
Phân tích lập chỉ mục HLO là một phân tích luồng dữ liệu mô tả cách các phần tử của một tenxơ liên quan đến một tenxơ khác thông qua "các bản đồ lập chỉ mục". Ví dụ: cách chỉ mục của một đầu ra lệnh HLO ánh xạ đến chỉ mục của toán hạng lệnh HLO.
Ví dụ:
Đối với một chương trình phát sóng từ tensor<20xf32> đến tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
bản đồ lập chỉ mục từ đầu ra đến đầu vào là (i, j, k) -> (j) cho i in
[0, 10], j in [0, 20] và k in [0, 30].
Động lực
XLA sử dụng một số giải pháp tuỳ chỉnh để suy luận về việc hợp nhất, sử dụng toán hạng và các lược đồ phân ô (xem thêm thông tin bên dưới). Mục tiêu của việc phân tích lập chỉ mục là cung cấp một thành phần có thể dùng lại cho những trường hợp sử dụng như vậy. Phân tích lập chỉ mục được xây dựng trên cơ sở hạ tầng Affine Map của MLIR và thêm ngữ nghĩa HLO.
Kết hợp
Việc suy luận về việc hợp nhất bộ nhớ trở nên khả thi đối với các trường hợp không tầm thường, khi chúng ta biết những phần tử/lát nào của đầu vào được đọc để tính toán một phần tử của đầu ra.
Mức sử dụng toán hạng
Mức sử dụng toán hạng trong XLA cho biết mức độ sử dụng từng đầu vào của chỉ dẫn, giả sử đầu ra của chỉ dẫn được sử dụng hoàn toàn. Hiện tại, mức sử dụng cũng không được tính cho trường hợp chung. Phân tích lập chỉ mục giúp chúng tôi tính toán chính xác mức sử dụng.
Cách phân ô
Ô/lát là tập hợp con siêu chữ nhật của một tensor được tham số hoá theo độ lệch, kích thước và bước. Lan truyền ô là một cách để tính toán các tham số ô của nhà sản xuất/người tiêu dùng của hoạt động bằng cách sử dụng các tham số phân ô của chính hoạt động đó. Đã có một thư viện thực hiện việc này cho softmax và dấu chấm. Bạn có thể tạo hiệu ứng lan truyền ô tổng quát và mạnh mẽ hơn nếu thể hiện hiệu ứng này thông qua việc lập chỉ mục bản đồ.
Bản đồ lập chỉ mục
Bản đồ lập chỉ mục là sự kết hợp của
- một hàm được biểu thị bằng ký hiệu, ánh xạ mọi phần tử của một tensor
Ađến các dải phần tử trong tensorB; - các ràng buộc đối với đối số hàm hợp lệ, bao gồm cả miền của hàm.
Đối số hàm được chia thành 3 danh mục để truyền đạt rõ hơn bản chất của chúng:
các biến phương diện của tensor
Ahoặc lưới GPU mà chúng ta đang ánh xạ từ đó; các giá trị được biết một cách tĩnh. Các phần tử chỉ mục còn được gọi là biến phương diện.Biến phạm vi. Chúng xác định mối liên kết một-nhiều và chỉ định một tập hợp các phần tử trong
Bdùng để tính toán một giá trị duy nhất củaA; các giá trị được biết một cách tĩnh. Phương diện thu hẹp của phép nhân ma trận là một ví dụ về biến phạm vi.biến thời gian chạy chỉ được biết trong quá trình thực thi. Ví dụ: đối số chỉ mục của thao tác gather.
Kết quả của hàm là chỉ mục của tensor B đích.
Nói tóm lại, hàm lập chỉ mục từ tensor A đến tensor B cho thao tác x là
map_ab(index in A, range variables, runtime variables) -> index in B.
Để phân tách rõ hơn các loại đối số ánh xạ, chúng ta sẽ viết chúng dưới dạng:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Ví dụ: hãy xem các bản đồ lập chỉ mục cho thao tác giảm f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
để ánh xạ các phần tử của
inđếnout, hàm của chúng ta có thể được biểu thị dưới dạng(d0, d1, d2, d3) -> (d1, d2). Các ràng buộc của biếnd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]được xác định bằng hình dạng củain.Để ánh xạ các phần tử của
outđếnin:outchỉ có hai phương diện và việc giảm sẽ giới thiệu hai biến phạm vi bao gồm các phương diện giảm. Do đó, hàm ánh xạ là(d0, d1)[s0, s1] -> (s0, d0, d1, s1), trong đó(d0, d1)là chỉ mục củaout.s0,s1là các dải được xác định theo ngữ nghĩa của thao tác và chiều dài khoảng 0 và 3 của tenxơin. Các quy tắc ràng buộc làd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
Điều quan trọng cần lưu ý là trong hầu hết các trường hợp, chúng ta đều quan tâm đến việc lập bản đồ từ các phần tử của đầu ra. Để tính toán
C = op1(A, B)
E = op2(C, D)
chúng ta có thể nói về "lập chỉ mục B" có nghĩa là "ánh xạ các phần tử của E vào các phần tử của B". Điều này có thể đi ngược lại với các loại phân tích luồng dữ liệu khác hoạt động từ đầu vào đến đầu ra.
Các ràng buộc đối với các biến cho phép các cơ hội tối ưu hoá và hỗ trợ việc tạo mã. Trong tài liệu, các ràng buộc về việc triển khai cũng được gọi là miền vì chúng xác định tất cả các tổ hợp hoặc giá trị đối số hợp lệ của hàm ánh xạ. Đối với nhiều thao tác, các ràng buộc chỉ đơn giản là mô tả các phương diện của tensor, nhưng đối với một số thao tác, các ràng buộc có thể phức tạp hơn; hãy xem các ví dụ bên dưới.
Bằng cách biểu thị các hàm và ràng buộc đối số theo cách tượng trưng và có thể kết hợp các hàm và ràng buộc, chúng ta có thể tính toán một ánh xạ lập chỉ mục nhỏ gọn cho một phép tính lớn tuỳ ý (hợp nhất).
Tính biểu cảm của hàm và các quy tắc ràng buộc mang tính biểu tượng là sự cân bằng giữa độ phức tạp của việc triển khai và mức tăng tối ưu hoá mà chúng ta nhận được từ việc có một biểu diễn chính xác hơn. Đối với một số thao tác HLO, chúng tôi chỉ nắm bắt các mẫu truy cập một cách gần đúng.
Triển khai
Vì muốn giảm thiểu việc tính toán lại, chúng ta cần một thư viện để tính toán tượng trưng. XLA đã phụ thuộc vào MLIR, vì vậy, chúng tôi sử dụng mlir::AffineMap thay vì viết một thư viện số học tượng trưng khác.
AffineMap thường có dạng
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap có hai loại tham số: kích thước và biểu tượng.
Phương diện tương ứng với các biến phương diện d; ký hiệu tương ứng với các biến phạm vi r và biến thời gian chạy rt. AffineMap không chứa bất kỳ siêu dữ liệu nào về các ràng buộc của tham số, vì vậy, chúng ta phải cung cấp riêng các tham số này.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ mã hoá các ràng buộc hộp bao hàm cho các biến phương diện d của bản đồ lập chỉ mục, thường trùng với hình dạng của tensor đầu ra cho các thao tác như chuyển vị, giảm, theo phần tử, dấu chấm, nhưng có một số trường hợp ngoại lệ như HloConcatenateInstruction.
range_vars_ tất cả các giá trị mà các biến phạm vi s nhận. Bạn cần có các biến phạm vi khi cần nhiều giá trị để tính một phần tử duy nhất của tensor mà chúng ta đang ánh xạ, ví dụ: đối với bản đồ lập chỉ mục đầu ra->đầu vào của các phép rút gọn hoặc bản đồ đầu vào->đầu ra cho các phép truyền tin.
rt_vars_ mã hoá các giá trị khả thi trong thời gian chạy. Ví dụ: độ lệch là động đối với HloDynamicSliceInstruction 1D. RTVar tương ứng sẽ có các giá trị khả thi trong khoảng từ 0 đến tensor_size - slice_size - 1.
constraints_ nắm bắt mối quan hệ giữa các giá trị ở dạng <expression> in <range>, ví dụ: d0 + s0 in [0, 20]. Cùng với Variable.bounds, chúng xác định "miền" của hàm lập chỉ mục.
Hãy nghiên cứu bằng ví dụ để hiểu rõ ý nghĩa của tất cả những điều trên.
Lập chỉ mục Bản đồ cho các hoạt động không hợp nhất
Theo phần tử
Đối với các thao tác theo phần tử, bản đồ lập chỉ mục là một danh tính.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
Đầu ra cho bản đồ đầu vào output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Bản đồ đầu vào đến đầu ra p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Truyền tin
Truyền tin có nghĩa là một số phương diện sẽ bị xoá khi chúng ta ánh xạ đầu ra sang đầu vào và được thêm vào khi chúng ta ánh xạ đầu vào sang đầu ra.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
Đầu ra cho bản đồ đầu vào:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
Bản đồ đầu vào đến đầu ra:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Lưu ý rằng hiện tại chúng ta có các biến phạm vi s ở phía bên phải để liên kết đầu vào với đầu ra. Đó là những biểu tượng thể hiện các dải giá trị.
Ví dụ: trong trường hợp cụ thể này, mọi phần tử của dữ liệu đầu vào có chỉ mục d0 đều được ánh xạ đến một lát cắt 10x1x30 của dữ liệu đầu ra.
Iota
Iota không có toán hạng tensor đầu vào, nên không có đối số chỉ mục đầu vào.
iota = f32[2,4] iota(), dimensions={1}
Đầu ra cho bản đồ đầu vào:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Bản đồ đầu vào đến đầu ra:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice có các phần bù chỉ được biết trong thời gian chạy.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
Bản đồ đầu ra sang đầu vào từ ds đến src:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Lưu ý rằng hiện tại chúng ta có rt ở bên phải để ánh xạ đầu vào với đầu ra.
Đó là những biểu tượng đại diện cho các giá trị thời gian chạy. Ví dụ: trong trường hợp cụ thể này, đối với mọi phần tử của đầu ra có chỉ mục d0, d1, d2, chúng ta truy cập vào các độ lệch của lát cắt of1, of2 và of3 để tính chỉ mục của đầu vào.
Các khoảng cho biến thời gian chạy được suy ra bằng cách giả định rằng toàn bộ lát cắt nằm trong phạm vi.
Bản đồ đầu ra sang đầu vào cho of1, of2 và of3:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
Bản đồ đầu ra sang đầu vào cho src là không đáng kể. Bạn có thể làm cho truy vấn chính xác hơn bằng cách hạn chế miền đối với các chỉ mục chưa được cập nhật, nhưng hiện tại, các bản đồ lập chỉ mục không hỗ trợ các ràng buộc về sự bất bình đẳng.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
Đầu ra cho bản đồ đầu vào cho upd:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Xin lưu ý rằng giờ đây chúng ta có rt0 và rt1 đại diện cho các giá trị thời gian chạy. Trong trường hợp cụ thể này, đối với mọi phần tử của đầu ra có chỉ mục d0, d1, chúng ta sẽ truy cập vào các độ lệch của lát cắt of1 và of2 để tính chỉ mục của đầu vào. Các khoảng thời gian cho các biến thời gian chạy được suy ra bằng cách giả định rằng toàn bộ lát cắt nằm trong giới hạn.
Bản đồ đầu ra sang đầu vào cho of1 và of2:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
Chỉ hỗ trợ tính năng thu thập đơn giản. Xem gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
Đầu ra cho bản đồ đầu vào cho operand:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Xin lưu ý rằng hiện tại chúng ta có các biểu tượng rt đại diện cho các giá trị thời gian chạy.
Đầu ra cho bản đồ đầu vào cho indices:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
Biến phạm vi s0 cho thấy chúng ta cần toàn bộ hàng (d0, *) của tenxơ indices để tính toán một phần tử của đầu ra.
Chuyển vị
Bản đồ lập chỉ mục để chuyển vị là một hoán vị của các phương diện đầu vào/đầu ra.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
Đầu ra cho bản đồ đầu vào:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
Bản đồ đầu vào đến đầu ra:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Đảo ngược
Bản đồ lập chỉ mục cho các thay đổi đảo ngược, các phương diện được hoàn nguyên thành upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
Đầu ra cho bản đồ đầu vào:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
Bản đồ đầu vào đến đầu ra:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
Giảm số lượng biến có nhiều đầu vào và nhiều giá trị ban đầu, bản đồ từ đầu ra đến đầu vào sẽ thêm các phương diện được giảm.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
Đầu ra cho bản đồ đầu vào:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Bản đồ đầu vào đến đầu ra:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
Việc lập chỉ mục từ đầu ra đến đầu vào cho kết quả cắt sẽ tạo ra một bản đồ lập chỉ mục có bước, hợp lệ cho mọi phần tử của đầu ra. Việc ánh xạ từ đầu vào đến đầu ra bị giới hạn trong một dải ô có bước nhảy của các phần tử trong đầu vào.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
Đầu ra cho bản đồ đầu vào:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
Bản đồ đầu vào đến đầu ra:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Tạo lại hình dạng
Có nhiều loại định hình lại.
Thu gọn hình dạng
Đây là một thao tác định hình lại "tuyến tính hoá" từ N-D thành 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
Đầu ra cho bản đồ đầu vào:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Bản đồ đầu vào đến đầu ra:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Mở rộng hình dạng
Đây là một thao tác "thu gọn hình dạng" nghịch đảo, thao tác này sẽ định hình lại một đầu vào 1D thành đầu ra N-D.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
Đầu ra cho bản đồ đầu vào:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Bản đồ đầu vào đến đầu ra:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Tái định hình chung
Đây là những thao tác định hình lại không thể biểu thị dưới dạng một hình dạng mở rộng hoặc thu gọn duy nhất. Chúng chỉ có thể được biểu thị dưới dạng một thành phần gồm 2 hoặc nhiều hình dạng mở rộng hoặc thu gọn.
Ví dụ 1: Tuyến tính hoá – phi tuyến tính hoá.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Bạn có thể biểu thị thao tác định hình lại này dưới dạng một thành phần kết hợp của hình dạng thu gọn từ tensor<4x8xf32> thành tensor<32xf32>, sau đó là một hình dạng mở rộng thành tensor<2x4x4xf32>.
Đầu ra cho bản đồ đầu vào:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
Bản đồ đầu vào đến đầu ra:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Ví dụ 2: Hình dạng con được mở rộng và thu gọn
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Bạn có thể biểu thị thao tác định hình lại này dưới dạng một tổ hợp của hai thao tác định hình lại. Thao tác đầu tiên thu gọn các phương diện ngoài cùng tensor<4x8x12xf32> thành tensor<32x12xf32> và thao tác thứ hai mở rộng phương diện trong cùng tensor<32x12xf32> thành tensor<32x3x4xf32>.
Đầu ra cho bản đồ đầu vào:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
Bản đồ đầu vào đến đầu ra:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
Một thao tác bitcast có thể được biểu thị dưới dạng trình tự chuyển vị-định hình lại-chuyển vị. Do đó, các bản đồ lập chỉ mục của nó chỉ là một thành phần của các bản đồ lập chỉ mục cho chuỗi này.
Nối
Mối liên kết đầu ra với đầu vào cho concat được xác định cho tất cả các đầu vào, nhưng với các miền không chồng chéo, tức là chỉ một trong các đầu vào sẽ được sử dụng tại một thời điểm.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
Bản đồ đầu ra cho đầu vào:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
Đầu vào cho bản đồ đầu ra:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
Việc lập chỉ mục các bản đồ cho dot rất giống với việc lập chỉ mục các bản đồ cho reduce.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
Bản đồ đầu ra cho đầu vào:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
Đầu vào cho bản đồ đầu ra:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
Lập chỉ mục PadOp là giá trị nghịch đảo của lập chỉ mục SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
Cấu hình khoảng đệm 1_4_1x4_8_0 biểu thị lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
Đầu ra cho bản đồ đầu vào:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
ReduceWindow trong XLA cũng thực hiện việc thêm khoảng đệm. Do đó, bạn có thể tính toán các chỉ mục ánh xạ dưới dạng một thành phần của chỉ mục ReduceWindow không thực hiện bất kỳ thao tác đệm nào và chỉ mục PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
Đầu ra cho bản đồ đầu vào:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Lập chỉ mục bản đồ cho Fusion
Bản đồ lập chỉ mục cho thao tác hợp nhất là một thành phần của bản đồ lập chỉ mục cho mọi thao tác trong cụm. Có thể xảy ra trường hợp một số đầu vào được đọc nhiều lần với các mẫu truy cập khác nhau.
Một đầu vào, nhiều bản đồ lập chỉ mục
Sau đây là một ví dụ về p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Các sơ đồ lập chỉ mục đầu ra thành đầu vào cho p0 sẽ là (d0, d1) -> (d0, d1) và (d0, d1) -> (d1, d0). Điều này có nghĩa là để tính toán một phần tử của đầu ra, chúng ta có thể cần đọc tham số đầu vào hai lần.
Một đầu vào, bản đồ lập chỉ mục được loại bỏ trùng lặp
![]()
Có những trường hợp các bản đồ lập chỉ mục thực sự giống nhau, mặc dù điều này không rõ ràng ngay lập tức.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
Trong trường hợp này, bản đồ lập chỉ mục đầu ra thành đầu vào cho p0 chỉ là (d0, d1, d2) -> (d2, d0, d1).
Softmax
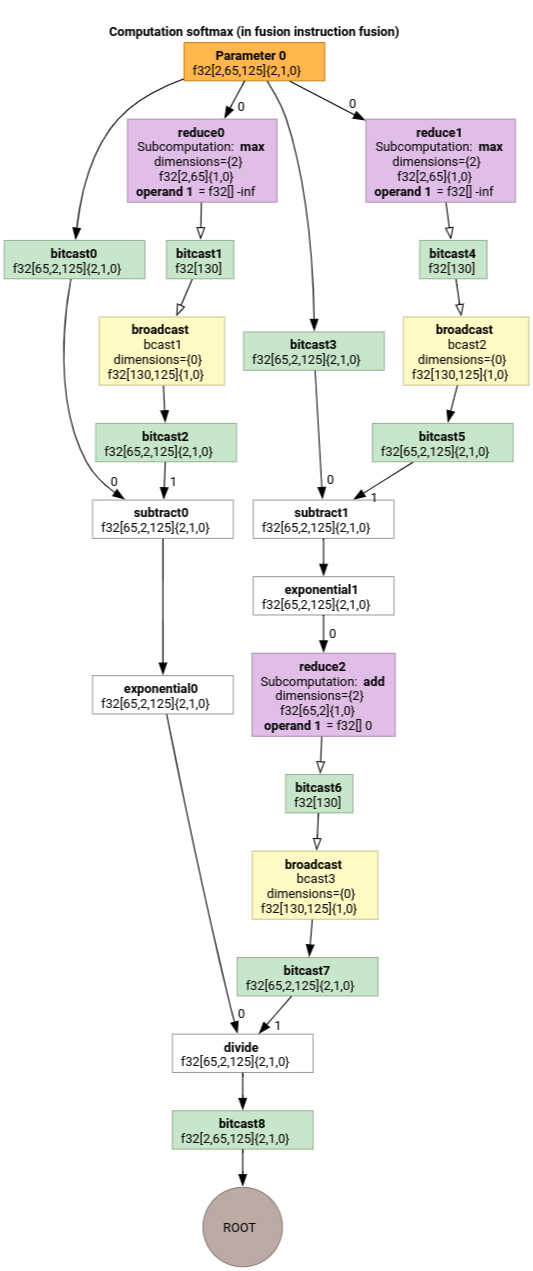
Các bản đồ lập chỉ mục đầu ra sang đầu vào cho parameter 0 cho softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
và
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
trong đó s0 là phương diện trong cùng của dữ liệu đầu vào.
Để xem thêm ví dụ, hãy xem indexing_analysis_test.cc.
Công cụ đơn giản hoá chỉ mục
Trình đơn giản hoá mặc định cho mlir::AffineMap ở nguồn trên không thể đưa ra bất kỳ giả định nào về phạm vi của các phương diện/ký hiệu. Do đó, nó không thể đơn giản hoá các biểu thức bằng mod và div một cách hiệu quả.
Chúng ta có thể tận dụng kiến thức về các giới hạn dưới và trên của biểu thức phụ trong các ánh xạ affine để đơn giản hoá chúng hơn nữa.
Trình đơn giản hoá có thể viết lại các biểu thức sau.
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)cho d trong[0, 6] x [0, 14]trở thành(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)chodi in [0, 9]trở thành(d0, d1, d2) -> (d0, d1, d2).(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)chod_i in [0, 9]trở thành(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8).(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)cho d trong[0, 9] x [0, 10]trở thành(d0, d1) -> (d0).
Trình đơn giản hoá bản đồ lập chỉ mục cho phép chúng ta hiểu rằng một số thao tác định hình lại theo chuỗi trong HLO sẽ huỷ lẫn nhau.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
Sau khi tạo bản đồ lập chỉ mục và đơn giản hoá bản đồ, chúng ta sẽ có
(d0, d1, d2) -> (d0, d1, d2).
Việc đơn giản hoá bản đồ lập chỉ mục cũng giúp đơn giản hoá các ràng buộc.
- Các ràng buộc thuộc loại
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundđược viết lại thànhupdated_lower_bound <= affine_expr <= updated_upped_bound. - Các quy tắc ràng buộc luôn được đáp ứng, ví dụ:
d0 + s0 in [0, 20]chod0 in [0, 5]vàs0 in [1, 3]sẽ bị loại bỏ. - Các biểu thức affine trong các ràng buộc được tối ưu hoá dưới dạng bản đồ affine lập chỉ mục ở trên.
Để xem thêm ví dụ, hãy xem indexing_map_test.cc.