
HLO 색인 분석은 '색인 맵'을 통해 한 텐서의 요소가 다른 텐서와 어떻게 관련되는지 설명하는 데이터 흐름 분석입니다. 예를 들어 HLO 명령어 출력의 색인이 HLO 명령어 피연산자의 색인에 매핑되는 방식입니다.
예
tensor<20xf32>에서 tensor<10x20x30xf32>로 방송
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
출력에서 입력으로의 색인 생성 맵은 i in
[0, 10], j in [0, 20], k in [0, 30]의 경우 (i, j, k) -> (j)입니다.
동기
XLA는 여러 맞춤 솔루션을 사용하여 병합, 피연산자 활용, 타일링 스키마를 추론합니다 (자세한 내용은 아래 참고). 색인 분석의 목표는 이러한 사용 사례에 재사용 가능한 구성요소를 제공하는 것입니다. 인덱싱 분석은 MLIR의 어파인 맵 인프라를 기반으로 빌드되며 HLO 시맨틱을 추가합니다.
병합
입력의 어떤 요소/슬라이스가 출력의 요소를 계산하기 위해 읽히는지 알면 사소하지 않은 경우에 메모리 병합에 관한 추론이 가능해집니다.
피연산자 사용률
XLA의 피연산자 활용률은 명령의 출력이 완전히 사용된다고 가정할 때 명령의 각 입력이 얼마나 사용되는지를 나타냅니다. 현재 일반적인 경우에도 사용률이 계산되지 않습니다. 색인 분석을 통해 사용률을 정확하게 계산할 수 있습니다.
타일식:
타일/슬라이스는 오프셋, 크기, 스트라이드로 매개변수화된 텐서의 초직사각형 하위 집합입니다. 타일 전파는 작업 자체의 타일링 매개변수를 사용하여 작업의 생산자/소비자의 타일 매개변수를 계산하는 방법입니다. softmax 및 dot에 대해 이를 실행하는 라이브러리가 이미 있습니다. 타일 전파는 색인 지도로 표현되는 경우 더 일반적이고 강력해질 수 있습니다.
색인 생성 지도
색인 지도는 다음의 조합입니다.
- 하나의 텐서
A의 모든 요소를 텐서B의 요소 범위에 매핑하는 기호로 표현된 함수 - 함수의 도메인을 비롯한 유효한 함수 인수에 대한 제약 조건
함수 인수는 그 특성을 더 잘 전달하기 위해 3가지 카테고리로 나뉩니다.
텐서
A또는 매핑하는 GPU 그리드의 측정기준 변수입니다. 값은 정적으로 알려져 있습니다. 색인 요소를 측정기준 변수라고도 합니다.range 변수 일대다 매핑을 정의하고
A의 단일 값을 계산하는 데 사용되는B의 요소 집합을 지정합니다. 값은 정적으로 알려져 있습니다. 행렬 곱셈의 축소 차원은 범위 변수의 예입니다.실행 중에만 알 수 있는 런타임 변수 예를 들어 gather 작업의 indices 인수입니다.
함수의 결과는 타겟 B 텐서의 색인입니다.
간단히 말해 작업 x의 텐서 A에서 텐서 B로의 색인 함수는 다음과 같습니다.
map_ab(index in A, range variables, runtime variables) -> index in B.
매핑 인수 유형을 더 잘 구분하기 위해 다음과 같이 작성합니다.
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
예를 들어 reduce 작업 f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}의 색인 지도를 살펴보겠습니다.
in의 요소를out에 매핑하는 함수는(d0, d1, d2, d3) -> (d1, d2)로 표현할 수 있습니다.d0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]변수의 제약 조건은in의 모양에 의해 정의됩니다.out의 요소를in에 매핑하려면out에 두 개의 차원만 있고 감소로 감소하는 차원을 포함하는 두 개의 범위 변수가 도입됩니다. 따라서 매핑 함수는(d0, d1)[s0, s1] -> (s0, d0, d1, s1)입니다. 여기서(d0, d1)은out의 색인입니다.s0,s1은 작업의 시맨틱으로 정의된 범위이며in텐서의 차원 0과 3에 걸쳐 있습니다. 제약 조건은d0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15]입니다.
대부분의 시나리오에서 출력의 요소를 매핑하는 데 관심이 있다는 점에 유의해야 합니다. 계산용
C = op1(A, B)
E = op2(C, D)
'B의 색인 생성'은 'E의 요소를 B의 요소에 매핑'을 의미합니다. 이는 입력에서 출력으로 작동하는 다른 유형의 데이터 흐름 분석과 비교할 때 직관적이지 않을 수 있습니다.
변수에 대한 제약 조건을 사용하면 최적화 기회를 활용하고 코드 생성에 도움이 됩니다. 문서와 구현에서 제약 조건은 매핑 함수의 모든 유효한 조합 또는 인수 값을 정의하므로 도메인이라고도 합니다. 많은 작업에서 제약 조건은 텐서의 차원을 설명하지만 일부 작업에서는 더 복잡할 수 있습니다. 아래의 예를 참고하세요.
함수와 인수 제약 조건을 기호로 표현하고 함수와 제약 조건을 결합할 수 있으므로 임의의 대규모 계산 (융합)을 위한 간결한 색인 매핑을 계산할 수 있습니다.
기호 함수와 제약 조건의 표현력은 구현 복잡성과 더 정확한 표현에서 얻는 최적화 이점 간의 균형입니다. 일부 HLO 작업의 경우 액세스 패턴을 대략적으로만 포착합니다.
구현
재계산을 최소화하려면 기호 계산을 위한 라이브러리가 필요합니다. XLA는 이미 MLIR에 종속되어 있으므로 또 다른 기호 산술 라이브러리를 작성하는 대신 mlir::AffineMap을 사용합니다.
일반적인 AffineMap는 다음과 같습니다.
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap에는 측정기준과 기호라는 두 가지 유형의 매개변수가 있습니다.
측정기준은 측정기준 변수 d에 해당하고 기호는 범위 변수 r 및 런타임 변수 rt에 해당합니다. AffineMap에는 매개변수의 제약 조건에 관한 메타데이터가 포함되어 있지 않으므로 별도로 제공해야 합니다.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_는 일반적으로 전치, 축소, 요소별, 점과 같은 작업의 출력 텐서 모양과 일치하는 인덱싱 맵의 차원 변수 d의 포함 상자 제약 조건을 인코딩합니다. 하지만 HloConcatenateInstruction과 같은 예외도 있습니다.
range_vars_ 범위 변수 s가 취하는 모든 값 범위 변수는 매핑하는 텐서의 단일 요소를 계산하는 데 여러 값이 필요한 경우에 필요합니다(예: 축소의 output->input 색인 매핑 또는 브로드캐스트의 input->output 매핑).
rt_vars_ 런타임에 가능한 값을 인코딩합니다. 예를 들어 1D HloDynamicSliceInstruction의 오프셋은 동적입니다. 해당 RTVar의 실행 가능한 값은 0~tensor_size - slice_size - 1입니다.
constraints_는 <expression> in <range> 형식의 값 간 관계를 캡처합니다(예: d0 + s0 in [0, 20]). Variable.bounds와 함께 색인 함수 '도메인'을 정의합니다.
위의 내용이 실제로 무엇을 의미하는지 예시를 통해 알아보겠습니다.
융합되지 않은 작업의 지도 색인 생성
요소별
요소별 작업의 경우 색인 생성 맵은 ID입니다.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
입력에 대한 출력 매핑 output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
입력-출력 맵 p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
방송
브로드캐스팅은 출력을 입력에 매핑할 때 일부 차원이 삭제되고 입력을 출력에 매핑할 때 추가된다는 것을 의미합니다.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
출력-입력 맵:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
입력-출력 맵은 다음과 같습니다.
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
이제 입력-출력 매핑의 오른쪽에 범위 변수 s가 있습니다. 이러한 기호는 값의 범위를 나타냅니다.
예를 들어 이 특정 사례에서는 색인 d0이 있는 입력의 모든 요소가 출력의 10x1x30 슬라이스에 매핑됩니다.
Iota
Iota에는 입력 텐서 피연산자가 없으므로 입력 인덱스 인수가 없습니다.
iota = f32[2,4] iota(), dimensions={1}
입력 맵으로 출력:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
입력에서 출력으로의 매핑:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice에는 런타임에만 알려진 오프셋이 있습니다.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
ds에서 src로의 출력-입력 매핑:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
이제 입력-출력 매핑을 위해 오른쪽에 rt가 있습니다.
이러한 기호는 런타임 값을 나타냅니다. 예를 들어 이 특정 사례에서 d0, d1, d2 인덱스가 있는 출력의 모든 요소에 대해 슬라이스 오프셋 of1, of2, of3에 액세스하여 입력의 인덱스를 계산합니다.
런타임 변수의 간격은 전체 슬라이스가 범위 내에 있다고 가정하여 파생됩니다.
of1, of2, of3의 출력-입력 맵:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
src의 출력-입력 맵은 사소합니다. 도메인을 업데이트되지 않은 색인으로 제한하면 더 정확해질 수 있지만 현재 색인 매핑은 부등식 제약 조건을 지원하지 않습니다.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
upd의 출력-입력 맵은 다음과 같습니다.
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
이제 런타임 값을 나타내는 rt0와 rt1가 있습니다. 이 특정 사례에서는 d0, d1 인덱스가 있는 출력의 모든 요소에 대해 슬라이스 오프셋 of1 및 of2에 액세스하여 입력의 인덱스를 계산합니다. 런타임 변수의 간격은 전체 슬라이스가 범위 내에 있다고 가정하여 파생됩니다.
of1 및 of2의 출력-입력 매핑:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
수집
단순화된 gather만 지원됩니다. gather_simplifier.h를 참고하세요.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
operand의 출력-입력 맵은 다음과 같습니다.
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
이제 런타임 값을 나타내는 rt 기호가 있습니다.
indices의 출력-입력 맵은 다음과 같습니다.
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
범위 변수 s0는 출력의 요소를 계산하기 위해 indices 텐서의 전체 행 (d0, *)이 필요함을 보여줍니다.
트랜스포즈
전치용 색인 맵은 입력/출력 차원의 순열입니다.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
출력-입력 맵:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
입력-출력 맵은 다음과 같습니다.
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
반전
되돌린 측정기준을 upper_bound(d_i) -
d_i로 변경하는 역방향 변경사항의 색인 지도:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
출력-입력 맵:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
입력-출력 맵은 다음과 같습니다.
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(가변)Reduce
가변 감소에는 여러 입력과 여러 초기 값이 있으며 출력에서 입력으로의 맵은 감소된 차원을 추가합니다.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
입력 맵에 대한 출력:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
입력-출력 맵은 다음과 같습니다.
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
슬라이스
슬라이스 결과의 출력을 입력으로 색싱하면 출력의 모든 요소에 유효한 스트라이드 색싱 맵이 생성됩니다. 입력에서 출력으로의 매핑은 입력의 스트라이드 범위 요소로 제한됩니다.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
출력-입력 맵:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
입력-출력 맵은 다음과 같습니다.
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Reshape
리셰이프는 다양한 맛이 있습니다.
모양 접기
이는 N차원에서 1차원으로 '선형화'하는 재구성입니다.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
출력-입력 맵:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
입력-출력 맵은 다음과 같습니다.
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
도형 펼치기
이는 역 '모양 축소' 작업으로, 1D 입력을 N-D 출력으로 재구성합니다.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
출력-입력 맵:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
입력-출력 맵은 다음과 같습니다.
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
일반 재구성
단일 확장 또는 축소 모양으로 표현할 수 없는 재구성 작업입니다. 2개 이상의 펼치기 또는 접기 도형의 구성으로만 표현할 수 있습니다.
예 1: 선형화-비선형화
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
이 리셰이프는 tensor<4x8xf32>에서 tensor<32xf32>로 모양을 축소한 후 tensor<2x4x4xf32>로 모양을 확장하는 컴포지션으로 나타낼 수 있습니다.
출력-입력 맵:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
입력-출력 맵은 다음과 같습니다.
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
예 2: 확장된 하위 도형과 접힌 하위 도형
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
이 재형성은 두 개의 재형성의 합성으로 표현할 수 있습니다. 첫 번째는 가장 바깥쪽 측정기준 tensor<4x8x12xf32>~tensor<32x12xf32>을 접고 두 번째는 가장 안쪽 측정기준 tensor<32x12xf32>을 tensor<32x3x4xf32>로 펼칩니다.
출력-입력 맵:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
입력-출력 맵은 다음과 같습니다.
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
비트캐스트 작업은 전치-모양 변경-전치 시퀀스로 나타낼 수 있습니다. 따라서 색인 생성 맵은 이 시퀀스의 색인 생성 맵으로 구성됩니다.
Concatenate
concat의 출력-입력 매핑은 모든 입력에 대해 정의되지만 도메인이 겹치지 않습니다. 즉, 한 번에 하나의 입력만 사용됩니다.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
입력에 대한 출력은 다음을 매핑합니다.
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
출력 맵의 입력은 다음과 같습니다.
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
점
점의 색인 매핑은 축소의 색인 매핑과 매우 유사합니다.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
입력에 대한 출력은 다음을 매핑합니다.
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
출력 맵의 입력은 다음과 같습니다.
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
PadOp의 색인 생성은 SliceOp 색인 생성의 역수입니다.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
패딩 구성 1_4_1x4_8_0는 lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1을 나타냅니다.
입력 맵에 대한 출력:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
XLA의 ReduceWindow는 패딩도 실행합니다. 따라서 색인 생성 맵은 패딩을 실행하지 않는 ReduceWindow 색인 생성과 PadOp의 색인 생성의 합성으로 계산할 수 있습니다.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
입력 맵에 대한 출력:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Fusion용 지도 색인 생성
융합 작업의 색인 생성 맵은 클러스터의 모든 작업의 색인 생성 맵으로 구성됩니다. 일부 입력이 서로 다른 액세스 패턴으로 여러 번 읽힐 수 있습니다.
하나의 입력, 여러 색인 지도
다음은 p0 + transpose(p0)의 예입니다.
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
p0의 출력-입력 색인 매핑은 (d0, d1) -> (d0, d1) 및 (d0, d1) -> (d1, d0)입니다. 즉, 출력의 한 요소를 계산하기 위해 입력 매개변수를 두 번 읽어야 할 수도 있습니다.
하나의 입력, 중복 제거 색인 맵
![]()
색인 매핑이 즉시 명확하지 않더라도 실제로 동일한 경우가 있습니다.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
이 경우 p0의 출력-입력 색인 지정 맵은 (d0, d1, d2) -> (d2, d0, d1)입니다.
소프트맥스
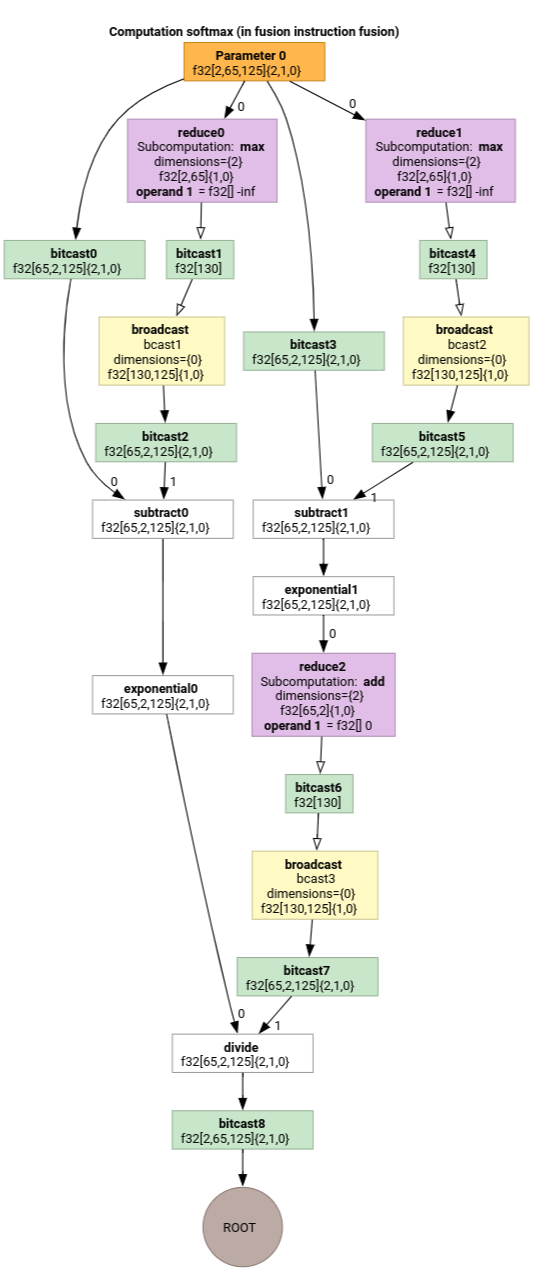
softmax의 parameter 0 출력-입력 색인 매핑은 다음과 같습니다.
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
및
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
여기서 s0는 입력의 가장 안쪽 차원을 나타냅니다.
자세한 예는 indexing_analysis_test.cc를 참고하세요.
색인 생성 지도 단순화 도구
mlir::AffineMap 업스트림의 기본 단순화 도구는 측정기준/기호의 범위에 관해 어떠한 가정도 할 수 없습니다. 따라서 mod 및 div를 사용하여 표현식을 효율적으로 단순화할 수 없습니다.
아핀 맵의 하위 표현식의 하한과 상한에 관한 지식을 활용하여 아핀 맵을 더욱 단순화할 수 있습니다.
단순화 도구는 다음 표현식을 다시 쓸 수 있습니다.
[0, 6] x [0, 14]의 d에 대한(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)이(d0, d1) -> (d0, d1)이 됩니다.di in [0, 9]의(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)이(가)(d0, d1, d2) -> (d0, d1, d2)이(가) 됩니다.d_i in [0, 9]의(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)이(가)(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8)이(가) 됩니다.[0, 9] x [0, 10]의 d에 대한(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)이(d0, d1) -> (d0)이 됩니다.
색인 지정 맵 단순화 도구를 사용하면 HLO에서 연결된 일부 재형성이 서로 취소된다는 것을 알 수 있습니다.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
색인 맵을 구성하고 단순화하면 다음을 얻을 수 있습니다.
(d0, d1, d2) -> (d0, d1, d2).
색인 생성 맵 단순화는 제약 조건도 단순화합니다.
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_bound유형의 제약 조건은updated_lower_bound <= affine_expr <= updated_upped_bound로 다시 작성됩니다.d0 in [0, 5]및s0 in [1, 3]의d0 + s0 in [0, 20]와 같이 항상 충족되는 제약 조건이 삭제됩니다.- 제약 조건의 아핀 표현식은 위의 색인 아핀 맵으로 최적화됩니다.
자세한 예는 indexing_map_test.cc를 참고하세요.