
Analiza indeksowania HLO to analiza przepływu danych, która opisuje, jak elementy jednego tensora są powiązane z innym za pomocą „map indeksowania”. Na przykład jak indeksy danych wyjściowych instrukcji HLO są mapowane na indeksy operandów instrukcji HLO.
Przykład
W przypadku transmisji z tensor<20xf32> do tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
mapa indeksowania z danych wyjściowych na wejściowe to (i, j, k) -> (j) dla i in
[0, 10], j in [0, 20] i k in [0, 30].
Motywacja
XLA korzysta z kilku niestandardowych rozwiązań do wnioskowania o łączeniu, wykorzystaniu operandów i schematach dzielenia na kafelki (więcej szczegółów poniżej). Celem analizy indeksowania jest udostępnienie komponentu wielokrotnego użytku do takich zastosowań. Analiza indeksowania jest oparta na infrastrukturze map afinicznych MLIR i dodaje semantykę HLO.
Łączenie
Rozumowanie dotyczące łączenia pamięci staje się możliwe w przypadku nietrywialnych przypadków, gdy wiemy, które elementy lub wycinki danych wejściowych są odczytywane w celu obliczenia elementu danych wyjściowych.
Wykorzystanie argumentu operacji
Wykorzystanie operandu w XLA wskazuje, w jakim stopniu używane jest każde wejście instrukcji, przy założeniu, że jej wyjście jest w pełni wykorzystywane. Obecnie wykorzystanie nie jest też obliczane w przypadku ogólnym. Analiza indeksowania pozwala nam dokładnie obliczać wykorzystanie.
Segmentacja:
Płytka/wycinek to hiperprostokątny podzbiór tensora sparametryzowany przez przesunięcia, rozmiary i kroki. Propagacja kafelków to sposób obliczania parametrów kafelków producenta/konsumenta operacji za pomocą parametrów kafelkowania samej operacji. Istnieje już biblioteka, która wykonuje to działanie w przypadku funkcji softmax i iloczynu skalarnego. Rozpowszechnianie kafelków może być bardziej ogólne i niezawodne, jeśli jest wyrażone za pomocą map indeksowania.
Mapa indeksowania
Mapa indeksowania to połączenie
- funkcja wyrażona symbolicznie, która mapuje każdy element jednego tensora
Ana zakresy elementów w tensorzeB; - ograniczenia dotyczące prawidłowych argumentów funkcji, w tym domeny funkcji.
Argumenty funkcji są podzielone na 3 kategorie, aby lepiej przedstawić ich charakter:
zmienne wymiaru tensora
Alub siatki GPU, z której mapujemy; wartości są znane statycznie. Elementy indeksu są też nazywane zmiennymi wymiaru.zmienne range. Definiują one mapowanie typu „jeden do wielu” i określają zestaw elementów w parametrze
Bużywanych do obliczania pojedynczej wartości parametruA. Wartości są znane statycznie. Wymiar kurczący się mnożenia macierzy jest przykładem zmiennej zakresu.zmienne środowiskowe, które są znane tylko w trakcie wykonywania. Na przykład argument indices operacji gather.
Wynikiem funkcji jest indeks tensora docelowego B.
Krótko mówiąc, funkcja indeksowania z tensora A do tensora B dla operacji x
to
map_ab(index in A, range variables, runtime variables) -> index in B.
Aby lepiej rozróżnić typy argumentów mapowania, zapisujemy je w ten sposób:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Przyjrzyjmy się na przykład mapom indeksowania dla operacji reduce:f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}
Aby przypisać elementy
indoout, naszą funkcję można zapisać jako(d0, d1, d2, d3) -> (d1, d2). Ograniczenia zmiennychd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]są zdefiniowane przez kształtin.Aby zmapować elementy
outnain:outma tylko 2 wymiary, a redukcja wprowadza 2 zmienne zakresu, które obejmują zmniejszanie wymiarów. Funkcja mapowania to(d0, d1)[s0, s1] -> (s0, d0, d1, s1), gdzie(d0, d1)to indeksout.s0,s1to zakresy zdefiniowane przez semantykę operacji i obejmujące wymiary 0 i 3 tensorain. Ograniczenia tod0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
Pamiętaj, że w większości przypadków interesuje nas mapowanie elementów danych wyjściowych. Do obliczeń
C = op1(A, B)
E = op2(C, D)
możemy mówić o „indeksowaniu B”, co oznacza „mapowanie elementów E na elementy B”. Może to być sprzeczne z intuicją w porównaniu z innymi rodzajami analizy przepływu danych, które działają od danych wejściowych do wyjściowych.
Ograniczenia dotyczące zmiennych umożliwiają optymalizację i ułatwiają generowanie kodu. W dokumentacji i ograniczeniach implementacji są one też nazywane domeną, ponieważ określają wszystkie prawidłowe kombinacje lub wartości argumentów funkcji mapowania. W przypadku wielu operacji ograniczenia po prostu opisują wymiary tensorów, ale w przypadku niektórych operacji mogą być bardziej skomplikowane. Przykłady znajdziesz poniżej.
Dzięki symbolicznemu wyrażaniu funkcji i ograniczeń argumentów oraz możliwości łączenia funkcji i ograniczeń możemy obliczyć kompaktowe mapowanie indeksowania dla dowolnie dużych obliczeń (fuzji).
Wyrazistość funkcji symbolicznej i ograniczeń to kompromis między złożonością implementacji a korzyściami z optymalizacji, jakie uzyskujemy dzięki bardziej precyzyjnej reprezentacji. W przypadku niektórych operacji HLO wzorce dostępu są rejestrowane tylko w przybliżeniu.
Implementacja
Chcemy zminimalizować liczbę ponownych obliczeń, dlatego potrzebujemy biblioteki do obliczeń symbolicznych. XLA zależy już od MLIR, więc zamiast pisać kolejną bibliotekę arytmetyki symbolicznej używamy mlir::AffineMap.
Typowy AffineMap wygląda tak:
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap ma 2 rodzaje parametrów: wymiary i symbole.
Wymiary odpowiadają zmiennym wymiarów d, a symbole – zmiennym zakresu r i zmiennym czasu działania rt. Plik AffineMap nie zawiera żadnych metadanych dotyczących ograniczeń parametrów, więc musimy je podać osobno.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ kodować włączające ograniczenia zakresu dla zmiennych wymiarów d mapy indeksowania, które zwykle pokrywają się z kształtem tensora wyjściowego w przypadku operacji takich jak transpozycja, redukcja, operacje na elementach, iloczyn skalarny, ale istnieją pewne wyjątki, np. HloConcatenateInstruction.
range_vars_ wszystkie wartości, które przyjmują zmienne zakresu s. Zmienne zakresu są potrzebne, gdy do obliczenia pojedynczego elementu tensora, z którego mapujemy, wymaganych jest wiele wartości, np. w przypadku mapowania indeksowania wyjście->wejście w redukcjach lub mapowania wejście->wyjście w przypadku rozgłaszania.
rt_vars_ zakoduj możliwe wartości w czasie działania. Na przykład w przypadku jednowymiarowego HloDynamicSliceInstruction przesunięcie jest dynamiczne. Odpowiedni parametr RTVar będzie miał dopuszczalne wartości z przedziału od 0 do tensor_size - slice_size - 1.
constraints_ rejestrować relacje między wartościami w formie<expression> in <range>, np. d0 + s0 in [0, 20]. Wraz z parametrem
Variable.bounds określają „dziedzinę” funkcji indeksowania.
Przyjrzyjmy się przykładom, aby zrozumieć, co to wszystko oznacza.
Indeksowanie Map na potrzeby operacji bez fuzji
Elementwise
W przypadku operacji wykonywanych na poszczególnych elementach mapa indeksowania jest tożsamością.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
Mapowanie danych wyjściowych na wejściowe output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Mapa danych wejściowych na wyjściowe p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Broadcast
Rozgłaszanie oznacza, że niektóre wymiary zostaną usunięte podczas mapowania danych wyjściowych na wejściowe i dodane podczas mapowania danych wejściowych na wyjściowe.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
Mapowanie danych wyjściowych na wejściowe:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
Mapa danych wejściowych i wyjściowych:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Zwróć uwagę, że po prawej stronie mamy teraz zmienne zakresu s dla mapowania danych wejściowych na wyjściowe. Są to symbole reprezentujące zakresy wartości.
Na przykład w tym konkretnym przypadku każdy element danych wejściowych o indeksie d0 jest mapowany na wycinek danych wyjściowych o rozmiarach 10 x 1 x 30.
Iota
Operacja Iota nie ma operanda tensora wejściowego, więc nie ma argumentów indeksu wejściowego.
iota = f32[2,4] iota(), dimensions={1}
Mapowanie danych wyjściowych na dane wejściowe:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Mapowanie danych wejściowych na wyjściowe:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
Wartości przesunięcia w przypadku DynamicSlice są znane tylko w czasie działania programu.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
Mapowanie danych wyjściowych na dane wejściowe z ds na src:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Zwróć uwagę, że po prawej stronie mamy teraz rt, które służy do mapowania danych wejściowych na wyjściowe.
Są to symbole reprezentujące wartości w czasie działania. Na przykład w tym konkretnym przypadku dla każdego elementu danych wyjściowych o indeksach d0, d1, d2 uzyskujemy dostęp do przesunięć wycinków of1, of2 i of3, aby obliczyć indeks danych wejściowych.
Przedziały zmiennych czasu działania są wyprowadzane przy założeniu, że cały wycinek pozostaje w zakresie.
Mapowanie danych wyjściowych na dane wejściowe w przypadku of1, of2 i of3:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
Mapowanie danych wyjściowych na dane wejściowe w przypadku funkcji src jest proste. Można ją zwiększyć, ograniczając domenę do indeksów, które nie zostały zaktualizowane, ale obecnie mapy indeksowania nie obsługują ograniczeń nierówności.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
Mapowanie danych wyjściowych na wejściowe w przypadku upd:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Zwróć uwagę, że teraz mamy rt0 i rt1, które reprezentują wartości w czasie działania. W tym konkretnym przypadku dla każdego elementu danych wyjściowych o indeksach d0, d1 uzyskujemy dostęp do przesunięć wycinków of1 i of2, aby obliczyć indeks danych wejściowych. Przedziały zmiennych środowiska wykonawczego są wyznaczane przy założeniu, że cały wycinek pozostaje w zakresie.
Mapa danych wyjściowych na wejściowe dla of1 i of2:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Zbieraj
Obsługiwane jest tylko uproszczone zbieranie. Zobacz gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
Mapowanie danych wyjściowych na wejściowe w przypadku operand:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Zwróć uwagę, że teraz mamy symbole rt, które reprezentują wartości w czasie działania.
Mapowanie danych wyjściowych na wejściowe w przypadku indices:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
Zmienna zakresu s0 pokazuje, że do obliczenia elementu wyjściowego potrzebujemy całego wiersza (d0, *) tensora indices.
Transponuj
Mapa indeksowania dla transpozycji to permutacja wymiarów wejściowych/wyjściowych.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
Mapowanie danych wyjściowych na wejściowe:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
Mapa danych wejściowych i wyjściowych:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Odwróć
Mapa indeksowania dla zmian odwrotnych zmienia przywrócone wymiary na upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
Mapowanie danych wyjściowych na wejściowe:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
Mapa danych wejściowych i wyjściowych:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
Redukcja zmiennoparametrowa ma kilka danych wejściowych i kilka wartości początkowych, a mapowanie danych wyjściowych na dane wejściowe dodaje zredukowane wymiary.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
Mapowanie danych wyjściowych na dane wejściowe:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Mapowania danych wejściowych na wyjściowe:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Wycinek
Indeksowanie od danych wyjściowych do wejściowych w przypadku wycinka powoduje powstanie mapy indeksowania z krokiem, która jest prawidłowa dla każdego elementu danych wyjściowych. Mapowanie danych wejściowych na wyjściowe jest ograniczone do zakresu elementów wejściowych o określonym kroku.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
Mapowanie danych wyjściowych na wejściowe:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
Mapa danych wejściowych i wyjściowych:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Zmień kształt
Zmiany kształtu mogą mieć różne formy.
Zwiń kształt
Jest to przekształcenie „linearyzujące” z N-wymiarowego na 1-wymiarowe.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
Mapowanie danych wyjściowych na wejściowe:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Mapa danych wejściowych i wyjściowych:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Rozwiń kształt
Jest to odwrotna operacja „collapse shape”, która przekształca 1-wymiarowe dane wejściowe w N-wymiarowe dane wyjściowe.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
Mapowanie danych wyjściowych na wejściowe:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Mapa danych wejściowych i wyjściowych:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Ogólne przekształcenie
Są to operacje zmiany kształtu, których nie można przedstawić jako pojedynczego rozszerzenia lub zwężenia kształtu. Można je przedstawić tylko jako kompozycję co najmniej 2 kształtów rozwijanych lub zwijanych.
Przykład 1. Linearyzacja i delinearyzacja.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Zmiana kształtu może być przedstawiona jako złożenie zwężenia kształtu od tensor<4x8xf32> do tensor<32xf32>, a następnie rozszerzenia kształtu do tensor<2x4x4xf32>.
Mapowanie danych wyjściowych na wejściowe:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
Mapa danych wejściowych i wyjściowych:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Przykład 2. Rozwinięte i zwinięte podkształty
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Zmiana kształtu może być przedstawiona jako kompozycja dwóch zmian kształtu. Pierwsza z nich zwija zewnętrzne wymiary tensor<4x8x12xf32> do tensor<32x12xf32>, a druga rozwija wewnętrzny wymiar tensor<32x12xf32> do tensor<32x3x4xf32>.
Mapowanie danych wyjściowych na wejściowe:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
Mapa danych wejściowych i wyjściowych:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
Operację bitcast można przedstawić jako sekwencję transpozycji, zmiany kształtu i transpozycji. Dlatego mapy indeksowania są tylko kompozycją map indeksowania dla tej sekwencji.
Połącz
Mapowanie danych wyjściowych na wejściowe w przypadku funkcji concat jest zdefiniowane dla wszystkich danych wejściowych, ale z niepokrywającymi się domenami, tzn. w danym momencie używane będą tylko jedne dane wejściowe.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
Mapowanie danych wyjściowych na dane wejściowe:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
Dane wejściowe do map wyjściowych:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
Mapy indeksowania dla funkcji dot są bardzo podobne do map funkcji reduce.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
Mapowanie danych wyjściowych na dane wejściowe:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
Dane wejściowe do map wyjściowych:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
Indeksowanie PadOp jest odwrotnością indeksowania SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
Konfiguracja dopełnienia 1_4_1x4_8_0 oznacza lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
Mapowanie danych wyjściowych na dane wejściowe:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
Funkcja ReduceWindow w XLA również wykonuje dopełnianie. Dlatego mapy indeksowania można obliczyć jako kompozycję indeksowania ReduceWindow, które nie wykonuje żadnego dopełniania, i indeksowania PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
Mapowanie danych wyjściowych na dane wejściowe:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Indeksowanie map dla Fusion
Mapa indeksowania dla operacji fuzji to kompozycja map indeksowania dla każdej operacji w klastrze. Może się zdarzyć, że niektóre dane wejściowe są odczytywane kilka razy z różnymi wzorcami dostępu.
Jedno wejście, kilka map indeksowania
Oto przykład dla parametru p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Mapy indeksowania danych wyjściowych do danych wejściowych dla p0 to (d0, d1) -> (d0, d1) i (d0, d1) -> (d1, d0). Oznacza to, że aby obliczyć jeden element wyjściowy, możemy potrzebować dwukrotnego odczytania parametru wejściowego.
Jedno wejście, zduplikowana mapa indeksowania
![]()
Czasami mapy indeksowania są takie same, chociaż nie jest to od razu oczywiste.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
Mapa indeksowania danych wyjściowych do wejściowych dla p0 to w tym przypadku po prostu (d0, d1, d2) -> (d2, d0, d1).
Softmax
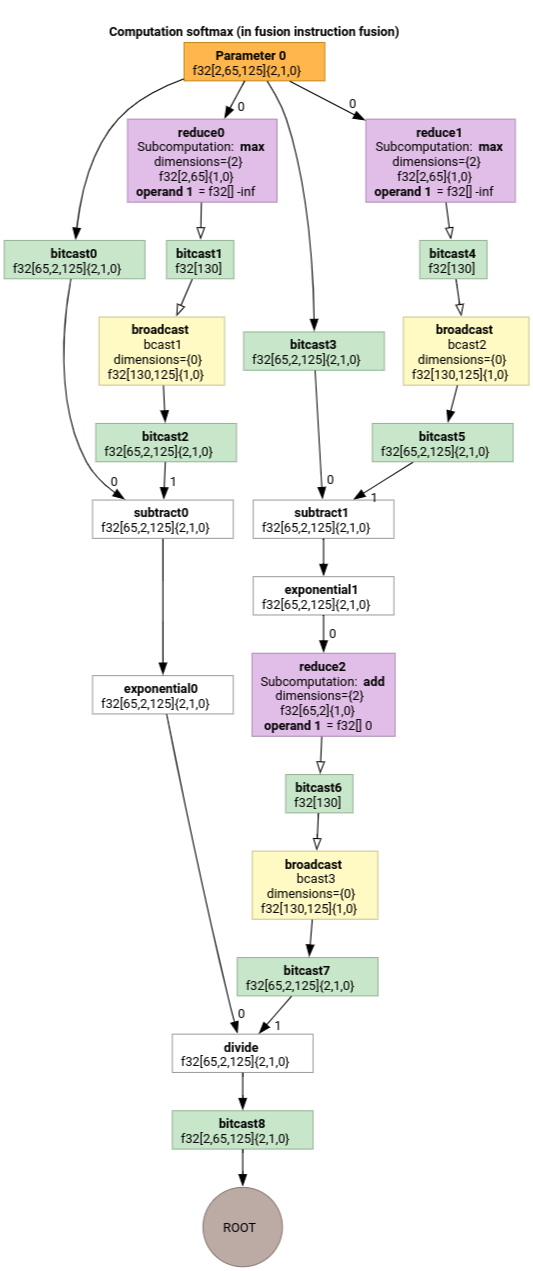
Mapowania indeksowania wyjścia na wejście dla parameter 0 w przypadku funkcji softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
i
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
gdzie s0 odnosi się do najbardziej wewnętrznego wymiaru danych wejściowych.
Więcej przykładów znajdziesz w pliku indexing_analysis_test.cc.
Uproszczenie indeksowania mapy
Domyślny upraszczacz dla mlir::AffineMap nie może przyjmować żadnych założeń dotyczących zakresów wymiarów ani symboli. Dlatego nie może skutecznie upraszczać wyrażeń z użyciem mod i div.
Możemy wykorzystać wiedzę o dolnych i górnych granicach podwyrażeń w mapach afinicznych, aby jeszcze bardziej je uprościć.
Upraszczarka może przekształcać te wyrażenia:
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)dla d w[0, 6] x [0, 14]zmienia się w(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)zadi in [0, 9]zmienia się w(d0, d1, d2) -> (d0, d1, d2).(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)zad_i in [0, 9]zmienia się w(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8).(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)za d w[0, 9] x [0, 10]zmienia się w(d0, d1) -> (d0).
Uproszczenie mapy indeksowania pozwala nam zrozumieć, że niektóre połączone przekształcenia w HLO znoszą się wzajemnie.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
Po utworzeniu map indeksowania i ich uproszczeniu otrzymamy
(d0, d1, d2) -> (d0, d1, d2).
Uproszczenie mapy indeksowania upraszcza też ograniczenia.
- Ograniczenia typu
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundsą przekształcane wupdated_lower_bound <= affine_expr <= updated_upped_bound. - Ograniczenia, które są zawsze spełnione, np.
d0 + s0 in [0, 20]dlad0 in [0, 5]is0 in [1, 3], są eliminowane. - Wyrażenia afiniczne w ograniczeniach są optymalizowane jako mapa afiniczna indeksowania powyżej.
Więcej przykładów znajdziesz w pliku indexing_map_test.cc.