
HLO 索引分析是一种数据流分析,用于描述一个张量的元素如何通过“索引映射”与另一个张量的元素相关联。例如,HLO 指令输出的索引如何映射到 HLO 指令操作数的索引。
示例
对于从 tensor<20xf32> 到 tensor<10x20x30xf32> 的广播
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
从输出到输入的索引映射对于 i in
[0, 10]、j in [0, 20] 和 k in [0, 30] 为 (i, j, k) -> (j)。
设计初衷
XLA 使用多种定制解决方案来推理合并、操作数利用率和平铺方案(详见下文)。索引分析的目标是为这类使用场景提供可重用的组件。索引分析基于 MLIR 的仿射映射基础架构构建,并添加了 HLO 语义。
合并
当我们知道读取哪些输入元素/切片来计算输出元素时,就可以针对非平凡情况进行内存合并推理。
操作数利用率
XLA 中的操作数利用率表示假设指令的输出得到充分利用,则指令的每个输入的使用程度。目前,系统也不会计算一般情况下的利用率。通过索引分析,我们可以精确计算利用率。
平铺:
平铺/切片是由偏移量、大小和步幅参数化的张量的超矩形子集。平铺传播是一种使用运算本身的平铺参数来计算运算的生产者/消费者的平铺参数的方法。已经有一个库可以实现 softmax 和点积。如果通过索引映射来表达,图块传播可以变得更加通用和稳健。
编制索引地图
索引映射是以下各项的组合
- 一种以符号表示的函数,用于将张量
A的每个元素映射到张量B中的元素范围; - 对有效函数实参的限制,包括函数网域。
函数实参分为 3 类,以便更好地说明其性质:
张量
A或我们正在映射的 GPU 网格的维度变量;值是静态已知的。索引元素也称为维度变量。范围变量。它们定义了一对多映射,并指定了
B中的一组元素,用于计算A的单个值;这些值是静态已知的。矩阵乘法的收缩维度是范围变量的一个示例。仅在执行期间已知的运行时变量。例如,gather 操作的 indices 实参。
函数的结果是目标 B 张量的索引。
简而言之,对于操作 x,从张量 A 到张量 B 的索引函数为
map_ab(index in A, range variables, runtime variables) -> index in B。
为了更好地区分映射实参的类型,我们将其写为:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
例如,我们来看一下 reduce 操作 f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3} 的索引映射:
将
in的元素映射到out的函数可以表示为(d0, d1, d2, d3) -> (d1, d2)。变量d0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]的约束由in的形状定义。将
out的元素映射到in:out只有两个维度,而缩减会引入两个涵盖缩减维度的范围变量。因此,映射函数为(d0, d1)[s0, s1] -> (s0, d0, d1, s1),其中(d0, d1)是out的指数。s0、s1是由操作的语义定义的范围,跨越in张量的维度 0 和 3。限制条件为d0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15]。
请务必注意,在大多数情况下,我们都希望从输出的元素进行映射。用于计算
C = op1(A, B)
E = op2(C, D)
我们可以说“B 的索引”,意思是“将 E 的元素映射到 B 的元素”。与其他从输入到输出的数据流分析相比,这可能有点反直觉。
变量的约束可提供优化机会,并有助于代码生成。在文档和实现中,约束也称为网域,因为它们定义了映射函数的所有有效组合或实参值。对于许多操作,约束条件只是描述张量的维度,但对于某些操作,约束条件可能会更复杂;请参见下面的示例。
通过以符号方式表达函数和实参限制,并能够组合函数和限制,我们可以为任意大型计算(融合)计算出紧凑的索引映射。
符号函数和约束的表达能力需要在实现复杂性和通过更精确的表示获得的优化增益之间取得平衡。对于某些 HLO 操作,我们仅大致捕获访问模式。
实现
由于我们希望尽可能减少重新计算,因此需要一个用于符号计算的库。XLA 已经依赖于 MLIR,因此我们使用 mlir::AffineMap,而不是编写另一个符号算术库。
典型的 AffineMap 如下所示
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap 有两种类型的参数:维度和符号。
维度对应于维度变量 d;符号对应于范围变量 r 和运行时变量 rt。AffineMap 不包含任何关于形参限制的元数据,因此我们必须单独提供这些信息。
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ 用于对索引映射的维度变量 d 的包含性方框约束进行编码,这些约束通常与转置、归约、按元素运算、点积等运算的输出张量的形状一致,但也有一些例外情况,例如 HloConcatenateInstruction。
range_vars_ 范围变量 s 的所有值。当需要多个值来计算我们正在映射的张量的单个元素时,就需要范围变量,例如,对于归约的输出到输入索引映射或广播的输入到输出映射。
rt_vars_ 在运行时对可行值进行编码。例如,对于 1D HloDynamicSliceInstruction,偏移量是动态的。相应的 RTVar 将具有介于 0 和 tensor_size - slice_size - 1 之间的可行值。
constraints_ 以 <expression> in <range> 形式捕获值之间的关系,例如 d0 + s0 in [0, 20]。它们与 Variable.bounds 一起定义了索引函数的“域”。
让我们通过示例来了解上述所有内容实际上意味着什么。
为非融合操作编入地图索引
按元素
对于按元素执行的运算,索引映射是恒等映射。
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
输出到输入映射 output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
输入到输出映射 p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
广播
广播是指,在将输出映射到输入时,某些维度会被移除;而在将输入映射到输出时,某些维度会被添加。
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
输出到输入映射:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
输入到输出的映射:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
请注意,现在右侧有范围变量 s,用于输入到输出的映射。这些符号表示值范围。
例如,在此特定情况下,索引为 d0 的输入的每个元素都会映射到输出的 10x1x30 切片。
Iota
Iota 没有输入张量操作数,因此没有输入索引实参。
iota = f32[2,4] iota(), dimensions={1}
输出到输入源映射:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
输入到输出地图:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice 具有仅在运行时才已知的偏移量。
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
从 ds 到 src 的输出到输入映射:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
请注意,现在我们在右侧添加了 rt,用于表示输入到输出的映射关系。
这些符号表示运行时值。例如,在此特定情况下,对于索引为 d0, d1, d2 的输出的每个元素,我们访问切片偏移量 of1、of2 和 of3 来计算输入的索引。运行时变量的区间是通过假设整个切片保持在界限内推导出来的。
of1、of2 和 of3 的输出到输入映射:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
src 的输出到输入映射是微不足道的。通过将网域限制为未更新的索引,可以提高精确度,但目前索引映射不支持不等式约束。
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
upd 的输出到输入映射:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
请注意,现在我们有了表示运行时值的 rt0 和 rt1。在此特定情况下,对于索引为 d0, d1 的输出的每个元素,我们访问切片偏移量 of1 和 of2 来计算输入的索引。运行时变量的区间是通过假设整个切片保持在界限内推导出来的。
of1 和 of2 的输出到输入映射:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
仅支持简化的收集。请参阅 gather_simplifier.h。
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
operand 的输出到输入映射:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
请注意,现在我们有了表示运行时值的 rt 符号。
indices 的输出到输入映射:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
范围变量 s0 表明我们需要 indices 张量的整个行 (d0, *) 来计算输出的某个元素。
转置
转置的索引映射是输入/输出维度的一种排列。
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
输出到输入映射:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
输入到输出的映射:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
反向
用于反向更改的索引映射,将还原的维度更改为 upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
输出到输入映射:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
输入到输出的映射:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(可变元数)Reduce
变参缩减有多个输入和多个初始值,从输出到输入的映射会添加缩减后的维度。
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
输出到输入源的映射:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
输入到输出的映射:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
从输出到输入的切片结果的索引会生成一个步幅索引映射,该映射对输出的每个元素都有效。从输入到输出的映射仅限于输入中元素的步进范围。
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
输出到输入映射:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
输入到输出的映射:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
重塑
重塑有不同的风格。
收起形状
这是从 N 维到 1 维的“线性化”重塑。
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
输出到输入映射:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
输入到输出的映射:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
展开形状
这是反向“折叠形状”运算,它将一维输入重塑为 N 维输出。
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
输出到输入映射:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
输入到输出的映射:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
通用 reshape
这些是无法表示为单个展开或折叠形状的重塑操作。它们只能表示为 2 个或更多展开或收起形状的组合。
示例 1:线性化-非线性化。
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
这种重塑可以表示为将 tensor<4x8xf32> 的形状压缩为 tensor<32xf32>,然后再将形状扩展为 tensor<2x4x4xf32> 的组合。
输出到输入映射:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
输入到输出的映射:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
示例 2:展开和收起子形状
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
这种重塑可以表示为两种重塑的组合。第一个函数将最外层维度 tensor<4x8x12xf32> 折叠为 tensor<32x12xf32>,第二个函数将最内层维度 tensor<32x12xf32> 扩展为 tensor<32x3x4xf32>。
输出到输入映射:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
输入到输出的映射:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
一个 bitcast 操作可以表示为转置-重塑-转置序列。因此,其索引映射只是相应序列的索引映射的组合。
串联
concat 的输出到输入映射是为所有输入定义的,但具有不重叠的网域,即一次只能使用一个输入。
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
输出到输入的映射:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
输出地图的输入:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
点积的索引映射与归约的索引映射非常相似。
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
输出到输入的映射:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- 输出 -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
输出地图的输入:
- p0 -> 输出:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> 输出:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
PadOp 的索引是 SliceOp 索引的逆。
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
填充配置 1_4_1x4_8_0 表示 lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1。
输出到输入源的映射:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- 输出 -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
XLA 中的 ReduceWindow 也会执行填充。因此,索引映射可以计算为不进行任何填充的 ReduceWindow 索引与 PadOp 的索引的组合。
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
输出到输入源的映射:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
为 Fusion 编制地图索引
融合操作的索引映射是集群中每个操作的索引映射的组合。可能会出现以下情况:某些输入被多次读取,但每次的访问模式都不同。
一个输入,多个索引映射
以下是 p0 + transpose(p0) 的示例。
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
p0 的输出到输入索引映射将为 (d0, d1) -> (d0, d1) 和 (d0, d1) -> (d1, d0)。这意味着,为了计算输出的一个元素,我们可能需要读取两次输入形参。
一个输入,去重索引映射
![]()
在某些情况下,即使索引映射看起来不同,但实际上是相同的。
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
在这种情况下,p0 的输出到输入索引映射只是 (d0, d1, d2) -> (d2, d0, d1)。
Softmax
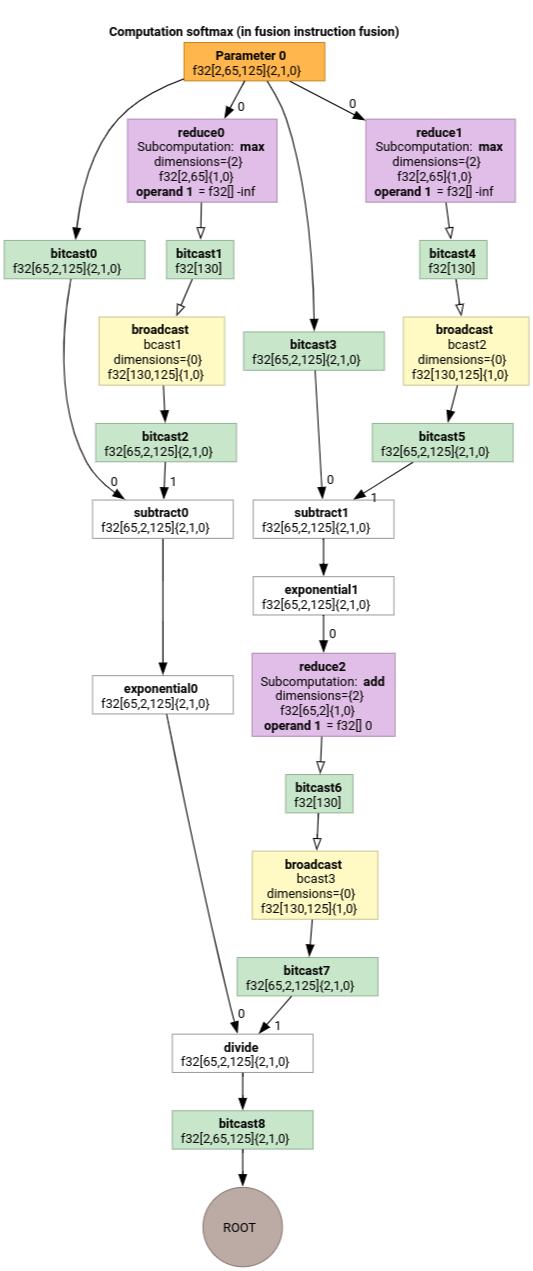
softmax 的输出到输入索引映射(针对 parameter 0):
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
和
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
其中 s0 是指输入的内层维度。
如需查看更多示例,请参阅 indexing_analysis_test.cc。
索引地图简化器
mlir::AffineMap 上游的默认简化器无法对维度/符号的范围做出任何假设。因此,它无法高效地简化包含 mod 和 div 的表达式。
我们可以利用仿射映射中子表达式的下限和上限相关知识,进一步简化这些表达式。
简化器可以重写以下表达式。
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)([0, 6] x [0, 14]中的 d)变为(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)(针对di in [0, 9])变为(d0, d1, d2) -> (d0, d1, d2)。(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)(针对d_i in [0, 9])变为(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8)。[0, 9] x [0, 10]中d的(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)变为(d0, d1) -> (d0)。
通过索引映射简化器,我们可以了解到 HLO 中的某些链式 reshape 会相互抵消。
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
在编制索引映射并对其进行简化后,我们将获得
(d0, d1, d2) -> (d0, d1, d2)。
简化索引图也会简化限制条件。
- 类型为
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_bound的约束会被重写为updated_lower_bound <= affine_expr <= updated_upped_bound。 - 始终满足的约束(例如
d0 + s0 in [0, 20]中d0 in [0, 5]和s0 in [1, 3]的约束)会被消除。 - 约束中的仿射表达式会优化为上面的索引仿射映射。
如需查看更多示例,请参阅 indexing_map_test.cc。