
يوضّح ما يلي دلالات العمليات المحدّدة في واجهة
XlaBuilder. عادةً، يتم ربط هذه العمليات بشكل مباشر بالعمليات المحدّدة في واجهة RPC في xla_data.proto.
ملاحظة حول التسمية: يتعامل نوع البيانات العام XLA مع مصفوفة ذات N بُعد تحتوي على عناصر من نوع موحّد (مثل عدد عشري ذي 32 بت). في جميع أنحاء المستندات، يتم استخدام المصفوفة للإشارة إلى مصفوفة ذات عدد عشوائي من الأبعاد. ولتسهيل الأمر، تحمل الحالات الخاصة أسماء أكثر تحديدًا ومألوفة، على سبيل المثال، المتجه هو مصفوفة ذات بُعد واحد، والمصفوفة هي مصفوفة ذات بُعدَين.
يمكنك الاطّلاع على مزيد من المعلومات حول بنية عملية في الأشكال والتصميم والتصميم المتجانب.
Abs
يمكنك الاطّلاع أيضًا على XlaBuilder::Abs.
القيمة المطلقة لكل عنصر x -> |x|
Abs(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - abs.
إضافة
يمكنك الاطّلاع أيضًا على XlaBuilder::Add.
تُجري هذه الدالة عملية جمع العناصر المتطابقة في lhs وrhs.
Add(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر خيار بديل يتوافق مع البث المتعدّد الأبعاد لعملية الإضافة:
Add(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على إضافة StableHLO.
AddDependency
يمكنك الاطّلاع أيضًا على HloInstruction::AddDependency.
قد يظهر AddDependency في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
AfterAll
يمكنك الاطّلاع أيضًا على XlaBuilder::AfterAll.
تأخذ الدالة AfterAll عددًا متغيرًا من الرموز المميزة وتنتج رمزًا مميزًا واحدًا. الرموز المميزة
هي أنواع أساسية يمكن ربطها بين العمليات التي لها آثار جانبية
لفرض الترتيب. يمكن استخدام AfterAll كعنصر ربط بين الرموز المميزة لترتيب عملية بعد مجموعة من العمليات.
AfterAll(tokens)
| الوسيطات | النوع | معاني |
|---|---|---|
tokens |
متّجه XlaOp |
عدد متغيّر من الرموز المميّزة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - after_all.
AllGather
يمكنك الاطّلاع أيضًا على XlaBuilder::AllGather.
تنفّذ عملية الدمج على مستوى النسخ المتماثلة.
AllGather(operand, all_gather_dimension, shard_count, replica_groups,
channel_id, layout, use_global_device_ids)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp
|
مصفوفة يتم ربطها عبر النسخ المتماثلة |
all_gather_dimension |
int64 |
سمة الدمج |
shard_count
|
int64
|
حجم كل مجموعة من النسخ المتماثلة |
replica_groups
|
متّجه من متّجهات
int64 |
المجموعات التي يتم إجراء عملية الدمج بينها |
channel_id
|
اختياري
ChannelHandle |
معرّف القناة الاختياري للتواصل بين الوحدات |
layout
|
اختياري Layout
|
تنشئ هذه الدالة نمط تخطيط سيتم من خلاله تسجيل التخطيط المطابق في الوسيطة |
use_global_device_ids
|
اختياري bool
|
تعرِض هذه الدالة القيمة "صحيح" إذا كانت المعرّفات في إعداد ReplicaGroup تمثّل معرّفًا عامًا. |
replica_groupsهي قائمة بمجموعات النسخ المتماثلة التي يتم إجراء التسلسل بينها (يمكن استرداد معرّف النسخة المتماثلة الحالية باستخدامReplicaId). يحدّد ترتيب النسخ المتماثلة في كل مجموعة ترتيب المواضع التي تظهر بها المدخلات في النتيجة. يجب أن تكونreplica_groupsفارغة (في هذه الحالة، تنتمي جميع النسخ المتماثلة إلى مجموعة واحدة، ويتم ترتيبها من0إلىN - 1)، أو أن تحتوي على العدد نفسه من العناصر مثل عدد النسخ المتماثلة. على سبيل المثال، تجريreplica_groups = {0, 2}, {1, 3}عملية التسلسل بين النسختين المتماثلتين0و2، و1و3.shard_countهو حجم كل مجموعة من النسخ المتماثلة. نحتاج إلى هذه المعلومات في الحالات التي تكون فيهاreplica_groupsفارغة.- يتم استخدام
channel_idللتواصل بين الوحدات: يمكن فقط لعملياتall-gatherالتي تحملchannel_idنفسها التواصل مع بعضها البعض. use_global_device_idsتعرض القيمة "صحيح" إذا كانت المعرّفات في إعداد ReplicaGroup تمثّل معرّفًا عامًا (replica_id * partition_count + partition_id) بدلاً من معرّف نسخة طبق الأصل. يتيح ذلك تجميع الأجهزة بشكل أكثر مرونة إذا كان هذا التخفيض الشامل متوافقًا مع كل من الأقسام والنسخ المتماثلة.
شكل الناتج هو شكل الإدخال مع تكبير all_gather_dimension بمقدار shard_count مرة. على سبيل المثال، إذا كان هناك نسختان طبق الأصل وكانت قيمة المعامِل [1.0, 2.5] و[3.0, 5.25] على التوالي في النسختين، ستكون قيمة الناتج من هذه العملية حيث all_gather_dim هي 0، هي [1.0, 2.5, 3.0,5.25] في كلتا النسختين.
يتم تقسيم واجهة برمجة التطبيقات الخاصة بـ AllGather داخليًا إلى تعليمتَين من تعليمات HLO
(AllGatherStart وAllGatherDone).
يمكنك الاطّلاع أيضًا على HloInstruction::CreateAllGatherStart.
تعمل AllGatherStart وAllGatherDone كعناصر أساسية في HLO، وقد تظهر هذه العمليات في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - all_gather.
AllReduce
يمكنك الاطّلاع أيضًا على XlaBuilder::AllReduce.
تُجري عملية حسابية مخصّصة على مستوى النسخ المتماثلة.
AllReduce(operand, computation, replica_groups, channel_id,
shape_with_layout, use_global_device_ids)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp
|
صفيف أو مجموعة غير فارغة من الصفائف لتقليل عدد النسخ المتماثلة |
computation |
XlaComputation |
احتساب التخفيض |
replica_groups
|
ReplicaGroup متّجه
|
المجموعات التي يتم إجراء عمليات التخفيض بينها |
channel_id
|
اختياري
ChannelHandle |
معرّف القناة الاختياري للتواصل بين الوحدات |
shape_with_layout
|
اختياري Shape
|
تحدّد هذه السمة تنسيق البيانات المنقولة |
use_global_device_ids
|
اختياري bool
|
تعرِض هذه الدالة القيمة "صحيح" إذا كانت المعرّفات في إعداد ReplicaGroup تمثّل معرّفًا عامًا. |
- عندما يكون
operandمجموعة من المصفوفات، يتم تنفيذ عملية all-reduce على كل عنصر من عناصر المجموعة. replica_groupsهي قائمة بمجموعات النسخ المتماثلة التي يتم إجراء عملية التصغير بينها (يمكن استرداد معرّف النسخة المتماثلة الحالية باستخدامReplicaId). يجب أن تكونreplica_groupsفارغة (في هذه الحالة، تنتمي جميع النسخ المتماثلة إلى مجموعة واحدة)، أو أن تحتوي على العدد نفسه من العناصر مثل عدد النسخ المتماثلة. على سبيل المثال، تنفّذreplica_groups = {0, 2}, {1, 3}عملية تقليل بين النسختَين المتطابقتَين0و2، و1و3.- يتم استخدام
channel_idللتواصل بين الوحدات: يمكن فقط لعملياتall-reduceالتي تحملchannel_idنفسها التواصل مع بعضها البعض. -
shape_with_layout: يفرض هذا الخيار تنسيق AllReduce على التنسيق المحدّد. يُستخدَم هذا الخيار لضمان التنسيق نفسه لمجموعة من عمليات AllReduce التي تم تجميعها بشكل منفصل. use_global_device_idsتعرض القيمة "صحيح" إذا كانت المعرّفات في إعداد ReplicaGroup تمثّل معرّفًا عامًا (replica_id * partition_count + partition_id) بدلاً من معرّف نسخة طبق الأصل. يتيح ذلك تجميع الأجهزة بشكل أكثر مرونة إذا كان هذا التخفيض الشامل متوافقًا مع كل من الأقسام والنسخ المتماثلة.
يكون شكل الناتج هو نفسه شكل الإدخال. على سبيل المثال، إذا كان هناك نسختان متطابقتان وكانت قيمة المعامِل [1.0, 2.5] و[3.0, 5.25] على التوالي في النسختين المتطابقتين، ستكون قيمة الناتج من هذه العملية الحسابية وعملية الجمع [4.0, 7.75] في كلتا النسختين المتطابقتين. إذا كان الإدخال عبارة عن مجموعة، سيكون الناتج عبارة عن مجموعة أيضًا.
يتطلّب احتساب نتيجة AllReduce الحصول على إدخال واحد من كل نسخة طبق الأصل، لذا إذا نفّذت إحدى النسخ عقدة AllReduce مرات أكثر من الأخرى، ستنتظر النسخة الأولى إلى الأبد. بما أنّ جميع النسخ المتماثلة تشغّل البرنامج نفسه، لا تتوفّر الكثير من الطرق لحدوث ذلك، ولكن يمكن أن يحدث عندما يعتمد شرط حلقة while على بيانات من infeed وتتسبّب البيانات التي infeed في تكرار حلقة while لعدد أكبر من المرات على نسخة متماثلة واحدة مقارنةً بنسخة أخرى.
يتم تقسيم واجهة برمجة التطبيقات الخاصة بـ AllReduce داخليًا إلى تعليمتَين من تعليمات HLO
(AllReduceStart وAllReduceDone).
يمكنك الاطّلاع أيضًا على HloInstruction::CreateAllReduceStart.
تعمل AllReduceStart وAllReduceDone كعناصر أساسية في HLO، وقد تظهر هذه العمليات في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
CrossReplicaSum
يمكنك الاطّلاع أيضًا على XlaBuilder::CrossReplicaSum.
تُجري عملية AllReduce مع احتساب المجموع.
CrossReplicaSum(operand, replica_groups)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp | صفيف أو مجموعة غير فارغة من الصفائف التي سيتم تقليلها على مستوى النسخ المتماثلة |
replica_groups
|
متّجه من المتّجهات الخاصة بـ
int64 |
المجموعات التي يتم إجراء عمليات التخفيض بينها |
تعرض هذه الدالة مجموع قيمة المعامِل ضمن كل مجموعة فرعية من النسخ المتماثلة. تقدّم جميع النسخ المتماثلة إدخالاً واحدًا إلى المجموع، وتتلقّى جميع النسخ المتماثلة المجموع الناتج لكل مجموعة فرعية.
AllToAll
يمكنك الاطّلاع أيضًا على XlaBuilder::AllToAll.
AllToAll هي عملية جماعية ترسل البيانات من جميع النوى إلى جميع النوى. تتضمّن هذه العملية مرحلتَين:
- مرحلة التوزيع: في كل نواة، يتم تقسيم المعامِل إلى
split_countعدد من الحِزم على طولsplit_dimensions، ويتم توزيع الحِزم على جميع النوى، مثلاً، يتم إرسال الحزمة رقم i إلى النواة رقم i. - مرحلة الجمع تدمج كل نواة الحِزم المستلَمة على طول
concat_dimension.
يمكن ضبط النوى المشارِكة من خلال:
-
replica_groups: تحتوي كل ReplicaGroup على قائمة بمعرّفات النسخ المتماثلة المشارِكة في عملية الحساب (يمكن استرداد معرّف النسخة المتماثلة الحالية باستخدامReplicaId). سيتم تطبيق AllToAll ضمن المجموعات الفرعية بالترتيب المحدّد. على سبيل المثال، يعنيreplica_groups = { {1,2,3}, {4,5,0} }أنّه سيتم تطبيق AllToAll ضمن النسخ المتماثلة{1, 2, 3}، وفي مرحلة التجميع، وسيتم ربط الكتل المستلَمة بالترتيب نفسه 1 و2 و3. بعد ذلك، سيتم تطبيق عملية AllToAll أخرى على النسخ المتماثلة 4 و5 و0، وسيكون ترتيب الدمج أيضًا 4 و5 و0. إذا كانتreplica_groupsفارغة، ستنتمي جميع النسخ المتطابقة إلى مجموعة واحدة، وذلك بترتيب تسلسل ظهورها.
المتطلَّبات الأساسية:
- يجب أن يكون حجم السمة الخاصة بالمعامل في
split_dimensionقابلاً للقسمة علىsplit_count. - شكل المعامِل ليس صفًا.
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups, layout, channel_id)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة إدخال ذات n أبعاد |
split_dimension
|
int64
|
قيمة في الفاصل الزمني
[0,n) تحدّد اسم السمة
التي يتم تقسيم
المعامل على طولها |
concat_dimension
|
int64
|
قيمة في الفاصل الزمني
[0,n) تحدّد اسم
السمة التي يتم
ربط الأقسام المقسّمة
على طولها |
split_count
|
int64
|
عدد النوى التي تشارك في هذه العملية. إذا كان
replica_groups فارغًا،
يجب أن يكون هذا هو عدد
النسخ المتماثلة، وإلا
يجب أن يكون هذا
مساويًا لعدد
النسخ المتماثلة في كل
مجموعة. |
replica_groups
|
ReplicaGroupvector
|
تحتوي كل مجموعة على قائمة بمعرّفات النسخ المتماثلة. |
layout |
اختياري Layout |
تنسيق الذاكرة الذي يحدّده المستخدم |
channel_id
|
اختياري ChannelHandle
|
معرّف فريد لكل زوج إرسال/استلام |
يمكنك الاطّلاع على xla::shapes لمزيد من المعلومات عن الأشكال والتنسيقات..
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - all_to_all.
AllToAll - المثال 1
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(
x,
/*split_dimension=*/ 1,
/*concat_dimension=*/ 0,
/*split_count=*/ 4);
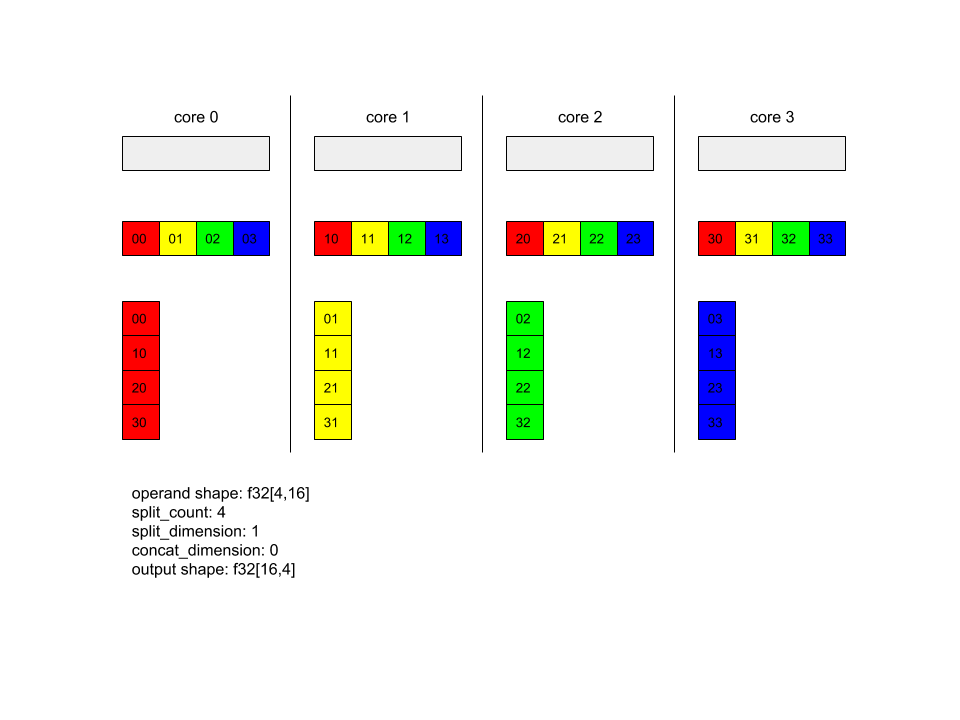
في المثال أعلاه، هناك 4 نوى تشارك في عملية Alltoall. في كل نواة، يتم تقسيم المعامِل إلى 4 أجزاء على طول البُعد 1، وبالتالي يكون لكل جزء شكل f32[4,4]. يتم توزيع الأجزاء الأربعة على جميع النوى. بعد ذلك، يربط كل نواة الأجزاء المستلَمة على طول السمة 0، بترتيب النواة 0-4. وبالتالي، يكون شكل الناتج على كل نواة f32[16,4].
AllToAll - Example 2 - StableHLO

في المثال أعلاه، هناك نسختان طبق الأصل تشاركان في عملية AllToAll. وفي كل نسخة طبق الأصل، يكون شكل المعامِل f32[2,4]. يتم تقسيم المعامِل إلى جزأين على طول البُعد 1، وبالتالي يكون شكل كل جزء f32[2,2]. بعد ذلك، يتم تبادل الجزأين بين النسخ المتطابقة وفقًا لموضعهما في مجموعة النسخ المتطابقة. تجمع كل نسخة طبق الأصل الجزء المقابل لها من كلا المعاملَين وتدمجهما على طول البُعد 0. ونتيجةً لذلك، يكون شكل الناتج في كل نسخة طبق الأصل f32[4,2].
RaggedAllToAll
يمكنك الاطّلاع أيضًا على XlaBuilder::RaggedAllToAll.
تُجري عملية RaggedAllToAll عملية جماعية من الكل إلى الكل، حيث يكون الإدخال والإخراج عبارة عن موترات غير منتظمة.
RaggedAllToAll(input, input_offsets, send_sizes, output, output_offsets,
recv_sizes, replica_groups, channel_id)
| الوسيطات | النوع | معاني |
|---|---|---|
input |
XlaOp |
مصفوفة N من النوع T |
input_offsets |
XlaOp |
مصفوفة N من النوع T |
send_sizes |
XlaOp |
مصفوفة N من النوع T |
output |
XlaOp |
مصفوفة N من النوع T |
output_offsets |
XlaOp |
مصفوفة N من النوع T |
recv_sizes |
XlaOp |
مصفوفة N من النوع T |
replica_groups
|
ReplicaGroup متّجه
|
تحتوي كل مجموعة على قائمة بمعرّفات النسخ المتماثلة. |
channel_id
|
اختياري ChannelHandle
|
معرّف فريد لكل زوج إرسال/استلام |
يتم تحديد الموترات غير المنتظمة من خلال مجموعة من ثلاثة موترات:
data: يكون المتّجه المتعدّد الأبعادdata"غير منتظم" على طول بُعده الخارجي، حيث يكون لكل عنصر مفهرس حجم متغير.offsets: يفهرس موترoffsetsالبُعد الخارجي لموترdata، ويمثّل الإزاحة الأولية لكل عنصر غير منتظم في موترdata.sizes: يمثّل موترsizesحجم كل عنصر غير منتظم في موترdata، حيث يتم تحديد الحجم بوحدات العناصر الفرعية. يتم تعريف العنصر الفرعي على أنّه لاحقة شكل موتر "البيانات" التي يتم الحصول عليها عن طريق إزالة البُعد "غير المنتظم" الخارجي.- يجب أن يكون حجم موترَي
offsetsوsizesمتطابقًا.
مثال على موتر غير منتظم:
data: [8,3] =
{ {a,b,c},{d,e,f},{g,h,i},{j,k,l},{m,n,o},{p,q,r},{s,t,u},{v,w,x} }
offsets: [3] = {0, 1, 4}
sizes: [3] = {1, 3, 4}
// Index 'data' at 'offsets'[0], 'sizes'[0]' // {a,b,c}
// Index 'data' at 'offsets'[1], 'sizes'[1]' // {d,e,f},{g,h,i},{j,k,l}
// Index 'data' at 'offsets'[2], 'sizes'[2]' // {m,n,o},{p,q,r},{s,t,u},{v,w,x}
يجب تقسيم output_offsets بطريقة تتيح لكل نسخة طبق الأصل الحصول على إزاحات من منظور مخرجات النسخة المستهدَفة.
بالنسبة إلى إزاحة الإخراج رقم i، سترسل النسخة المتماثلة الحالية تحديث input[input_offsets[i]:input_offsets[i]+send_sizes[i]] إلى النسخة المتماثلة رقم i التي ستتم كتابتها إلى output_i[output_offsets[i]:output_offsets[i]+send_sizes[i]] في النسخة المتماثلة رقم i output.
على سبيل المثال، إذا كان لدينا نسختان طبق الأصل:
replica 0:
input: [1, 2, 2]
output:[0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 2]
output_offsets: [0, 0]
recv_sizes: [1, 1]
replica 1:
input: [3, 4, 0]
output: [0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 1]
output_offsets: [1, 2]
recv_sizes: [2, 1]
// replica 0's result will be: [1, 3, 0, 0]
// replica 1's result will be: [2, 2, 4, 0]
تتضمّن عملية ragged all-to-all في HLO الوسيطات التالية:
-
input: موتر بيانات إدخال غير منتظم -
output: موتر بيانات الإخراج غير المنتظم -
input_offsets: متّجه إزاحات الإدخال غير المنتظم. send_sizes: موتر أحجام الإرسال غير المنتظمة-
output_offsets: مصفوفة من الإزاحات غير المنتظمة في ناتج النسخة المتماثلة المستهدَفة. recv_sizes: موتر أحجام الاستقبال غير المنتظمة
يجب أن يكون لجميع موترات *_offsets و*_sizes الشكل نفسه.
يتوفّر شكلان لموترَي *_offsets و*_sizes:
[num_devices]حيث يمكن أن يرسل ragged-all-to-all تحديثًا واحدًا على الأكثر إلى كل جهاز بعيد في مجموعة النسخ المتماثلة. على سبيل المثال:
for (remote_device_id : replica_group) {
SEND input[input_offsets[remote_device_id]],
output[output_offsets[remote_device_id]],
send_sizes[remote_device_id] }
[num_devices, num_updates]حيث يمكن أن يرسل ragged-all-to-all ما يصل إلىnum_updatesتحديثات إلى الجهاز البعيد نفسه (كل تحديث بإزاحة مختلفة)، لكل جهاز بعيد في مجموعة النسخ المتماثلة.
على سبيل المثال:
for (remote_device_id : replica_group) {
for (update_idx : num_updates) {
SEND input[input_offsets[remote_device_id][update_idx]],
output[output_offsets[remote_device_id][update_idx]]],
send_sizes[remote_device_id][update_idx] } }
و
يمكنك الاطّلاع أيضًا على XlaBuilder::And.
تُجري عملية AND على مستوى العناصر في موترَين lhs وrhs.
And(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل من "و" يتيح البث بأبعاد مختلفة:
And(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - and.
غير متزامنة
راجِع أيضًا HloInstruction::CreateAsyncStart وHloInstruction::CreateAsyncUpdate وHloInstruction::CreateAsyncDone.
AsyncDone وAsyncStart وAsyncUpdate هي تعليمات HLO داخلية تُستخدَم
في العمليات غير المتزامنة وتعمل كعناصر أساسية في HLO. قد تظهر هذه العمليات
في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
Atan2
يمكنك الاطّلاع أيضًا على XlaBuilder::Atan2.
تُجري هذه الدالة عملية atan2 على مستوى كل عنصر في lhs وrhs.
Atan2(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بالشكل الناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل مع إمكانية البث بأبعاد مختلفة للدالة Atan2:
Atan2(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات عن StableHLO، يُرجى الاطّلاع على StableHLO - atan2.
BatchNormGrad
راجِع أيضًا
XlaBuilder::BatchNormGrad
وورقة البحث الأصلية حول التسوية الدفعية
للحصول على وصف تفصيلي للخوارزمية.
تحسب هذه العملية تدرّجات التسوية الدفعية.
BatchNormGrad(operand, scale, batch_mean, batch_var, grad_output, epsilon,
feature_index)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp | المصفوفة ذات الأبعاد n المطلوب تسويتها (x) |
scale |
XlaOp | مصفوفة أحادية البُعد (\(\gamma\)) |
batch_mean |
XlaOp | مصفوفة أحادية البُعد (\(\mu\)) |
batch_var |
XlaOp | مصفوفة أحادية البُعد (\(\sigma^2\)) |
grad_output |
XlaOp | التدرّجات التي تم تمريرها إلى BatchNormTraining (\(\nabla y\)) |
epsilon |
float |
قيمة إبسيلون (\(\epsilon\)) |
feature_index |
int64 |
فهرس سمة الميزة في operand |
بالنسبة إلى كل ميزة في سمة الميزة (feature_index هو فهرس سمة الميزة في operand)، تحسب العملية التدرّجات بالنسبة إلى operand وoffset وscale في جميع السمات الأخرى. يجب أن يكون feature_index فهرسًا صالحًا لسمة الميزة في operand.
يتم تحديد التدرّجات الثلاثة من خلال الصيغ التالية (بافتراض مصفوفة رباعية الأبعاد operand وفهرس سمة البُعد l وحجم الدفعة m والأحجام المكانية w وh):
\[ \begin{split} c_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) \\\\ d_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \\\\ \nabla x_{ijkl} &= \frac{\gamma_{l} }{\sqrt{\sigma^2_{l}+\epsilon} } \left( \nabla y_{ijkl} - d_l - c_l (x_{ijkl} - \mu_{l}) \right) \\\\ \nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon} } \right) \\\\\ \nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \end{split} \]
تمثّل المدخلات batch_mean وbatch_var قيم اللحظات على مستوى الدُفعات والأبعاد المكانية.
نوع الإخراج هو مجموعة من ثلاثة معرّفات:
| النواتج | النوع | معاني |
|---|---|---|
grad_operand
|
XlaOp | تدرّج اللون بالنسبة إلى
الإدخال operand
(\(\nabla x\)) |
grad_scale
|
XlaOp | تدرّج بالنسبة إلى
الإدخال **scale **
(\(\nabla\gamma\)) |
grad_offset
|
XlaOp | تدرّج الألوان بالنسبة إلى
الإدخال
offset(\(\nabla\beta\)) |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - batch_norm_grad.
BatchNormInference
راجِع أيضًا
XlaBuilder::BatchNormInference
وورقة البحث الأصلية حول التسوية الدفعية
للحصول على وصف تفصيلي للخوارزمية.
تعمل هذه الدالة على تسوية مصفوفة على مستوى الدُفعات والأبعاد المكانية.
BatchNormInference(operand, scale, offset, mean, variance, epsilon,
feature_index)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp | المصفوفة ذات الأبعاد n المطلوب تسويتها |
scale |
XlaOp | مصفوفة أحادية البُعد |
offset |
XlaOp | مصفوفة أحادية البُعد |
mean |
XlaOp | مصفوفة أحادية البُعد |
variance |
XlaOp | مصفوفة أحادية البُعد |
epsilon |
float |
قيمة إبسيلون |
feature_index |
int64 |
فهرس سمة الميزة في operand |
بالنسبة إلى كل ميزة في سمة الميزة (feature_index هو فهرس سمة الميزة في operand)، تحسب العملية المتوسط والتباين في جميع السمات الأخرى، وتستخدم المتوسط والتباين لتسوية كل عنصر في operand. يجب أن يكون feature_index فهرسًا صالحًا لسمة الميزة في operand.
BatchNormInference هي نفسها استدعاء BatchNormTraining بدون احتساب mean وvariance لكل دفعة، بل تستخدم mean وvariance كقيم مقدّرة. والغرض من هذه العملية هو تقليل وقت الاستجابة في الاستدلال، ومن هنا جاءت التسمية BatchNormInference.
الناتج هو صفيفة عادية ذات n أبعاد لها الشكل نفسه كشكل الإدخال
operand.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - batch_norm_inference.
BatchNormTraining
راجِع أيضًا
XlaBuilder::BatchNormTraining
وthe original batch normalization paper
للحصول على وصف تفصيلي للخوارزمية.
تعمل هذه الدالة على تسوية مصفوفة على مستوى الدُفعات والأبعاد المكانية.
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المصفوفة ذات الأبعاد n المطلوب تسويتها (x) |
scale |
XlaOp |
مصفوفة أحادية البُعد (\(\gamma\)) |
offset |
XlaOp |
مصفوفة أحادية البُعد (\(\beta\)) |
epsilon |
float |
قيمة إبسيلون (\(\epsilon\)) |
feature_index |
int64 |
فهرس سمة الميزة في operand |
بالنسبة إلى كل ميزة في سمة الميزة (feature_index هو فهرس سمة الميزة في operand)، تحسب العملية المتوسط والتباين في جميع السمات الأخرى، وتستخدم المتوسط والتباين لتسوية كل عنصر في operand. يجب أن يكون feature_index فهرسًا صالحًا لسمة الميزة في operand.
تكون الخوارزمية على النحو التالي لكل مجموعة في operand \(x\) تحتوي على m
عناصر بحجم الأبعاد المكانية w وh (بافتراض أنّ operand
هي مصفوفة رباعية الأبعاد):
تحسب هذه الدالة متوسط الدفعة \(\mu_l\) لكل ميزة
lفي سمة الميزة: \(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\)تحسب هذه الدالة تباين الدُفعات \(\sigma^2_l\): $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
تطبيع البيانات وتوسيع نطاقها وتغييرها: \(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon} }+\beta_l\)
تتم إضافة قيمة إبسيلون، وهي عادةً رقم صغير، لتجنُّب أخطاء القسمة على صفر.
نوع الإخراج هو مجموعة من ثلاثة XlaOp:
| النواتج | النوع | معاني |
|---|---|---|
output
|
XlaOp
|
مصفوفة ذات n أبعاد لها الشكل نفسه كما في الإدخال
operand (y) |
batch_mean |
XlaOp |
مصفوفة أحادية البُعد (\(\mu\)) |
batch_var |
XlaOp |
مصفوفة أحادية البُعد (\(\sigma^2\)) |
batch_mean وbatch_var هما لحظات يتم احتسابها على مستوى الدفعة والسمات المكانية باستخدام الصيغ أعلاه.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - batch_norm_training.
Bitcast
يمكنك الاطّلاع أيضًا على HloInstruction::CreateBitcast.
قد يظهر Bitcast في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
BitcastConvertType
يمكنك الاطّلاع أيضًا على XlaBuilder::BitcastConvertType.
على غرار tf.bitcast في TensorFlow، تنفّذ هذه العملية عملية bitcast على مستوى العناصر من شكل بيانات إلى شكل مستهدف. يجب أن يتطابق حجم الإدخال والإخراج: على سبيل المثال، تصبح عناصر s32 عناصر f32 من خلال روتين bitcast، وسيصبح عنصر s32 واحد أربعة عناصر s8. يتم تنفيذ عملية bitcast كعملية تحويل منخفضة المستوى، لذا ستؤدي الآلات التي تستخدم تمثيلات مختلفة للأرقام النقطية العائمة إلى نتائج مختلفة.
BitcastConvertType(operand, new_element_type)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T ذات الأبعاد D |
new_element_type |
PrimitiveType |
النوع U |
يجب أن تتطابق أبعاد المعامِل والشكل المستهدف، باستثناء البُعد الأخير الذي سيتغيّر حسب نسبة حجم العنصر الأساسي قبل التحويل وبعده.
يجب ألا تكون أنواع عناصر المصدر والوجهة عبارة عن مجموعات.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - bitcast_convert.
Bitcast-converting to primitive type of different width
تتيح تعليمات HLO الحالة التي لا يكون فيها حجم نوع عنصر الإخراج T' مساويًا لحجم عنصر الإدخال T.BitcastConvert بما أنّ العملية بأكملها هي من الناحية المفاهيمية عملية تحويل إلى سلسلة من البتات ولا تغيّر البايتات الأساسية، يجب تغيير شكل العنصر الناتج. بالنسبة إلى B = sizeof(T), B' =
sizeof(T')، هناك حالتان محتملتان.
أولاً، عندما تكون B > B'، يحصل شكل الإخراج على بُعد جديد أصغر حجمًا يبلغ B/B'. على سبيل المثال:
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
تبقى القاعدة كما هي بالنسبة إلى القيم العددية الفعّالة:
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
بدلاً من ذلك، بالنسبة إلى B' > B، تتطلّب التعليمات أن يكون آخر بُعد منطقي للشكل الإدخال مساويًا B'/B، ويتم حذف هذا البُعد أثناء عملية التحويل:
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
يُرجى العِلم أنّ عمليات التحويل بين عروض بتات مختلفة ليست على مستوى العناصر.
البث
يمكنك الاطّلاع أيضًا على XlaBuilder::Broadcast.
تضيف هذه الدالة سمات إلى مصفوفة من خلال تكرار البيانات في المصفوفة.
Broadcast(operand, broadcast_sizes)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
الصفيف المطلوب تكراره |
broadcast_sizes |
ArraySlice<int64> |
أحجام السمات الجديدة |
يتم إدراج السمات الجديدة على اليسار، أي إذا كان broadcast_sizes يتضمّن القيم {a0, ..., aN} وكان شكل المعامِل يتضمّن السمات {b0, ..., bM}، فإنّ شكل الناتج يتضمّن السمات {a0, ..., aN, b0, ..., bM}.
يتم فهرسة الأبعاد الجديدة في نُسخ من المعامِل، أي
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
على سبيل المثال، إذا كان operand عددًا قياسيًا f32 بقيمة 2.0f، وكان broadcast_sizes هو {2, 3}، ستكون النتيجة مصفوفة بالشكل f32[2, 3] وستكون جميع القيم في النتيجة هي 2.0f.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - البث.
BroadcastInDim
يمكنك الاطّلاع أيضًا على XlaBuilder::BroadcastInDim.
توسّع هذه الدالة حجم وعدد أبعاد مصفوفة من خلال تكرار البيانات في المصفوفة.
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
الصفيف المطلوب تكراره |
out_dim_size
|
ArraySlice<int64>
|
أحجام أبعاد الشكل المستهدَف |
broadcast_dimensions
|
ArraySlice<int64>
|
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يشبه هذا النوع Broadcast، ولكنّه يتيح إضافة سمات في أي مكان وتوسيع السمات الحالية بالحجم 1.
يتم بث operand إلى الشكل الموصوف بواسطة out_dim_size.
تعمل broadcast_dimensions على ربط أبعاد operand بأبعاد الشكل المستهدف، أي يتم ربط البُعد رقم i في المعامِل بالبُعد رقم broadcast_dimension[i] في شكل الناتج. يجب أن يكون حجم أبعاد operand هو 1 أو أن يكون الحجم نفسه كحجم البُعد في شكل الناتج الذي يتم الربط به. يتم ملء الأبعاد المتبقية بأبعاد حجمها 1. بعد ذلك، يتم بث البث ذو الأبعاد المتدهورة على طول هذه الأبعاد المتدهورة للوصول إلى شكل الناتج. يتم وصف الدلالات بالتفصيل في صفحة البث.
الاتصال
يمكنك الاطّلاع أيضًا على XlaBuilder::Call.
يستدعي عملية حسابية باستخدام الوسيطات المحدّدة.
Call(computation, operands...)
| الوسيطات | النوع | معاني |
|---|---|---|
computation
|
XlaComputation
|
حساب النوع T_0, T_1, ...,
T_{N-1} -> S مع N مَعلمة من أي نوع |
operands |
تسلسل N XlaOps |
وسيطات N من أي نوع |
يجب أن تتطابق عدد المعلمات وأنواعها في operands مع معلمات computation، ويُسمح بعدم توفّر operands.
CompositeCall
يمكنك الاطّلاع أيضًا على XlaBuilder::CompositeCall.
تغليف عملية مكوّنة من عمليات StableHLO أخرى، مع أخذ مدخلات وcomposite_attributes وإنتاج نتائج يتم تنفيذ دلالات العملية من خلال سمة التجزئة. يمكن استبدال العملية المركّبة بعملية التفكيك بدون تغيير دلالات البرنامج. في الحالات التي لا يؤدي فيها تضمين عملية التحليل إلى توفير دلالات العملية نفسها، يُفضّل استخدام custom_call.
يُستخدَم حقل الإصدار (القيمة التلقائية هي 0) للإشارة إلى وقت تغيير دلالات العنصر المركّب.
يتم تنفيذ هذه العملية كـ kCall مع السمة is_composite=true. يتم تحديد الحقل
decomposition من خلال السمة computation. تخزّن سمات الواجهة الأمامية السمات المتبقية التي تبدأ بالبادئة composite..
مثال على عملية CompositeCall:
f32[] call(f32[] %cst), to_apply=%computation, is_composite=true,
frontend_attributes = {
composite.name="foo.bar",
composite.attributes={n = 1 : i32, tensor = dense<1> : tensor<i32>},
composite.version="1"
}
CompositeCall(computation, operands..., name, attributes, version)
| الوسيطات | النوع | معاني |
|---|---|---|
computation
|
XlaComputation
|
حساب النوع T_0, T_1, ...,
T_{N-1} -> S مع N مَعلمة من أي نوع |
operands |
تسلسل N XlaOps |
عدد متغيّر من القيم |
name |
string |
اسم المكوِّن |
attributes
|
اختياري string
|
قاموس اختياري للسمات بتنسيق السلسلة |
version
|
اختياري int64
|
عدد عمليات تعديل الإصدارات التي يجب أن تكون أقل من 0x0A دلالات العملية المركّبة |
إنّ decomposition الخاص بعملية ليس حقلاً يُطلق عليه اسم، بل يظهر كسمة to_apply تشير إلى الدالة التي تحتوي على التنفيذ على مستوى أدنى، أي to_apply=%funcname.
يمكنك الاطّلاع على مزيد من المعلومات حول التركيب والتحليل على مواصفات StableHLO.
Cbrt
يمكنك الاطّلاع أيضًا على XlaBuilder::Cbrt.
عملية الجذر التكعيبي لكل عنصر x -> cbrt(x).
Cbrt(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Cbrt أيضًا الوسيط الاختياري result_accuracy:
Cbrt(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - cbrt.
تقريب للأعلى
يمكنك الاطّلاع أيضًا على XlaBuilder::Ceil.
دالة السقف لكل عنصر x -> ⌈x⌉
Ceil(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - ceil.
Cholesky
يمكنك الاطّلاع أيضًا على XlaBuilder::Cholesky.
تحسب هذه الدالة تحليل شوليسكي لمجموعة من المصفوفات المحددة الموجبة المتماثلة (الهرميتية).
Cholesky(a, lower)
| الوسيطات | النوع | معاني |
|---|---|---|
a
|
XlaOp
|
مصفوفة من نوع معقّد أو نقطة عائمة بأكثر من بُعدَين |
lower |
bool |
تحديد ما إذا كان سيتم استخدام المثلث العلوي أو السفلي من a |
إذا كانت lower هي true، يتم احتساب المصفوفات المثلثية السفلية l بحيث يكون $a = l .
l^T$. إذا كانت lower هي false، يتم احتساب المصفوفات المثلثية العلوية u بحيث تكون
\(a = u^T . u\).
تتم قراءة بيانات الإدخال من المثلث السفلي/العلوي فقط من a، وذلك حسب قيمة lower. ويتم تجاهل القيم من المثلث الآخر. ويتم عرض بيانات الإخراج في المثلث نفسه، وتكون القيم في المثلث الآخر غير محدّدة في التنفيذ وقد تكون أي شيء.
إذا كان a يحتوي على أكثر من سمتَين، يتم التعامل مع a على أنّه مجموعة من المصفوفات،
حيث تكون جميع السمات باستثناء السمتَين الثانويتَين سمات مجمّعة.
إذا لم تكن a متماثلة (هيرميتية) ومحدّدة موجبة، ستكون النتيجة محددة حسب التنفيذ.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - cholesky.
عقدة تقييد القيم
يمكنك الاطّلاع أيضًا على XlaBuilder::Clamp.
تحدّ هذه العقدة من قيمة عامل التشغيل ضمن النطاق بين الحدّ الأدنى والحدّ الأقصى.
Clamp(min, operand, max)
| الوسيطات | النوع | معاني |
|---|---|---|
min |
XlaOp |
مصفوفة من النوع T |
operand |
XlaOp |
مصفوفة من النوع T |
max |
XlaOp |
مصفوفة من النوع T |
بالنظر إلى معامل وقيمتَي الحدّ الأدنى والأقصى، تعرض هذه الدالة المعامل إذا كان ضمن النطاق بين الحدّ الأدنى والأقصى، وإلا تعرض قيمة الحدّ الأدنى إذا كان المعامل أقل من هذا النطاق أو قيمة الحدّ الأقصى إذا كان المعامل أعلى من هذا النطاق. أي clamp(a, x, b) = min(max(a, x), b).
يجب أن تكون جميع المصفوفات الثلاثة بالشكل نفسه. بدلاً من ذلك، يمكن أن يكون min و/أو max عددًا قياسيًا من النوع T، وذلك كشكل مقيّد من البث.
مثال مع min وmax:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - clamp.
تصغير
يمكنك الاطّلاع أيضًا على XlaBuilder::Collapse.
وعملية tf.reshape
تدمج هذه الدالة أبعاد الصفيف في بُعد واحد.
Collapse(operand, dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T |
dimensions |
int64 متّجه |
مجموعة فرعية متسلسلة ومرتّبة من سمات T |
يستبدل الدمج المجموعة الفرعية المحدّدة من أبعاد العنصر الذي يتم إجراء العملية عليه ببعد واحد. وسيطات الإدخال هي مصفوفة عشوائية من النوع T ومتجه ثابت لوقت الترجمة لفهارس الأبعاد. يجب أن تكون فهارس الأبعاد مجموعة فرعية متسلسلة من أبعاد T (من أصغر رقم إلى أكبر رقم). وبالتالي، فإنّ {0, 1, 2} أو {0, 1} أو {1, 2} هي مجموعات أبعاد صالحة، ولكنّ {1, 0} أو {0, 2} غير صالحة. يتم استبدالها ببعد جديد واحد، في الموضع نفسه في تسلسل الأبعاد الذي تم استبداله، ويكون حجم البعد الجديد مساويًا لناتج أحجام الأبعاد الأصلية. إنّ أصغر رقم بعد في dimensions هو البعد الأبطأ تغيرًا (الأكثر أهمية) في مجموعة الحلقات التي تدمج هذه الأبعاد، وأكبر رقم بعد هو الأسرع تغيرًا (الأقل أهمية). راجِع عامل التشغيل tf.reshape إذا كانت هناك حاجة إلى ترتيب دمج أكثر عمومية.
على سبيل المثال، لنفترض أنّ v هي مصفوفة من 24 عنصرًا:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
Clz
يمكنك الاطّلاع أيضًا على XlaBuilder::Clz.
تحسب هذه الدالة عدد الأصفار البادئة على مستوى كل عنصر.
Clz(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
CollectiveBroadcast
يمكنك الاطّلاع أيضًا على XlaBuilder::CollectiveBroadcast.
يبث البيانات على جميع النسخ المتماثلة. يتم إرسال البيانات من المعرّف الأول للنسخة المتطابقة في كل مجموعة إلى المعرّفات الأخرى في المجموعة نفسها. إذا لم يكن معرّف النسخة المتماثلة في أي مجموعة نسخ متماثلة، سيكون الناتج على تلك النسخة المتماثلة عبارة عن موتر يتألف من أصفار في shape.
CollectiveBroadcast(operand, replica_groups, channel_id)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
replica_groups
|
ReplicaGroupvector
|
تحتوي كل مجموعة على قائمة بمعرّفات النسخ المتماثلة. |
channel_id
|
اختياري ChannelHandle
|
معرّف فريد لكل زوج إرسال/استلام |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - collective_broadcast.
CollectivePermute
يمكنك الاطّلاع أيضًا على XlaBuilder::CollectivePermute.
CollectivePermute هي عملية جماعية ترسل البيانات وتتلقّاها على مستوى النسخ المتماثلة.
CollectivePermute(operand, source_target_pairs, channel_id)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة إدخال ذات n أبعاد |
source_target_pairs
|
<int64, int64> متّجه
|
قائمة بأزواج (source_replica_id وtarget_replica_id). بالنسبة إلى كل زوج، يتم إرسال المعامِل من النسخة المتماثلة المصدر إلى النسخة المتماثلة الهدف. |
channel_id
|
اختياري ChannelHandle
|
معرّف قناة اختياري للتواصل بين الوحدات |
يُرجى العِلم أنّ هناك القيود التالية على source_target_pairs:
- يجب ألا يتضمّن أي زوجَين معرّف نسخة طبق الأصل مستهدَفة نفسه، ويجب ألا يتضمّنا معرّف نسخة طبق الأصل مصدر نفسه.
- إذا لم يكن معرّف النسخة المتماثلة هدفًا في أي زوج، يكون الناتج على تلك النسخة المتماثلة موترًا يتألف من أصفار بالشكل نفسه الذي يتخذه الإدخال.
يتم تقسيم واجهة برمجة التطبيقات لعملية CollectivePermute داخليًا إلى تعليمتَين من لغة HLO (CollectivePermuteStart وCollectivePermuteDone).
يمكنك الاطّلاع أيضًا على HloInstruction::CreateCollectivePermuteStart.
تعمل CollectivePermuteStart وCollectivePermuteDone كعناصر أساسية في HLO.
قد تظهر هذه العمليات في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - collective_permute.
مقارنة
يمكنك الاطّلاع أيضًا على XlaBuilder::Compare.
تُجري مقارنة بين عناصر lhs وrhs في ما يلي:
Eq
يمكنك الاطّلاع أيضًا على XlaBuilder::Eq.
تُجري هذه الدالة مقارنة يساوي بين عناصر lhs وrhs.
\(lhs = rhs\)
Eq(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر خيار بديل يتوافق مع البث بأبعاد مختلفة للمعادلة:
Eq(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
يتم توفير ترتيب إجمالي للأعداد العشرية في Eq، وذلك من خلال فرض ما يلي:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
EqTotalOrder(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - مقارنة.
Ne
يمكنك الاطّلاع أيضًا على XlaBuilder::Ne.
تُجري هذه الدالة مقارنة عدم تساوي بين عناصر lhs وrhs.
\(lhs != rhs\)
Ne(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر إصدار بديل من Ne يتيح البث بأبعاد مختلفة:
Ne(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
يجب أن يكون هناك دعم لإجمالي الطلب الذي يتجاوز الأعداد العشرية العائمة في Ne، وذلك من خلال فرض ما يلي:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
NeTotalOrder(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - مقارنة.
Ge
يمكنك الاطّلاع أيضًا على XlaBuilder::Ge.
تُجري هذه الدالة مقارنة greater-or-equal-than بين عناصر lhs وrhs.
\(lhs >= rhs\)
Ge(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر إصدار بديل يتوافق مع البث بأبعاد مختلفة لـ Ge:
Ge(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
يتوفّر دعم لإجمالي الطلب على أرقام النقطة العائمة في Gt، وذلك من خلال فرض ما يلي:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
GtTotalOrder(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - مقارنة.
Gt
يمكنك الاطّلاع أيضًا على XlaBuilder::Gt.
تُجري هذه الدالة مقارنة أكبر من بين lhs وrhs على مستوى العناصر.
\(lhs > rhs\)
Gt(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل مع إمكانية البث بأبعاد مختلفة لـ Gt:
Gt(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - مقارنة.
Le
يمكنك الاطّلاع أيضًا على XlaBuilder::Le.
تُجري مقارنة less-or-equal-than على مستوى العناصر بين lhs وrhs.
\(lhs <= rhs\)
Le(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بالشكل الناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر إصدار بديل من Le يتوافق مع البث بأبعاد مختلفة:
Le(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
يجب أن يتوفّر دعم لإجمالي الطلب الذي يتجاوز أرقام النقطة العائمة في Le، وذلك من خلال فرض ما يلي:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LeTotalOrder(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - مقارنة.
Lt
يمكنك الاطّلاع أيضًا على XlaBuilder::Lt.
تُجري هذه الدالة مقارنة أصغر من على مستوى العناصر بين lhs وrhs.
\(lhs < rhs\)
Lt(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر صيغة بديلة تتوافق مع البث بأبعاد مختلفة لـ Lt:
Lt(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
يتم توفير إجمالي الطلب على الأرقام العشرية في Lt، وذلك من خلال فرض ما يلي:
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LtTotalOrder(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - مقارنة.
متقدّم
يمكنك الاطّلاع أيضًا على XlaBuilder::Complex.
تُجري هذه الدالة عملية تحويل على مستوى كل عنصر إلى قيمة مركّبة من زوج من القيم الحقيقية والتخيّلية، lhs وrhs.
Complex(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل مع إمكانية البث بأبعاد مختلفة للنوع Complex:
Complex(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - complex.
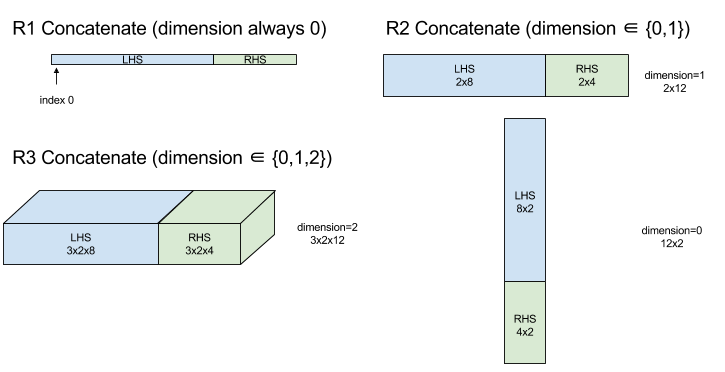
ConcatInDim (دمج)
يمكنك الاطّلاع أيضًا على XlaBuilder::ConcatInDim.
تنشئ الدالة Concatenate مصفوفة من معاملات مصفوفة متعددة. تحتوي المصفوفة على عدد الأبعاد نفسه لكل من معاملات مصفوفة الإدخال (التي يجب أن تحتوي على عدد الأبعاد نفسه لكل منها) وتحتوي على الوسيطات بالترتيب الذي تم تحديده.
Concatenate(operands..., dimension)
| الوسيطات | النوع | معاني |
|---|---|---|
operands
|
تسلسل N XlaOp
|
مصفوفات N من النوع T بالأبعاد [L0, L1, ...]. يجب أن يكون N >= 1. |
dimension
|
int64
|
قيمة في الفاصل الزمني [0, N) تحدّد اسم السمة المطلوب ربطها
بين operands. |
باستثناء dimension، يجب أن تكون جميع السمات متطابقة، لأنّ XLA لا يتيح استخدام مصفوفات "غير منتظمة". يُرجى أيضًا العِلم أنّه لا يمكن ربط القيم ذات البُعد 0 (لأنّه من المستحيل تسمية السمة التي يتم الربط على أساسها).
مثال أحادي الأبعاد:
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
//Output: {2, 3, 4, 5, 6, 7}
مثال ثنائي الأبعاد:
let a = { {1, 2},
{3, 4},
{5, 6} };
let b = { {7, 8} };
Concat({a, b}, 0)
//Output: { {1, 2},
// {3, 4},
// {5, 6},
// {7, 8} }
الرسم البياني:
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - concatenate.
الجملة الشرطية
يمكنك الاطّلاع أيضًا على XlaBuilder::Conditional.
Conditional(predicate, true_operand, true_computation, false_operand,
false_computation)
| الوسيطات | النوع | معاني |
|---|---|---|
predicate |
XlaOp |
قيمة عددية من النوع PRED |
true_operand |
XlaOp |
وسيطة من النوع \(T_0\) |
true_computation |
XlaComputation |
XlaComputation of type \(T_0 \to S\) |
false_operand |
XlaOp |
وسيطة من النوع \(T_1\) |
false_computation |
XlaComputation |
XlaComputation of type \(T_1 \to S\) |
تنفيذ true_computation إذا كانت predicate هي true، وتنفيذ false_computation إذا كانت predicate هي false، وعرض النتيجة
يجب أن يقبل true_computation وسيطًا واحدًا من النوع \(T_0\) ، وسيتم استدعاؤه باستخدام true_operand الذي يجب أن يكون من النوع نفسه. يجب أن يقبل false_computation وسيطًا واحدًا من النوع \(T_1\) ، وسيتم استدعاؤه باستخدام false_operand الذي يجب أن يكون من النوع نفسه. يجب أن يكون نوع القيمة المعروضة لكل من true_computation وfalse_computation هو نفسه.
يُرجى العِلم أنّه سيتم تنفيذ إحدى القيمتين true_computation وfalse_computation فقط استنادًا إلى قيمة predicate.
Conditional(branch_index, branch_computations, branch_operands)
| الوسيطات | النوع | معاني |
|---|---|---|
branch_index |
XlaOp |
قيمة عددية من النوع S32 |
branch_computations |
تسلسل N XlaComputation |
XlaComputations من النوع \(T_0 \to S , T_1 \to S , ..., T_{N-1} \to S\) |
branch_operands |
تسلسل N XlaOp |
وسيطات من النوع \(T_0 , T_1 , ..., T_{N-1}\) |
ينفّذ branch_computations[branch_index] ويعرض النتيجة. إذا كان
branch_index عبارة عن S32 أصغر من 0 أو أكبر من أو يساوي N، يتم تنفيذ branch_computations[N-1]
كفرع تلقائي.
يجب أن تقبل كل branch_computations[b] وسيطة واحدة من النوع \(T_b\) ، وسيتم استدعاؤها باستخدام branch_operands[b] الذي يجب أن يكون من النوع نفسه. يجب أن يكون نوع القيمة المعروضة لكل branch_computations[b] هو نفسه.
يُرجى العِلم أنّه سيتم تنفيذ أحد الإجراءَين branch_computations فقط استنادًا إلى قيمة branch_index.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - if.
ثابت
يمكنك الاطّلاع أيضًا على XlaBuilder::ConstantLiteral.
تُنشئ هذه الدالة output من قيمة ثابتة literal.
Constant(literal)
| الوسيطات | النوع | معاني |
|---|---|---|
literal |
LiteralSlice |
عرض ثابت لـ Literal حالي |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - ثابت.
ConvertElementType
يمكنك الاطّلاع أيضًا على XlaBuilder::ConvertElementType.
على غرار static_cast على مستوى العناصر في C++، تنفّذ ConvertElementType عملية تحويل على مستوى العناصر من شكل بيانات إلى شكل مستهدف. يجب أن تتطابق الأبعاد، وأن يكون التحويل على مستوى العناصر، على سبيل المثال، تصبح عناصر s32 عناصر f32 من خلال روتين تحويل من s32 إلى f32.
ConvertElementType(operand, new_element_type)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T ذات الأبعاد D |
new_element_type |
PrimitiveType |
النوع U |
يجب أن تتطابق أبعاد المعامِل وشكل الهدف. يجب ألا تكون أنواع عناصر المصدر والوجهة عبارة عن مجموعات.
ستنفّذ عملية تحويل، مثل T=s32 إلى U=f32، روتين تحويل عادي من عدد صحيح إلى عدد عشري، مثل التقريب إلى أقرب عدد زوجي.
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
لمزيد من المعلومات عن StableHLO، يُرجى الاطّلاع على StableHLO - convert.
الالتفاف (Convolution)
يمكنك الاطّلاع أيضًا على XlaBuilder::Conv.
تحسب هذه الدالة التفافًا من النوع المستخدَم في الشبكات العصبونية، حيث يمكن اعتبار التفاف نافذة ذات n بعد تتحرك عبر مساحة أساسية ذات n بعد، ويتم إجراء عملية حسابية لكل موضع ممكن للنافذة.
Conv يتم وضع تعليمات الالتفاف في قائمة الانتظار ضمن عملية الحساب، والتي تستخدم أرقام أبعاد الالتفاف التلقائية بدون تمديد.
يتم تحديد المساحة المتروكة بطريقة مختصرة على النحو التالي: SAME أو VALID. تضيف عملية التعبئة SAME أصفارًا إلى الإدخال (lhs) ليكون شكل الإخراج مماثلاً لشكل الإدخال عند عدم أخذ الخطوات في الاعتبار. تعني المساحة المتروكة الصالحة ببساطة
عدم وجود مساحة متروكة.
Conv(lhs, rhs, window_strides, padding, feature_group_count,
batch_group_count, precision_config, preferred_element_type)
| الوسيطات | النوع | معاني |
|---|---|---|
lhs
|
XlaOp
|
مصفوفة إدخالات ذات (n+2) بُعد |
rhs
|
XlaOp
|
مصفوفة (n+2) ذات أبعاد لأوزان النواة |
window_strides |
ArraySlice<int64> |
مصفوفة n-d لخطوات النواة |
padding |
Padding |
تعداد المساحة المتروكة |
feature_group_count
|
int64 | عدد مجموعات الميزات |
batch_group_count |
int64 | عدد مجموعات الدفعات |
precision_config
|
اختياري
PrecisionConfig |
تعداد لمستوى الدقّة |
preferred_element_type
|
اختياري
PrimitiveType |
تعداد نوع العنصر العددي |
تتوفّر مستويات متزايدة من عناصر التحكّم في Conv:
ليكن n هو عدد الأبعاد المكانية. الوسيطة lhs هي مصفوفة ذات (n+2) بُعد تصف المساحة الأساسية. يُطلق على هذا الاسم "الإدخال"،
مع أنّ الجانب الأيسر هو أيضًا إدخال. في الشبكة العصبية، تكون هذه القيم هي عمليات التفعيل المدخلة. السمات n+2 هي، بهذا الترتيب:
batch: يمثّل كل إحداثي في هذا البُعد إدخالاً مستقلاً يتم إجراء الالتفاف له.z/depth/features: لكل موضع (y,x) في المساحة الأساسية متّجه مرتبط به، ويتم إدخاله في هذه السمة.-
spatial_dims: تصف هذه السمة الأبعاد المكانيةnالتي تحدّد المساحة الأساسية التي تتحرّك النافذة عليها.
وسيطة rhs هي مصفوفة (n+2) ذات أبعاد تصف فلتر/نواة/نافذة الالتفاف. وتكون الأبعاد بالترتيب التالي:
output-z: تمثّل هذه السمةzالخاصة بالناتج.input-z: يجب أن يساوي حجم هذه السمة مضروبًا فيfeature_group_countحجم السمةzفي الجانب الأيسر.-
spatial_dims: تصف هذه السمة الأبعاد المكانيةnالتي تحدّد النافذة ذات الأبعاد n التي تتحرّك في جميع أنحاء المساحة الأساسية.
تحدّد الوسيطة window_strides خطوة النافذة الالتفافية في الأبعاد المكانية. على سبيل المثال، إذا كانت الخطوة في البُعد المكاني الأول هي 3، لا يمكن وضع النافذة إلا في الإحداثيات التي يكون فيها الفهرس المكاني الأول قابلاً للقسمة على 3.
تحدّد الوسيطة padding مقدار التعبئة بالأصفار التي سيتم تطبيقها على المساحة الأساسية. يمكن أن تكون قيمة المساحة المتروكة سالبة، وتشير القيمة المطلقة للمساحة المتروكة السالبة إلى عدد العناصر التي يجب إزالتها من البُعد المحدّد قبل إجراء الالتفاف. تحدّد padding[0] مساحة الحشو للسمة y، وتحدّد padding[1] مساحة الحشو للسمة x. يحتوي كل زوج على مساحة الحشو المنخفضة كعنصر أول ومساحة الحشو العالية كعنصر ثانٍ. يتم تطبيق المساحة المتروكة المنخفضة في اتجاه الفهارس المنخفضة، بينما يتم تطبيق المساحة المتروكة العالية في اتجاه الفهارس العالية. على سبيل المثال، إذا كانت قيمة padding[1] هي (2,3)، سيتم إضافة مساحة فارغة تتضمّن صفرَين على اليسار وثلاثة أصفار على اليمين في البُعد المكاني الثاني. استخدام الحشو
يعادل إدراج قيم الأصفار نفسها في الإدخال (lhs) قبل
إجراء الالتفاف.
تحدّد الوسيطتان lhs_dilation وrhs_dilation عامل التمدّد الذي سيتم تطبيقه على الجانب الأيسر والجانب الأيمن، على التوالي، في كل بُعد مكاني. إذا كان عامل التمدّد في بُعد مكاني هو d، سيتم ضمنيًا وضع d-1 ثقب بين كل إدخال في هذا البُعد، ما يؤدي إلى زيادة حجم المصفوفة. يتم ملء الثقوب بقيمة لا تؤدي إلى أي عملية، ما يعني أصفارًا في عملية الالتفاف.
يُطلق على تمديد الجانب الأيمن أيضًا اسم الالتفاف الثقوبي. لمزيد من التفاصيل، يمكنك الاطّلاع على tf.nn.atrous_conv2d. يُطلق على تمديد الجانب الأيسر أيضًا اسم الالتفاف المحوّل. لمزيد من التفاصيل، يمكنك الاطّلاع على tf.nn.conv2d_transpose.
يمكن استخدام وسيطة feature_group_count (القيمة التلقائية 1) لعمليات الالتفاف المجمّعة. يجب أن يكون feature_group_count عاملاً مشتركًا لكل من أبعاد الميزات المدخلة والمخرَجة. إذا كانت قيمة feature_group_count أكبر من 1، يعني ذلك أنّه يتم تقسيم بُعد ميزة الإدخال والإخراج وبُعد ميزة الإخراج rhs بالتساوي إلى العديد من المجموعات feature_group_count، وتتألف كل مجموعة من تسلسل فرعي متتالٍ من الميزات. يجب أن يكون بُعد ميزة الإدخال rhs مساويًا لبُعد ميزة الإدخال lhs مقسومًا على feature_group_count (وبالتالي، يجب أن يكون له حجم مجموعة من ميزات الإدخال). يتم استخدام المجموعات ذات الترتيب i معًا لاحتساب
feature_group_count للعديد من عمليات الالتفاف المنفصلة. يتم ربط نتائج هذه الالتفافات معًا في سمة الإخراج.
بالنسبة إلى الالتفاف العميق، سيتم ضبط وسيطة feature_group_count على بُعد ميزة الإدخال، وستتم إعادة تشكيل الفلتر من [filter_height, filter_width, in_channels, channel_multiplier] إلى [filter_height, filter_width, 1, in_channels * channel_multiplier]. لمزيد من التفاصيل، يُرجى الاطّلاع على tf.nn.depthwise_conv2d.
يمكن استخدام وسيطة batch_group_count (القيمة التلقائية 1) للفلاتر المجمّعة أثناء الانتشار العكسي. يجب أن يكون batch_group_count أحد قواسم حجم سمة الدفعة lhs (الإدخال). إذا كانت قيمة batch_group_count أكبر من 1، يعني ذلك أنّ حجم مجموعة النتائج يجب أن يكون input batch
/ batch_group_count. يجب أن يكون batch_group_count عاملاً من عوامل حجم الميزة الناتج.
يتضمّن شكل الإخراج الأبعاد التالية، بهذا الترتيب:
-
batch: يجب أن يساوي حجم هذه السمة مضروبًا فيbatch_group_countحجم السمةbatchفي الجانب الأيسر. -
z: نفس حجمoutput-zعلى النواة (rhs) -
spatial_dims: قيمة واحدة لكل موضع صالح لنافذة الالتفاف.

يوضّح الشكل أعلاه طريقة عمل الحقل batch_group_count. في الواقع، نقسّم كل مجموعة من الجانب الأيسر إلى batch_group_count مجموعات، ونفعل الشيء نفسه مع ميزات الإخراج. بعد ذلك، نجري عمليات التفاف زوجية لكل مجموعة من هذه المجموعات
ونربط الناتج على طول بُعد ميزة الناتج. ستظل الدلالات التشغيلية لجميع السمات الأخرى (الميزات والمساحة) كما هي.
يتم تحديد مواضع النافذة الالتفافية الصالحة من خلال الخطوات وحجم المساحة الأساسية بعد إضافة المساحة المتروكة.
لوصف ما تفعله عملية الالتفاف، لنأخذ عملية التفاف ثنائية الأبعاد، ونختار بعض الإحداثيات الثابتة batch وz وy وx في الناتج. بعد ذلك، (y,x) هو موضع أحد أركان النافذة ضمن المساحة الأساسية (مثل الركن الأيمن العلوي، حسب طريقة تفسير الأبعاد المكانية). لدينا الآن نافذة ثنائية الأبعاد، مأخوذة من المساحة الأساسية، حيث يرتبط كل موضع ثنائي الأبعاد بمتّجه أحادي الأبعاد، وبالتالي نحصل على مربّع ثلاثي الأبعاد. من نواة الالتفاف، وبما أنّنا ثبّتنا إحداثيات الناتج z، نحصل أيضًا على مربّع ثلاثي الأبعاد. يتشارك المربّعان الأبعاد نفسها، لذا يمكننا أخذ مجموع المنتجات على مستوى العناصر بين المربّعين (على غرار الضرب النقطي). هذه هي قيمة الناتج.
يُرجى العِلم أنّه إذا كانت قيمة output-z هي 5 مثلاً، سيؤدي كل موضع في النافذة إلى إنشاء 5 قيم في الناتج ضمن السمة z. وتختلف هذه القيم في الجزء المستخدَم من نواة الالتفاف، إذ يتم استخدام مربّع ثلاثي الأبعاد منفصل من القيم لكل إحداثي output-z. وبالتالي، يمكنك اعتبارها 5 عمليات التفاف منفصلة مع فلتر مختلف لكل منها.
في ما يلي رمز زائف لالتفاف ثنائي الأبعاد مع الحشو والخطوات:
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
يُستخدَم precision_config للإشارة إلى إعدادات الدقة. يحدّد المستوى ما إذا كان يجب أن تحاول الأجهزة إنشاء المزيد من تعليمات لغة الآلة لتوفير محاكاة أكثر دقة لنوع البيانات عند الحاجة (أي محاكاة f32 على وحدة معالجة الموتّرات التي لا تتوافق إلا مع عمليات ضرب المصفوفات bf16). يمكن أن تكون القيم
DEFAULT أو HIGH أو HIGHEST. تفاصيل إضافية
في أقسام MXU
preferred_element_type هو عنصر عددي من أنواع الإخراج ذات الدقة الأعلى/الأدنى المستخدَمة للتراكم. تنصح preferred_element_type باستخدام نوع التجميع للعملية المحدّدة، ولكن ليس مضمونًا أن يكون متاحًا. يتيح ذلك لبعض برامج الخلفية للأجهزة تجميع البيانات بدلاً من ذلك في نوع مختلف وتحويلها إلى نوع الإخراج المفضّل.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - الالتفاف.
ConvWithGeneralPadding
يمكنك الاطّلاع أيضًا على XlaBuilder::ConvWithGeneralPadding.
ConvWithGeneralPadding(lhs, rhs, window_strides, padding,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
هي نفسها Conv حيث يكون إعداد المساحة المتروكة صريحًا.
| الوسيطات | النوع | معاني |
|---|---|---|
lhs
|
XlaOp
|
مصفوفة إدخالات ذات (n+2) بُعد |
rhs
|
XlaOp
|
مصفوفة (n+2) ذات أبعاد لأوزان النواة |
window_strides |
ArraySlice<int64> |
مصفوفة n-d لخطوات النواة |
padding
|
ArraySlice<
pair<int64,int64>> |
مصفوفة n-d من (منخفض، مرتفع) حشو |
feature_group_count
|
int64 | عدد مجموعات الميزات |
batch_group_count |
int64 | عدد مجموعات الدفعات |
precision_config
|
اختياري
PrecisionConfig |
تعداد لمستوى الدقّة |
preferred_element_type
|
اختياري
PrimitiveType |
تعداد نوع العنصر العددي |
ConvWithGeneralDimensions
يمكنك الاطّلاع أيضًا على XlaBuilder::ConvWithGeneralDimensions.
ConvWithGeneralDimensions(lhs, rhs, window_strides, padding,
dimension_numbers, feature_group_count, batch_group_count, precision_config,
preferred_element_type)
هي نفسها Conv حيث تكون أرقام السمات واضحة.
| الوسيطات | النوع | معاني |
|---|---|---|
lhs
|
XlaOp
|
مصفوفة إدخالات ذات (n+2) بُعد |
rhs
|
XlaOp
|
مصفوفة أوزان النواة ذات (n+2) بُعد |
window_strides
|
ArraySlice<int64>
|
مصفوفة n-d لخطوات النواة |
padding |
Padding |
تعداد المساحة المتروكة |
dimension_numbers
|
ConvolutionDimensionNumbers
|
عدد السمات |
feature_group_count
|
int64 | عدد مجموعات الميزات |
batch_group_count
|
int64 | عدد مجموعات الدفعات |
precision_config
|
اختياري PrecisionConfig
|
تعداد لمستوى الدقة |
preferred_element_type
|
اختياري PrimitiveType
|
تعداد لنوع العنصر العددي |
ConvGeneral
يمكنك الاطّلاع أيضًا على XlaBuilder::ConvGeneral.
ConvGeneral(lhs, rhs, window_strides, padding, dimension_numbers,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
كما هو الحال في Conv حيث تكون أرقام السمات وإعدادات المساحة المتروكة
واضحة
| الوسيطات | النوع | معاني |
|---|---|---|
lhs
|
XlaOp
|
مصفوفة إدخالات ذات (n+2) بُعد |
rhs
|
XlaOp
|
مصفوفة أوزان النواة ذات (n+2) بُعد |
window_strides
|
ArraySlice<int64>
|
مصفوفة n-d لخطوات النواة |
padding
|
ArraySlice<
pair<int64,int64>>
|
مصفوفة n-d من (low, high) padding |
dimension_numbers
|
ConvolutionDimensionNumbers
|
عدد السمات |
feature_group_count
|
int64 | عدد مجموعات الميزات |
batch_group_count
|
int64 | عدد مجموعات الدفعات |
precision_config
|
اختياري PrecisionConfig
|
تعداد لمستوى الدقة |
preferred_element_type
|
اختياري PrimitiveType
|
تعداد لنوع العنصر العددي |
ConvGeneralDilated
يمكنك الاطّلاع أيضًا على XlaBuilder::ConvGeneralDilated.
ConvGeneralDilated(lhs, rhs, window_strides, padding, lhs_dilation,
rhs_dilation, dimension_numbers, feature_group_count, batch_group_count,
precision_config, preferred_element_type, window_reversal)
كما هو الحال مع Conv، حيث تكون إعدادات المساحة المتروكة وعوامل التمدد وأرقام الأبعاد واضحة.
| الوسيطات | النوع | معاني |
|---|---|---|
lhs
|
XlaOp
|
مصفوفة إدخالات ذات (n+2) بُعد |
rhs
|
XlaOp
|
مصفوفة أوزان النواة ذات (n+2) بُعد |
window_strides
|
ArraySlice<int64>
|
مصفوفة n-d لخطوات النواة |
padding
|
ArraySlice<
pair<int64,int64>>
|
مصفوفة n-d من (low, high) padding |
lhs_dilation
|
ArraySlice<int64>
|
مصفوفة عوامل التمدد في الجانب الأيسر من المعادلة (n-d) |
rhs_dilation
|
ArraySlice<int64>
|
n-d rhs dilation factor array |
dimension_numbers
|
ConvolutionDimensionNumbers
|
عدد السمات |
feature_group_count
|
int64 | عدد مجموعات الميزات |
batch_group_count
|
int64 | عدد مجموعات الدفعات |
precision_config
|
اختياري PrecisionConfig
|
تعداد لمستوى الدقة |
preferred_element_type
|
اختياري PrimitiveType
|
تعداد لنوع العنصر العددي |
window_reversal
|
اختياري vector<bool>
|
علامة تُستخدَم لعكس ترتيب الأبعاد منطقيًا قبل تطبيق الالتفاف |
نسخ
يمكنك الاطّلاع أيضًا على HloInstruction::CreateCopyStart.
يتم تقسيم Copy داخليًا إلى تعليمتَي HLO، وهما CopyStart وCopyDone. وتُستخدَم Copy مع CopyStart وCopyDone كعناصر أساسية في HLO. وقد تظهر هذه العمليات في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
Cos
يمكنك الاطّلاع أيضًا علىXlaBuilder::Cos.
جيب التمام العنصري x -> cos(x)
Cos(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Cos أيضًا استخدام الوسيطة الاختيارية result_accuracy:
Cos(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - cosine.
Cosh
يمكنك الاطّلاع أيضًا على XlaBuilder::Cosh.
جيب التمام الزائدي لكل عنصر x -> cosh(x)
Cosh(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة cosh أيضًا الوسيطة الاختيارية result_accuracy:
Cosh(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
CustomCall
يمكنك الاطّلاع أيضًا على XlaBuilder::CustomCall.
استدعاء دالة يقدّمها المستخدم ضمن عملية حسابية
تتوفّر مستندات CustomCall في تفاصيل المطوّر - مكالمات XLA المخصّصة
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - custom_call.
درجة
يمكنك الاطّلاع أيضًا على XlaBuilder::Div.
تُجري هذه الدالة عملية قسمة كل عنصر على حدة بين المقسوم lhs والمقسوم عليه rhs.
Div(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يؤدي تجاوز سعة قسمة عدد صحيح (قسمة/باقي عدد صحيح أو غير صحيح على صفر أو قسمة/باقي عدد صحيح
INT_SMIN على -1) إلى إنتاج قيمة محددة التنفيذ.
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بالشكل الناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر متغير بديل مع إمكانية البث بأبعاد مختلفة للدالة Div:
Div(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - divide.
النطاق
يمكنك الاطّلاع أيضًا على HloInstruction::CreateDomain.
قد يظهر Domain في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئه المستخدمون النهائيون يدويًا.
نقطة
يمكنك الاطّلاع أيضًا على XlaBuilder::Dot.
Dot(lhs, rhs, precision_config, preferred_element_type)
| الوسيطات | النوع | معاني |
|---|---|---|
lhs |
XlaOp |
مصفوفة من النوع T |
rhs |
XlaOp |
مصفوفة من النوع T |
precision_config
|
اختياري
PrecisionConfig |
تعداد لمستوى الدقّة |
preferred_element_type
|
اختياري
PrimitiveType |
تعداد نوع العنصر العددي |
تعتمد الدلالات الدقيقة لهذه العملية على ترتيب المعامِلات:
| الإدخال | الناتج | معاني |
|---|---|---|
المتّجه [n] dot المتّجه [n] |
الكمية القياسية | الجداء النقطي للمتجه |
المصفوفة [m x k] dot المتجه
[k] |
المتّجه [م] | ضرب المصفوفة في المتّجه |
المصفوفة [m x k] dot المصفوفة [k x n] |
المصفوفة [m x n] | ضرب المصفوفات |
تُجري العملية مجموع المنتجات على مستوى السمة الثانية من lhs (أو السمة الأولى إذا كانت تتضمّن سمة واحدة) والسمة الأولى من rhs. هذه هي السمات "المختصرة". يجب أن يكون حجم السمات المختصرة في lhs وrhs متساويًا. ويمكن استخدامها في الواقع لإجراء عمليات الضرب النقطي بين المتجهات أو عمليات ضرب المتجهات/المصفوفات أو عمليات ضرب المصفوفات/المصفوفات.
يُستخدَم precision_config للإشارة إلى إعدادات الدقة. يحدّد المستوى ما إذا كان يجب أن تحاول الأجهزة إنشاء المزيد من تعليمات لغة الآلة لتوفير محاكاة أكثر دقة لنوع البيانات عند الحاجة (أي محاكاة f32 على وحدة معالجة الموتّرات التي لا تتوافق إلا مع عمليات ضرب المصفوفات bf16). يمكن أن تكون القيم
DEFAULT أو HIGH أو HIGHEST. تفاصيل إضافية
في أقسام MXU
preferred_element_type هو عنصر عددي من أنواع الإخراج ذات الدقة الأعلى/الأدنى المستخدَمة للتراكم. تنصح preferred_element_type باستخدام نوع التجميع للعملية المحدّدة، ولكن ليس مضمونًا أن يكون متاحًا. يتيح ذلك لبعض برامج الخلفية للأجهزة تجميع البيانات بدلاً من ذلك في نوع مختلف وتحويلها إلى نوع الإخراج المفضّل.
للحصول على معلومات عن StableHLO، يُرجى الاطّلاع على StableHLO - dot.
DotGeneral
يمكنك الاطّلاع أيضًا على XlaBuilder::DotGeneral.
DotGeneral(lhs, rhs, dimension_numbers, precision_config,
preferred_element_type)
| الوسيطات | النوع | معاني |
|---|---|---|
lhs |
XlaOp |
مصفوفة من النوع T |
rhs |
XlaOp |
مصفوفة من النوع T |
dimension_numbers
|
DotDimensionNumbers
|
أرقام الأبعاد الخاصة بالتعاقدات والدفعات |
precision_config
|
اختياري
PrecisionConfig |
تعداد لمستوى الدقة |
preferred_element_type
|
اختياري
PrimitiveType |
تعداد لنوع العنصر القياسي |
تشبه هذه السمة Dot، ولكنّها تتيح تحديد أرقام الأبعاد المجمّعة والمختصرة لكل من lhs وrhs.
| حقول DotDimensionNumbers | النوع | معاني |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | أرقام سمات lhs التعاقد |
rhs_contracting_dimensions
|
repeated int64 | أرقام سمات rhs التعاقد |
lhs_batch_dimensions
|
repeated int64 | lhs أرقام سمات الدُفعات |
rhs_batch_dimensions
|
repeated int64 | rhs أرقام سمات الدُفعات |
تُجري DotGeneral مجموع المنتجات على السمات المتناقصة المحدّدة في
dimension_numbers.
ليس من الضروري أن تتطابق أرقام سمات التعاقد المرتبطة من lhs وrhs، ولكن يجب أن تتطابق أحجام السمات.
مثال يتضمّن أرقام سمات التعاقد:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { { 6.0, 12.0},
{15.0, 30.0} }
يجب أن تتطابق أحجام سمات الدُفعات المرتبطة من lhs وrhs.
مثال مع أرقام سمات الدُفعات (حجم الدفعة 2، مصفوفات 2x2):
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> {
{ {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| الإدخال | الناتج | معاني |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | batch matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | batch matmul |
ويترتّب على ذلك أنّ رقم السمة الناتج يبدأ بسمة الدفعة، ثم السمة lhs غير التعاقدية/غير الدفعية، وأخيرًا السمة rhs غير التعاقدية/غير الدفعية.
يُستخدَم precision_config للإشارة إلى إعدادات الدقة. يحدّد المستوى ما إذا كان يجب أن تحاول الأجهزة إنشاء المزيد من تعليمات لغة الآلة لتوفير محاكاة أكثر دقة لنوع البيانات عند الحاجة (أي محاكاة f32 على وحدة معالجة الموتّرات التي لا تتوافق إلا مع عمليات ضرب المصفوفات bf16). يمكن أن تكون القيم
DEFAULT أو HIGH أو HIGHEST. يمكنك الاطّلاع على تفاصيل إضافية في أقسام MXU.
preferred_element_type هو عنصر عددي من أنواع الإخراج ذات الدقة الأعلى/الأدنى المستخدَمة للتراكم. تنصح preferred_element_type باستخدام نوع التجميع للعملية المحدّدة، ولكن ليس مضمونًا أن يكون متاحًا. يتيح ذلك لبعض برامج الخلفية للأجهزة تجميع البيانات بدلاً من ذلك في نوع مختلف وتحويلها إلى نوع الإخراج المفضّل.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - dot_general.
ScaledDot
يمكنك الاطّلاع أيضًا على XlaBuilder::ScaledDot.
ScaledDot(lhs, lhs_scale, rhs, rhs_scale, dimension_number,
precision_config,preferred_element_type)
| الوسيطات | النوع | معاني |
|---|---|---|
lhs |
XlaOp |
مصفوفة من النوع T |
rhs |
XlaOp |
مصفوفة من النوع T |
lhs_scale |
XlaOp |
مصفوفة من النوع T |
rhs_scale |
XlaOp |
مصفوفة من النوع T |
dimension_number
|
ScatterDimensionNumbers
|
أرقام السمات لعملية التشتيت |
precision_config
|
PrecisionConfig
|
تعداد لمستوى الدقة |
preferred_element_type
|
اختياري PrimitiveType
|
تعداد لنوع العنصر العددي |
مشابه لـ DotGeneral.
تُنشئ هذه الدالة عملية ضرب نقطي موسّعة مع المعامِلات lhs وlhs_scale وrhs وrhs_scale، مع تحديد أبعاد التجميع والدُفعات في dimension_numbers.
RaggedDot
يمكنك الاطّلاع أيضًا على XlaBuilder::RaggedDot.
للاطّلاع على تفاصيل حول عملية احتساب RaggedDot، يُرجى الرجوع إلى
StableHLO - chlo.ragged_dot.
DynamicReshape
يمكنك الاطّلاع أيضًا على XlaBuilder::DynamicReshape.
هذه العملية مطابقة وظيفيًا لعملية reshape، ولكن يتم تحديد شكل النتيجة بشكل ديناميكي من خلال output_shape.
DynamicReshape(operand, dim_sizes, new_size_bounds, dims_are_dynamic)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة N ذات أبعاد من النوع T |
dim_sizes |
متّجه XlaOP |
أحجام المتجهات ذات الأبعاد N |
new_size_bounds |
متّجه int63 |
متّجه حدود ذو N أبعاد |
dims_are_dynamic |
متّجه bool |
N dimensional dynamic dim |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - dynamic_reshape.
DynamicSlice
يمكنك الاطّلاع أيضًا على XlaBuilder::DynamicSlice.
تستخرِج DynamicSlice صفيفة فرعية من الصفيفة المدخلة في start_indices الديناميكي. يتم تمرير حجم الشريحة في كل بُعد في size_indices، الذي يحدّد نقطة النهاية لفواصل الشرائح الحصرية في كل بُعد: [البداية، البداية + الحجم). يجب أن يكون شكل start_indices أحادي الأبعاد، وأن يكون حجم البُعد مساويًا لعدد أبعاد operand.
DynamicSlice(operand, start_indices, slice_sizes)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة N ذات أبعاد من النوع T |
start_indices
|
تسلسل N XlaOp
|
قائمة تضم N عددًا صحيحًا عدديًا أصغر من 0x0A تحتوي على فهارس البداية لشريحة كل بُعد. يجب أن تكون القيمة أكبر من صفر أو تساويه. |
size_indices
|
ArraySlice<int64>
|
قائمة من N عدد صحيح تحتوي على حجم الشريحة لكل بُعد. يجب أن تكون كل قيمة أكبر من صفر، ويجب أن يكون المجموع بين قيمة البداية والحجم أقل من أو يساوي حجم البُعد لتجنُّب الالتفاف حول حجم البُعد. |
يتم احتساب فهارس الشرائح الفعّالة من خلال تطبيق عملية التحويل التالية لكل فهرس i في [1, N) قبل تنفيذ الشريحة:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - slice_sizes[i])
يضمن ذلك أن يكون الجزء المستخرَج دائمًا ضمن حدود مصفوفة المعامِلات. وإذا كان الجزء المستخرَج ضمن الحدود قبل تطبيق عملية التحويل، لن يكون للتحويل أي تأثير.
مثال أحادي الأبعاد:
let a = {0.0, 1.0, 2.0, 3.0, 4.0};
let s = {2};
DynamicSlice(a, s, {2});
// Result: {2.0, 3.0}
مثال ثنائي الأبعاد:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2});
//Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - dynamic_slice.
DynamicUpdateSlice
يمكنك الاطّلاع أيضًا على XlaBuilder::DynamicUpdateSlice.
تنشئ DynamicUpdateSlice نتيجة وهي قيمة مصفوفة الإدخال
operand، مع استبدال شريحة update في start_indices.
يحدّد شكل update شكل المصفوفة الفرعية للنتيجة التي يتم تعديلها.
يجب أن يكون شكل start_indices أحادي الأبعاد، وأن يكون حجم البُعد مساويًا لعدد أبعاد operand.
DynamicUpdateSlice(operand, update, start_indices)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة N ذات أبعاد من النوع T |
update
|
XlaOp
|
مصفوفة متعددة الأبعاد من النوع T تحتوي على تحديث الشريحة. يجب أن يكون كل بُعد من أبعاد التحديث أكبر من صفر، ويجب أن يكون start + update أقل من أو يساوي حجم المعامِل لكل بُعد لتجنُّب إنشاء فهارس تحديث خارج الحدود. |
start_indices
|
تسلسل N XlaOp
|
قائمة تضم N عددًا صحيحًا عدديًا أصغر من 0x0A تحتوي على فهارس البداية لشريحة كل بُعد. يجب أن تكون القيمة أكبر من صفر أو تساويه. |
يتم احتساب فهارس الشرائح الفعّالة من خلال تطبيق عملية التحويل التالية لكل فهرس i في [1, N) قبل تنفيذ الشريحة:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
يضمن ذلك أنّ الشريحة المعدَّلة تكون دائمًا ضمن الحدود بالنسبة إلى مصفوفة المعامِلات. وإذا كانت الشريحة ضمن الحدود قبل تطبيق عملية التحويل، لن يكون للتحويل أي تأثير.
مثال أحادي الأبعاد:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s)
// Result: {0.0, 1.0, 5.0, 6.0, 4.0}
مثال ثنائي الأبعاد:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s)
// Result:
// { {0.0, 1.0, 2.0},
// {3.0, 12.0, 13.0},
// {6.0, 14.0, 15.0},
// {9.0, 16.0, 17.0} }
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - dynamic_update_slice.
Erf
يمكنك الاطّلاع أيضًا على XlaBuilder::Erf.
دالة الخطأ على مستوى العناصر x -> erf(x) حيث:
\(\text{erf}(x) = \frac{2}{\sqrt{\pi} }\int_0^x e^{-t^2} \, dt\).
Erf(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح Erf أيضًا استخدام الوسيطة الاختيارية result_accuracy:
Erf(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
التعرض للضوء
يمكنك الاطّلاع أيضًا على XlaBuilder::Exp.
الدالة الأسية الطبيعية لكل عنصر x -> e^x
Exp(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح Exp أيضًا الوسيطة الاختيارية result_accuracy:
Exp(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات عن StableHLO، يُرجى الاطّلاع على StableHLO - exponential.
Expm1
يمكنك الاطّلاع أيضًا على XlaBuilder::Expm1.
قيمة الثابت الرياضي مطروحًا منها واحدًا x -> e^x - 1.
Expm1(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Expm1 أيضًا الوسيطة الاختيارية result_accuracy:
Expm1(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - exponential_minus_one.
Fft
يمكنك الاطّلاع أيضًا على XlaBuilder::Fft.
تنفّذ عملية XLA FFT تحويلات فورييه المباشرة والعكسية للمدخلات والمخرجات الحقيقية والمعقدة. يمكن استخدام تحويلات فورييه السريعة المتعددة الأبعاد على ما يصل إلى 3 محاور.
Fft(operand, ftt_type, fft_length)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp
|
المصفوفة التي نريد إجراء تحويل فورييه عليها. |
fft_type |
FftType |
اطّلِع على الجدول التالي لمزيد من المعلومات. |
fft_length
|
ArraySlice<int64>
|
تمثّل هذه السمة أطوال المحاور في المجال الزمني التي يتم تحويلها. هذا الإجراء ضروري بشكل خاص لعملية IRFFT من أجل تحديد الحجم المناسب للمحور الأعمق، لأنّ RFFT(fft_length=[16]) له شكل الإخراج نفسه مثل RFFT(fft_length=[17]). |
FftType |
معاني |
|---|---|
FFT |
تحويل فورييه السريع من عدد مركّب إلى عدد مركّب، ولا يتغيّر الشكل. |
IFFT |
تحويل فورييه السريع المعقّد إلى المعقّد المعكوس لم يتم تغيير الشكل. |
RFFT
|
تحويل فورييه السريع من الأعداد الحقيقية إلى الأعداد المركّبة يتم تقليل شكل المحور الأقرب إلى الداخل إلى fft_length[-1] // 2 + 1 إذا كانت fft_length[-1] قيمة غير صفرية، مع حذف الجزء المقترن المعكوس من الإشارة المحوّلة بعد تردد Nyquist. |
IRFFT
|
تحويل فورييه العكسي من الأعداد الحقيقية إلى الأعداد المركّبة (أي يأخذ أعدادًا مركّبة ويعرض أعدادًا حقيقية).
يتم توسيع شكل المحور الأقرب إلى fft_length[-1] إذا كانت قيمة fft_length[-1] غير صفرية، ما يشير إلى جزء الإشارة المحوَّلة الذي يتجاوز تردد Nyquist من المرافق العكسي للإدخالات من 1 إلى fft_length[-1] // 2 + 1. |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - fft.
تحويل فورييه السريع المتعدد الأبعاد
عند توفير أكثر من fft_length واحد، يكون ذلك مكافئًا لتطبيق سلسلة من عمليات تحويل فورييه السريع على كل محور من المحاور الداخلية. يُرجى العِلم أنّه في الحالتين real->complex وcomplex->real، يتم إجراء عملية تحويل المحور الأقرب إلى الداخل (فعليًا) أولاً (RFFT؛ آخر عملية في IRFFT)، ولهذا السبب يكون المحور الأقرب إلى الداخل هو المحور الذي يتغير حجمه. بعد ذلك، ستصبح عمليات تحويل المحاور الأخرى معقّدة->معقّدة.
تفاصيل التنفيذ
تستند عملية تحويل فورييه السريع (FFT) لوحدة المعالجة المركزية إلى TensorFFT من Eigen، بينما تستخدم عملية تحويل فورييه السريع (FFT) لوحدة معالجة الرسومات cuFFT.
الطابق
يمكنك الاطّلاع أيضًا على XlaBuilder::Floor.
الجزء الصحيح من كل عنصر x -> ⌊x⌋
Floor(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - floor.
فيوجن
يمكنك الاطّلاع أيضًا على HloInstruction::CreateFusion.
تمثّل عملية Fusion تعليمات HLO وتعمل كعنصر أساسي في HLO.
قد يظهر هذا الرمز في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئه المستخدمون النهائيون يدويًا.
جمع
تجمع عملية XLA عدة شرائح (كل شريحة في إزاحة وقت تشغيل مختلفة محتملة) من مصفوفة إدخال.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - gather.
الدلالات العامة
يُرجى الاطّلاع أيضًا على
XlaBuilder::Gather.
للحصول على وصف أكثر وضوحًا، يُرجى الاطّلاع على قسم "الوصف غير الرسمي" أدناه.
gather(operand, start_indices, dimension_numbers, slice_sizes,
indices_are_sorted)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp
|
الصفيف الذي نجمع البيانات منه. |
start_indices
|
XlaOp
|
مصفوفة تحتوي على فهارس البدء للشرائح التي نجمعها. |
dimension_numbers
|
GatherDimensionNumbers
|
السمة في
start_indices التي
تحتوي على
فهارس البدء. راجِع الوصف
التفصيلي أدناه. |
slice_sizes
|
ArraySlice<int64>
|
slice_sizes[i] هي حدود الشريحة في السمة i. |
indices_are_sorted
|
bool
|
ما إذا كان المتصل يضمن ترتيب الفهارس. |
لتسهيل الأمر، نصنّف السمات في مصفوفة الإخراج التي لا تظهر في offset_dims
على أنّها batch_dims.
المخرجات هي مصفوفة ذات batch_dims.size + offset_dims.size أبعاد.
يجب أن تكون قيمة operand.rank مساوية لمجموع offset_dims.size وcollapsed_slice_dims.size، كما يجب أن تكون قيمة slice_sizes.size مساوية لقيمة operand.rank.
إذا كانت قيمة index_vector_dim تساوي start_indices.rank، سنعتبر ضمنيًا أنّ start_indices يتضمّن بُعدًا لاحقًا 1 (أي إذا كان شكل start_indices هو [6,7] وكانت قيمة index_vector_dim هي 2، سنعتبر ضمنيًا أنّ شكل start_indices هو [6,7,1]).
يتم احتساب حدود مصفوفة الإخراج على طول البُعد i على النحو التالي:
إذا كان
iمتوفّرًا فيbatch_dims(أي يساويbatch_dims[k]لبعضk)، نختار حدود السمة المطابقة منstart_indices.shape، مع تخطّيindex_vector_dim(أي نختارstart_indices.shape.dims[k] إذا كانk<index_vector_dim، وstart_indices.shape.dims[k+1] في الحالات الأخرى).إذا كان
iمتوفّرًا فيoffset_dims(أي يساويoffset_dims[k] لبعضk)، نختار الحدّ المطابق منslice_sizesبعد أخذcollapsed_slice_dimsفي الاعتبار (أي نختارadjusted_slice_sizes[k] حيثadjusted_slice_sizesهوslice_sizesمع إزالة الحدود في الفهارسcollapsed_slice_dims).
رياضيًا، يتم حساب فهرس العنصر In الذي يتوافق مع فهرس الناتج Out على النحو التالي:
ليكن
G= {Out[k] forkinbatch_dims}. استخدِمGلتقسيم المتّجهSبحيث يكونS[i] =start_indices[Combine(G,i)] حيث إنّ Combine(A, b) تُدرِج b في الموضعindex_vector_dimفي A. يُرجى العِلم أنّ هذا الإجراء محدّد جيدًا حتى إذا كانتGفارغة: إذا كانتGفارغة، فإنّS=start_indices.أنشئ فهرسًا أوليًا،
Sin، فيoperandباستخدامSمن خلال توزيعSباستخدامstart_index_map. في ما يلي المزيد من التفاصيل:Sin[start_index_map[k]] =S[k] ifk<start_index_map.size.Sin[_] =0في الحالات الأخرى.
أنشئ فهرسًا
Oinفيoperandمن خلال توزيع الفهارس في سمات الإزاحة فيOutوفقًا لمجموعةcollapsed_slice_dims. في ما يلي المزيد من التفاصيل:
Oin[remapped_offset_dims(k)] =Out[offset_dims[k]] ifk<offset_dims.size(remapped_offset_dimsis defined below).Oin[_] =0في الحالات الأخرى.
InهيOin+Sinحيث + هي عملية جمع على مستوى العناصر.
remapped_offset_dims هي دالة رتيبة مع مجال [0,
offset_dims.size) ومدى [0, operand.rank) \ collapsed_slice_dims. بالتالي،
إذا كان، على سبيل المثال، offset_dims.size هو 4 وoperand.rank هو 6 وcollapsed_slice_dims هو {0, 2}،
فإنّ remapped_offset_dims هو {0→1,
1→3, 2→4, 3→5}.
في حال ضبط indices_are_sorted على "صحيح"، يمكن أن يفترض XLA أنّ المستخدم قد رتّب start_indices (ترتيب تصاعدي، بعد توزيع قيمه وفقًا start_index_map). وفي حال عدم توفّرها، يتم تحديد الدلالات حسب التنفيذ.
الوصف غير الرسمي والأمثلة
بشكل غير رسمي، يتطابق كل فهرس Out في مصفوفة الإخراج مع عنصر E في مصفوفة المعامِلات، ويتم حسابه على النحو التالي:
نستخدم سمات المجموعة في
Outللبحث عن فهرس بدء منstart_indices.نستخدم
start_index_mapلربط الفهرس الأوّلي (الذي قد يكون حجمه أقل من operand.rank) بفهرس أوّلي "كامل" فيoperand.نقسم بشكل ديناميكي شريحة بحجم
slice_sizesباستخدام الفهرس الكامل للبداية.نعيد تشكيل الشريحة من خلال تصغير الأبعاد
collapsed_slice_dims. بما أنّ جميع أبعاد الشريحة المصغّرة يجب أن يكون لها حدّ يساوي 1، فإنّ عملية إعادة التشكيل هذه تكون صالحة دائمًا.نستخدم أبعاد الإزاحة في
Outللفهرسة في هذا الجزء للحصول على عنصر الإدخالEالمقابل لفهرس الإخراجOut.
تم ضبط index_vector_dim على start_indices.rank - 1 في جميع الأمثلة التالية. لا تؤدي القيم الأكثر إثارة للاهتمام في index_vector_dim إلى تغيير العملية بشكل أساسي، ولكنها تجعل التمثيل المرئي أكثر صعوبة.
للحصول على فكرة عن كيفية عمل كل ما سبق معًا، لنلقِ نظرة على مثال يجمع 5 شرائح من الشكل [8,6] من مصفوفة [16,11]. يمكن تمثيل موضع شريحة في مصفوفة [16,11] كمتجه فهرس ذي شكل S64[2]، وبالتالي يمكن تمثيل مجموعة من 5 مواضع كمصفوفة S64[5,2].
يمكن بعد ذلك وصف سلوك عملية التجميع على أنّه تحويل فهرس يأخذ [G،O0،O1]، وهو فهرس في شكل الإخراج، ويربطه بعنصر في مصفوفة الإدخال بالطريقة التالية:

نختار أولاً متّجه (X,Y) من مصفوفة فهارس التجميع باستخدام G.
يكون العنصر في مصفوفة الإخراج عند الفهرس
[G,O0,O1] هو العنصر في مصفوفة الإدخال عند الفهرس [X+O0,Y+O1].
slice_sizes هي [8,6]، التي تحدّد نطاق O0 وO1، وهذا بدوره يحدّد حدود الشريحة.
تعمل عملية التجميع هذه كشريحة ديناميكية مجمّعة مع G كبعد مجمّع.
قد تكون فهارس التجميع متعدّدة الأبعاد. على سبيل المثال، يمكن ترجمة نسخة أكثر عمومية من المثال أعلاه باستخدام مصفوفة "جمع الفهارس" بالشكل [4,5,2] على النحو التالي:

مرة أخرى، يعمل هذا كشريحة ديناميكية مجمّعة G0 وG1 كأبعاد مجمّعة، ويظل حجم الشريحة [8,6].
تعمّم عملية التجميع في XLA الدلالات غير الرسمية الموضّحة أعلاه بالطرق التالية:
يمكننا ضبط السمات التي تمثّل سمات الإزاحة في شكل الإخراج (السمات التي تحتوي على
O0وO1في المثال الأخير). يتم تحديد سمات الدفعة الناتجة (السمات التي تحتوي علىG0وG1في المثال الأخير) على أنّها سمات ناتجة ليست سمات إزاحة.قد يكون عدد سمات الإزاحة في الناتج الظاهرة بشكل صريح في شكل الناتج أقل من عدد سمات الإزاحة في الإدخال. يجب أن يكون حجم شريحة السمات "المفقودة"، المدرَجة بشكل صريح على النحو
collapsed_slice_dims، يساوي1. بما أنّ حجم الشريحة هو1، فإنّ الفهرس الصالح الوحيد هو0، ولا يؤدي حذفها إلى حدوث أي غموض.قد يحتوي الجزء الذي تم استخراجه من مصفوفة "جمع الفهارس" (
XوYفي المثال الأخير) على عناصر أقل من عدد سمات مصفوفة الإدخال، ويحدّد الربط الواضح كيفية توسيع الفهرس ليتضمّن عدد السمات نفسه في الإدخال.
كمثال أخير، نستخدم (2) و (3) لتنفيذ tf.gather_nd:

يُستخدم G0 وG1 لتقسيم فهرس البداية من مصفوفة فهارس التجميع كالمعتاد، باستثناء أنّ فهرس البداية يحتوي على عنصر واحد فقط، وهو X. وبالمثل، لا يوجد سوى فهرس إزاحة إخراج واحد بالقيمة O0. ومع ذلك، قبل استخدامها كفهارس في مصفوفة الإدخال، يتم توسيعها وفقًا لـ "ربط فهارس التجميع" (start_index_map في الوصف الرسمي) و "ربط الإزاحة" (remapped_offset_dims في الوصف الرسمي) إلى [X,0] و[0,O0] على التوالي، ما يؤدي إلى [X,O0]. بعبارة أخرى، يرتبط فهرس الإخراج [G0,G1,O0] بفهرس الإدخال [GatherIndices[G0,G1,0],O0]، ما يمنحنا دلالات tf.gather_nd.
slice_sizes لهذه الحافظة هو [1,11]. يعني هذا بشكل بديهي أنّ كل فهرس X في مصفوفة فهارس التجميع يختار صفًا كاملاً، والنتيجة هي تسلسل كل هذه الصفوف.
GetDimensionSize
يمكنك الاطّلاع أيضًا على XlaBuilder::GetDimensionSize.
تعرض هذه الدالة حجم البُعد المحدّد للمعامل، ويجب أن يكون المعامل على شكل مصفوفة.
GetDimensionSize(operand, dimension)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة إدخال ذات n أبعاد |
dimension
|
int64
|
قيمة في الفاصل [0, n) تحدّد السمة |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - get_dimension_size.
GetTupleElement
يمكنك الاطّلاع أيضًا على XlaBuilder::GetTupleElement.
فهارس في مجموعة بقيمة ثابتة في وقت الترجمة
يجب أن تكون القيمة ثابتة في وقت الترجمة حتى يتمكّن استنتاج الشكل من تحديد نوع القيمة الناتجة.
وهذا مشابه لـ std::get<int N>(t) في C++. من الناحية النظرية:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
يمكنك الاطّلاع أيضًا على tf.tuple.
GetTupleElement(tuple_data, index)
| الوسيطة | النوع | معاني |
|---|---|---|
tuple_data |
XlaOP |
الصف |
index |
int64 |
فهرس شكل المجموعة |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - get_tuple_element.
Imag
يمكنك الاطّلاع أيضًا على XlaBuilder::Imag.
الجزء التخيلي من شكل مركّب (أو حقيقي) على مستوى كل عنصر x -> imag(x). إذا كان المعامِل من النوع ذي الفاصلة العائمة، يتم عرض 0.
Imag(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - imag.
Infeed
يمكنك الاطّلاع أيضًا على XlaBuilder::Infeed.
Infeed(shape, config)
| الوسيطة | النوع | معاني |
|---|---|---|
shape
|
Shape
|
شكل البيانات التي يتم قراءتها من واجهة Infeed يجب ضبط حقل التنسيق الخاص بالشكل ليطابق تنسيق البيانات المرسَلة إلى الجهاز، وإلا سيكون سلوكه غير محدّد. |
config |
اختياري string |
إعدادات العملية |
يقرأ هذا الإذن عنصر بيانات واحدًا من واجهة البث الضمني Infeed على الجهاز، ويفسّر البيانات على أنّها الشكل المحدّد وتصميمه، ويعرض XlaOp للبيانات. يُسمح بتنفيذ عمليات Infeed متعددة في عملية حسابية، ولكن يجب أن يكون هناك ترتيب إجمالي بين عمليات Infeed. على سبيل المثال، يكون للرمزين
Infeed في الرمز أدناه ترتيب إجمالي لأنّ هناك تبعية
بين حلقتَي while.
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
لا تتوفّر أشكال الصفوف المتداخلة. بالنسبة إلى شكل المجموعة الفارغة، تكون عملية Infeed في الواقع عملية غير نشطة وتستمر بدون قراءة أي بيانات من Infeed للجهاز.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - infeed.
أمواج هادئة قصيرة
يمكنك الاطّلاع أيضًا على XlaBuilder::Iota.
Iota(shape, iota_dimension)
تنشئ هذه الدالة قيمة حرفية ثابتة على الجهاز بدلاً من عملية نقل كبيرة محتملة للمضيف. وتنشئ مصفوفة ذات شكل محدّد وتحتوي على قيم تبدأ من صفر وتزيد بمقدار واحد على طول البُعد المحدّد. بالنسبة إلى أنواع الفاصلة العائمة، تكون المصفوفة الناتجة مكافئة لـ ConvertElementType(Iota(...)) حيث يكون Iota من النوع المتكامل ويتم التحويل إلى نوع الفاصلة العائمة.
| الوسيطات | النوع | معاني |
|---|---|---|
shape |
Shape |
شكل الصفيف الذي تم إنشاؤه بواسطة Iota() |
iota_dimension |
int64 |
السمة المطلوب زيادة قيمتها. |
على سبيل المثال، تعرض الدالة Iota(s32[4, 8], 0)
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
يمكن إرجاع المشتريات مقابل Iota(s32[4, 8], 1).
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - iota.
IsFinite
يمكنك الاطّلاع أيضًا على XlaBuilder::IsFinite.
تختبر هذه الدالة ما إذا كان كل عنصر من عناصر operand محدودًا، أي ليس موجبًا أو سالبًا بلا حدود، وليس NaN. وتعرض مصفوفة من قيم PRED بالشكل نفسه كشكل الإدخال، حيث يكون كل عنصر true إذا كان عنصر الإدخال المقابل محدودًا فقط.
IsFinite(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - is_finite.
السجل
يمكنك الاطّلاع أيضًا على XlaBuilder::Log.
اللوغاريتم الطبيعي لكل عنصر x -> ln(x)
Log(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة log أيضًا الوسيط الاختياري result_accuracy:
Log(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - log.
Log1p
يمكنك الاطّلاع أيضًا على XlaBuilder::Log1p.
اللوغاريتم الطبيعي المعدَّل x -> ln(1+x).
Log1p(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Log1p أيضًا الوسيط الاختياري result_accuracy:
Log1p(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - log_plus_one.
Logistic
يمكنك الاطّلاع أيضًا على XlaBuilder::Logistic.
عملية حساب الدالة اللوجستية على مستوى العناصر x -> logistic(x)
Logistic(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة اللوجستية أيضًا الوسيطة الاختيارية result_accuracy:
Logistic(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - logistic.
خريطة
يمكنك الاطّلاع أيضًا على XlaBuilder::Map.
Map(operands..., computation, dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
operands |
تسلسل N XlaOps |
مصفوفات N من الأنواع T0..T{N-1} |
computation
|
XlaComputation
|
عملية حسابية من النوع T_0, T_1,
.., T_{N + M -1} -> S مع N من المَعلمات من النوع T وM من النوع العشوائي |
dimensions |
int64 array |
مصفوفة سمات الخريطة |
static_operands
|
تسلسل N XlaOps
|
عمليات ثابتة لعملية الخريطة |
تطبِّق هذه الدالة دالة عددية على مصفوفات operands المحدّدة، ما يؤدي إلى إنشاء مصفوفة
بالأبعاد نفسها حيث يكون كل عنصر هو نتيجة الدالة التي تم ربطها
والمطبَّقة على العناصر المقابلة في المصفوفات المُدخَلة.
الدالة التي تم ربطها هي عملية حسابية عشوائية مع شرط أن يكون لها N مدخلات من النوع العددي T ومخرج واحد من النوع S. ويكون للمخرج الأبعاد نفسها الخاصة بالمعاملات باستثناء أنّه يتم استبدال نوع العنصر T بالنوع S.
على سبيل المثال: Map(op1, op2, op3, computation, par1) تربط elem_out <-
computation(elem1, elem2, elem3, par1) بكل فهرس (متعدد الأبعاد) في صفائف الإدخال لإنتاج صفيف الإخراج.
لمزيد من المعلومات حول StableHLO، يمكنك الاطّلاع على StableHLO - map.
الحد الأقصى
يمكنك الاطّلاع أيضًا على XlaBuilder::Max.
تُجري هذه الدالة عملية الحد الأقصى على مستوى العناصر في الموترَين lhs وrhs.
Max(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر إصدار بديل من Max يتوافق مع البث بأبعاد مختلفة:
Max(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - الحد الأقصى.
الحد الأدنى
يمكنك الاطّلاع أيضًا على XlaBuilder::Min.
تُجري عملية الحد الأدنى على مستوى العناصر في lhs وrhs.
Min(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل يتوافق مع البث بأبعاد مختلفة لـ Min:
Min(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - الحد الأدنى.
Mul
يمكنك الاطّلاع أيضًا على XlaBuilder::Mul.
تُجري هذه الدالة عملية ضرب العناصر المقابلة في lhs وrhs.
Mul(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
تتوفّر صيغة بديلة مع إمكانية البث بأبعاد مختلفة للدالة Mul:
Mul(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - multiply.
Neg
يمكنك الاطّلاع أيضًا على XlaBuilder::Neg.
النفي على مستوى العناصر x -> -x
Neg(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - negate.
ليس
يمكنك الاطّلاع أيضًا على XlaBuilder::Not.
Element-wise logical not x -> !(x)
Not(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - not.
OptimizationBarrier
يمكنك الاطّلاع أيضًا على XlaBuilder::OptimizationBarrier.
يمنع أي عملية تحسين من نقل العمليات الحسابية عبر الحاجز.
OptimizationBarrier(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
يضمن تقييم جميع المدخلات قبل أي عوامل تشغيل تعتمد على مخرجات الحاجز.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - optimization_barrier.
أو
يمكنك الاطّلاع أيضًا على XlaBuilder::Or.
تُجري عملية OR على مستوى العناصر في lhs وrhs .
Or(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بالشكل الناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر متغير بديل مع إمكانية البث بأبعاد مختلفة للدالة Or:
Or(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - or.
Outfeed
يمكنك الاطّلاع أيضًا على XlaBuilder::Outfeed.
تكتب هذه العملية المدخلات في موجز الخرج.
Outfeed(operand, shape_with_layout, outfeed_config)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T |
shape_with_layout |
Shape |
تحديد تنسيق البيانات المنقولة |
outfeed_config |
string |
ثابت الإعدادات لتعليمات Outfeed |
تعرض shape_with_layout الشكل الذي نريد إخراجه.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - outfeed.
الوسادة
يمكنك الاطّلاع أيضًا على XlaBuilder::Pad.
Pad(operand, padding_value, padding_config)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T |
padding_value
|
XlaOp
|
عدد قياسي من النوع T لملء المساحة المتروكة المضافة |
padding_config
|
PaddingConfig
|
مقدار المساحة المتروكة على كلا الحافتين (منخفض، مرتفع) وبين عناصر كل بُعد |
توسّع هذه الدالة نطاق مصفوفة operand المحدّدة من خلال إضافة مساحة متروكة حول المصفوفة وكذلك بين عناصر المصفوفة باستخدام padding_value المحدّدة. تحدّد هذه السمة مقدار المساحة المتروكة على الحواف والمساحة المتروكة الداخلية لكل بُعد.padding_config
PaddingConfig هو حقل متكرّر من PaddingConfigDimension، ويحتوي على ثلاثة حقول لكل سمة: edge_padding_low وedge_padding_high وinterior_padding.
تحدّد edge_padding_low وedge_padding_high مقدار المساحة المتروكة المضافة
في الطرف الأدنى (بجانب الفهرس 0) والطرف الأعلى (بجانب الفهرس الأعلى) لكل بُعد على التوالي. يمكن أن يكون مقدار المساحة المتروكة على الحواف سالبًا، وتشير القيمة المطلقة للمساحة السالبة إلى عدد العناصر التي يجب إزالتها من البُعد المحدّد.
تحدّد interior_padding مقدار المساحة المتروكة بين أي عنصرَين في كل بُعد، ويجب ألا تكون قيمة سالبة. يحدث الحشو الداخلي منطقيًا قبل الحشو على الحواف، لذا في حالة الحشو السلبي على الحواف، تتم إزالة العناصر من المعامِل المحشو داخليًا.
لا تؤدي هذه العملية أي إجراء إذا كانت جميع أزواج الحشو على الحواف هي (0, 0) وكانت جميع قيم الحشو الداخلية هي 0. يوضّح الشكل أدناه أمثلة على قيم edge_padding وinterior_padding المختلفة لمصفوفة ثنائية الأبعاد.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - pad.
المَعلمة
يمكنك الاطّلاع أيضًا على XlaBuilder::Parameter.
يمثّل Parameter إدخال وسيطة إلى عملية حسابية.
PartitionID
يمكنك الاطّلاع أيضًا على XlaBuilder::BuildPartitionId.
تُنتج partition_id للعملية الحالية.
PartitionID(shape)
| الوسيطات | النوع | معاني |
|---|---|---|
shape |
Shape |
شكل البيانات |
قد يظهر PartitionID في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئه المستخدمون النهائيون يدويًا.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - partition_id.
PopulationCount
يمكنك الاطّلاع أيضًا على XlaBuilder::PopulationCount.
تحسب هذه الدالة عدد البتات المضبوطة في كل عنصر من عناصر operand.
PopulationCount(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - popcnt.
Pow
يمكنك الاطّلاع أيضًا على XlaBuilder::Pow.
تُجري هذه الدالة عملية رفع كل عنصر من عناصر lhs إلى الأس rhs.
Pow(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر إصدار بديل من Pow يتوافق مع البث بأبعاد مختلفة:
Pow(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - power.
Real
يمكنك الاطّلاع أيضًا على XlaBuilder::Real.
الجزء الحقيقي من الشكل المركّب (أو الحقيقي) على مستوى كل عنصر. x -> real(x). إذا كان نوع المعامِل نقطة عائمة، تعرض الدالة Real القيمة نفسها.
Real(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
لمزيد من المعلومات عن StableHLO، يُرجى الاطّلاع على StableHLO - real.
Recv
يمكنك الاطّلاع أيضًا على XlaBuilder::Recv.
Recv وRecvWithTokens وRecvToHost هي عمليات تعمل كعناصر أساسية للتواصل في HLO. تظهر هذه العمليات عادةً في عمليات تفريغ HLO كجزء من عمليات الإدخال/الإخراج المنخفضة المستوى أو عمليات النقل التي تعمل من خلال جهاز آخر، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
Recv(shape, handle)
| الوسيطات | النوع | معاني |
|---|---|---|
shape |
Shape |
شكل البيانات المطلوب تلقّيها |
handle |
ChannelHandle |
معرّف فريد لكل زوج إرسال/استلام |
تتلقّى هذه العملية بيانات بالشكل المحدّد من تعليمات Send في عملية حسابية أخرى تشارك معها معرّف القناة نفسه. تعرض هذه الدالة XlaOp للبيانات المستلَمة.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - recv.
RecvDone
يمكنك الاطّلاع أيضًا على
HloInstruction::CreateRecv وHloInstruction::CreateRecvDone.
على غرار Send، تمثّل واجهة برمجة التطبيقات الخاصة بالعميل لعملية Recv عملية التواصل المتزامن. ومع ذلك، يتم تقسيم التعليمات داخليًا إلى تعليمتَين من تعليمات HLO (Recv وRecvDone) لتفعيل عمليات نقل البيانات غير المتزامنة.
Recv(const Shape& shape, int64 channel_id)
تخصّص هذه السمة الموارد اللازمة لتلقّي البيانات من تعليمات Send تتضمّن channel_id نفسه. تعرض هذه السمة سياقًا للموارد المخصّصة، وتستخدمه تعليمات RecvDone التالية لانتظار اكتمال عملية نقل البيانات. السياق هو مجموعة من {مخزن الاستقبال المؤقت (الشكل)، معرّف الطلب (U32)} ولا يمكن استخدامه إلا من خلال تعليمات RecvDone.
بالنظر إلى السياق الذي تم إنشاؤه بواسطة تعليمات Recv، تنتظر هذه السمة إلى أن يكتمل نقل البيانات وتعرض البيانات المستلَمة.
الحدّ
يمكنك الاطّلاع أيضًا على XlaBuilder::Reduce.
تطبِّق دالة اختزال على صفيف واحد أو أكثر بالتوازي.
Reduce(operands..., init_values..., computation, dimensions_to_reduce)
| الوسيطات | النوع | معاني |
|---|---|---|
operands
|
تسلسل N XlaOp
|
مصفوفات N من النوع T_0,...,
T_{N-1} |
init_values
|
تسلسل N XlaOp
|
قيم N عددية من النوع
T_0,..., T_{N-1}. |
computation
|
XlaComputation
|
احتساب النوع
T_0,..., T_{N-1}, T_0,
...,T_{N-1} ->
Collate(T_0,...,
T_{N-1}) |
dimensions_to_reduce
|
int64 array
|
مصفوفة غير مرتبة من السمات التي سيتم تقليلها. |
المكان:
- يجب أن تكون قيمة N أكبر من أو تساوي 1.
- يجب أن تكون عملية الاحتساب "ترابطية" "تقريبًا" (راجِع ما يلي).
- يجب أن تتطابق أبعاد جميع مصفوفات الإدخال.
- يجب أن تشكّل جميع القيم الأولية هوية ضمن
computation. - إذا كان
N = 1، فإنّCollate(T)هوT. - إذا كان
N > 1،Collate(T_0, ..., T_{N-1})عبارة عن مجموعة من عناصرNمن النوعT.
تقلّل هذه العملية من سمة واحدة أو أكثر لكل صفيف إدخال إلى قيم عددية.
عدد أبعاد كل صفيف معروض هو
number_of_dimensions(operand) - len(dimensions). يكون الناتج من العملية
Collate(Q_0, ..., Q_N) حيث Q_i هي مصفوفة من النوع T_i،
ويتم وصف أبعادها أدناه.
يُسمح للخوادم الخلفية المختلفة بإعادة ربط عملية احتساب التخفيض، ما قد يؤدي إلى اختلافات رقمية، لأنّ بعض دوال التخفيض، مثل الجمع، ليست ترابطية بالنسبة إلى الأعداد العشرية. ومع ذلك، إذا كان نطاق البيانات محدودًا، يكون جمع الأعداد العشرية قريبًا بدرجة كافية من أن يكون ترابطيًا بالنسبة إلى معظم الاستخدامات العملية.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - reduce.
أمثلة
عند تقليل عدد العناصر على مستوى بُعد واحد في صفيف أحادي الأبعاد واحد يتضمّن القيم [10, 11,
12, 13]، باستخدام دالة تقليل عدد العناصر f (هذا هو computation)، يمكن حساب ذلك على النحو التالي:
f(10, f(11, f(12, f(init_value, 13)))
ولكن هناك أيضًا العديد من الاحتمالات الأخرى، مثل
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
في ما يلي مثال تقريبي على الرمز الزائف يوضّح كيفية تنفيذ عملية الاختزال، وذلك باستخدام عملية الجمع كعملية حسابية للاختزال مع قيمة أولية تبلغ 0.
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the number of dimensions of the result.
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
في ما يلي مثال على تقليل مصفوفة ثنائية الأبعاد (مصفوفة). يحتوي الشكل على بُعدَين، البُعد 0 بحجم 2 والبُعد 1 بحجم 3:
نتائج خفض الأبعاد بمقدار 0 أو 1 باستخدام دالة "إضافة":
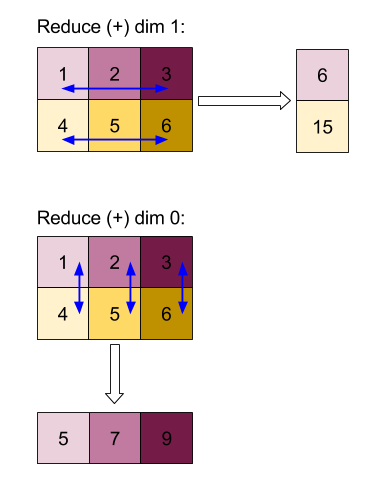
يُرجى العِلم أنّ نتائج الاختزال هي عبارة عن مصفوفات أحادية البُعد، ويظهر أحدها كعمود والآخر كصف في الرسم التوضيحي لتسهيل العرض.
للحصول على مثال أكثر تعقيدًا، إليك مصفوفة ثلاثية الأبعاد. عدد أبعادها هو 3، والبعد 0 بحجم 4، والبعد 1 بحجم 2، والبعد 2 بحجم 3. للتسهيل، يتم تكرار القيم من 1 إلى 6 في البُعد 0.
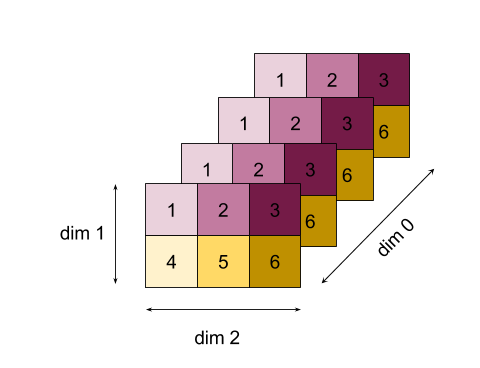
على غرار المثال الثنائي الأبعاد، يمكننا تقليل بُعد واحد فقط. إذا قلّلنا البُعد 0، على سبيل المثال، سنحصل على مصفوفة ثنائية الأبعاد تم فيها طيّ جميع القيم في البُعد 0 إلى قيمة عددية:
| 4 8 12 |
| 16 20 24 |
إذا قلّلنا السمة 2، سنحصل أيضًا على مصفوفة ثنائية الأبعاد تم فيها دمج جميع القيم في السمة 2 في قيمة عددية:
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
يُرجى العِلم أنّه يتم الحفاظ على الترتيب النسبي بين السمات المتبقية في الإدخال في الإخراج، ولكن قد يتم تعيين أرقام جديدة لبعض السمات (بما أنّ عدد السمات يتغيّر).
يمكننا أيضًا تقليل أبعاد متعدّدة. تؤدي إضافة أبعاد التقليل 0 و1 إلى إنشاء الصفيف الأحادي الأبعاد [20, 28, 36].
يؤدي تقليل مصفوفة ثلاثية الأبعاد على جميع أبعادها إلى إنتاج العدد القياسي 84.
Variadic Reduce
عندما تكون قيمة N > 1، يكون تطبيق الدالة reduce أكثر تعقيدًا بعض الشيء، لأنّه يتم تطبيقه في الوقت نفسه على جميع المدخلات. يتم تقديم المعامِلات إلى عملية الحساب بالترتيب التالي:
- تشغيل القيمة المخفَّضة للعامل الأول
- ...
- تشغيل قيمة مخفَّضة للمعامل رقم N
- قيمة الإدخال للمعامل الأول
- ...
- قيمة الإدخال للعامل الحسابي رقم N
على سبيل المثال، ضع في اعتبارك دالة الاختزال التالية التي يمكن استخدامها لحساب الحد الأقصى وargmax لمصفوفة أحادية البعد بالتوازي:
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
بالنسبة إلى مصفوفات الإدخال أحادية الأبعاد V = Float[N], K = Int[N] والقيم الأولية I_V = Float, I_K = Int، تكون النتيجة f_(N-1) لعملية الاختزال على مستوى سمة الإدخال الوحيدة مكافئة للتطبيق المتكرّر التالي:
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
سيؤدي تطبيق هذا الاختزال على مصفوفة من القيم ومصفوفة من الفهارس التسلسلية (أي iota) إلى تكرار مشترك على المصفوفات، وسيعرض مجموعة تحتوي على القيمة القصوى والفهرس المطابق.
ReducePrecision
يمكنك الاطّلاع أيضًا على XlaBuilder::ReducePrecision.
تُحاكي هذه الدالة تأثير تحويل قيم الفاصلة العائمة إلى تنسيق أقل دقة (مثل IEEE-FP16) ثم الرجوع إلى التنسيق الأصلي. ويمكن تحديد عدد بتات الأس والجزء الكسري في التنسيق الأقل دقة بشكل عشوائي، مع العلم أنّه قد لا تتوافق جميع أحجام البتات مع جميع عمليات التنفيذ على الأجهزة.
ReducePrecision(operand, exponent_bits, mantissa_bits)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T ذي النقطة العائمة |
exponent_bits |
int32 |
عدد وحدات البت الخاصة بالأس في التنسيق ذي الدقة المنخفضة |
mantissa_bits |
int32 |
عدد بتات الجزء الكسري في التنسيق ذي الدقة المنخفضة |
والنتيجة هي مصفوفة من النوع T. يتم تقريب قيم الإدخال إلى أقرب قيمة يمكن تمثيلها باستخدام عدد محدد من بتات الجزء الكسري (باستخدام دلالات "التقريب إلى أقرب عدد زوجي")، ويتم حصر أي قيم تتجاوز النطاق المحدد بعدد بتات الأس في اللانهاية الموجبة أو السالبة. يتم الاحتفاظ بقيم NaN، على الرغم من أنّه يمكن تحويلها إلى قيم NaN أساسية.
يجب أن يتضمّن التنسيق ذو الدقة الأقل وحدة بت واحدة على الأقل للأس (من أجل التمييز بين القيمة صفر واللانهاية، لأنّ كلتيهما تتضمّنان جزءًا كسريًا يساوي صفرًا)، ويجب أن يتضمّن عددًا غير سالب من وحدات بت الجزء الكسري. وقد يتجاوز عدد وحدات بت الأس أو الجزء الكسري القيمة المقابلة للنوع T، وبالتالي يكون الجزء المقابل من التحويل بلا تأثير.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - reduce_precision.
ReduceScatter
يمكنك الاطّلاع أيضًا على XlaBuilder::ReduceScatter.
ReduceScatter هي عملية جماعية تنفّذ عملية AllReduce بشكل فعّال، ثم تقسم النتيجة إلى shard_count كتلة على طول scatter_dimension، وتتلقّى النسخة المتماثلة i في مجموعة النسخ المتماثلة الجزء ith.
ReduceScatter(operand, computation, scatter_dimension, shard_count,
replica_groups, channel_id, layout, use_global_device_ids)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp
|
صفيف أو مجموعة غير فارغة من الصفائف لتقليل عدد النسخ المتماثلة. |
computation |
XlaComputation |
احتساب التخفيض |
scatter_dimension |
int64 |
السمة المطلوب توزيعها |
shard_count
|
int64
|
عدد الحِزم المطلوب تقسيمها
scatter_dimension |
replica_groups
|
ReplicaGroup متّجه
|
المجموعات التي يتم إجراء عمليات التخفيض بينها |
channel_id
|
اختياري
ChannelHandle |
معرّف القناة الاختياري للتواصل بين الوحدات |
layout
|
اختياري Layout
|
تنسيق الذاكرة الذي يحدّده المستخدم |
use_global_device_ids |
اختياري bool |
علامة يحدّدها المستخدم |
- عندما يكون
operandمجموعة من المصفوفات، يتم تنفيذ عملية reduce-scatter على كل عنصر من عناصر المجموعة. replica_groupsهي قائمة بمجموعات النسخ المتماثلة التي يتم إجراء عملية التصغير بينها (يمكن استرداد معرّف النسخة المتماثلة الحالية باستخدامReplicaId). ويحدّد ترتيب النسخ المتماثلة في كل مجموعة ترتيب توزيع نتيجة عملية التصغير. يجب أن يكون الحقلreplica_groupsإما فارغًا (وفي هذه الحالة تنتمي جميع النسخ المتطابقة إلى مجموعة واحدة)، أو يحتوي على عدد العناصر نفسه الذي يتضمّنه عدد النسخ المتطابقة. عندما يكون هناك أكثر من مجموعة واحدة من النسخ المتطابقة، يجب أن تكون جميعها بالحجم نفسه. على سبيل المثال، تنفّذreplica_groups = {0, 2}, {1, 3}عملية تصغير بين النسختين المتطابقتين0و2، و1و3، ثم تنشر النتيجة.shard_countهو حجم كل مجموعة من النسخ المتماثلة. نحتاج إلى ذلك في الحالات التي تكون فيهاreplica_groupsفارغة. إذا لم يكنreplica_groupsفارغًا، يجب أن تكون قيمةshard_countمساوية لحجم كل مجموعة من النسخ المتطابقة.- يتم استخدام
channel_idللتواصل بين الوحدات: يمكن فقط لعملياتreduce-scatterالتي لهاchannel_idنفسها التواصل مع بعضها البعض. layoutيمكنك الاطّلاع على xla::shapes للحصول على مزيد من المعلومات حول التنسيقات.use_global_device_idsهي علامة يحدّدها المستخدم. عندما تكون القيمةfalse(تلقائية)، تكون الأرقام فيreplica_groupsهيReplicaIdعندما تكون القيمةtrue، ويمثّلreplica_groupsمعرّفًا عامًا بالقيمة (ReplicaID*partition_count+partition_id). على سبيل المثال:- مع نسختَين متطابقتَين و4 أقسام،
- replica_groups={ {0,1,4,5},{2,3,6,7} } and use_global_device_ids=true
- group[0] = (0,0), (0,1), (1,0), (1,1)
- group[1] = (0,2), (0,3), (1,2), (1,3)
- حيث يمثّل كل زوج (replica_id, partition_id).
يكون شكل الناتج هو شكل الإدخال مع تصغير scatter_dimension بمقدار shard_count مرة. على سبيل المثال، إذا كان هناك نسختان متطابقتان وكانت قيمة المعامِل [1.0, 2.25] و[3.0, 5.25] على التوالي في النسختين المتطابقتين، ستكون قيمة الناتج من هذه العملية حيث scatter_dim هي 0، [4.0] للنسخة المتطابقة الأولى و[7.5] للنسخة المتطابقة الثانية.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - reduce_scatter.
ReduceScatter - Example 1 - StableHLO

في المثال أعلاه، هناك نسختان طبق الأصل تشاركان في عملية ReduceScatter. في كل نسخة طبق الأصل، يكون للمعامل الشكل f32[2,4]. يتم إجراء عملية تقليل شاملة (مجموع) على مستوى جميع النسخ المتماثلة، ما يؤدي إلى إنتاج قيمة مخفَّضة بالشكل f32[2,4] على كل نسخة متماثلة. يتم بعد ذلك تقسيم هذه القيمة المخفَّضة إلى جزأين على طول البُعد 1، وبالتالي يكون لكل جزء شكل f32[2,2]. يتلقّى كل نسخة طبق الأصل ضمن مجموعة العمليات الجزء الذي يتوافق مع موضعها في المجموعة. نتيجةً لذلك، يكون الناتج على كل نسخة طبق الأصل بالشكل f32[2,2].
ReduceWindow
يمكنك الاطّلاع أيضًا على XlaBuilder::ReduceWindow.
تطبِّق هذه السمة دالة تقليل على جميع العناصر في كل نافذة من سلسلة من مصفوفات N متعددة الأبعاد، ما يؤدي إلى إنشاء مصفوفة واحدة أو مجموعة من مصفوفات N متعددة الأبعاد كناتج. يحتوي كل صفيف ناتج على عدد العناصر نفسه كعدد المواضع الصالحة للنافذة. يمكن التعبير عن طبقة التجميع كـ ReduceWindow. على غرار Reduce، يتم دائمًا تمرير computation المطبَّقة إلى init_values على الجانب الأيسر.
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| الوسيطات | النوع | معاني |
|---|---|---|
operands
|
N XlaOps
|
تسلسل من N
مصفوفات متعددة الأبعاد من
النوع T_0,..., T_{N-1}، يمثّل كل منها
مساحة القاعدة التي
يتم وضع النافذة عليها. |
init_values
|
N XlaOps
|
تمثّل هذه السمة قيم N الأولية لعملية التصغير، قيمة واحدة لكل من معاملات N. راجِع Reduce للحصول على التفاصيل. |
computation
|
XlaComputation
|
دالة الاختزال من النوع T_0,
..., T_{N-1}, T_0, ..., T_{N-1}
-> Collate(T_0, ..., T_{N-1})،
التي سيتم تطبيقها على العناصر في كل
نافذة من جميع
معاملات الإدخال. |
window_dimensions
|
ArraySlice<int64>
|
مصفوفة أعداد صحيحة لقيم سمات النافذة |
window_strides
|
ArraySlice<int64>
|
مصفوفة أعداد صحيحة لقيم خطوة النافذة |
base_dilations
|
ArraySlice<int64>
|
صفيف من الأعداد الصحيحة لقيم التمدد الأساسية |
window_dilations
|
ArraySlice<int64>
|
مصفوفة أعداد صحيحة لقيم تمديد النافذة |
padding
|
Padding
|
نوع الحشو للنافذة (Padding::kSame، الذي يحشو بحيث يكون شكل الإخراج هو نفسه شكل الإدخال إذا كانت الخطوة 1، أو Padding::kValid، الذي لا يستخدم أي حشو و "يوقف" النافذة عندما لا تعود مناسبة) |
المكان:
- يجب أن تكون قيمة N أكبر من أو تساوي 1.
- يجب أن تتطابق أبعاد جميع مصفوفات الإدخال.
- إذا كان
N = 1، فإنّCollate(T)هوT. - إذا كان
N > 1،Collate(T_0, ..., T_{N-1})عبارة عن مجموعة من عناصرNمن النوع(T0,...T{N-1}).
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - reduce_window.
ReduceWindow - Example 1
الإدخال هو مصفوفة بحجم [4x6]، وكلا window_dimensions وwindow_stride_dimensions هما [2x3].
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
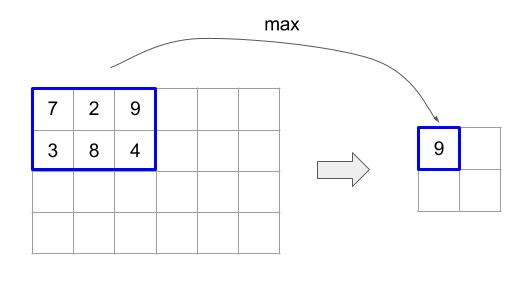
تشير الخطوة بمقدار 1 في أحد الأبعاد إلى أنّ موضع النافذة في البُعد يبعد بمقدار عنصر واحد عن النافذة المجاورة. لتحديد أنّه لا تتداخل أي نوافذ مع بعضها البعض، يجب أن تكون window_stride_dimensions مساوية لـ window_dimensions. يوضّح الشكل أدناه استخدام قيمتَين مختلفتَين للخطوة. يتم تطبيق الحشو على كل بُعد من أبعاد الإدخال، وتكون العمليات الحسابية مماثلة لما لو تم إدخال الأبعاد بعد إضافة الحشو.
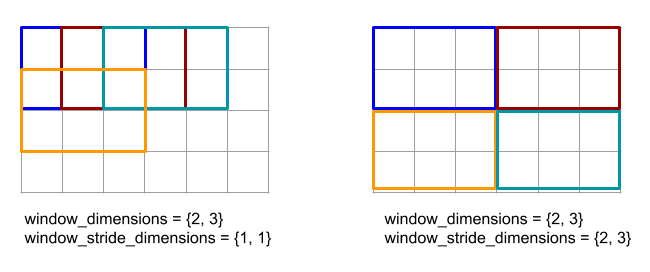
للحصول على مثال غير بسيط على الحشو، لنفترض أنّنا نريد حساب الحد الأدنى لنافذة التصغير (القيمة الأولية هي MAX_FLOAT) مع البُعد 3 والخطوة 2 على مستوى مصفوفة الإدخال [10000, 1000, 100, 10, 1]. يحسب الحشو kValid الحد الأدنى على مستوى نافذتَين صالحتَين: [10000, 1000, 100] و[100, 10, 1]، ما يؤدي إلى الحصول على الناتج [100, 1]. يحشو kSame المصفوفة أولاً ليكون الشكل بعد عملية التصغير مطابقًا لشكل الإدخال عند استخدام خطوة واحدة، وذلك عن طريق إضافة عناصر أولية على كلا الجانبين، ما يؤدي إلى الحصول على [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE]. يؤدي تنفيذ عملية التصغير على المصفوفة المحشوة إلى تشغيل ثلاث نوافذ [MAX_VALUE, 10000, 1000] و[1000, 100, 10] و[10, 1, MAX_VALUE]، ما يؤدي إلى الحصول على [1000, 10, 1].
إنّ ترتيب تقييم دالة الاختزال هو ترتيب عشوائي وقد يكون غير قطعي، لذا يجب ألا تكون دالة الاختزال حساسة بشكل مفرط لإعادة الربط. لمزيد من التفاصيل، راجِع المناقشة حول التجميعية في سياق Reduce.
ReduceWindow - المثال 2 - StableHLO

في المثال أعلاه:
الإدخال) يحتوي المعامِل على شكل إدخال S32[3,2]، مع قيم
[[1,2],[3,4],[5,6]]
الخطوة 1) يؤدي التوسيع الأساسي بمعامل 2 على طول بُعد الصف إلى إدراج فجوات بين كل صف من المعامِل. يتم تطبيق مساحة متروكة من صفَّين في الأعلى وصف واحد في الأسفل بعد التوسيع. نتيجةً لذلك، يصبح الموتر أطول.
الخطوة 2) يتم تحديد نافذة بالشكل [2,1]، مع تمديد النافذة [3,1]. وهذا يعني أنّ كل نافذة تختار عنصرَين من العمود نفسه، ولكن يتم أخذ العنصر الثاني من ثلاثة صفوف أسفل العنصر الأول بدلاً من الصف الذي يليه مباشرةً.
الخطوة 3) يتم بعد ذلك تمرير النوافذ على مستوى المعامِل مع الخطوة [4,1]. يؤدي ذلك إلى تحريك النافذة أربعة صفوف للأسفل في كل مرة، مع إزاحة عمود واحد في كل مرة أفقيًا. يتم ملء خلايا المساحة المتروكة بالقيمة init_value (في هذه الحالة init_value = 0)، ويتم تجاهل القيم التي "تندرج" ضمن خلايا التمديد.
بسبب الخطوة والحشو، تتداخل بعض النوافذ مع الأصفار والفجوات فقط، بينما تتداخل نوافذ أخرى مع قيم الإدخال الحقيقية.
الخطوة 4) ضمن كل نافذة، يتم دمج العناصر باستخدام دالة الاختزال (a, b) → a + b، بدءًا من القيمة الأولية 0. لا يظهر في النافذتين العلويتين سوى المساحات الفارغة والثقوب، لذا تكون النتائج 0. تعرض النوافذ السفلية القيمتين 3 و4 من الإدخال وتعرضهما كنتائج.
النتائج) يكون الناتج النهائي بالشكل S32[2,2]، مع القيم: [[0,0],[3,4]]
Rem
يمكنك الاطّلاع أيضًا على XlaBuilder::Rem.
تُجري هذه الدالة عملية حساب باقي القسمة بين المقسوم lhs والمقسوم عليه rhs لكل عنصر.
تُستمد إشارة النتيجة من المقسوم، وتكون القيمة المطلقة للنتيجة دائمًا أقل من القيمة المطلقة للمقسوم عليه.
Rem(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل من Rem يتوافق مع البث بأبعاد مختلفة:
Rem(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - remainder.
ReplicaId
يمكنك الاطّلاع أيضًا على XlaBuilder::ReplicaId.
تعرِض هذه السمة المعرّف الفريد (عدد صحيح غير سالب من 32 بت) للنسخة المتماثلة.
ReplicaId()
المعرّف الفريد لكل نسخة طبق الأصل هو عدد صحيح غير موقّع في الفترة [0, N)، حيث N هو عدد النسخ المتماثلة. بما أنّ جميع النسخ المتماثلة تشغّل البرنامج نفسه، فإنّ استدعاء ReplicaId() في البرنامج سيعرض قيمة مختلفة على كل نسخة متماثلة.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - replica_id.
تغيير الشكل
يمكنك الاطّلاع أيضًا على XlaBuilder::Reshape.
وعملية Collapse
تعيد تشكيل أبعاد الصفيف إلى إعداد جديد.
Reshape(operand, dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T |
dimensions |
int64 متّجه |
متّجه أحجام السمات الجديدة |
من الناحية المفاهيمية، تعمل عملية إعادة التشكيل أولاً على تسوية الصفيف إلى متّجه أحادي البُعد من قيم البيانات، ثم تحسين هذا المتّجه إلى شكل جديد. وسيطات الإدخال هي مصفوفة عشوائية من النوع T، ومتّجه ثابت في وقت الترجمة لفهارس الأبعاد، ومتّجه ثابت في وقت الترجمة لأحجام الأبعاد للنتيجة.
يحدّد المتّجه dimensions حجم مصفوفة الإخراج. القيمة في الفهرس 0 في dimensions هي حجم السمة 0، والقيمة في الفهرس 1 هي حجم السمة 1، وهكذا. يجب أن يكون ناتج ضرب أبعاد dimensions مساويًا لناتج ضرب أحجام أبعاد المعامِل. عند تحويل المصفوفة المضغوطة إلى مصفوفة متعددة الأبعاد محددة بواسطة dimensions، يتم ترتيب الأبعاد في dimensions من الأبطأ تغيرًا (الأكثر أهمية) إلى الأسرع تغيرًا (الأقل أهمية).
على سبيل المثال، لنفترض أنّ v هي مصفوفة من 24 عنصرًا:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
let v012_24 = Reshape(v, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
في حالة خاصة، يمكن أن تحوّل عملية إعادة التشكيل صفيفًا يتضمّن عنصرًا واحدًا إلى قيمة عددية والعكس صحيح. على سبيل المثال:
Reshape(f32[1x1] { {5} }, {}) == 5;
Reshape(5, {1,1}) == f32[1x1] { {5} };
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - reshape.
تغيير الشكل (صريح)
يمكنك الاطّلاع أيضًا على XlaBuilder::Reshape.
Reshape(shape, operand)
عملية إعادة تشكيل تستخدم شكلاً مستهدفًا صريحًا.
| الوسيطات | النوع | معاني |
|---|---|---|
shape |
Shape |
شكل الإخراج من النوع T |
operand |
XlaOp |
مصفوفة من النوع T |
Rev (عكس)
يمكنك الاطّلاع أيضًا على XlaBuilder::Rev.
Rev(operand, dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة من النوع T |
dimensions |
ArraySlice<int64> |
السمات المطلوب عكس ترتيبها |
تعكس هذه الدالة ترتيب العناصر في الصفيف operand على طول dimensions المحدّد، ما يؤدي إلى إنشاء صفيف إخراج بالشكل نفسه. يتم تخزين كل عنصر من عناصر مصفوفة المعامِلات في فهرس متعدّد الأبعاد في مصفوفة الإخراج عند فهرس تم تحويله. يتم تحويل الفهرس المتعدد الأبعاد من خلال عكس الفهرس في كل بُعد سيتم عكسه (أي إذا كان أحد أبعاد الحجم N هو أحد الأبعاد التي سيتم عكسها، سيتم تحويل الفهرس i إلى N - 1 - i).
أحد استخدامات العملية Rev هو عكس مصفوفة أوزان الالتفاف على طول بُعدَي النافذة أثناء حساب التدرّج في الشبكات العصبية.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - reverse.
RngNormal
يمكنك الاطّلاع أيضًا على XlaBuilder::RngNormal.
تنشئ هذه الدالة مصفوفة ذات شكل محدّد تتضمّن أرقامًا عشوائية تم إنشاؤها وفقًا \(N(\mu, \sigma)\) للتوزيع الطبيعي. يجب أن يكون للمَعلمتَين \(\mu\) و \(\sigma\)ولشكل الإخراج نوع أساسي من الفاصلة العائمة. يجب أن تكون المَعلمات أيضًا ذات قيمة عددية.
RngNormal(mu, sigma, shape)
| الوسيطات | النوع | معاني |
|---|---|---|
mu |
XlaOp |
عدد قياسي من النوع T يحدّد متوسط الأرقام التي تم إنشاؤها |
sigma
|
XlaOp
|
عدد قياسي من النوع T يحدّد الانحراف المعياري للقيمة التي تم إنشاؤها |
shape |
Shape |
شكل الإخراج من النوع T |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - rng.
RngUniform
يمكنك الاطّلاع أيضًا على XlaBuilder::RngUniform.
تنشئ هذه الدالة ناتجًا بالشكل المحدّد مع أرقام عشوائية تم إنشاؤها باتّباع التوزيع المنتظم على الفاصل الزمني \([a,b)\). يجب أن يكون نوع المَعلمات ونوع عنصر الإخراج نوعًا منطقيًا أو نوعًا متكاملاً أو نوعًا من أنواع الفاصلة العائمة، ويجب أن تكون الأنواع متسقة. لا تتوافق الخلفيات البرمجية لوحدة المعالجة المركزية ووحدة معالجة الرسومات حاليًا إلا مع F64 وF32 وF16 وBF16 وS64 وU64 وS32 وU32. بالإضافة إلى ذلك، يجب أن تكون المَعلمات ذات قيمة عددية. إذا \(b <= a\) كانت النتيجة محدّدة حسب التنفيذ.
RngUniform(a, b, shape)
| الوسيطات | النوع | معاني |
|---|---|---|
a |
XlaOp |
عدد قياسي من النوع T يحدّد الحد الأدنى للفترة |
b |
XlaOp |
قيمة عددية من النوع T تحدّد الحدّ الأعلى للفترة |
shape |
Shape |
شكل الإخراج من النوع T |
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - rng.
RngBitGenerator
يمكنك الاطّلاع أيضًا على XlaBuilder::RngBitGenerator.
تنشئ هذه العملية ناتجًا بالشكل المحدّد مملوءًا بوحدات بت عشوائية موحّدة باستخدام الخوارزمية المحدّدة (أو الإعداد التلقائي للخلفية) وتعرض حالة معدَّلة (بالشكل نفسه للحالة الأولية) والبيانات العشوائية التي تم إنشاؤها.
الحالة الأولية هي الحالة الأولية لإنشاء الرقم العشوائي الحالي. ويعتمد هذا الحقل والشكل المطلوب والقيم الصالحة على الخوارزمية المستخدَمة.
من المضمون أن يكون الناتج دالة قطعية للحالة الأولية، ولكن لا يمكن ضمان أن يكون الناتج قطعيًا بين الخلفيات وإصدارات مختلفة من برنامج الترجمة البرمجية.
RngBitGenerator(algorithm, initial_state, shape)
| الوسيطات | النوع | معاني |
|---|---|---|
algorithm |
RandomAlgorithm |
خوارزمية مولّد الأرقام العشوائية الزائفة التي سيتم استخدامها |
initial_state |
XlaOp |
الحالة الأولية لخوارزمية مولّد الأرقام العشوائية الزائفة |
shape |
Shape |
شكل الناتج للبيانات التي تم إنشاؤها |
القيم المتاحة لـ algorithm:
rng_default: خوارزمية خاصة بالخادم الخلفي مع متطلبات خاصة بالخادم الخلفي بشأن الشكل.rng_three_fry: خوارزمية ThreeFry المستندة إلى العداد لإنشاء أرقام عشوائية زائفة. يكون شكلinitial_stateهوu64[2]مع قيم عشوائية. Salmon et al. SC 2011. Parallel random numbers: as easy as 1, 2, 3.rng_philox: خوارزمية Philox لإنشاء أرقام عشوائية بالتوازي الشكلinitial_stateهوu64[3]مع قيم عشوائية. Salmon et al. SC 2011. أرقام عشوائية متوازية: سهلة وبسيطة.
لمزيد من المعلومات عن StableHLO، يُرجى الاطّلاع على StableHLO - rng_bit_generator.
RngGetAndUpdateState
يمكنك الاطّلاع أيضًا على HloInstruction::CreateRngGetAndUpdateState.
يتم تقسيم واجهة برمجة التطبيقات الخاصة بعمليات Rng المختلفة داخليًا إلى تعليمات HLO تتضمّن RngGetAndUpdateState.
تعمل RngGetAndUpdateState كعنصر أساسي في HLO. قد يظهر هذا الرمز في عمليات تفريغ HLO، ولكن ليس من المفترض أن ينشئه المستخدمون النهائيون يدويًا.
الدورة
يمكنك الاطّلاع أيضًا على XlaBuilder::Round.
التقريب حسب العناصر، مع إبعاد القيم المتساوية عن الصفر.
Round(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
RoundNearestAfz
يمكنك الاطّلاع أيضًا على XlaBuilder::RoundNearestAfz.
تنفيذ عملية تقريب على مستوى كل عنصر إلى أقرب عدد صحيح، مع حل حالات التعادل بعيدًا عن الصفر.
RoundNearestAfz(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - round_nearest_afz.
RoundNearestEven
يمكنك الاطّلاع أيضًا على XlaBuilder::RoundNearestEven.
التقريب حسب العنصر، ويتم التقريب إلى أقرب عدد زوجي.
RoundNearestEven(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - round_nearest_even.
Rsqrt
يمكنك الاطّلاع أيضًا على XlaBuilder::Rsqrt.
المعاملة بالمثل لكل عنصر من عملية الجذر التربيعي x -> 1.0 / sqrt(x).
Rsqrt(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Rsqrt أيضًا الوسيط الاختياري result_accuracy:
Rsqrt(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - rsqrt.
فحص
يمكنك الاطّلاع أيضًا على XlaBuilder::Scan.
تطبِّق دالة تقليل على صفيف في بُعد معيّن، ما يؤدي إلى إنشاء حالة نهائية وصفيف من القيم الوسيطة.
Scan(inputs..., inits..., to_apply, scan_dimension,
is_reverse, is_associative)
| الوسيطات | النوع | معاني |
|---|---|---|
inputs |
تسلسل m XlaOp |
مصفوفات البحث |
inits |
تسلسل k XlaOp |
عمليات النقل الأولية |
to_apply |
XlaComputation |
عملية حسابية من النوع i_0, ..., i_{m-1}, c_0, ..., c_{k-1} -> (o_0, ..., o_{n-1}, c'_0, ..., c'_{k-1}) |
scan_dimension |
int64 |
السمة المطلوب البحث فيها. |
is_reverse |
bool |
إذا كانت القيمة صحيحة، يتم البحث بترتيب عكسي. |
is_associative |
bool (ثلاثي الحالات) |
إذا كانت القيمة true، تكون العملية ترابطية. |
يتم تطبيق الدالة to_apply بالتسلسل على العناصر في inputs على طول scan_dimension. إذا كانت قيمة is_reverse هي false، تتم معالجة العناصر بالترتيب
0 إلى N-1، حيث N هو حجم scan_dimension. إذا كانت قيمة is_reverse هي
true، تتم معالجة العناصر من N-1 إلى 0.
تتضمّن الدالة to_apply معاملات m + k:
mالعناصر الحالية منinputs- تحمل
kقيمًا من الخطوة السابقة (أوinitsللعنصر الأول).
تعرض الدالة to_apply صفًا من قيم n + k:
nعناصر منoutputskقيم جديدة لحقائب السفر
تنتج عملية "الفحص" مجموعة من قيم n + k:
- مصفوفات الإخراج
nالتي تحتوي على قيم الإخراج لكل خطوة - تحتوي
kالنهائية على القيم بعد معالجة جميع العناصر.
يجب أن تتطابق أنواع مدخلات m مع أنواع المَعلمات الأولى m في to_apply مع بُعد مسح إضافي. ويجب أن تتطابق أنواع مخرجات n مع أنواع قيم الإرجاع الأولى n في to_apply مع بُعد مسح إضافي. ويجب أن يكون لبُعد المسح الإضافي بين جميع المدخلات والمخرجات الحجم نفسه N. ويجب أن تتطابق أنواع المَعلمات الأخيرة k وقيم الإرجاع في to_apply بالإضافة إلى عمليات التهيئة k.
على سبيل المثال (m, n, k == 1, N == 3)، بالنسبة إلى عملية الحمل الأولية i، أدخِل [a, b, c] والدالة f(x, c) -> (y, c') وscan_dimension=0 وis_reverse=false:
- الخطوة 0:
f(a, i) -> (y0, c0) - الخطوة 1:
f(b, c0) -> (y1, c1) - الخطوة 2:
f(c, c1) -> (y2, c2)
ناتج Scan هو ([y0, y1, y2], c2).
رسم بياني للنقاط المبعثرة
يمكنك الاطّلاع أيضًا على XlaBuilder::Scatter.
تنشئ عملية التشتيت في XLA تسلسلاً من النتائج التي تمثّل قيم الصفيف الإدخال operands، مع تعديل عدة شرائح (في الفهارس المحدّدة بواسطة scatter_indices) باستخدام تسلسل القيم في updates باستخدام update_computation.
Scatter(operands..., scatter_indices, updates..., update_computation,
dimension_numbers, indices_are_sorted, unique_indices)
| الوسيطات | النوع | معاني |
|---|---|---|
operands |
تسلسل N XlaOp |
مصفوفات N من النوع T_0, ..., T_N سيتم توزيعها. |
scatter_indices |
XlaOp |
مصفوفة تحتوي على فهارس البدء للشرائح التي يجب توزيعها. |
updates |
تسلسل N XlaOp |
مصفوفات N من النوع T_0, ..., T_N يحتوي updates[i] على القيم التي يجب استخدامها لتشتيت operands[i]. |
update_computation |
XlaComputation |
عملية حسابية تُستخدَم لدمج القيم الحالية في مصفوفة الإدخال والتعديلات أثناء التوزيع، ويجب أن يكون هذا الحساب من النوع T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N). |
index_vector_dim |
int64 |
السمة في scatter_indices التي تحتوي على فهارس البدء |
update_window_dims |
ArraySlice<int64> |
مجموعة السمات في شكل updates التي تمثّل سمات النافذة. |
inserted_window_dims |
ArraySlice<int64> |
مجموعة أبعاد النافذة التي يجب إدراجها في شكل updates |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
خريطة أبعاد من مؤشرات التشتت إلى مساحة فهرس المعامِل. يتم تفسير هذا الصفيف على أنّه ربط i بـ scatter_dims_to_operand_dims[i] . يجب أن تكون النسبة بينهما متطابقة وإجمالية. |
dimension_number |
ScatterDimensionNumbers |
أرقام السمات لعملية التشتيت |
indices_are_sorted |
bool |
ما إذا كان المتصل يضمن ترتيب الفهارس. |
unique_indices |
bool |
تحديد ما إذا كان المتصل يضمن أن تكون الفهارس فريدة. |
المكان:
- يجب أن تكون قيمة N أكبر من أو تساوي 1.
- يجب أن تتضمّن جميع السمات
operands[0]، ...،operands[N-1] الأبعاد نفسها. - يجب أن تتضمّن جميع السمات
updates[0]، ...،updates[N-1] الأبعاد نفسها. - إذا كان
N = 1، فإنّCollate(T)هوT. - إذا كان
N > 1،Collate(T_0, ..., T_N)عبارة عن مجموعة من عناصرNمن النوعT.
إذا كانت index_vector_dim تساوي scatter_indices.rank، نعتبر ضمنيًا أنّ scatter_indices يتضمّن بُعدًا لاحقًا 1.
نعرّف update_scatter_dims من النوع ArraySlice<int64> على أنّه مجموعة الأبعاد في شكل updates التي لا تندرج ضمن update_window_dims، بترتيب تصاعدي.
يجب أن تلتزم وسيطات الدالة scatter بالقيود التالية:
يجب أن تحتوي كل مصفوفة
updatesعلىupdate_window_dims.size + scatter_indices.rank - 1أبعاد.يجب أن تتوافق حدود السمة
iفي كل مصفوفةupdatesمع ما يلي:- إذا كان
iمتوفّرًا فيupdate_window_dims(أي يساويupdate_window_dims[k] لبعض قيمk)، يجب ألا يتجاوز الحدّ الخاص بالسمةiفيupdatesالحدّ المقابل فيoperandبعد أخذinserted_window_dimsفي الاعتبار (أيadjusted_window_bounds[k]، حيث يحتويadjusted_window_boundsعلى حدودoperandمع إزالة الحدود في الفهارسinserted_window_dims). - إذا كانت
iمتوفّرة فيupdate_scatter_dims(أي تساويupdate_scatter_dims[k] لبعض قيمk)، يجب أن يكون حد السمةiفيupdatesمساويًا لحد السمةscatter_indicesالمقابل، مع تخطّيindex_vector_dim(أيscatter_indices.shape.dims[k]، إذا كانتk<index_vector_dim، وscatter_indices.shape.dims[k+1] في الحالات الأخرى).
- إذا كان
يجب أن يكون
update_window_dimsبترتيب تصاعدي، وألا يتضمّن أي أرقام أبعاد متكرّرة، وأن يكون ضمن النطاق[0, updates.rank).يجب أن يكون
inserted_window_dimsبترتيب تصاعدي، وألا يتضمّن أي أرقام أبعاد متكرّرة، وأن يكون ضمن النطاق[0, operand.rank).يجب أن تساوي
operand.rankمجموعupdate_window_dims.sizeوinserted_window_dims.size.يجب أن تكون قيمة
scatter_dims_to_operand_dims.sizeمساويةً لقيمةscatter_indices.shape.dims[index_vector_dim]، ويجب أن تكون قيمهما ضمن النطاق[0, operand.rank).
بالنسبة إلى الفهرس U في كل مصفوفة updates، يتم احتساب الفهرس I المقابل في مصفوفة operands المقابلة التي يجب تطبيق هذا التعديل عليها على النحو التالي:
- لنفترض أنّ
G= {U[k] forkinupdate_scatter_dims}. استخدِمGللبحث عن متجه فهرسSفي مصفوفةscatter_indices، بحيث يكونS[i] =scatter_indices[Combine(G,i)]، حيث يؤدي Combine(A, b) إلى إدراج b في المواضعindex_vector_dimفي A. - أنشئ فهرسًا
SinفيoperandباستخدامSمن خلال التوزيعSباستخدام خريطةscatter_dims_to_operand_dims. بشكل أكثر رسمية:Sin[scatter_dims_to_operand_dims[k]] =S[k] ifk<scatter_dims_to_operand_dims.size.Sin[_] =0في الحالات الأخرى.
- أنشئ فهرسًا
Winفي كل مصفوفةoperandsمن خلال توزيع الفهارس فيupdate_window_dimsفيUوفقًا لـinserted_window_dims. بشكل أكثر رسمية:Win[window_dims_to_operand_dims(k)] =U[k] ifkis inupdate_window_dims, wherewindow_dims_to_operand_dimsis the monotonic function with domain [0,update_window_dims.size) and range [0,operand.rank) \inserted_window_dims. (على سبيل المثال، إذا كانت قيمةupdate_window_dims.sizeهي4، وقيمةoperand.rankهي6، وقيمةinserted_window_dimsهي {0،2}، ستكون قيمةwindow_dims_to_operand_dimsهي {0→1،1→3،2→4،3→5}).Win[_] =0في الحالات الأخرى.
-
IهيWin+Sinحيث + هي عملية جمع على مستوى العناصر.
باختصار، يمكن تعريف عملية التشتيت على النحو التالي.
- اضبط قيمة
outputعلىoperands، أي لكل الفهارسJ، ولكل الفهارسOفي مصفوفةoperands[J]:
output[J][O] =operands[J][O] - لكل فهرس
Uفي المصفوفةupdates[J] والفهرس المقابلOفي المصفوفةoperand[J]، إذا كانOفهرسًا صالحًا لـoutput:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
إنّ ترتيب تطبيق التعديلات غير محدّد، لذا عندما تشير فهارس متعددة في updates إلى الفهرس نفسه في operands، ستكون القيمة المقابلة في output غير محدّدة.
يُرجى العِلم أنّ المَعلمة الأولى التي يتم تمريرها إلى update_computation ستكون دائمًا القيمة الحالية من مصفوفة output، وستكون المَعلمة الثانية دائمًا القيمة من مصفوفة updates. وهذا مهم تحديدًا في الحالات التي تكون فيها update_computation غير تبادلية.
في حال ضبط indices_are_sorted على "صحيح"، يمكن أن يفترض XLA أنّ المستخدم رتّب scatter_indices (ترتيبًا تصاعديًا، بعد توزيع القيم وفقًا scatter_dims_to_operand_dims). إذا لم تكن كذلك، يتم تحديد الدلالات حسب التنفيذ.
إذا تم ضبط unique_indices على "صحيح"، يمكن أن يفترض XLA أنّ جميع العناصر التي يتم توزيعها فريدة، وبالتالي يمكن أن يستخدم عمليات غير ذرية. إذا تم ضبط unique_indices على "صحيح" وكانت الفهارس التي يتم توزيعها غير فريدة، سيتم تحديد الدلالات حسب التنفيذ.
بشكل غير رسمي، يمكن اعتبار عملية التوزيع عكسًا لعملية التجميع، أي أنّ عملية التوزيع تعدّل العناصر في الإدخال التي يتم استخراجها بواسطة عملية التجميع المقابلة.
للحصول على وصف غير رسمي مفصّل وأمثلة، يُرجى الرجوع إلى قسم "الوصف غير الرسمي" ضمن Gather.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - scatter.
Scatter - Example 1 - StableHLO

في الصورة أعلاه، يمثّل كل صف من الجدول مثالاً على فهرس تعديل. لنراجع الخطوات من اليسار(فهرس التعديل) إلى اليمين(فهرس النتيجة):
يكون شكل الإدخال) input هو S32[2,3,4,2]. ويكون شكل scatter_indices هو S64[2,2,3,2]. ويكون شكل updates هو S32[2,2,3,1,2].
تعديل الفهرس) كجزء من المدخلات التي يتم تزويدنا بها update_window_dims:[3,4]. يخبرنا ذلك أنّ البُعدَين 3 و4 في updates هما أبعاد النافذة، وهما مميّزان باللون الأصفر. يتيح لنا ذلك استنتاج أنّ update_scatter_dims = [0,1,2].
تعديل مؤشر التشتّت) يعرض updated_scatter_dims الذي تم استخراجه لكل منها.
(الخلايا غير الصفراء في عمود "تعديل المؤشر")
فهرس البداية) عند النظر إلى صورة scatter_indices tensor، يمكننا أن نرى أنّ القيم من الخطوة السابقة (تعديل فهرس التشتت) تمنحنا موقع فهرس البداية. من index_vector_dim، نعرف أيضًا بُعد starting_indices الذي يحتوي على فهارس البداية، وهو البُعد 3 بحجم 2 بالنسبة إلى scatter_indices.
يخبرنا Full Start Index) scatter_dims_to_operand_dims = [2,1] أنّ العنصر الأول من متجه الفهرس ينتقل إلى البُعد 2 الخاص بالمعامل، وأنّ العنصر الثاني من متجه الفهرس ينتقل إلى البُعد 1 الخاص بالمعامل، ويتم ملء أبعاد المعامل المتبقية بالقيمة 0.
مؤشر التجميع الكامل) يمكننا ملاحظة أنّ المنطقة المميّزة باللون الأرجواني تظهر في هذا العمود(مؤشر التجميع الكامل) وعمود مؤشر التشتت للتعديل وعمود مؤشر التعديل.
مؤشر النافذة الكاملة) يتم احتسابه من update_window_dimensions [3,4].
فهرس النتيجة) هو مجموع فهرس البداية الكامل وفهرس التجميع الكامل وفهرس النافذة الكاملة في موتر operand. لاحظ أنّ المناطق المميّزة باللون الأخضر تتوافق مع الشكل operand أيضًا. تم تخطّي الصف الأخير لأنّه يقع خارج موتر operand.
اختيار
يمكنك الاطّلاع أيضًا على XlaBuilder::Select.
تنشئ هذه الدالة مصفوفة إخراج من عناصر مصفوفتَي إدخال، استنادًا إلى قيم مصفوفة دالة منطقية.
Select(pred, on_true, on_false)
| الوسيطات | النوع | معاني |
|---|---|---|
pred |
XlaOp |
مصفوفة من النوع PRED |
on_true |
XlaOp |
مصفوفة من النوع T |
on_false |
XlaOp |
مصفوفة من النوع T |
يجب أن يكون للمصفوفتَين on_true وon_false الشكل نفسه، وهو أيضًا شكل مصفوفة الإخراج. يجب أن يكون للمصفوفة pred عدد الأبعاد نفسه كما في on_true وon_false، مع نوع العنصر PRED.
بالنسبة إلى كل عنصر P من pred، يتم أخذ العنصر المقابل من مصفوفة الإخراج من on_true إذا كانت قيمة P هي true، ومن on_false إذا كانت قيمة P هي false. بما أنّ pred هو شكل مقيّد من البث،
يمكن أن يكون عددًا قياسيًا من النوع PRED. في هذه الحالة، يتم أخذ مصفوفة الإخراج بالكامل من on_true إذا كانت قيمة pred هي true، ومن on_false إذا كانت قيمة pred هي false.
مثال على pred غير عددي:
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
مثال باستخدام pred:
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
يمكن إجراء عمليات اختيار بين الصفوف، ويتم اعتبار الصفوف من الأنواع العددية لهذا الغرض. إذا كان on_true وon_false صفوفًا (يجب أن يكون لهما الشكل نفسه)، يجب أن يكون pred عددًا من النوع PRED.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - select.
SelectAndScatter
يمكنك الاطّلاع أيضًا على XlaBuilder::SelectAndScatter.
يمكن اعتبار هذه العملية عملية مركّبة تحسب أولاً ReduceWindow على مصفوفة operand لاختيار عنصر من كل نافذة، ثم توزّع مصفوفة source على فهارس العناصر المحدّدة لإنشاء مصفوفة إخراج بالشكل نفسه لمصفوفة المعامِل. يتم استخدام الدالة الثنائية
select لاختيار عنصر من كل نافذة من خلال تطبيقها
على كل نافذة، ويتم استدعاؤها مع السمة التي يكون فيها متجه الفهرس الخاص بالمعلَمة الأولى
أصغر معجميًا من متجه الفهرس الخاص بالمعلَمة الثانية. تعرض الدالة select القيمة true إذا تم اختيار المَعلمة الأولى، وتعرض القيمة false إذا تم اختيار المَعلمة الثانية، ويجب أن تكون الدالة متعدية (أي إذا كانت select(a, b) وselect(b, c) هما true، ستكون select(a, c) أيضًا true) حتى لا يعتمد العنصر المحدّد على ترتيب العناصر التي تم اجتيازها لنافذة معيّنة.
يتم تطبيق الدالة scatter على كل فهرس محدّد في مصفوفة الإخراج، وهي تأخذ مَعلمتَين قياسيتَين:
- القيمة الحالية في الفهرس المحدّد في مصفوفة الإخراج
- قيمة التشتّت من
sourceالتي تنطبق على الفهرس المحدّد
تجمع هذه الدالة بين المَعلمتَين وتعرض قيمة عددية يتم استخدامها لتعديل القيمة في الفهرس المحدّد في مصفوفة الإخراج. في البداية، يتم ضبط جميع فهارس مصفوفة الإخراج على init_value.
تتضمّن مصفوفة الإخراج الشكل نفسه لمصفوفة operand، ويجب أن تتضمّن مصفوفة source الشكل نفسه لنتيجة تطبيق عملية ReduceWindow على مصفوفة operand. يمكن استخدام SelectAndScatter لإجراء عملية الانتشار العكسي لقيم التدرّج لطبقة تجميع في شبكة عصبية.
SelectAndScatter(operand, select, window_dimensions, window_strides, padding,
source, init_value, scatter)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp
|
مصفوفة من النوع T يتم تحريك النوافذ عليها |
select
|
XlaComputation
|
عملية حسابية ثنائية من النوع T, T
-> PRED، يتم تطبيقها على جميع العناصر في كل نافذة، وتعرض true إذا تم اختيار المَعلمة الأولى، وتعرض false إذا تم اختيار المَعلمة الثانية |
window_dimensions
|
ArraySlice<int64>
|
مصفوفة أعداد صحيحة لقيم سمات النافذة |
window_strides
|
ArraySlice<int64>
|
مصفوفة أعداد صحيحة لقيم خطوة النافذة |
padding
|
Padding
|
نوع المساحة المتروكة للنافذة (Padding::kSame أو Padding::kValid) |
source
|
XlaOp
|
مصفوفة من النوع T تتضمّن القيم المطلوب توزيعها |
init_value
|
XlaOp
|
قيمة عددية من النوع T للقيمة الأولية لمصفوفة الإخراج |
scatter
|
XlaComputation
|
الحساب الثنائي من النوع T, T
-> T، لتطبيق كل عنصر من عناصر مصدر التشتت مع عنصر الوجهة |
يعرض الشكل أدناه أمثلة على استخدام SelectAndScatter، مع احتساب الدالة select
للقيمة القصوى بين مَعلماتِها. تجدر الإشارة إلى أنّه عند تداخل النوافذ، كما هو موضّح في الشكل (2) أدناه، قد يتم اختيار فهرس مصفوفة operand عدة مرات من خلال نوافذ مختلفة. في الشكل، يتم اختيار العنصر ذو القيمة 9 من خلال كلتا النافذتين العلويتين (الأزرق والأحمر)، وتنتج دالة الجمع الثنائي scatter العنصر الناتج ذو القيمة 8 (2 + 6).
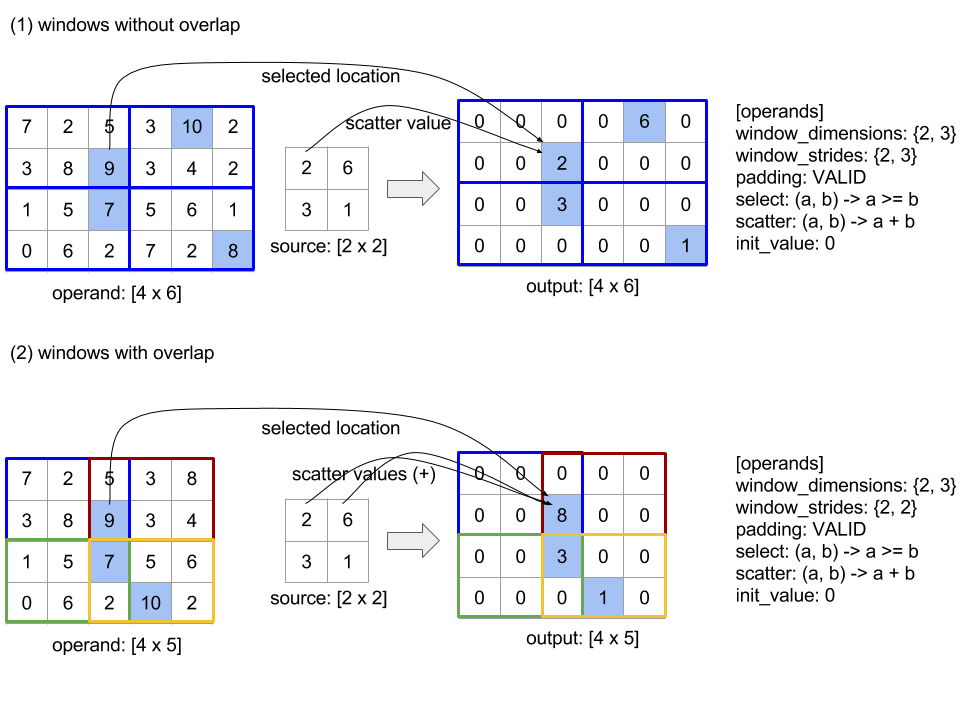
إنّ ترتيب تقييم الدالة scatter هو ترتيب عشوائي وقد يكون غير قطعي. لذلك، يجب ألا تكون وظيفة scatter حساسة بشكل مفرط
لعملية إعادة الربط. يمكنك الاطّلاع على المناقشة حول الترابط في سياق Reduce لمزيد من التفاصيل.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - select_and_scatter.
إرسال
يمكنك الاطّلاع أيضًا على XlaBuilder::Send.
Send وSendWithTokens وSendToHost هي عمليات تعمل كعناصر أساسية للتواصل في HLO. تظهر هذه العمليات عادةً في عمليات تفريغ HLO كجزء من عمليات الإدخال/الإخراج المنخفضة المستوى أو عمليات النقل التي تعمل من خلال جهاز آخر، ولكن ليس من المفترض أن ينشئها المستخدمون النهائيون يدويًا.
Send(operand, handle)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
البيانات المطلوب إرسالها (مصفوفة من النوع T) |
handle |
ChannelHandle |
معرّف فريد لكل زوج إرسال/استلام |
يرسل بيانات المعامِل المحدّدة إلى تعليمات Recv في عملية حسابية أخرى تشارك معرّف القناة نفسه. لا تعرض أي بيانات.
على غرار عملية Recv، تمثّل واجهة برمجة التطبيقات الخاصة بالعميل لعملية Send عملية اتصال متزامن، ويتم تقسيمها داخليًا إلى تعليمتَين من تعليمات HLO (Send وSendDone) لتفعيل عمليات نقل البيانات غير المتزامنة. يمكنك الاطّلاع أيضًا على HloInstruction::CreateSend وHloInstruction::CreateSendDone.
Send(HloInstruction operand, int64 channel_id)
يبدأ عملية نقل غير متزامنة للمعامل إلى الموارد التي خصّصتها التعليمات Recv باستخدام رقم تعريف القناة نفسه. تعرض هذه الدالة سياقًا تستخدمه التعليمات SendDone التالية لانتظار اكتمال عملية نقل البيانات. السياق هو مجموعة من {المعامل (الشكل) ومعرّف الطلب (U32)} ويمكن استخدامه فقط من خلال التعليمات SendDone.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - send.
SendDone
يمكنك الاطّلاع أيضًا على HloInstruction::CreateSendDone.
SendDone(HloInstruction context)
بالنظر إلى السياق الذي تم إنشاؤه بواسطة تعليمات Send، ينتظر اكتمال عملية نقل البيانات. لا تعرض التعليمات أي بيانات.
جدولة تعليمات القناة
يكون ترتيب تنفيذ التعليمات الأربع لكل قناة (Recv وRecvDone وSend وSendDone) كما هو موضّح أدناه.
- يحدث
RecvقبلSend - يحدث
SendقبلRecvDone - يحدث
RecvقبلRecvDone - يحدث
SendقبلSendDone
عندما تنشئ برامج الترجمة الخلفية جدولاً زمنيًا خطيًا لكل عملية حسابية تتواصل عبر تعليمات القناة، يجب ألا تكون هناك دورات في العمليات الحسابية. على سبيل المثال، تؤدي الجداول الزمنية أدناه إلى حدوث حالات توقّف تام.
SetDimensionSize
يمكنك الاطّلاع أيضًا على XlaBuilder::SetDimensionSize.
تضبط هذه السمة الحجم الديناميكي للبعد المحدّد في XlaOp. يجب أن يكون المعامِل على شكل مصفوفة.
SetDimensionSize(operand, val, dimension)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة إدخال ذات n أبعاد |
val |
XlaOp |
عدد صحيح 32 بت يمثّل الحجم الديناميكي لوقت التشغيل. |
dimension
|
int64
|
قيمة في الفاصل الزمني [0, n) تحدّد السمة. |
يتم تمرير المعامِل كنتيجة، مع تتبُّع السمة الديناميكية من خلال المترجم.
سيتم تجاهل القيم المضافة من خلال عمليات تقليل عدد الأبعاد اللاحقة.
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
ShiftLeft
يمكنك الاطّلاع أيضًا على XlaBuilder::ShiftLeft.
تُجري عملية إزاحة إلى اليسار على مستوى كل عنصر في lhs بمقدار rhs من وحدات البت.
ShiftLeft(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر إصدار بديل من ShiftLeft يتوافق مع البث بأبعاد مختلفة:
ShiftLeft(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - shift_left.
ShiftRightArithmetic
يمكنك الاطّلاع أيضًا على XlaBuilder::ShiftRightArithmetic.
تُجري عملية إزاحة حسابية لليمين على مستوى كل عنصر في lhs بمقدار rhs من وحدات البت.
ShiftRightArithmetic(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر خيار بديل مع إمكانية البث بأبعاد مختلفة للدالة ShiftRightArithmetic:
ShiftRightArithmetic(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - shift_right_arithmetic.
ShiftRightLogical
يمكنك الاطّلاع أيضًا على XlaBuilder::ShiftRightLogical.
تُجري عملية إزاحة منطقية لليمين على مستوى العناصر في lhs بمقدار rhs من وحدات البت.
ShiftRightLogical(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل من ShiftRightLogical يتيح البث بأبعاد مختلفة:
ShiftRightLogical(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - shift_right_logical.
العلامة
يمكنك الاطّلاع أيضًا على XlaBuilder::Sign.
Sign(operand) عملية الإشارة على مستوى العنصر x -> sgn(x) حيث
\[\text{sgn}(x) = \begin{cases} -1 & x < 0\\ -0 & x = -0\\ NaN & x = NaN\\ +0 & x = +0\\ 1 & x > 0 \end{cases}\]
باستخدام عامل المقارنة لنوع العنصر operand.
Sign(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
للحصول على معلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - sign.
الخطيئة
Sin(operand) دالة الجيب لكل عنصر x -> sin(x)
يمكنك الاطّلاع أيضًا على XlaBuilder::Sin.
Sin(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Sin أيضًا استخدام الوسيطة الاختيارية result_accuracy:
Sin(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - sine.
شريحة
يمكنك الاطّلاع أيضًا على XlaBuilder::Slice.
يستخرج التقطيع مصفوفة فرعية من مصفوفة الإدخال، وتتضمّن المصفوفة الفرعية عددًا مماثلاً من الأبعاد كما في مصفوفة الإدخال، كما تتضمّن القيم داخل مربّع محيطي ضمن مصفوفة الإدخال، حيث يتم تقديم أبعاد المربّع المحيطي وفهارسه كمعلمات لعملية التقطيع.
Slice(operand, start_indices, limit_indices, strides)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
مصفوفة N ذات أبعاد من النوع T |
start_indices
|
ArraySlice<int64>
|
قائمة تتضمّن N عددًا صحيحًا يحتوي على فهارس البدء الخاصة بالشريحة لكل بُعد، ويجب أن تكون القيم أكبر من أو تساوي صفرًا. |
limit_indices
|
ArraySlice<int64>
|
قائمة تتضمّن N عددًا صحيحًا يحتوي على فهارس النهاية (غير شاملة) لشريحة كل سمة. يجب أن تكون كل قيمة أكبر من أو تساوي قيمة start_indices الخاصة بالسمة وأقل من أو تساوي حجم السمة. |
strides
|
ArraySlice<int64>
|
قائمة من N أعداد صحيحة تحدّد خطوة الإدخال للشريحة. تختار الشريحة كل عنصر strides[d] في السمة d. |
مثال أحادي الأبعاد:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4})
// Result: {2.0, 3.0}
مثال ثنائي الأبعاد:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3})
// Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - slice.
ترتيب
يمكنك الاطّلاع أيضًا على XlaBuilder::Sort.
Sort(operands, comparator, dimension, is_stable)
| الوسيطات | النوع | معاني |
|---|---|---|
operands |
ArraySlice<XlaOp> |
المعاملات التي سيتم ترتيبها. |
comparator |
XlaComputation |
عملية المقارنة المطلوب استخدامها. |
dimension |
int64 |
السمة التي سيتم الفرز وفقًا لها. |
is_stable |
bool |
ما إذا كان يجب استخدام الترتيب الثابت. |
في حال توفير عامل واحد فقط:
إذا كان المعامِل عبارة عن موتر أحادي البُعد (صفيف)، تكون النتيجة صفيفًا مرتّبًا. إذا أردت ترتيب المصفوفة بترتيب تصاعدي، يجب أن تنفّذ الدالة المقارنة عملية مقارنة "أصغر من". بشكل رسمي، بعد ترتيب المصفوفة، يتم تطبيق ذلك على جميع مواضع الفهرس
i, jالتي تتضمّنi < jالتي تكون إماcomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseأوcomparator(value[i], value[j]) = true.إذا كان للمعامل عدد أكبر من السمات، يتم ترتيب المعامل حسب السمة المقدَّمة. على سبيل المثال، بالنسبة إلى موتر ثنائي الأبعاد (مصفوفة)، ستؤدي قيمة البُعد
0إلى ترتيب كل عمود بشكل مستقل، وستؤدي قيمة البُعد1إلى ترتيب كل صف بشكل مستقل. في حال عدم توفير رقم البُعد، سيتم اختيار البُعد الأخير تلقائيًا. بالنسبة إلى السمة التي يتم ترتيبها، ينطبق ترتيب الفرز نفسه كما في الحالة أحادية البُعد.
في حال توفير معاملات n > 1:
يجب أن تكون جميع معاملات
nعبارة عن موترات لها الأبعاد نفسها، ولكن قد تختلف أنواع العناصر في الموترات.يتم ترتيب جميع المعامِلات معًا، وليس بشكلٍ فردي. من الناحية المفاهيمية، يتم التعامل مع المعامِلات كصفوف. عند التحقّق مما إذا كان يجب تبديل عناصر كل معامل في مواضع الفهرس
iوj، يتم استدعاء أداة المقارنة باستخدام المَعلمات العددية2 * n، حيث تتوافق المَعلمة2 * kمع القيمة في الموضعiمن المعاملk-th، وتتوافق المَعلمة2 * k + 1مع القيمة في الموضعjمن المعاملk-th. عادةً، يقارن عامل المقارنة المَعلمتَين2 * kو2 * k + 1ببعضهما البعض، وقد يستخدم أزواجًا أخرى من المَعلمات لتحديد الفائز في حال التعادل.والنتيجة هي مجموعة من القيم تتألف من المعامِلات بالترتيب المصنّف (على طول السمة المقدَّمة، كما هو موضّح أعلاه). يتوافق المعامل
i-thالخاص بالصف مع المعاملi-thالخاص بـ Sort.
على سبيل المثال، إذا كانت هناك ثلاث معاملات operand0 = [3, 1] وoperand1 = [42, 50] وoperand2 = [-3.0, 1.1]، وكان عامل المقارنة يقارن قيم operand0 فقط باستخدام علامة أصغر من، يكون الناتج من عملية الترتيب هو المجموعة ([1, 3], [50, 42], [1.1, -3.0]).
إذا تم ضبط is_stable على "صحيح"، سيتم ضمان أن يكون الترتيب ثابتًا، أي أنّه إذا كانت هناك عناصر يعتبرها عامل المقارنة متساوية، سيتم الحفاظ على الترتيب النسبي للقيم المتساوية. يتساوى العنصران e1 وe2 إذا وفقط إذا كان comparator(e1, e2) = comparator(e2, e1) = false. تكون القيمة التلقائية لـ is_stable هي false.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - sort.
Sqrt
يمكنك الاطّلاع أيضًا على XlaBuilder::Sqrt.
عملية الجذر التربيعي لكل عنصر x -> sqrt(x).
Sqrt(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Sqrt أيضًا الوسيطة الاختيارية result_accuracy:
Sqrt(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - sqrt.
فرعي
يمكنك الاطّلاع أيضًا على XlaBuilder::Sub.
تُجري هذه الدالة عملية طرح على مستوى العناصر بين lhs وrhs.
Sub(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بالشكل الناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر إصدار بديل من الترجمة والشرح يدعم البث بأبعاد مختلفة للفيديو الفرعي:
Sub(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - subtract.
تاني
يمكنك الاطّلاع أيضًا على XlaBuilder::Tan.
ظلّ كل عنصر x -> tan(x)
Tan(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة tan أيضًا الوسيطة الاختيارية result_accuracy:
Tan(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - tan.
Tanh
يمكنك الاطّلاع أيضًا على XlaBuilder::Tanh.
دالة الظل الزائدي x -> tanh(x) لكل عنصر.
Tanh(operand)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
تتيح الدالة Tanh أيضًا الوسيطة الاختيارية result_accuracy:
Tanh(operand, result_accuracy)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل الخاص بالدالة |
result_accuracy
|
اختياري ResultAccuracy
|
أنواع الدقة التي يمكن للمستخدم طلبها للعمليات الأحادية التي تتضمّن عمليات تنفيذ متعددة |
لمزيد من المعلومات حول result_accuracy، يُرجى الاطّلاع على مقالة
دقة النتائج.
لمزيد من المعلومات عن StableHLO، يُرجى الاطّلاع على StableHLO - tanh.
TopK
يمكنك الاطّلاع أيضًا على XlaBuilder::TopK.
تعثر الدالة TopK على قيم ومؤشرات k أكبر أو أصغر عناصر في آخر بُعد من الموتر المحدّد.
TopK(operand, k, largest)
| الوسيطات | النوع | معاني |
|---|---|---|
operand
|
XlaOp
|
الموتّر الذي سيتم استخراج أفضل k عناصر منه.
يجب أن يكون للمتّجه متعدّد الأبعاد عدد من الأبعاد أكبر من أو يساوي واحدًا. يجب أن يكون حجم آخر بُعد في الموتر أكبر من أو يساوي k. |
k |
int64 |
عدد العناصر المطلوب استخراجها. |
largest
|
bool
|
لتحديد ما إذا كان سيتم استخراج أكبر أو أصغر k عناصر. |
بالنسبة إلى متّجه متعدّد الأبعاد إدخال أحادي البُعد (مصفوفة)، يتم العثور على k أكبر أو أصغر إدخالات في المصفوفة ويتم عرض مجموعة من مصفوفتَين (values, indices). وبالتالي، فإنّ values[j] هو الإدخال رقم j الأكبر/الأصغر في operand، وفهرسه هو indices[j].
بالنسبة إلى موتر إدخال يتضمّن أكثر من بُعد واحد، يتم احتساب أعلى k إدخالات
على طول البُعد الأخير، مع الحفاظ على جميع الأبعاد الأخرى (الصفوف) في الناتج.
وبالتالي، بالنسبة إلى عامل بشكل [A, B, ..., P, Q] حيث Q >= k يكون الناتج
عبارة عن مجموعة (values, indices) حيث:
values.shape = indices.shape = [A, B, ..., P, k]
إذا كان هناك عنصران متساويان في صف واحد، سيظهر العنصر ذو الفهرس الأقل أولاً.
تبديل
راجِع أيضًا عملية tf.reshape.
Transpose(operand, permutation)
| الوسيطات | النوع | معاني |
|---|---|---|
operand |
XlaOp |
المعامل المطلوب تبديل موضع عناصره. |
permutation |
ArraySlice<int64> |
كيفية تبديل ترتيب الأبعاد |
تبدّل ترتيب أبعاد المعامِل باستخدام التبديل المحدد، وبالتالي
∀ i . 0 ≤ i < number of dimensions ⇒
input_dimensions[permutation[i]] = output_dimensions[i].
وهذا هو نفسه Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions)).
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - transpose.
TriangularSolve
يمكنك الاطّلاع أيضًا على XlaBuilder::TriangularSolve.
تحلّ هذه الدالة أنظمة المعادلات الخطية ذات معاملات المصفوفات المثلثية السفلية أو العلوية باستخدام التعويض الأمامي أو الخلفي. ومن خلال البث على طول الأبعاد الرئيسية، تحلّ هذه الدالة أحد أنظمة المصفوفات op(a) * x =
b أو x * op(a) = b للمتغير x، مع الأخذ في الاعتبار a وb، حيث op(a) هي إما op(a) = a أو op(a) = Transpose(a) أو op(a) = Conj(Transpose(a)).
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| الوسيطات | النوع | معاني |
|---|---|---|
a
|
XlaOp
|
مصفوفة ذات أكثر من بُعدَين من نوع عدد مركّب أو
نقطة عائمة بالشكل [..., M,
M]. |
b
|
XlaOp
|
مصفوفة ذات أكثر من بُعدَين من النوع نفسه
بالشكل [..., M, K] إذا كانت قيمة left_side
صحيحة، أو [..., K, M] في الحالات الأخرى. |
left_side
|
bool
|
تشير إلى ما إذا كان سيتم حل نظام من النموذج op(a) * x = b (true) أو x *
op(a) = b (false). |
lower
|
bool
|
تحديد ما إذا كان سيتم استخدام المثلث العلوي أو السفلي من a |
unit_diagonal
|
bool
|
إذا كانت القيمة true، سيتم افتراض أنّ العناصر القطرية في a هي 1 ولن يتم الوصول إليها. |
transpose_a
|
Transpose
|
ما إذا كان يجب استخدام a كما هو أو تبديل صفوفه بأعمدته أو
أخذ تبديل صفوفه بأعمدته المقترن. |
تتم قراءة بيانات الإدخال من المثلث السفلي/العلوي فقط من a، وذلك حسب قيمة lower. ويتم تجاهل القيم من المثلث الآخر. ويتم عرض بيانات الإخراج في المثلث نفسه، وتكون القيم في المثلث الآخر غير محدّدة في التنفيذ وقد تكون أي شيء.
إذا كان عدد أبعاد a وb أكبر من 2، يتم التعامل معها كمجموعات من المصفوفات، حيث تكون جميع الأبعاد باستثناء البُعدَين الثانويَين عبارة عن أبعاد مجمّعة. يجب أن يكون لـ a وb أبعاد دفعية متساوية.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - triangular_solve.
Tuple
يمكنك الاطّلاع أيضًا على XlaBuilder::Tuple.
مجموعة تحتوي على عدد متغير من معرّفات البيانات، ولكل منها شكل خاص.
Tuple(elements)
| الوسيطات | النوع | معاني |
|---|---|---|
elements |
متّجه XlaOp |
مصفوفة N من النوع T |
وهذا مشابه لـ std::tuple في C++. من الناحية النظرية:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
يمكن تفكيك الصفوف (الوصول إليها) من خلال عملية GetTupleElement.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - tuple.
في حين
يمكنك الاطّلاع أيضًا على XlaBuilder::While.
While(condition, body, init)
| الوسيطات | النوع | معاني |
|---|---|---|
condition
|
XlaComputation
|
XlaComputation من النوع T -> PRED الذي يحدّد شرط إنهاء الحلقة. |
body
|
XlaComputation
|
XlaComputation من النوع T -> T الذي يحدد نص الحلقة. |
init
|
T
|
القيمة الأولية لمَعلمة
condition وbody |
يتم تنفيذ body بالتسلسل إلى أن يتعذّر تنفيذ condition. وهي تشبه حلقة while النموذجية في العديد من اللغات الأخرى، باستثناء الاختلافات والقيود المذكورة أدناه.
- تعرض عقدة
Whileقيمة من النوعT، وهي النتيجة من آخر تنفيذ لـbody. - يتم تحديد شكل النوع
Tبشكل ثابت ويجب أن يكون هو نفسه في جميع التكرارات.
يتم إعداد مَعلمات T الخاصة بالحسابات باستخدام القيمة init في التكرار الأول، ويتم تعديلها تلقائيًا إلى النتيجة الجديدة من body في كل تكرار لاحق.
تتمثّل إحدى حالات الاستخدام الرئيسية للعقدة While في تنفيذ التدريب بشكل متكرّر في الشبكات العصبية. يظهر أدناه رمز زائف مبسط مع رسم بياني يمثّل العملية الحسابية. يمكنك العثور على الرمز في
while_test.cc.
النوع T في هذا المثال هو Tuple يتألف من int32 لعدد التكرارات وvector[10] للمراكم. بالنسبة إلى 1000 تكرار، تستمر الحلقة في إضافة متجه ثابت إلى المجمّع.
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - while.
Xor
يمكنك الاطّلاع أيضًا على XlaBuilder::Xor.
تُجري عملية XOR على مستوى العناصر في lhs وrhs.
Xor(lhs, rhs)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
يجب أن تكون أشكال الوسيطات متشابهة أو متوافقة. راجِع مستندات البث لمعرفة معنى توافق الأشكال. تكون نتيجة العملية بشكل ناتج عن بث الصفيفَين المدخلَين. في هذا النوع، لا يمكن إجراء عمليات بين مصفوفات ذات ترتيبات مختلفة، إلا إذا كان أحد المعامِلَين عددًا قياسيًا.
يتوفّر نوع بديل من Xor يتيح البث بأبعاد مختلفة:
Xor(lhs,rhs, broadcast_dimensions)
| الوسيطات | النوع | معاني |
|---|---|---|
| lhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| rhs | XlaOp | المعامل الأيمن: مصفوفة من النوع T |
| broadcast_dimension | ArraySlice |
تحديد البُعد في الشكل المستهدف الذي يتطابق مع كل بُعد في شكل المعامِل |
يجب استخدام هذا النوع من العملية للعمليات الحسابية بين مصفوفات ذات ترتيبات مختلفة (مثل إضافة مصفوفة إلى متّجه).
معامل broadcast_dimensions الإضافي هو شريحة من الأعداد الصحيحة تحدّد الأبعاد التي سيتم استخدامها لبث المعامِلات. يتم وصف الدلالات بالتفصيل في صفحة البث.
لمزيد من المعلومات حول StableHLO، يُرجى الاطّلاع على StableHLO - xor.