
एचएलओ इंडेक्सिंग विश्लेषण, डेटाफ़्लो विश्लेषण होता है. इसमें बताया जाता है कि "इंडेक्सिंग मैप" के ज़रिए, एक टेंसर के एलिमेंट दूसरे टेंसर से कैसे जुड़े होते हैं. उदाहरण के लिए, किसी एचएलओ निर्देश के आउटपुट के इंडेक्स, एचएलओ निर्देश के ऑपरेंड के इंडेक्स से कैसे मैप होते हैं.
उदाहरण
tensor<20xf32> से tensor<10x20x30xf32> तक ब्रॉडकास्ट करने के लिए
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
आउटपुट से इनपुट तक इंडेक्सिंग मैप, i in
[0, 10], j in [0, 20], और k in [0, 30] के लिए (i, j, k) -> (j) है.
वजह
XLA, कोएलसिंग, ऑपरेंड के इस्तेमाल, और टाइलिंग स्कीम के बारे में तर्क देने के लिए, कई खास समाधानों का इस्तेमाल करता है. इसके बारे में ज़्यादा जानकारी यहां दी गई है. इंडेक्सिंग के विश्लेषण का मकसद, इस्तेमाल के ऐसे मामलों के लिए दोबारा इस्तेमाल किया जा सकने वाला कॉम्पोनेंट उपलब्ध कराना है. इंडेक्सिंग के विश्लेषण को एमएलआईआर के अफ़ाइन मैप इंफ़्रास्ट्रक्चर पर बनाया गया है. साथ ही, इसमें एचएलओ सिमैंटिक जोड़े गए हैं.
कोएलसिंग
जब हमें यह पता होता है कि आउटपुट के किसी एलिमेंट का हिसाब लगाने के लिए, इनपुट के किन एलिमेंट/स्लाइस को पढ़ा जाता है, तब मेमोरी को एक साथ लाने के बारे में तर्क करना आसान हो जाता है.
ऑपरेंड का इस्तेमाल
XLA में ऑपरेंड यूटिलाइज़ेशन से पता चलता है कि निर्देश के हर इनपुट का इस्तेमाल कितना किया गया है. यह इस आधार पर तय किया जाता है कि इसके आउटपुट का पूरी तरह से इस्तेमाल किया गया है. फ़िलहाल, सामान्य मामले के लिए भी इस्तेमाल की जानकारी नहीं दी जाती. इंडेक्सिंग के विश्लेषण से, हमें इस्तेमाल का सटीक हिसाब लगाने में मदद मिलती है.
टाइलिंग
टाइल/स्लाइस, एक हाइपर-रेक्टेंगुलर सबसेट होता है. इसे ऑफ़सेट, साइज़, और स्ट्राइड के हिसाब से पैरामीटर में बांटा जाता है. टाइल प्रोपगेशन, ऑप के प्रोड्यूसर/कंज्यूमर के टाइल पैरामीटर का हिसाब लगाने का एक तरीका है. इसके लिए, ऑप के टाइलिंग पैरामीटर का इस्तेमाल किया जाता है. सॉफ्टमैक्स और डॉट के लिए, पहले से ही एक लाइब्रेरी मौजूद है. अगर इंडेक्सिंग मैप के ज़रिए टाइल प्रोपगेशन को दिखाया जाता है, तो इसे ज़्यादा सामान्य और बेहतर बनाया जा सकता है.
इंडेक्सिंग मैप
इंडेक्सिंग मैप, इन दोनों का कॉम्बिनेशन होता है
- एक ऐसा फ़ंक्शन जिसे सिंबल के तौर पर दिखाया गया है. यह एक टेंसर
Aके हर एलिमेंट को, टेंसरBके एलिमेंट की रेंज से मैप करता है; - मान्य फ़ंक्शन आर्ग्युमेंट पर पाबंदियां, जिनमें फ़ंक्शन का डोमेन भी शामिल है.
फ़ंक्शन के आर्ग्युमेंट को तीन कैटगरी में बांटा गया है, ताकि उनके बारे में बेहतर तरीके से बताया जा सके:
टेंसर
Aया जीपीयू ग्रिड के डाइमेंशन वैरिएबल, जिन्हें हम मैप कर रहे हैं; वैल्यू स्टैटिक तौर पर जानी जाती हैं. इंडेक्स एलिमेंट को डाइमेंशन वैरिएबल भी कहा जाता है.range वैरिएबल. ये एक से ज़्यादा मैपिंग तय करते हैं. साथ ही,
Bमें मौजूद एलिमेंट का एक सेट तय करते हैं. इसका इस्तेमाल,Aकी एक वैल्यू का हिसाब लगाने के लिए किया जाता है. वैल्यू स्टैटिक तौर पर जानी जाती हैं. मैट्रिक्स के गुणन में सिकुड़ने वाला डाइमेंशन, रेंज वैरिएबल का एक उदाहरण है.रनटाइम वैरिएबल, जिनके बारे में सिर्फ़ टैग चालू करते समय पता चलता है. उदाहरण के लिए, gather ऑपरेशन का indices आर्ग्युमेंट.
इस फ़ंक्शन का नतीजा, टारगेट किए गए B टेंसर का इंडेक्स होता है.
संक्षेप में, A से B टेंसर तक इंडेक्स करने वाला फ़ंक्शन, x ऑपरेशन के लिए यह है
map_ab(index in A, range variables, runtime variables) -> index in B.
मैपिंग के अलग-अलग तरह के आर्ग्युमेंट को बेहतर तरीके से अलग करने के लिए, हम उन्हें इस तरह लिखते हैं:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
उदाहरण के लिए, आइए रिड्यूस ऑपरेशन f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3} के लिए इंडेक्सिंग मैप देखें:
inके एलिमेंट कोoutमें मैप करने के लिए, हमारे फ़ंक्शन को(d0, d1, d2, d3) -> (d1, d2)के तौर पर दिखाया जा सकता है. वैरिएबलd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]की सीमाएं,inके आकार से तय होती हैं.outके एलिमेंट कोinपर मैप करने के लिए:outमें सिर्फ़ दो डाइमेंशन होते हैं. साथ ही, रिडक्शन से दो रेंज वैरिएबल मिलते हैं, जो डाइमेंशन को कम करते हैं. इसलिए, मैपिंग फ़ंक्शन(d0, d1)[s0, s1] -> (s0, d0, d1, s1)है, जहां(d0, d1),outका इंडेक्स है.s0औरs1, ऑपरेशन के सिमैंटिक से तय की गई रेंज हैं. साथ ही, येinटेंसर के डाइमेंशन 0 और 3 पर फैली हुई हैं. ये पाबंदियां लागू होती हैंd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
यह ध्यान रखना ज़रूरी है कि ज़्यादातर मामलों में, हम आउटपुट के एलिमेंट से मैपिंग करने में दिलचस्पी रखते हैं. कैलकुलेशन के लिए
C = op1(A, B)
E = op2(C, D)
हम "B की इंडेक्सिंग" के बारे में बात कर सकते हैं. इसका मतलब है कि "E के एलिमेंट को B के एलिमेंट में मैप करना". यह इनपुट से आउटपुट की ओर काम करने वाले, डेटा-फ़्लो के अन्य विश्लेषणों की तुलना में अलग हो सकता है.
चरों पर पाबंदियां लगाने से, ऑप्टिमाइज़ेशन के मौके मिलते हैं. साथ ही, कोड जनरेट करने में मदद मिलती है. दस्तावेज़ में, लागू करने से जुड़ी पाबंदियों को डोमेन भी कहा जाता है, क्योंकि ये मैपिंग फ़ंक्शन के सभी मान्य कॉम्बिनेशन या आर्ग्युमेंट वैल्यू तय करती हैं. कई ऑपरेशनों के लिए, कॉन्स्ट्रेंट सिर्फ़ टेंसर के डाइमेंशन के बारे में बताते हैं. हालांकि, कुछ ऑपरेशनों के लिए ये ज़्यादा जटिल हो सकते हैं. यहां दिए गए उदाहरण देखें.
फ़ंक्शन और तर्क की सीमाओं को सिंबल के तौर पर दिखाने और फ़ंक्शन और सीमाओं को एक साथ इस्तेमाल करने की सुविधा की मदद से, हम किसी भी बड़ी गणना (फ़्यूज़न) के लिए कॉम्पैक्ट इंडेक्सिंग मैपिंग का हिसाब लगा सकते हैं.
सिंबॉलिक फ़ंक्शन और शर्तों को इस तरह से डिज़ाइन किया जाता है कि वे लागू करने में आसान हों और उनसे ऑप्टिमाइज़ेशन के फ़ायदे भी मिलें. इसके लिए, सटीक जानकारी का इस्तेमाल किया जाता है. हम कुछ एचएलओ कार्रवाइयों के लिए, ऐक्सेस पैटर्न को सिर्फ़ अनुमानित तौर पर कैप्चर करते हैं.
लागू करना
हम दोबारा कैलकुलेट करने की प्रोसेस को कम करना चाहते हैं. इसलिए, हमें सिंबॉलिक कैलकुलेशन के लिए एक लाइब्रेरी की ज़रूरत है. XLA पहले से ही MLIR पर निर्भर है. इसलिए, हम एक और सिंबॉलिक अंकगणित लाइब्रेरी लिखने के बजाय, mlir::AffineMap का इस्तेमाल करते हैं.
सामान्य AffineMap ऐसा दिखता है
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap में दो तरह के पैरामीटर होते हैं: डाइमेंशन और सिंबल.
डाइमेंशन, डाइमेंशन वैरिएबल d से मेल खाते हैं. सिंबल, रेंज वैरिएबल r और रनटाइम वैरिएबल rt से मेल खाते हैं. AffineMap में पैरामीटर की सीमाओं के बारे में कोई मेटाडेटा शामिल नहीं होता. इसलिए, हमें उन्हें अलग से उपलब्ध कराना होता है.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ इंडेक्सिंग मैप के डाइमेंशन वैरिएबल d के लिए, inclusive बॉक्स की सीमाओं को कोड में बदलता है. आम तौर पर, ये सीमाएं ट्रांसपोज़, रिड्यूस, एलिमेंटवाइज़, डॉट जैसे ऑपरेशनों के लिए आउटपुट टेंसर के आकार से मेल खाती हैं. हालांकि, कुछ अपवाद भी हैं, जैसे कि HloConcatenateInstruction.
range_vars_ वे सभी वैल्यू जो रेंज वैरिएबल s लेते हैं. रेंज वैरिएबल तब ज़रूरी होते हैं, जब हमें मैप किए जा रहे टेंसर के किसी एक एलिमेंट का हिसाब लगाने के लिए कई वैल्यू की ज़रूरत होती है. उदाहरण के लिए, रिडक्शन के आउटपुट->इनपुट इंडेक्सिंग मैप या ब्रॉडकास्ट के लिए इनपुट->आउटपुट मैप.
rt_vars_ रनटाइम में, इस्तेमाल की जा सकने वाली वैल्यू को कोड में बदलें. उदाहरण के लिए, 1D HloDynamicSliceInstruction के लिए ऑफ़सेट डाइनैमिक होता है. इसके हिसाब से, RTVar की वैल्यू 0 और tensor_size - slice_size - 1 के बीच होगी.
constraints_ फ़ॉर्म में वैल्यू के बीच के संबंध कैप्चर करें
<expression> in <range>, जैसे कि d0 + s0 in [0, 20]. Variable.bounds के साथ मिलकर, ये इंडेक्सिंग फ़ंक्शन का "डोमेन" तय करते हैं.
आइए, उदाहरणों की मदद से समझते हैं कि ऊपर दिए गए सभी विकल्पों का क्या मतलब है.
अनफ़्यूज़्ड ऑप्स के लिए Maps को इंडेक्स करना
Elementwise
एलिमेंटवाइज़ ऑपरेशंस के लिए, इंडेक्सिंग मैप एक आइडेंटिटी है.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
आउटपुट से इनपुट मैप output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
इनपुट से आउटपुट मैप p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
ब्रॉडकास्ट
ब्रॉडकास्टिंग का मतलब है कि जब हम आउटपुट को इनपुट से मैप करते हैं, तो कुछ डाइमेंशन हटा दिए जाएंगे. वहीं, जब हम इनपुट को आउटपुट से मैप करते हैं, तो कुछ डाइमेंशन जोड़ दिए जाएंगे.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
इनपुट मैप का आउटपुट:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
इनपुट से आउटपुट मैप करने की सुविधा:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
ध्यान दें कि अब हमारे पास इनपुट-टू-आउटपुट मैपिंग के लिए, दाईं ओर रेंज वैरिएबल s हैं. ये ऐसे सिंबल होते हैं जो वैल्यू की रेंज दिखाते हैं.
उदाहरण के लिए, इस मामले में इंडेक्स d0 वाले इनपुट के हर एलिमेंट को आउटपुट के 10x1x30 स्लाइस पर मैप किया जाता है.
Iota
Iota में कोई इनपुट टेंसर ऑपरेंड नहीं होता. इसलिए, इसमें कोई इनपुट इंडेक्स आर्ग्युमेंट नहीं होता.
iota = f32[2,4] iota(), dimensions={1}
इनपुट मैप में आउटपुट:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
इनपुट से आउटपुट मैप:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice में ऐसे ऑफ़सेट होते हैं जो सिर्फ़ रनटाइम पर पता चलते हैं.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
ds से src तक के इनपुट मैप का आउटपुट:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
ध्यान दें कि अब हमारे पास इनपुट-टू-आउटपुट मैपिंग के लिए, दाईं ओर rt है.
ये ऐसे सिंबल हैं जो रनटाइम वैल्यू को दिखाते हैं. उदाहरण के लिए, इस खास मामले में इंडेक्स d0, d1, d2 वाले आउटपुट के हर एलिमेंट के लिए, हम स्लाइस ऑफ़सेट of1, of2, और of3 को ऐक्सेस करते हैं, ताकि इनपुट का इंडेक्स कैलकुलेट किया जा सके.
रनटाइम वैरिएबल के इंटरवल, इस आधार पर तय किए जाते हैं कि पूरा स्लाइस तय सीमा के अंदर रहता है.
of1, of2, और of3 के लिए, आउटपुट से इनपुट तक का मैप:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
src के लिए, इनपुट मैप से आउटपुट मैप में बदलाव करना आसान है. इसे ज़्यादा सटीक बनाया जा सकता है. इसके लिए, डोमेन को उन इंडेक्स तक सीमित करें जिन्हें अपडेट नहीं किया गया है. हालांकि, फ़िलहाल इंडेक्सिंग मैप, असमानता की शर्तों के साथ काम नहीं करते.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
upd के लिए, आउटपुट से इनपुट मैप करने की सुविधा:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
ध्यान दें कि अब हमारे पास rt0 और rt1 हैं, जो रनटाइम वैल्यू को दिखाते हैं. इस खास मामले में, इंडेक्स d0, d1 वाले आउटपुट के हर एलिमेंट के लिए, हम स्लाइस ऑफ़सेट of1 और of2 को ऐक्सेस करते हैं, ताकि इनपुट का इंडेक्स कैलकुलेट किया जा सके. रनटाइम वैरिएबल के इंटरवल, यह मानकर निकाले जाते हैं कि पूरा स्लाइस तय सीमा में रहता है.
of1 और of2 के लिए, आउटपुट से इनपुट मैप करने की सुविधा:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
सिर्फ़ आसान तरीके से डेटा इकट्ठा करने की सुविधा काम करती है. gather_simplifier.h देखें.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
operand के लिए, आउटपुट से इनपुट मैप करने की सुविधा:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
ध्यान दें कि अब हमारे पास rt सिंबल हैं, जो रनटाइम वैल्यू को दिखाते हैं.
indices के लिए, आउटपुट से इनपुट मैप करने की सुविधा:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
रेंज वैरिएबल s0 से पता चलता है कि आउटपुट के किसी एलिमेंट का हिसाब लगाने के लिए, हमें indices टेंसर की पूरी लाइन (d0, *) की ज़रूरत है.
ट्रांसपोज़ करें
ट्रांसपोज़ के लिए इंडेक्सिंग मैप, इनपुट/आउटपुट डाइमेंशन का क्रमपरिवर्तन होता है.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
इनपुट मैप का आउटपुट:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
इनपुट से आउटपुट मैप करने की सुविधा:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
उल्टा करें
बदलावों को वापस लाने के लिए इंडेक्सिंग मैप, वापस लाए गए डाइमेंशन को upper_bound(d_i) -
d_i में बदलता है:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
इनपुट मैप का आउटपुट:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
इनपुट से आउटपुट मैप करने की सुविधा:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
वेरिऐडिक रिडक्शन में कई इनपुट और कई शुरुआती वैल्यू होती हैं. आउटपुट से इनपुट तक का मैप, कम किए गए डाइमेंशन जोड़ता है.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
इनपुट मैप का आउटपुट:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
आउटपुट मैप के लिए इनपुट:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
स्लाइस
स्लाइस के नतीजों के लिए, आउटपुट से इनपुट तक इंडेक्स करने पर, स्ट्राइड इंडेक्सिंग मैप मिलता है. यह आउटपुट के हर एलिमेंट के लिए मान्य होता है. इनपुट से आउटपुट तक मैपिंग, इनपुट में मौजूद एलिमेंट की स्ट्राइड रेंज तक सीमित होती है.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
इनपुट मैप का आउटपुट:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
इनपुट से आउटपुट मैप करने की सुविधा:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
फिर से आकार दें
रीशेप करने की सुविधा अलग-अलग फ़्लेवर में उपलब्ध है.
शेप को छोटा करना
यह N-D से 1D तक का "लीनियर करने वाला" रीशेप है.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
इनपुट मैप का आउटपुट:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
इनपुट से आउटपुट मैप करने की सुविधा:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
शेप को बड़ा करें
यह "कोलैप्स शेप" ऑप का उलटा है. यह 1D इनपुट को N-D आउटपुट में बदलता है.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
इनपुट मैप का आउटपुट:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
इनपुट से आउटपुट मैप करने की सुविधा:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
जेनेरिक रीशेप
ये ऐसे रीशेप ऑप्स हैं जिन्हें एक ही एक्सपैंड या कोलैप्स शेप के तौर पर नहीं दिखाया जा सकता. इन्हें सिर्फ़ दो या उससे ज़्यादा एक्सपैंड या कोलैप्स किए जा सकने वाले शेप के तौर पर दिखाया जा सकता है.
उदाहरण 1: लीनियरलाइज़ेशन-डीलीनियरलाइज़ेशन.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
इस रीशेप को, tensor<4x8xf32> से tensor<32xf32> तक के कोलैप्स शेप और फिर tensor<2x4x4xf32> तक के शेप एक्सपैंशन के कंपोज़िशन के तौर पर दिखाया जा सकता है.
इनपुट मैप का आउटपुट:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
इनपुट से आउटपुट मैप करने की सुविधा:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
दूसरा उदाहरण: बड़े और छोटे किए गए सबशेप
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
इस रीशेप को दो रीशेप के कंपोज़िशन के तौर पर दिखाया जा सकता है. पहली इमेज में, सबसे बाहरी डाइमेंशन tensor<4x8x12xf32> से tensor<32x12xf32> तक छोटा किया गया है. वहीं, दूसरी इमेज में सबसे अंदरूनी डाइमेंशन tensor<32x12xf32> को tensor<32x3x4xf32> में बड़ा किया गया है.
इनपुट मैप का आउटपुट:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
इनपुट से आउटपुट मैप करने की सुविधा:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
बिटकास्ट ऑपरेशन को ट्रांसपोज़-रीशेप-ट्रांसपोज़ के क्रम के तौर पर दिखाया जा सकता है. इसलिए, इसके इंडेक्सिंग मैप, इस क्रम के इंडेक्सिंग मैप से मिलकर बने होते हैं.
Concatenate
concat के लिए आउटपुट-टू-इनपुट मैपिंग, सभी इनपुट के लिए तय की जाती है.हालांकि, इसमें नॉन-ओवरलैपिंग डोमेन होते हैं. इसका मतलब है कि एक बार में सिर्फ़ एक इनपुट का इस्तेमाल किया जाएगा.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
इनपुट के हिसाब से आउटपुट इस तरह मैप किया जाता है:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
आउटपुट मैप के लिए इनपुट:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
बिंदु
डॉट के लिए इंडेक्सिंग मैप, रिड्यूस के इंडेक्सिंग मैप से काफ़ी मिलते-जुलते हैं.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
इनपुट के हिसाब से आउटपुट इस तरह मैप किया जाता है:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
आउटपुट मैप के लिए इनपुट:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
पैड
PadOp की इंडेक्सिंग, SliceOp की इंडेक्सिंग से बिलकुल उलट होती है.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
पैडिंग कॉन्फ़िगरेशन 1_4_1x4_8_0, lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1 को दिखाता है.
इनपुट मैप का आउटपुट:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
XLA में ReduceWindow, पैडिंग भी करता है. इसलिए, इंडेक्सिंग मैप को ReduceWindow इंडेक्सिंग के कंपोज़िशन के तौर पर कैलकुलेट किया जा सकता है. इसमें कोई पैडिंग नहीं होती है. साथ ही, PadOp की इंडेक्सिंग भी होती है.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
इनपुट मैप का आउटपुट:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Fusion के लिए मैप इंडेक्स करना
फ़्यूज़न ऑप के लिए इंडेक्सिंग मैप, क्लस्टर में मौजूद हर ऑप के लिए इंडेक्सिंग मैप का कंपोज़िशन होता है. ऐसा हो सकता है कि कुछ इनपुट को अलग-अलग ऐक्सेस पैटर्न के साथ कई बार पढ़ा जाए.
एक इनपुट, कई इंडेक्सिंग मैप
यहां p0 + transpose(p0) का एक उदाहरण दिया गया है.
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
p0 के लिए, आउटपुट-टू-इनपुट इंडेक्सिंग मैप (d0, d1) -> (d0, d1) और (d0, d1) -> (d1, d0) होंगे. इसका मतलब है कि आउटपुट के किसी एलिमेंट का हिसाब लगाने के लिए, हमें इनपुट पैरामीटर को दो बार पढ़ना पड़ सकता है.
एक इनपुट, डुप्लीकेट हटाकर इंडेक्स किया गया मैप
![]()
ऐसे मामले भी होते हैं जब इंडेक्सिंग मैप एक जैसे होते हैं. हालांकि, यह तुरंत पता नहीं चलता.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
इस मामले में, p0 के लिए आउटपुट-टू-इनपुट इंडेक्सिंग मैप सिर्फ़ (d0, d1, d2) -> (d2, d0, d1) है.
Softmax
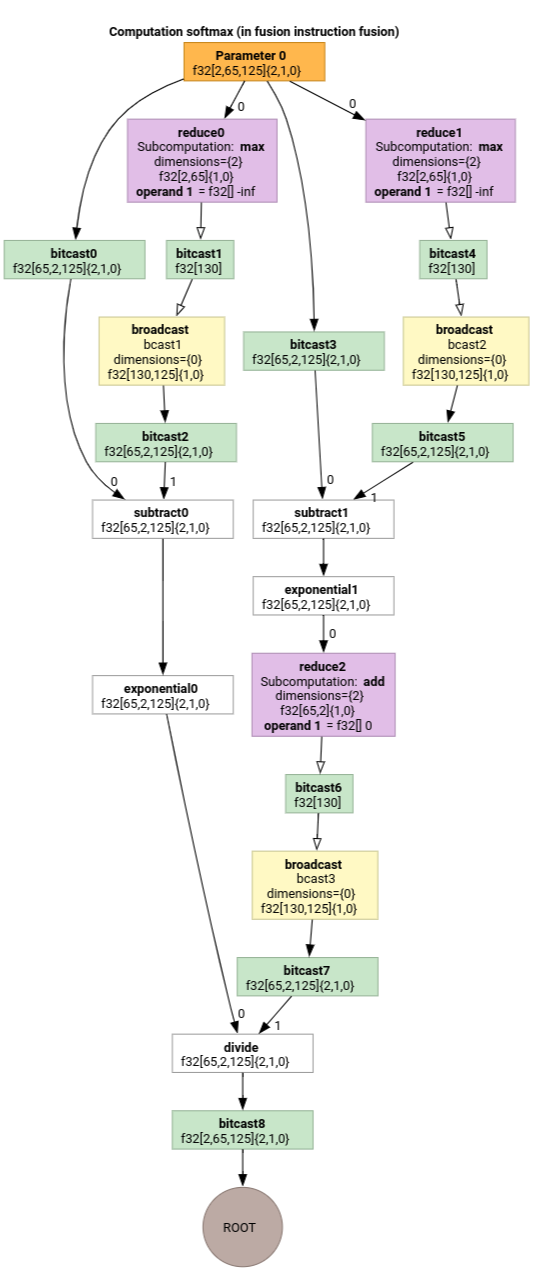
सॉफ्टमैक्स के लिए, आउटपुट-टू-इनपुट इंडेक्सिंग मैप parameter 0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
और
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
यहां s0 का मतलब, इनपुट का सबसे अंदरूनी डाइमेंशन है.
ज़्यादा उदाहरणों के लिए, indexing_analysis_test.cc देखें.
Indexing Map Simplifier
mlir::AffineMap अपस्ट्रीम के लिए डिफ़ॉल्ट सिंपलीफायर, डाइमेंशन/सिंबल की रेंज के बारे में कोई अनुमान नहीं लगा सकता. इसलिए, यह mod और div वाले एक्सप्रेशन को आसानी से हल नहीं कर सकता.
हम ऐफ़ाइन मैप में मौजूद सब-एक्सप्रेशन की लोअर और अपर बाउंड की जानकारी का इस्तेमाल करके, उन्हें और भी आसान बना सकते हैं.
आसान बनाने की सुविधा, इन एक्सप्रेशन को फिर से लिख सकती है.
[0, 6] x [0, 14]में d के लिए(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16),(d0, d1) -> (d0, d1)हो जाता हैdi in [0, 9]के लिए(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)की वैल्यू(d0, d1, d2) -> (d0, d1, d2)हो जाती है.d_i in [0, 9]के लिए(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)की वैल्यू(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8)हो जाती है.[0, 9] x [0, 10]में d के लिए(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9),(d0, d1) -> (d0)हो जाता है.
इंडेक्सिंग मैप सिंपलीफायर की मदद से, हमें यह समझने में मदद मिलती है कि HLO में चेन किए गए कुछ रीशेप एक-दूसरे को रद्द कर देते हैं.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
इंडेक्सिंग मैप बनाने और उन्हें आसान बनाने के बाद, हमें यह मिलेगा
(d0, d1, d2) -> (d0, d1, d2).
इंडेक्सिंग मैप को आसान बनाने से, पाबंदियां भी आसान हो जाती हैं.
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundटाइप की शर्तों कोupdated_lower_bound <= affine_expr <= updated_upped_boundके तौर पर फिर से लिखा जाता है.- ऐसी पाबंदियां हटा दी जाती हैं जो हमेशा पूरी होती हैं. जैसे,
d0 in [0, 5]औरs0 in [1, 3]के लिएd0 + s0 in [0, 20]. - ऊपर दिए गए इंडेक्सिंग अफ़ाइन मैप की तरह, कॉन्स्ट्रेंट में अफ़ाइन एक्सप्रेशन को ऑप्टिमाइज़ किया जाता है.
ज़्यादा उदाहरणों के लिए, indexing_map_test.cc देखें.