
HLO インデックス分析は、あるテンソルの要素が「インデックス マップ」を介して別のテンソルとどのように関連しているかを記述するデータフロー分析です。たとえば、HLO 命令の出力のインデックスが HLO 命令のオペランドのインデックスにどのようにマッピングされるかなどです。
例
tensor<20xf32> から tensor<10x20x30xf32> へのブロードキャストの場合
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
出力から入力へのインデックス マップは、i in
[0, 10]、j in [0, 20]、k in [0, 30] の場合は (i, j, k) -> (j) です。
目的
XLA は、統合、オペランドの使用率、タイリング スキームについて推論するために、いくつかのカスタム ソリューションを使用します(詳細は後述)。インデックス分析の目的は、このようなユースケースで再利用可能なコンポーネントを提供することです。インデックス分析は MLIR のアフィン マップ インフラストラクチャに基づいて構築され、HLO セマンティクスを追加します。
統合
入力のどの要素/スライスが読み取られて出力の要素を計算するのかがわかれば、メモリの統合について非自明なケースでも推論できるようになります。
オペランド使用率
XLA のオペランド使用率は、出力が完全に使用されていると仮定した場合に、命令の各入力がどの程度使用されているかを示します。現在、汎用ケースの使用率も計算されていません。インデックス登録分析により、使用率を正確に計算できます。
並べ方
タイル/スライスは、オフセット、サイズ、ストライドでパラメータ化されたテンソルの超長方形のサブセットです。タイル伝播は、op 自体のタイリング パラメータを使用して、op のプロデューサー/コンシューマーのタイル パラメータを計算する方法です。softmax と dot の処理を行うライブラリはすでに存在します。インデックス マップで表現すると、タイルの伝播をより汎用的で堅牢にすることができます。
インデックス マップ
インデックス マップは、次の要素の組み合わせです。
- 1 つのテンソル
Aのすべての要素をテンソルBの要素の範囲にマッピングする関数を記号で表したもの。 - 関数のドメインなど、有効な関数引数に関する制約。
関数の引数は、その性質をより明確にするために 3 つのカテゴリに分類されます。
マッピング元のテンソル
Aまたは GPU グリッドのディメンション変数。値は静的に認識されます。インデックス要素は、ディメンション変数とも呼ばれます。range 変数。これらは 1 対多のマッピングを定義し、
Aの単一の値を計算するために使用されるBの要素のセットを指定します。値は静的に認識されます。行列乗算の縮約ディメンションは、範囲変数の例です。実行時にのみ認識されるランタイム変数。たとえば、gather オペレーションの indices 引数などです。
関数の結果は、ターゲット B テンソルのインデックスです。
つまり、演算 x のテンソル A からテンソル B へのインデックス関数は次のようになります。
map_ab(index in A, range variables, runtime variables) -> index in B。
マッピング引数の型をより明確に分離するために、次のように記述します。
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
たとえば、reduce オペレーション f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3} のインデックス マップを見てみましょう。
inの要素をoutにマッピングする関数は、(d0, d1, d2, d3) -> (d1, d2)と表現できます。変数d0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]の制約は、inの形状によって定義されます。outの要素をinにマッピングするには:outには 2 つのディメンションしかなく、削減により、ディメンションの削減をカバーする 2 つの範囲変数が導入されます。したがって、マッピング関数は(d0, d1)[s0, s1] -> (s0, d0, d1, s1)です。ここで、(d0, d1)はoutのインデックスです。s0、s1はオペレーションのセマンティクスによって定義される範囲で、inテンソルのディメンション 0 と 3 に及びます。制約はd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15]です。
ほとんどのシナリオでは、出力の要素からのマッピングに関心があることに注意してください。計算用
C = op1(A, B)
E = op2(C, D)
「B のインデックス作成」は「E の要素を B の要素にマッピングする」という意味になります。これは、入力から出力に向かって処理する他のタイプのデータフロー分析とは対照的です。
変数に対する制約により、最適化の機会が生まれ、コード生成に役立ちます。ドキュメントと実装の制約は、マッピング関数の有効な組み合わせまたは引数値のすべてを定義するため、ドメインとも呼ばれます。多くのオペレーションでは、制約は単にテンソルの次元を記述しますが、一部のオペレーションではより複雑になることがあります。以下の例をご覧ください。
関数と引数の制約を記号で表現し、関数と制約を組み合わせることで、任意の大きな計算(融合)のコンパクトなインデックス マッピングを計算できます。
シンボリック関数と制約の表現力は、実装の複雑さと、より正確な表現から得られる最適化の利得のバランスです。一部の HLO オペレーションでは、アクセス パターンを概算でしかキャプチャしません。
実装
再計算を最小限に抑えるため、記号計算用のライブラリが必要です。XLA はすでに MLIR に依存しているため、別の記号演算ライブラリを作成する代わりに mlir::AffineMap を使用します。
一般的な AffineMap は次のようになります。
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap には、ディメンションとシンボルの 2 種類のパラメータがあります。ディメンションはディメンション変数 d に対応し、シンボルは範囲変数 r とランタイム変数 rt に対応します。AffineMap にはパラメータの制約に関するメタデータが含まれていないため、別途指定する必要があります。
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ は、インデックス マップのディメンション変数 d の包括的なボックス制約をエンコードします。通常、これは転置、削減、要素ごと、ドットなどの演算の出力テンソルの形状と一致しますが、HloConcatenateInstruction などの例外もあります。
range_vars_ は、範囲変数 s が取るすべての値です。範囲変数は、マッピング元のテンソルの単一の要素を計算するために複数の値が必要な場合(削減の出力から入力へのインデックス マップやブロードキャストの入力から出力へのマップなど)に必要です。
rt_vars_ は、実行時に実行可能な値をエンコードします。たとえば、1D HloDynamicSliceInstruction のオフセットは動的です。対応する RTVar の実行可能な値は 0~tensor_size - slice_size - 1 の範囲になります。
constraints_ は、<expression> in <range> 形式の値間の関係をキャプチャします(例: d0 + s0 in [0, 20])。Variable.bounds とともに、インデックス関数の「ドメイン」を定義します。
上記の意味を理解するために、例を挙げて説明します。
統合されていないオペレーションのマップのインデックス登録
要素ごと
要素ごとの演算の場合、インデックス マップは ID です。
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
出力から入力へのマッピング output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
入力から出力へのマッピング p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
ブロードキャスト
ブロードキャストとは、出力を入力にマッピングするときに一部のディメンションが削除され、入力を出力にマッピングするときに追加されることを意味します。
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
出力から入力へのマッピング:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
入力から出力へのマッピング:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
入力から出力へのマッピングの右側に範囲変数 s が表示されるようになりました。これらは値の範囲を表す記号です。たとえば、この特定のケースでは、インデックス d0 の入力のすべての要素が、出力の 10x1x30 スライスにマッピングされます。
Iota
Iota には入力テンソル オペランドがないため、入力インデックス引数はありません。
iota = f32[2,4] iota(), dimensions={1}
出力から入力へのマッピング:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
入力から出力へのマッピング:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice には、実行時にのみ認識されるオフセットがあります。
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
ds から src への出力から入力へのマッピング:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
入力から出力へのマッピングの右側に rt が表示されます。これらは、ランタイム値を表す記号です。たとえば、この特定のケースでは、インデックス d0, d1, d2 を持つ出力のすべての要素に対して、スライス オフセット of1、of2、of3 にアクセスして入力のインデックスを計算します。ランタイム変数の間隔は、スライス全体が境界内にとどまることを前提として導出されます。
of1、of2、of3 の出力から入力へのマッピング:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
src の出力から入力へのマッピングは自明です。ドメインを更新されていないインデックスに制限することで、精度を高めることができますが、現在のインデックス マップでは不等式制約はサポートされていません。
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
upd の出力から入力へのマッピング:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
ここで、ランタイム値を表す rt0 と rt1 があることに注意してください。この特定のケースでは、インデックス d0, d1 を持つ出力のすべての要素について、スライス オフセット of1 と of2 にアクセスして入力のインデックスを計算します。ランタイム変数の間隔は、スライス全体が範囲内にあることを前提として導出されます。
of1 と of2 の出力から入力へのマッピング:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
簡略化された収集のみがサポートされています。gather_simplifier.h をご覧ください。
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
operand の出力から入力へのマッピング:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
ランタイム値を表す rt 記号が追加されています。
indices の出力から入力へのマッピング:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
範囲変数 s0 は、出力の要素を計算するために indices テンソルの行全体(d0, *)が必要であることを示しています。
転置
転置のインデックス マップは、入力/出力ディメンションの順列です。
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
出力から入力へのマッピング:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
入力から出力へのマッピング:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
反転
逆変更のインデックス マップでは、元に戻されたディメンションが upper_bound(d_i) -
d_i に変更されます。
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
出力から入力へのマッピング:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
入力から出力へのマッピング:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(可変長)Reduce
可変長削減には複数の入力と複数の初期値があり、出力から入力へのマップには削減されたディメンションが追加されます。
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
出力から入力へのマッピングは次のとおりです。
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
入力から出力へのマッピングは次のとおりです。
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
スライス
スライス結果の出力から入力へのインデックス登録により、出力のすべての要素で有効なストライド インデックス マップが生成されます。入力から出力へのマッピングは、入力内の要素のストライド範囲に制限されます。
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
出力から入力へのマッピング:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
入力から出力へのマッピング:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Reshape
リシェイプにはさまざまな種類があります。
図形を折りたたむ
これは、N 次元から 1 次元への「線形化」された再形成です。
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
出力から入力へのマッピング:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
入力から出力へのマッピング:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
図形を開く
これは逆の「形状の折りたたみ」演算で、1D 入力を N-D 出力に再形成します。
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
出力から入力へのマッピング:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
入力から出力へのマッピング:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
汎用的な再形成
これらは、単一の拡大または縮小の形状として表すことができない形状変更オペレーションです。2 つ以上の展開または折りたたみシェイプの構成としてのみ表現できます。
例 1: 線形化と非線形化。
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
この再形成は、tensor<4x8xf32> から tensor<32xf32> への形状の縮小と、tensor<2x4x4xf32> への形状の拡大の合成として表すことができます。
出力から入力へのマッピング:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
入力から出力へのマッピング:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
例 2: 展開されたサブシェイプと折りたたまれたサブシェイプ
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
この再形成は、2 つの再形成の構成として表すことができます。1 つ目は最も外側のディメンション tensor<4x8x12xf32> を tensor<32x12xf32> に折りたたみ、2 つ目は最も内側のディメンション tensor<32x12xf32> を tensor<32x3x4xf32> に展開します。
出力から入力へのマッピング:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
入力から出力へのマッピング:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
ビットキャスト オペレーションは、転置-再形成-転置のシーケンスとして表すことができます。したがって、そのインデックス マップは、このシーケンスのインデックス マップの構成にすぎません。
連結
concat の出力から入力へのマッピングはすべての入力に対して定義されていますが、ドメインが重複していないため、一度に使用される入力は 1 つだけです。
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
出力から入力へのマッピング:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
出力マップへの入力:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
ドットのインデックス マップは、reduce のインデックス マップと非常によく似ています。
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
出力から入力へのマッピング:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
出力マップへの入力:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
パッド
PadOp のインデックス登録は、SliceOp のインデックス登録の逆です。
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
パディング構成 1_4_1x4_8_0 は lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1 を示します。
出力から入力へのマッピングは次のとおりです。
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
XLA の ReduceWindow もパディングを実行します。したがって、インデックス マップは、パディングを行わない ReduceWindow インデックスと PadOp のインデックスの合成として計算できます。
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
出力から入力へのマッピングは次のとおりです。
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Fusion 用のマップのインデックス登録
融合オペレーションのインデックス マップは、クラスタ内のすべてのオペレーションのインデックス マップの構成です。入力が異なるアクセス パターンで複数回読み取られることがあります。
1 つの入力、複数のインデックス マップ
p0 + transpose(p0) の例を次に示します。
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
p0 の出力から入力へのインデックス マップは (d0, d1) -> (d0, d1) と (d0, d1) -> (d1, d0) になります。つまり、出力の 1 つの要素を計算するために、入力パラメータを 2 回読み取る必要がある場合があります。
1 つの入力、重複除去されたインデックス マップ
![]()
インデックス マップが実際には同じであるにもかかわらず、すぐにわからない場合があります。
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
この場合の p0 の出力から入力へのインデックス マップは (d0, d1, d2) -> (d2, d0, d1) になります。
ソフトマックス
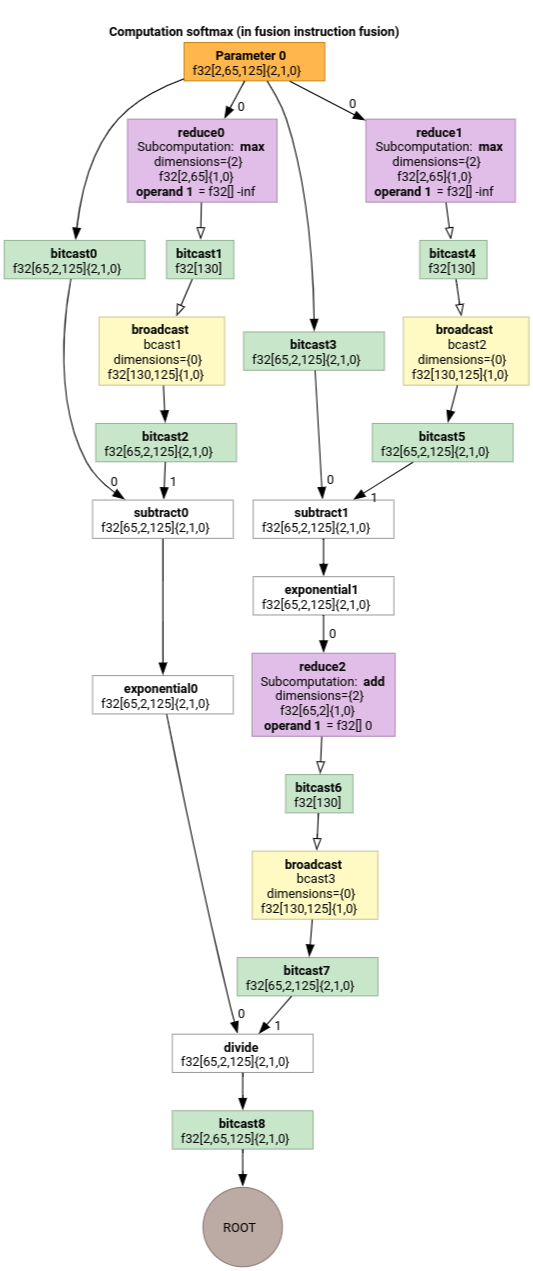
softmax の parameter 0 の出力から入力へのインデックス マップ:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
と
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
ここで、s0 は入力の最も内側のディメンションを指します。
その他の例については、indexing_analysis_test.cc をご覧ください。
Indexing Map Simplifier
mlir::AffineMap アップストリームのデフォルトの簡略化ツールは、ディメンション/シンボルの範囲について何も想定できません。そのため、mod と div を含む式を効率的に簡略化できません。
アフィン マップのサブ式の上下限に関する知識を活用して、さらに簡素化できます。
簡略化ツールは、次の式を書き換えることができます。
[0, 6] x [0, 14]の d の(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)は(d0, d1) -> (d0, d1)になりますdi in [0, 9]の(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)が(d0, d1, d2) -> (d0, d1, d2)になります。d_i in [0, 9]の(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)が(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8)になります。[0, 9] x [0, 10]の d の(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)は(d0, d1) -> (d0)になります。
インデックス マップの簡略化により、HLO の連鎖した reshape の一部が互いにキャンセルされることがわかります。
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
インデックス マップの構成とその簡略化の後、次のようになります。
(d0, d1, d2) -> (d0, d1, d2)。
インデックス マップの簡素化により、制約も簡素化されます。
- タイプ
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundの制約はupdated_lower_bound <= affine_expr <= updated_upped_boundとして書き換えられます。 - 常に満たされる制約(
d0 in [0, 5]とs0 in [1, 3]のd0 + s0 in [0, 20]など)は削除されます。 - 制約のアフィン式は、上記のようにインデックス アフィンマップとして最適化されます。
その他の例については、indexing_map_test.cc をご覧ください。