
Sau đây mô tả ngữ nghĩa của các thao tác được xác định trong giao diện XlaBuilder. Thông thường, các thao tác này sẽ liên kết một-một với các thao tác được xác định trong giao diện RPC trong xla_data.proto.
Lưu ý về quy tắc đặt tên: loại dữ liệu tổng quát mà XLA xử lý là một mảng N chiều chứa các phần tử thuộc một số loại đồng nhất (chẳng hạn như số thực 32 bit). Trong toàn bộ tài liệu, mảng được dùng để biểu thị một mảng có số chiều tuỳ ý. Để thuận tiện, các trường hợp đặc biệt có tên cụ thể và quen thuộc hơn; ví dụ: vectơ là một mảng 1 chiều và ma trận là một mảng 2 chiều.
Tìm hiểu thêm về cấu trúc của một Thao tác trong Hình dạng và bố cục và Bố cục dạng lát.
Cơ bụng
Xem thêm XlaBuilder::Abs.
Hàm abs theo phần tử x -> |x|.
Abs(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – abs.
Thêm
Xem thêm XlaBuilder::Add.
Thực hiện phép cộng từng phần tử của lhs và rhs.
Add(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Có một biến thể thay thế hỗ trợ truyền hình nhiều chiều cho Add:
Add(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem bài viết StableHLO – add.
AddDependency
Xem thêm HloInstruction::AddDependency.
AddDependency có thể xuất hiện trong các kết xuất HLO, nhưng người dùng cuối không nên tạo các kết xuất này theo cách thủ công.
AfterAll
Xem thêm XlaBuilder::AfterAll.
AfterAll lấy một số lượng mã thông báo thay đổi và tạo ra một mã thông báo duy nhất. Mã thông báo là các loại nguyên thuỷ có thể được liên kết giữa các thao tác có tác dụng phụ để thực thi việc sắp xếp. AfterAll có thể được dùng làm một mã thông báo kết hợp để sắp xếp một thao tác sau một tập hợp các thao tác.
AfterAll(tokens)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
tokens |
vectơ của XlaOp |
số lượng mã thông báo có thể thay đổi |
Để biết thông tin về StableHLO, hãy xem StableHLO – after_all.
AllGather
Xem thêm XlaBuilder::AllGather.
Thực hiện phép nối trên các bản sao.
AllGather(operand, all_gather_dimension, shard_count, replica_groups,
channel_id, layout, use_global_device_ids)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp
|
Mảng để nối trên các bản sao |
all_gather_dimension |
int64 |
Phương diện nối |
shard_count
|
int64
|
Kích thước của mỗi nhóm bản sao |
replica_groups
|
vectơ của vectơ của
int64 |
Các nhóm mà phép nối được thực hiện |
channel_id
|
không bắt buộc
ChannelHandle |
Mã nhận dạng kênh không bắt buộc để giao tiếp giữa các mô-đun |
layout
|
không bắt buộc Layout
|
Tạo một mẫu bố cục sẽ nắm bắt bố cục khớp trong đối số |
use_global_device_ids
|
không bắt buộc bool
|
Trả về true nếu các mã nhận dạng trong cấu hình ReplicaGroup đại diện cho một mã nhận dạng chung |
replica_groupslà danh sách các nhóm bản sao mà phép nối được thực hiện (bạn có thể truy xuất mã nhận dạng bản sao cho bản sao hiện tại bằng cách sử dụngReplicaId). Thứ tự của các bản sao trong mỗi nhóm sẽ xác định thứ tự mà các đầu vào của chúng nằm trong kết quả.replica_groupsphải trống (trong trường hợp đó, tất cả các bản sao đều thuộc một nhóm duy nhất, được sắp xếp từ0đếnN - 1) hoặc chứa cùng số lượng phần tử như số lượng bản sao. Ví dụ:replica_groups = {0, 2}, {1, 3}thực hiện phép nối giữa các bản sao0và2, cũng như1và3.shard_countlà kích thước của mỗi nhóm bản sao. Chúng ta cần thông tin này trong trường hợpreplica_groupstrống.channel_idđược dùng để giao tiếp giữa các mô-đun: chỉ những thao tácall-gathercó cùngchannel_idmới có thể giao tiếp với nhau.use_global_device_idsTrả về true nếu các mã nhận dạng trong cấu hình ReplicaGroup biểu thị mã nhận dạng chung của (replica_id * partition_count + partition_id) thay vì mã nhận dạng bản sao. Điều này cho phép nhóm các thiết bị linh hoạt hơn nếu thao tác giảm tất cả này vừa là thao tác trên nhiều phân vùng vừa là thao tác trên nhiều bản sao.
Hình dạng đầu ra là hình dạng đầu vào với all_gather_dimension được tạo lớn hơn shard_count lần. Ví dụ: nếu có 2 bản sao và toán hạng có giá trị lần lượt là [1.0, 2.5] và [3.0, 5.25] trên 2 bản sao, thì giá trị đầu ra từ thao tác này, trong đó all_gather_dim là 0, sẽ là [1.0, 2.5, 3.0,5.25] trên cả 2 bản sao.
API của AllGather được phân tách nội bộ thành 2 chỉ dẫn HLO (AllGatherStart và AllGatherDone).
Xem thêm HloInstruction::CreateAllGatherStart.
AllGatherStart, AllGatherDone đóng vai trò là các thành phần cơ bản trong HLO. Các thao tác này có thể xuất hiện trong các kết xuất HLO, nhưng người dùng cuối không được phép tạo các thao tác này theo cách thủ công.
Để biết thông tin về StableHLO, hãy xem StableHLO – all_gather.
AllReduce
Xem thêm XlaBuilder::AllReduce.
Thực hiện một phép tính tuỳ chỉnh trên các bản sao.
AllReduce(operand, computation, replica_groups, channel_id,
shape_with_layout, use_global_device_ids)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp
|
Mảng hoặc bộ dữ liệu không trống gồm các mảng cần giảm trên các bản sao |
computation |
XlaComputation |
Tính toán mức giảm |
replica_groups
|
ReplicaGroup vectơ
|
Các nhóm mà giữa đó sẽ diễn ra quá trình giảm |
channel_id
|
không bắt buộc
ChannelHandle |
Mã nhận dạng kênh không bắt buộc để giao tiếp giữa các mô-đun |
shape_with_layout
|
không bắt buộc Shape
|
Xác định bố cục của dữ liệu được chuyển |
use_global_device_ids
|
không bắt buộc bool
|
Trả về true nếu các mã nhận dạng trong cấu hình ReplicaGroup đại diện cho một mã nhận dạng chung |
- Khi
operandlà một bộ gồm các mảng, thao tác giảm tất cả sẽ được thực hiện trên từng phần tử của bộ. replica_groupslà danh sách các nhóm bản sao mà quá trình giảm được thực hiện (bạn có thể truy xuất mã nhận dạng bản sao cho bản sao hiện tại bằng cách sử dụngReplicaId).replica_groupsphải trống (trong trường hợp tất cả các bản sao thuộc về một nhóm duy nhất) hoặc chứa cùng số lượng phần tử như số lượng bản sao. Ví dụ:replica_groups = {0, 2}, {1, 3}thực hiện thao tác giảm giữa các bản sao0và2,1và3.channel_idđược dùng để giao tiếp giữa các mô-đun: chỉ những thao tácall-reducecó cùngchannel_idmới có thể giao tiếp với nhau.shape_with_layout: buộc bố cục của AllReduce thành bố cục đã cho. Điều này được dùng để đảm bảo cùng một bố cục cho một nhóm các thao tác AllReduce được biên dịch riêng.use_global_device_idsTrả về true nếu các mã nhận dạng trong cấu hình ReplicaGroup biểu thị mã nhận dạng chung của (replica_id * partition_count + partition_id) thay vì mã nhận dạng bản sao. Điều này cho phép nhóm các thiết bị linh hoạt hơn nếu thao tác giảm tất cả này vừa là thao tác trên nhiều phân vùng vừa là thao tác trên nhiều bản sao.
Hình dạng đầu ra giống với hình dạng đầu vào. Ví dụ: nếu có 2 bản sao và toán hạng có giá trị lần lượt là [1.0, 2.5] và [3.0, 5.25] trên 2 bản sao, thì giá trị đầu ra từ phép tính tổng và op này sẽ là [4.0, 7.75] trên cả 2 bản sao. Nếu đầu vào là một bộ dữ liệu, thì đầu ra cũng là một bộ dữ liệu.
Để tính toán kết quả của AllReduce, bạn cần có một đầu vào từ mỗi bản sao. Vì vậy, nếu một bản sao thực thi một nút AllReduce nhiều lần hơn một bản sao khác, thì bản sao trước sẽ đợi mãi mãi. Vì tất cả các bản sao đều đang chạy cùng một chương trình, nên không có nhiều cách để điều đó xảy ra, nhưng điều này có thể xảy ra khi điều kiện của vòng lặp while phụ thuộc vào dữ liệu từ infeed và dữ liệu đó infeed khiến vòng lặp while lặp lại nhiều lần hơn trên một bản sao so với một bản sao khác.
API của AllReduce được phân tách nội bộ thành 2 chỉ dẫn HLO (AllReduceStart và AllReduceDone).
Xem thêm HloInstruction::CreateAllReduceStart.
AllReduceStart và AllReduceDone đóng vai trò là các thành phần cơ bản trong HLO. Các thao tác này có thể xuất hiện trong các kết xuất HLO, nhưng người dùng cuối không được phép tạo các thao tác này theo cách thủ công.
CrossReplicaSum
Xem thêm XlaBuilder::CrossReplicaSum.
Thực hiện AllReduce bằng phép tính tổng.
CrossReplicaSum(operand, replica_groups)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp | Mảng hoặc một bộ không trống gồm các mảng cần giảm trên các bản sao |
replica_groups
|
vectơ của vectơ của
int64 |
Các nhóm mà giữa đó sẽ diễn ra quá trình giảm |
Trả về tổng giá trị toán hạng trong mỗi nhóm con của các bản sao. Tất cả các bản sao đều cung cấp một giá trị đầu vào cho tổng và tất cả các bản sao đều nhận được tổng kết quả cho mỗi nhóm con.
AllToAll
Xem thêm XlaBuilder::AllToAll.
AllToAll là một thao tác tập thể gửi dữ liệu từ tất cả các lõi đến tất cả các lõi. Quy trình này có 2 giai đoạn:
- Giai đoạn phân tán. Trên mỗi lõi, toán hạng được chia thành
split_countsố khối dọc theosplit_dimensionsvà các khối được phân tán đến tất cả các lõi, ví dụ: khối thứ i được gửi đến lõi thứ i. - Giai đoạn thu thập. Mỗi lõi sẽ nối các khối nhận được dọc theo
concat_dimension.
Bạn có thể định cấu hình các lõi tham gia bằng cách:
replica_groups: mỗi ReplicaGroup chứa một danh sách mã nhận dạng bản sao tham gia vào quá trình tính toán (có thể truy xuất mã nhận dạng bản sao cho bản sao hiện tại bằng cách sử dụngReplicaId). AllToAll sẽ được áp dụng trong các nhóm con theo thứ tự đã chỉ định. Ví dụ:replica_groups = { {1,2,3}, {4,5,0} }có nghĩa là AllToAll sẽ được áp dụng trong các bản sao{1, 2, 3}và trong giai đoạn thu thập, các khối nhận được sẽ được nối theo cùng một thứ tự là 1, 2, 3. Sau đó, một AllToAll khác sẽ được áp dụng trong các bản sao 4, 5, 0 và thứ tự nối cũng là 4, 5, 0. Nếureplica_groupstrống, tất cả các bản sao sẽ thuộc về một nhóm, theo thứ tự phép nối của sự xuất hiện.
Điều kiện tiên quyết:
- Kích thước phương diện của toán hạng trên
split_dimensioncó thể chia hết chosplit_count. - Hình dạng của toán hạng không phải là bộ giá trị.
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups, layout, channel_id)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng đầu vào n chiều |
split_dimension
|
int64
|
Một giá trị trong khoảng [0,n) đặt tên cho phương diện mà theo đó toán hạng được phân chia |
concat_dimension
|
int64
|
Một giá trị trong khoảng [0,n) đặt tên cho phương diện mà các khối phân chia được nối với nhau |
split_count
|
int64
|
Số lượng lõi tham gia vào thao tác này. Nếu replica_groups trống, thì đây phải là số lượng bản sao; nếu không, số này phải bằng số lượng bản sao trong mỗi nhóm. |
replica_groups
|
ReplicaGroupvector
|
Mỗi nhóm chứa một danh sách mã nhận dạng bản sao. |
layout |
không bắt buộc Layout |
bố cục bộ nhớ do người dùng chỉ định |
channel_id
|
không bắt buộc ChannelHandle
|
giá trị nhận dạng riêng biệt cho mỗi cặp gửi/nhận |
Hãy xem xla::shapes để biết thêm thông tin về các hình dạng và bố cục..
Để biết thông tin về StableHLO, hãy xem StableHLO – all_to_all.
AllToAll – Ví dụ 1.
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(
x,
/*split_dimension=*/ 1,
/*concat_dimension=*/ 0,
/*split_count=*/ 4);
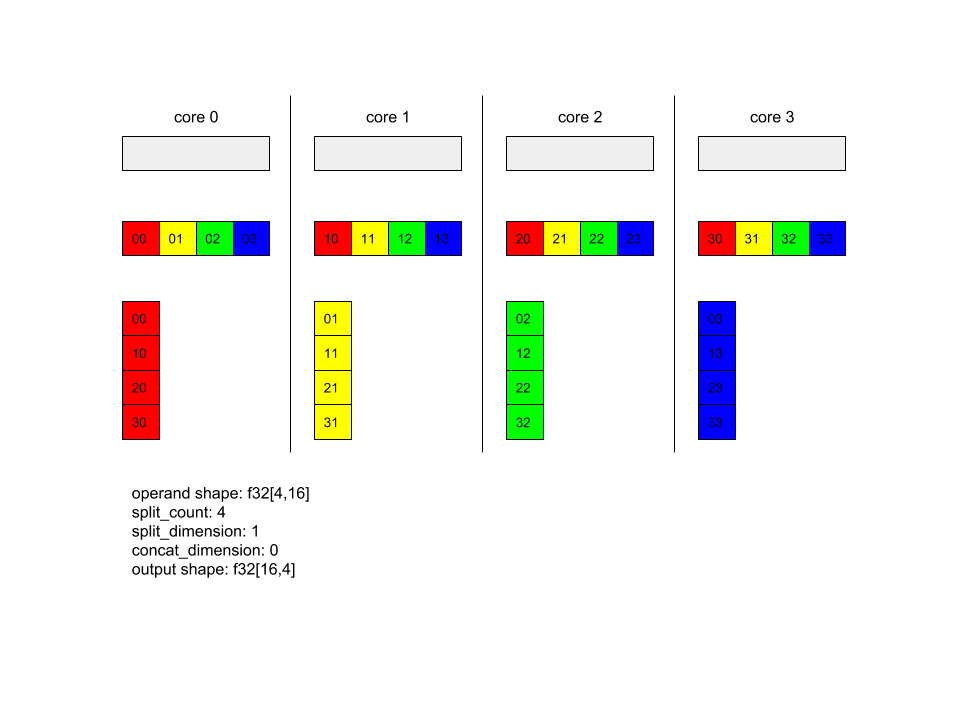
Trong ví dụ trên, có 4 lõi tham gia vào Alltoall. Trên mỗi lõi, toán hạng được chia thành 4 phần dọc theo phương diện 1, do đó, mỗi phần có hình dạng f32[4,4]. 4 phần này được phân tán đến tất cả các lõi. Sau đó, mỗi lõi sẽ nối các phần đã nhận được dọc theo phương diện 0, theo thứ tự lõi 0-4. Vì vậy, đầu ra trên mỗi lõi có hình dạng f32[16,4].
AllToAll – Ví dụ 2 – StableHLO

Trong ví dụ trên, có 2 bản sao tham gia vào AllToAll. Trên mỗi bản sao, toán hạng có hình dạng f32[2,4]. Toán hạng được chia thành 2 phần dọc theo phương diện 1, vì vậy mỗi phần có hình dạng f32[2,2]. Sau đó, 2 phần này sẽ được trao đổi giữa các bản sao theo vị trí của chúng trong nhóm bản sao. Mỗi bản sao sẽ thu thập phần tương ứng của bản sao đó từ cả hai toán hạng và nối chúng dọc theo chiều 0. Do đó, đầu ra trên mỗi bản sao có hình dạng f32[4,2].
RaggedAllToAll
Xem thêm XlaBuilder::RaggedAllToAll.
RaggedAllToAll thực hiện một thao tác tập thể từ tất cả đến tất cả, trong đó đầu vào và đầu ra là các tensor không đồng đều.
RaggedAllToAll(input, input_offsets, send_sizes, output, output_offsets,
recv_sizes, replica_groups, channel_id)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
input |
XlaOp |
Mảng N thuộc loại T |
input_offsets |
XlaOp |
Mảng N thuộc loại T |
send_sizes |
XlaOp |
Mảng N thuộc loại T |
output |
XlaOp |
Mảng N thuộc loại T |
output_offsets |
XlaOp |
Mảng N thuộc loại T |
recv_sizes |
XlaOp |
Mảng N thuộc loại T |
replica_groups
|
ReplicaGroup vectơ
|
Mỗi nhóm chứa một danh sách mã nhận dạng bản sao. |
channel_id
|
không bắt buộc ChannelHandle
|
giá trị nhận dạng riêng biệt cho mỗi cặp gửi/nhận |
Tensor thưa được xác định bằng một tập hợp gồm 3 tensor:
data:datatensor là "không đồng đều" dọc theo chiều ngoài cùng, dọc theo đó mỗi phần tử được lập chỉ mục có kích thước thay đổi.offsets: tenxơoffsetslập chỉ mục chiều ngoài cùng của tenxơdatavà biểu thị độ lệch bắt đầu của từng phần tử không đồng đều của tenxơdata.sizes: tenxơsizesbiểu thị kích thước của từng phần tử không đồng đều của tenxơdata, trong đó kích thước được chỉ định theo đơn vị của các phần tử phụ. Phần tử con được xác định là hậu tố của hình dạng tenxơ "dữ liệu" thu được bằng cách xoá chiều "không đều" ngoài cùng.- Các tensor
offsetsvàsizesphải có cùng kích thước.
Ví dụ về một tensor thưa:
data: [8,3] =
{ {a,b,c},{d,e,f},{g,h,i},{j,k,l},{m,n,o},{p,q,r},{s,t,u},{v,w,x} }
offsets: [3] = {0, 1, 4}
sizes: [3] = {1, 3, 4}
// Index 'data' at 'offsets'[0], 'sizes'[0]' // {a,b,c}
// Index 'data' at 'offsets'[1], 'sizes'[1]' // {d,e,f},{g,h,i},{j,k,l}
// Index 'data' at 'offsets'[2], 'sizes'[2]' // {m,n,o},{p,q,r},{s,t,u},{v,w,x}
output_offsets phải được phân đoạn theo cách mà mỗi bản sao có độ lệch trong góc nhìn đầu ra của bản sao đích.
Đối với độ lệch đầu ra thứ i, bản sao hiện tại sẽ gửi bản cập nhật input[input_offsets[i]:input_offsets[i]+send_sizes[i]] đến bản sao thứ i sẽ được ghi vào output_i[output_offsets[i]:output_offsets[i]+send_sizes[i]] trong bản sao thứ i output.
Ví dụ: nếu chúng ta có 2 bản sao:
replica 0:
input: [1, 2, 2]
output:[0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 2]
output_offsets: [0, 0]
recv_sizes: [1, 1]
replica 1:
input: [3, 4, 0]
output: [0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 1]
output_offsets: [1, 2]
recv_sizes: [2, 1]
// replica 0's result will be: [1, 3, 0, 0]
// replica 1's result will be: [2, 2, 4, 0]
HLO không đồng đều từ tất cả đến tất cả có các đối số sau:
input: tensor dữ liệu đầu vào không đồng đều.output: tensor dữ liệu đầu ra không đồng đều.input_offsets: tensor bù đầu vào không đều.send_sizes: tensor kích thước gửi không đều.output_offsets: mảng gồm các mức chênh lệch không đều trong đầu ra của bản sao đích.recv_sizes: tensor có kích thước recv không đều.
Tất cả các tensor *_offsets và *_sizes đều phải có cùng hình dạng.
Hai hình dạng được hỗ trợ cho các tensor *_offsets và *_sizes:
[num_devices]trong đó ragged-all-to-all có thể gửi tối đa một bản cập nhật cho mỗi thiết bị từ xa trong nhóm bản sao. Ví dụ:
for (remote_device_id : replica_group) {
SEND input[input_offsets[remote_device_id]],
output[output_offsets[remote_device_id]],
send_sizes[remote_device_id] }
[num_devices, num_updates]trong đó ragged-all-to-all có thể gửi tối đanum_updatesbản cập nhật cho cùng một thiết bị từ xa (mỗi bản cập nhật ở các độ lệch khác nhau), cho mỗi thiết bị từ xa trong nhóm bản sao.
Ví dụ:
for (remote_device_id : replica_group) {
for (update_idx : num_updates) {
SEND input[input_offsets[remote_device_id][update_idx]],
output[output_offsets[remote_device_id][update_idx]]],
send_sizes[remote_device_id][update_idx] } }
và
Xem thêm XlaBuilder::And.
Thực hiện phép toán AND theo phần tử của hai tensor lhs và rhs.
And(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Một biến thể thay thế có hỗ trợ truyền hình nhiều chiều tồn tại cho And:
And(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – và.
Không đồng bộ
Xem thêm HloInstruction::CreateAsyncStart, HloInstruction::CreateAsyncUpdate, HloInstruction::CreateAsyncDone.
AsyncDone, AsyncStart và AsyncUpdate là các chỉ dẫn HLO nội bộ được dùng cho các hoạt động không đồng bộ và đóng vai trò là các thành phần cơ bản trong HLO. Các thao tác này có thể xuất hiện trong các kết xuất HLO nhưng người dùng cuối không được phép tạo các thao tác này theo cách thủ công.
Atan2
Xem thêm XlaBuilder::Atan2.
Thực hiện thao tác atan2 theo từng phần tử trên lhs và rhs.
Atan2(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Có một biến thể thay thế hỗ trợ truyền tin nhiều chiều cho Atan2:
Atan2(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – atan2.
BatchNormGrad
Xem thêm XlaBuilder::BatchNormGrad và bài viết gốc về chuẩn hoá theo lô để biết nội dung mô tả chi tiết về thuật toán này.
Tính toán độ dốc của chuẩn hoá theo lô.
BatchNormGrad(operand, scale, batch_mean, batch_var, grad_output, epsilon,
feature_index)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp | Mảng n chiều cần được chuẩn hoá (x) |
scale |
XlaOp | Mảng 1 chiều (\(\gamma\)) |
batch_mean |
XlaOp | Mảng 1 chiều (\(\mu\)) |
batch_var |
XlaOp | Mảng 1 chiều (\(\sigma^2\)) |
grad_output |
XlaOp | Các chuyển màu được truyền đến BatchNormTraining (\(\nabla y\)) |
epsilon |
float |
Giá trị epsilon (\(\epsilon\)) |
feature_index |
int64 |
Chỉ mục cho phương diện đối tượng trong operand |
Đối với mỗi đối tượng trong phương diện đối tượng (feature_index là chỉ mục cho phương diện đối tượng trong operand), thao tác này sẽ tính toán độ dốc liên quan đến operand, offset và scale trên tất cả các phương diện khác. feature_index phải là một chỉ mục hợp lệ cho phương diện đối tượng trong operand.
Ba độ dốc được xác định bằng các công thức sau (giả sử mảng 4 chiều là operand và có chỉ mục phương diện đối tượng l, kích thước lô m và kích thước không gian w và h):
\[ \begin{split} c_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) \\\\ d_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \\\\ \nabla x_{ijkl} &= \frac{\gamma_{l} }{\sqrt{\sigma^2_{l}+\epsilon} } \left( \nabla y_{ijkl} - d_l - c_l (x_{ijkl} - \mu_{l}) \right) \\\\ \nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon} } \right) \\\\\ \nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \end{split} \]
Đầu vào batch_mean và batch_var biểu thị các giá trị khoảnh khắc trên các phương diện lô và không gian.
Loại đầu ra là một bộ gồm 3 đối tượng xử lý:
| Kết quả đầu ra | Loại | Ngữ nghĩa |
|---|---|---|
grad_operand
|
XlaOp | độ dốc liên quan đến đầu vào operand (\(\nabla x\)) |
grad_scale
|
XlaOp | độ dốc liên quan đến đầu vào **scale **
(\(\nabla\gamma\)) |
grad_offset
|
XlaOp | độ dốc liên quan đến đầu vào offset(\(\nabla\beta\)) |
Để biết thông tin về StableHLO, hãy xem StableHLO – batch_norm_grad.
BatchNormInference
Xem thêm XlaBuilder::BatchNormInference và bài viết gốc về chuẩn hoá theo lô để biết nội dung mô tả chi tiết về thuật toán này.
Chuẩn hoá một mảng trên các phương diện lô và không gian.
BatchNormInference(operand, scale, offset, mean, variance, epsilon,
feature_index)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp | mảng n chiều cần được chuẩn hoá |
scale |
XlaOp | Mảng một chiều |
offset |
XlaOp | Mảng một chiều |
mean |
XlaOp | Mảng một chiều |
variance |
XlaOp | Mảng một chiều |
epsilon |
float |
Giá trị Epsilon |
feature_index |
int64 |
Chỉ mục cho phương diện đối tượng trong operand |
Đối với mỗi đối tượng trong phương diện đối tượng (feature_index là chỉ mục cho phương diện đối tượng trong operand), thao tác này sẽ tính toán giá trị trung bình và phương sai trên tất cả các phương diện khác, đồng thời sử dụng giá trị trung bình và phương sai để chuẩn hoá từng phần tử trong operand. feature_index phải là một chỉ mục hợp lệ cho phương diện đối tượng trong operand.
BatchNormInference tương đương với việc gọi BatchNormTraining mà không cần tính toán mean và variance cho mỗi lô. Thay vào đó, nó sử dụng mean và variance đầu vào làm giá trị ước tính. Mục đích của thao tác này là giảm độ trễ trong quá trình suy luận, do đó có tên là BatchNormInference.
Đầu ra là một mảng n chiều, được chuẩn hoá có cùng hình dạng với đầu vào operand.
Để biết thông tin về StableHLO, hãy xem StableHLO – batch_norm_inference.
BatchNormTraining
Xem thêm XlaBuilder::BatchNormTraining và the original batch normalization paper để biết nội dung mô tả chi tiết về thuật toán.
Chuẩn hoá một mảng trên các phương diện lô và không gian.
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng n chiều cần được chuẩn hoá (x) |
scale |
XlaOp |
Mảng 1 chiều (\(\gamma\)) |
offset |
XlaOp |
Mảng 1 chiều (\(\beta\)) |
epsilon |
float |
Giá trị epsilon (\(\epsilon\)) |
feature_index |
int64 |
Chỉ mục cho phương diện đối tượng trong operand |
Đối với mỗi đối tượng trong phương diện đối tượng (feature_index là chỉ mục cho phương diện đối tượng trong operand), thao tác này sẽ tính toán giá trị trung bình và phương sai trên tất cả các phương diện khác, đồng thời sử dụng giá trị trung bình và phương sai để chuẩn hoá từng phần tử trong operand. feature_index phải là một chỉ mục hợp lệ cho phương diện đối tượng trong operand.
Thuật toán diễn ra như sau cho mỗi lô trong operand \(x\) chứa các phần tử m có w và h là kích thước của các phương diện không gian (giả sử operand là một mảng 4 chiều):
Tính toán giá trị trung bình theo lô \(\mu_l\) cho từng đối tượng
ltrong phương diện đối tượng: \(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\)Tính phương sai theo lô \(\sigma^2_l\):$\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} -\mu_l)^2$
Chuẩn hoá, điều chỉnh tỷ lệ và dịch chuyển: \(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon} }+\beta_l\)
Giá trị epsilon (thường là một số nhỏ) được thêm vào để tránh lỗi chia cho 0.
Loại đầu ra là một bộ gồm 3 XlaOp:
| Kết quả đầu ra | Loại | Ngữ nghĩa |
|---|---|---|
output
|
XlaOp
|
mảng n chiều có cùng hình dạng với đầu vào operand (y) |
batch_mean |
XlaOp |
Mảng 1 chiều (\(\mu\)) |
batch_var |
XlaOp |
Mảng 1 chiều (\(\sigma^2\)) |
batch_mean và batch_var là những thời điểm được tính toán trên các phương diện lô và không gian bằng các công thức ở trên.
Để biết thông tin về StableHLO, hãy xem StableHLO – batch_norm_training.
Bitcast
Xem thêm HloInstruction::CreateBitcast.
Bitcast có thể xuất hiện trong các kết xuất HLO, nhưng người dùng cuối không nên tạo các kết xuất này theo cách thủ công.
BitcastConvertType
Xem thêm XlaBuilder::BitcastConvertType.
Tương tự như tf.bitcast trong TensorFlow, thực hiện thao tác bitcast theo từng phần tử từ một hình dạng dữ liệu đến một hình dạng đích. Kích thước đầu vào và đầu ra phải khớp: ví dụ: s32 phần tử trở thành f32 phần tử thông qua quy trình bitcast và một phần tử s32 sẽ trở thành bốn phần tử s8. Bitcast được triển khai dưới dạng một thao tác truyền cấp thấp, vì vậy, các máy có nhiều cách biểu diễn số thực dấu phẩy động sẽ cho ra các kết quả khác nhau.
BitcastConvertType(operand, new_element_type)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại T có kích thước D |
new_element_type |
PrimitiveType |
loại U |
Kích thước của toán hạng và hình dạng đích phải khớp với nhau, ngoài kích thước cuối cùng sẽ thay đổi theo tỷ lệ kích thước nguyên thuỷ trước và sau khi chuyển đổi.
Loại phần tử nguồn và đích không được là bộ giá trị.
Để biết thông tin về StableHLO, hãy xem StableHLO – bitcast_convert.
Chuyển đổi Bitcast sang kiểu nguyên thuỷ có độ rộng khác
BitcastConvert Chỉ thị HLO hỗ trợ trường hợp kích thước của loại phần tử đầu ra T' không bằng kích thước của phần tử đầu vào T. Vì toàn bộ thao tác này về mặt khái niệm là một bitcast và không thay đổi các byte cơ bản, nên hình dạng của phần tử đầu ra phải thay đổi. Đối với B = sizeof(T), B' =
sizeof(T'), có 2 trường hợp có thể xảy ra.
Trước tiên, khi B > B', hình dạng đầu ra sẽ có một thứ nguyên phụ mới có kích thước nhỏ nhất là B/B'. Ví dụ:
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
Quy tắc vẫn giữ nguyên đối với các đại lượng vô hướng hiệu quả:
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
Ngoài ra, đối với B' > B, hướng dẫn yêu cầu chiều logic cuối cùng của hình dạng đầu vào phải bằng B'/B và chiều này sẽ bị loại bỏ trong quá trình chuyển đổi:
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
Xin lưu ý rằng các lượt chuyển đổi giữa các độ rộng bit khác nhau không phải là theo từng phần tử.
Phát đi thông báo
Xem thêm XlaBuilder::Broadcast.
Thêm phương diện vào một mảng bằng cách sao chép dữ liệu trong mảng.
Broadcast(operand, broadcast_sizes)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng cần sao chép |
broadcast_sizes |
ArraySlice<int64> |
Kích thước của các phương diện mới |
Các phương diện mới được chèn vào bên trái, tức là nếu broadcast_sizes có các giá trị {a0, ..., aN} và hình dạng toán hạng có các phương diện {b0, ..., bM} thì hình dạng của đầu ra sẽ có các phương diện {a0, ..., aN, b0, ..., bM}.
Chỉ mục kích thước mới vào các bản sao của toán hạng, tức là
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
Ví dụ: nếu operand là một đại lượng vô hướng f32 có giá trị 2.0f và broadcast_sizes là {2, 3}, thì kết quả sẽ là một mảng có hình dạng f32[2, 3] và tất cả các giá trị trong kết quả sẽ là 2.0f.
Để biết thông tin về StableHLO, hãy xem StableHLO – broadcast.
BroadcastInDim
Xem thêm XlaBuilder::BroadcastInDim.
Mở rộng kích thước và số lượng phương diện của một mảng bằng cách sao chép dữ liệu trong mảng.
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng cần sao chép |
out_dim_size
|
ArraySlice<int64>
|
Kích thước của các phương diện của hình dạng đích |
broadcast_dimensions
|
ArraySlice<int64>
|
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Tương tự như Broadcast, nhưng cho phép thêm phương diện ở bất kỳ vị trí nào và mở rộng các phương diện hiện có có kích thước là 1.
operand được truyền đến hình dạng do out_dim_size mô tả.
broadcast_dimensions ánh xạ các phương diện của operand đến các phương diện của hình dạng đích, tức là phương diện thứ i của toán hạng được ánh xạ đến phương diện thứ broadcast_dimension[i] của hình dạng đầu ra. Phương diện của operand phải có kích thước là 1 hoặc có cùng kích thước với phương diện trong hình dạng đầu ra mà chúng được ánh xạ đến. Các phương diện còn lại được điền bằng các phương diện có kích thước là 1. Sau đó, hoạt động truyền tin suy biến theo chiều sẽ truyền tin dọc theo các chiều suy biến này để đạt được hình dạng đầu ra. Ngữ nghĩa được mô tả chi tiết trên trang truyền tin.
Cuộc gọi
Xem thêm XlaBuilder::Call.
Gọi một phép tính bằng các đối số đã cho.
Call(computation, operands...)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
computation
|
XlaComputation
|
phép tính của loại T_0, T_1, ...,
T_{N-1} -> S với N tham số thuộc loại tuỳ ý |
operands |
chuỗi gồm N XlaOp |
N đối số thuộc loại tuỳ ý |
Tính chất và các loại của operands phải khớp với các tham số của computation. Bạn có thể không có operands.
CompositeCall
Xem thêm XlaBuilder::CompositeCall.
Đóng gói một thao tác được tạo thành từ các thao tác StableHLO khác, nhận đầu vào và composite_attributes, đồng thời tạo ra kết quả. Ngữ nghĩa của thao tác được triển khai bằng thuộc tính phân tách. Thao tác kết hợp có thể được thay thế bằng thao tác phân tách mà không làm thay đổi ngữ nghĩa của chương trình. Trong trường hợp việc nội tuyến thao tác phân tách không cung cấp cùng ngữ nghĩa thao tác, hãy ưu tiên sử dụng custom_call.
Trường phiên bản (mặc định là 0) được dùng để biểu thị thời điểm ngữ nghĩa của một thành phần thay đổi.
Thao tác này được triển khai dưới dạng kCall có thuộc tính is_composite=true. Trường decomposition được chỉ định bằng thuộc tính computation. Các thuộc tính giao diện người dùng lưu trữ các thuộc tính còn lại có tiền tố là composite..
Ví dụ về thao tác CompositeCall:
f32[] call(f32[] %cst), to_apply=%computation, is_composite=true,
frontend_attributes = {
composite.name="foo.bar",
composite.attributes={n = 1 : i32, tensor = dense<1> : tensor<i32>},
composite.version="1"
}
CompositeCall(computation, operands..., name, attributes, version)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
computation
|
XlaComputation
|
phép tính của loại T_0, T_1, ...,
T_{N-1} -> S với N tham số thuộc loại tuỳ ý |
operands |
chuỗi gồm N XlaOp |
số lượng giá trị thay đổi |
name |
string |
tên của thành phần |
attributes
|
không bắt buộc string
|
từ điển được chuyển đổi thành chuỗi không bắt buộc của các thuộc tính |
version
|
không bắt buộc int64
|
số lượng bản cập nhật phiên bản cho ngữ nghĩa của thao tác kết hợp |
decomposition của một thao tác không phải là một trường được gọi, mà thay vào đó xuất hiện dưới dạng thuộc tính to_apply trỏ đến hàm chứa việc triển khai cấp thấp hơn, tức là to_apply=%funcname
Bạn có thể xem thêm thông tin về thành phần và quá trình phân tách trong Quy cách StableHLO.
Cbrt
Xem thêm XlaBuilder::Cbrt.
Thao tác căn bậc ba theo từng phần tử x -> cbrt(x).
Cbrt(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Cbrt cũng hỗ trợ đối số result_accuracy không bắt buộc:
Cbrt(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – cbrt.
Trần
Xem thêm XlaBuilder::Ceil.
Hàm ceil theo phần tử x -> ⌈x⌉.
Ceil(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – ceil.
Cholesky
Xem thêm XlaBuilder::Cholesky.
Tính toán phân tích Cholesky của một lô ma trận xác định dương đối xứng (Hermitian).
Cholesky(a, lower)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
a
|
XlaOp
|
một mảng thuộc loại số phức hoặc dấu phẩy động có > 2 chiều. |
lower |
bool |
có nên sử dụng tam giác trên hay dưới của a hay không. |
Nếu lower là true, tính toán ma trận tam giác dưới l sao cho $a = l .
l^T$. Nếu lower là false, tính toán ma trận tam giác trên u sao cho\(a = u^T . u\).
Dữ liệu đầu vào chỉ được đọc từ tam giác dưới/trên của a, tuỳ thuộc vào giá trị của lower. Các giá trị từ tam giác còn lại sẽ bị bỏ qua. Dữ liệu đầu ra được trả về trong cùng một tam giác; các giá trị trong tam giác còn lại được xác định theo cách triển khai và có thể là bất kỳ giá trị nào.
Nếu a có hơn 2 phương diện, thì a được coi là một lô ma trận, trong đó tất cả trừ 2 phương diện phụ đều là phương diện lô.
Nếu a không đối xứng (Hermitian) xác định dương, thì kết quả sẽ do quá trình triển khai xác định.
Để biết thông tin về StableHLO, hãy xem StableHLO – cholesky.
Giới hạn giá trị trong một khoảng
Xem thêm XlaBuilder::Clamp.
Kẹp một toán hạng trong phạm vi giữa giá trị tối thiểu và tối đa.
Clamp(min, operand, max)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
min |
XlaOp |
mảng thuộc loại T |
operand |
XlaOp |
mảng thuộc loại T |
max |
XlaOp |
mảng thuộc loại T |
Cho trước một toán hạng và giá trị tối thiểu và tối đa, trả về toán hạng nếu toán hạng nằm trong phạm vi giữa giá trị tối thiểu và tối đa, nếu không, trả về giá trị tối thiểu nếu toán hạng nằm dưới phạm vi này hoặc giá trị tối đa nếu toán hạng nằm trên phạm vi này. Tức là clamp(a, x, b) = min(max(a, x), b).
Cả ba mảng phải có cùng hình dạng. Ngoài ra, dưới dạng một hình thức phát sóng bị hạn chế, min và/hoặc max có thể là một đại lượng vô hướng thuộc loại T.
Ví dụ về min và max vô hướng:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
Để biết thông tin về StableHLO, hãy xem StableHLO – clamp.
Thu gọn
Xem thêm XlaBuilder::Collapse.
và thao tác tf.reshape.
Thu gọn các phương diện của một mảng thành một phương diện.
Collapse(operand, dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại T |
dimensions |
int64 vectơ |
thứ tự, tập hợp con liên tiếp của các phương diện của T. |
Thu gọn sẽ thay thế tập hợp con đã cho của các phương diện của toán hạng bằng một phương diện duy nhất. Các đối số đầu vào là một mảng tuỳ ý thuộc loại T và một vectơ hằng số thời gian biên dịch của chỉ mục phương diện. Chỉ mục phương diện phải là một tập hợp con liên tiếp theo thứ tự (số phương diện từ thấp đến cao) của các phương diện của T. Do đó, {0, 1, 2}, {0, 1} hoặc {1, 2} đều là các tập hợp phương diện hợp lệ, nhưng {1, 0} hoặc {0, 2} thì không. Các phương diện này được thay thế bằng một phương diện mới duy nhất, ở cùng vị trí trong chuỗi phương diện như các phương diện mà chúng thay thế, với kích thước phương diện mới bằng tích của các kích thước phương diện ban đầu. Số thứ nguyên thấp nhất trong dimensions là thứ nguyên thay đổi chậm nhất (quan trọng nhất) trong nhóm lặp lại sẽ thu gọn các thứ nguyên này, còn số thứ nguyên cao nhất là thứ nguyên thay đổi nhanh nhất (ít quan trọng nhất). Hãy xem toán tử tf.reshape nếu bạn cần thêm thứ tự thu gọn chung.
Ví dụ: giả sử v là một mảng gồm 24 phần tử:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
Clz
Xem thêm XlaBuilder::Clz.
Đếm số lượng số 0 ở đầu theo từng phần tử.
Clz(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
CollectiveBroadcast
Xem thêm XlaBuilder::CollectiveBroadcast.
Truyền dữ liệu trên các bản sao. Dữ liệu được gửi từ mã nhận dạng bản sao đầu tiên trong mỗi nhóm đến các mã nhận dạng khác trong cùng một nhóm. Nếu mã nhận dạng bản sao không nằm trong nhóm bản sao nào, thì đầu ra trên bản sao đó là một tensor bao gồm 0(s) trong shape.
CollectiveBroadcast(operand, replica_groups, channel_id)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
replica_groups
|
ReplicaGroupvector
|
Mỗi nhóm chứa một danh sách mã nhận dạng bản sao |
channel_id
|
không bắt buộc ChannelHandle
|
giá trị nhận dạng riêng biệt cho mỗi cặp gửi/nhận |
Để biết thông tin về StableHLO, hãy xem StableHLO – collective_broadcast.
CollectivePermute
Xem thêm XlaBuilder::CollectivePermute.
CollectivePermute là một thao tác tập thể gửi và nhận dữ liệu trên các bản sao.
CollectivePermute(operand, source_target_pairs, channel_id)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng đầu vào n chiều |
source_target_pairs
|
<int64, int64> vectơ
|
Một danh sách các cặp (source_replica_id, target_replica_id). Đối với mỗi cặp, toán hạng được gửi từ bản sao nguồn đến bản sao đích. |
channel_id
|
không bắt buộc ChannelHandle
|
Mã nhận dạng kênh không bắt buộc để giao tiếp giữa các mô-đun |
Xin lưu ý rằng source_target_pairs có các hạn chế sau:
- Không có hai cặp nào được có cùng mã nhận dạng bản sao đích và chúng không được có cùng mã nhận dạng bản sao nguồn.
- Nếu mã nhận dạng bản sao không phải là đích đến trong bất kỳ cặp nào, thì đầu ra trên bản sao đó là một tensor bao gồm 0(s) có cùng hình dạng với đầu vào.
API của thao tác CollectivePermute được phân tách nội bộ thành 2 chỉ dẫn HLO (CollectivePermuteStart và CollectivePermuteDone).
Xem thêm HloInstruction::CreateCollectivePermuteStart.
CollectivePermuteStart và CollectivePermuteDone đóng vai trò là các thành phần cơ bản trong HLO. Các thao tác này có thể xuất hiện trong các tệp kết xuất HLO, nhưng người dùng cuối không nên tạo các thao tác này theo cách thủ công.
Để biết thông tin về StableHLO, hãy xem StableHLO – collective_permute.
So sánh
Xem thêm XlaBuilder::Compare.
Thực hiện so sánh từng phần tử của lhs và rhs như sau:
Eq
Xem thêm XlaBuilder::Eq.
Thực hiện phép so sánh bằng theo phần tử của lhs và rhs.
\(lhs = rhs\)
Eq(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Một biến thể thay thế có hỗ trợ truyền tin nhiều chiều tồn tại cho Eq:
Eq(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Hỗ trợ tổng số đơn đặt hàng trên số thực cho Eq, bằng cách thực thi:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
EqTotalOrder(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Để biết thông tin về StableHLO, hãy xem StableHLO – so sánh.
Ne
Xem thêm XlaBuilder::Ne.
Thực hiện phép so sánh không bằng theo từng phần tử của lhs và rhs.
\(lhs != rhs\)
Ne(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Ne có một biến thể thay thế hỗ trợ truyền hình nhiều chiều:
Ne(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Hỗ trợ tổng đơn đặt hàng trên số dấu phẩy động tồn tại cho Ne, bằng cách thực thi:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
NeTotalOrder(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Để biết thông tin về StableHLO, hãy xem StableHLO – so sánh.
Ge
Xem thêm XlaBuilder::Ge.
Thực hiện phép so sánh greater-or-equal-than theo phần tử của lhs và rhs.
\(lhs >= rhs\)
Ge(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Ge có một biến thể thay thế hỗ trợ truyền hình nhiều chiều:
Ge(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Hỗ trợ tổng số đơn đặt hàng trên số thực dấu phẩy động tồn tại cho Gt, bằng cách thực thi:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
GtTotalOrder(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Để biết thông tin về StableHLO, hãy xem StableHLO – so sánh.
Gt
Xem thêm XlaBuilder::Gt.
Thực hiện phép so sánh lớn hơn theo từng phần tử của lhs và rhs.
\(lhs > rhs\)
Gt(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Gt có một biến thể thay thế hỗ trợ truyền tin nhiều chiều:
Gt(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – so sánh.
Le
Xem thêm XlaBuilder::Le.
Thực hiện phép so sánh less-or-equal-than theo phần tử của lhs và rhs.
\(lhs <= rhs\)
Le(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Đối với Le, có một biến thể thay thế hỗ trợ truyền hình nhiều chiều:
Le(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Hỗ trợ tổng đơn đặt hàng trên số dấu phẩy động tồn tại cho Le, bằng cách thực thi:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LeTotalOrder(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Để biết thông tin về StableHLO, hãy xem StableHLO – so sánh.
Lt
Xem thêm XlaBuilder::Lt.
Thực hiện phép so sánh nhỏ hơn theo phần tử của lhs và rhs.
\(lhs < rhs\)
Lt(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Một biến thể thay thế có hỗ trợ truyền hình nhiều chiều tồn tại cho Lt:
Lt(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Hỗ trợ tổng đơn đặt hàng trên số dấu phẩy động tồn tại cho Lt, bằng cách thực thi:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LtTotalOrder(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Để biết thông tin về StableHLO, hãy xem StableHLO – so sánh.
Phức tạp
Xem thêm XlaBuilder::Complex.
Thực hiện chuyển đổi từng phần tử thành một giá trị phức từ một cặp giá trị thực và giá trị ảo, lhs và rhs.
Complex(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Complex có một biến thể thay thế hỗ trợ truyền hình nhiều chiều:
Complex(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – complex.
ConcatInDim (Nối)
Xem thêm XlaBuilder::ConcatInDim.
Hàm nối tạo một mảng từ nhiều toán hạng mảng. Mảng này có cùng số chiều với mỗi toán hạng mảng đầu vào (các toán hạng này phải có cùng số chiều với nhau) và chứa các đối số theo thứ tự được chỉ định.
Concatenate(operands..., dimension)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operands
|
chuỗi N XlaOp
|
N mảng thuộc loại T có kích thước [L0, L1, ...]. Yêu cầu N >= 1. |
dimension
|
int64
|
Một giá trị trong khoảng [0, N) đặt tên cho phương diện cần nối giữa operands. |
Ngoại trừ dimension, tất cả phương diện phải giống nhau. Điều này là do XLA không hỗ trợ mảng "không đồng đều". Ngoài ra, hãy lưu ý rằng bạn không thể nối các giá trị 0 chiều (vì không thể đặt tên cho phương diện mà theo đó quá trình nối diễn ra).
Ví dụ về 1 chiều:
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
//Output: {2, 3, 4, 5, 6, 7}
Ví dụ về 2 chiều:
let a = { {1, 2},
{3, 4},
{5, 6} };
let b = { {7, 8} };
Concat({a, b}, 0)
//Output: { {1, 2},
// {3, 4},
// {5, 6},
// {7, 8} }
Sơ đồ:
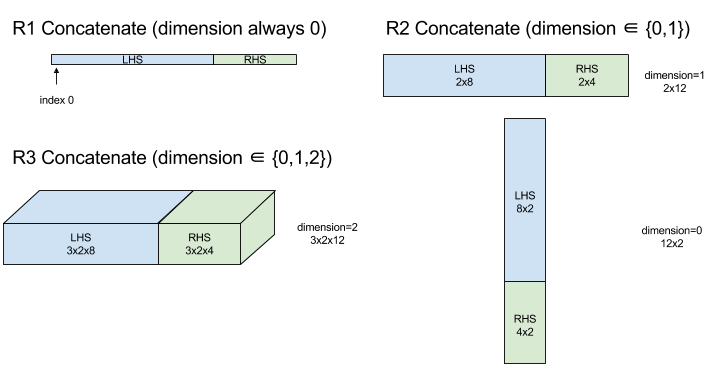
Để biết thông tin về StableHLO, hãy xem StableHLO – concatenate.
Câu lệnh có điều kiện
Xem thêm XlaBuilder::Conditional.
Conditional(predicate, true_operand, true_computation, false_operand,
false_computation)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
predicate |
XlaOp |
Vô hướng thuộc loại PRED |
true_operand |
XlaOp |
Đối số thuộc loại \(T_0\) |
true_computation |
XlaComputation |
XlaComputation thuộc loại \(T_0 \to S\) |
false_operand |
XlaOp |
Đối số thuộc loại \(T_1\) |
false_computation |
XlaComputation |
XlaComputation thuộc loại \(T_1 \to S\) |
Thực thi true_computation nếu predicate là true, false_computation nếu predicate là false và trả về kết quả.
true_computation phải nhận một đối số duy nhất thuộc loại \(T_0\) và sẽ được gọi bằng true_operand (phải thuộc cùng một loại). false_computation phải nhận một đối số duy nhất thuộc loại \(T_1\) và sẽ được gọi bằng false_operand (phải thuộc cùng một loại). Loại giá trị được trả về của true_computation và false_computation phải giống nhau.
Xin lưu ý rằng chỉ một trong true_computation và false_computation sẽ được thực thi tuỳ thuộc vào giá trị của predicate.
Conditional(branch_index, branch_computations, branch_operands)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
branch_index |
XlaOp |
Vô hướng thuộc loại S32 |
branch_computations |
chuỗi N XlaComputation |
XlaComputations thuộc loại \(T_0 \to S , T_1 \to S , ..., T_{N-1} \to S\) |
branch_operands |
chuỗi N XlaOp |
Đối số thuộc loại \(T_0 , T_1 , ..., T_{N-1}\) |
Thực thi branch_computations[branch_index] và trả về kết quả. Nếu branch_index là một S32 nhỏ hơn 0 hoặc lớn hơn hoặc bằng N, thì branch_computations[N-1] sẽ được thực thi dưới dạng nhánh mặc định.
Mỗi branch_computations[b] phải nhận một đối số duy nhất thuộc loại \(T_b\) và sẽ được gọi bằng branch_operands[b] (phải thuộc cùng một loại). Loại giá trị trả về của mỗi branch_computations[b] phải giống nhau.
Xin lưu ý rằng chỉ một trong các branch_computations sẽ được thực thi tuỳ thuộc vào giá trị của branch_index.
Để biết thông tin về StableHLO, hãy xem StableHLO – if.
Hằng số
Xem thêm XlaBuilder::ConstantLiteral.
Tạo ra một output từ một literal hằng số.
Constant(literal)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
literal |
LiteralSlice |
chế độ xem liên tục của một Literal hiện có |
Để biết thông tin về StableHLO, hãy xem StableHLO – hằng số.
ConvertElementType
Xem thêm XlaBuilder::ConvertElementType.
Tương tự như static_cast theo từng phần tử trong C++, ConvertElementType thực hiện một thao tác chuyển đổi theo từng phần tử từ một hình dạng dữ liệu sang một hình dạng mục tiêu. Các phương diện phải khớp và quá trình chuyển đổi là theo từng phần tử; ví dụ: các phần tử s32 trở thành các phần tử f32 thông qua một quy trình chuyển đổi từ s32 sang f32.
ConvertElementType(operand, new_element_type)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại T có kích thước D |
new_element_type |
PrimitiveType |
loại U |
Kích thước của toán hạng và hình dạng đích phải khớp với nhau. Các loại phần tử nguồn và đích không được là bộ giá trị.
Một lượt chuyển đổi như T=s32 thành U=f32 sẽ thực hiện một quy trình chuyển đổi int sang float chuẩn hoá, chẳng hạn như làm tròn đến số chẵn gần nhất.
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
Để biết thông tin về StableHLO, hãy xem StableHLO – convert.
Conv (Tích chập)
Xem thêm XlaBuilder::Conv.
Tính toán một phép tích chập thuộc loại được dùng trong mạng nơ-ron. Ở đây, bạn có thể coi một phép tích chập là một cửa sổ n chiều di chuyển trên một vùng cơ sở n chiều và một phép tính được thực hiện cho từng vị trí có thể có của cửa sổ.
Conv Xếp hàng một chỉ dẫn tích chập vào quá trình tính toán, sử dụng các số chiều tích chập mặc định mà không có độ giãn nở.
Khoảng đệm được chỉ định theo cách viết tắt là SAME hoặc VALID. SAME (GIỐNG NHAU) sẽ thêm các số 0 vào đầu vào (lhs) để đầu ra có cùng hình dạng với đầu vào khi không tính đến bước sải. Khoảng đệm HỢP LỆ chỉ đơn giản là không có khoảng đệm.
Conv(lhs, rhs, window_strides, padding, feature_group_count,
batch_group_count, precision_config, preferred_element_type)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs
|
XlaOp
|
Mảng đầu vào (n+2) chiều |
rhs
|
XlaOp
|
Mảng (n+2) chiều của trọng số hạt nhân |
window_strides |
ArraySlice<int64> |
mảng n chiều của bước sải hạt nhân |
padding |
Padding |
enum của khoảng đệm |
feature_group_count
|
int64 | số lượng nhóm đối tượng |
batch_group_count |
int64 | số lượng nhóm lô |
precision_config
|
không bắt buộc
PrecisionConfig |
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc
PrimitiveType |
enum của loại phần tử vô hướng |
Conv có các cấp độ kiểm soát tăng dần như sau:
Giả sử n là số lượng chiều không gian. Đối số lhs là một mảng (n+2) chiều mô tả vùng cơ sở. Đây được gọi là đầu vào, mặc dù tất nhiên rhs cũng là đầu vào. Trong mạng nơ-ron, đây là các lượt kích hoạt đầu vào. n+2 phương diện theo thứ tự như sau:
batch: Mỗi toạ độ trong phương diện này đại diện cho một đầu vào độc lập mà quá trình tích chập được thực hiện.z/depth/features: Mỗi vị trí (y,x) trong vùng cơ sở đều có một vectơ được liên kết với vị trí đó, đi vào phương diện này.spatial_dims: Mô tả các phương diện không giannxác định vùng cơ sở mà cửa sổ di chuyển qua.
Đối số rhs là một mảng (n+2) chiều mô tả bộ lọc/hạt nhân/cửa sổ tích chập. Các phương diện theo thứ tự như sau:
output-z: Phương diệnzcủa đầu ra.input-z: Kích thước của phương diện này nhân vớifeature_group_countphải bằng kích thước của phương diệnzở phía bên trái.spatial_dims: Mô tả các phương diện không giannxác định cửa sổ n-d di chuyển trên vùng cơ sở.
Đối số window_strides chỉ định bước sải của cửa sổ tích chập theo kích thước không gian. Ví dụ: nếu bước sải theo kích thước không gian đầu tiên là 3, thì cửa sổ chỉ có thể được đặt tại các toạ độ mà chỉ mục không gian đầu tiên chia hết cho 3.
Đối số padding chỉ định lượng khoảng đệm bằng 0 sẽ được áp dụng cho vùng cơ sở. Lượng khoảng đệm có thể là số âm – giá trị tuyệt đối của khoảng đệm âm cho biết số lượng phần tử cần loại bỏ khỏi phương diện được chỉ định trước khi thực hiện phép tích chập. padding[0] chỉ định khoảng đệm cho phương diện y và padding[1] chỉ định khoảng đệm cho phương diện x. Mỗi cặp có khoảng đệm thấp là phần tử đầu tiên và khoảng đệm cao là phần tử thứ hai. Khoảng đệm thấp được áp dụng theo hướng chỉ mục thấp hơn, trong khi khoảng đệm cao được áp dụng theo hướng chỉ mục cao hơn. Ví dụ: nếu padding[1] là (2,3) thì sẽ có một khoảng đệm gồm 2 số 0 ở bên trái và 3 số 0 ở bên phải trong chiều không gian thứ hai. Việc sử dụng khoảng đệm tương đương với việc chèn các giá trị 0 tương tự vào đầu vào (lhs) trước khi thực hiện phép tích chập.
Các đối số lhs_dilation và rhs_dilation chỉ định hệ số giãn nở sẽ được áp dụng cho lhs và rhs, tương ứng, trong mỗi phương diện không gian. Nếu hệ số giãn nở trong một chiều không gian là d, thì d-1 lỗ sẽ được đặt ngầm giữa mỗi mục trong chiều đó, làm tăng kích thước của mảng. Các lỗ hổng được điền bằng giá trị không hoạt động, đối với tích chập có nghĩa là các số 0.
Việc giãn nở rhs còn được gọi là phép tích chập atrous. Để biết thêm thông tin, hãy xem tf.nn.atrous_conv2d. Sự giãn nở của lhs còn được gọi là phép tích chập chuyển vị. Để biết thêm thông tin, hãy xem tf.nn.conv2d_transpose.
Bạn có thể dùng đối số feature_group_count (giá trị mặc định là 1) cho các phép tích chập theo nhóm. feature_group_count cần là số chia của cả phương diện tính năng đầu vào và đầu ra. Nếu feature_group_count lớn hơn 1, điều đó có nghĩa là về mặt khái niệm, kích thước đối tượng đầu vào và đầu ra cũng như kích thước đối tượng đầu ra rhs được chia đều thành nhiều nhóm feature_group_count, mỗi nhóm bao gồm một chuỗi con liên tiếp của các đối tượng. Phương diện đối tượng đầu vào của rhs cần bằng với phương diện đối tượng đầu vào lhs chia cho feature_group_count (vì vậy, phương diện này đã có kích thước của một nhóm đối tượng đầu vào). Các nhóm thứ i được dùng cùng nhau để tính toán feature_group_count cho nhiều phép tích chập riêng biệt. Kết quả của các phép tích chập này được nối với nhau trong phương diện đối tượng đầu ra.
Đối với phép tích chập theo chiều sâu, đối số feature_group_count sẽ được đặt thành phương diện tính năng đầu vào và bộ lọc sẽ được định hình lại từ [filter_height, filter_width, in_channels, channel_multiplier] thành [filter_height, filter_width, 1, in_channels * channel_multiplier]. Để biết thêm thông tin chi tiết, hãy xem tf.nn.depthwise_conv2d.
Đối số batch_group_count (giá trị mặc định là 1) có thể dùng cho các bộ lọc được nhóm trong quá trình lan truyền ngược. batch_group_count phải là số chia của kích thước của phương diện lô lhs (đầu vào). Nếu batch_group_count lớn hơn 1, tức là phương diện lô đầu ra phải có kích thước input batch
/ batch_group_count. batch_group_count phải là số chia của kích thước đối tượng đầu ra.
Hình dạng đầu ra có các phương diện sau, theo thứ tự này:
batch: Kích thước của phương diện này nhân vớibatch_group_countphải bằng kích thước của phương diệnbatchở phía bên trái.z: Có cùng kích thước vớioutput-ztrên nhân (rhs).spatial_dims: Một giá trị cho mỗi vị trí hợp lệ của cửa sổ tích chập.

Hình trên cho thấy cách hoạt động của trường batch_group_count. Trên thực tế, chúng ta chia mỗi lô lhs thành batch_group_count nhóm và làm tương tự cho các đặc điểm đầu ra. Sau đó, đối với mỗi nhóm này, chúng ta sẽ thực hiện các phép tích chập theo cặp và nối đầu ra dọc theo chiều đặc trưng đầu ra. Ngữ nghĩa hoạt động của tất cả các phương diện khác (đặc điểm và không gian) vẫn giữ nguyên.
Vị trí hợp lệ của cửa sổ tích chập được xác định bằng các bước sải và kích thước của vùng cơ sở sau khi đệm.
Để mô tả những gì mà một phép tích chập thực hiện, hãy xem xét một phép tích chập 2d và chọn một số toạ độ cố định batch, z, y, x trong đầu ra. Sau đó, (y,x) là vị trí của một góc của cửa sổ trong vùng cơ sở (ví dụ: góc trên bên trái, tuỳ thuộc vào cách bạn diễn giải các kích thước không gian). Giờ đây, chúng ta có một cửa sổ 2d, lấy từ vùng cơ sở, trong đó mỗi điểm 2d được liên kết với một vectơ 1d, vì vậy, chúng ta sẽ có một hộp 3d. Từ hạt nhân tích chập, vì chúng ta đã cố định toạ độ đầu ra z, nên chúng ta cũng có một hộp 3d. Hai hộp này có cùng kích thước, vì vậy, chúng ta có thể lấy tổng của các tích theo phần tử giữa hai hộp (tương tự như tích vô hướng). Đó là giá trị đầu ra.
Xin lưu ý rằng nếu output-z là 5, thì mỗi vị trí của cửa sổ sẽ tạo ra 5 giá trị trong đầu ra thành phương diện z của đầu ra. Các giá trị này khác nhau ở phần nhân tích chập được dùng – có một hộp giá trị 3d riêng biệt được dùng cho mỗi toạ độ output-z. Vì vậy, bạn có thể coi đây là 5 phép tích chập riêng biệt với một bộ lọc khác nhau cho mỗi phép tích chập.
Sau đây là mã giả cho một phép tích chập 2D có khoảng đệm và bước sải:
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
precision_config được dùng để cho biết cấu hình độ chính xác. Cấp độ này quyết định xem phần cứng có nên cố gắng tạo thêm các chỉ dẫn mã máy để cung cấp hoạt động mô phỏng dtype chính xác hơn khi cần (tức là mô phỏng f32 trên TPU chỉ hỗ trợ bf16 matmul) hay không. Giá trị có thể là DEFAULT, HIGH, HIGHEST. Thông tin chi tiết khác trong các phần MXU.
preferred_element_type là một phần tử vô hướng của các loại đầu ra có độ chính xác cao/thấp hơn được dùng để tích luỹ. preferred_element_type đề xuất loại tích luỹ cho thao tác đã cho, tuy nhiên, điều này không được đảm bảo. Điều này cho phép một số phần phụ trợ phần cứng tích luỹ trong một loại khác và chuyển đổi sang loại đầu ra ưu tiên.
Để biết thông tin về StableHLO, hãy xem StableHLO – convolution.
ConvWithGeneralPadding
Xem thêm XlaBuilder::ConvWithGeneralPadding.
ConvWithGeneralPadding(lhs, rhs, window_strides, padding,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Tương tự như Conv khi cấu hình khoảng đệm là rõ ràng.
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs
|
XlaOp
|
Mảng đầu vào (n+2) chiều |
rhs
|
XlaOp
|
Mảng (n+2) chiều của trọng số hạt nhân |
window_strides |
ArraySlice<int64> |
mảng n chiều của bước sải hạt nhân |
padding
|
ArraySlice<
pair<int64,int64>> |
mảng n chiều của khoảng đệm (thấp, cao) |
feature_group_count
|
int64 | số lượng nhóm đối tượng |
batch_group_count |
int64 | số lượng nhóm lô |
precision_config
|
không bắt buộc
PrecisionConfig |
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc
PrimitiveType |
enum của loại phần tử vô hướng |
ConvWithGeneralDimensions
Xem thêm XlaBuilder::ConvWithGeneralDimensions.
ConvWithGeneralDimensions(lhs, rhs, window_strides, padding,
dimension_numbers, feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Tương tự như Conv trong đó số phương diện là số rõ ràng.
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs
|
XlaOp
|
Mảng đầu vào (n+2) chiều |
rhs
|
XlaOp
|
Mảng trọng số của nhân có (n+2) chiều |
window_strides
|
ArraySlice<int64>
|
mảng n chiều của các bước sải của hạt nhân |
padding |
Padding |
enum của khoảng đệm |
dimension_numbers
|
ConvolutionDimensionNumbers
|
số lượng phương diện |
feature_group_count
|
int64 | số lượng nhóm đối tượng |
batch_group_count
|
int64 | số lượng nhóm lô |
precision_config
|
không bắt buộc PrecisionConfig
|
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc PrimitiveType
|
enum của loại phần tử vô hướng |
ConvGeneral
Xem thêm XlaBuilder::ConvGeneral.
ConvGeneral(lhs, rhs, window_strides, padding, dimension_numbers,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Tương tự như Conv trong đó số phương diện và cấu hình khoảng đệm được xác định rõ ràng
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs
|
XlaOp
|
Mảng đầu vào (n+2) chiều |
rhs
|
XlaOp
|
Mảng trọng số của nhân có (n+2) chiều |
window_strides
|
ArraySlice<int64>
|
mảng n chiều của các bước sải của hạt nhân |
padding
|
ArraySlice<
pair<int64,int64>>
|
mảng n chiều của khoảng đệm (thấp, cao) |
dimension_numbers
|
ConvolutionDimensionNumbers
|
số lượng phương diện |
feature_group_count
|
int64 | số lượng nhóm đối tượng |
batch_group_count
|
int64 | số lượng nhóm lô |
precision_config
|
không bắt buộc PrecisionConfig
|
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc PrimitiveType
|
enum của loại phần tử vô hướng |
ConvGeneralDilated
Xem thêm XlaBuilder::ConvGeneralDilated.
ConvGeneralDilated(lhs, rhs, window_strides, padding, lhs_dilation,
rhs_dilation, dimension_numbers, feature_group_count, batch_group_count,
precision_config, preferred_element_type, window_reversal)
Tương tự như Conv, trong đó cấu hình khoảng đệm, hệ số giãn nở và số lượng phương diện là rõ ràng.
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs
|
XlaOp
|
Mảng đầu vào (n+2) chiều |
rhs
|
XlaOp
|
Mảng trọng số của nhân có (n+2) chiều |
window_strides
|
ArraySlice<int64>
|
mảng n chiều của các bước sải của hạt nhân |
padding
|
ArraySlice<
pair<int64,int64>>
|
mảng n chiều của khoảng đệm (thấp, cao) |
lhs_dilation
|
ArraySlice<int64>
|
mảng hệ số giãn nở n-d lhs |
rhs_dilation
|
ArraySlice<int64>
|
mảng hệ số giãn nở n chiều bên phải |
dimension_numbers
|
ConvolutionDimensionNumbers
|
số lượng phương diện |
feature_group_count
|
int64 | số lượng nhóm đối tượng |
batch_group_count
|
int64 | số lượng nhóm lô |
precision_config
|
không bắt buộc PrecisionConfig
|
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc PrimitiveType
|
enum của loại phần tử vô hướng |
window_reversal
|
không bắt buộc vector<bool>
|
cờ dùng để đảo ngược kích thước một cách hợp lý trước khi áp dụng phép tích chập |
Sao chép
Xem thêm HloInstruction::CreateCopyStart.
Copy được phân tách nội bộ thành 2 chỉ dẫn HLO CopyStart và CopyDone. Copy cùng với CopyStart và CopyDone đóng vai trò là các thành phần cơ bản trong HLO. Các thao tác này có thể xuất hiện trong các kết xuất HLO, nhưng người dùng cuối không được phép tạo các thao tác này theo cách thủ công.
Cos
Xem thêm XlaBuilder::Cos.
Cosine theo phần tử x -> cos(x).
Cos(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Cos cũng hỗ trợ đối số result_accuracy không bắt buộc:
Cos(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – cosine.
Cosh
Xem thêm XlaBuilder::Cosh.
Hàm cos hyperbol theo phần tử x -> cosh(x).
Cosh(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Hàm cosh cũng hỗ trợ đối số result_accuracy không bắt buộc:
Cosh(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
CustomCall
Xem thêm XlaBuilder::CustomCall.
Gọi một hàm do người dùng cung cấp trong quá trình tính toán.
Tài liệu về CustomCall có trong phần Thông tin chi tiết về nhà phát triển – Lệnh gọi tuỳ chỉnh XLA
Để biết thông tin về StableHLO, hãy xem StableHLO – custom_call.
TTB
Xem thêm XlaBuilder::Div.
Thực hiện phép chia từng phần tử của số bị chia lhs và số chia rhs.
Div(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Tràn số nguyên khi chia (chia/dư số có dấu/không dấu cho 0 hoặc chia/dư số có dấu của INT_SMIN với -1) sẽ tạo ra một giá trị do quá trình triển khai xác định.
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Có một biến thể thay thế hỗ trợ truyền hình nhiều chiều cho Div:
Div(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – divide.
Miền
Xem thêm HloInstruction::CreateDomain.
Domain có thể xuất hiện trong các kết xuất HLO, nhưng người dùng cuối không nên tự tạo Domain theo cách thủ công.
Chấm
Xem thêm XlaBuilder::Dot.
Dot(lhs, rhs, precision_config, preferred_element_type)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs |
XlaOp |
mảng thuộc loại T |
rhs |
XlaOp |
mảng thuộc loại T |
precision_config
|
không bắt buộc
PrecisionConfig |
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc
PrimitiveType |
enum của loại phần tử vô hướng |
Ngữ nghĩa chính xác của thao tác này phụ thuộc vào thứ hạng của các toán hạng:
| Đầu vào | Đầu ra | Ngữ nghĩa |
|---|---|---|
vector [n] dot vector [n] |
đại lượng vô hướng | tích vô hướng của vectơ |
ma trận [m x k] dot vectơ
[k] |
vectơ [m] | phép nhân ma trận-vectơ |
ma trận [m x k] dot ma trận [k x n] |
ma trận [m x n] | phép nhân ma trận với ma trận |
Thao tác này thực hiện tổng của các tích trên phương diện thứ hai của lhs (hoặc phương diện đầu tiên nếu có 1 phương diện) và phương diện đầu tiên của rhs. Đây là các phương diện "được thu gọn". Các phương diện được thu gọn của lhs và rhs phải có cùng kích thước. Trên thực tế, bạn có thể dùng hàm này để thực hiện các phép tính tích vô hướng giữa các vectơ, phép nhân vectơ/ma trận hoặc phép nhân ma trận/ma trận.
precision_config được dùng để cho biết cấu hình độ chính xác. Cấp độ này quyết định xem phần cứng có nên cố gắng tạo thêm các chỉ dẫn mã máy để cung cấp hoạt động mô phỏng dtype chính xác hơn khi cần (tức là mô phỏng f32 trên TPU chỉ hỗ trợ bf16 matmul) hay không. Giá trị có thể là DEFAULT, HIGH, HIGHEST. Thông tin chi tiết khác trong các phần MXU.
preferred_element_type là một phần tử vô hướng của các loại đầu ra có độ chính xác cao/thấp hơn được dùng để tích luỹ. preferred_element_type đề xuất loại tích luỹ cho thao tác đã cho, tuy nhiên, điều này không được đảm bảo. Điều này cho phép một số phần phụ trợ phần cứng tích luỹ trong một loại khác và chuyển đổi sang loại đầu ra ưu tiên.
Để biết thông tin về StableHLO, hãy xem StableHLO – dot.
DotGeneral
Xem thêm XlaBuilder::DotGeneral.
DotGeneral(lhs, rhs, dimension_numbers, precision_config,
preferred_element_type)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs |
XlaOp |
mảng thuộc loại T |
rhs |
XlaOp |
mảng thuộc loại T |
dimension_numbers
|
DotDimensionNumbers
|
số lượng hợp đồng và số lượng kích thước theo lô |
precision_config
|
không bắt buộc
PrecisionConfig |
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc
PrimitiveType |
enum của loại phần tử vô hướng |
Tương tự như Dot, nhưng cho phép chỉ định số lượng kích thước theo lô và số lượng kích thước theo lô cho cả lhs và rhs.
| Trường DotDimensionNumbers | Loại | Ngữ nghĩa |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | lhs số lượng phương diện thu hẹp |
rhs_contracting_dimensions
|
repeated int64 | rhs số lượng phương diện thu hẹp |
lhs_batch_dimensions
|
repeated int64 | lhs số phương diện theo lô |
rhs_batch_dimensions
|
repeated int64 | rhs số phương diện theo lô |
DotGeneral thực hiện tổng các sản phẩm trên các phương diện thu hẹp được chỉ định trong dimension_numbers.
Số đo kích thước hợp đồng liên kết từ lhs và rhs không cần phải giống nhau nhưng phải có cùng kích thước.
Ví dụ về số đo kích thước thu hẹp:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { { 6.0, 12.0},
{15.0, 30.0} }
Các số phương diện theo lô được liên kết từ lhs và rhs phải có cùng kích thước phương diện.
Ví dụ về số lượng phương diện theo lô (kích thước lô là 2, ma trận 2x2):
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> {
{ {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| Đầu vào | Đầu ra | Ngữ nghĩa |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | matmul theo lô |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | matmul theo lô |
Theo đó, số thứ nguyên thu được sẽ bắt đầu bằng thứ nguyên lô, sau đó là thứ nguyên lhs không thu hẹp/không theo lô và cuối cùng là thứ nguyên rhs không thu hẹp/không theo lô.
precision_config được dùng để cho biết cấu hình độ chính xác. Cấp độ này quyết định xem phần cứng có nên cố gắng tạo thêm các chỉ dẫn mã máy để cung cấp hoạt động mô phỏng dtype chính xác hơn khi cần (tức là mô phỏng f32 trên TPU chỉ hỗ trợ bf16 matmul) hay không. Giá trị có thể là DEFAULT, HIGH, HIGHEST. Bạn có thể xem thêm thông tin chi tiết trong các phần về MXU.
preferred_element_type là một phần tử vô hướng của các loại đầu ra có độ chính xác cao/thấp hơn được dùng để tích luỹ. preferred_element_type đề xuất loại tích luỹ cho thao tác đã cho, tuy nhiên, điều này không được đảm bảo. Điều này cho phép một số phần phụ trợ phần cứng tích luỹ trong một loại khác và chuyển đổi sang loại đầu ra ưu tiên.
Để biết thông tin về StableHLO, hãy xem StableHLO – dot_general.
ScaledDot
Xem thêm XlaBuilder::ScaledDot.
ScaledDot(lhs, lhs_scale, rhs, rhs_scale, dimension_number,
precision_config,preferred_element_type)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
lhs |
XlaOp |
mảng thuộc loại T |
rhs |
XlaOp |
mảng thuộc loại T |
lhs_scale |
XlaOp |
mảng thuộc loại T |
rhs_scale |
XlaOp |
mảng thuộc loại T |
dimension_number
|
ScatterDimensionNumbers
|
Số phương diện cho thao tác phân tán |
precision_config
|
PrecisionConfig
|
enum cho mức độ chính xác |
preferred_element_type
|
không bắt buộc PrimitiveType
|
enum của loại phần tử vô hướng |
Tương tự như DotGeneral.
Tạo một thao tác chấm được chia tỷ lệ với các toán hạng "lhs", "lhs_scale", "rhs" và "rhs_scale", với các phương diện thu hẹp và theo lô được chỉ định trong "dimension_numbers".
RaggedDot
Xem thêm XlaBuilder::RaggedDot.
Để biết thông tin chi tiết về cách tính toán RaggedDot, hãy xem StableHLO – chlo.ragged_dot
DynamicReshape
Xem thêm XlaBuilder::DynamicReshape.
Thao tác này có chức năng giống hệt như reshape, nhưng hình dạng kết quả được chỉ định linh hoạt thông qua output_shape.
DynamicReshape(operand, dim_sizes, new_size_bounds, dims_are_dynamic)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng N chiều thuộc loại T |
dim_sizes |
vectơ của XlaOP |
Kích thước vectơ N chiều |
new_size_bounds |
vectơ của int63 |
Vectơ N chiều của các giới hạn |
dims_are_dynamic |
vectơ của bool |
N chiều động |
Để biết thông tin về StableHLO, hãy xem StableHLO – dynamic_reshape.
DynamicSlice
Xem thêm XlaBuilder::DynamicSlice.
DynamicSlice trích xuất một mảng con từ mảng đầu vào tại start_indices động. Kích thước của lát cắt trong mỗi phương diện được truyền vào size_indices, chỉ định điểm cuối của các khoảng lát cắt loại trừ trong mỗi phương diện: [start, start + size). Hình dạng của start_indices phải là 1 chiều, với kích thước phương diện bằng số phương diện của operand.
DynamicSlice(operand, start_indices, slice_sizes)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng N chiều thuộc loại T |
start_indices
|
chuỗi N XlaOp
|
Danh sách N số nguyên vô hướng chứa các chỉ mục bắt đầu của lát cắt cho mỗi phương diện. Giá trị phải lớn hơn hoặc bằng 0. |
size_indices
|
ArraySlice<int64>
|
Danh sách gồm N số nguyên chứa kích thước lát cắt cho từng phương diện. Mỗi giá trị phải lớn hơn 0 và start + size phải nhỏ hơn hoặc bằng kích thước của phương diện để tránh bao bọc kích thước phương diện theo mô-đun. |
Các chỉ mục lát hiệu quả được tính bằng cách áp dụng phép biến đổi sau cho mỗi chỉ mục i trong [1, N) trước khi thực hiện lát:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - slice_sizes[i])
Điều này đảm bảo rằng lát cắt được trích xuất luôn nằm trong phạm vi liên quan đến mảng toán hạng. Nếu lát cắt nằm trong phạm vi trước khi áp dụng phép biến đổi, thì phép biến đổi sẽ không có tác dụng.
Ví dụ về 1 chiều:
let a = {0.0, 1.0, 2.0, 3.0, 4.0};
let s = {2};
DynamicSlice(a, s, {2});
// Result: {2.0, 3.0}
Ví dụ về 2 chiều:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2});
//Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
Để biết thông tin về StableHLO, hãy xem StableHLO – dynamic_slice.
DynamicUpdateSlice
Xem thêm XlaBuilder::DynamicUpdateSlice.
DynamicUpdateSlice tạo ra một kết quả là giá trị của mảng đầu vào operand, với một lát update được ghi đè tại start_indices.
Hình dạng của update xác định hình dạng của mảng con trong kết quả được cập nhật.
Hình dạng của start_indices phải là 1 chiều, với kích thước chiều bằng số chiều của operand.
DynamicUpdateSlice(operand, update, start_indices)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng N chiều thuộc loại T |
update
|
XlaOp
|
Mảng N chiều thuộc loại T chứa bản cập nhật lát cắt. Mỗi phương diện của hình dạng cập nhật phải lớn hơn 0 và start + update phải nhỏ hơn hoặc bằng kích thước toán hạng cho mỗi phương diện để tránh tạo chỉ mục cập nhật nằm ngoài phạm vi. |
start_indices
|
chuỗi N XlaOp
|
Danh sách N số nguyên vô hướng chứa các chỉ mục bắt đầu của lát cắt cho mỗi phương diện. Giá trị phải lớn hơn hoặc bằng 0. |
Các chỉ mục lát hiệu quả được tính bằng cách áp dụng phép biến đổi sau cho mỗi chỉ mục i trong [1, N) trước khi thực hiện lát:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
Điều này đảm bảo rằng phần cập nhật luôn nằm trong phạm vi liên quan đến mảng toán hạng. Nếu lát cắt nằm trong phạm vi trước khi áp dụng phép biến đổi, thì phép biến đổi sẽ không có tác dụng.
Ví dụ về 1 chiều:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s)
// Result: {0.0, 1.0, 5.0, 6.0, 4.0}
Ví dụ về 2 chiều:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s)
// Result:
// { {0.0, 1.0, 2.0},
// {3.0, 12.0, 13.0},
// {6.0, 14.0, 15.0},
// {9.0, 16.0, 17.0} }
Để biết thông tin về StableHLO, hãy xem StableHLO – dynamic_update_slice.
Erf
Xem thêm XlaBuilder::Erf.
Hàm sai số theo phần tử x -> erf(x), trong đó:
\(\text{erf}(x) = \frac{2}{\sqrt{\pi} }\int_0^x e^{-t^2} \, dt\).
Erf(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Erf cũng hỗ trợ đối số result_accuracy không bắt buộc:
Erf(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Hết hạn
Xem thêm XlaBuilder::Exp.
Hàm mũ tự nhiên theo phần tử x -> e^x.
Exp(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Exp cũng hỗ trợ đối số result_accuracy không bắt buộc:
Exp(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – hàm mũ.
Expm1
Xem thêm XlaBuilder::Expm1.
Số mũ tự nhiên trừ đi 1 theo từng phần tử x -> e^x - 1.
Expm1(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Hàm expm1 cũng hỗ trợ đối số result_accuracy không bắt buộc:
Expm1(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – exponential_minus_one.
Fft
Xem thêm XlaBuilder::Fft.
Thao tác FFT XLA triển khai Phép biến đổi Fourier thuận và nghịch cho các đầu vào/đầu ra thực và phức. FFT đa chiều trên tối đa 3 trục được hỗ trợ.
Fft(operand, ftt_type, fft_length)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp
|
Mảng mà chúng ta đang biến đổi Fourier. |
fft_type |
FftType |
Hãy xem bảng bên dưới. |
fft_length
|
ArraySlice<int64>
|
Độ dài miền thời gian của các trục đang được biến đổi. Điều này đặc biệt cần thiết đối với IRFFT để điều chỉnh kích thước trục trong cùng, vì RFFT(fft_length=[16]) có cùng hình dạng đầu ra với RFFT(fft_length=[17]). |
FftType |
Ngữ nghĩa |
|---|---|
FFT |
FFT phức tạp sang phức tạp chuyển tiếp. Hình dạng không thay đổi. |
IFFT |
FFT phức tạp sang phức tạp nghịch đảo. Hình dạng không thay đổi. |
RFFT
|
FFT thực sang phức chuyển tiếp. Hình dạng của trục trong cùng được giảm xuống fft_length[-1] // 2 + 1 nếu fft_length[-1] là giá trị khác 0, bỏ qua phần liên hợp đảo ngược của tín hiệu được biến đổi vượt quá tần số Nyquist. |
IRFFT
|
FFT thực sang phức nghịch đảo (tức là lấy số phức, trả về số thực).
Hình dạng của trục trong cùng được mở rộng thành fft_length[-1] nếu fft_length[-1] là một giá trị khác 0, suy ra phần của tín hiệu đã chuyển đổi vượt quá tần số Nyquist từ liên hợp đảo ngược của các mục 1 đến fft_length[-1] // 2 + 1. |
Để biết thông tin về StableHLO, hãy xem StableHLO – fft.
FFT đa chiều
Khi có nhiều fft_length, điều này tương đương với việc áp dụng một chuỗi các thao tác FFT cho từng trục trong cùng. Xin lưu ý rằng đối với các trường hợp thực->phức tạp và phức tạp->thực, phép biến đổi trục trong cùng nhất được thực hiện trước (RFFT; cuối cùng đối với IRFFT), đó là lý do tại sao trục trong cùng nhất là trục thay đổi kích thước. Các phép biến đổi trục khác sẽ là complex->complex.
Thông tin chi tiết về việc triển khai
FFT của CPU được hỗ trợ bởi TensorFFT của Eigen. GPU FFT sử dụng cuFFT.
Tầng
Xem thêm XlaBuilder::Floor.
Hàm sàn theo phần tử x -> ⌊x⌋.
Floor(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – floor.
Món ăn hỗn hợp
Xem thêm HloInstruction::CreateFusion.
Thao tác Fusion biểu thị các chỉ dẫn HLO và đóng vai trò là một nguyên tắc cơ bản trong HLO.
Thao tác này có thể xuất hiện trong các kết xuất HLO nhưng người dùng cuối không nên tạo thao tác này theo cách thủ công.
Thu thập
Thao tác thu thập XLA kết hợp nhiều lát (mỗi lát có độ lệch thời gian chạy có thể khác nhau) của một mảng đầu vào.
Để biết thông tin về StableHLO, hãy xem StableHLO – gather.
Ngữ nghĩa chung
Xem thêm XlaBuilder::Gather.
Để biết nội dung mô tả trực quan hơn, hãy xem phần "Nội dung mô tả không chính thức" bên dưới.
gather(operand, start_indices, dimension_numbers, slice_sizes,
indices_are_sorted)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp
|
Mảng mà chúng ta đang thu thập. |
start_indices
|
XlaOp
|
Mảng chứa các chỉ mục bắt đầu của các lát mà chúng ta thu thập. |
dimension_numbers
|
GatherDimensionNumbers
|
Phương diện trong start_indices "chứa" các chỉ mục bắt đầu. Hãy xem phần bên dưới để biết nội dung mô tả chi tiết. |
slice_sizes
|
ArraySlice<int64>
|
slice_sizes[i] là ranh giới cho lát cắt trên phương diện i. |
indices_are_sorted
|
bool
|
Liệu người gọi có đảm bảo sắp xếp các chỉ mục hay không. |
Để thuận tiện, chúng tôi gắn nhãn các phương diện trong mảng đầu ra không có trong offset_dims là batch_dims.
Kết quả là một mảng có kích thước batch_dims.size + offset_dims.size.
operand.rank phải bằng tổng của offset_dims.size và collapsed_slice_dims.size. Ngoài ra, slice_sizes.size phải bằng operand.rank.
Nếu index_vector_dim bằng start_indices.rank, chúng ta sẽ ngầm coi start_indices có một phương diện 1 theo sau (tức là nếu start_indices có hình dạng [6,7] và index_vector_dim là 2 thì chúng ta sẽ ngầm coi hình dạng của start_indices là [6,7,1]).
Các ranh giới cho mảng đầu ra dọc theo phương diện i được tính như sau:
Nếu
icó trongbatch_dims(tức là bằngbatch_dims[k]đối với một sốk) thì chúng ta sẽ chọn ranh giới tương ứng của phương diện trongstart_indices.shape, bỏ quaindex_vector_dim(tức là chọnstart_indices.shape.dims[k] nếuk<index_vector_dimvàstart_indices.shape.dims[k+1] nếu không).Nếu
icó trongoffset_dims(tức là bằngoffset_dims[k] đối với một sốk), thì chúng ta sẽ chọn giới hạn tương ứng trongslice_sizessau khi tính đếncollapsed_slice_dims(tức là chúng ta chọnadjusted_slice_sizes[k] trong đóadjusted_slice_sizeslàslice_sizesvới các giới hạn tại chỉ mụccollapsed_slice_dimsđã bị xoá).
Theo hình thức, chỉ mục toán hạng In tương ứng với một chỉ mục đầu ra nhất định Out được tính như sau:
Đặt
G= {Out[k] forkinbatch_dims}. Sử dụngGđể cắt một vectơSsao choS[i] =start_indices[Combine(G,i)] trong đó Combine(A, b) chèn b vào vị tríindex_vector_dimtrong A. Lưu ý rằng điều này được xác định rõ ngay cả khiGtrống: NếuGtrống thìS=start_indices.Tạo một chỉ mục bắt đầu,
Sin, vàooperandbằng cách sử dụngSbằng cách phân tánSbằngstart_index_map. Cụ thể hơn:Sin[start_index_map[k]] =S[k] ifk<start_index_map.size.Sin[_] =0nếu không.
Tạo một chỉ mục
Oinvàooperandbằng cách phân tán các chỉ mục tại các phương diện bù trongOuttheo bộcollapsed_slice_dims. Cụ thể hơn:Oin[remapped_offset_dims(k)] =Out[offset_dims[k]] nếuk<offset_dims.size(remapped_offset_dimsđược xác định bên dưới).Oin[_] =0nếu không.
InlàOin+Sintrong đó + là phép cộng theo phần tử.
remapped_offset_dims là một hàm đơn điệu với miền [0, offset_dims.size) và phạm vi [0, operand.rank) \ collapsed_slice_dims. Vì vậy, nếu chẳng hạn, offset_dims.size là 4, operand.rank là 6 và collapsed_slice_dims là {0, 2} thì remapped_offset_dims là {0→1, 1→3, 2→4, 3→5}.
Nếu indices_are_sorted được đặt thành true, thì XLA có thể giả định rằng start_indices được người dùng sắp xếp (theo thứ tự tăng dần, sau khi phân tán các giá trị theo start_index_map). Nếu không, ngữ nghĩa sẽ được xác định theo cách triển khai.
Nội dung mô tả và ví dụ không chính thức
Một cách không chính thức, mọi chỉ mục Out trong mảng đầu ra đều tương ứng với một phần tử E trong mảng toán hạng, được tính như sau:
Chúng ta sẽ sử dụng các phương diện theo lô trong
Outđể tra cứu chỉ mục bắt đầu từstart_indices.Chúng ta dùng
start_index_mapđể ánh xạ chỉ mục bắt đầu (có thể có kích thước nhỏ hơn operand.rank) thành chỉ mục bắt đầu "đầy đủ" trongoperand.Chúng ta sẽ cắt động một lát có kích thước
slice_sizesbằng cách sử dụng chỉ mục bắt đầu đầy đủ.Chúng ta định hình lại lát cắt bằng cách thu gọn các phương diện
collapsed_slice_dims. Vì tất cả các phương diện lát cắt được thu gọn đều phải có giới hạn là 1, nên việc định hình lại này luôn hợp lệ.Chúng ta sử dụng các phương diện bù trong
Outđể lập chỉ mục vào lát cắt này nhằm lấy phần tử đầu vàoEtương ứng với chỉ mục đầu raOut.
index_vector_dim được đặt thành start_indices.rank – 1 trong tất cả các ví dụ sau. Các giá trị thú vị hơn cho index_vector_dim không thay đổi cơ bản hoạt động, nhưng khiến việc biểu diễn trực quan trở nên rườm rà hơn.
Để hiểu rõ cách kết hợp tất cả những điều trên, hãy xem một ví dụ thu thập 5 phần của hình dạng [8,6] từ một mảng [16,11]. Vị trí của một lát cắt trong mảng [16,11] có thể được biểu thị dưới dạng một vectơ chỉ mục có hình dạng S64[2], vì vậy, tập hợp 5 vị trí có thể được biểu thị dưới dạng một mảng S64[5,2].
Sau đó,bạn có thể mô tả hành vi của thao tác thu thập dưới dạng một phép biến đổi chỉ mục lấy [G,O0,O1], một chỉ mục trong hình dạng đầu ra và ánh xạ chỉ mục đó đến một phần tử trong mảng đầu vào theo cách sau:

Trước tiên, chúng ta chọn một vectơ (X,Y) từ mảng chỉ mục tập hợp bằng cách sử dụng G.
Phần tử trong mảng đầu ra tại chỉ mục [G,O0,O1] sau đó là phần tử trong mảng đầu vào tại chỉ mục [X+O0,Y+O1].
slice_sizes là [8,6], quyết định phạm vi của O0 và O1, và điều này lần lượt quyết định ranh giới của lát cắt.
Thao tác thu thập này hoạt động như một lát cắt động theo lô với G là phương diện lô.
Các chỉ mục thu thập có thể là đa chiều. Ví dụ: phiên bản chung chung hơn của ví dụ trên sử dụng một mảng "gather indices" có hình dạng [4,5,2] sẽ dịch các chỉ mục như sau:

Một lần nữa, điều này đóng vai trò là một lát cắt động theo lô G0 và G1 làm phương diện theo lô. Kích thước của lát vẫn là [8,6].
Thao tác thu thập trong XLA khái quát hoá ngữ nghĩa không chính thức được nêu ở trên theo những cách sau:
Chúng ta có thể định cấu hình phương diện nào trong hình dạng đầu ra là phương diện bù (phương diện chứa
O0,O1trong ví dụ cuối cùng). Các phương diện lô đầu ra (phương diện chứaG0,G1trong ví dụ cuối cùng) được xác định là các phương diện đầu ra không phải là phương diện bù.Số lượng phương diện bù đầu ra có trong hình dạng đầu ra có thể nhỏ hơn số lượng phương diện đầu vào. Các phương diện "bị thiếu" này (được liệt kê rõ ràng là
collapsed_slice_dims) phải có kích thước lát cắt là1. Vì chúng có kích thước lát là1nên chỉ số hợp lệ duy nhất cho chúng là0và việc bỏ qua chúng không gây ra sự mơ hồ.Lát cắt được trích xuất từ mảng "Gather Indices" ((
X,Y) trong ví dụ cuối cùng) có thể có ít phần tử hơn số lượng phương diện của mảng đầu vào và một ánh xạ rõ ràng sẽ quy định cách chỉ mục phải được mở rộng để có cùng số lượng phương diện như đầu vào.
Ví dụ cuối cùng, chúng ta sẽ sử dụng (2) và (3) để triển khai tf.gather_nd:

G0 và G1 thường được dùng để cắt chỉ mục bắt đầu từ mảng chỉ mục thu thập, ngoại trừ chỉ mục bắt đầu chỉ có một phần tử, X. Tương tự, chỉ có một chỉ mục độ lệch đầu ra có giá trị O0. Tuy nhiên, trước khi được dùng làm chỉ mục trong mảng đầu vào, các chỉ mục này sẽ được mở rộng theo "Gather Index Mapping" (Ánh xạ chỉ mục thu thập) (start_index_map trong nội dung mô tả chính thức) và "Offset Mapping" (Ánh xạ độ lệch) (remapped_offset_dims trong nội dung mô tả chính thức) thành [X,0] và [0,O0] tương ứng, cộng lại thành [X,O0]. Nói cách khác, chỉ mục đầu ra [G0,G1,O0] ánh xạ đến chỉ mục đầu vào [GatherIndices[G0,G1,0],O0] cho chúng ta ngữ nghĩa cho tf.gather_nd.
slice_sizes cho trường hợp này là [1,11]. Theo trực giác, điều này có nghĩa là mọi chỉ mục X trong mảng chỉ mục thu thập sẽ chọn toàn bộ một hàng và kết quả là sự nối kết của tất cả các hàng này.
GetDimensionSize
Xem thêm XlaBuilder::GetDimensionSize.
Trả về kích thước của phương diện đã cho của toán hạng. Toán hạng phải có dạng mảng.
GetDimensionSize(operand, dimension)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng đầu vào n chiều |
dimension
|
int64
|
Một giá trị trong khoảng [0, n) chỉ định phương diện |
Để biết thông tin về StableHLO, hãy xem StableHLO – get_dimension_size.
GetTupleElement
Xem thêm XlaBuilder::GetTupleElement.
Chỉ mục vào một bộ có giá trị hằng số thời gian biên dịch.
Giá trị phải là một hằng số thời gian biên dịch để suy luận hình dạng có thể xác định loại giá trị kết quả.
Điều này tương tự như std::get<int N>(t) trong C++. Về mặt khái niệm:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
Xem thêm tf.tuple.
GetTupleElement(tuple_data, index)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
tuple_data |
XlaOP |
Bộ giá trị |
index |
int64 |
Chỉ mục của hình dạng bộ giá trị |
Để biết thông tin về StableHLO, hãy xem StableHLO – get_tuple_element.
Imag
Xem thêm XlaBuilder::Imag.
Phần ảo theo phần tử của một hình dạng phức tạp (hoặc thực). x -> imag(x). Nếu toán hạng là kiểu dấu phẩy động, hàm sẽ trả về 0.
Imag(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – imag.
Trong nguồn cấp dữ liệu
Xem thêm XlaBuilder::Infeed.
Infeed(shape, config)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
shape
|
Shape
|
Hình dạng của dữ liệu được đọc từ giao diện Trong nguồn cấp dữ liệu. Bạn phải đặt trường bố cục của hình dạng sao cho khớp với bố cục của dữ liệu được gửi đến thiết bị; nếu không, hành vi của dữ liệu sẽ không xác định. |
config |
không bắt buộc string |
Cấu hình của thao tác. |
Đọc một mục dữ liệu duy nhất từ giao diện truyền phát trực tiếp In-feed ngầm ẩn của thiết bị, diễn giải dữ liệu dưới dạng hình dạng và bố cục đã cho, đồng thời trả về một XlaOp của dữ liệu. Bạn có thể dùng nhiều thao tác Infeed trong một phép tính, nhưng phải có tổng số thứ tự giữa các thao tác Infeed. Ví dụ: 2 Infeed trong đoạn mã bên dưới có tổng thứ tự vì có một phần phụ thuộc giữa các vòng lặp while.
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
Không được hỗ trợ các hình dạng bộ dữ liệu lồng nhau. Đối với một hình dạng bộ dữ liệu trống, thao tác Infeed thực sự là một thao tác không có tác dụng và tiếp tục mà không cần đọc bất kỳ dữ liệu nào từ Infeed của thiết bị.
Để biết thông tin về StableHLO, hãy xem StableHLO – infeed.
Iôta
Xem thêm XlaBuilder::Iota.
Iota(shape, iota_dimension)
Tạo một giá trị cố định theo nghĩa đen trên thiết bị thay vì một lượt chuyển máy chủ có thể lớn. Tạo một mảng có hình dạng đã chỉ định và giữ các giá trị bắt đầu từ 0 và tăng thêm 1 theo chiều đã chỉ định. Đối với các loại dấu phẩy động, mảng được tạo tương đương với ConvertElementType(Iota(...)) trong đó Iota thuộc loại số nguyên và quá trình chuyển đổi là sang loại dấu phẩy động.
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
shape |
Shape |
Hình dạng của mảng do Iota() tạo |
iota_dimension |
int64 |
Phương diện cần tăng. |
Ví dụ: Iota(s32[4, 8], 0) trả về
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
Trả lại hàng với mức phí Iota(s32[4, 8], 1)
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
Để biết thông tin về StableHLO, hãy xem StableHLO – iota.
IsFinite
Xem thêm XlaBuilder::IsFinite.
Kiểm tra xem mỗi phần tử của operand có hữu hạn hay không, tức là không phải vô cực dương hoặc âm và không phải là NaN. Trả về một mảng các giá trị PRED có cùng hình dạng với dữ liệu đầu vào, trong đó mỗi phần tử là true nếu và chỉ nếu phần tử đầu vào tương ứng là hữu hạn.
IsFinite(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – is_finite.
Nhật ký
Xem thêm XlaBuilder::Log.
Lôgarit tự nhiên theo phần tử x -> ln(x).
Log(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Hàm Log cũng hỗ trợ đối số result_accuracy không bắt buộc:
Log(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – log.
Log1p
Xem thêm XlaBuilder::Log1p.
Lôgarit tự nhiên được dịch chuyển theo từng phần tử x -> ln(1+x).
Log1p(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Log1p cũng hỗ trợ đối số result_accuracy không bắt buộc:
Log1p(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – log_plus_one.
Logistic
Xem thêm XlaBuilder::Logistic.
Phép tính hàm logistic theo phần tử x -> logistic(x).
Logistic(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Logistic cũng hỗ trợ đối số result_accuracy không bắt buộc:
Logistic(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – logistic.
Bản đồ
Xem thêm XlaBuilder::Map.
Map(operands..., computation, dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operands |
chuỗi gồm N XlaOp |
N mảng thuộc các loại T0..T{N-1} |
computation
|
XlaComputation
|
Tính toán loại T_0, T_1,
.., T_{N + M -1} -> S với N tham số thuộc loại T và M thuộc loại tuỳ ý. |
dimensions |
int64 mảng |
Mảng phương diện bản đồ |
static_operands
|
chuỗi gồm N XlaOp |
Các thao tác tĩnh cho thao tác bản đồ |
Áp dụng một hàm vô hướng trên các mảng operands đã cho, tạo ra một mảng có cùng kích thước, trong đó mỗi phần tử là kết quả của hàm được ánh xạ áp dụng cho các phần tử tương ứng trong mảng đầu vào.
Hàm được ánh xạ là một phép tính tuỳ ý với hạn chế là hàm này có N đầu vào thuộc loại vô hướng T và một đầu ra thuộc loại S. Đầu ra có cùng kích thước với toán hạng, ngoại trừ việc loại phần tử T được thay thế bằng S.
Ví dụ: Map(op1, op2, op3, computation, par1) ánh xạ elem_out <-
computation(elem1, elem2, elem3, par1) tại mỗi chỉ mục (nhiều chiều) trong mảng đầu vào để tạo ra mảng đầu ra.
Để biết thông tin về StableHLO, hãy xem StableHLO – bản đồ.
Tối đa
Xem thêm XlaBuilder::Max.
Thực hiện phép toán max theo phần tử trên các tensor lhs và rhs.
Max(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Max có một phiên bản thay thế hỗ trợ truyền hình nhiều chiều:
Max(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – tối đa.
Phút
Xem thêm XlaBuilder::Min.
Thực hiện phép toán min theo phần tử trên lhs và rhs.
Min(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Một biến thể thay thế có hỗ trợ truyền tin nhiều chiều tồn tại cho Min:
Min(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – tối thiểu.
Mul
Xem thêm XlaBuilder::Mul.
Thực hiện phép nhân từng phần tử của lhs và rhs.
Mul(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Mul có một biến thể thay thế hỗ trợ truyền hình nhiều chiều:
Mul(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – multiply.
Neg
Xem thêm XlaBuilder::Neg.
Phép phủ định theo phần tử x -> -x.
Neg(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – phủ định
Không
Xem thêm XlaBuilder::Not.
Phủ định logic theo phần tử x -> !(x).
Not(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – không.
OptimizationBarrier
Xem thêm XlaBuilder::OptimizationBarrier.
Chặn mọi lượt tối ưu hoá di chuyển các phép tính qua rào cản.
OptimizationBarrier(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Đảm bảo rằng tất cả các đầu vào đều được đánh giá trước mọi toán tử phụ thuộc vào đầu ra của rào cản.
Để biết thông tin về StableHLO, hãy xem StableHLO – optimization_barrier.
Hoặc
Xem thêm XlaBuilder::Or.
Thực hiện phép OR theo phần tử của lhs và rhs .
Or(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Có một biến thể thay thế hỗ trợ truyền hình nhiều chiều cho Or:
Or(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – or.
Outfeed
Xem thêm XlaBuilder::Outfeed.
Ghi dữ liệu đầu vào vào nguồn cấp dữ liệu đầu ra.
Outfeed(operand, shape_with_layout, outfeed_config)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại T |
shape_with_layout |
Shape |
Xác định bố cục của dữ liệu được chuyển |
outfeed_config |
string |
Hằng số của cấu hình cho chỉ dẫn Outfeed |
shape_with_layout cho biết hình dạng được bố trí mà chúng ta muốn xuất.
Để biết thông tin về StableHLO, hãy xem StableHLO – outfeed.
Miếng đệm
Xem thêm XlaBuilder::Pad.
Pad(operand, padding_value, padding_config)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại T |
padding_value
|
XlaOp
|
vô hướng thuộc loại T để điền vào khoảng đệm đã thêm |
padding_config
|
PaddingConfig
|
lượng khoảng đệm ở cả hai cạnh (thấp, cao) và giữa các phần tử của mỗi phương diện |
Mở rộng mảng operand đã cho bằng cách thêm khoảng đệm xung quanh mảng cũng như giữa các phần tử của mảng bằng padding_value đã cho. padding_config chỉ định lượng khoảng đệm cạnh và khoảng đệm bên trong cho từng phương diện.
PaddingConfig là một trường lặp lại của PaddingConfigDimension, chứa 3 trường cho mỗi phương diện: edge_padding_low, edge_padding_high và interior_padding.
edge_padding_low và edge_padding_high lần lượt chỉ định lượng khoảng đệm được thêm vào ở đầu dưới (bên cạnh chỉ mục 0) và đầu trên (bên cạnh chỉ mục cao nhất) của mỗi phương diện. Lượng khoảng đệm cạnh có thể là số âm – giá trị tuyệt đối của khoảng đệm âm cho biết số lượng phần tử cần xoá khỏi phương diện được chỉ định.
interior_padding chỉ định lượng khoảng đệm được thêm vào giữa hai phần tử bất kỳ trong mỗi phương diện; giá trị này không được âm. Khoảng đệm bên trong xuất hiện một cách hợp lý trước khoảng đệm cạnh, vì vậy, trong trường hợp khoảng đệm cạnh âm, các phần tử sẽ bị xoá khỏi toán hạng được đệm bên trong.
Thao tác này không có tác dụng nếu tất cả các cặp khoảng đệm cạnh đều là (0, 0) và tất cả các giá trị khoảng đệm bên trong đều là 0. Hình dưới đây cho thấy ví dụ về các giá trị edge_padding và interior_padding khác nhau cho một mảng hai chiều.
Để biết thông tin về StableHLO, hãy xem StableHLO – pad.
Tham số
Xem thêm XlaBuilder::Parameter.
Parameter biểu thị một đối số đầu vào cho một phép tính.
PartitionID
Xem thêm XlaBuilder::BuildPartitionId.
Tạo partition_id của quy trình hiện tại.
PartitionID(shape)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
shape |
Shape |
Hình dạng của dữ liệu |
PartitionID có thể xuất hiện trong các kết xuất HLO nhưng người dùng cuối không nên tự tạo.
Để biết thông tin về StableHLO, hãy xem StableHLO – partition_id.
PopulationCount
Xem thêm XlaBuilder::PopulationCount.
Tính số lượng bit được đặt trong mỗi phần tử của operand.
PopulationCount(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – popcnt.
Pow
Xem thêm XlaBuilder::Pow.
Thực hiện phép luỹ thừa theo từng phần tử của lhs theo rhs.
Pow(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Pow có một biến thể thay thế hỗ trợ truyền tin nhiều chiều:
Pow(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – power.
Real
Xem thêm XlaBuilder::Real.
Phần thực theo phần tử của một hình dạng phức tạp (hoặc thực). x -> real(x). Nếu toán hạng là kiểu số thực dấu phẩy động, Real sẽ trả về cùng một giá trị.
Real(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – real.
Recv
Xem thêm XlaBuilder::Recv.
Recv, RecvWithTokens và RecvToHost là các thao tác đóng vai trò là các thành phần giao tiếp cơ bản trong HLO. Các thao tác này thường xuất hiện trong các trích xuất dữ liệu HLO như một phần của hoạt động đầu vào/đầu ra cấp thấp hoặc chuyển dữ liệu giữa nhiều thiết bị, nhưng người dùng cuối không nên tự tạo các thao tác này theo cách thủ công.
Recv(shape, handle)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
shape |
Shape |
hình dạng của dữ liệu cần nhận |
handle |
ChannelHandle |
giá trị nhận dạng riêng biệt cho mỗi cặp gửi/nhận |
Nhận dữ liệu của hình dạng đã cho từ một chỉ dẫn Send trong một phép tính khác dùng chung cùng một mã nhận dạng kênh. Trả về một XlaOp cho dữ liệu nhận được.
Để biết thông tin về StableHLO, hãy xem StableHLO – recv.
RecvDone
Xem thêm HloInstruction::CreateRecv và HloInstruction::CreateRecvDone.
Tương tự như Send, API ứng dụng của thao tác Recv biểu thị hoạt động giao tiếp đồng bộ. Tuy nhiên, hướng dẫn này được phân tách nội bộ thành 2 hướng dẫn HLO (Recv và RecvDone) để cho phép chuyển dữ liệu không đồng bộ.
Recv(const Shape& shape, int64 channel_id)
Phân bổ các tài nguyên cần thiết để nhận dữ liệu từ một chỉ dẫn Send có cùng channel_id. Trả về một ngữ cảnh cho các tài nguyên được phân bổ. Ngữ cảnh này được hướng dẫn RecvDone sau đây dùng để chờ hoàn tất quá trình truyền dữ liệu. Ngữ cảnh là một bộ {bộ đệm nhận (hình dạng), mã nhận dạng yêu cầu (U32)} và chỉ có thể được dùng bằng một chỉ dẫn RecvDone.
Với một ngữ cảnh do chỉ dẫn Recv tạo, hãy đợi quá trình truyền dữ liệu hoàn tất và trả về dữ liệu đã nhận.
Giảm bớt
Xem thêm XlaBuilder::Reduce.
Áp dụng hàm rút gọn cho một hoặc nhiều mảng song song.
Reduce(operands..., init_values..., computation, dimensions_to_reduce)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operands
|
Chuỗi N XlaOp
|
N mảng thuộc loại T_0,...,
T_{N-1}. |
init_values
|
Chuỗi N XlaOp
|
N đại lượng vô hướng thuộc các loại T_0,..., T_{N-1}. |
computation
|
XlaComputation
|
phép tính thuộc loại T_0,..., T_{N-1}, T_0,
...,T_{N-1} ->
Collate(T_0,...,
T_{N-1}). |
dimensions_to_reduce
|
int64 mảng |
mảng không có thứ tự của các phương diện cần giảm. |
Trong trường hợp:
- N phải lớn hơn hoặc bằng 1.
- Phép tính phải có tính kết hợp "tương đối" (xem bên dưới).
- Tất cả các mảng đầu vào phải có cùng kích thước.
- Tất cả các giá trị ban đầu phải tạo thành một danh tính trong
computation. - Nếu
N = 1,Collate(T)làT. - Nếu
N > 1,Collate(T_0, ..., T_{N-1})là một bộ gồm các phần tửNthuộc loạiT.
Thao tác này sẽ giảm một hoặc nhiều phương diện của mỗi mảng đầu vào thành các đại lượng vô hướng.
Số lượng phương diện của mỗi mảng được trả về là number_of_dimensions(operand) - len(dimensions). Đầu ra của thao tác này là Collate(Q_0, ..., Q_N), trong đó Q_i là một mảng thuộc loại T_i, kích thước của mảng này được mô tả bên dưới.
Các chương trình phụ trợ khác nhau được phép liên kết lại phép tính giảm. Điều này có thể dẫn đến sự khác biệt về số, vì một số hàm giảm như phép cộng không có tính kết hợp đối với số thực. Tuy nhiên, nếu phạm vi của dữ liệu bị hạn chế, thì phép cộng số thực dấu phẩy động sẽ đủ gần để kết hợp cho hầu hết các mục đích sử dụng thực tế.
Để biết thông tin về StableHLO, hãy xem StableHLO – reduce.
Ví dụ
Khi giảm trên một chiều trong một mảng 1D duy nhất có các giá trị [10, 11,
12, 13], với hàm giảm f (đây là computation), thì hàm đó có thể được tính là
f(10, f(11, f(12, f(init_value, 13)))
nhưng cũng có nhiều khả năng khác, chẳng hạn như
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
Sau đây là ví dụ về mã giả sơ bộ về cách có thể triển khai thao tác giảm, sử dụng phép tính tổng là phép tính giảm với giá trị ban đầu là 0.
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the number of dimensions of the result.
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
Sau đây là ví dụ về cách giảm mảng 2 chiều (ma trận). Hình dạng có 2 phương diện, phương diện 0 có kích thước 2 và phương diện 1 có kích thước 3:
Kết quả của việc giảm kích thước 0 hoặc 1 bằng hàm "add":
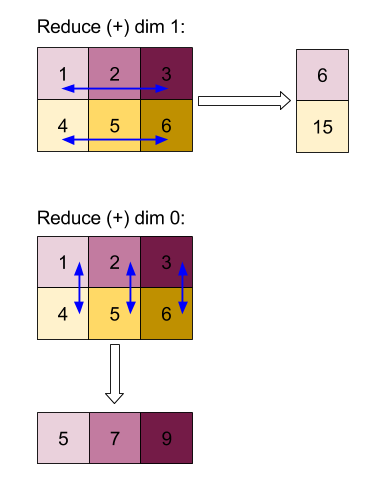
Xin lưu ý rằng cả hai kết quả rút gọn đều là mảng 1 chiều. Sơ đồ này cho thấy một cột và một hàng chỉ để thuận tiện cho việc hình dung.
Để có ví dụ phức tạp hơn, sau đây là một mảng 3 chiều. Số lượng phương diện của nó là 3, phương diện 0 có kích thước 4, phương diện 1 có kích thước 2 và phương diện 2 có kích thước 3. Để đơn giản, các giá trị từ 1 đến 6 được sao chép trên phương diện 0.
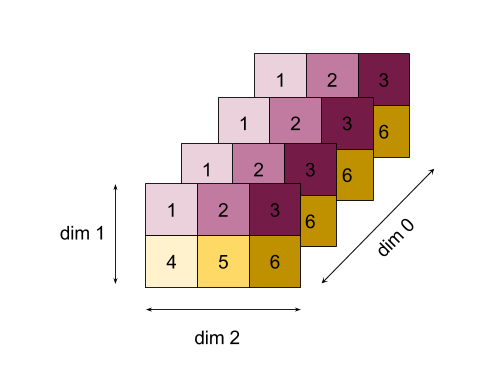
Tương tự như ví dụ 2D, chúng ta có thể giảm chỉ một phương diện. Ví dụ: nếu giảm chiều 0, chúng ta sẽ nhận được một mảng 2 chiều, trong đó tất cả các giá trị trên chiều 0 được gộp thành một đại lượng vô hướng:
| 4 8 12 |
| 16 20 24 |
Nếu giảm phương diện 2, chúng ta cũng sẽ nhận được một mảng 2 chiều, trong đó tất cả các giá trị trên phương diện 2 được gộp thành một đại lượng vô hướng:
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
Xin lưu ý rằng thứ tự tương đối giữa các phương diện còn lại trong dữ liệu đầu vào sẽ được giữ nguyên trong dữ liệu đầu ra, nhưng một số phương diện có thể được chỉ định số mới (vì số lượng phương diện thay đổi).
Chúng ta cũng có thể giảm nhiều phương diện. Việc thêm các phương diện giảm 0 và 1 sẽ tạo ra mảng 1 chiều [20, 28, 36].
Việc giảm mảng 3D trên tất cả các phương diện sẽ tạo ra đại lượng vô hướng 84.
Giảm số lượng biến
Khi N > 1, việc áp dụng hàm giảm phức tạp hơn một chút, vì hàm này được áp dụng đồng thời cho tất cả các đầu vào. Các toán hạng được cung cấp cho phép tính theo thứ tự sau:
- Giá trị giảm dần cho toán hạng đầu tiên
- ...
- Đang chạy giá trị giảm cho toán hạng thứ N
- Giá trị đầu vào cho toán hạng đầu tiên
- ...
- Giá trị đầu vào cho toán hạng thứ N
Ví dụ: hãy xem xét hàm giảm sau đây. Hàm này có thể dùng để tính giá trị tối đa và argmax của một mảng 1 chiều song song:
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
Đối với mảng đầu vào 1 chiều V = Float[N], K = Int[N] và các giá trị init I_V = Float, I_K = Int, kết quả f_(N-1) của việc giảm trên phương diện đầu vào duy nhất tương đương với ứng dụng đệ quy sau:
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
Việc áp dụng thao tác giảm này cho một mảng giá trị và một mảng chỉ mục tuần tự (tức là iota) sẽ cùng lặp lại trên các mảng và trả về một bộ chứa giá trị tối đa và chỉ mục phù hợp.
ReducePrecision
Xem thêm XlaBuilder::ReducePrecision.
Mô hình hoá hiệu ứng của việc chuyển đổi các giá trị dấu phẩy động sang định dạng có độ chính xác thấp hơn (chẳng hạn như IEEE-FP16) và quay lại định dạng ban đầu. Bạn có thể chỉ định tuỳ ý số lượng bit số mũ và phần định trị trong định dạng có độ chính xác thấp, mặc dù không phải tất cả các kích thước bit đều được hỗ trợ trên mọi cách triển khai phần cứng.
ReducePrecision(operand, exponent_bits, mantissa_bits)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại dấu phẩy động T. |
exponent_bits |
int32 |
số lượng bit số mũ ở định dạng có độ chính xác thấp hơn |
mantissa_bits |
int32 |
số lượng bit phần định trị trong định dạng có độ chính xác thấp hơn |
Kết quả là một mảng thuộc loại T. Các giá trị đầu vào được làm tròn đến giá trị gần nhất có thể biểu thị bằng số lượng bit phần định trị đã cho (sử dụng ngữ nghĩa "làm tròn đến số chẵn"), đồng thời mọi giá trị vượt quá phạm vi được chỉ định theo số lượng bit số mũ đều được giới hạn ở vô cực dương hoặc âm. Các giá trị NaN được giữ lại, mặc dù có thể được chuyển đổi thành các giá trị NaN chuẩn.
Định dạng có độ chính xác thấp phải có ít nhất một bit số mũ (để phân biệt giá trị 0 với vô cực, vì cả hai đều có số phần nguyên bằng 0) và phải có số bit số phần nguyên không âm. Số bit số mũ hoặc số phần nguyên có thể vượt quá giá trị tương ứng cho loại T; phần tương ứng của quá trình chuyển đổi chỉ đơn giản là không hoạt động.
Để biết thông tin về StableHLO, hãy xem StableHLO – reduce_precision.
ReduceScatter
Xem thêm XlaBuilder::ReduceScatter.
ReduceScatter là một thao tác tập thể thực hiện AllReduce một cách hiệu quả, sau đó phân tán kết quả bằng cách chia kết quả thành shard_count khối dọc theo scatter_dimension và bản sao i trong nhóm bản sao sẽ nhận được phân đoạn ith.
ReduceScatter(operand, computation, scatter_dimension, shard_count,
replica_groups, channel_id, layout, use_global_device_ids)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp
|
Mảng hoặc một bộ không trống gồm các mảng cần giảm trên các bản sao. |
computation |
XlaComputation |
Tính toán mức giảm |
scatter_dimension |
int64 |
Phương diện cần phân tán. |
shard_count
|
int64
|
Số khối cần chia scatter_dimension |
replica_groups
|
ReplicaGroup vectơ
|
Các nhóm mà giữa đó sẽ diễn ra quá trình giảm |
channel_id
|
không bắt buộc
ChannelHandle |
Mã nhận dạng kênh không bắt buộc để giao tiếp giữa các mô-đun |
layout
|
không bắt buộc Layout
|
bố cục bộ nhớ do người dùng chỉ định |
use_global_device_ids |
không bắt buộc bool |
cờ do người dùng chỉ định |
- Khi
operandlà một bộ gồm các mảng, thao tác giảm phân tán sẽ được thực hiện trên từng phần tử của bộ. replica_groupslà danh sách các nhóm bản sao mà quá trình giảm được thực hiện (bạn có thể truy xuất mã nhận dạng bản sao cho bản sao hiện tại bằng cách sử dụngReplicaId). Thứ tự của các bản sao trong mỗi nhóm sẽ xác định thứ tự mà kết quả giảm tất cả sẽ được phân tán.replica_groupsphải trống (trong trường hợp tất cả các bản sao thuộc về một nhóm duy nhất) hoặc chứa cùng số lượng phần tử như số lượng bản sao. Khi có nhiều nhóm bản sao, tất cả các nhóm đó phải có cùng kích thước. Ví dụ:replica_groups = {0, 2}, {1, 3}thực hiện quá trình giảm giữa các bản sao0và2,1và3, sau đó phân tán kết quả.shard_countlà kích thước của mỗi nhóm bản sao. Chúng ta cần thông tin này trong trường hợpreplica_groupstrống. Nếureplica_groupskhông trống, thìshard_countphải bằng kích thước của mỗi nhóm bản sao.channel_idđược dùng để giao tiếp giữa các mô-đun: chỉ những thao tácreduce-scattercó cùngchannel_idmới có thể giao tiếp với nhau.layoutXem xla::shapes để biết thêm thông tin về bố cục.use_global_device_idslà một cờ do người dùng chỉ định. Khifalse(mặc định) các số trongreplica_groupslàReplicaIdkhitruereplica_groupsbiểu thị một mã nhận dạng chung của (ReplicaID*partition_count+partition_id). Ví dụ:- Với 2 bản sao và 4 phân vùng,
- replica_groups={ {0,1,4,5},{2,3,6,7} } and use_global_device_ids=true
- group[0] = (0,0), (0,1), (1,0), (1,1)
- group[1] = (0,2), (0,3), (1,2), (1,3)
- trong đó mỗi cặp là (replica_id, partition_id).
Hình dạng đầu ra là hình dạng đầu vào với scatter_dimension nhỏ hơn shard_count lần. Ví dụ: nếu có 2 bản sao và toán hạng có giá trị lần lượt là [1.0, 2.25] và [3.0, 5.25] trên 2 bản sao, thì giá trị đầu ra từ thao tác này (trong đó scatter_dim là 0) sẽ là [4.0] cho bản sao đầu tiên và [7.5] cho bản sao thứ hai.
Để biết thông tin về StableHLO, hãy xem StableHLO – reduce_scatter.
ReduceScatter – Ví dụ 1 – StableHLO

Trong ví dụ trên, có 2 bản sao tham gia vào ReduceScatter. Trên mỗi bản sao, toán hạng có hình dạng f32[2,4]. Một thao tác giảm tất cả (tổng) được thực hiện trên các bản sao, tạo ra một giá trị đã giảm của hình dạng f32[2,4] trên mỗi bản sao. Sau đó, giá trị rút gọn này được chia thành 2 phần dọc theo phương diện 1, do đó mỗi phần có hình dạng f32[2,2]. Mỗi bản sao trong nhóm quy trình sẽ nhận được phần tương ứng với vị trí của bản sao đó trong nhóm. Do đó, đầu ra trên mỗi bản sao có hình dạng f32[2,2].
ReduceWindow
Xem thêm XlaBuilder::ReduceWindow.
Áp dụng một hàm rút gọn cho tất cả các phần tử trong mỗi cửa sổ của một chuỗi gồm N mảng đa chiều, tạo ra một hoặc một bộ gồm N mảng đa chiều làm đầu ra. Mỗi mảng đầu ra có số lượng phần tử bằng với số lượng vị trí hợp lệ của cửa sổ. Bạn có thể biểu thị một lớp gộp dưới dạng ReduceWindow. Tương tự như Reduce, computation được áp dụng luôn được truyền init_values ở phía bên trái.
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operands
|
N XlaOps
|
Một chuỗi gồm N mảng đa chiều thuộc các loại T_0,..., T_{N-1}, mỗi mảng đại diện cho vùng cơ sở mà cửa sổ được đặt trên đó. |
init_values
|
N XlaOps
|
N giá trị bắt đầu cho phép giảm, một giá trị cho mỗi N toán hạng. Hãy xem phần Giảm để biết thông tin chi tiết. |
computation
|
XlaComputation
|
Hàm rút gọn thuộc loại T_0,
..., T_{N-1}, T_0, ..., T_{N-1}
-> Collate(T_0, ..., T_{N-1}), để áp dụng cho các phần tử trong mỗi cửa sổ của tất cả các toán hạng đầu vào. |
window_dimensions
|
ArraySlice<int64>
|
mảng số nguyên cho các giá trị kích thước cửa sổ |
window_strides
|
ArraySlice<int64>
|
mảng số nguyên cho các giá trị sải cửa sổ |
base_dilations
|
ArraySlice<int64>
|
mảng số nguyên cho các giá trị giãn nở cơ sở |
window_dilations
|
ArraySlice<int64>
|
mảng số nguyên cho các giá trị giãn nở cửa sổ |
padding
|
Padding
|
loại khoảng đệm cho cửa sổ (Padding::kSame, khoảng đệm này sẽ đệm để có cùng hình dạng đầu ra như đầu vào nếu bước là 1 hoặc Padding::kValid, khoảng đệm này không sử dụng khoảng đệm và "dừng" cửa sổ khi cửa sổ không còn phù hợp) |
Trong trường hợp:
- N phải lớn hơn hoặc bằng 1.
- Tất cả các mảng đầu vào phải có cùng kích thước.
- Nếu
N = 1,Collate(T)làT. - Nếu
N > 1,Collate(T_0, ..., T_{N-1})là một bộ gồm các phần tửNthuộc loại(T0,...T{N-1}).
Để biết thông tin về StableHLO, hãy xem StableHLO – reduce_window.
ReduceWindow – Ví dụ 1
Đầu vào là một ma trận có kích thước [4x6] và cả window_dimensions và window_stride_dimensions đều là [2x3].
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
Bước sải là 1 trong một phương diện chỉ định rằng vị trí của một cửa sổ trong phương diện đó cách cửa sổ liền kề 1 phần tử. Để chỉ định rằng không có cửa sổ nào chồng lên nhau, window_stride_dimensions phải bằng window_dimensions. Hình dưới đây minh hoạ việc sử dụng 2 giá trị bước sải khác nhau. Khoảng đệm được áp dụng cho từng phương diện của dữ liệu đầu vào và các phép tính cũng giống như khi dữ liệu đầu vào có các phương diện sau khi thêm khoảng đệm.
Đối với ví dụ về phần đệm không tầm thường, hãy cân nhắc việc tính toán giá trị tối thiểu của cửa sổ giảm (giá trị ban đầu là MAX_FLOAT) với phương diện 3 và bước sải 2 trên mảng đầu vào [10000, 1000, 100, 10, 1]. Khoảng đệm kValid tính toán giá trị tối thiểu trên hai cửa sổ hợp lệ: [10000, 1000, 100] và [100, 10, 1], dẫn đến đầu ra [100, 1]. Khoảng đệm kSame trước tiên sẽ đệm mảng để hình dạng sau cửa sổ giảm sẽ giống như đầu vào cho bước sải một bằng cách thêm các phần tử ban đầu ở cả hai bên, nhận được [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE]. Việc chạy reduce-window trên mảng được đệm sẽ hoạt động trên 3 cửa sổ [MAX_VALUE, 10000, 1000], [1000, 100, 10], [10, 1, MAX_VALUE] và tạo ra [1000, 10, 1].
Thứ tự đánh giá của hàm rút gọn là tuỳ ý và có thể không xác định. Do đó, hàm rút gọn không nên quá nhạy cảm với việc liên kết lại. Hãy xem phần thảo luận về tính kết hợp trong bối cảnh của Reduce để biết thêm thông tin chi tiết.
ReduceWindow – Ví dụ 2 – StableHLO

Trong ví dụ trên:
Đầu vào) Toán hạng có hình dạng đầu vào là S32[3,2]. Với giá trị là [[1,2],[3,4],[5,6]]
Bước 1) Giãn nở cơ sở với hệ số 2 dọc theo chiều hàng sẽ chèn các lỗ hổng giữa mỗi hàng của toán hạng. Sau khi giãn nở, hệ thống sẽ áp dụng khoảng đệm gồm 2 hàng ở trên cùng và 1 hàng ở dưới cùng. Do đó, tensor sẽ cao hơn.
Bước 2) Một cửa sổ có hình dạng [2,1] được xác định, với độ giãn nở cửa sổ [3,1]. Điều này có nghĩa là mỗi cửa sổ chọn hai phần tử trong cùng một cột, nhưng phần tử thứ hai được lấy ở 3 hàng bên dưới phần tử đầu tiên thay vì ngay bên dưới phần tử đó.
Bước 3) Sau đó, các cửa sổ được trượt trên toán hạng với bước sải [4,1]. Thao tác này khiến cửa sổ di chuyển xuống 4 hàng mỗi lần, đồng thời dịch chuyển 1 cột mỗi lần theo chiều ngang. Các ô đệm được điền bằng init_value (trong trường hợp này là init_value = 0). Các giá trị "rơi vào" các ô giãn nở sẽ bị bỏ qua.
Do bước và khoảng đệm, một số cửa sổ chỉ chồng lên các số 0 và lỗ hổng, trong khi những cửa sổ khác chồng lên các giá trị đầu vào thực.
Bước 4) Trong mỗi cửa sổ, các phần tử được kết hợp bằng hàm giảm (a, b) → a + b, bắt đầu từ giá trị ban đầu là 0. Hai cửa sổ trên cùng chỉ thấy khoảng trống và lỗ, nên kết quả của chúng là 0. Các cửa sổ dưới cùng ghi lại các giá trị 3 và 4 từ đầu vào và trả về các giá trị đó dưới dạng kết quả.
Kết quả) Đầu ra cuối cùng có hình dạng S32[2,2], với các giá trị: [[0,0],[3,4]]
Rem
Xem thêm XlaBuilder::Rem.
Thực hiện phép chia lấy phần dư theo từng phần tử của số bị chia lhs và số chia rhs.
Dấu của kết quả được lấy từ số bị chia và giá trị tuyệt đối của kết quả luôn nhỏ hơn giá trị tuyệt đối của số chia.
Rem(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Rem có một biến thể thay thế hỗ trợ truyền tin nhiều chiều:
Rem(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – số dư.
ReplicaId
Xem thêm XlaBuilder::ReplicaId.
Trả về mã nhận dạng duy nhất (vô hướng U32) của bản sao.
ReplicaId()
Mã nhận dạng riêng biệt của mỗi bản sao là một số nguyên không dấu trong khoảng [0, N), trong đó N là số lượng bản sao. Vì tất cả các bản sao đều đang chạy cùng một chương trình, nên lệnh gọi ReplicaId() trong chương trình sẽ trả về một giá trị khác nhau trên mỗi bản sao.
Để biết thông tin về StableHLO, hãy xem StableHLO – replica_id.
Tạo lại hình dạng
Xem thêm XlaBuilder::Reshape.
và thao tác Collapse.
Định hình lại các phương diện của một mảng thành một cấu hình mới.
Reshape(operand, dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại T |
dimensions |
int64 vectơ |
vectơ kích thước của các phương diện mới |
Về mặt khái niệm, trước tiên, hàm này sẽ làm phẳng một mảng thành một vectơ một chiều gồm các giá trị dữ liệu, sau đó tinh chỉnh vectơ này thành một hình dạng mới. Các đối số đầu vào là một mảng tuỳ ý thuộc loại T, một vectơ hằng số tại thời gian biên dịch của chỉ mục kích thước và một vectơ hằng số tại thời gian biên dịch của kích thước cho kết quả.
Vectơ dimensions xác định kích thước của mảng đầu ra. Giá trị tại chỉ mục 0 trong dimensions là kích thước của phương diện 0, giá trị tại chỉ mục 1 là kích thước của phương diện 1, v.v. Tích của các phương diện dimensions phải bằng tích của các kích thước phương diện của toán hạng. Khi tinh chỉnh mảng thu gọn thành mảng đa chiều do dimensions xác định, các chiều trong dimensions được sắp xếp từ thay đổi chậm nhất (chính nhất) đến thay đổi nhanh nhất (phụ nhất).
Ví dụ: giả sử v là một mảng gồm 24 phần tử:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
let v012_24 = Reshape(v, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
Trong trường hợp đặc biệt, hàm reshape có thể chuyển đổi một mảng có một phần tử thành một đại lượng vô hướng và ngược lại. Ví dụ:
Reshape(f32[1x1] { {5} }, {}) == 5;
Reshape(5, {1,1}) == f32[1x1] { {5} };
Để biết thông tin về StableHLO, hãy xem StableHLO – định hình lại.
Định hình lại (rõ ràng)
Xem thêm XlaBuilder::Reshape.
Reshape(shape, operand)
Reshape op sử dụng một hình dạng đích rõ ràng.
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
shape |
Shape |
Hình dạng đầu ra của loại T |
operand |
XlaOp |
mảng thuộc loại T |
Rev (đảo ngược)
Xem thêm XlaBuilder::Rev.
Rev(operand, dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
mảng thuộc loại T |
dimensions |
ArraySlice<int64> |
các phương diện cần đảo ngược |
Đảo ngược thứ tự của các phần tử trong mảng operand dọc theo dimensions đã chỉ định, tạo ra một mảng đầu ra có cùng hình dạng. Mỗi phần tử của mảng toán hạng tại một chỉ mục đa chiều được lưu trữ vào mảng đầu ra tại một chỉ mục đã chuyển đổi. Chỉ mục đa chiều được chuyển đổi bằng cách đảo ngược chỉ mục trong mỗi chiều cần đảo ngược (tức là nếu một chiều có kích thước N là một trong các chiều đảo ngược, thì chỉ mục i của chiều đó sẽ được chuyển đổi thành N – 1 – i).
Một cách sử dụng thao tác Rev là đảo ngược mảng trọng số tích chập dọc theo hai chiều cửa sổ trong quá trình tính toán độ dốc trong mạng nơ-ron.
Để biết thông tin về StableHLO, hãy xem StableHLO – reverse.
RngNormal
Xem thêm XlaBuilder::RngNormal.
Tạo một đầu ra có hình dạng nhất định với các số ngẫu nhiên được tạo theo phân phối chuẩn \(N(\mu, \sigma)\) . Các tham số \(\mu\) và \(\sigma\), cũng như hình dạng đầu ra phải có kiểu phần tử dấu phẩy động. Ngoài ra, các tham số phải có giá trị vô hướng.
RngNormal(mu, sigma, shape)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
mu |
XlaOp |
Vô hướng thuộc loại T chỉ định giá trị trung bình của các số được tạo |
sigma
|
XlaOp
|
Vô hướng thuộc loại T chỉ định độ lệch chuẩn của |
shape |
Shape |
Hình dạng đầu ra của loại T |
Để biết thông tin về StableHLO, hãy xem StableHLO – rng.
RngUniform
Xem thêm XlaBuilder::RngUniform.
Tạo đầu ra có hình dạng nhất định bằng các số ngẫu nhiên được tạo theo phân phối đồng nhất trên khoảng \([a,b)\). Các tham số và loại phần tử đầu ra phải là loại boolean, loại số nguyên hoặc loại dấu phẩy động và các loại phải nhất quán. Hiện tại, các phần phụ trợ CPU và GPU chỉ hỗ trợ F64, F32, F16, BF16, S64, U64, S32 và U32. Hơn nữa, các tham số cần có giá trị vô hướng. Nếu \(b <= a\) kết quả được xác định theo cách triển khai.
RngUniform(a, b, shape)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
a |
XlaOp |
Vô hướng thuộc loại T chỉ định giới hạn dưới của khoảng thời gian |
b |
XlaOp |
Vô hướng thuộc loại T chỉ định giới hạn trên của khoảng thời gian |
shape |
Shape |
Hình dạng đầu ra của loại T |
Để biết thông tin về StableHLO, hãy xem StableHLO – rng.
RngBitGenerator
Xem thêm XlaBuilder::RngBitGenerator.
Tạo một đầu ra có hình dạng nhất định, được điền bằng các bit ngẫu nhiên đồng nhất bằng cách sử dụng thuật toán được chỉ định (hoặc mặc định của chương trình phụ trợ) và trả về trạng thái đã cập nhật (có cùng hình dạng với trạng thái ban đầu) và dữ liệu ngẫu nhiên đã tạo.
Trạng thái ban đầu là trạng thái ban đầu của quá trình tạo số ngẫu nhiên hiện tại. Hình dạng bắt buộc và các giá trị hợp lệ của khoá này phụ thuộc vào thuật toán được dùng.
Đầu ra được đảm bảo là một hàm xác định của trạng thái ban đầu nhưng không được đảm bảo là xác định giữa các phần phụ trợ và các phiên bản trình biên dịch khác nhau.
RngBitGenerator(algorithm, initial_state, shape)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
algorithm |
RandomAlgorithm |
Thuật toán PRNG sẽ được sử dụng. |
initial_state |
XlaOp |
Trạng thái ban đầu cho thuật toán PRNG. |
shape |
Shape |
Hình dạng đầu ra cho dữ liệu được tạo. |
Các giá trị hợp lệ cho algorithm:
rng_default: Thuật toán dành riêng cho phần phụ trợ với các yêu cầu cụ thể về hình dạng của phần phụ trợ.rng_three_fry: Thuật toán PRNG dựa trên bộ đếm ThreeFry. Hình dạnginitial_statelàu64[2]với các giá trị tuỳ ý. Salmon et al. SC 2011. Số ngẫu nhiên song song: dễ dàng như đếm 1, 2, 3.rng_philox: Thuật toán Philox để tạo số ngẫu nhiên song song. Hình dạnginitial_statelàu64[3]với các giá trị tuỳ ý. Salmon et al. SC 2011. Số ngẫu nhiên song song: dễ dàng như đếm 1, 2, 3.
Để biết thông tin về StableHLO, hãy xem StableHLO – rng_bit_generator.
RngGetAndUpdateState
Xem thêm HloInstruction::CreateRngGetAndUpdateState.
API của nhiều thao tác Rng được phân tách nội bộ thành các chỉ dẫn HLO, bao gồm cả RngGetAndUpdateState.
RngGetAndUpdateState đóng vai trò là một nguyên hàm trong HLO. Thao tác này có thể xuất hiện trong các kết xuất HLO, nhưng người dùng cuối không nên tạo thao tác này theo cách thủ công.
Vòng
Xem thêm XlaBuilder::Round.
Làm tròn theo từng phần tử, các số bằng nhau được làm tròn ra xa 0.
Round(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
RoundNearestAfz
Xem thêm XlaBuilder::RoundNearestAfz.
Thực hiện việc làm tròn từng phần tử đến số nguyên gần nhất, phá vỡ các mối liên kết từ 0.
RoundNearestAfz(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – round_nearest_afz.
RoundNearestEven
Xem thêm XlaBuilder::RoundNearestEven.
Làm tròn theo từng phần tử, liên kết đến số chẵn gần nhất.
RoundNearestEven(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – round_nearest_even.
Rsqrt
Xem thêm XlaBuilder::Rsqrt.
Phép toán nghịch đảo theo phần tử của căn bậc hai x -> 1.0 / sqrt(x).
Rsqrt(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Rsqrt cũng hỗ trợ đối số result_accuracy không bắt buộc:
Rsqrt(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – rsqrt.
Quét
Xem thêm XlaBuilder::Scan.
Áp dụng một hàm rút gọn cho một mảng trên một phương diện nhất định, tạo ra trạng thái cuối cùng và một mảng các giá trị trung gian.
Scan(inputs..., inits..., to_apply, scan_dimension,
is_reverse, is_associative)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
inputs |
Chuỗi m XlaOp |
Mảng cần quét. |
inits |
Chuỗi k XlaOp |
Lần mang theo ban đầu. |
to_apply |
XlaComputation |
Phép tính thuộc loại i_0, ..., i_{m-1}, c_0, ..., c_{k-1} -> (o_0, ..., o_{n-1}, c'_0, ..., c'_{k-1}). |
scan_dimension |
int64 |
Phương diện cần quét. |
is_reverse |
bool |
Nếu đúng, hãy quét theo thứ tự đảo ngược. |
is_associative |
bool (ba trạng thái) |
Nếu đúng, thì phép toán có tính kết hợp. |
Hàm to_apply được áp dụng tuần tự cho các phần tử trong inputs dọc theo scan_dimension. Nếu is_reverse là false, các phần tử sẽ được xử lý theo thứ tự 0 đến N-1, trong đó N là kích thước của scan_dimension. Nếu is_reverse là true, các phần tử sẽ được xử lý từ N-1 xuống 0.
Hàm to_apply nhận các toán hạng m + k:
mphần tử hiện tại từinputs.kmang các giá trị từ bước trước (hoặcinitscho phần tử đầu tiên).
Hàm to_apply trả về một bộ giá trị n + k:
nphần tử củaoutputs.kgiá trị chuyển tiếp mới.
Thao tác Quét tạo ra một bộ gồm các giá trị n + k:
- Mảng đầu ra
n, chứa các giá trị đầu ra cho từng bước. kcuối cùng mang các giá trị sau khi xử lý tất cả các phần tử.
Các loại đầu vào m phải khớp với các loại tham số m đầu tiên của to_apply với một phương diện quét bổ sung. Các loại đầu ra n phải khớp với các loại giá trị trả về n đầu tiên của to_apply với một phương diện quét bổ sung. Kích thước của phương diện quét bổ sung trong số tất cả các đầu vào và đầu ra phải có cùng kích thước N. Các loại tham số k và giá trị trả về cuối cùng của to_apply cũng như k init phải khớp.
Ví dụ (m, n, k == 1, N == 3), đối với số nhớ ban đầu i, đầu vào [a, b, c], hàm f(x, c) -> (y, c') và scan_dimension=0, is_reverse=false:
- Bước 0:
f(a, i) -> (y0, c0) - Bước 1:
f(b, c0) -> (y1, c1) - Bước 2:
f(c, c1) -> (y2, c2)
Đầu ra của Scan là ([y0, y1, y2], c2).
Tán xạ
Xem thêm XlaBuilder::Scatter.
Thao tác phân tán XLA tạo ra một chuỗi kết quả là các giá trị của mảng đầu vào operands, với một số lát cắt (tại các chỉ mục do scatter_indices chỉ định) được cập nhật bằng chuỗi giá trị trong updates bằng cách sử dụng update_computation.
Scatter(operands..., scatter_indices, updates..., update_computation,
dimension_numbers, indices_are_sorted, unique_indices)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operands |
Chuỗi N XlaOp |
N mảng thuộc loại T_0, ..., T_N sẽ được phân tán vào. |
scatter_indices |
XlaOp |
Mảng chứa các chỉ mục bắt đầu của các lát phải được phân tán. |
updates |
Chuỗi N XlaOp |
N mảng thuộc loại T_0, ..., T_N. updates[i] chứa các giá trị phải được dùng để phân tán operands[i]. |
update_computation |
XlaComputation |
Phép tính dùng để kết hợp các giá trị hiện có trong mảng đầu vào và các giá trị cập nhật trong quá trình phân tán. Phép tính này phải thuộc loại T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N). |
index_vector_dim |
int64 |
Phương diện trong scatter_indices chứa các chỉ mục bắt đầu. |
update_window_dims |
ArraySlice<int64> |
Tập hợp các phương diện trong hình dạng updates là phương diện cửa sổ. |
inserted_window_dims |
ArraySlice<int64> |
Tập hợp kích thước cửa sổ phải được chèn vào hình dạng updates. |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
Một bản đồ phương diện từ các chỉ mục phân tán đến không gian chỉ mục toán hạng. Mảng này được diễn giải là ánh xạ i đến scatter_dims_to_operand_dims[i] . Mảng này phải là ánh xạ một-một và tổng. |
dimension_number |
ScatterDimensionNumbers |
Số phương diện cho thao tác phân tán |
indices_are_sorted |
bool |
Liệu người gọi có đảm bảo sắp xếp các chỉ mục hay không. |
unique_indices |
bool |
Liệu người gọi có đảm bảo rằng các chỉ mục là duy nhất hay không. |
Trong trường hợp:
- N phải lớn hơn hoặc bằng 1.
operands[0], ...,operands[N-1] phải có cùng kích thước.updates[0], ...,updates[N-1] phải có cùng kích thước.- Nếu
N = 1,Collate(T)làT. - Nếu
N > 1,Collate(T_0, ..., T_N)là một bộ gồm các phần tửNthuộc loạiT.
Nếu index_vector_dim bằng scatter_indices.rank, chúng ta sẽ ngầm coi scatter_indices có một phương diện 1 ở cuối.
Chúng ta xác định update_scatter_dims thuộc loại ArraySlice<int64> là tập hợp các phương diện trong hình dạng updates không có trong update_window_dims, theo thứ tự tăng dần.
Các đối số của scatter phải tuân theo những ràng buộc sau:
Mỗi mảng
updatesphải cóupdate_window_dims.size + scatter_indices.rank - 1phương diện.Ranh giới của phương diện
itrong mỗi mảngupdatesphải tuân thủ những điều sau:- Nếu
icó trongupdate_window_dims(tức là bằngupdate_window_dims[k] đối với một sốk), thì giới hạn của phương diệnitrongupdateskhông được vượt quá giới hạn tương ứng củaoperandsau khi tính đếninserted_window_dims(tức làadjusted_window_bounds[k], trong đóadjusted_window_boundschứa giới hạn củaoperandvới các giới hạn tại chỉ mụcinserted_window_dimsđã bị xoá). - Nếu
icó trongupdate_scatter_dims(tức là bằngupdate_scatter_dims[k] đối với một sốk), thì giới hạn của phương diệnitrongupdatesphải bằng với giới hạn tương ứng củascatter_indices, bỏ quaindex_vector_dim(tức làscatter_indices.shape.dims[k], nếuk<index_vector_dimvàscatter_indices.shape.dims[k+1] nếu không).
- Nếu
update_window_dimsphải theo thứ tự tăng dần, không có số thứ nguyên lặp lại và nằm trong phạm vi[0, updates.rank).inserted_window_dimsphải theo thứ tự tăng dần, không có số thứ nguyên lặp lại và nằm trong phạm vi[0, operand.rank).operand.rankphải bằng tổng củaupdate_window_dims.sizevàinserted_window_dims.size.scatter_dims_to_operand_dims.sizephải bằngscatter_indices.shape.dims[index_vector_dim] và các giá trị củascatter_dims_to_operand_dims.sizephải nằm trong phạm vi[0, operand.rank).
Đối với một chỉ mục U nhất định trong mỗi mảng updates, chỉ mục I tương ứng trong mảng operands tương ứng mà bạn phải áp dụng bản cập nhật này được tính như sau:
- Đặt
G= {U[k] choktrongupdate_scatter_dims}. Sử dụngGđể tra cứu một vectơ chỉ mụcStrong mảngscatter_indicessao choS[i] =scatter_indices[Combine(G,i)] trong đó Combine(A, b) chèn b vào các vị tríindex_vector_dimtrong A. - Tạo một chỉ mục
Sinthànhoperandbằng cách sử dụngSbằng cách phân tánSbằng bản đồscatter_dims_to_operand_dims. Cụ thể hơn:Sin[scatter_dims_to_operand_dims[k]] =S[k] nếuk<scatter_dims_to_operand_dims.size.Sin[_] =0nếu không.
- Tạo một chỉ mục
Wincho từng mảngoperandsbằng cách phân tán các chỉ mục tạiupdate_window_dimstrongUtheoinserted_window_dims. Một cách trang trọng hơn:Win[window_dims_to_operand_dims(k)] =U[k] nếuknằm trongupdate_window_dims, trong đówindow_dims_to_operand_dimslà hàm đơn điệu có miền [0,update_window_dims.size) và phạm vi [0,operand.rank) \inserted_window_dims. (Ví dụ: nếuupdate_window_dims.sizelà4,operand.ranklà6vàinserted_window_dimslà {0,2} thìwindow_dims_to_operand_dimslà {0→1,1→3,2→4,3→5}).Win[_] =0nếu không.
IlàWin+Sintrong đó + là phép cộng theo phần tử.
Tóm lại, bạn có thể xác định thao tác phân tán như sau.
- Khởi tạo
outputbằngoperands, tức là đối với tất cả các chỉ mụcJ, đối với tất cả các chỉ mụcOtrong mảngoperands[J]:
output[J][O] =operands[J][O] - Đối với mọi chỉ mục
Utrong mảngupdates[J] và chỉ mục tương ứngOtrong mảngoperand[J], nếuOlà chỉ mục hợp lệ chooutput:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
Thứ tự áp dụng các nội dung cập nhật là không xác định. Vì vậy, khi nhiều chỉ mục trong updates tham chiếu đến cùng một chỉ mục trong operands, giá trị tương ứng trong output sẽ không xác định.
Xin lưu ý rằng tham số đầu tiên được truyền vào update_computation sẽ luôn là giá trị hiện tại từ mảng output và tham số thứ hai sẽ luôn là giá trị từ mảng updates. Điều này đặc biệt quan trọng đối với những trường hợp update_computation không giao hoán.
Nếu indices_are_sorted được đặt thành true, thì XLA có thể giả định rằng scatter_indices được người dùng sắp xếp (theo thứ tự tăng dần, sau khi phân tán các giá trị theo scatter_dims_to_operand_dims). Nếu không, ngữ nghĩa sẽ được xác định bằng cách triển khai.
Nếu unique_indices được đặt thành true, thì XLA có thể giả định rằng tất cả các phần tử được phân tán đều là duy nhất. Vì vậy, XLA có thể sử dụng các thao tác không nguyên tử. Nếu unique_indices được đặt thành true và các chỉ mục được phân tán không phải là duy nhất thì ngữ nghĩa sẽ được xác định theo cách triển khai.
Một cách không chính thức, thao tác phân tán có thể được xem là ngược lại với thao tác thu thập, tức là thao tác phân tán sẽ cập nhật các phần tử trong đầu vào được trích xuất bằng thao tác thu thập tương ứng.
Để biết nội dung mô tả chi tiết không chính thức và ví dụ, hãy tham khảo phần "Nội dung mô tả không chính thức" trong Gather.
Để biết thông tin về StableHLO, hãy xem StableHLO – scatter.
Scatter – Ví dụ 1 – StableHLO

Trong hình ảnh trên, mỗi hàng của bảng là một ví dụ về chỉ mục cập nhật. Hãy xem xét từng bước từ trái(Chỉ mục cập nhật) sang phải(Chỉ mục kết quả):
Đầu vào) input có hình dạng S32[2,3,4,2]. scatter_indices có hình dạng S64[2,2,3,2]. updates có hình dạng S32[2,2,3,1,2].
Cập nhật chỉ mục) Trong phần đầu vào, chúng ta được cung cấp update_window_dims:[3,4]. Điều này cho chúng ta biết rằng dim 3 và dim 4 của updates là kích thước cửa sổ, được làm nổi bật bằng màu vàng. Điều này cho phép chúng ta suy ra rằng update_scatter_dims = [0,1,2].
Cập nhật chỉ mục phân tán) Cho chúng ta biết updated_scatter_dims đã trích xuất cho từng chỉ mục.
(Không phải màu vàng của cột Chỉ mục cập nhật)
Start Index (Chỉ mục bắt đầu) Nhìn vào hình ảnh tensor scatter_indices, chúng ta có thể thấy rằng các giá trị từ bước trước (Update scatter Index) cho chúng ta biết vị trí của chỉ mục bắt đầu. Từ index_vector_dim, chúng ta cũng biết được phương diện của starting_indices chứa các chỉ mục bắt đầu, đối với scatter_indices là phương diện 3 có kích thước 2.
Chỉ mục bắt đầu đầy đủ) scatter_dims_to_operand_dims = [2,1] cho biết phần tử đầu tiên của vectơ chỉ mục chuyển đến toán hạng chiều 2. Phần tử thứ hai của vectơ chỉ mục sẽ chuyển đến toán hạng chiều 1. Các phương diện toán hạng còn lại được điền bằng 0.
Chỉ mục phân lô đầy đủ) Chúng ta có thể thấy vùng được đánh dấu màu tím xuất hiện trong cột này(chỉ mục phân lô đầy đủ), cột chỉ mục phân tán cập nhật và cột chỉ mục cập nhật.
Chỉ mục toàn màn hình) Được tính từ update_window_dimensions [3,4].
Chỉ mục kết quả) Việc bổ sung Chỉ mục bắt đầu đầy đủ, Chỉ mục phân lô đầy đủ và Chỉ mục cửa sổ đầy đủ trong tenxơ operand. Lưu ý rằng các vùng được đánh dấu màu xanh lục cũng tương ứng với hình operand. Hàng cuối cùng bị bỏ qua vì nằm ngoài tenxơ operand.
Chọn
Xem thêm XlaBuilder::Select.
Tạo một mảng đầu ra từ các phần tử của hai mảng đầu vào, dựa trên các giá trị của một mảng vị từ.
Select(pred, on_true, on_false)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
pred |
XlaOp |
mảng thuộc loại PRED |
on_true |
XlaOp |
mảng thuộc loại T |
on_false |
XlaOp |
mảng thuộc loại T |
Các mảng on_true và on_false phải có cùng hình dạng. Đây cũng là hình dạng của mảng đầu ra. Mảng pred phải có cùng số chiều với on_true và on_false, với kiểu phần tử PRED.
Đối với mỗi phần tử P của pred, phần tử tương ứng của mảng đầu ra được lấy từ on_true nếu giá trị của P là true và từ on_false nếu giá trị của P là false. Là một dạng truyền tin bị hạn chế, pred có thể là một đại lượng vô hướng thuộc loại PRED. Trong trường hợp này, mảng đầu ra được lấy hoàn toàn từ on_true nếu pred là true và từ on_false nếu pred là false.
Ví dụ về pred không phải là vô hướng:
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
Ví dụ về pred vô hướng:
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
Hệ thống hỗ trợ lựa chọn giữa các bộ giá trị. Bộ được coi là các loại vô hướng cho mục đích này. Nếu on_true và on_false là các bộ (phải có cùng hình dạng!) thì pred phải là một đại lượng vô hướng thuộc loại PRED.
Để biết thông tin về StableHLO, hãy xem StableHLO – select
SelectAndScatter
Xem thêm XlaBuilder::SelectAndScatter.
Thao tác này có thể được coi là một thao tác kết hợp, trước tiên sẽ tính toán ReduceWindow trên mảng operand để chọn một phần tử từ mỗi cửa sổ, sau đó phân tán mảng source đến các chỉ mục của các phần tử đã chọn để tạo một mảng đầu ra có cùng hình dạng với mảng toán hạng. Hàm nhị phân select được dùng để chọn một phần tử trong mỗi cửa sổ bằng cách áp dụng phần tử đó trên mỗi cửa sổ và được gọi bằng thuộc tính rằng vectơ chỉ mục của tham số đầu tiên nhỏ hơn theo từ điển so với vectơ chỉ mục của tham số thứ hai. Hàm select trả về true nếu tham số đầu tiên được chọn và trả về false nếu tham số thứ hai được chọn, đồng thời hàm phải giữ tính bắc cầu (tức là nếu select(a, b) và select(b, c) là true, thì select(a, c) cũng là true) để phần tử được chọn không phụ thuộc vào thứ tự của các phần tử được duyệt qua cho một cửa sổ nhất định.
Hàm scatter được áp dụng tại mỗi chỉ mục đã chọn trong mảng đầu ra. Hàm này nhận hai tham số vô hướng:
- Giá trị hiện tại tại chỉ mục đã chọn trong mảng đầu ra
- Giá trị phân tán từ
sourceáp dụng cho chỉ mục đã chọn
Thao tác này kết hợp hai tham số và trả về một giá trị vô hướng dùng để cập nhật giá trị tại chỉ mục đã chọn trong mảng đầu ra. Ban đầu, tất cả chỉ mục của mảng đầu ra được đặt thành init_value.
Mảng đầu ra có cùng hình dạng với mảng operand và mảng source phải có cùng hình dạng với kết quả của việc áp dụng một thao tác ReduceWindow trên mảng operand. Bạn có thể dùng SelectAndScatter để truyền ngược các giá trị độ dốc cho một lớp gộp trong mạng nơ-ron.
SelectAndScatter(operand, select, window_dimensions, window_strides, padding,
source, init_value, scatter)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp
|
mảng thuộc loại T mà các cửa sổ trượt qua |
select
|
XlaComputation
|
phép tính nhị phân thuộc loại T, T
-> PRED, áp dụng cho tất cả các phần tử trong mỗi cửa sổ; trả về true nếu tham số đầu tiên được chọn và trả về false nếu tham số thứ hai được chọn |
window_dimensions
|
ArraySlice<int64>
|
mảng số nguyên cho các giá trị kích thước cửa sổ |
window_strides
|
ArraySlice<int64>
|
mảng số nguyên cho các giá trị sải cửa sổ |
padding
|
Padding
|
loại khoảng đệm cho cửa sổ (Padding::kSame hoặc Padding::kValid) |
source
|
XlaOp
|
mảng thuộc loại T có các giá trị cần phân tán |
init_value
|
XlaOp
|
giá trị vô hướng thuộc loại T cho giá trị ban đầu của mảng đầu ra |
scatter
|
XlaComputation
|
phép tính nhị phân thuộc loại T, T
-> T, để áp dụng từng phần tử nguồn phân tán với phần tử đích |
Hình dưới đây cho thấy các ví dụ về cách sử dụng SelectAndScatter, trong đó hàm select tính toán giá trị tối đa trong số các tham số của hàm. Xin lưu ý rằng khi các cửa sổ chồng lên nhau, như trong hình (2) bên dưới, chỉ mục của mảng operand có thể được chọn nhiều lần bởi các cửa sổ khác nhau. Trong hình, phần tử có giá trị 9 được chọn bởi cả hai cửa sổ trên cùng (màu xanh dương và màu đỏ) và hàm cộng nhị phân scatter tạo ra phần tử đầu ra có giá trị 8 (2 + 6).
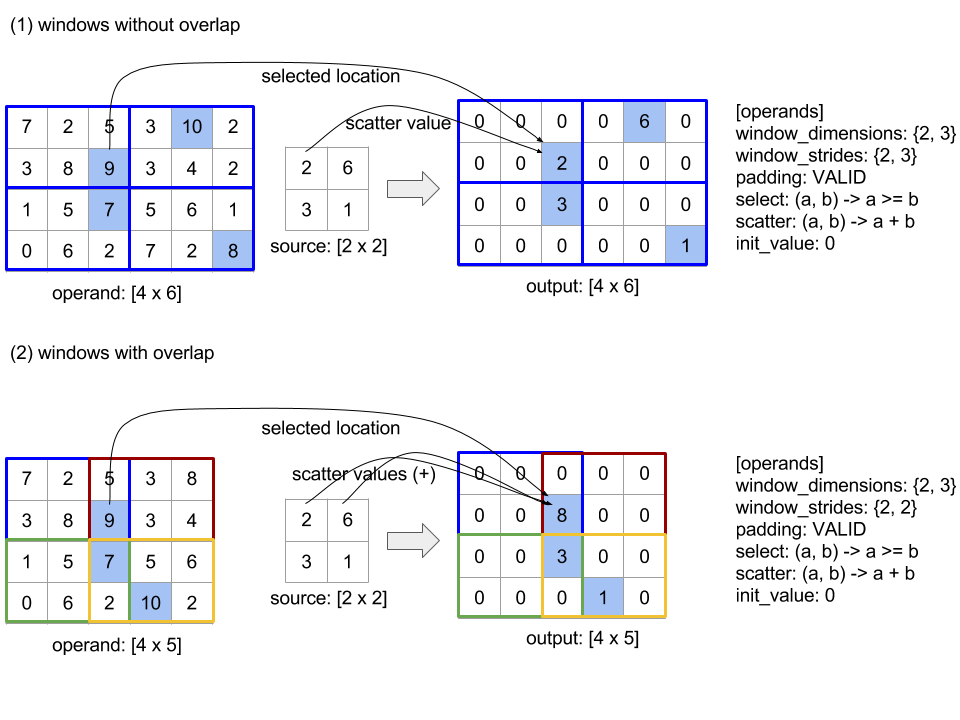
Thứ tự đánh giá của hàm scatter là tuỳ ý và có thể không xác định. Do đó, hàm scatter không nên quá nhạy cảm với việc liên kết lại. Hãy xem phần thảo luận về tính kết hợp trong bối cảnh của Reduce để biết thêm thông tin.
Để biết thông tin về StableHLO, hãy xem StableHLO – select_and_scatter.
Gửi
Xem thêm XlaBuilder::Send.
Send, SendWithTokens và SendToHost là các thao tác đóng vai trò là các thành phần giao tiếp cơ bản trong HLO. Các thao tác này thường xuất hiện trong các trích xuất dữ liệu HLO như một phần của hoạt động đầu vào/đầu ra cấp thấp hoặc chuyển dữ liệu giữa nhiều thiết bị, nhưng người dùng cuối không nên tự tạo các thao tác này theo cách thủ công.
Send(operand, handle)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
dữ liệu cần gửi (mảng thuộc loại T) |
handle |
ChannelHandle |
giá trị nhận dạng riêng biệt cho mỗi cặp gửi/nhận |
Gửi dữ liệu toán hạng đã cho đến một chỉ dẫn Recv trong một phép tính khác dùng chung cùng một mã nhận dạng kênh. Không trả về dữ liệu nào.
Tương tự như thao tác Recv, API ứng dụng của thao tác Send biểu thị giao tiếp đồng bộ và được phân tách nội bộ thành 2 chỉ dẫn HLO (Send và SendDone) để cho phép chuyển dữ liệu không đồng bộ. Xem thêm HloInstruction::CreateSend và HloInstruction::CreateSendDone.
Send(HloInstruction operand, int64 channel_id)
Khởi tạo một quá trình truyền không đồng bộ của toán hạng đến các tài nguyên được phân bổ theo chỉ dẫn Recv có cùng mã nhận dạng kênh. Trả về một ngữ cảnh, được dùng theo hướng dẫn SendDone sau đây để chờ hoàn tất quá trình truyền dữ liệu. Ngữ cảnh là một bộ {toán hạng (hình dạng), mã nhận dạng yêu cầu (U32)} và chỉ có thể được dùng bằng một chỉ dẫn SendDone.
Để biết thông tin về StableHLO, hãy xem StableHLO – send.
SendDone
Xem thêm HloInstruction::CreateSendDone.
SendDone(HloInstruction context)
Với ngữ cảnh do chỉ dẫn Send tạo, hãy đợi quá trình truyền dữ liệu hoàn tất. Lệnh này không trả về dữ liệu nào.
Lập lịch biểu cho chỉ dẫn của kênh
Thứ tự thực thi của 4 chỉ dẫn cho mỗi kênh (Recv, RecvDone, Send, SendDone) như sau.
Recvxảy ra trướcSendSendxảy ra trướcRecvDoneRecvxảy ra trướcRecvDoneSendxảy ra trướcSendDone
Khi trình biên dịch phụ trợ tạo lịch biểu tuyến tính cho từng phép tính giao tiếp thông qua các chỉ dẫn kênh, không được có chu kỳ giữa các phép tính. Ví dụ: các lịch biểu dưới đây dẫn đến tình trạng bế tắc.
SetDimensionSize
Xem thêm XlaBuilder::SetDimensionSize.
Đặt kích thước động của phương diện đã cho của XlaOp. Toán hạng phải có dạng mảng.
SetDimensionSize(operand, val, dimension)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng đầu vào n chiều. |
val |
XlaOp |
int32 đại diện cho kích thước động của thời gian chạy. |
dimension
|
int64
|
Một giá trị trong khoảng [0, n) chỉ định kích thước. |
Truyền toán hạng dưới dạng kết quả, với phương diện động do trình biên dịch theo dõi.
Các thao tác giảm giá trị ở hạ nguồn sẽ bỏ qua các giá trị được thêm vào.
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
ShiftLeft
Xem thêm XlaBuilder::ShiftLeft.
Thực hiện thao tác dịch chuyển bit sang trái theo từng phần tử trên lhs theo số lượng bit rhs.
ShiftLeft(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
ShiftLeft có một biến thể thay thế hỗ trợ truyền tin nhiều chiều:
ShiftLeft(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – shift_left.
ShiftRightArithmetic
Xem thêm XlaBuilder::ShiftRightArithmetic.
Thực hiện phép toán dịch chuyển số học sang phải theo từng phần tử trên lhs theo số lượng bit rhs.
ShiftRightArithmetic(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Một biến thể thay thế có hỗ trợ truyền tin nhiều chiều cho ShiftRightArithmetic:
ShiftRightArithmetic(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – shift_right_arithmetic.
ShiftRightLogical
Xem thêm XlaBuilder::ShiftRightLogical.
Thực hiện phép toán dịch chuyển logic sang phải theo từng phần tử trên lhs theo số lượng bit rhs.
ShiftRightLogical(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Có một biến thể thay thế hỗ trợ truyền tin nhiều chiều cho ShiftRightLogical:
ShiftRightLogical(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – shift_right_logical.
Ký
Xem thêm XlaBuilder::Sign.
Sign(operand) Phép toán dấu trên từng phần tử x -> sgn(x) trong đó
\[\text{sgn}(x) = \begin{cases} -1 & x < 0\\ -0 & x = -0\\ NaN & x = NaN\\ +0 & x = +0\\ 1 & x > 0 \end{cases}\]
bằng cách sử dụng toán tử so sánh của loại phần tử operand.
Sign(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Để biết thông tin về StableHLO, hãy xem StableHLO – sign.
Sin
Sin(operand) Hàm sin theo phần tử x -> sin(x).
Xem thêm XlaBuilder::Sin.
Sin(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Sin cũng hỗ trợ đối số result_accuracy không bắt buộc:
Sin(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – sine.
Slice (lát cắt)
Xem thêm XlaBuilder::Slice.
Thao tác phân đoạn sẽ trích xuất một mảng con từ mảng đầu vào. Mảng con có cùng số lượng phương diện như mảng đầu vào và chứa các giá trị bên trong một hộp giới hạn trong mảng đầu vào, trong đó các phương diện và chỉ mục của hộp giới hạn được đưa ra dưới dạng đối số cho thao tác phân đoạn.
Slice(operand, start_indices, limit_indices, strides)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Mảng N chiều thuộc loại T |
start_indices
|
ArraySlice<int64>
|
Danh sách N số nguyên chứa các chỉ mục bắt đầu của lát cắt cho mỗi phương diện. Giá trị phải lớn hơn hoặc bằng 0. |
limit_indices
|
ArraySlice<int64>
|
Danh sách gồm N số nguyên chứa các chỉ mục kết thúc (loại trừ) cho lát cắt của từng phương diện. Mỗi giá trị phải lớn hơn hoặc bằng giá trị start_indices tương ứng cho phương diện và nhỏ hơn hoặc bằng kích thước của phương diện. |
strides
|
ArraySlice<int64>
|
Danh sách gồm N số nguyên quyết định bước đầu vào của lát cắt. Lát cắt chọn mọi phần tử strides[d] trong phương diện d. |
Ví dụ về 1 chiều:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4})
// Result: {2.0, 3.0}
Ví dụ về 2 chiều:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3})
// Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
Để biết thông tin về StableHLO, hãy xem StableHLO – slice.
Sắp xếp
Xem thêm XlaBuilder::Sort.
Sort(operands, comparator, dimension, is_stable)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operands |
ArraySlice<XlaOp> |
Các toán hạng cần sắp xếp. |
comparator |
XlaComputation |
Phép tính so sánh cần sử dụng. |
dimension |
int64 |
Phương diện dùng để sắp xếp. |
is_stable |
bool |
Có nên sử dụng sắp xếp ổn định hay không. |
Nếu chỉ có một toán hạng được cung cấp:
Nếu toán hạng là một tensor 1 chiều (một mảng), thì kết quả sẽ là một mảng đã sắp xếp. Nếu bạn muốn sắp xếp mảng theo thứ tự tăng dần, thì bộ so sánh phải thực hiện phép so sánh nhỏ hơn. Chính thức, sau khi mảng được sắp xếp, mảng này sẽ giữ cho tất cả các vị trí chỉ mục
i, jcói < jlàcomparator(value[i], value[j]) = comparator(value[j], value[i]) = falsehoặccomparator(value[i], value[j]) = true.Nếu toán hạng có số lượng phương diện lớn hơn, thì toán hạng sẽ được sắp xếp theo phương diện đã cho. Ví dụ: đối với một tenxơ 2 chiều (một ma trận), giá trị phương diện
0sẽ sắp xếp độc lập mọi cột và giá trị phương diện1sẽ sắp xếp độc lập từng hàng. Nếu không có số phương diện nào được cung cấp, thì theo mặc định, phương diện cuối cùng sẽ được chọn. Đối với phương diện được sắp xếp, thứ tự sắp xếp tương tự sẽ áp dụng như trong trường hợp 1 chiều.
Nếu bạn cung cấp toán hạng n > 1:
Tất cả toán hạng
nphải là các tensor có cùng kích thước. Các loại phần tử của tensor có thể khác nhau.Tất cả các toán hạng đều được sắp xếp cùng nhau, chứ không phải riêng lẻ. Về mặt khái niệm, các toán hạng được coi là một bộ. Khi kiểm tra xem các phần tử của mỗi toán hạng ở vị trí chỉ mục
ivàjcó cần được hoán đổi hay không, bộ so sánh sẽ được gọi bằng các tham số vô hướng2 * n, trong đó tham số2 * ktương ứng với giá trị ở vị tríitừ toán hạngk-thvà tham số2 * k + 1tương ứng với giá trị ở vị tríjtừ toán hạngk-th. Do đó, thông thường, bộ so sánh sẽ so sánh các tham số2 * kvà2 * k + 1với nhau và có thể sử dụng các cặp tham số khác làm tiêu chí phân định.Kết quả là một bộ bao gồm các toán hạng theo thứ tự đã sắp xếp (dọc theo phương diện được cung cấp, như trên). Toán hạng
i-thcủa bộ tương ứng với toán hạngi-thcủa Sort.
Ví dụ: nếu có 3 toán hạng operand0 = [3, 1], operand1 = [42, 50], operand2 = [-3.0, 1.1] và bộ so sánh chỉ so sánh các giá trị của operand0 với giá trị nhỏ hơn, thì đầu ra của thao tác sắp xếp là bộ ([1, 3], [50, 42], [1.1, -3.0]).
Nếu is_stable được đặt thành true, thì quá trình sắp xếp sẽ được đảm bảo ổn định, tức là nếu có những phần tử được bộ so sánh coi là bằng nhau, thì thứ tự tương đối của các giá trị bằng nhau sẽ được giữ nguyên. Hai phần tử e1 và e2 bằng nhau khi và chỉ khi comparator(e1, e2) = comparator(e2, e1) = false. Theo mặc định, is_stable được đặt thành false.
Để biết thông tin về StableHLO, hãy xem StableHLO – sort.
Sqrt
Xem thêm XlaBuilder::Sqrt.
Phép toán căn bậc hai trên các phần tử tương ứng x -> sqrt(x).
Sqrt(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Sqrt cũng hỗ trợ đối số result_accuracy không bắt buộc:
Sqrt(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – sqrt.
Phụ
Xem thêm XlaBuilder::Sub.
Thực hiện phép trừ theo phần tử của lhs và rhs.
Sub(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Một biến thể thay thế có hỗ trợ truyền tin nhiều chiều cho Sub:
Sub(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – subtract.
Màu nâu vàng
Xem thêm XlaBuilder::Tan.
Tiếp tuyến theo phần tử x -> tan(x).
Tan(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Tan cũng hỗ trợ đối số result_accuracy không bắt buộc:
Tan(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – tan.
Tanh
Xem thêm XlaBuilder::Tanh.
Hàm tan hyperbolic theo phần tử x -> tanh(x).
Tanh(operand)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
Tanh cũng hỗ trợ đối số result_accuracy không bắt buộc:
Tanh(operand, result_accuracy)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng của hàm |
result_accuracy
|
không bắt buộc ResultAccuracy
|
Các loại độ chính xác mà người dùng có thể yêu cầu cho các thao tác đơn nguyên với nhiều cách triển khai |
Để biết thêm thông tin về result_accuracy, hãy xem phần Độ chính xác của kết quả.
Để biết thông tin về StableHLO, hãy xem StableHLO – tanh.
TopK
Xem thêm XlaBuilder::TopK.
TopK tìm các giá trị và chỉ mục của k phần tử lớn nhất hoặc nhỏ nhất cho chiều cuối cùng của tensor đã cho.
TopK(operand, k, largest)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand
|
XlaOp
|
Tensor mà từ đó trích xuất k phần tử hàng đầu.
Tensor phải có từ một chiều trở lên. Kích thước của phương diện cuối cùng của tensor phải lớn hơn hoặc bằng k. |
k |
int64 |
Số lượng phần tử cần trích xuất. |
largest
|
bool
|
Có nên trích xuất k phần tử lớn nhất hoặc nhỏ nhất hay không. |
Đối với một tensor đầu vào 1 chiều (một mảng), hãy tìm k mục lớn nhất hoặc nhỏ nhất trong mảng và xuất ra một bộ gồm hai mảng (values, indices). Do đó, values[j] là mục lớn/nhỏ thứ j trong operand và chỉ mục của mục này là indices[j].
Đối với một tensor đầu vào có nhiều hơn 1 phương diện, hãy tính toán k mục nhập hàng đầu dọc theo phương diện cuối cùng, giữ lại tất cả các phương diện (hàng) khác trong đầu ra.
Do đó, đối với một toán hạng có hình dạng [A, B, ..., P, Q] trong đó Q >= k đầu ra là một bộ dữ liệu (values, indices) trong đó:
values.shape = indices.shape = [A, B, ..., P, k]
Nếu hai phần tử trong một hàng bằng nhau, thì phần tử có chỉ mục thấp hơn sẽ xuất hiện trước.
Chuyển vị
Xem thêm thao tác tf.reshape.
Transpose(operand, permutation)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
operand |
XlaOp |
Toán hạng cần chuyển vị. |
permutation |
ArraySlice<int64> |
Cách hoán vị các phương diện. |
Hoán vị các phương diện toán hạng với hoán vị đã cho, sao cho ∀ i . 0 ≤ i < number of dimensions ⇒
input_dimensions[permutation[i]] = output_dimensions[i].
Điều này tương tự như Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions)).
Để biết thông tin về StableHLO, hãy xem StableHLO – transpose.
TriangularSolve
Xem thêm XlaBuilder::TriangularSolve.
Giải hệ phương trình tuyến tính với ma trận hệ số tam giác trên hoặc dưới bằng cách thay thế xuôi hoặc ngược. Phát sóng dọc theo các phương diện chính, quy trình này giải một trong các hệ thống ma trận op(a) * x =
b hoặc x * op(a) = b cho biến x, cho trước a và b, trong đó op(a) là op(a) = a hoặc op(a) = Transpose(a) hoặc op(a) = Conj(Transpose(a)).
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
a
|
XlaOp
|
mảng có nhiều hơn 2 chiều thuộc loại số phức hoặc dấu phẩy động có hình dạng [..., M,
M]. |
b
|
XlaOp
|
một mảng có hơn 2 chiều thuộc cùng một loại có hình dạng [..., M, K] nếu left_side là true, nếu không thì [..., K, M]. |
left_side
|
bool
|
cho biết có giải hệ phương trình dạng op(a) * x = b (true) hay x *
op(a) = b (false) hay không. |
lower
|
bool
|
có nên sử dụng tam giác trên hay dưới của a hay không. |
unit_diagonal
|
bool
|
nếu true, các phần tử đường chéo của a được giả định là 1 và không được truy cập. |
transpose_a
|
Transpose
|
có sử dụng a như hiện tại, chuyển vị hoặc lấy chuyển vị liên hợp của nó hay không. |
Dữ liệu đầu vào chỉ được đọc từ tam giác dưới/trên của a, tuỳ thuộc vào giá trị của lower. Các giá trị từ tam giác còn lại sẽ bị bỏ qua. Dữ liệu đầu ra được trả về trong cùng một tam giác; các giá trị trong tam giác còn lại được xác định theo cách triển khai và có thể là bất kỳ giá trị nào.
Nếu số phương diện của a và b lớn hơn 2, thì chúng được coi là các lô ma trận, trong đó tất cả các phương diện ngoại trừ 2 phương diện phụ đều là phương diện lô. a và b phải có phương diện lô bằng nhau.
Để biết thông tin về StableHLO, hãy xem StableHLO – triangular_solve.
Bộ
Xem thêm XlaBuilder::Tuple.
Một bộ chứa một số lượng biến đổi của các ô dữ liệu, mỗi ô có hình dạng riêng.
Tuple(elements)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
elements |
vectơ của XlaOp |
Mảng N thuộc loại T |
Điều này tương tự như std::tuple trong C++. Về mặt khái niệm:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
Bạn có thể phân tách (truy cập) các bộ dữ liệu thông qua thao tác GetTupleElement.
Để biết thông tin về StableHLO, hãy xem StableHLO – bộ dữ liệu.
Mặc dù
Xem thêm XlaBuilder::While.
While(condition, body, init)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
condition
|
XlaComputation
|
XlaComputation thuộc loại T -> PRED xác định điều kiện kết thúc của vòng lặp. |
body
|
XlaComputation
|
XlaComputation thuộc loại T -> T xác định nội dung của vòng lặp. |
init
|
T
|
Giá trị ban đầu cho thông số của condition và body. |
Thực thi tuần tự body cho đến khi condition không thành công. Điều này tương tự như một vòng lặp while điển hình trong nhiều ngôn ngữ khác, ngoại trừ những điểm khác biệt và hạn chế được liệt kê bên dưới.
- Nút
Whiletrả về giá trị thuộc loạiT, là kết quả từ lần thực thi cuối cùng củabody. - Hình dạng của loại
Tđược xác định tĩnh và phải giống nhau trên tất cả các lần lặp.
Các tham số T của phép tính được khởi tạo bằng giá trị init trong lần lặp đầu tiên và tự động cập nhật thành kết quả mới từ body trong mỗi lần lặp tiếp theo.
Một trường hợp sử dụng chính của nút While là triển khai việc thực thi lặp lại quá trình huấn luyện trong mạng nơ-ron. Mã giả đơn giản được trình bày bên dưới cùng với một biểu đồ biểu thị quá trình tính toán. Bạn có thể tìm thấy mã này trong while_test.cc.
Loại T trong ví dụ này là một Tuple bao gồm một int32 cho số lần lặp và một vector[10] cho bộ tích luỹ. Trong 1.000 lần lặp, vòng lặp sẽ tiếp tục thêm một vectơ hằng số vào bộ tích luỹ.
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}
Để biết thông tin về StableHLO, hãy xem StableHLO – while.
Xor
Xem thêm XlaBuilder::Xor.
Thực hiện phép toán XOR theo phần tử của lhs và rhs.
Xor(lhs, rhs)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng ở phía bên trái: mảng thuộc loại T |
Hình dạng của các đối số phải tương tự hoặc tương thích. Hãy xem tài liệu truyền tin để biết ý nghĩa của việc các hình dạng tương thích với nhau. Kết quả của một thao tác có hình dạng là kết quả của việc truyền hai mảng đầu vào. Trong biến thể này, các thao tác giữa các mảng có thứ hạng khác nhau không được hỗ trợ, trừ phi một trong các toán hạng là một đại lượng vô hướng.
Có một biến thể thay thế hỗ trợ truyền tin nhiều chiều cho Xor:
Xor(lhs,rhs, broadcast_dimensions)
| Đối số | Loại | Ngữ nghĩa |
|---|---|---|
| lhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| rhs | XlaOp | Toán hạng bên trái: mảng thuộc loại T |
| broadcast_dimension | ArraySlice |
Kích thước nào trong hình dạng đích tương ứng với từng kích thước của hình dạng toán hạng |
Biến thể này của thao tác nên được dùng cho các phép toán số học giữa các mảng có thứ hạng khác nhau (chẳng hạn như thêm một ma trận vào một vectơ).
Toán hạng broadcast_dimensions bổ sung là một lát số nguyên chỉ định các phương diện cần dùng để truyền toán hạng. Ngữ nghĩa được mô tả chi tiết trên trang phát sóng.
Để biết thông tin về StableHLO, hãy xem StableHLO – xor.