
L'analisi dell'indicizzazione HLO è un'analisi del flusso di dati che descrive la relazione tra gli elementi di un tensore e un altro tramite le "mappe di indicizzazione". Ad esempio, come vengono mappati gli indici di un output di istruzione HLO agli indici degli operandi dell'istruzione HLO.
Esempio
Per una trasmissione dal giorno tensor<20xf32> al giorno tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
La mappatura dell'indicizzazione dall'output all'input è (i, j, k) -> (j) per i in
[0, 10], j in [0, 20] e k in [0, 30].
Motivazione
XLA utilizza diverse soluzioni personalizzate per ragionare su coalescenza, utilizzo degli operandi e schemi di tiling (maggiori dettagli di seguito). L'obiettivo dell'analisi dell'indicizzazione è fornire un componente riutilizzabile per questi casi d'uso. L'analisi dell'indicizzazione si basa sull'infrastruttura di Affine Map di MLIR e aggiunge la semantica HLO.
Raggruppamento
Il ragionamento sulla coalescenza della memoria diventa fattibile per i casi non banali, quando sappiamo quali elementi/sezioni degli input vengono letti per calcolare un elemento dell'output.
Utilizzo dell'operando
L'utilizzo degli operandi in XLA indica la quantità di ciascun input dell'istruzione utilizzata supponendo che l'output venga utilizzato completamente. Al momento, l'utilizzo non viene calcolato nemmeno per un caso generico. L'analisi dell'indicizzazione ci consente di calcolare l'utilizzo con precisione.
Riquadri:
Un riquadro/slice è un sottoinsieme iperrettangolare di un tensore parametrizzato da offset, dimensioni e passi. La propagazione dei riquadri è un modo per calcolare i parametri dei riquadri del produttore/consumatore dell'operazione utilizzando i parametri di tiling dell'operazione stessa. Esiste già una libreria che lo fa per softmax e dot. La propagazione dei riquadri può essere resa più generica e robusta se espressa tramite mappe di indicizzazione.
Mappa di indicizzazione
Una mappa di indicizzazione è una combinazione di
- una funzione espressa simbolicamente che mappa ogni elemento di un tensore
Aa intervalli di elementi nel tensoreB; - vincoli sugli argomenti di funzione validi, incluso il dominio della funzione.
Gli argomenti delle funzioni sono suddivisi in tre categorie per comunicare meglio la loro natura:
Variabili di dimensione del tensore
Ao di una griglia GPU da cui eseguiamo la mappatura; i valori sono noti staticamente. Gli elementi dell'indice sono chiamati anche variabili delle dimensioni.Variabili intervallo. Definiscono una mappatura uno-a-molti e specificano un insieme di elementi in
Butilizzati per calcolare un singolo valore diA; i valori sono noti staticamente. La dimensione di contrazione di una moltiplicazione di matrici è un esempio di variabile di intervallo.Variabili di runtime note solo durante l'esecuzione. Ad esempio, l'argomento indices dell'operazione gather.
Il risultato della funzione è un indice del tensore target B.
In breve, una funzione di indicizzazione dal tensore A al tensore B per l'operazione x
è
map_ab(index in A, range variables, runtime variables) -> index in B.
Per separare meglio i tipi di argomenti di mappatura, li scriviamo come segue:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Ad esempio, esaminiamo le mappe di indicizzazione per l'operazione di riduzione
f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
per mappare gli elementi di
inaout, la nostra funzione può essere espressa come(d0, d1, d2, d3) -> (d1, d2). I vincoli delle variabilid0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]sono definiti dalla forma diin.Per mappare gli elementi di
outain:outha solo due dimensioni e la riduzione introduce due variabili di intervallo che coprono la riduzione delle dimensioni. Pertanto, la funzione di mappatura è(d0, d1)[s0, s1] -> (s0, d0, d1, s1), dove(d0, d1)è l'indice diout.s0,s1sono intervalli definiti dalla semantica dell'operazione e coprono le dimensioni 0 e 3 del tensorein. I vincoli sonod0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
È importante notare che nella maggior parte degli scenari ci interessa la mappatura degli elementi dell'output. Per il calcolo
C = op1(A, B)
E = op2(C, D)
Possiamo parlare di "indicizzazione di B" intendendo la "mappatura degli elementi di E negli elementi di B". Questo potrebbe essere controintuitivo rispetto ad altri tipi di analisi del flusso di dati che funzionano dall'input verso gli output.
I vincoli sulle variabili consentono opportunità di ottimizzazione e aiutano con la generazione di codice. Nella documentazione e nei vincoli di implementazione vengono anche definiti dominio in quanto definiscono tutte le combinazioni o i valori degli argomenti validi della funzione di mappatura. Per molte operazioni, i vincoli descrivono semplicemente le dimensioni dei tensori, ma per alcune operazioni potrebbero essere più complessi. Vedi gli esempi di seguito.
Se le funzioni e i vincoli degli argomenti vengono espressi simbolicamente e se è possibile combinare funzioni e vincoli, possiamo calcolare una mappatura di indicizzazione compatta per un calcolo arbitrariamente grande (fusione).
L'espressività della funzione simbolica e dei vincoli è un equilibrio tra la complessità dell'implementazione e i vantaggi dell'ottimizzazione che otteniamo da una rappresentazione più precisa. Per alcune operazioni HLO, acquisiscono i pattern di accesso solo in modo approssimativo.
Implementazione
Poiché vogliamo ridurre al minimo i ricalcoli, abbiamo bisogno di una libreria per i calcoli simbolici. XLA dipende già da MLIR, quindi utilizziamo mlir::AffineMap invece di scrivere un'altra libreria di aritmetica simbolica.
Un tipico AffineMap ha questo aspetto:
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap ha due tipi di parametri: dimensioni e simboli.
Le dimensioni corrispondono alle variabili di dimensione d; i simboli corrispondono alle variabili di intervallo r e alle variabili di runtime rt. AffineMap non contiene metadati sui vincoli dei parametri, quindi dobbiamo fornirli separatamente.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ codifica i vincoli della casella inclusiva per le variabili
delle dimensioni d della mappa di indicizzazione, che di solito coincidono con
la forma del tensore di output per operazioni come trasposizione, riduzione, elementwise, dot, ma
ci sono alcune eccezioni come
HloConcatenateInstruction.
range_vars_ tutti i valori assunti dalle variabili di intervallo s. Le variabili di intervallo
sono necessarie quando sono necessari più valori per calcolare un singolo elemento del
tensore da cui eseguiamo la mappatura, ad esempio per la mappatura dell'indicizzazione output->input delle riduzioni o
la mappatura input->output per le trasmissioni.
rt_vars_ codifica i valori fattibili in fase di runtime. Ad esempio, l'offset è
dinamico per un HloDynamicSliceInstruction 1D. Il valore RTVar corrispondente
avrà valori possibili compresi tra 0 e tensor_size - slice_size - 1.
constraints_ acquisisci le relazioni tra i valori nel formato
<expression> in <range>, ad es. d0 + s0 in [0, 20]. Insieme a
Variable.bounds definiscono il "dominio" della funzione di indicizzazione.
Vediamo un esempio per capire cosa significa tutto questo.
Indicizzazione di Maps per le operazioni non unite
Elementwise
Per le operazioni elementwise, la mappa di indicizzazione è un'identità.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
La mappatura da output a input output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
La mappatura input-output p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Annuncio
La trasmissione significa che alcune dimensioni verranno rimosse quando mappiamo l'output all'input e aggiunte quando mappiamo l'input all'output.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
La mappatura input-output:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
La mappatura input-output:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Tieni presente che ora abbiamo le variabili di intervallo s sul lato destro per la mappatura input-output. Questi sono i simboli che rappresentano gli intervalli di valori.
Ad esempio, in questo caso specifico ogni elemento dell'input con indice d0 viene mappato a una sezione 10x1x30 dell'output.
Iota
Iota non ha un operando tensore di input, quindi non ci sono argomenti di indice di input.
iota = f32[2,4] iota(), dimensions={1}
Output to input map (mappa da output a input):
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Mappa input-output:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice ha offset noti solo in fase di runtime.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
La mappatura da output a input da ds a src:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Tieni presente che ora abbiamo rt sul lato destro per il mapping input-output.
Questi sono i simboli che rappresentano i valori di runtime. Ad esempio, in questo caso specifico per ogni elemento dell'output con indici d0, d1, d2 accediamo agli offset delle sezioni of1, of2 e of3 per calcolare l'indice dell'input.
Gli intervalli per le variabili di runtime vengono derivati presupponendo che l'intera
fetta rimanga nei limiti.
La mappatura input-output per of1, of2 e of3:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
La mappatura dell'output all'input per src è banale. Può essere resa più precisa
limitando il dominio agli indici non aggiornati, ma al momento le mappe di indicizzazione
non supportano i vincoli di disuguaglianza.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
La mappatura input-output per upd:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Tieni presente che ora abbiamo rt0 e rt1 che rappresentano i valori di runtime. In
questo caso specifico, per ogni elemento dell'output con indici d0, d1, accediamo agli offset delle sezioni of1 e of2 per calcolare l'indice dell'input. Gli intervalli per le variabili di runtime vengono derivati presupponendo che l'intera
fetta rimanga nei limiti.
La mappatura da output a input per of1 e of2:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Raccogli
È supportata solo la raccolta semplificata. Vedi gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
La mappatura input-output per operand:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Tieni presente che ora abbiamo simboli rt che rappresentano i valori di runtime.
La mappatura input-output per indices:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
La variabile di intervallo s0 mostra che abbiamo bisogno dell'intera riga (d0, *) del tensore indices per calcolare un elemento dell'output.
Trasponi
La mappa di indicizzazione per la trasposizione è una permutazione delle dimensioni di input/output.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
La mappatura input-output:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
La mappatura input-output:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Inverti
La mappa di indicizzazione per l'inversione delle modifiche riporta le dimensioni revertite a upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
La mappatura input-output:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
La mappatura input-output:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
La riduzione variadica ha diversi input e diversi valori iniziali, la mappatura da output a input aggiunge le dimensioni ridotte.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
Le mappe di output e input:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Le mappature da input a output:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Sezione
L'indicizzazione dall'output all'input per la sezione genera una mappa di indicizzazione con passo che è valida per ogni elemento dell'output. Il mapping dall'input all'output è limitato a un intervallo con passo degli elementi nell'input.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
La mappatura input-output:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
La mappatura input-output:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Rimodella
I rimodellamenti sono disponibili in diversi tipi.
Comprimi forma
Si tratta di un'operazione di rimodellamento "linearizzante" da N-D a 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
La mappatura input-output:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
La mappatura input-output:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Espandi forma
Si tratta di un'operazione inversa di "comprimi forma", che rimodella un input 1D in un output N-D.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
La mappatura input-output:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
La mappatura input-output:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Rimodellamento generico
Queste sono le operazioni di rimodellamento che non possono essere rappresentate come una singola forma di espansione o compressione. Possono essere rappresentati solo come una composizione di due o più forme espandibili o comprimibili.
Esempio 1: linearizzazione-delinearizzazione.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Questa rimodellamento può essere rappresentato come una composizione della forma di compressione da
tensor<4x8xf32> a tensor<32xf32> e poi un'espansione della forma a
tensor<2x4x4xf32>.
La mappatura input-output:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
La mappatura input-output:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Esempio 2: forme secondarie espanse e compresse
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Questo rimodellamento può essere rappresentato come una composizione di due rimodellamenti. Il primo comprime le dimensioni più esterne tensor<4x8x12xf32> in tensor<32x12xf32> e il secondo espande la dimensione più interna tensor<32x12xf32> in tensor<32x3x4xf32>.
La mappatura input-output:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
La mappatura input-output:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
Un'operazione bitcast può essere rappresentata come una sequenza di trasposizione-rimodellamento-trasposizione. Pertanto, le sue mappe di indicizzazione sono solo una composizione delle mappe di indicizzazione per questa sequenza.
Concatenate
Il mapping da output a input per concat è definito per tutti gli input, ma con domini non sovrapposti, ovvero verrà utilizzato un solo input alla volta.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
La mappatura dell'output agli input:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
Le mappature degli input e degli output:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Punto
Le mappe di indicizzazione per il punto sono molto simili a quelle di riduzione.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
La mappatura dell'output agli input:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
Le mappature degli input e degli output:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
L'indicizzazione di PadOp è l'opposto dell'indicizzazione di SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
La configurazione del padding 1_4_1x4_8_0 indica lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
Le mappe di output e input:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
ReduceWindow in XLA esegue anche il padding. Pertanto, le mappe di indicizzazione possono essere calcolate come composizione dell'indicizzazione ReduceWindow che non esegue alcun padding e dell'indicizzazione di PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
Le mappe di output e input:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Indicizzazione delle mappe per Fusion
La mappa di indicizzazione per l'operazione di fusione è una composizione delle mappe di indicizzazione per ogni operazione nel cluster. Può capitare che alcuni input vengano letti più volte con pattern di accesso diversi.
Un input, diverse mappe di indicizzazione
Ecco un esempio per p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Le mappe di indicizzazione da output a input per p0 saranno (d0, d1) -> (d0, d1) e
(d0, d1) -> (d1, d0). Ciò significa che per calcolare un elemento
dell'output potrebbe essere necessario leggere il parametro di input due volte.
Una mappa di indicizzazione deduplicata per input
![]()
Esistono casi in cui le mappe di indicizzazione sono effettivamente le stesse, anche se non è immediatamente ovvio.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
In questo caso, la mappa di indicizzazione da output a input per p0 è semplicemente
(d0, d1, d2) -> (d2, d0, d1).
Softmax
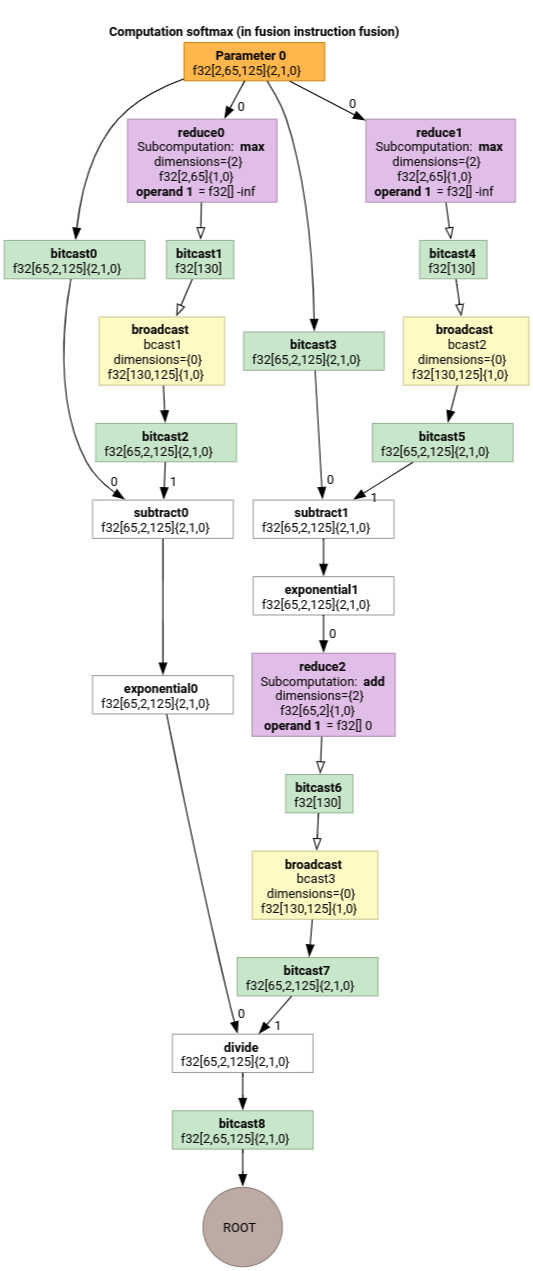
Le mappature dell'indicizzazione da output a input per parameter 0 per softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
e
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
dove s0 si riferisce alla dimensione più interna dell'input.
Per altri esempi, consulta indexing_analysis_test.cc.
Indicizzazione di Map Simplifier
Il semplificatore predefinito per mlir::AffineMap upstream non può fare
ipotesi sugli intervalli di dimensioni/simboli. Pertanto, non può
semplificare le espressioni con mod e div in modo efficiente.
Possiamo sfruttare le informazioni sui limiti inferiore e superiore delle sottoespressioni nelle mappe affini per semplificarle ulteriormente.
Il semplificatore può riscrivere le seguenti espressioni.
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)per d in[0, 6] x [0, 14]diventa(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)perdi in [0, 9]diventa(d0, d1, d2) -> (d0, d1, d2).(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)perd_i in [0, 9]diventa(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8).(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)per d in[0, 9] x [0, 10]diventa(d0, d1) -> (d0).
Lo strumento di semplificazione della mappa di indicizzazione ci consente di capire che alcune delle rimodellature concatenate in HLO si annullano a vicenda.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
Dopo la composizione delle mappe di indicizzazione e la loro semplificazione, otterremo
(d0, d1, d2) -> (d0, d1, d2).
La semplificazione della mappa di indicizzazione semplifica anche i vincoli.
- I vincoli di tipo
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundvengono riscritti comeupdated_lower_bound <= affine_expr <= updated_upped_bound. - I vincoli sempre soddisfatti, ad esempio
d0 + s0 in [0, 20]perd0 in [0, 5]es0 in [1, 3], vengono eliminati. - Le espressioni affini nei vincoli vengono ottimizzate come la mappa affine di indicizzazione sopra.
Per altri esempi, consulta indexing_map_test.cc.