]
output: [0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 1]
output_offsets: [1, 2]
recv_sizes: [2, 1]
// replica 0's result will be: [1, 3, 0, 0]
// replica 1's result will be: [2, 2, 4, 0]
HLO all-to-all tidak beraturan memiliki argumen berikut:
input: tensor data input tidak beraturan.output: tensor data output tidak beraturan.input_offsets: tensor offset input tidak beraturan.send_sizes: tensor ukuran pengiriman yang tidak beraturan.output_offsets: array offset tidak beraturan dalam output replika target.recv_sizes: tensor ukuran recv tidak beraturan.
Semua tensor *_offsets dan *_sizes harus memiliki bentuk yang sama.
Dua bentuk didukung untuk tensor *_offsets dan *_sizes:
[num_devices]di mana ragged-all-to-all dapat mengirim paling banyak satu update ke setiap perangkat jarak jauh dalam grup replika. Contoh:
for (remote_device_id : replica_group) {
SEND input[input_offsets[remote_device_id]],
output[output_offsets[remote_device_id]],
send_sizes[remote_device_id] }
[num_devices, num_updates]di mana ragged-all-to-all dapat mengirim hingganum_updatesupdate ke perangkat jarak jauh yang sama (masing-masing pada offset yang berbeda), untuk setiap perangkat jarak jauh dalam grup replika.
Contoh:
for (remote_device_id : replica_group) {
for (update_idx : num_updates) {
SEND input[input_offsets[remote_device_id][update_idx]],
output[output_offsets[remote_device_id][update_idx]]],
send_sizes[remote_device_id][update_idx] } }
Dan
Lihat juga
XlaBuilder::And.
Melakukan AND per elemen dari dua tensor lhs dan rhs.
And(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk And:
And(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk mengetahui informasi StableHLO, lihat StableHLO - dan.
Asinkron
Lihat juga HloInstruction::CreateAsyncStart,
HloInstruction::CreateAsyncUpdate,
HloInstruction::CreateAsyncDone.
AsyncDone, AsyncStart, dan AsyncUpdate adalah petunjuk HLO internal yang digunakan
untuk operasi Asinkron dan berfungsi sebagai primitif di HLO. Operasi ini mungkin muncul
dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Atan2
Lihat juga
XlaBuilder::Atan2.
Melakukan operasi atan2 per elemen pada lhs dan rhs.
Atan2(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk Atan2:
Atan2(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - atan2.
BatchNormGrad
Lihat juga
XlaBuilder::BatchNormGrad
dan makalah normalisasi batch asli
untuk mengetahui deskripsi mendetail tentang algoritma.
Menghitung gradien normalisasi batch.
BatchNormGrad(operand, scale, batch_mean, batch_var, grad_output, epsilon,
feature_index)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp | Array n dimensi yang akan dinormalisasi (x) |
scale |
XlaOp | Array 1 dimensi (\(\gamma\)) |
batch_mean |
XlaOp | Array 1 dimensi (\(\mu\)) |
batch_var |
XlaOp | Array 1 dimensi (\(\sigma^2\)) |
grad_output |
XlaOp | Gradien yang diteruskan ke BatchNormTraining (\(\nabla y\)) |
epsilon |
float |
Nilai epsilon (\(\epsilon\)) |
feature_index |
int64 |
Indeks untuk menampilkan dimensi di operand |
Untuk setiap fitur dalam dimensi fitur (feature_index adalah indeks untuk dimensi fitur dalam operand), operasi menghitung gradien sehubungan dengan operand, offset, dan scale di semua dimensi lainnya. feature_index harus berupa indeks yang valid untuk dimensi fitur dalam operand.
Tiga gradien ditentukan oleh formula berikut (dengan asumsi array 4 dimensi sebagai operand dan dengan indeks dimensi fitur l, ukuran batch m, serta ukuran spasial w dan h):
\[ \begin{split} c_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) \\\\ d_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \\\\ \nabla x_{ijkl} &= \frac{\gamma_{l} }{\sqrt{\sigma^2_{l}+\epsilon} } \left( \nabla y_{ijkl} - d_l - c_l (x_{ijkl} - \mu_{l}) \right) \\\\ \nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon} } \right) \\\\\ \nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \end{split} \]
Input batch_mean dan batch_var merepresentasikan nilai momen di seluruh dimensi batch
dan spasial.
Jenis output adalah tuple dari tiga handle:
| Output | Jenis | Semantik |
|---|---|---|
grad_operand
|
XlaOp | gradien terhadap
input operand
(\(\nabla x\)) |
grad_scale
|
XlaOp | gradien terhadap
input **scale **
(\(\nabla\gamma\)) |
grad_offset
|
XlaOp | gradien terhadap
input
offset(\(\nabla\beta\)) |
Untuk informasi StableHLO, lihat StableHLO - batch_norm_grad.
BatchNormInference
Lihat juga
XlaBuilder::BatchNormInference
dan makalah normalisasi batch asli
untuk mengetahui deskripsi mendetail tentang algoritma.
Menormalisasi array di seluruh dimensi batch dan spasial.
BatchNormInference(operand, scale, offset, mean, variance, epsilon,
feature_index)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp | Array n dimensi yang akan dinormalisasi |
scale |
XlaOp | Array 1 dimensi |
offset |
XlaOp | Array 1 dimensi |
mean |
XlaOp | Array 1 dimensi |
variance |
XlaOp | Array 1 dimensi |
epsilon |
float |
Nilai epsilon |
feature_index |
int64 |
Indeks untuk menampilkan dimensi di operand |
Untuk setiap fitur dalam dimensi fitur (feature_index adalah indeks untuk dimensi fitur dalam operand), operasi menghitung rata-rata dan varians di semua dimensi lainnya serta menggunakan rata-rata dan varians untuk menormalisasi setiap elemen dalam operand. feature_index harus berupa indeks yang valid untuk dimensi fitur dalam operand.
BatchNormInference setara dengan memanggil BatchNormTraining tanpa
menghitung mean dan variance untuk setiap batch. Operasi ini menggunakan mean dan
variance input sebagai nilai yang diperkirakan. Tujuan dari operasi ini adalah untuk mengurangi
latensi dalam inferensi, sehingga dinamakan BatchNormInference.
Outputnya adalah array yang dinormalisasi berdimensi n dengan bentuk yang sama seperti input
operand.
Untuk informasi StableHLO, lihat StableHLO - batch_norm_inference.
BatchNormTraining
Lihat juga
XlaBuilder::BatchNormTraining
dan the original batch normalization paper
untuk deskripsi mendetail tentang algoritma.
Menormalisasi array di seluruh dimensi batch dan spasial.
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array n dimensi yang akan dinormalisasi (x) |
scale |
XlaOp |
Array 1 dimensi (\(\gamma\)) |
offset |
XlaOp |
Array 1 dimensi (\(\beta\)) |
epsilon |
float |
Nilai epsilon (\(\epsilon\)) |
feature_index |
int64 |
Indeks untuk menampilkan dimensi di operand |
Untuk setiap fitur dalam dimensi fitur (feature_index adalah indeks untuk dimensi fitur dalam operand), operasi menghitung rata-rata dan varians di semua dimensi lainnya serta menggunakan rata-rata dan varians untuk menormalisasi setiap elemen dalam operand. feature_index harus berupa indeks yang valid untuk dimensi fitur dalam operand.
Algoritmanya adalah sebagai berikut untuk setiap batch di operand \(x\) yang berisi elemen m
dengan w dan h sebagai ukuran dimensi spasial (dengan asumsi operand
adalah array 4 dimensi):
Menghitung rata-rata batch \(\mu_l\) untuk setiap fitur
ldalam dimensi fitur: \(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\)Menghitung varians batch \(\sigma^2_l\): $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
Menormalisasi, menskalakan, dan menggeser: \(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon} }+\beta_l\)
Nilai epsilon, biasanya berupa angka kecil, ditambahkan untuk menghindari error pembagian dengan nol.
Jenis output adalah tuple dari tiga XlaOp:
| Output | Jenis | Semantik |
|---|---|---|
output
|
XlaOp
|
Array n dimensi dengan bentuk yang sama seperti input
operand (y) |
batch_mean |
XlaOp |
Array 1 dimensi (\(\mu\)) |
batch_var |
XlaOp |
Array 1 dimensi (\(\sigma^2\)) |
batch_mean dan batch_var adalah momen yang dihitung di seluruh batch dan
dimensi spasial menggunakan formula di atas.
Untuk informasi StableHLO, lihat StableHLO - batch_norm_training.
Bitcast
Lihat juga
HloInstruction::CreateBitcast.
Bitcast dapat muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
BitcastConvertType
Lihat juga
XlaBuilder::BitcastConvertType.
Mirip dengan tf.bitcast di TensorFlow, melakukan operasi bitcast per elemen dari bentuk data ke bentuk target. Ukuran input dan output harus sama: misalnya, s32 elemen menjadi f32 elemen melalui rutin bitcast, dan satu elemen s32 akan menjadi empat elemen s8. Bitcast diimplementasikan sebagai cast tingkat rendah, sehingga mesin dengan representasi floating point yang berbeda akan memberikan hasil yang berbeda.
BitcastConvertType(operand, new_element_type)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis T dengan dimensi D |
new_element_type |
PrimitiveType |
type U |
Dimensi operand dan bentuk target harus cocok, selain dimensi terakhir yang akan berubah berdasarkan rasio ukuran primitif sebelum dan setelah konversi.
Jenis elemen sumber dan tujuan tidak boleh berupa tuple.
Untuk informasi StableHLO, lihat StableHLO - bitcast_convert.
Konversi Bitcast ke jenis primitif dengan lebar yang berbeda
BitcastConvert Instruksi HLO mendukung kasus ketika ukuran jenis elemen output T' tidak sama dengan ukuran elemen input T. Karena
seluruh operasi secara konseptual adalah bitcast dan tidak mengubah byte yang mendasarinya, bentuk elemen output harus berubah. Untuk B = sizeof(T), B' =
sizeof(T'), ada dua kemungkinan kasus.
Pertama, saat B > B', bentuk output mendapatkan dimensi paling kecil baru berukuran
B/B'. Contoh:
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
Aturannya tetap sama untuk skalar efektif:
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
Atau, untuk B' > B, petunjuk memerlukan dimensi logis terakhir
dari bentuk input agar sama dengan B'/B, dan dimensi ini dihilangkan selama
konversi:
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
Perhatikan bahwa konversi antara bitwidth yang berbeda tidak dilakukan per elemen.
Siaran
Lihat juga
XlaBuilder::Broadcast.
Menambahkan dimensi ke array dengan menduplikasi data dalam array.
Broadcast(operand, broadcast_sizes)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array yang akan diduplikasi |
broadcast_sizes |
ArraySlice<int64> |
Ukuran dimensi baru |
Dimensi baru disisipkan di sebelah kiri, yaitu jika broadcast_sizes memiliki nilai {a0, ..., aN} dan bentuk operand memiliki dimensi {b0, ..., bM}, maka bentuk output memiliki dimensi {a0, ..., aN, b0, ..., bM}.
Dimensi baru mengindeks ke dalam salinan operand, yaitu
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
Misalnya, jika operand adalah skalar f32 dengan nilai 2.0f, dan
broadcast_sizes adalah {2, 3}, maka hasilnya akan berupa array dengan bentuk
f32[2, 3] dan semua nilai dalam hasil akan berupa 2.0f.
Untuk mengetahui informasi StableHLO, lihat StableHLO - broadcast.
BroadcastInDim
Lihat juga
XlaBuilder::BroadcastInDim.
Memperluas ukuran dan jumlah dimensi array dengan menduplikasi data dalam array.
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array yang akan diduplikasi |
out_dim_size
|
ArraySlice<int64>
|
Ukuran dimensi bentuk target |
broadcast_dimensions
|
ArraySlice<int64>
|
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Mirip dengan Broadcast, tetapi memungkinkan penambahan dimensi di mana saja dan perluasan dimensi yang ada dengan ukuran 1.
operand disiarkan ke bentuk yang dijelaskan oleh out_dim_size.
broadcast_dimensions memetakan dimensi operand ke dimensi
bentuk target, yaitu dimensi ke-i operand dipetakan ke
dimensi broadcast_dimension[i] dari bentuk output. Dimensi
operand harus memiliki ukuran 1 atau ukuran yang sama dengan dimensi dalam bentuk
output yang dipetakan. Dimensi yang tersisa diisi dengan dimensi berukuran 1. Penyiaran dimensi degenerasi kemudian menyiarkan sepanjang dimensi degenerasi ini untuk mencapai bentuk output. Semantik dijelaskan secara mendetail di
halaman penyiaran.
Telepon
Lihat juga
XlaBuilder::Call.
Memanggil komputasi dengan argumen yang diberikan.
Call(computation, operands...)
| Argumen | Jenis | Semantik |
|---|---|---|
computation
|
XlaComputation
|
komputasi jenis T_0, T_1, ...,
T_{N-1} -> S dengan N parameter jenis arbitrer |
operands |
urutan XlaOp N |
N argumen dari jenis arbitrer |
Jumlah dan jenis operands harus cocok dengan parameter
computation. operands boleh tidak ada.
CompositeCall
Lihat juga
XlaBuilder::CompositeCall.
Merangkum operasi yang terdiri dari (dikomposisikan) operasi StableHLO lainnya, yang menggunakan input dan composite_attributes serta menghasilkan hasil. Semantik op diimplementasikan oleh atribut dekomposisi. Operasi komposit dapat diganti dengan dekomposisinya tanpa mengubah semantik program. Jika penyisipan dekomposisi tidak memberikan semantik op yang sama, sebaiknya gunakan custom_call.
Kolom versi (defaultnya 0) digunakan untuk menunjukkan kapan semantik komposit berubah.
Operasi ini diterapkan sebagai kCall dengan atribut is_composite=true. Kolom
decomposition ditentukan oleh atribut computation. Atribut frontend
menyimpan atribut yang tersisa dengan awalan composite..
Contoh op CompositeCall:
f32[] call(f32[] %cst), to_apply=%computation, is_composite=true,
frontend_attributes = {
composite.name="foo.bar",
composite.attributes={n = 1 : i32, tensor = dense<1> : tensor<i32>},
composite.version="1"
}
CompositeCall(computation, operands..., name, attributes, version)
| Argumen | Jenis | Semantik |
|---|---|---|
computation
|
XlaComputation
|
komputasi jenis T_0, T_1, ...,
T_{N-1} -> S dengan N parameter jenis arbitrer |
operands |
urutan XlaOp N |
jumlah nilai variadik |
name |
string |
nama komposit |
attributes
|
opsional string
|
kamus atribut opsional yang diubah menjadi string |
version
|
opsional int64
|
number to version updates to semantik operasi gabungan |
decomposition op bukan merupakan kolom yang dipanggil, tetapi muncul sebagai atribut to_apply
yang mengarah ke fungsi yang berisi penerapan tingkat yang lebih rendah, yaitu to_apply=%funcname
Informasi selengkapnya tentang komposit dan dekomposisi dapat ditemukan di Spesifikasi StableHLO.
Cbrt
Lihat juga
XlaBuilder::Cbrt.
Operasi akar kubik per elemen x -> cbrt(x).
Cbrt(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Cbrt juga mendukung argumen result_accuracy opsional:
Cbrt(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - cbrt.
Ceil
Lihat juga
XlaBuilder::Ceil.
Ceil per elemen x -> ⌈x⌉.
Ceil(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - ceil.
Cholesky
Lihat juga
XlaBuilder::Cholesky.
Menghitung dekomposisi Cholesky dari batch matriks definit positif simetris (Hermitian).
Cholesky(a, lower)
| Argumen | Jenis | Semantik |
|---|---|---|
a
|
XlaOp
|
array jenis kompleks atau floating point dengan > 2 dimensi. |
lower |
bool |
apakah akan menggunakan segitiga atas atau bawah a. |
Jika lower adalah true, menghitung matriks segitiga bawah l sehingga $a = l .
l^T$. Jika lower adalah false, menghitung matriks segitiga atas u sehingga
\(a = u^T . u\).
Data input hanya dibaca dari segitiga bawah/atas a, bergantung pada
nilai lower. Nilai dari segitiga lainnya akan diabaikan. Data output
ditampilkan dalam segitiga yang sama; nilai dalam segitiga lainnya
ditetapkan oleh implementasi dan dapat berupa apa saja.
Jika a memiliki lebih dari 2 dimensi, a diperlakukan sebagai batch matriks,
dengan semua kecuali 2 dimensi kecil adalah dimensi batch.
Jika a tidak simetris (Hermitian) dan definit positif, hasilnya ditentukan oleh implementasi.
Untuk mengetahui informasi StableHLO, lihat StableHLO - cholesky.
Pembatas
Lihat juga
XlaBuilder::Clamp.
Mengepaskan operand dalam rentang antara nilai minimum dan maksimum.
Clamp(min, operand, max)
| Argumen | Jenis | Semantik |
|---|---|---|
min |
XlaOp |
array jenis T |
operand |
XlaOp |
array jenis T |
max |
XlaOp |
array jenis T |
Mengingat operand serta nilai minimum dan maksimum, menampilkan operand jika berada dalam rentang antara nilai minimum dan maksimum, atau menampilkan nilai minimum jika operand berada di bawah rentang ini atau nilai maksimum jika operand berada di atas rentang ini. Artinya, clamp(a, x, b) = min(max(a, x), b).
Ketiga array harus memiliki bentuk yang sama. Atau, sebagai bentuk penyiaran terbatas, min dan/atau max dapat berupa skalar jenis T.
Contoh dengan skalar min dan max:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
Untuk informasi StableHLO, lihat StableHLO - clamp.
Ciutkan
Lihat juga
XlaBuilder::Collapse.
dan operasi tf.reshape.
Menciutkan dimensi array menjadi satu dimensi.
Collapse(operand, dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis T |
dimensions |
int64 vektor |
subset dimensi T yang berurutan. |
Collapse menggantikan subset dimensi operand yang diberikan dengan satu
dimensi. Argumen input adalah array arbitrer berjenis T dan vektor
indeks dimensi konstanta waktu kompilasi. Indeks dimensi harus berupa
subset dimensi T yang berurutan (angka dimensi rendah ke tinggi) dan berurutan. Jadi, {0, 1, 2}, {0, 1}, atau {1, 2} adalah semua set dimensi yang valid, tetapi
{1, 0} atau {0, 2} tidak valid. Indeks tersebut digantikan oleh satu dimensi baru, di
posisi yang sama dalam urutan dimensi dengan indeks yang digantikannya, dengan
ukuran dimensi baru sama dengan produk ukuran dimensi asli. Angka
dimensi terendah dalam dimensions adalah dimensi yang berubah paling lambat (paling utama)
dalam nest loop yang menciutkan dimensi ini, dan angka dimensi tertinggi
adalah yang berubah paling cepat (paling kecil). Lihat operator tf.reshape jika diperlukan
pengurutan penciutan yang lebih umum.
Misalnya, misalkan v adalah array 24 elemen:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
Clz
Lihat juga
XlaBuilder::Clz.
Menghitung angka nol di depan secara elemen.
Clz(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
CollectiveBroadcast
Lihat juga
XlaBuilder::CollectiveBroadcast.
Menyiarkan data di seluruh replika. Data dikirim dari ID replika pertama di setiap
grup ke ID lain dalam grup yang sama. Jika ID replika tidak ada dalam grup replika mana pun, output pada replika tersebut adalah tensor yang terdiri dari 0 dalam shape.
CollectiveBroadcast(operand, replica_groups, channel_id)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
replica_groups
|
ReplicaGroupvektor
|
Setiap grup berisi daftar ID replika |
channel_id
|
opsional ChannelHandle
|
ID unik untuk setiap pasangan kirim/terima |
Untuk informasi StableHLO, lihat StableHLO - collective_broadcast.
CollectivePermute
Lihat juga
XlaBuilder::CollectivePermute.
CollectivePermute adalah operasi kolektif yang mengirim dan menerima data di seluruh replika.
CollectivePermute(operand, source_target_pairs, channel_id)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array input dimensi n |
source_target_pairs
|
<int64, int64> vektor
|
Daftar pasangan (source_replica_id, target_replica_id). Untuk setiap pasangan, operan dikirim dari replika sumber ke replika target. |
channel_id
|
opsional ChannelHandle
|
ID channel opsional untuk komunikasi lintas modul |
Perhatikan bahwa ada batasan berikut pada source_target_pairs:
- Dua pasangan tidak boleh memiliki ID replika target yang sama, dan tidak boleh memiliki ID replika sumber yang sama.
- Jika ID replika bukan target dalam pasangan apa pun, maka output pada replika tersebut adalah tensor yang terdiri dari 0(s) dengan bentuk yang sama seperti input.
API operasi CollectivePermute secara internal diuraikan menjadi 2 instruksi HLO (CollectivePermuteStart dan CollectivePermuteDone).
Lihat juga
HloInstruction::CreateCollectivePermuteStart.
CollectivePermuteStart dan CollectivePermuteDone berfungsi sebagai primitif di HLO.
Operasi ini mungkin muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Untuk informasi StableHLO, lihat StableHLO - collective_permute.
Bandingkan
Lihat juga
XlaBuilder::Compare.
Melakukan perbandingan berbasis elemen lhs dan rhs berikut:
Eq
Lihat juga
XlaBuilder::Eq.
Melakukan perbandingan sama dengan per elemen antara lhs dan rhs.
\(lhs = rhs\)
Eq(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Tersedia varian alternatif dengan dukungan penyiaran berdimensi berbeda untuk Eq:
Eq(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Mendukung total pesanan di atas angka floating point untuk Eq, dengan menerapkan:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
EqTotalOrder(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Untuk mengetahui informasi StableHLO, lihat StableHLO - compare.
Ne
Lihat juga
XlaBuilder::Ne.
Melakukan perbandingan tidak sama dengan per elemen dari lhs dan rhs.
\(lhs != rhs\)
Ne(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk Ne:
Ne(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Mendukung total pesanan di atas angka floating point untuk Ne, dengan menerapkan:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
NeTotalOrder(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Untuk mengetahui informasi StableHLO, lihat StableHLO - compare.
Ge
Lihat juga
XlaBuilder::Ge.
Melakukan perbandingan greater-or-equal-than per elemen antara lhs dan rhs.
\(lhs >= rhs\)
Ge(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Tersedia varian alternatif dengan dukungan penyiaran berdimensi berbeda untuk Ge:
Ge(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Mendukung total pesanan di atas bilangan floating point untuk Gt, dengan menerapkan:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
GtTotalOrder(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Untuk mengetahui informasi StableHLO, lihat StableHLO - compare.
Gt
Lihat juga
XlaBuilder::Gt.
Melakukan perbandingan lebih besar dari per elemen antara lhs dan rhs.
\(lhs > rhs\)
Gt(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Tersedia varian alternatif dengan dukungan penyiaran dimensi yang berbeda untuk Gt:
Gt(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk mengetahui informasi StableHLO, lihat StableHLO - compare.
Le
Lihat juga
XlaBuilder::Le.
Melakukan perbandingan less-or-equal-than per elemen dari lhs dan rhs.
\(lhs <= rhs\)
Le(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk Le:
Le(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Mendukung total pesanan di atas angka floating point ada untuk Le, dengan menerapkan:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LeTotalOrder(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Untuk mengetahui informasi StableHLO, lihat StableHLO - compare.
Lt
Lihat juga
XlaBuilder::Lt.
Melakukan perbandingan kurang dari per elemen antara lhs dan rhs.
\(lhs < rhs\)
Lt(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk Lt:
Lt(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Mendukung total pesanan di atas angka floating point untuk Lt, dengan menerapkan:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LtTotalOrder(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Untuk mengetahui informasi StableHLO, lihat StableHLO - compare.
Kompleks
Lihat juga
XlaBuilder::Complex.
Melakukan konversi per elemen ke nilai kompleks dari pasangan nilai riil dan imajiner, lhs dan rhs.
Complex(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran berdimensi berbeda ada untuk Complex:
Complex(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - complex.
ConcatInDim (Gabungkan)
Lihat juga
XlaBuilder::ConcatInDim.
Concatenate menyusun array dari beberapa operand array. Array memiliki jumlah dimensi yang sama dengan setiap operand array input (yang harus memiliki jumlah dimensi yang sama satu sama lain) dan berisi argumen dalam urutan yang ditentukan.
Concatenate(operands..., dimension)
| Argumen | Jenis | Semantik |
|---|---|---|
operands
|
urutan N XlaOp
|
N array berjenis T dengan dimensi [L0, L1, ...]. Memerlukan N >= 1. |
dimension
|
int64
|
Nilai dalam interval [0, N) yang
menamai dimensi yang akan digabungkan
di antara operands. |
Dengan pengecualian dimension, semua dimensi harus sama. Hal ini karena XLA tidak mendukung array "tidak beraturan". Perhatikan juga bahwa nilai 0 dimensi tidak dapat digabungkan (karena dimensi yang digunakan untuk penggabungan tidak dapat diberi nama).
Contoh 1 dimensi:
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
//Output: {2, 3, 4, 5, 6, 7}
Contoh 2 dimensi:
let a = { {1, 2},
{3, 4},
{5, 6} };
let b = { {7, 8} };
Concat({a, b}, 0)
//Output: { {1, 2},
// {3, 4},
// {5, 6},
// {7, 8} }
Diagram:
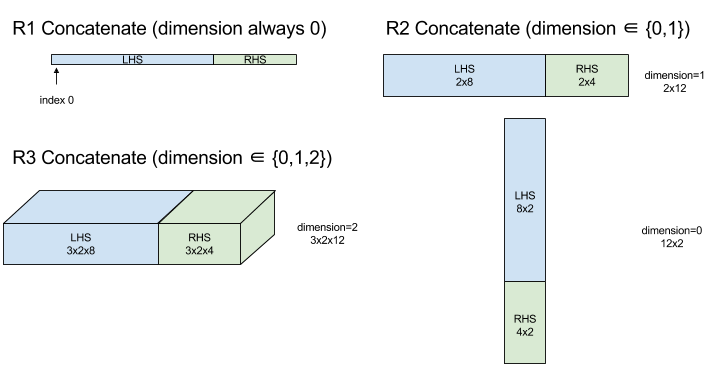
Untuk informasi StableHLO, lihat StableHLO - concatenate.
Kondisional
Lihat juga
XlaBuilder::Conditional.
Conditional(predicate, true_operand, true_computation, false_operand,
false_computation)
| Argumen | Jenis | Semantik |
|---|---|---|
predicate |
XlaOp |
Skalar jenis PRED |
true_operand |
XlaOp |
Argumen jenis \(T_0\) |
true_computation |
XlaComputation |
XlaComputation of type \(T_0 \to S\) |
false_operand |
XlaOp |
Argumen jenis \(T_1\) |
false_computation |
XlaComputation |
XlaComputation of type \(T_1 \to S\) |
Menjalankan true_computation jika predicate adalah true, false_computation jika
predicate adalah false, dan menampilkan hasilnya.
true_computation harus mengambil satu argumen jenis \(T_0\) dan akan
dipanggil dengan true_operand yang harus memiliki jenis yang sama. false_computation harus mengambil satu argumen jenis \(T_1\) dan akan dipanggil dengan false_operand yang harus memiliki jenis yang sama. Jenis nilai yang ditampilkan dari true_computation dan false_computation harus sama.
Perhatikan bahwa hanya salah satu dari true_computation dan false_computation yang akan
dieksekusi, bergantung pada nilai predicate.
Conditional(branch_index, branch_computations, branch_operands)
| Argumen | Jenis | Semantik |
|---|---|---|
branch_index |
XlaOp |
Skalar jenis S32 |
branch_computations |
urutan N XlaComputation |
XlaComputations jenis \(T_0 \to S , T_1 \to S , ..., T_{N-1} \to S\) |
branch_operands |
urutan N XlaOp |
Argumen jenis \(T_0 , T_1 , ..., T_{N-1}\) |
Menjalankan branch_computations[branch_index], dan menampilkan hasilnya. Jika
branch_index adalah S32 yang < 0 atau >= N, maka branch_computations[N-1]
dieksekusi sebagai cabang default.
Setiap branch_computations[b] harus mengambil satu argumen berjenis \(T_b\) dan
akan dipanggil dengan branch_operands[b] yang harus berjenis sama. Jenis nilai yang ditampilkan dari setiap branch_computations[b] harus sama.
Perhatikan bahwa hanya salah satu branch_computations yang akan dieksekusi, bergantung pada
nilai branch_index.
Untuk mengetahui informasi StableHLO, lihat StableHLO - if.
Konstanta
Lihat juga
XlaBuilder::ConstantLiteral.
Menghasilkan output dari literal konstan.
Constant(literal)
| Argumen | Jenis | Semantik |
|---|---|---|
literal |
LiteralSlice |
tampilan konstan Literal yang ada |
Untuk informasi StableHLO, lihat StableHLO - constant.
ConvertElementType
Lihat juga
XlaBuilder::ConvertElementType.
Mirip dengan static_cast per elemen di C++, ConvertElementType melakukan
operasi konversi per elemen dari bentuk data ke bentuk target. Dimensi harus cocok, dan konversinya adalah per elemen; misalnya, elemen s32 menjadi elemen f32 melalui rutin konversi s32 ke f32.
ConvertElementType(operand, new_element_type)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis T dengan dimensi D |
new_element_type |
PrimitiveType |
type U |
Dimensi operand dan bentuk target harus cocok. Jenis elemen sumber dan tujuan tidak boleh berupa tuple.
Konversi seperti T=s32 ke U=f32 akan melakukan rutin konversi int-ke-float yang menormalisasi seperti round-to-nearest-even.
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
Untuk informasi StableHLO, lihat StableHLO - convert.
Conv (Konvolusi)
Lihat juga
XlaBuilder::Conv.
Menghitung konvolusi jenis yang digunakan dalam jaringan neural. Di sini, konvolusi dapat dianggap sebagai jendela n-dimensi yang bergerak di seluruh area dasar n-dimensi dan komputasi dilakukan untuk setiap kemungkinan posisi jendela.
Conv Mengantrekan instruksi konvolusi ke komputasi, yang menggunakan
nomor dimensi konvolusi default tanpa dilatasi.
Padding ditentukan dengan cara singkat sebagai SAME atau VALID. Penggabungan
SAME mengisi input (lhs) dengan nol sehingga output memiliki bentuk yang sama
dengan input saat tidak memperhitungkan langkah. Padding VALID berarti tidak ada padding.
Conv(lhs, rhs, window_strides, padding, feature_group_count,
batch_group_count, precision_config, preferred_element_type)
| Argumen | Jenis | Semantik |
|---|---|---|
lhs
|
XlaOp
|
Array input berdimensi (n+2) |
rhs
|
XlaOp
|
Array (n+2) dimensi dari bobot kernel |
window_strides |
ArraySlice<int64> |
Array n-d langkah kernel |
padding |
Padding |
enum padding |
feature_group_count
|
int64 | jumlah grup fitur |
batch_group_count |
int64 | jumlah grup batch |
precision_config
|
opsional
PrecisionConfig |
enum untuk tingkat presisi |
preferred_element_type
|
opsional
PrimitiveType |
enum jenis elemen skalar |
Tingkat kontrol yang lebih tinggi tersedia untuk Conv:
Misalkan n adalah jumlah dimensi spasial. Argumen lhs adalah array berdimensi (n+2) yang menjelaskan area dasar. Ini disebut input,
meskipun tentu saja rhs juga merupakan input. Dalam jaringan neural, ini adalah
aktivasi input. Dimensi n+2 adalah, dalam urutan ini:
batch: Setiap koordinat dalam dimensi ini merepresentasikan input independen yang akan dilakukan konvolusi.z/depth/features: Setiap posisi (y,x) di area dasar memiliki vektor yang terkait dengannya, yang masuk ke dimensi ini.spatial_dims: Mendeskripsikan dimensi spasialnyang menentukan area dasar tempat jendela bergerak.
Argumen rhs adalah array (n+2) dimensi yang menjelaskan filter/kernel/jendela konvolusional. Dimensinya adalah, dalam urutan ini:
output-z: Dimensizoutput.input-z: Ukuran dimensi ini dikalikanfeature_group_countharus sama dengan ukuran dimensizdi lhs.spatial_dims: Mendeskripsikan dimensi spasialnyang menentukan jendela n-d yang bergerak di seluruh area dasar.
Argumen window_strides menentukan langkah jendela konvolusional dalam dimensi spasial. Misalnya, jika langkah dalam dimensi spasial pertama adalah 3, maka jendela hanya dapat ditempatkan pada koordinat dengan indeks spasial pertama yang dapat dibagi 3.
Argumen padding menentukan jumlah padding nol yang akan diterapkan ke area dasar. Jumlah padding dapat berupa negatif -- nilai absolut padding negatif menunjukkan jumlah elemen yang akan dihapus dari dimensi yang ditentukan sebelum melakukan konvolusi. padding[0] menentukan padding untuk dimensi y dan padding[1] menentukan padding untuk dimensi x. Setiap pasangan memiliki padding rendah sebagai elemen pertama dan padding tinggi sebagai elemen kedua. Padding rendah diterapkan ke arah indeks yang lebih rendah, sedangkan padding tinggi diterapkan ke arah indeks yang lebih tinggi. Misalnya, jika padding[1] adalah (2,3), maka akan ada padding dengan 2 nol di sebelah kiri dan 3 nol di sebelah kanan dalam dimensi spasial kedua. Menggunakan padding sama dengan menyisipkan nilai nol yang sama ke dalam input (lhs) sebelum melakukan konvolusi.
Argumen lhs_dilation dan rhs_dilation menentukan faktor dilatasi yang akan diterapkan ke lhs dan rhs, masing-masing, di setiap dimensi spasial. Jika faktor
dilatasi dalam dimensi spasial adalah d, maka d-1 lubang secara implisit
ditempatkan di antara setiap entri dalam dimensi tersebut, sehingga meningkatkan ukuran
array. Kekosongan diisi dengan nilai no-op, yang untuk konvolusi berarti nol.
Dilation rhs juga disebut konvolusi atrous. Untuk detail selengkapnya, lihat
tf.nn.atrous_conv2d. Dilatasi lhs juga disebut konvolusi
yang ditransposisikan. Untuk detail selengkapnya, lihat tf.nn.conv2d_transpose.
Argumen feature_group_count (nilai default 1) dapat digunakan untuk konvolusi yang dikelompokkan. feature_group_count harus berupa pembagi dimensi fitur input dan output. Jika feature_group_count lebih besar dari 1, artinya secara konseptual dimensi fitur input dan output serta dimensi fitur output rhs dibagi secara merata menjadi banyak grup feature_group_count, dengan setiap grup terdiri dari subsekuens fitur yang berurutan. Dimensi fitur input rhs harus sama dengan dimensi fitur input lhs yang dibagi dengan feature_group_count (sehingga sudah memiliki ukuran grup fitur input). Grup ke-i digunakan bersama untuk menghitung feature_group_count untuk banyak konvolusi terpisah. Hasil konvolusi ini digabungkan dalam dimensi fitur output.
Untuk konvolusi per kedalaman, argumen feature_group_count akan disetel ke
dimensi fitur input, dan filter akan diubah bentuknya dari
[filter_height, filter_width, in_channels, channel_multiplier] menjadi
[filter_height, filter_width, 1, in_channels * channel_multiplier]. Untuk detail selengkapnya, lihat tf.nn.depthwise_conv2d.
Argumen batch_group_count (nilai default 1) dapat digunakan untuk filter
yang dikelompokkan selama backpropagation. batch_group_count harus berupa pembagi
ukuran dimensi batch lhs (input). Jika batch_group_count lebih besar
dari 1, berarti dimensi batch output harus berukuran input batch
/ batch_group_count. batch_group_count harus berupa pembagi ukuran fitur
output.
Bentuk output memiliki dimensi berikut, dalam urutan ini:
batch: Ukuran dimensi ini dikalikanbatch_group_countharus sama dengan ukuran dimensibatchdi lhs.z: Ukuran yang sama denganoutput-zpada kernel (rhs).spatial_dims: Satu nilai untuk setiap penempatan jendela konvolusional yang valid.

Gambar di atas menunjukkan cara kerja kolom batch_group_count. Secara efektif, kita
membagi setiap batch lhs menjadi batch_group_count grup, dan melakukan hal yang sama untuk
fitur output. Kemudian, untuk setiap grup ini, kita melakukan konvolusi berpasangan dan menggabungkan output di sepanjang dimensi fitur output. Semantik operasional
semua dimensi lainnya (fitur dan spasial) tetap sama.
Penempatan jendela konvolusional yang valid ditentukan oleh langkah dan ukuran area dasar setelah padding.
Untuk menjelaskan fungsi konvolusi, pertimbangkan konvolusi 2D, dan pilih beberapa koordinat batch, z, y, x tetap dalam output. Kemudian, (y,x) adalah
posisi sudut jendela dalam area dasar (misalnya, sudut kiri atas
bergantung pada cara Anda menafsirkan dimensi spasial). Sekarang kita memiliki jendela 2D, yang diambil dari area dasar, di mana setiap titik 2D dikaitkan dengan vektor 1D, sehingga kita mendapatkan kotak 3D. Dari kernel konvolusional, karena kita telah menetapkan
koordinat output z, kita juga memiliki kotak 3D. Kedua kotak memiliki dimensi yang sama, sehingga kita dapat mengambil jumlah produk per elemen antara kedua kotak (mirip dengan produk dot). Itulah nilai outputnya.
Perhatikan bahwa jika output-z misalnya, 5, maka setiap posisi jendela menghasilkan 5
nilai dalam output ke dimensi z output. Nilai ini berbeda
di bagian kernel konvolusional yang digunakan - ada kotak 3D terpisah dari
nilai yang digunakan untuk setiap koordinat output-z. Jadi, Anda dapat menganggapnya sebagai 5
konvolusi terpisah dengan filter yang berbeda untuk masing-masing konvolusi.
Berikut adalah kode semu untuk konvolusi 2D dengan padding dan striding:
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
precision_config digunakan untuk menunjukkan konfigurasi presisi. Tingkat
menentukan apakah hardware harus mencoba membuat lebih banyak petunjuk kode mesin
untuk memberikan emulasi dtype yang lebih akurat jika diperlukan (yaitu,
mengemulasi f32 di TPU yang hanya mendukung matmul bf16). Nilainya dapat berupa
DEFAULT, HIGH, HIGHEST. Detail tambahan
di bagian MXU.
preferred_element_type adalah elemen skalar dari jenis output presisi yang lebih tinggi/rendah yang digunakan untuk akumulasi. preferred_element_type merekomendasikan jenis akumulasi untuk operasi tertentu, tetapi tidak dijamin. Hal ini memungkinkan beberapa backend hardware untuk mengakumulasi dalam jenis yang berbeda dan mengonversi ke jenis output yang diinginkan.
Untuk informasi StableHLO, lihat StableHLO - convolution.
ConvWithGeneralPadding
Lihat juga
XlaBuilder::ConvWithGeneralPadding.
ConvWithGeneralPadding(lhs, rhs, window_strides, padding,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Sama seperti Conv dengan konfigurasi padding yang eksplisit.
| Argumen | Jenis | Semantik |
|---|---|---|
lhs
|
XlaOp
|
Array input berdimensi (n+2) |
rhs
|
XlaOp
|
Array (n+2) dimensi dari bobot kernel |
window_strides |
ArraySlice<int64> |
Array n-d langkah kernel |
padding
|
ArraySlice<
pair<int64,int64>> |
Array n-d (rendah, tinggi) padding |
feature_group_count
|
int64 | jumlah grup fitur |
batch_group_count |
int64 | jumlah grup batch |
precision_config
|
opsional
PrecisionConfig |
enum untuk tingkat presisi |
preferred_element_type
|
opsional
PrimitiveType |
enum jenis elemen skalar |
ConvWithGeneralDimensions
Lihat juga
XlaBuilder::ConvWithGeneralDimensions.
ConvWithGeneralDimensions(lhs, rhs, window_strides, padding,
dimension_numbers, feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Sama seperti Conv dengan angka dimensi yang eksplisit.
| Argumen | Jenis | Semantik |
|---|---|---|
lhs
|
XlaOp
|
Array input berdimensi (n+2) |
rhs
|
XlaOp
|
Array bobot kernel berdimensi (n+2) |
window_strides
|
ArraySlice<int64>
|
Array n-d dari langkah kernel |
padding |
Padding |
enum padding |
dimension_numbers
|
ConvolutionDimensionNumbers
|
jumlah dimensi |
feature_group_count
|
int64 | jumlah grup fitur |
batch_group_count
|
int64 | jumlah grup batch |
precision_config
|
opsional PrecisionConfig
|
enum untuk tingkat presisi |
preferred_element_type
|
opsional PrimitiveType
|
enum jenis elemen skalar |
ConvGeneral
Lihat juga
XlaBuilder::ConvGeneral.
ConvGeneral(lhs, rhs, window_strides, padding, dimension_numbers,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Sama seperti Conv dengan konfigurasi padding dan nomor dimensi yang eksplisit
| Argumen | Jenis | Semantik |
|---|---|---|
lhs
|
XlaOp
|
Array input berdimensi (n+2) |
rhs
|
XlaOp
|
Array bobot kernel berdimensi (n+2) |
window_strides
|
ArraySlice<int64>
|
Array n-d dari langkah kernel |
padding
|
ArraySlice<
pair<int64,int64>>
|
Array n-d dari padding (rendah, tinggi) |
dimension_numbers
|
ConvolutionDimensionNumbers
|
jumlah dimensi |
feature_group_count
|
int64 | jumlah grup fitur |
batch_group_count
|
int64 | jumlah grup batch |
precision_config
|
opsional PrecisionConfig
|
enum untuk tingkat presisi |
preferred_element_type
|
opsional PrimitiveType
|
enum jenis elemen skalar |
ConvGeneralDilated
Lihat juga
XlaBuilder::ConvGeneralDilated.
ConvGeneralDilated(lhs, rhs, window_strides, padding, lhs_dilation,
rhs_dilation, dimension_numbers, feature_group_count, batch_group_count,
precision_config, preferred_element_type, window_reversal)
Sama seperti Conv dengan konfigurasi padding, faktor
dilasi, dan nomor dimensi yang eksplisit.
| Argumen | Jenis | Semantik |
|---|---|---|
lhs
|
XlaOp
|
Array input berdimensi (n+2) |
rhs
|
XlaOp
|
Array bobot kernel berdimensi (n+2) |
window_strides
|
ArraySlice<int64>
|
Array n-d dari langkah kernel |
padding
|
ArraySlice<
pair<int64,int64>>
|
Array n-d dari padding (rendah, tinggi) |
lhs_dilation
|
ArraySlice<int64>
|
n-d lhs dilation factor array |
rhs_dilation
|
ArraySlice<int64>
|
n-d rhs dilation factor array |
dimension_numbers
|
ConvolutionDimensionNumbers
|
jumlah dimensi |
feature_group_count
|
int64 | jumlah grup fitur |
batch_group_count
|
int64 | jumlah grup batch |
precision_config
|
opsional PrecisionConfig
|
enum untuk tingkat presisi |
preferred_element_type
|
opsional PrimitiveType
|
enum jenis elemen skalar |
window_reversal
|
opsional vector<bool>
|
flag yang digunakan untuk membalikkan dimensi secara logis sebelum menerapkan konvolusi |
Salin
Lihat juga
HloInstruction::CreateCopyStart.
Copy secara internal diuraikan menjadi 2 instruksi HLO CopyStart dan
CopyDone. Copy bersama dengan CopyStart dan CopyDone berfungsi sebagai primitif dalam
HLO. Operasi ini mungkin muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Cos
Lihat juga
XlaBuilder::Cos.
Kosine per elemen x -> cos(x).
Cos(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Cos juga mendukung argumen result_accuracy opsional:
Cos(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk mengetahui informasi StableHLO, lihat StableHLO - kosinus.
Cosh
Lihat juga
XlaBuilder::Cosh.
Kosinus hiperbolik per elemen x -> cosh(x).
Cosh(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Cosh juga mendukung argumen result_accuracy opsional:
Cosh(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
CustomCall
Lihat juga
XlaBuilder::CustomCall.
Panggil fungsi yang disediakan pengguna dalam komputasi.
Dokumentasi CustomCall disediakan di Detail developer - XLA Custom Calls
Untuk informasi StableHLO, lihat StableHLO - custom_call.
Div
Lihat juga
XlaBuilder::Div.
Melakukan pembagian per elemen dari dividen lhs dan pembagi rhs.
Div(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Overflow pembagian bilangan bulat (pembagian/sisa bertanda/tidak bertanda dengan nol atau pembagian/sisa bertanda INT_SMIN dengan -1) menghasilkan nilai yang ditentukan implementasi.
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda tersedia untuk Div:
Div(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - divide.
Domain
Lihat juga
HloInstruction::CreateDomain.
Domain mungkin muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Titik
Lihat juga
XlaBuilder::Dot.
Dot(lhs, rhs, precision_config, preferred_element_type)
| Argumen | Jenis | Semantik |
|---|---|---|
lhs |
XlaOp |
array jenis T |
rhs |
XlaOp |
array jenis T |
precision_config
|
opsional
PrecisionConfig |
enum untuk tingkat presisi |
preferred_element_type
|
opsional
PrimitiveType |
enum jenis elemen skalar |
Semantik persis dari operasi ini bergantung pada peringkat operan:
| Input | Output | Semantik |
|---|---|---|
vector [n] dot vector [n] |
skalar | perkalian titik vektor |
matriks [m x k] dot vector
[k] |
vektor [m] | perkalian matriks-vektor |
matriks [m x k] dot matriks
[k x n] |
matriks [m x n] | perkalian matriks-matriks |
Operasi ini melakukan jumlah produk di dimensi kedua lhs (atau
dimensi pertama jika memiliki 1 dimensi) dan dimensi pertama rhs. Ini adalah dimensi "dikecilkan". Dimensi yang dikontrak dari lhs dan rhs harus berukuran sama. Dalam praktiknya, fungsi ini dapat digunakan untuk melakukan produk titik antara vektor, perkalian vektor/matriks, atau perkalian matriks/matriks.
precision_config digunakan untuk menunjukkan konfigurasi presisi. Tingkat
menentukan apakah hardware harus mencoba membuat lebih banyak petunjuk kode mesin
untuk memberikan emulasi dtype yang lebih akurat jika diperlukan (yaitu,
mengemulasi f32 di TPU yang hanya mendukung matmul bf16). Nilainya dapat berupa
DEFAULT, HIGH, HIGHEST. Detail tambahan
di bagian MXU.
preferred_element_type adalah elemen skalar dari jenis output presisi yang lebih tinggi/rendah yang digunakan untuk akumulasi. preferred_element_type merekomendasikan jenis akumulasi untuk operasi tertentu, tetapi tidak dijamin. Hal ini memungkinkan beberapa backend hardware untuk mengakumulasi dalam jenis yang berbeda dan mengonversi ke jenis output yang diinginkan.
Untuk mengetahui informasi StableHLO, lihat StableHLO - dot.
DotGeneral
Lihat juga
XlaBuilder::DotGeneral.
DotGeneral(lhs, rhs, dimension_numbers, precision_config,
preferred_element_type)
| Argumen | Jenis | Semantik |
|---|---|---|
lhs |
XlaOp |
array jenis T |
rhs |
XlaOp |
array jenis T |
dimension_numbers
|
DotDimensionNumbers
|
nomor dimensi batch dan kontraksi |
precision_config
|
opsional
PrecisionConfig |
enum untuk tingkat presisi |
preferred_element_type
|
opsional
PrimitiveType |
enum jenis elemen skalar |
Mirip dengan Dot, tetapi memungkinkan angka dimensi batch dan kontraksi ditentukan untuk lhs dan rhs.
| Kolom DotDimensionNumbers | Jenis | Semantik |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | lhs angka dimensi
penyusutan |
rhs_contracting_dimensions
|
repeated int64 | rhs angka dimensi
penyusutan |
lhs_batch_dimensions
|
repeated int64 | lhs nomor dimensi batch |
rhs_batch_dimensions
|
repeated int64 | rhs nomor dimensi batch |
DotGeneral melakukan penjumlahan produk pada dimensi kontraksi yang ditentukan dalam
dimension_numbers.
Nomor dimensi kontraksi terkait dari lhs dan rhs tidak harus sama, tetapi harus memiliki ukuran dimensi yang sama.
Contoh dengan angka dimensi yang menyusut:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { { 6.0, 12.0},
{15.0, 30.0} }
Nomor dimensi batch terkait dari lhs dan rhs harus memiliki ukuran dimensi yang sama.
Contoh dengan angka dimensi tumpukan (ukuran tumpukan 2, matriks 2x2):
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> {
{ {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| Input | Output | Semantik |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | batch matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | batch matmul |
Dengan demikian, nomor dimensi yang dihasilkan dimulai dengan dimensi batch,
kemudian dimensi lhs non-batch/non-kontrak, dan terakhir dimensi rhs
non-batch/non-kontrak.
precision_config digunakan untuk menunjukkan konfigurasi presisi. Tingkat
menentukan apakah hardware harus mencoba membuat lebih banyak petunjuk kode mesin
untuk memberikan emulasi dtype yang lebih akurat jika diperlukan (yaitu,
mengemulasi f32 di TPU yang hanya mendukung matmul bf16). Nilainya dapat berupa
DEFAULT, HIGH, HIGHEST. Detail tambahan
dapat ditemukan di bagian MXU.
preferred_element_type adalah elemen skalar dari jenis output presisi yang lebih tinggi/rendah yang digunakan untuk akumulasi. preferred_element_type merekomendasikan jenis akumulasi untuk operasi tertentu, tetapi tidak dijamin. Hal ini memungkinkan beberapa backend hardware untuk mengakumulasi dalam jenis yang berbeda dan mengonversi ke jenis output yang diinginkan.
Untuk mengetahui informasi StableHLO, lihat StableHLO - dot_general.
ScaledDot
Lihat juga
XlaBuilder::ScaledDot.
ScaledDot(lhs, lhs_scale, rhs, rhs_scale, dimension_number,
precision_config,preferred_element_type)
| Argumen | Jenis | Semantik |
|---|---|---|
lhs |
XlaOp |
array jenis T |
rhs |
XlaOp |
array jenis T |
lhs_scale |
XlaOp |
array jenis T |
rhs_scale |
XlaOp |
array jenis T |
dimension_number
|
ScatterDimensionNumbers
|
Angka dimensi untuk operasi sebar |
precision_config
|
PrecisionConfig
|
enum untuk tingkat presisi |
preferred_element_type
|
opsional PrimitiveType
|
enum jenis elemen skalar |
Mirip dengan DotGeneral.
Membuat operasi dot yang diskalakan dengan operan 'lhs', 'lhs_scale', 'rhs', dan 'rhs_scale', dengan dimensi batch dan kontraksi yang ditentukan dalam 'dimension_numbers'.
RaggedDot
Lihat juga
XlaBuilder::RaggedDot.
Untuk perincian komputasi RaggedDot, lihat
StableHLO - chlo.ragged_dot
DynamicReshape
Lihat juga
XlaBuilder::DynamicReshape.
Operasi ini secara fungsional identik dengan reshape, tetapi bentuk hasil ditentukan secara dinamis melalui output_shape.
DynamicReshape(operand, dim_sizes, new_size_bounds, dims_are_dynamic)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array berdimensi N dari jenis T |
dim_sizes |
vektor XlaOP |
Ukuran vektor N dimensi |
new_size_bounds |
vektor int63 |
Vektor batas N dimensi |
dims_are_dynamic |
vektor bool |
Dimensi dinamis N dimensi |
Untuk informasi StableHLO, lihat StableHLO - dynamic_reshape.
DynamicSlice
Lihat juga
XlaBuilder::DynamicSlice.
DynamicSlice mengekstrak sub-array dari array input pada indeks dinamis
start_indices. Ukuran irisan di setiap dimensi diteruskan dalam
size_indices, yang menentukan titik akhir interval irisan eksklusif di setiap
dimensi: [start, start + size). Bentuk start_indices harus 1 dimensi, dengan ukuran dimensi yang sama dengan jumlah dimensi operand.
DynamicSlice(operand, start_indices, slice_sizes)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array berdimensi N dari jenis T |
start_indices
|
urutan N XlaOp
|
Daftar N bilangan bulat skalar yang berisi indeks awal slice untuk setiap dimensi. Nilai harus lebih besar dari atau sama dengan nol. |
size_indices
|
ArraySlice<int64>
|
Daftar N bilangan bulat yang berisi ukuran slice untuk setiap dimensi. Setiap nilai harus lebih besar dari nol, dan start + size harus kurang dari atau sama dengan ukuran dimensi untuk menghindari penggabungan ukuran dimensi modulo. |
Indeks irisan efektif dihitung dengan menerapkan transformasi berikut untuk setiap indeks i dalam [1, N) sebelum melakukan irisan:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - slice_sizes[i])
Hal ini memastikan bahwa slice yang diekstrak selalu berada dalam batas sehubungan dengan array operand. Jika slice berada dalam batas sebelum transformasi diterapkan, transformasi tidak akan berpengaruh.
Contoh 1 dimensi:
let a = {0.0, 1.0, 2.0, 3.0, 4.0};
let s = {2};
DynamicSlice(a, s, {2});
// Result: {2.0, 3.0}
Contoh 2 dimensi:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2});
//Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
Untuk informasi StableHLO, lihat StableHLO - dynamic_slice.
DynamicUpdateSlice
Lihat juga
XlaBuilder::DynamicUpdateSlice.
DynamicUpdateSlice menghasilkan hasil yang merupakan nilai array input
operand, dengan slice update yang diganti di start_indices.
Bentuk update menentukan bentuk sub-array hasil yang diperbarui.
Bentuk start_indices harus 1 dimensi, dengan ukuran dimensi yang sama dengan
jumlah dimensi operand.
DynamicUpdateSlice(operand, update, start_indices)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array berdimensi N dari jenis T |
update
|
XlaOp
|
Array N dimensi berjenis T yang berisi update slice. Setiap dimensi bentuk update harus lebih besar dari nol, dan start + update harus kurang dari atau sama dengan ukuran operand untuk setiap dimensi guna menghindari pembuatan indeks update di luar batas. |
start_indices
|
urutan N XlaOp
|
Daftar N bilangan bulat skalar yang berisi indeks awal slice untuk setiap dimensi. Nilai harus lebih besar dari atau sama dengan nol. |
Indeks irisan efektif dihitung dengan menerapkan transformasi berikut untuk setiap indeks i dalam [1, N) sebelum melakukan irisan:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
Hal ini memastikan bahwa slice yang diperbarui selalu berada dalam batas sehubungan dengan array operand. Jika irisan berada dalam batas sebelum transformasi diterapkan, transformasi tidak akan berpengaruh.
Contoh 1 dimensi:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s)
// Result: {0.0, 1.0, 5.0, 6.0, 4.0}
Contoh 2 dimensi:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s)
// Result:
// { {0.0, 1.0, 2.0},
// {3.0, 12.0, 13.0},
// {6.0, 14.0, 15.0},
// {9.0, 16.0, 17.0} }
Untuk informasi StableHLO, lihat StableHLO - dynamic_update_slice.
Erf
Lihat juga
XlaBuilder::Erf.
Fungsi error per elemen x -> erf(x) dengan:
\(\text{erf}(x) = \frac{2}{\sqrt{\pi} }\int_0^x e^{-t^2} \, dt\).
Erf(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Erf juga mendukung argumen result_accuracy opsional:
Erf(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Berakhir
Lihat juga
XlaBuilder::Exp.
Eksponensial alami per elemen x -> e^x.
Exp(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Exp juga mendukung argumen result_accuracy opsional:
Exp(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - eksponensial.
Expm1
Lihat juga
XlaBuilder::Expm1.
Eksponensial alami per elemen dikurangi satu x -> e^x - 1.
Expm1(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Expm1 juga mendukung argumen result_accuracy opsional:
Expm1(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - exponential_minus_one.
Fft
Lihat juga
XlaBuilder::Fft.
Operasi FFT XLA mengimplementasikan Transformasi Fourier maju dan invers untuk input/output real dan kompleks. FFT multidimensi hingga 3 sumbu didukung.
Fft(operand, ftt_type, fft_length)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp
|
Array yang kita lakukan transformasi Fourier. |
fft_type |
FftType |
Lihat tabel di bawah. |
fft_length
|
ArraySlice<int64>
|
Panjang domain waktu
sumbu yang
ditransformasikan. Hal ini
khususnya diperlukan untuk
IRFFT guna menyesuaikan ukuran
sumbu paling dalam, karena
RFFT(fft_length=[16])
memiliki bentuk
output yang sama dengan
RFFT(fft_length=[17]). |
FftType |
Semantik |
|---|---|
FFT |
FFT kompleks-ke-kompleks maju. Bentuk tidak berubah. |
IFFT |
FFT kompleks-ke-kompleks terbalik. Bentuk tidak berubah. |
RFFT
|
FFT riil ke kompleks. Bentuk sumbu paling dalam dikurangi menjadi fft_length[-1] // 2 + 1 jika fft_length[-1] adalah nilai bukan nol, dengan menghilangkan bagian konjugat terbalik dari sinyal yang diubah di luar frekuensi Nyquist. |
IRFFT
|
FFT riil ke kompleks terbalik (yaitu mengambil kompleks, menampilkan riil).
Bentuk sumbu paling dalam diperluas menjadi fft_length[-1] jika
fft_length[-1] adalah nilai bukan nol, menyimpulkan bagian sinyal yang
ditransformasikan di luar frekuensi Nyquist dari konjugat
terbalik dari entri 1 hingga fft_length[-1] // 2 + 1. |
Untuk informasi StableHLO, lihat StableHLO - fft.
FFT Multidimensi
Jika lebih dari 1 fft_length diberikan, hal ini setara dengan menerapkan serangkaian operasi FFT ke setiap sumbu paling dalam. Perhatikan bahwa untuk kasus real->kompleks dan kompleks->real, transformasi sumbu paling dalam (secara efektif) dilakukan terlebih dahulu (RFFT; terakhir untuk IRFFT), itulah sebabnya sumbu paling dalam adalah sumbu yang mengubah ukuran. Transformasi sumbu lainnya kemudian akan menjadi
kompleks->kompleks.
Detail implementasi
FFT CPU didukung oleh TensorFFT Eigen. FFT GPU menggunakan cuFFT.
Lantai
Lihat juga
XlaBuilder::Floor.
Floor per elemen x -> ⌊x⌋.
Floor(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk mengetahui informasi StableHLO, lihat StableHLO - floor.
Fusion
Lihat juga
HloInstruction::CreateFusion.
Operasi Fusion merepresentasikan instruksi HLO dan berfungsi sebagai primitif di HLO.
Op ini dapat muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual
oleh pengguna akhir.
Mengumpulkan
Operasi pengumpulan XLA menggabungkan beberapa slice (setiap slice pada offset runtime yang berpotensi berbeda) dari array input.
Untuk informasi StableHLO, lihat StableHLO - gather.
Semantik Umum
Lihat juga
XlaBuilder::Gather.
Untuk deskripsi yang lebih intuitif, lihat bagian "Deskripsi Informal" di bawah.
gather(operand, start_indices, dimension_numbers, slice_sizes,
indices_are_sorted)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp
|
Array yang kita kumpulkan dari. |
start_indices
|
XlaOp
|
Array yang berisi indeks awal slice yang kami kumpulkan. |
dimension_numbers
|
GatherDimensionNumbers
|
Dimensi di
start_indices yang
"berisi" indeks
awal. Lihat di bawah untuk
deskripsi mendetail. |
slice_sizes
|
ArraySlice<int64>
|
slice_sizes[i] adalah
batas untuk irisan pada
dimensi i. |
indices_are_sorted
|
bool
|
Apakah indeks dijamin diurutkan oleh pemanggil. |
Untuk mempermudah, kita memberi label dimensi dalam array output yang tidak ada di offset_dims
sebagai batch_dims.
Outputnya adalah array dengan dimensi batch_dims.size + offset_dims.size.
operand.rank harus sama dengan jumlah offset_dims.size dan
collapsed_slice_dims.size. Selain itu, slice_sizes.size harus sama dengan
operand.rank.
Jika index_vector_dim sama dengan start_indices.rank, kita secara implisit menganggap
start_indices memiliki dimensi 1 di belakang (yaitu, jika start_indices berbentuk
[6,7] dan index_vector_dim adalah 2, kita secara implisit menganggap
bentuk start_indices adalah [6,7,1]).
Batas untuk array output di sepanjang dimensi i dihitung sebagai berikut:
Jika
iada dibatch_dims(yaitu sama denganbatch_dims[k]untuk beberapak), kita akan memilih batas dimensi yang sesuai daristart_indices.shape, dengan melewatiindex_vector_dim(yaitu memilihstart_indices.shape.dims[k] jikak<index_vector_dimdanstart_indices.shape.dims[k+1] jika tidak).Jika
iada dioffset_dims(yaitu sama denganoffset_dims[k] untuk beberapak), kita akan memilih batas yang sesuai darislice_sizessetelah memperhitungkancollapsed_slice_dims(yaitu kita memilihadjusted_slice_sizes[k] denganadjusted_slice_sizesadalahslice_sizesdengan batas pada indekscollapsed_slice_dimsdihapus).
Secara formal, indeks operand In yang sesuai dengan indeks output Out tertentu dihitung sebagai berikut:
Misalkan
G= {Out[k] forkinbatch_dims}. GunakanGuntuk memotong vektorSsehinggaS[i] =start_indices[Combine(G,i)] dengan Combine(A, b) menyisipkan b pada posisiindex_vector_dimke dalam A. Perhatikan bahwa hal ini didefinisikan dengan baik meskipunGkosong: JikaGkosong, makaS=start_indices.Buat indeks awal,
Sin, ke dalamoperandmenggunakanSdengan menyebarkanSmenggunakanstart_index_map. Lebih tepatnya:Sin[start_index_map[k]] =S[k] jikak<start_index_map.size.Sin[_] =0jika tidak.
Buat indeks
Oinke dalamoperanddengan menyebarkan indeks pada dimensi offset diOutsesuai dengan setcollapsed_slice_dims. Lebih tepatnya:Oin[remapped_offset_dims(k)] =Out[offset_dims[k]] jikak<offset_dims.size(remapped_offset_dimsditentukan di bawah).Oin[_] =0jika tidak.
InadalahOin+Sindengan + adalah penambahan per elemen.
remapped_offset_dims adalah fungsi monoton dengan domain [0, offset_dims.size) dan rentang [0, operand.rank) \ collapsed_slice_dims. Jadi, jika misalnya, offset_dims.size adalah 4, operand.rank adalah 6, dan
collapsed_slice_dims adalah {0, 2}, maka remapped_offset_dims adalah {0→1,
1→3, 2→4, 3→5}.
Jika indices_are_sorted disetel ke benar (true), XLA dapat mengasumsikan bahwa start_indices
diurutkan (dalam urutan menaik, setelah menyebarkan nilainya sesuai dengan
start_index_map) oleh pengguna. Jika tidak, semantiknya ditentukan oleh implementasi.
Deskripsi dan Contoh Tidak Resmi
Secara informal, setiap indeks Out dalam array output sesuai dengan elemen E
dalam array operand, yang dihitung sebagai berikut:
Kita menggunakan dimensi batch di
Outuntuk mencari indeks awal daristart_indices.Kita menggunakan
start_index_mapuntuk memetakan indeks awal (yang ukurannya mungkin kurang dari operand.rank) ke indeks awal "penuh" ke dalamoperand.Kita memotong secara dinamis slice dengan ukuran
slice_sizesmenggunakan indeks awal penuh.Kita mengubah bentuk slice dengan menciutkan dimensi
collapsed_slice_dims. Karena semua dimensi slice yang diciutkan harus memiliki batas 1, perubahan bentuk ini selalu valid.Kita menggunakan dimensi offset di
Outuntuk mengindeks ke dalam slice ini guna mendapatkan elemen input,E, yang sesuai dengan indeks outputOut.
index_vector_dim ditetapkan ke start_indices.rank - 1 di semua contoh
berikutnya. Nilai index_vector_dim yang lebih menarik tidak mengubah
operasi secara mendasar, tetapi membuat representasi visual lebih rumit.
Untuk mendapatkan intuisi tentang cara semua hal di atas cocok, mari kita lihat contoh yang mengumpulkan 5 slice bentuk [8,6] dari array [16,11]. Posisi slice ke dalam array [16,11] dapat direpresentasikan sebagai vektor indeks bentuk S64[2], sehingga kumpulan 5 posisi dapat direpresentasikan sebagai array S64[5,2].
Perilaku operasi pengumpulan kemudian dapat digambarkan sebagai transformasi indeks yang mengambil [G,O0,O1], indeks dalam bentuk output, dan memetakannya ke elemen dalam array input dengan cara berikut:

Pertama, kita memilih vektor (X,Y) dari array indeks pengumpulan menggunakan G.
Elemen dalam array output pada indeks
[G,O0,O1] kemudian menjadi elemen dalam array input
pada indeks [X+O0,Y+O1].
slice_sizes adalah [8,6], yang menentukan rentang O0 dan
O1, dan ini pada gilirannya menentukan batas irisan.
Operasi pengumpulan ini berfungsi sebagai irisan dinamis batch dengan G sebagai dimensi batch.
Indeks pengumpulan dapat berupa multidimensi. Misalnya, versi contoh di atas yang lebih umum menggunakan array "kumpulkan indeks" dengan bentuk [4,5,2] akan menerjemahkan indeks seperti ini:

Sekali lagi, ini bertindak sebagai irisan dinamis batch G0 dan
G1 sebagai dimensi batch. Ukuran irisan masih [8,6].
Operasi pengumpulan di XLA menggeneralisasi semantik informal yang diuraikan di atas dengan cara berikut:
Kita dapat mengonfigurasi dimensi mana dalam bentuk output yang merupakan dimensi offset (dimensi yang berisi
O0,O1dalam contoh terakhir). Dimensi batch output (dimensi yang berisiG0,G1dalam contoh terakhir) ditentukan sebagai dimensi output yang bukan dimensi offset.Jumlah dimensi offset output yang secara eksplisit ada dalam bentuk output mungkin lebih kecil daripada jumlah dimensi input. Dimensi "yang tidak ada" ini, yang tercantum secara eksplisit sebagai
collapsed_slice_dims, harus memiliki ukuran irisan1. Karena memiliki ukuran slice1, satu-satunya indeks yang valid untuknya adalah0dan menghilangkannya tidak menimbulkan ambiguitas.Slice yang diekstrak dari array "Kumpulkan Indeks" ((
X,Y) dalam contoh terakhir) mungkin memiliki lebih sedikit elemen daripada jumlah dimensi array input, dan pemetaan eksplisit menentukan cara indeks harus diperluas agar memiliki jumlah dimensi yang sama dengan input.
Sebagai contoh terakhir, kita menggunakan (2) dan (3) untuk menerapkan tf.gather_nd:

G0 dan G1 digunakan untuk memotong indeks awal
dari array indeks pengumpulan seperti biasa, kecuali indeks awal hanya memiliki satu
elemen, X. Demikian pula, hanya ada satu indeks offset output dengan nilai
O0. Namun, sebelum digunakan sebagai indeks ke dalam array input, indeks ini diperluas sesuai dengan "Gather Index Mapping" (start_index_map dalam deskripsi formal) dan "Offset Mapping" (remapped_offset_dims dalam deskripsi formal) menjadi [X,0] dan [0,O0], masing-masing, yang berjumlah [X,O0]. Dengan kata lain, indeks output [G0,G1,O0] dipetakan ke indeks input [GatherIndices[G0,G1,0],O0] yang memberikan semantik untuk tf.gather_nd.
slice_sizes untuk kasus ini adalah [1,11]. Secara intuitif, ini berarti setiap
indeks X dalam array indeks pengumpulan memilih seluruh baris dan hasilnya adalah
penggabungan semua baris ini.
GetDimensionSize
Lihat juga
XlaBuilder::GetDimensionSize.
Menampilkan ukuran dimensi operand yang diberikan. Operand harus berbentuk array.
GetDimensionSize(operand, dimension)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array input dimensi n |
dimension
|
int64
|
Nilai dalam interval [0, n) yang menentukan
dimensi |
Untuk informasi StableHLO, lihat StableHLO - get_dimension_size.
GetTupleElement
Lihat juga
XlaBuilder::GetTupleElement.
Mengindeks ke dalam tuple dengan nilai konstanta waktu kompilasi.
Nilai harus berupa konstanta waktu kompilasi sehingga inferensi bentuk dapat menentukan jenis nilai yang dihasilkan.
Hal ini analog dengan std::get<int N>(t) di C++. Secara konseptual:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
Lihat juga tf.tuple.
GetTupleElement(tuple_data, index)
| Argumen | Jenis | Semantik |
|---|---|---|
tuple_data |
XlaOP |
Tuple |
index |
int64 |
Indeks bentuk tuple |
Untuk informasi StableHLO, lihat StableHLO - get_tuple_element.
Imag
Lihat juga
XlaBuilder::Imag.
Bagian imajiner elemen-bijaksana dari bentuk kompleks (atau riil). x -> imag(x). Jika
operand adalah jenis floating point, fungsi ini akan menampilkan 0.
Imag(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - imag.
Dalam feed
Lihat juga
XlaBuilder::Infeed.
Infeed(shape, config)
| Argumen | Jenis | Semantik |
|---|---|---|
shape
|
Shape
|
Bentuk data yang dibaca dari antarmuka In-feed. Kolom tata letak bentuk harus ditetapkan agar cocok dengan tata letak data yang dikirim ke perangkat; jika tidak, perilakunya tidak terdefinisi. |
config |
opsional string |
Konfigurasi op. |
Membaca satu item data dari antarmuka streaming In-feed implisit
perangkat, menafsirkan data sebagai bentuk dan tata letaknya yang diberikan, serta menampilkan
XlaOp data. Beberapa operasi Infeed diizinkan dalam komputasi,
tetapi harus ada total urutan di antara operasi Infeed. Misalnya, dua
Infeed dalam kode di bawah memiliki urutan total karena ada dependensi
antara loop while.
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
Bentuk tuple bertingkat tidak didukung. Untuk bentuk tuple kosong, operasi Infeed secara efektif tidak melakukan apa pun dan berlanjut tanpa membaca data apa pun dari Infeed perangkat.
Untuk informasi StableHLO, lihat StableHLO - infeed.
Iota
Lihat juga
XlaBuilder::Iota.
Iota(shape, iota_dimension)
Membangun literal konstanta di perangkat, bukan transfer host yang berpotensi besar. Membuat array yang memiliki bentuk yang ditentukan dan menyimpan nilai yang dimulai dari nol dan bertambah satu di sepanjang dimensi yang ditentukan. Untuk jenis floating point, array yang dihasilkan setara dengan ConvertElementType(Iota(...)) dengan Iota berjenis integral dan konversinya adalah ke jenis floating point.
| Argumen | Jenis | Semantik |
|---|---|---|
shape |
Shape |
Bentuk array yang dibuat oleh Iota() |
iota_dimension |
int64 |
Dimensi yang akan ditambahkan. |
Misalnya, Iota(s32[4, 8], 0) akan menampilkan
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
Pengembalian dengan biaya Iota(s32[4, 8], 1)
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
Untuk informasi StableHLO, lihat StableHLO - iota.
IsFinite
Lihat juga
XlaBuilder::IsFinite.
Menguji apakah setiap elemen operand terbatas, yaitu bukan nilai tak terbatas positif atau negatif, dan bukan NaN. Menampilkan array nilai PRED dengan
bentuk yang sama dengan input, dengan setiap elemen adalah true jika dan hanya jika
elemen input yang sesuai adalah terbatas.
IsFinite(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - is_finite.
Log
Lihat juga
XlaBuilder::Log.
Logaritma natural per elemen x -> ln(x).
Log(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Log juga mendukung argumen result_accuracy opsional:
Log(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - log.
Log1p
Lihat juga
XlaBuilder::Log1p.
Logaritma natural yang digeser menurut elemen x -> ln(1+x).
Log1p(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Log1p juga mendukung argumen result_accuracy opsional:
Log1p(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - log_plus_one.
Logistik
Lihat juga
XlaBuilder::Logistic.
Penghitungan fungsi logistik per elemen x -> logistic(x).
Logistic(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Logistic juga mendukung argumen result_accuracy opsional:
Logistic(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk mengetahui informasi StableHLO, lihat StableHLO - logistik.
Peta
Lihat juga
XlaBuilder::Map.
Map(operands..., computation, dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
operands |
urutan XlaOp N |
Array N dari jenis T0..T{N-1} |
computation
|
XlaComputation
|
Komputasi jenis T_0, T_1,
.., T_{N + M -1} -> S dengan N
parameter jenis T dan M jenis
arbitrary. |
dimensions |
Array int64 |
Array dimensi peta |
static_operands
|
urutan XlaOp N
|
Operasi statis untuk operasi peta |
Menerapkan fungsi skalar pada array operands yang diberikan, menghasilkan array dengan dimensi yang sama di mana setiap elemen adalah hasil dari fungsi yang dipetakan yang diterapkan ke elemen yang sesuai dalam array input.
Fungsi yang dipetakan adalah komputasi arbitrer dengan batasan bahwa fungsi tersebut memiliki
N input jenis skalar T dan satu output dengan jenis S. Output memiliki
dimensi yang sama dengan operand, kecuali jenis elemen T diganti
dengan S.
Misalnya: Map(op1, op2, op3, computation, par1) memetakan elem_out <-
computation(elem1, elem2, elem3, par1) di setiap indeks (multidimensi) dalam
array input untuk menghasilkan array output.
Untuk informasi StableHLO, lihat StableHLO - map.
Maks
Lihat juga
XlaBuilder::Max.
Melakukan operasi maks per elemen pada tensor lhs dan rhs.
Max(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran berdimensi berbeda tersedia untuk Max:
Max(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - maksimum.
Min
Lihat juga
XlaBuilder::Min.
Melakukan operasi min per elemen pada lhs dan rhs.
Min(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran berdimensi berbeda ada untuk Min:
Min(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - minimum.
Mul
Lihat juga
XlaBuilder::Mul.
Melakukan perkalian per elemen lhs dan rhs.
Mul(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk Mul:
Mul(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - multiply.
Neg
Lihat juga
XlaBuilder::Neg.
Negasi per elemen x -> -x.
Neg(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - negate
Tidak
Lihat juga
XlaBuilder::Not.
Logika not x -> !(x) per elemen.
Not(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - not.
OptimizationBarrier
Lihat juga
XlaBuilder::OptimizationBarrier.
Memblokir semua proses pengoptimalan agar tidak memindahkan komputasi melintasi penghalang.
OptimizationBarrier(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Memastikan bahwa semua input dievaluasi sebelum operator yang bergantung pada output penghalang.
Untuk informasi StableHLO, lihat StableHLO - optimization_barrier.
Atau
Lihat juga
XlaBuilder::Or.
Melakukan OR per elemen lhs dan rhs .
Or(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran berdimensi berbeda ada untuk Or:
Or(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk mengetahui informasi StableHLO, lihat StableHLO - or.
Keluar
Lihat juga
XlaBuilder::Outfeed.
Menulis input ke outfeed.
Outfeed(operand, shape_with_layout, outfeed_config)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis T |
shape_with_layout |
Shape |
Menentukan tata letak data yang ditransfer |
outfeed_config |
string |
Konstanta konfigurasi untuk instruksi Outfeed |
shape_with_layout mengomunikasikan bentuk yang telah diatur yang ingin kita keluarkan.
Untuk informasi StableHLO, lihat StableHLO - outfeed.
Bantalan
Lihat juga
XlaBuilder::Pad.
Pad(operand, padding_value, padding_config)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis T |
padding_value
|
XlaOp
|
skalar jenis T untuk mengisi padding yang ditambahkan |
padding_config
|
PaddingConfig
|
jumlah padding di kedua tepi (rendah, tinggi) dan di antara elemen setiap dimensi |
Memperluas array operand yang diberikan dengan padding di sekitar array serta di antara elemen array dengan padding_value yang diberikan. padding_config
menentukan jumlah padding tepi dan padding interior untuk setiap
dimensi.
PaddingConfig adalah kolom berulang dari PaddingConfigDimension, yang berisi
tiga kolom untuk setiap dimensi: edge_padding_low, edge_padding_high, dan
interior_padding.
edge_padding_low dan edge_padding_high menentukan jumlah padding yang ditambahkan di ujung bawah (di samping indeks 0) dan ujung atas (di samping indeks tertinggi) dari setiap dimensi. Jumlah padding tepi dapat negatif -- nilai absolut padding negatif menunjukkan jumlah elemen yang akan dihapus dari dimensi yang ditentukan.
interior_padding menentukan jumlah padding yang ditambahkan di antara dua
elemen dalam setiap dimensi; tidak boleh negatif. Padding interior terjadi secara logis sebelum padding tepi, jadi dalam kasus padding tepi negatif, elemen dihapus dari operand yang diberi padding interior.
Operasi ini tidak akan melakukan apa pun jika pasangan padding tepi semuanya (0, 0) dan nilai padding interior semuanya 0. Gambar di bawah menunjukkan contoh nilai edge_padding dan interior_padding yang berbeda untuk array dua dimensi.
Untuk informasi StableHLO, lihat StableHLO - pad.
Parameter
Lihat juga
XlaBuilder::Parameter.
Parameter merepresentasikan input argumen ke komputasi.
PartitionID
Lihat juga
XlaBuilder::BuildPartitionId.
Menghasilkan partition_id dari proses saat ini.
PartitionID(shape)
| Argumen | Jenis | Semantik |
|---|---|---|
shape |
Shape |
Bentuk data |
PartitionID dapat muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Untuk informasi StableHLO, lihat StableHLO - partition_id.
PopulationCount
Lihat juga
XlaBuilder::PopulationCount.
Menghitung jumlah bit yang ditetapkan di setiap elemen operand.
PopulationCount(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - popcnt.
Pow
Lihat juga
XlaBuilder::Pow.
Melakukan eksponensiasi per elemen lhs dengan rhs.
Pow(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran berdimensi berbeda tersedia untuk Pow:
Pow(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - power.
Real
Lihat juga
XlaBuilder::Real.
Bagian riil per elemen dari bentuk kompleks (atau riil). x -> real(x). Jika
operand adalah jenis floating point, Real akan menampilkan nilai yang sama.
Real(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk mengetahui informasi StableHLO, lihat StableHLO - real.
Recv
Lihat juga
XlaBuilder::Recv.
Recv, RecvWithTokens, dan RecvToHost adalah operasi yang berfungsi sebagai
primitif komunikasi di HLO. Operasi ini biasanya muncul dalam dump HLO sebagai bagian dari input/output tingkat rendah atau transfer lintas perangkat, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Recv(shape, handle)
| Argumen | Jenis | Semantik |
|---|---|---|
shape |
Shape |
bentuk data yang akan diterima |
handle |
ChannelHandle |
ID unik untuk setiap pasangan kirim/terima |
Menerima data dengan bentuk tertentu dari instruksi Send dalam komputasi lain yang menggunakan handle channel yang sama. Menampilkan
XlaOp untuk data yang diterima.
Untuk informasi StableHLO, lihat StableHLO - recv.
RecvDone
Lihat juga
HloInstruction::CreateRecv dan HloInstruction::CreateRecvDone.
Mirip dengan Send, API klien operasi Recv merepresentasikan komunikasi sinkron. Namun, petunjuk secara internal diuraikan menjadi 2 petunjuk HLO (Recv dan RecvDone) untuk memungkinkan transfer data asinkron.
Recv(const Shape& shape, int64 channel_id)
Mengalokasikan resource yang diperlukan untuk menerima data dari instruksi Send
dengan channel_id yang sama. Menampilkan konteks untuk resource yang dialokasikan, yang
digunakan oleh instruksi RecvDone berikutnya untuk menunggu penyelesaian
transfer data. Konteks adalah tuple {buffer penerima (bentuk), ID permintaan (U32)} dan hanya dapat digunakan oleh instruksi RecvDone.
Mengingat konteks yang dibuat oleh instruksi Recv, menunggu transfer data selesai dan menampilkan data yang diterima.
Reduce (Mengurangi)
Lihat juga
XlaBuilder::Reduce.
Menerapkan fungsi pengurangan ke satu atau beberapa array secara paralel.
Reduce(operands..., init_values..., computation, dimensions_to_reduce)
| Argumen | Jenis | Semantik |
|---|---|---|
operands
|
Urutan N XlaOp
|
N array jenis T_0,...,
T_{N-1}. |
init_values
|
Urutan N XlaOp
|
N skalar jenis
T_0,..., T_{N-1}. |
computation
|
XlaComputation
|
komputasi jenis
T_0,..., T_{N-1}, T_0,
...,T_{N-1} ->
Collate(T_0,...,
T_{N-1}). |
dimensions_to_reduce
|
Array int64
|
array dimensi yang tidak berurutan untuk dikurangi. |
Dengan:
- N harus lebih besar atau sama dengan 1.
- Komputasi harus bersifat asosiatif "secara kasar" (lihat di bawah).
- Semua array input harus memiliki dimensi yang sama.
- Semua nilai awal harus membentuk identitas di bawah
computation. - Jika
N = 1,Collate(T)adalahT. - Jika
N > 1,Collate(T_0, ..., T_{N-1})adalah tuple elemenNberjenisT.
Operasi ini mengurangi satu atau beberapa dimensi setiap array input menjadi skalar.
Jumlah dimensi setiap array yang ditampilkan adalah
number_of_dimensions(operand) - len(dimensions). Output op adalah
Collate(Q_0, ..., Q_N) dengan Q_i adalah array berjenis T_i, yang
dimensinya dijelaskan di bawah.
Backend yang berbeda diizinkan untuk mengaitkan kembali komputasi pengurangan. Hal ini dapat menyebabkan perbedaan numerik, karena beberapa fungsi pengurangan seperti penambahan tidak bersifat asosiatif untuk float. Namun, jika rentang datanya terbatas, penambahan bilangan floating point cukup dekat untuk menjadi asosiatif bagi sebagian besar penggunaan praktis.
Untuk informasi StableHLO, lihat StableHLO - reduce.
Contoh
Saat merampingkan di satu dimensi dalam satu array 1D dengan nilai [10, 11,
12, 13], dengan fungsi perampingan f (ini adalah computation), maka hal itu dapat
dihitung sebagai
f(10, f(11, f(12, f(init_value, 13)))
tetapi ada juga banyak kemungkinan lain, misalnya
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
Berikut adalah contoh pseudo-kode kasar tentang cara penerapan reduksi, menggunakan penjumlahan sebagai komputasi reduksi dengan nilai awal 0.
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the number of dimensions of the result.
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
Berikut contoh pengurangan array 2D (matriks). Bentuk memiliki 2 dimensi, dimensi 0 berukuran 2 dan dimensi 1 berukuran 3:
Hasil pengurangan dimensi 0 atau 1 dengan fungsi "add":
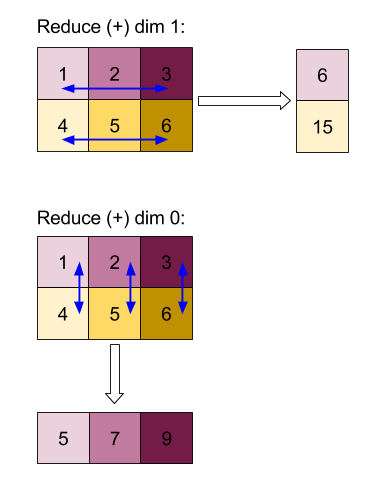
Perhatikan bahwa kedua hasil reduksi adalah array 1D. Diagram menampilkan satu sebagai kolom dan yang lain sebagai baris hanya untuk kemudahan visual.
Untuk contoh yang lebih kompleks, berikut adalah array 3D. Jumlah dimensinya adalah 3, dimensi 0 berukuran 4, dimensi 1 berukuran 2, dan dimensi 2 berukuran 3. Agar sederhana, nilai 1 hingga 6 direplikasi di seluruh dimensi 0.
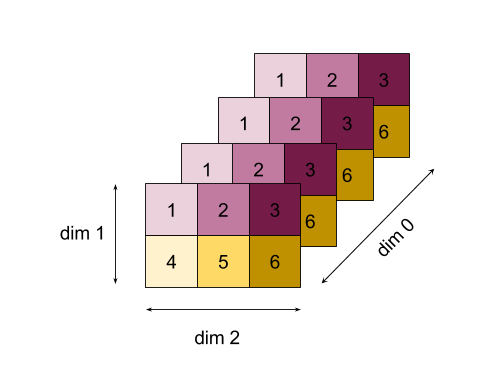
Mirip dengan contoh 2D, kita dapat mengurangi hanya satu dimensi. Jika kita mengurangi dimensi 0, misalnya, kita akan mendapatkan array 2 dimensi dengan semua nilai di dimensi 0 dilipat menjadi skalar:
| 4 8 12 |
| 16 20 24 |
Jika kita mengurangi dimensi 2, kita juga akan mendapatkan array 2 dimensi dengan semua nilai di seluruh dimensi 2 dilipat menjadi skalar:
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
Perhatikan bahwa urutan relatif antara dimensi yang tersisa dalam input dipertahankan dalam output, tetapi beberapa dimensi dapat diberi nomor baru (karena jumlah dimensi berubah).
Kita juga dapat mengurangi beberapa dimensi. Menambahkan dimensi 0 dan 1 yang mengurangi menghasilkan
array 1D [20, 28, 36].
Mengurangi array 3D di semua dimensinya akan menghasilkan skalar 84.
Reduksi Variadik
Saat N > 1, penerapan fungsi reduce sedikit lebih rumit, karena diterapkan secara bersamaan ke semua input. Operand diberikan ke
komputasi dalam urutan berikut:
- Menjalankan nilai yang dikurangi untuk operand pertama
- ...
- Menjalankan nilai yang dikurangi untuk operand ke-N
- Nilai input untuk operand pertama
- ...
- Nilai input untuk operan ke-N
Misalnya, pertimbangkan fungsi pengurangan berikut, yang dapat digunakan untuk menghitung maks dan argmaks array 1-D secara paralel:
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
Untuk array Input 1-D V = Float[N], K = Int[N], dan nilai init
I_V = Float, I_K = Int, hasil f_(N-1) dari pengurangan di seluruh
dimensi input saja setara dengan penerapan rekursif berikut:
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
Menerapkan reduksi ini ke array nilai, dan array indeks berurutan (yaitu iota), akan berulang-ulang di seluruh array, dan menampilkan tuple yang berisi nilai maksimum dan indeks yang cocok.
ReducePrecision
Lihat juga
XlaBuilder::ReducePrecision.
Memodelkan efek mengonversi nilai floating-point ke format presisi yang lebih rendah (seperti IEEE-FP16) dan kembali ke format asli. Jumlah bit eksponen dan mantisa dalam format presisi yang lebih rendah dapat ditentukan secara arbitrer, meskipun semua ukuran bit mungkin tidak didukung di semua implementasi hardware.
ReducePrecision(operand, exponent_bits, mantissa_bits)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis floating point T. |
exponent_bits |
int32 |
jumlah bit eksponen dalam format presisi yang lebih rendah |
mantissa_bits |
int32 |
jumlah bit mantisa dalam format presisi yang lebih rendah |
Hasilnya adalah array berjenis T. Nilai input dibulatkan ke nilai terdekat yang dapat direpresentasikan dengan jumlah bit mantisa yang diberikan (menggunakan semantik "ties to even"), dan nilai apa pun yang melebihi rentang yang ditentukan oleh jumlah bit eksponen akan di-clamp ke tak terhingga positif atau negatif. Nilai NaN dipertahankan, meskipun dapat dikonversi menjadi nilai NaN kanonis.
Format presisi yang lebih rendah harus memiliki setidaknya satu bit eksponen (untuk membedakan nilai nol dari tak hingga, karena keduanya memiliki mantisa nol), dan harus memiliki jumlah bit mantisa non-negatif. Jumlah bit eksponen atau mantisa dapat melebihi nilai yang sesuai untuk jenis T; bagian konversi yang sesuai kemudian hanyalah no-op.
Untuk informasi StableHLO, lihat StableHLO - reduce_precision.
ReduceScatter
Lihat juga
XlaBuilder::ReduceScatter.
ReduceScatter adalah operasi kolektif yang secara efektif melakukan AllReduce, lalu menyebarkan hasilnya dengan membaginya menjadi shard_count blok di sepanjang scatter_dimension dan replika i dalam grup replika menerima sharding ith.
ReduceScatter(operand, computation, scatter_dimension, shard_count,
replica_groups, channel_id, layout, use_global_device_ids)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp
|
Array atau tuple array yang tidak kosong untuk merampingkan di seluruh replika. |
computation |
XlaComputation |
Penghitungan pengurangan |
scatter_dimension |
int64 |
Dimensi untuk menyebarkan. |
shard_count
|
int64
|
Jumlah blok yang akan dibagi
scatter_dimension |
replica_groups
|
ReplicaGroup vektor
|
Grup yang menjadi tujuan pengurangan |
channel_id
|
opsional
ChannelHandle |
ID channel opsional untuk komunikasi lintas modul |
layout
|
opsional Layout
|
tata letak memori yang ditentukan pengguna |
use_global_device_ids |
opsional bool |
bendera yang ditentukan pengguna |
- Jika
operandadalah tuple array, reduce-scatter dilakukan pada setiap elemen tuple. replica_groupsadalah daftar grup replika yang di antaranya pengurangan dilakukan (ID replika untuk replika saat ini dapat diambil menggunakanReplicaId). Urutan replika di setiap grup menentukan urutan hasil pengurangan semua akan disebarkan.replica_groupsharus kosong (dalam hal ini semua replika termasuk dalam satu grup), atau berisi jumlah elemen yang sama dengan jumlah replika. Jika ada lebih dari satu grup replika, semuanya harus berukuran sama. Misalnya,replica_groups = {0, 2}, {1, 3}melakukan reduksi antara replika0dan2, serta1dan3, lalu menyebarkan hasilnya.shard_countadalah ukuran setiap grup replika. Kami memerlukan ini jikareplica_groupskosong. Jikareplica_groupstidak kosong,shard_countharus sama dengan ukuran setiap grup replika.channel_iddigunakan untuk komunikasi lintas modul: hanya operasireduce-scatterdenganchannel_idyang sama yang dapat berkomunikasi satu sama lain.layoutLihat xla::shapes untuk mengetahui informasi selengkapnya tentang tata letak.use_global_device_idsadalah tanda yang ditentukan pengguna. Jikafalse(default), angka dalamreplica_groupsadalahReplicaIdsaattrue,replica_groupsmewakili ID global (ReplicaID*partition_count+partition_id). Misalnya:- Dengan 2 replika dan 4 partisi,
- replica_groups={ {0,1,4,5},{2,3,6,7} } and use_global_device_ids=true
- group[0] = (0,0), (0,1), (1,0), (1,1)
- group[1] = (0,2), (0,3), (1,2), (1,3)
- dengan setiap pasangan adalah (replica_id, partition_id).
Bentuk output adalah bentuk input dengan scatter_dimension yang dibuat
shard_count kali lebih kecil. Misalnya, jika ada dua replika dan
operand masing-masing memiliki nilai [1.0, 2.25] dan [3.0, 5.25] pada kedua
replika, maka nilai output dari operasi ini dengan scatter_dim adalah 0 akan menjadi
[4.0] untuk replika pertama dan [7.5] untuk replika kedua.
Untuk informasi StableHLO, lihat StableHLO - reduce_scatter.
ReduceScatter - Contoh 1 - StableHLO

Pada contoh di atas, ada 2 replika yang berpartisipasi dalam ReduceScatter. Pada setiap replika, operand memiliki bentuk f32[2,4]. All-reduce (sum) dilakukan di seluruh replika, sehingga menghasilkan nilai yang dikurangi dengan bentuk f32[2,4] di setiap replika. Nilai yang dikurangi ini kemudian dibagi menjadi 2 bagian di sepanjang dimensi 1, sehingga setiap bagian memiliki bentuk f32[2,2]. Setiap replika dalam grup proses menerima bagian yang sesuai dengan posisinya dalam grup. Akibatnya, output pada setiap replika memiliki bentuk f32[2,2].
ReduceWindow
Lihat juga
XlaBuilder::ReduceWindow.
Menerapkan fungsi reduksi ke semua elemen di setiap jendela dari urutan N array multidimensi, menghasilkan satu atau tuple dari N array multidimensi sebagai output. Setiap array output memiliki jumlah elemen yang sama dengan jumlah posisi valid jendela. Lapisan penggabungan dapat dinyatakan sebagai
ReduceWindow. Mirip dengan Reduce, computation yang diterapkan selalu diteruskan ke init_values di sebelah kiri.
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| Argumen | Jenis | Semantik |
|---|---|---|
operands
|
N XlaOps
|
Urutan N
array multidimensi dari
jenis T_0,..., T_{N-1}, yang masing-masing
merepresentasikan area dasar tempat
jendela ditempatkan. |
init_values
|
N XlaOps
|
Nilai awal N untuk pengurangan, satu untuk setiap N operan. Lihat Mengurangi untuk mengetahui detailnya. |
computation
|
XlaComputation
|
Fungsi reduksi jenis T_0,
..., T_{N-1}, T_0, ..., T_{N-1}
-> Collate(T_0, ..., T_{N-1}),
untuk diterapkan ke elemen di setiap
jendela semua operan
input. |
window_dimensions
|
ArraySlice<int64>
|
array bilangan bulat untuk nilai dimensi jendela |
window_strides
|
ArraySlice<int64>
|
array bilangan bulat untuk nilai langkah jendela |
base_dilations
|
ArraySlice<int64>
|
array bilangan bulat untuk nilai pelebaran dasar |
window_dilations
|
ArraySlice<int64>
|
array bilangan bulat untuk nilai dilasi jendela |
padding
|
Padding
|
jenis padding untuk jendela (Padding::kSame, yang melakukan padding sehingga memiliki bentuk output yang sama dengan input jika langkahnya adalah 1, atau Padding::kValid, yang tidak menggunakan padding dan "menghentikan" jendela setelah tidak lagi sesuai) |
Dengan:
- N harus lebih besar atau sama dengan 1.
- Semua array input harus memiliki dimensi yang sama.
- Jika
N = 1,Collate(T)adalahT. - Jika
N > 1,Collate(T_0, ..., T_{N-1})adalah tuple elemenNberjenis(T0,...T{N-1}).
Untuk informasi StableHLO, lihat StableHLO - reduce_window.
ReduceWindow - Contoh 1
Input adalah matriks berukuran [4x6] dan window_dimensions serta window_stride_dimensions adalah [2x3].
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
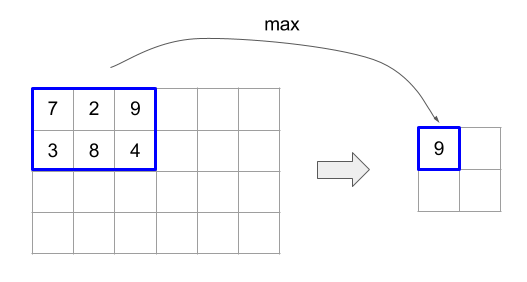
Stride 1 dalam dimensi menentukan bahwa posisi jendela dalam dimensi berjarak 1 elemen dari jendela yang berdekatan. Untuk menentukan bahwa tidak ada jendela yang tumpang-tindih, window_stride_dimensions harus sama dengan window_dimensions. Gambar di bawah mengilustrasikan penggunaan dua nilai stride yang berbeda. Padding diterapkan ke setiap dimensi input dan perhitungannya sama seperti jika input masuk dengan dimensi yang dimilikinya setelah padding.
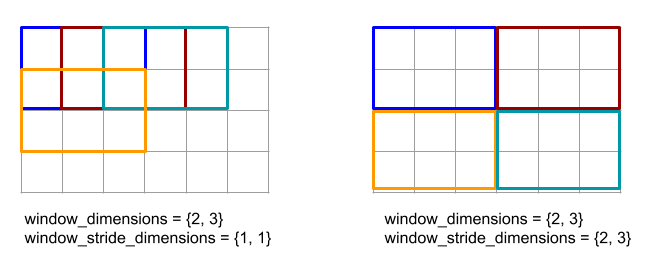
Untuk contoh padding yang tidak sepele, pertimbangkan untuk menghitung minimum reduce-window
(nilai awal adalah MAX_FLOAT) dengan dimensi 3 dan langkah 2 pada array
input [10000, 1000, 100, 10, 1]. Padding kValid menghitung nilai minimum di dua jendela
valid: [10000, 1000, 100] dan [100, 10, 1], sehingga menghasilkan
output [100, 1]. Padding kSame pertama-tama mengisi array sehingga bentuk setelah
reduce-window akan sama dengan input untuk langkah satu dengan menambahkan elemen
awal di kedua sisi, sehingga menghasilkan [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE]. Menjalankan reduce-window pada array yang di-padding beroperasi pada tiga
jendela [MAX_VALUE, 10000, 1000], [1000, 100, 10], [10, 1, MAX_VALUE], dan
menghasilkan [1000, 10, 1].
Urutan evaluasi fungsi pengurangan bersifat arbitrer dan mungkin
non-deterministik. Oleh karena itu, fungsi pengurangan tidak boleh terlalu sensitif terhadap pengaitan ulang. Lihat diskusi tentang asosiativitas dalam konteks Reduce untuk mengetahui detail selengkapnya.
ReduceWindow - Contoh 2 - StableHLO

Dalam contoh di atas:
Input) Operand memiliki bentuk input S32[3,2]. Dengan nilai
[[1,2],[3,4],[5,6]]
Langkah 1) Pelebaran dasar dengan faktor 2 di sepanjang dimensi baris menyisipkan lubang di antara setiap baris operand. Padding 2 baris di bagian atas dan 1 baris di bagian bawah diterapkan setelah dilatasi. Akibatnya, tensor menjadi lebih tinggi.
Langkah 2) Jendela berbentuk [2,1] ditentukan, dengan dilatasi jendela [3,1]. Artinya, setiap jendela memilih dua elemen dari kolom yang sama, tetapi elemen kedua diambil tiga baris di bawah elemen pertama, bukan tepat di bawahnya.
Langkah 3) Jendela kemudian digeser di seluruh operand dengan langkah [4,1]. Tindakan ini
akan memindahkan jendela ke bawah empat baris sekaligus, sambil menggeser satu kolom
sekaligus secara horizontal. Sel padding diisi dengan init_value (dalam hal ini init_value = 0). Nilai yang 'termasuk dalam' sel dilatasi diabaikan.
Karena langkah dan padding, beberapa jendela hanya tumpang-tindih dengan nol dan lubang,
sementara yang lain tumpang-tindih dengan nilai input sebenarnya.
Langkah 4) Dalam setiap jendela, elemen digabungkan menggunakan fungsi reduksi (a, b) → a + b, dimulai dari nilai awal 0. Dua jendela teratas hanya melihat padding dan lubang, sehingga hasilnya adalah 0. Jendela bawah mengambil nilai 3 dan 4 dari input dan menampilkannya sebagai hasil.
Hasil) Output akhir memiliki bentuk S32[2,2], dengan nilai: [[0,0],[3,4]]
Rem
Lihat juga
XlaBuilder::Rem.
Melakukan sisa pembagian per elemen dari dividen lhs dan pembagi rhs.
Tanda hasil diambil dari dividen, dan nilai absolut hasil selalu kurang dari nilai absolut pembagi.
Rem(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran multi-dimensi tersedia untuk Rem:
Rem(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - remainder.
ReplicaId
Lihat juga
XlaBuilder::ReplicaId.
Menampilkan ID unik (skalar U32) replika.
ReplicaId()
ID unik setiap replika adalah bilangan bulat tidak bertanda dalam interval [0, N),
dengan N adalah jumlah replika. Karena semua replika menjalankan program yang sama, panggilan ReplicaId() dalam program akan menampilkan nilai yang berbeda pada setiap replika.
Untuk informasi StableHLO, lihat StableHLO - replica_id.
Membentuk ulang
Lihat juga
XlaBuilder::Reshape.
dan operasi Collapse.
Membentuk ulang dimensi array menjadi konfigurasi baru.
Reshape(operand, dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis T |
dimensions |
int64 vektor |
vektor ukuran dimensi baru |
Secara konseptual, reshape terlebih dahulu meratakan array menjadi vektor satu dimensi dari nilai data, lalu menyempurnakan vektor ini menjadi bentuk baru. Argumen input adalah array arbitrer dari jenis T, vektor indeks dimensi konstanta waktu kompilasi, dan vektor ukuran dimensi konstanta waktu kompilasi untuk hasilnya. Vektor dimensions menentukan ukuran array output. Nilai pada indeks 0 dalam dimensions adalah ukuran dimensi 0, nilai pada indeks 1 adalah ukuran dimensi 1, dan seterusnya. Hasil kali dimensi dimensions harus sama dengan hasil kali ukuran dimensi operand. Saat menyempurnakan array yang diciutkan menjadi array multidimensi yang ditentukan oleh dimensions, dimensi dalam dimensions diurutkan dari yang paling lambat berubah (paling utama) hingga yang paling cepat berubah (paling kecil).
Misalnya, misalkan v adalah array 24 elemen:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
let v012_24 = Reshape(v, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
Sebagai kasus khusus, reshape dapat mengubah array elemen tunggal menjadi skalar dan sebaliknya. Misalnya,
Reshape(f32[1x1] { {5} }, {}) == 5;
Reshape(5, {1,1}) == f32[1x1] { {5} };
Untuk informasi StableHLO, lihat StableHLO - reshape.
Membentuk ulang (eksplisit)
Lihat juga
XlaBuilder::Reshape.
Reshape(shape, operand)
Operasi pembentukan ulang yang menggunakan bentuk target eksplisit.
| Argumen | Jenis | Semantik |
|---|---|---|
shape |
Shape |
Bentuk output jenis T |
operand |
XlaOp |
array jenis T |
Rev (mundur)
Lihat juga
XlaBuilder::Rev.
Rev(operand, dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
array jenis T |
dimensions |
ArraySlice<int64> |
dimensi yang akan dibalik |
Membalikkan urutan elemen dalam array operand di sepanjang dimensions yang ditentukan, sehingga menghasilkan array output dengan bentuk yang sama. Setiap elemen array
operand pada indeks multidimensi disimpan ke dalam array output pada indeks
yang diubah. Indeks multidimensi diubah dengan membalikkan
indeks di setiap dimensi yang akan dibalikkan (yaitu, jika dimensi berukuran N adalah salah satu
dimensi pembalik, indeks i-nya diubah menjadi N - 1 - i).
Salah satu penggunaan operasi Rev adalah untuk membalikkan array bobot konvolusi di sepanjang dua dimensi jendela selama komputasi gradien dalam jaringan neural.
Untuk informasi StableHLO, lihat StableHLO - reverse.
RngNormal
Lihat juga
XlaBuilder::RngNormal.
Membangun output dengan bentuk tertentu dengan angka acak yang dihasilkan mengikuti distribusi \(N(\mu, \sigma)\) normal. Parameter \(\mu\) dan \(\sigma\), serta bentuk output harus memiliki jenis elemen floating point. Selain itu, parameter harus bernilai skalar.
RngNormal(mu, sigma, shape)
| Argumen | Jenis | Semantik |
|---|---|---|
mu |
XlaOp |
Skalar jenis T yang menentukan rata-rata angka yang dihasilkan |
sigma
|
XlaOp
|
Skalar jenis T yang menentukan simpangan baku yang dihasilkan |
shape |
Shape |
Bentuk output jenis T |
Untuk informasi StableHLO, lihat StableHLO - rng.
RngUniform
Lihat juga
XlaBuilder::RngUniform.
Membangun output dengan bentuk tertentu dengan bilangan acak yang dihasilkan mengikuti distribusi seragam pada interval \([a,b)\). Parameter dan jenis elemen output harus berupa jenis boolean, jenis integral, atau jenis floating point, dan jenisnya harus konsisten. Backend CPU dan GPU saat ini hanya mendukung F64, F32, F16, BF16, S64, U64, S32, dan U32. Selain itu, parameter harus bernilai skalar. Jika \(b <= a\) hasilnya ditentukan oleh implementasi.
RngUniform(a, b, shape)
| Argumen | Jenis | Semantik |
|---|---|---|
a |
XlaOp |
Skalar jenis T yang menentukan batas bawah interval |
b |
XlaOp |
Skalar jenis T yang menentukan batas atas interval |
shape |
Shape |
Bentuk output jenis T |
Untuk informasi StableHLO, lihat StableHLO - rng.
RngBitGenerator
Lihat juga
XlaBuilder::RngBitGenerator.
Membuat output dengan bentuk tertentu yang diisi dengan bit acak seragam menggunakan algoritma yang ditentukan (atau default backend) dan menampilkan status yang diperbarui (dengan bentuk yang sama dengan status awal) dan data acak yang dihasilkan.
Status awal adalah status awal pembuatan angka acak saat ini. Bentuk yang diperlukan dan nilai yang valid bergantung pada algoritma yang digunakan.
Output dijamin menjadi fungsi deterministik dari status awal, tetapi tidak dijamin deterministik antara backend dan versi kompiler yang berbeda.
RngBitGenerator(algorithm, initial_state, shape)
| Argumen | Jenis | Semantik |
|---|---|---|
algorithm |
RandomAlgorithm |
Algoritma PRNG yang akan digunakan. |
initial_state |
XlaOp |
Status awal untuk algoritma PRNG. |
shape |
Shape |
Bentuk output untuk data yang dihasilkan. |
Nilai yang tersedia untuk algorithm:
rng_default: Algoritma khusus backend dengan persyaratan bentuk khusus backend.rng_three_fry: Algoritma PRNG berbasis penghitung ThreeFry. Bentukinitial_stateadalahu64[2]dengan nilai arbitrer. Salmon et al. SC 2011. Angka acak paralel: semudah 1, 2, 3.rng_philox: Algoritma Philox untuk menghasilkan angka acak secara paralel. Bentukinitial_stateadalahu64[3]dengan nilai arbitrer. Salmon et al. SC 2011. Parallel random numbers: as easy as 1, 2, 3.
Untuk informasi StableHLO, lihat StableHLO - rng_bit_generator.
RngGetAndUpdateState
Lihat juga
HloInstruction::CreateRngGetAndUpdateState.
API dari berbagai operasi Rng secara internal diuraikan menjadi petunjuk HLO
termasuk RngGetAndUpdateState.
RngGetAndUpdateState berfungsi sebagai primitif di HLO. Op ini dapat muncul dalam dump HLO, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Round
Lihat juga
XlaBuilder::Round.
Pembulatan per elemen, jika nilainya tepat di tengah, pembulatan dilakukan menjauhi nol.
Round(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
RoundNearestAfz
Lihat juga
XlaBuilder::RoundNearestAfz.
Melakukan pembulatan per elemen ke bilangan bulat terdekat, memisahkan ikatan dari nol.
RoundNearestAfz(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - round_nearest_afz.
RoundNearestEven
Lihat juga
XlaBuilder::RoundNearestEven.
Pembulatan per elemen, pembulatan ke bilangan genap terdekat.
RoundNearestEven(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - round_nearest_even.
Rsqrt
Lihat juga
XlaBuilder::Rsqrt.
Operasi kebalikan per elemen dari akar kuadrat x -> 1.0 / sqrt(x).
Rsqrt(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Rsqrt juga mendukung argumen result_accuracy opsional:
Rsqrt(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - rsqrt.
Periksa
Lihat juga
XlaBuilder::Scan.
Menerapkan fungsi pengurangan ke array di seluruh dimensi tertentu, yang menghasilkan status akhir dan array nilai median.
Scan(inputs..., inits..., to_apply, scan_dimension,
is_reverse, is_associative)
| Argumen | Jenis | Semantik |
|---|---|---|
inputs |
Urutan m XlaOp |
Array yang akan dipindai. |
inits |
Urutan k XlaOp |
Pengiriman awal. |
to_apply |
XlaComputation |
Komputasi jenis i_0, ..., i_{m-1}, c_0, ..., c_{k-1} -> (o_0, ..., o_{n-1}, c'_0, ..., c'_{k-1}). |
scan_dimension |
int64 |
Dimensi yang akan dipindai. |
is_reverse |
bool |
Jika benar (true), pindai dalam urutan terbalik. |
is_associative |
bool (tiga negara bagian) |
Jika benar, operasi bersifat asosiatif. |
Fungsi to_apply diterapkan secara berurutan ke elemen dalam inputs di sepanjang
scan_dimension. Jika is_reverse salah (false), elemen diproses dalam urutan
0 hingga N-1, dengan N adalah ukuran scan_dimension. Jika is_reverse adalah
true, elemen diproses dari N-1 hingga 0.
Fungsi to_apply mengambil operan m + k:
melemen saat ini dariinputs.kmembawa nilai dari langkah sebelumnya (atauinitsuntuk elemen pertama).
Fungsi to_apply menampilkan tuple nilai n + k:
nelemenoutputs.knilai bawaan baru.
Operasi Scan menghasilkan tuple nilai n + k:
- Array output
n, yang berisi nilai output untuk setiap langkah. - Nilai akhir
ksetelah memproses semua elemen.
Jenis input m harus cocok dengan jenis parameter m pertama dari
to_apply dengan dimensi pemindaian tambahan. Jenis output n harus cocok dengan jenis nilai yang ditampilkan n pertama dari to_apply dengan dimensi pemindaian tambahan. Dimensi pemindaian tambahan di antara semua input dan output harus memiliki
ukuran yang sama N. Jenis parameter k terakhir dan nilai yang ditampilkan dari
to_apply serta inisialisasi k harus cocok.
Misalnya (m, n, k == 1, N == 3), untuk carry awal i, masukkan [a, b, c],
fungsi f(x, c) -> (y, c'), dan scan_dimension=0, is_reverse=false:
- Langkah 0:
f(a, i) -> (y0, c0) - Langkah 1:
f(b, c0) -> (y1, c1) - Langkah 2:
f(c, c1) -> (y2, c2)
Output Scan adalah ([y0, y1, y2], c2).
Sebar
Lihat juga
XlaBuilder::Scatter.
Operasi sebar XLA menghasilkan urutan hasil yang merupakan nilai
dari array input operands, dengan beberapa slice (pada indeks yang ditentukan oleh
scatter_indices) diperbarui dengan urutan nilai dalam updates menggunakan
update_computation.
Scatter(operands..., scatter_indices, updates..., update_computation,
dimension_numbers, indices_are_sorted, unique_indices)
| Argumen | Jenis | Semantik |
|---|---|---|
operands |
Urutan N XlaOp |
N array jenis T_0, ..., T_N yang akan disebarkan. |
scatter_indices |
XlaOp |
Array yang berisi indeks awal slice yang harus disebarkan. |
updates |
Urutan N XlaOp |
N array jenis T_0, ..., T_N. updates[i] berisi nilai yang harus digunakan untuk menyebarkan operands[i]. |
update_computation |
XlaComputation |
Komputasi yang akan digunakan untuk menggabungkan nilai yang ada dalam array input dan update selama scatter. Penghitungan ini harus berjenis T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N). |
index_vector_dim |
int64 |
Dimensi dalam scatter_indices yang berisi indeks awal. |
update_window_dims |
ArraySlice<int64> |
Kumpulan dimensi dalam bentuk updates yang merupakan dimensi jendela. |
inserted_window_dims |
ArraySlice<int64> |
Kumpulan dimensi jendela yang harus dimasukkan ke dalam bentuk updates. |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
Peta dimensi dari indeks sebar ke ruang indeks operand. Array ini ditafsirkan sebagai pemetaan i ke scatter_dims_to_operand_dims[i] . Harus bersifat satu-ke-satu dan total. |
dimension_number |
ScatterDimensionNumbers |
Nomor dimensi untuk operasi sebar |
indices_are_sorted |
bool |
Apakah indeks dijamin diurutkan oleh pemanggil. |
unique_indices |
bool |
Apakah indeks dijamin unik oleh pemanggil. |
Dengan:
- N harus lebih besar atau sama dengan 1.
operands[0], ...,operands[N-1] harus memiliki dimensi yang sama.updates[0], ...,updates[N-1] harus memiliki dimensi yang sama.- Jika
N = 1,Collate(T)adalahT. - Jika
N > 1,Collate(T_0, ..., T_N)adalah tuple elemenNberjenisT.
Jika index_vector_dim sama dengan scatter_indices.rank, kita secara implisit menganggap
scatter_indices memiliki dimensi 1 di belakangnya.
Kita mendefinisikan update_scatter_dims berjenis ArraySlice<int64> sebagai kumpulan
dimensi dalam bentuk updates yang tidak ada dalam update_window_dims, dalam urutan
menaik.
Argumen scatter harus mengikuti batasan berikut:
Setiap array
updatesharus memiliki dimensiupdate_window_dims.size + scatter_indices.rank - 1.Batas dimensi
idi setiap arrayupdatesharus sesuai dengan berikut:- Jika
iada diupdate_window_dims(yaitu sama denganupdate_window_dims[k] untuk beberapak), maka batas dimensiidiupdatestidak boleh melebihi batasoperandyang sesuai setelah memperhitungkaninserted_window_dims(yaituadjusted_window_bounds[k], denganadjusted_window_boundsberisi batasoperanddengan batas pada indeksinserted_window_dimsdihapus). - Jika
iada diupdate_scatter_dims(yaitu sama denganupdate_scatter_dims[k] untuk beberapak), maka batas dimensiidiupdatesharus sama dengan batasscatter_indicesyang sesuai, dengan melewatiindex_vector_dim(yaituscatter_indices.shape.dims[k], jikak<index_vector_dimdanscatter_indices.shape.dims[k+1] jika tidak).
- Jika
update_window_dimsharus dalam urutan menaik, tidak memiliki nomor dimensi yang berulang, dan berada dalam rentang[0, updates.rank).inserted_window_dimsharus dalam urutan menaik, tidak memiliki nomor dimensi yang berulang, dan berada dalam rentang[0, operand.rank).operand.rankharus sama dengan jumlahupdate_window_dims.sizedaninserted_window_dims.size.scatter_dims_to_operand_dims.sizeharus sama denganscatter_indices.shape.dims[index_vector_dim], dan nilainya harus berada dalam rentang[0, operand.rank).
Untuk indeks U tertentu di setiap array updates, indeks I yang sesuai di
array operands yang sesuai tempat pembaruan ini harus diterapkan dihitung
sebagai berikut:
- Misalkan
G= {U[k] forkinupdate_scatter_dims}. GunakanGuntuk mencari vektor indeksSdalam arrayscatter_indicessehinggaS[i] =scatter_indices[Combine(G,i)] dengan Combine(A, b) menyisipkan b pada posisiindex_vector_dimke dalam A. - Buat indeks
SinkeoperandmenggunakanSdengan menyebarkanSmenggunakan petascatter_dims_to_operand_dims. Lebih formal:Sin[scatter_dims_to_operand_dims[k]] =S[k] ifk<scatter_dims_to_operand_dims.size.Sin[_] =0jika tidak.
- Buat indeks
Winke setiap arrayoperandsdengan menyebarkan indeks diupdate_window_dimsdalamUsesuai denganinserted_window_dims. Lebih formal:Win[window_dims_to_operand_dims(k)] =U[k] jikakada diupdate_window_dims, denganwindow_dims_to_operand_dimsadalah fungsi monoton dengan domain [0,update_window_dims.size) dan rentang [0,operand.rank) \inserted_window_dims. (Misalnya, jikaupdate_window_dims.sizeadalah4,operand.rankadalah6, daninserted_window_dimsadalah {0,2}, makawindow_dims_to_operand_dimsadalah {0→1,1→3,2→4,3→5}).Win[_] =0jika tidak.
IadalahWin+Sindengan + adalah penambahan per elemen.
Singkatnya, operasi sebar dapat ditentukan sebagai berikut.
- Lakukan inisialisasi
outputdenganoperands, yaitu untuk semua indeksJ, untuk semua indeksOdalam arrayoperands[J]:
output[J][O] =operands[J][O] - Untuk setiap indeks
Udalam arrayupdates[J] dan indeksOyang sesuai dalam arrayoperand[J], jikaOadalah indeks yang valid untukoutput:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
Urutan penerapan update tidak deterministik. Jadi, jika beberapa
indeks di updates merujuk ke indeks yang sama di operands, nilai
yang sesuai di output akan menjadi non-deterministik.
Perhatikan bahwa parameter pertama yang diteruskan ke update_computation akan
selalu menjadi nilai saat ini dari array output dan parameter kedua
akan selalu menjadi nilai dari array updates. Hal ini penting
khususnya untuk kasus saat update_computation tidak komutatif.
Jika indices_are_sorted disetel ke benar (true), XLA dapat mengasumsikan bahwa
scatter_indices diurutkan (dalam urutan menaik, setelah menyebarkan nilainya
sesuai dengan scatter_dims_to_operand_dims) oleh pengguna. Jika tidak, semantikanya ditentukan oleh implementasi.
Jika unique_indices disetel ke benar (true), XLA dapat mengasumsikan bahwa semua elemen yang disebarkan bersifat unik. Jadi, XLA dapat menggunakan operasi non-atomik. Jika unique_indices disetel ke benar (true) dan indeks yang disebarkan tidak unik, semantiknya ditentukan oleh implementasi.
Secara informal, operasi sebar dapat dilihat sebagai kebalikan dari operasi pengumpulan, yaitu operasi sebar memperbarui elemen dalam input yang diekstrak oleh operasi pengumpulan yang sesuai.
Untuk mengetahui deskripsi informal dan contoh yang mendetail, lihat bagian "Deskripsi Informal" di bagian Gather.
Untuk informasi StableHLO, lihat StableHLO - scatter.
Scatter - Contoh 1 - StableHLO

Pada gambar di atas, setiap baris tabel adalah contoh dari satu contoh indeks pembaruan. Mari kita tinjau langkah demi langkah dari kiri(Perbarui Indeks) ke kanan(Indeks Hasil):
Input) input memiliki bentuk S32[2,3,4,2]. scatter_indices memiliki bentuk
S64[2,2,3,2]. updates memiliki bentuk S32[2,2,3,1,2].
Update Index) Sebagai bagian dari input, kita diberi update_window_dims:[3,4]. Hal ini
memberi tahu kita bahwa dim 3 dan dim 4 updates adalah dimensi jendela, yang ditandai dengan warna
kuning. Dengan demikian, kita dapat menyimpulkan bahwa update_scatter_dims = [0,1,2].
Update Scatter Index) Menampilkan updated_scatter_dims yang diekstrak untuk setiap item.
(Non-kuning kolom Perbarui Indeks)
Start Index) Dengan melihat gambar tensor scatter_indices, kita dapat melihat bahwa nilai dari langkah sebelumnya (Update scatter Index) memberi kita lokasi indeks awal. Dari index_vector_dim, kita juga mengetahui dimensi
starting_indices yang berisi indeks awal, yang untuk
scatter_indices adalah dim 3 dengan ukuran 2.
Indeks Awal Lengkap) scatter_dims_to_operand_dims = [2,1] memberi tahu kita bahwa elemen pertama vektor indeks masuk ke dimensi operand 2. Elemen kedua dari
vektor indeks masuk ke operand dim 1. Dimensi operand yang tersisa diisi
dengan 0.
Indeks Batching Penuh) Kita dapat melihat area yang ditandai dengan warna ungu ditampilkan di kolom ini(indeks batching penuh), kolom indeks sebar update, dan kolom indeks update.
Indeks Jendela Penuh) Dihitung dari update_window_dimensions [3,4].
Indeks Hasil) Penambahan Indeks Awal Penuh, Indeks Batching Penuh, dan Indeks
Jendela Penuh dalam tensor operand. Perhatikan bahwa area yang ditandai hijau
juga sesuai dengan gambar operand. Baris terakhir dilewati karena berada di luar
tensor operand.
Pilih
Lihat juga
XlaBuilder::Select.
Membuat array output dari elemen dua array input, berdasarkan nilai array predikat.
Select(pred, on_true, on_false)
| Argumen | Jenis | Semantik |
|---|---|---|
pred |
XlaOp |
array jenis PRED |
on_true |
XlaOp |
array jenis T |
on_false |
XlaOp |
array jenis T |
Array on_true dan on_false harus memiliki bentuk yang sama. Ini juga merupakan
bentuk array output. Array pred harus memiliki dimensi yang sama dengan
on_true dan on_false, dengan jenis elemen PRED.
Untuk setiap elemen P dari pred, elemen yang sesuai dari array output diambil dari on_true jika nilai P adalah true, dan dari on_false jika nilai P adalah false. Sebagai bentuk penyiaran yang terbatas,
pred dapat berupa skalar jenis PRED. Dalam hal ini, array output diambil
seluruhnya dari on_true jika pred adalah true, dan dari on_false jika pred adalah
false.
Contoh dengan pred non-skalar:
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
Contoh dengan skalar pred:
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
Pemilihan antara tuple didukung. Tuple dianggap sebagai jenis skalar untuk tujuan ini. Jika on_true dan on_false adalah tuple (yang harus memiliki
bentuk yang sama!), maka pred harus berupa skalar berjenis PRED.
Untuk informasi StableHLO, lihat StableHLO - select
SelectAndScatter
Lihat juga
XlaBuilder::SelectAndScatter.
Operasi ini dapat dianggap sebagai operasi komposit yang pertama-tama menghitung
ReduceWindow pada array operand untuk memilih elemen dari setiap jendela, dan
kemudian menyebarkan array source ke indeks elemen yang dipilih untuk
membuat array output dengan bentuk yang sama seperti array operand. Fungsi
select biner digunakan untuk memilih elemen dari setiap jendela dengan menerapkannya
di setiap jendela, dan dipanggil dengan properti bahwa vektor indeks parameter
pertama kurang dari vektor indeks parameter kedua secara leksikografis. Fungsi
select menampilkan true jika parameter pertama dipilih dan menampilkan false jika parameter kedua dipilih, dan
fungsi harus mempertahankan transitivitas (yaitu, jika select(a, b) dan select(b, c) adalah
true, maka select(a, c) juga true) sehingga elemen yang dipilih tidak
bergantung pada urutan elemen yang dilalui untuk jendela tertentu.
Fungsi scatter diterapkan pada setiap indeks yang dipilih dalam array output. Fungsi ini
menggunakan dua parameter skalar:
- Nilai saat ini pada indeks yang dipilih dalam array output
- Nilai sebar dari
sourceyang berlaku untuk indeks yang dipilih
Fungsi ini menggabungkan kedua parameter dan menampilkan nilai skalar yang digunakan untuk memperbarui nilai pada indeks yang dipilih dalam array output. Awalnya, semua indeks array output ditetapkan ke init_value.
Array output memiliki bentuk yang sama dengan array operand dan array source harus memiliki bentuk yang sama dengan hasil penerapan operasi ReduceWindow pada array operand. SelectAndScatter dapat digunakan untuk melakukan propagasi mundur nilai gradien untuk lapisan penggabungan dalam jaringan neural.
SelectAndScatter(operand, select, window_dimensions, window_strides, padding,
source, init_value, scatter)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp
|
array jenis T yang jendela gesernya |
select
|
XlaComputation
|
komputasi biner jenis T, T
-> PRED, untuk diterapkan ke semua
elemen di setiap jendela; menampilkan
true jika parameter pertama
dipilih dan menampilkan false jika
parameter kedua dipilih |
window_dimensions
|
ArraySlice<int64>
|
array bilangan bulat untuk nilai dimensi jendela |
window_strides
|
ArraySlice<int64>
|
array bilangan bulat untuk nilai langkah jendela |
padding
|
Padding
|
jenis padding untuk jendela (Padding::kSame atau Padding::kValid) |
source
|
XlaOp
|
array jenis T dengan nilai yang akan disebarkan |
init_value
|
XlaOp
|
nilai skalar jenis T untuk nilai awal array output |
scatter
|
XlaComputation
|
komputasi biner jenis T, T
-> T, untuk menerapkan setiap elemen sumber sebar dengan elemen tujuannya |
Gambar di bawah menunjukkan contoh penggunaan SelectAndScatter, dengan fungsi select menghitung nilai maksimum di antara parameternya. Perhatikan bahwa saat
jendela tumpang-tindih, seperti pada gambar (2) di bawah, indeks array operand dapat
dipilih beberapa kali oleh jendela yang berbeda. Pada gambar, elemen
bernilai 9 dipilih oleh kedua jendela atas (biru dan merah) dan fungsi
penambahan biner scatter menghasilkan elemen output bernilai 8 (2 + 6).
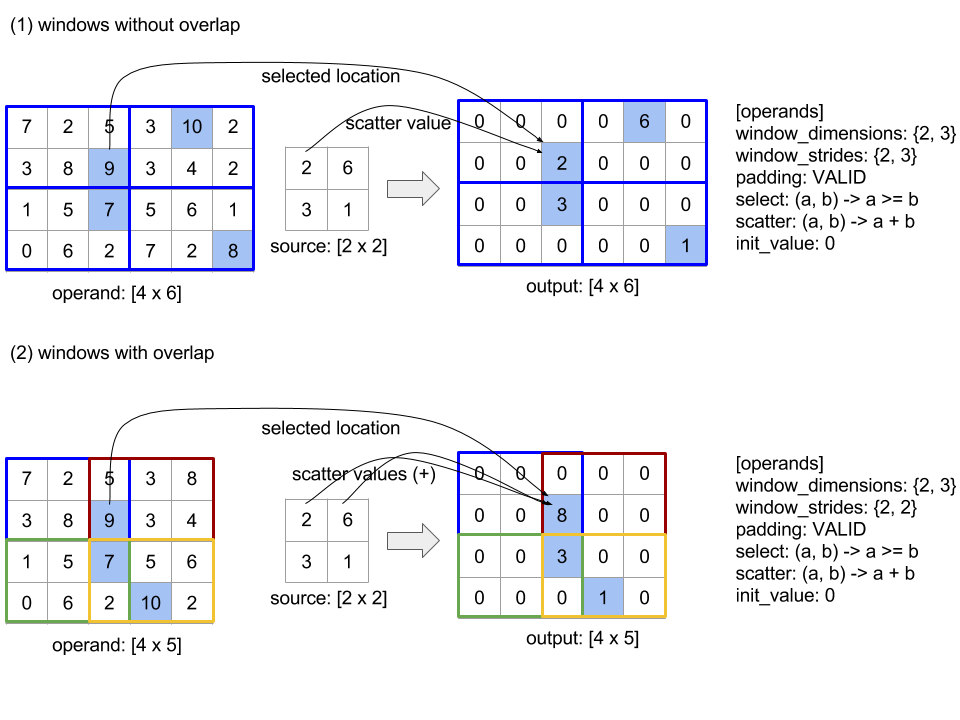
Urutan evaluasi fungsi scatter bersifat arbitrer dan mungkin
non-deterministik. Oleh karena itu, fungsi scatter tidak boleh terlalu sensitif terhadap pengaitan ulang. Lihat diskusi tentang asosiativitas dalam konteks Reduce untuk mengetahui detail selengkapnya.
Untuk informasi StableHLO, lihat StableHLO - select_and_scatter.
Kirim
Lihat juga
XlaBuilder::Send.
Send, SendWithTokens, dan SendToHost adalah operasi yang berfungsi sebagai
primitif komunikasi di HLO. Operasi ini biasanya muncul dalam dump HLO sebagai bagian dari input/output tingkat rendah atau transfer lintas perangkat, tetapi tidak dimaksudkan untuk dibuat secara manual oleh pengguna akhir.
Send(operand, handle)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
data yang akan dikirim (array jenis T) |
handle |
ChannelHandle |
ID unik untuk setiap pasangan kirim/terima |
Mengirim data operand yang diberikan ke instruksi Recv dalam komputasi lain yang menggunakan handle saluran yang sama. Tidak menampilkan data apa pun.
Mirip dengan operasi Recv, API klien operasi Send
merepresentasikan komunikasi sinkron, dan secara internal diuraikan menjadi 2 instruksi HLO (Send dan SendDone) untuk mengaktifkan transfer data asinkron. Lihat
juga
HloInstruction::CreateSend dan HloInstruction::CreateSendDone.
Send(HloInstruction operand, int64 channel_id)
Memulai transfer operand secara asinkron ke resource yang dialokasikan oleh
instruksi Recv dengan ID saluran yang sama. Menampilkan konteks, yang
digunakan oleh instruksi SendDone berikutnya untuk menunggu penyelesaian
transfer data. Konteks adalah tuple {operand (bentuk), ID permintaan
(U32)} dan hanya dapat digunakan oleh instruksi SendDone.
Untuk mengetahui informasi StableHLO, lihat StableHLO - send.
SendDone
Lihat juga
HloInstruction::CreateSendDone.
SendDone(HloInstruction context)
Mengingat konteks yang dibuat oleh instruksi Send, menunggu transfer data selesai. Petunjuk tidak menampilkan data apa pun.
Penjadwalan petunjuk channel
Urutan eksekusi 4 petunjuk untuk setiap saluran (Recv, RecvDone,
Send, SendDone) adalah sebagai berikut.
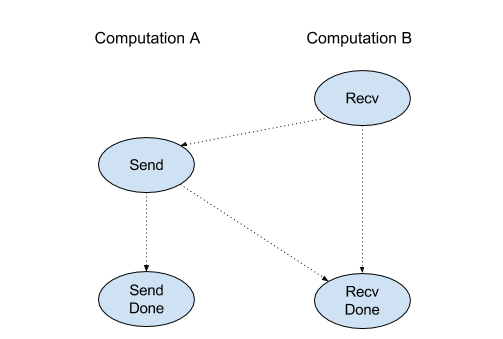
Recvterjadi sebelumSendSendterjadi sebelumRecvDoneRecvterjadi sebelumRecvDoneSendterjadi sebelumSendDone
Saat compiler backend menghasilkan jadwal linear untuk setiap komputasi yang berkomunikasi melalui petunjuk saluran, tidak boleh ada siklus di seluruh komputasi. Misalnya, jadwal di bawah ini menyebabkan kebuntuan.
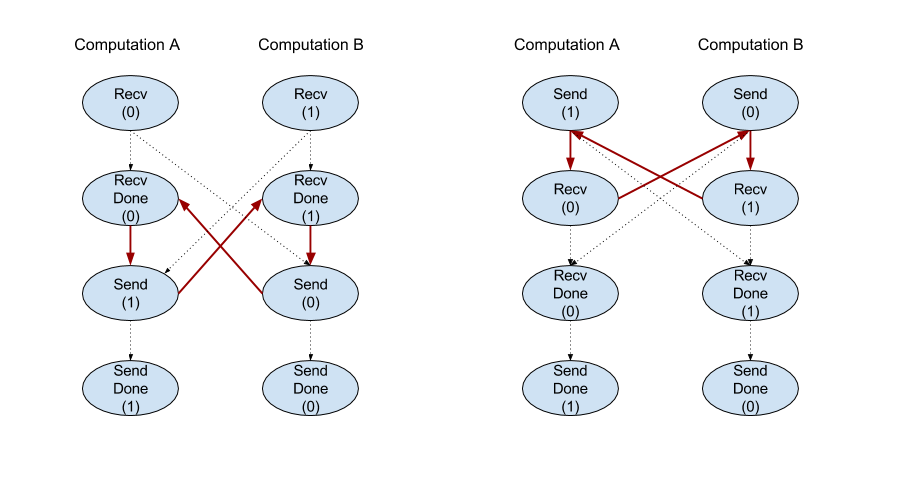
SetDimensionSize
Lihat juga
XlaBuilder::SetDimensionSize.
Menetapkan ukuran dinamis dimensi tertentu XlaOp. Operand harus berbentuk array.
SetDimensionSize(operand, val, dimension)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array input n dimensi. |
val |
XlaOp |
int32 yang merepresentasikan ukuran dinamis runtime. |
dimension
|
int64
|
Nilai dalam interval [0, n) yang menentukan
dimensi. |
Meneruskan operand sebagai hasil, dengan dimensi dinamis yang dilacak oleh kompiler.
Nilai yang diisi akan diabaikan oleh operasi pengurangan hilir.
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
ShiftLeft
Lihat juga
XlaBuilder::ShiftLeft.
Melakukan operasi geser kiri per elemen pada lhs dengan jumlah bit rhs.
ShiftLeft(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk ShiftLeft:
ShiftLeft(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - shift_left.
ShiftRightArithmetic
Lihat juga
XlaBuilder::ShiftRightArithmetic.
Melakukan operasi pergeseran aritmatika ke kanan per elemen pada lhs sebanyak rhs bit.
ShiftRightArithmetic(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Tersedia varian alternatif dengan dukungan penyiaran dimensi yang berbeda untuk ShiftRightArithmetic:
ShiftRightArithmetic(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - shift_right_arithmetic.
ShiftRightLogical
Lihat juga
XlaBuilder::ShiftRightLogical.
Melakukan operasi pergeseran kanan logis per elemen pada lhs dengan jumlah bit rhs.
ShiftRightLogical(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk ShiftRightLogical:
ShiftRightLogical(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - shift_right_logical.
Tanda
Lihat juga
XlaBuilder::Sign.
Sign(operand) Operasi tanda per elemen x -> sgn(x) dengan
\[\text{sgn}(x) = \begin{cases} -1 & x < 0\\ -0 & x = -0\\ NaN & x = NaN\\ +0 & x = +0\\ 1 & x > 0 \end{cases}\]
menggunakan operator perbandingan jenis elemen operand.
Sign(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Untuk informasi StableHLO, lihat StableHLO - sign.
Sinus
Sin(operand) Sinus per elemen x -> sin(x).
Lihat juga
XlaBuilder::Sin.
Sin(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Sin juga mendukung argumen result_accuracy opsional:
Sin(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - sine.
Slice
Lihat juga
XlaBuilder::Slice.
Pengirisan mengekstrak sub-array dari array input. Sub-array memiliki jumlah dimensi yang sama dengan input dan berisi nilai di dalam kotak pembatas dalam array input tempat dimensi dan indeks kotak pembatas diberikan sebagai argumen untuk operasi slice.
Slice(operand, start_indices, limit_indices, strides)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Array berdimensi N dari jenis T |
start_indices
|
ArraySlice<int64>
|
Daftar N bilangan bulat yang berisi indeks awal slice untuk setiap dimensi. Nilai harus lebih besar dari atau sama dengan nol. |
limit_indices
|
ArraySlice<int64>
|
Daftar N bilangan bulat yang berisi
indeks akhir (eksklusif) untuk
slice untuk setiap dimensi. Setiap nilai
harus lebih besar dari atau sama dengan
nilai start_indices masing-masing untuk
dimensi dan kurang dari atau sama dengan
ukuran dimensi. |
strides
|
ArraySlice<int64>
|
Daftar N bilangan bulat yang menentukan langkah input slice. Slice
memilih setiap elemen strides[d] dalam
dimensi d. |
Contoh 1 dimensi:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4})
// Result: {2.0, 3.0}
Contoh 2 dimensi:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3})
// Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
Untuk mengetahui informasi StableHLO, lihat StableHLO - slice.
Urutkan
Lihat juga
XlaBuilder::Sort.
Sort(operands, comparator, dimension, is_stable)
| Argumen | Jenis | Semantik |
|---|---|---|
operands |
ArraySlice<XlaOp> |
Operand yang akan diurutkan. |
comparator |
XlaComputation |
Komputasi pembanding yang akan digunakan. |
dimension |
int64 |
Dimensi yang akan digunakan untuk mengurutkan. |
is_stable |
bool |
Apakah pengurutan stabil harus digunakan. |
Jika hanya satu operand yang diberikan:
Jika operand adalah tensor 1 dimensi (array), hasilnya adalah array yang diurutkan. Jika Anda ingin mengurutkan array dalam urutan menaik, pembanding harus melakukan perbandingan kurang dari. Secara formal, setelah array diurutkan, array tersebut berlaku untuk semua posisi indeks
i, jdengani < jyang merupakancomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseataucomparator(value[i], value[j]) = true.Jika operand memiliki jumlah dimensi yang lebih tinggi, operand akan diurutkan di sepanjang dimensi yang diberikan. Misalnya, untuk tensor 2 dimensi (matriks), nilai dimensi
0akan mengurutkan setiap kolom secara independen, dan nilai dimensi1akan mengurutkan setiap baris secara independen. Jika tidak ada nomor dimensi yang diberikan, dimensi terakhir akan dipilih secara default. Untuk dimensi yang diurutkan, urutan pengurutan yang sama berlaku seperti pada kasus 1 dimensi.
Jika operand n > 1 diberikan:
Semua operand
nharus berupa tensor dengan dimensi yang sama. Jenis elemen tensor dapat berbeda.Semua operand diurutkan bersama, bukan satu per satu. Secara konseptual, operand diperlakukan sebagai tuple. Saat memeriksa apakah elemen setiap operand pada posisi indeks
idanjperlu ditukar, pembanding dipanggil dengan parameter skalar2 * n, dengan parameter2 * ksesuai dengan nilai pada posisiidari operandk-th, dan parameter2 * k + 1sesuai dengan nilai pada posisijdari operandk-th. Biasanya, pembanding akan membandingkan parameter2 * kdan2 * k + 1satu sama lain dan mungkin menggunakan pasangan parameter lain sebagai pemutus seri.Hasilnya adalah tuple yang terdiri dari operand dalam urutan yang diurutkan (di sepanjang dimensi yang diberikan, seperti di atas). Operand
i-thtuple sesuai dengan operandi-thSort.
Misalnya, jika ada tiga operan operand0 = [3, 1], operand1 = [42, 50], operand2 = [-3.0, 1.1], dan pembanding hanya membandingkan nilai operand0 dengan kurang dari, maka output pengurutan adalah tuple ([1, 3], [50, 42], [1.1, -3.0]).
Jika is_stable disetel ke benar (true), pengurutan dijamin stabil, yaitu, jika ada elemen yang dianggap sama oleh pembanding, urutan relatif nilai yang sama akan dipertahankan. Dua elemen e1 dan e2 sama jika dan hanya jika comparator(e1, e2) = comparator(e2, e1) = false. Secara default, is_stable disetel ke salah (false).
Untuk mengetahui informasi StableHLO, lihat StableHLO - sort.
Sqrt
Lihat juga
XlaBuilder::Sqrt.
Operasi akar kuadrat per elemen x -> sqrt(x).
Sqrt(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Sqrt juga mendukung argumen result_accuracy opsional:
Sqrt(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - sqrt.
Sub
Lihat juga
XlaBuilder::Sub.
Melakukan pengurangan per elemen lhs dan rhs.
Sub(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran berdimensi berbeda ada untuk Sub:
Sub(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - subtract.
Tan
Lihat juga
XlaBuilder::Tan.
Tangen per elemen x -> tan(x).
Tan(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Tan juga mendukung argumen result_accuracy opsional:
Tan(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk mengetahui informasi StableHLO, lihat StableHLO - tan.
Tanh
Lihat juga
XlaBuilder::Tanh.
Tangen hiperbolik per elemen x -> tanh(x).
Tanh(operand)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
Tanh juga mendukung argumen result_accuracy opsional:
Tanh(operand, result_accuracy)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand ke fungsi |
result_accuracy
|
opsional ResultAccuracy
|
Jenis akurasi yang dapat diminta pengguna untuk operasi unaria dengan beberapa penerapan |
Untuk mengetahui informasi selengkapnya tentang result_accuracy, lihat
Akurasi Hasil.
Untuk informasi StableHLO, lihat StableHLO - tanh.
TopK
Lihat juga
XlaBuilder::TopK.
TopK menemukan nilai dan indeks dari k elemen terbesar atau terkecil untuk
dimensi terakhir dari tensor yang diberikan.
TopK(operand, k, largest)
| Argumen | Jenis | Semantik |
|---|---|---|
operand
|
XlaOp
|
Tensor yang akan diekstrak elemen k teratasnya.
Tensor harus memiliki dimensi yang lebih besar atau sama dengan satu. Ukuran dimensi terakhir tensor harus lebih besar atau sama dengan k. |
k |
int64 |
Jumlah elemen yang akan diekstrak. |
largest
|
bool
|
Apakah akan mengekstrak elemen k
terbesar atau terkecil. |
Untuk tensor input 1 dimensi (array), menemukan kentri terbesar atau terkecil
dalam array dan menghasilkan tuple dari dua array (values, indices). Dengan demikian,
values[j] adalah entri terbesar/terkecil ke-j dalam operand, dan indeksnya adalah
indices[j].
Untuk tensor input dengan lebih dari 1 dimensi, menghitung k entri teratas
di sepanjang dimensi terakhir, dengan mempertahankan semua dimensi (baris) lainnya dalam output.
Jadi, untuk operand dengan bentuk [A, B, ..., P, Q] dengan Q >= k, outputnya adalah
tuple (values, indices) dengan:
values.shape = indices.shape = [A, B, ..., P, k]
Jika dua elemen dalam baris sama, elemen dengan indeks yang lebih rendah akan muncul terlebih dahulu.
Transpose
Lihat juga operasi tf.reshape.
Transpose(operand, permutation)
| Argumen | Jenis | Semantik |
|---|---|---|
operand |
XlaOp |
Operand yang akan ditransposisikan. |
permutation |
ArraySlice<int64> |
Cara melakukan permutasi dimensi. |
Memutasikan dimensi operand dengan permutasi yang diberikan, sehingga
∀ i . 0 ≤ i < number of dimensions ⇒
input_dimensions[permutation[i]] = output_dimensions[i].
Ini sama dengan Reshape(operand, permutasi, Permute(permutasi, operand.shape.dimensions)).
Untuk informasi StableHLO, lihat StableHLO - transpose.
TriangularSolve
Lihat juga
XlaBuilder::TriangularSolve.
Menyelesaikan sistem persamaan linear dengan matriks koefisien segitiga bawah atau atas dengan substitusi maju atau mundur. Menyiarkan sepanjang dimensi
utama, rutin ini menyelesaikan salah satu sistem matriks op(a) * x =
b, atau x * op(a) = b, untuk variabel x, dengan a dan b, dengan op(a)
adalah op(a) = a, atau op(a) = Transpose(a), atau
op(a) = Conj(Transpose(a)).
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| Argumen | Jenis | Semantik |
|---|---|---|
a
|
XlaOp
|
array berdimensi > 2 dari jenis bilangan kompleks atau
floating-point dengan bentuk [..., M,
M]. |
b
|
XlaOp
|
array 2 dimensi dengan jenis yang sama
dengan bentuk [..., M, K] jika left_side adalah
benar, [..., K, M] jika tidak. |
left_side
|
bool
|
menunjukkan apakah akan menyelesaikan sistem
bentuk op(a) * x = b (true) atau x *
op(a) = b (false). |
lower
|
bool
|
apakah akan menggunakan segitiga atas atau bawah
dari a. |
unit_diagonal
|
bool
|
Jika true, elemen diagonal a diasumsikan sebagai 1 dan tidak diakses. |
transpose_a
|
Transpose
|
apakah akan menggunakan a apa adanya, mentransposisikannya, atau
mengambil transposisi konjugasinya. |
Data input hanya dibaca dari segitiga bawah/atas a, bergantung pada
nilai lower. Nilai dari segitiga lainnya akan diabaikan. Data output
ditampilkan dalam segitiga yang sama; nilai dalam segitiga lainnya
ditetapkan oleh implementasi dan dapat berupa apa saja.
Jika jumlah dimensi a dan b lebih besar dari 2, keduanya diperlakukan
sebagai batch matriks, dengan semua kecuali 2 dimensi kecil adalah dimensi
batch. a dan b harus memiliki dimensi batch yang sama.
Untuk informasi StableHLO, lihat StableHLO - triangular_solve.
Tuple
Lihat juga
XlaBuilder::Tuple.
Tuple yang berisi sejumlah variabel data, yang masing-masing memiliki bentuknya sendiri.
Tuple(elements)
| Argumen | Jenis | Semantik |
|---|---|---|
elements |
vektor XlaOp |
Array N berjenis T |
Hal ini analog dengan std::tuple di C++. Secara konseptual:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
Tuple dapat didekonstruksi (diakses) melalui operasi GetTupleElement.
Untuk informasi StableHLO, lihat StableHLO - tuple.
Meskipun
Lihat juga
XlaBuilder::While.
While(condition, body, init)
| Argumen | Jenis | Semantik |
|---|---|---|
condition
|
XlaComputation
|
XlaComputation berjenis T -> PRED yang
menentukan kondisi penghentian
loop. |
body
|
XlaComputation
|
XlaComputation jenis T -> T yang
menentukan isi loop. |
init
|
T
|
Nilai awal untuk parameter
condition dan body. |
Menjalankan body secara berurutan hingga condition gagal. Hal ini mirip dengan
loop while biasa di banyak bahasa lain, kecuali perbedaan dan
batasan yang tercantum di bawah.
- Node
Whilemenampilkan nilai jenisT, yang merupakan hasil dari eksekusi terakhirbody. - Bentuk huruf
Tditentukan secara statis dan harus sama di semua iterasi.
Parameter T komputasi diinisialisasi dengan nilai init dalam
iterasi pertama dan otomatis diupdate ke hasil baru dari body
di setiap iterasi berikutnya.
Salah satu kasus penggunaan utama node While adalah untuk menerapkan eksekusi berulang
pelatihan dalam jaringan neural. Pseudocode yang disederhanakan ditampilkan di bawah dengan grafik
yang merepresentasikan komputasi. Kode dapat ditemukan di
while_test.cc.
Jenis T dalam contoh ini adalah Tuple yang terdiri dari int32 untuk
jumlah iterasi dan vector[10] untuk akumulator. Untuk 1.000 iterasi, loop
terus menambahkan vektor konstan ke akumulator.
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}
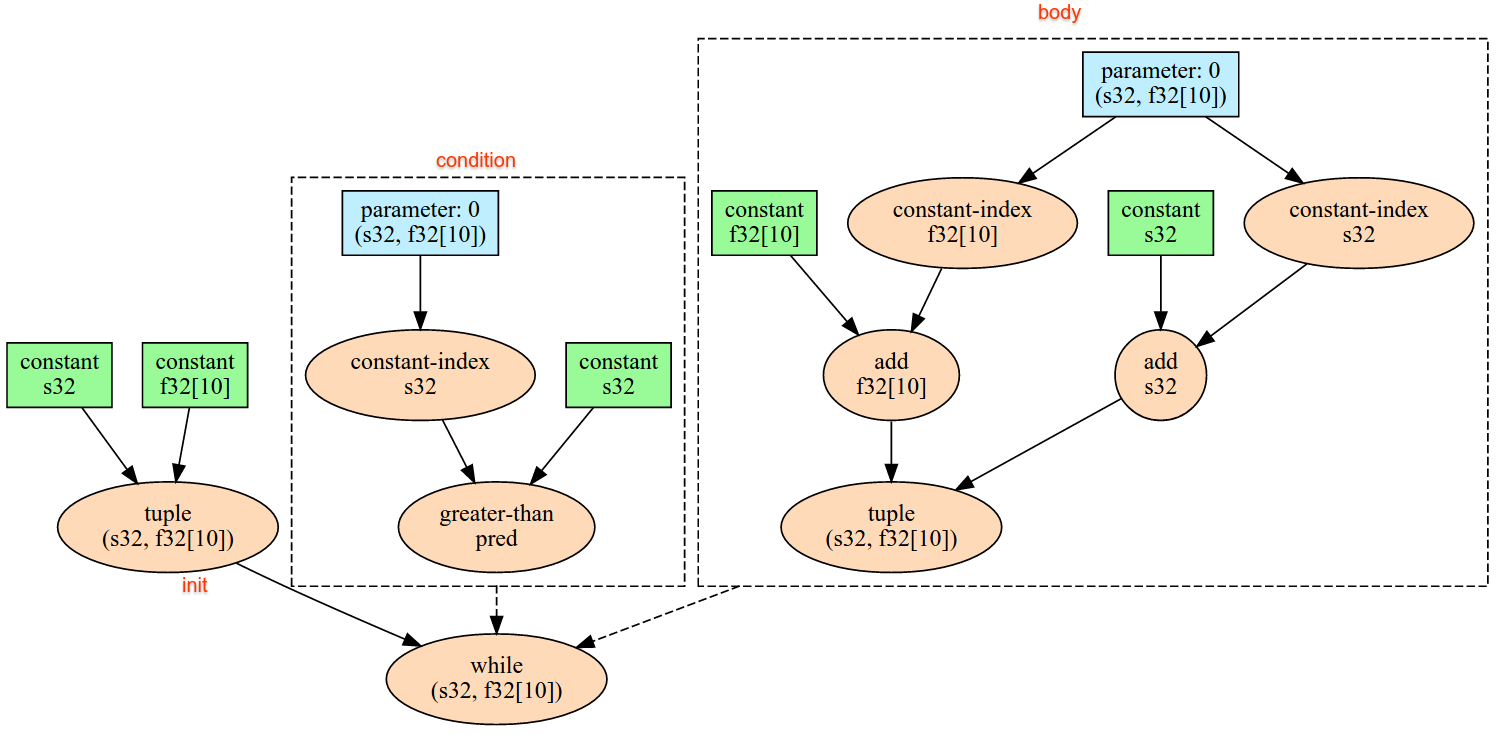
Untuk informasi StableHLO, lihat StableHLO - while.
Xor
Lihat juga
XlaBuilder::Xor.
Melakukan XOR per elemen lhs dan rhs.
Xor(lhs, rhs)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
Bentuk argumen harus serupa atau kompatibel. Lihat dokumentasi penyiaran tentang arti kesesuaian bentuk. Hasil operasi memiliki bentuk yang merupakan hasil penyiaran dua array input. Dalam varian ini, operasi antara array dengan peringkat yang berbeda tidak didukung, kecuali jika salah satu operan adalah skalar.
Varian alternatif dengan dukungan penyiaran dimensi yang berbeda ada untuk Xor:
Xor(lhs,rhs, broadcast_dimensions)
| Argumen | Jenis | Semantik |
|---|---|---|
| lhs | XlaOp | Operand sisi kiri: array jenis T |
| rhs | XlaOp | Operand sisi kiri: array jenis T |
| broadcast_dimension | ArraySlice |
Dimensi mana dalam bentuk target yang sesuai dengan setiap dimensi bentuk operand |
Varian operasi ini harus digunakan untuk operasi aritmatika antara array dengan peringkat yang berbeda (seperti menambahkan matriks ke vektor).
Operand broadcast_dimensions tambahan adalah slice bilangan bulat yang menentukan dimensi yang akan digunakan untuk menyiarkan operand. Semantik dijelaskan secara mendetail di halaman penyiaran.
Untuk informasi StableHLO, lihat StableHLO - xor.