
HLO 索引分析是資料流程分析,用於說明一個張量的元素如何透過「索引對應」與另一個張量的元素建立關聯。舉例來說,HLO 指令輸出的索引如何對應至 HLO 指令運算元的索引。
範例
從 tensor<20xf32> 廣播至 tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
從輸出到輸入的索引對應為 (i, j, k) -> (j),適用於 i in
[0, 10]、j in [0, 20] 和 k in [0, 30]。
動機
XLA 會使用多種專屬解決方案,推斷合併、運算元利用率和分塊配置 (詳情請見下文)。索引分析的目標是為這類用途提供可重複使用的元件。索引分析是以 MLIR 的仿射對應基礎架構為基礎,並加入 HLO 語意。
合併
當我們知道要讀取哪些輸入元素/切片來計算輸出元素時,就能針對非簡單案例進行記憶體合併的推理。
運算元使用率
XLA 中的運算元使用率表示指令的每個輸入內容的使用量 (假設輸出內容已完全使用)。目前,系統也不會計算一般情況的利用率。索引分析可讓我們精確計算使用率。
圖塊
圖塊/切片是張量的超矩形子集,由偏移量、大小和步幅參數化。圖塊傳播可使用運算元本身的平鋪參數,計算運算元生產者/消費者的圖塊參數。目前已有程式庫可執行 softmax 和點積作業。如果透過索引對應表示,圖塊傳播可以更通用且穩固。
索引地圖
索引地圖是下列項目的組合:
- 以符號表示的函式,可將張量
A的每個元素對應至張量B的元素範圍; - 有效函式引數的限制,包括函式的網域。
函式引數分為 3 類,方便您瞭解引數的性質:
張量
A的維度變數,或我們對應的 GPU 格線;值是靜態已知的。索引元素也稱為「維度變數」。範圍變數。這些函式會定義一對多對應,並在
B中指定一組元素,用於計算A的單一值;這些值是靜態值。矩陣乘法的收縮維度是範圍變數的範例。執行階段變數,這類變數只會在執行期間得知。舉例來說,gather 作業的索引引數。
函式的結果是目標 B 張量的索引。
簡而言之,從張量 A 到張量 B 的索引函式,適用於運算 x
map_ab(index in A, range variables, runtime variables) -> index in B。
為更清楚區分對應引數的類型,我們將其編寫為:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
舉例來說,我們來看看縮減作業的索引對應:
f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
將
in的元素對應至out,我們的函式可以表示為(d0, d1, d2, d3) -> (d1, d2)。變數d0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]的限制條件是由in的形狀定義。如要將
out的元素對應至in,out只有兩個維度,而縮減會導入兩個涵蓋縮減維度的範圍變數。因此對應函式為(d0, d1)[s0, s1] -> (s0, d0, d1, s1),其中(d0, d1)是out的索引。s0和s1是由作業語意定義的範圍,以及in張量範圍維度 0 和 3。限制為d0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15]。
請注意,在大多數情況下,我們感興趣的是從輸出的元素進行對應。用於計算
C = op1(A, B)
E = op2(C, D)
我們可以討論「B 的索引」,也就是「將 E 的元素對應到 B 的元素」。相較於從輸入到輸出的其他類型資料流分析,這可能違反直覺。
變數的限制可提供最佳化機會,並協助產生程式碼。在說明文件和實作限制中,也稱為「網域」,因為這些限制會定義對應函式的所有有效組合或引數值。對於許多作業而言,限制條件只是描述張量的維度,但對於某些作業而言,限制條件可能更複雜,請參閱下方的範例。
透過以符號表示函式和引數限制,並結合函式和限制,我們可以計算任意大型運算 (融合) 的精簡索引對應。
符號函式和限制條件的表達能力,是在實作複雜度和最佳化收益之間取得平衡,因為更精確的表示法可帶來最佳化收益。對於某些 HLO 作業,我們只會大約擷取存取模式。
導入作業
由於我們想盡量減少重新運算,因此需要用於符號運算的程式庫。XLA 已經依附於 MLIR,因此我們使用 mlir::AffineMap, 而不是編寫另一個符號算術程式庫。
典型的 AffineMap 如下所示
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap 有兩種參數:維度和符號。
維度對應於維度變數 d;符號對應於範圍變數 r 和執行階段變數 rt。AffineMap 不含參數限制的任何中繼資料,因此我們必須另外提供。
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ 對索引對映的維度變數 d 編碼含括方塊限制,這通常與轉置、縮減、元素式、點積等運算的輸出張量形狀一致,但也有例外狀況,例如 HloConcatenateInstruction。
range_vars_ 範圍變數 s 的所有值。當需要多個值來計算要對應的張量單一元素時,就需要範圍變數,例如縮減作業的輸出 -> 輸入索引對應,或是廣播作業的輸入 -> 輸出對應。
rt_vars_ 在執行階段編碼可行值。舉例來說,1D HloDynamicSliceInstruction 的位移是動態的。對應的 RTVar 會有介於 0 和 tensor_size - slice_size - 1 之間的可行值。
constraints_擷取表單中各個值之間的關係<expression> in <range>,例如 d0 + s0 in [0, 20]。與 Variable.bounds 共同定義索引函式的「網域」。
讓我們透過範例來瞭解上述各項概念的實際意義。
為未合併的作業建立地圖索引
Elementwise
對於元素運算,索引對應是身分。
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
輸出至輸入對應 output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
輸入至輸出內容對應 p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
廣播
廣播是指在將輸出對應至輸入時,系統會移除部分維度;將輸入對應至輸出時,則會新增維度。
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
輸出至輸入對應:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
輸入至輸出內容對應:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
請注意,現在輸入到輸出對應的右側有範圍變數 s。這些符號代表值的範圍。
舉例來說,在本例中,索引 d0 的每個輸入元素都會對應到輸出內容的 10x1x30 切片。
Iota
Iota 沒有輸入張量運算元,因此沒有輸入索引引數。
iota = f32[2,4] iota(), dimensions={1}
輸出至輸入對應:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
輸入至輸出內容對應:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice 具有僅在執行階段才可知的位移。
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
從 ds 到 src 的輸出至輸入對應:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
請注意,現在輸入到輸出的對應關係位於右側的 rt。
這些符號代表執行階段值。舉例來說,在這個特定案例中,對於輸出內容的每個元素 (索引為 d0, d1, d2),我們會存取切片偏移 of1、of2 和 of3,藉此計算輸入內容的索引。執行階段變數的間隔是假設整個切片保持在界限內而推導出來。
of1、of2 和 of3 的輸出至輸入對應:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
src 的輸出至輸入對應非常簡單。您可以將網域限制為未更新的索引,進一步提高準確度,但目前索引對應不支援不等式限制。
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
upd 的輸出至輸入對應:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
請注意,現在我們有 rt0 和 rt1,代表執行階段值。在這個特定案例中,對於輸出內容的每個元素 (索引為 d0, d1),我們會存取切片偏移 of1 和 of2,以計算輸入內容的索引。執行階段變數的間隔是假設整個切片保持在界限內而推導得出。
of1 和 of2 的輸出至輸入對應:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
系統僅支援簡化版收集功能。請參閱 gather_simplifier.h。
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
operand 的輸出至輸入對應:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
請注意,現在我們有代表執行階段值的 rt 符號。
indices 的輸出至輸入對應:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
範圍變數 s0 顯示我們需要 indices 張量中的整列 (d0, *),才能計算輸出內容的元素。
轉置
轉置的索引對應是輸入/輸出維度的排列。
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
輸出至輸入對應:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
輸入至輸出內容對應:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
反向
索引對應表 (適用於反向變更) 會將還原的維度變更為 upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
輸出至輸入對應:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
輸入至輸出內容對應:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
可變縮減有多個輸入和多個初始值,從輸出到輸入的對應會新增縮減的維度。
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
輸出至輸入對應:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
輸入至輸出內容的對應:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
從輸出到切片結果的輸入建立索引,會產生適用於輸出中每個元素的步幅索引對應。輸入到輸出的對應會限制在輸入中元素的步進範圍。
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
輸出至輸入對應:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
輸入至輸出內容對應:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
重新塑形
重塑功能有不同變種版本。
收合形狀
這是從 N 維到 1 維的「線性化」重塑。
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
輸出至輸入對應:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
輸入至輸出內容對應:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
展開形狀
這是「摺疊形狀」作業的反向作業,可將 1D 輸入內容重塑為 N-D 輸出內容。
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
輸出至輸入對應:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
輸入至輸出內容對應:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
一般重塑
這些是無法以單一擴展或摺疊形狀表示的重塑作業。只能以 2 個以上的展開或收合形狀組合表示。
範例 1:線性化-去線性化。
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
這種重塑可表示為從 tensor<4x8xf32> 到 tensor<32xf32> 的形狀摺疊,然後再擴展到 tensor<2x4x4xf32> 的組合。
輸出至輸入對應:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
輸入至輸出內容對應:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
範例 2:展開和收合的子圖形
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
這項重塑作業可表示為兩項重塑作業的組合。第一個會將最外層的維度 tensor<4x8x12xf32> 摺疊為 tensor<32x12xf32>,第二個則會將最內層的維度 tensor<32x12xf32> 展開為 tensor<32x3x4xf32>。
輸出至輸入對應:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
輸入至輸出內容對應:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
位元轉換運算可以表示為轉置-重塑-轉置序列。因此,這項序列的索引地圖只是這些索引地圖的組合。
串連
系統會為所有輸入定義 concat 的輸出至輸入對應,但使用不重疊的網域,也就是一次只會使用一個輸入。
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
輸出至輸入內容的對應:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
輸出地圖的輸入內容:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
點的索引對應與縮減的索引對應非常相似。
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
輸出至輸入內容的對應:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
輸出地圖的輸入內容:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
PadOp 的索引與 SliceOp 的索引相反。
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
邊框間距設定 1_4_1x4_8_0 表示 lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1。
輸出至輸入對應:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
XLA 中的 ReduceWindow 也會執行填補作業。因此,索引對應可以計算為 ReduceWindow 索引的組合,不會執行任何填補作業,以及 PadOp 的索引。
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
輸出至輸入對應:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
為 Fusion 建立地圖索引
融合作業的索引對應是叢集中每個作業的索引對應組合。某些輸入內容可能會以不同的存取模式讀取多次。
一個輸入內容,多個索引地圖
以下是 p0 + transpose(p0) 的範例。
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
p0 的輸出至輸入索引對應會是 (d0, d1) -> (d0, d1) 和 (d0, d1) -> (d1, d0)。也就是說,如要計算輸出內容的某個元素,我們可能需要讀取輸入參數兩次。
一個輸入內容,重複資料刪除索引對應
![]()
有時索引對應表實際上是相同的,但並非顯而易見。
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
在本例中,p0 的輸出至輸入索引對應只是 (d0, d1, d2) -> (d2, d0, d1)。
Softmax
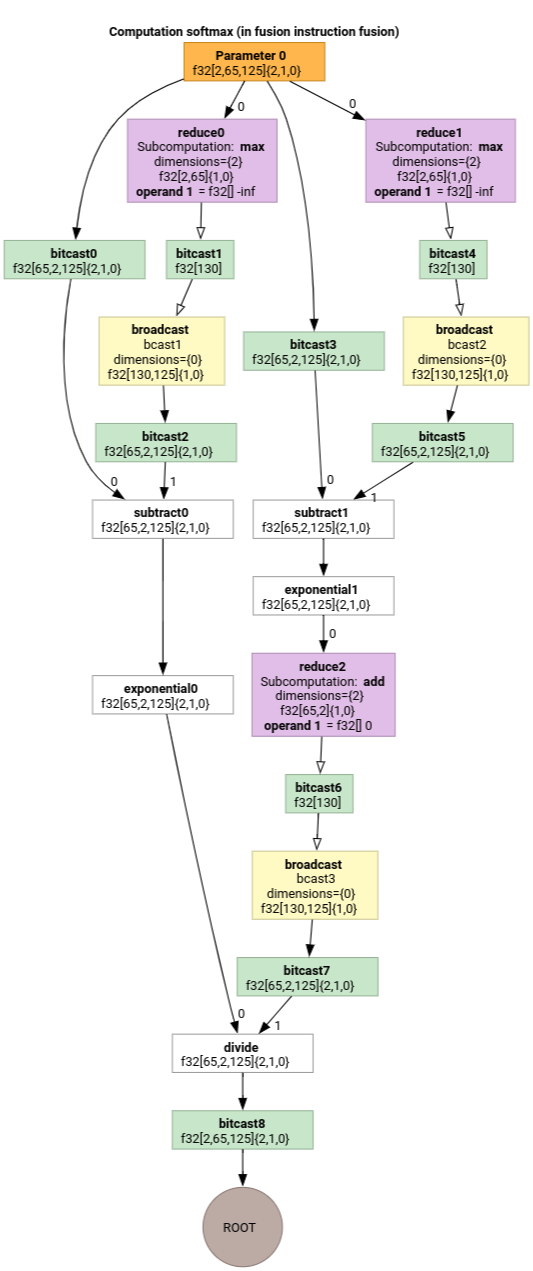
Softmax 的輸出至輸入索引對應:parameter 0
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
和
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
其中 s0 是指輸入內容的最內層維度。
如需更多範例,請參閱 indexing_analysis_test.cc。
索引地圖簡化器
mlir::AffineMap 上游的預設簡化器無法對維度/符號的範圍做出任何假設。因此無法有效簡化含有 mod 和 div 的運算式。
我們可以運用仿射對映中子運算式的上下限相關知識,進一步簡化這些運算式。
簡化器可以改寫下列運算式。
- 「
[0, 6] x [0, 14]」的「d」會變成「(d0, d1) -> (d0, d1)」(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16) (d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)的「di in [0, 9]」會變成「(d0, d1, d2) -> (d0, d1, d2)」。(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)的「d_i in [0, 9]」會變成「(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8)」。(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)的「d」 會變成「[0, 9] x [0, 10]」,「(d0, d1) -> (d0)」。
索引對應簡化器可讓我們瞭解,HLO 中某些鏈結的重塑作業會彼此取消。
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
編排索引對應表並簡化後,我們會得到
(d0, d1, d2) -> (d0, d1, d2)。
索引地圖簡化作業也會簡化限制。
- 類型為
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_bound的限制條件會改寫為updated_lower_bound <= affine_expr <= updated_upped_bound。 - 系統會排除一律符合的限制,例如
d0 + s0 in [0, 20]的d0 in [0, 5]和s0 in [1, 3]。 - 約束條件中的仿射運算式會經過最佳化,如上方的索引仿射對應所示。
如需更多範例,請參閱 indexing_map_test.cc。