
Анализ индексации HLO — это анализ потока данных , описывающий, как элементы одного тензора соотносятся с другими посредством «карт индексации». Например, как индексы выходных данных инструкции HLO отображаются на индексы операндов инструкции HLO.
Пример
Для трансляции из tensor<20xf32> в tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
Карта индексации от выхода к входу имеет вид (i, j, k) -> (j) для i in [0, 10] , j in [0, 20] и k in [0, 30] .
Мотивация
XLA использует несколько специализированных решений для анализа объединения данных, использования операндов и схем разбиения на блоки (подробнее см. ниже). Цель анализа индексирования — предоставление многократно используемого компонента для подобных задач. Анализ индексирования построен на основе собственной инфраструктуры XLA SymbolicExpr и SymbolicMap и добавляет семантику HLO.
Слияние
Рассуждения об объединении памяти становятся возможными для нетривиальных случаев, когда нам известно, какие элементы/срезы входных данных считываются для вычисления элемента выходных данных.
Использование операндов
В XLA показатель использования операндов показывает, насколько используется каждый вход инструкции при условии полного использования её выходного значения. В настоящее время показатель использования также не вычисляется для обобщенного случая. Анализ индексации позволяет точно вычислить показатель использования.
Укладка плитки
Плитка/срез — это гиперпрямоугольное подмножество тензора, параметризованное смещениями, размерами и шагами. Распространение плиток — это способ вычисления параметров плиток производителя/потребителя операции с использованием параметров разбиения на плитки самой операции. Уже существует библиотека , которая делает это для softmax и dot. Распространение плиток можно сделать более универсальным и надежным, если выразить его с помощью карт индексации.
Карта индексации
Карта индексации представляет собой комбинацию
- символически выраженная функция, которая отображает каждый элемент одного тензора
Aв диапазоны элементов тензораB; - ограничения на допустимые аргументы функции, включая область определения функции.
Аргументы функций разделены на 3 категории для более наглядного представления их природы:
Переменные размерности тензора
Aили сетки GPU, с которой мы выполняем отображение; значения известны статически. Элементы индекса также называются переменными размерности .Переменные диапазона . Они определяют отображение «один ко многим» и задают набор элементов в
B, используемых для вычисления единственного значенияA; значения известны статически. Примером переменной диапазона является сжимающая размерность умножения матриц.Переменные времени выполнения , которые становятся известны только во время выполнения. Например, аргумент indices операции gather .
Результатом работы функции является индекс целевого тензора B
Вкратце, функция индексации тензора A в тензор B для операции x — это
map_ab(index in A, range variables, runtime variables) -> index in B .
Для лучшего разделения типов аргументов сопоставления мы записываем их следующим образом:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Например, давайте посмотрим на карты индексации для операции reduce: f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3} :
Для
outэлементовin[0, 1] на [0, 3] нашу функцию можно выразить как(d0, d1, d2, d3) -> (d1, d2). Ограничения переменных d0 в [0, 1], d1 в [0, 3], d2 в [0, 7], d3 в [0, 15] определяются формойind0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15].Для отображения элементов
outвin:outимеет только два измерения, а редукция вводит две переменные диапазона, которые охватывают редуцирующие измерения. Таким образом, функция отображения имеет вид(d0, d1)[s0, s1] -> (s0, d0, d1, s1), где(d0, d1)— индексout.s0,s1— диапазоны, определенные семантикой операции, и охватывают измерения 0 и 3 тензораin. Ограничения:d0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
Важно отметить, что в большинстве случаев нас интересует отображение элементов выходных данных . Для вычислений...
C = op1(A, B)
E = op2(C, D)
Мы можем говорить об «индексировании B», то есть об «отображении элементов E в элементы B ». Это может показаться нелогичным по сравнению с другими типами анализа потока данных, которые работают от входа к выходу.
Ограничения на переменные предоставляют возможности для оптимизации и помогают в генерации кода. В документации и реализации ограничения также называются областью определения , поскольку они определяют все допустимые комбинации значений аргументов функции отображения. Для многих операций ограничения просто описывают размерность тензоров, но для некоторых операций они могут быть более сложными; см. примеры ниже.
Благодаря символическому представлению функций и ограничений аргументов, а также возможности комбинировать функции и ограничения, мы можем вычислить компактное отображение индексации для произвольно больших вычислений (слияния).
Выразительность символических функций и ограничений представляет собой баланс между сложностью реализации и преимуществами оптимизации, которые мы получаем благодаря более точному представлению. Для некоторых операций HLO мы описываем шаблоны доступа лишь приблизительно.
Выполнение
Для минимизации перерасчетов нам необходима структура для символических вычислений. Она реализована в виде SymbolicExpr и SymbolicMap .
Типичная SymbolicMap выглядит следующим образом:
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
SymbolicMap имеет два типа параметров: измерения и символы . Измерения соответствуют переменным измерения d ; символы соответствуют переменным диапазона r и переменным времени выполнения rt . SymbolicMap не содержит никаких метаданных об ограничениях параметров, поэтому их необходимо указывать отдельно.
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
// struct Interval represents a closed interval [lower_bound, upper_bound].
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
SymbolicMap symbolic_map_;
// A dimension variable represents a dimension of a tensor or a GPU grid.
// Dimension variables correspond to the dimensions of the `symbolic_map_`.
std::vector<Variable> dim_vars_;
// A range variable represents a range of values, e.g. to compute a single
// element of the reduction's result we need a range of values from the input
// tensor. Range variables correspond to the front portion of the
// symbols in `symbolic_map_`.
std::vector<Variable> range_vars_;
// A runtime variable represents a runtime symbol, e.g. a dynamic offset in of
// a HLO dynamic-update-slice op. Runtime variables correspond to the back
// portion of the symbols in `symbolic_map_`.
std::vector<Variable> rt_vars_;
// Inequality constraints for symbolic expressions. They restrict the feasible
// set for the domain of the indexing map. It contains symbolic expressions
// other than SymbolicDimExpr and SymbolicSymbolExpr.
llvm::MapVector<SymbolicExpr, Interval> constraints_;
};
Ссылка на код: indexing_map.h#L114
dim_vars_ кодирует ограничения, включающие в себя ограничивающие рамки для переменных размерности d карты индексации, которые обычно совпадают с формой выходного тензора для таких операций, как транспонирование, редукция, поэлементное преобразование, точечное представление, но есть некоторые исключения, например, HloConcatenateInstruction .
range_vars_ все значения, которые принимают переменные диапазона. Переменные диапазона необходимы, когда для вычисления одного элемента тензора, из которого мы выполняем отображение, требуется несколько значений, например, для отображения индексации выход->вход при редукции или для отображения вход->выход при широковещательной рассылке.
rt_vars_ кодирует допустимые значения во время выполнения. Например, смещение является динамическим для одномерной инструкции HloDynamicSliceInstruction . Соответствующая RTVar будет иметь допустимые значения от 0 до tensor_size - slice_size - 1 .
constraints_ фиксируют связи между значениями в форме <expression> in <range> , например d0 + s0 in [0, 20] . Вместе с Variable.bounds они определяют "область определения" функции индексации.
Давайте рассмотрим каждый пример, чтобы понять, что всё вышесказанное на самом деле означает.
Индексирование карт для операций Unfused
Элементарно
Для поэлементных операций карта индексации представляет собой тождество.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
Выходная карта для ввода output -> p0 :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Карта ввода-вывода p0 -> output :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Транслировать
Широковещательная передача означает, что некоторые измерения будут удалены при преобразовании выходных данных во входные и добавлены при преобразовании входных данных в выходные.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
Карта «выход-вход»:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
Карта «вход-выход»:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Обратите внимание, что теперь справа у нас есть переменные диапазона s для отображения входных данных на выходные. Это символы, представляющие диапазоны значений. Например, в этом конкретном случае каждый элемент входных данных с индексом d0 отображается на фрагмент выходных данных размером 10x1x30.
Йота
В Iota нет операнда входного тензора, поэтому нет аргументов входного индекса.
iota = f32[2,4] iota(), dimensions={1}
Карта вывода на вход:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Карта ввода-вывода:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
Динамический срез
В DynamicSlice смещения известны только во время выполнения.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
Карта преобразования выходных данных в входные данные из ds в src :
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Обратите внимание, что теперь справа от нас находится rt, обозначающее отображение входных данных на выходные. Это символы, представляющие значения, определяемые во время выполнения. Например, в данном конкретном случае для каждого элемента выходных данных с индексами d0, d1, d2 мы обращаемся к смещениям среза of1 , of2 и of3 , чтобы вычислить индекс входных данных. Интервалы для переменных времени выполнения определяются исходя из предположения, что весь срез остается в пределах заданных границ.
Карта преобразования выходных данных во входные для of1 , of2 и of3 :
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
Сопоставление выходных и входных данных для src тривиально. Его можно сделать более точным, ограничив область определения необновляемыми индексами, но в настоящее время карты индексации не поддерживают ограничения в виде неравенств.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
Карта ввода-вывода для upd :
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Обратите внимание, что теперь у нас есть rt0 и rt1 , представляющие значения, полученные во время выполнения. В данном конкретном случае для каждого элемента выходных данных с индексами d0, d1 мы обращаемся к смещениям среза of1 и of2 чтобы вычислить индекс входных данных. Интервалы для переменных времени выполнения определяются исходя из предположения, что весь срез остается в пределах заданных границ.
Карта преобразования выходных данных в входные для of1 и of2 :
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Собирать
Поддерживается только упрощенный алгоритм сбора данных. См. gather_simplifier.h .
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
Карта преобразования выходных данных в входные для operand :
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Обратите внимание, что теперь у нас есть символы rt , которые представляют значения, полученные во время выполнения.
Карта преобразования выходных данных в входные для indices :
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
Переменная диапазона s0 показывает, что для вычисления элемента выходных данных нам необходима вся строка (d0, *) тензора indices .
Транспонировать
Карта индексации для транспонирования представляет собой перестановку входных/выходных измерений.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
Карта «выход-вход»:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
Карта «вход-выход»:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Обеспечить регресс
При изменении карты индексации для обратного преобразования размерности возвращаемого значения устанавливается значение upper_bound(d_i) - d_i :
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
Карта «выход-вход»:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
Карта «вход-выход»:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Вариативный)Сокращение
Метод вариационного редукции предполагает наличие нескольких входных параметров и нескольких начальных значений; отображение от выхода к входу суммирует уменьшенные размерности.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
Карты преобразования выходных данных во входные:
-
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Карты ввода-вывода:
-
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Ломтик
Индексирование от выхода к входу для среза приводит к созданию карты индексации с шагом, которая действительна для каждого элемента выходных данных. Отображение от входа к выходу ограничено диапазоном элементов входных данных с шагом.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
Карта «выход-вход»:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
Карта «вход-выход»:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Изменить форму
Изменённые формы бывают разных видов.
Свернуть форму
Это «линеаризующее» преобразование из ND в 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
Карта «выход-вход»:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Карта «вход-выход»:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Развернуть форму
Это обратная операция "свертывания формы", она преобразует одномерный входной сигнал в нейтрально-серый выходной сигнал.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
Карта «выход-вход»:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Карта «вход-выход»:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Типичная переформовка
Это операции изменения формы, которые нельзя представить в виде одной фигуры расширения или свертывания. Их можно представить только в виде композиции из двух или более фигур расширения или свертывания.
Пример 1: Линеаризация-делинеаризация.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Это изменение формы можно представить как композицию преобразования формы tensor<4x8xf32> в tensor<32xf32> , а затем расширения формы до tensor<2x4x4xf32> .
Карта «выход-вход»:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
Карта «вход-выход»:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Пример 2: Расширенные и свернутые подфигуры
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Это преобразование можно представить как композицию двух преобразований. Первое сворачивает tensor<4x8x12xf32> в tensor<32x12xf32> , а второе расширяет tensor<32x12xf32> в tensor<32x3x4xf32> .
Карта «выход-вход»:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
Карта «вход-выход»:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Биткаст
Операция преобразования битов может быть представлена как последовательность транспонирования-изменения формы-транспонирования . Следовательно, ее карты индексации представляют собой просто композицию карт индексации для этой последовательности.
Последовательно соединять
В алгоритме конкатенации отображение выходных и входных данных определено для всех входных данных, но с непересекающимися областями, то есть одновременно будет использоваться только один из входных параметров.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
Сопоставление выходных и входных данных:
-
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
Карты, отображающие входные данные на выходные:
-
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Точка
Карты индексации для dot очень похожи на карты индексации для reduce.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
Сопоставление выходных и входных данных:
- вывод -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- вывод -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
Карты, отображающие входные данные на выходные:
- p0 -> вывод:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> вывод:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Пад
Индексирование PadOp является обратным индексированию SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
Конфигурация отступов 1_4_1x4_8_0 обозначает lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1 .
Карты преобразования выходных данных во входные:
- вывод -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- вывод -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
Функция ReduceWindow в XLA также выполняет заполнение (padding). Поэтому карты индексации можно вычислить как композицию индексации ReduceWindow, которая не выполняет заполнения, и индексации PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
Карты преобразования выходных данных во входные:
-
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Индексирование карт для Fusion
Карта индексации для операции слияния представляет собой композицию карт индексации для каждой операции в кластере. Может случиться так, что некоторые входные данные считываются несколько раз с использованием различных шаблонов доступа.
Один вход, несколько карт индексации
Вот пример для p0 + transpose(p0) .
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Индексация выходных данных для p0 будет следующей: (d0, d1) -> (d0, d1) и (d0, d1) -> (d1, d0) . Это означает, что для вычисления одного элемента выходных данных нам может потребоваться дважды считать входной параметр.
Карта индексации с одним входным параметром и без дубликатов

Бывают случаи, когда карты индексации на самом деле совпадают, хотя это и не сразу очевидно.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
В данном случае отображение индексации выходных данных на входные для p0 выглядит следующим образом: (d0, d1, d2) -> (d2, d0, d1) .
Софтмакс
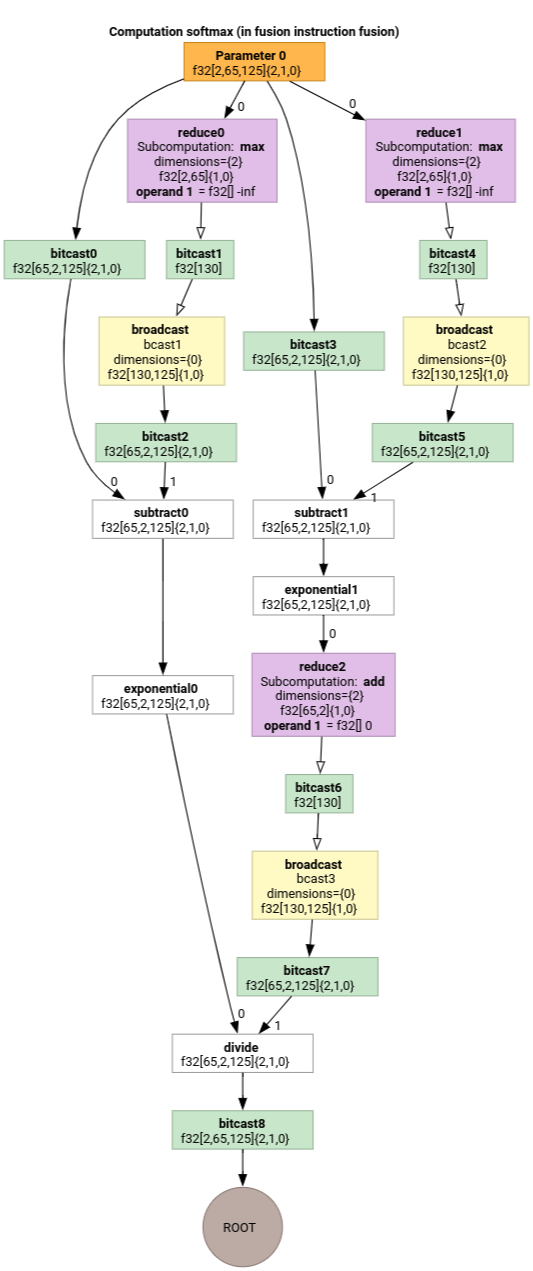
Сопоставление индексации выходных и входных данных для parameter 0 функции softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
и
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
где s0 обозначает самую внутреннюю размерность входных данных.
Дополнительные примеры см. на сайте indexing_analysis_test.cc .
Упрощение индексации карт
Мы можем использовать знания о нижних и верхних границах подвыражений в символических картах, чтобы еще больше упростить их.
Упрощение индексации карты позволяет переписать следующие выражения.
-
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)for d in[0, 6] x [0, 14]становится(d0, d1) -> (d0, d1) -
(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)fordi in [0, 9]становится(d0, d1, d2) -> (d0, d1, d2). -
(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)дляd_i in [0, 9]становится(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8). -
(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)for d in[0, 9] x [0, 10]becomes(d0, d1) -> (d0).
Это позволяет нам понять, что некоторые из связанных между собой преобразований в HLO взаимно компенсируют друг друга. Например:
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
После составления индексных карт и их упрощения мы получим следующую карту:
(d0, d1, d2) -> (d0, d1, d2) .
Упрощение карты индексации также упрощает ограничения.
- Ограничения типа
lower_bound <= symbolic_expr (floordiv, ceildiv, +, -, *, mod, min, max) constant <= upper_boundпереписываются какupdated_lower_bound <= symbolic_expr <= updated_upped_bound. - Исключаются ограничения, которые всегда выполняются, например,
d0 + s0 in [0, 20]дляd0 in [0, 5]иs0 in [1, 3]. - Символические выражения в ограничениях оптимизируются в соответствии с приведенной выше символической картой индексации.
Дополнительные примеры см. в файле indexing_map_test.cc .