
تحليل الفهرسة على مستوى العمليات العليا هو تحليل لتدفّق البيانات يوضّح كيفية ارتباط عناصر موتر بآخر من خلال "خرائط الفهرسة". على سبيل المثال، كيف يتم ربط فهارس ناتج تعليمات HLO بفهارس معاملات تعليمات HLO؟
مثال
لإرسال إعلان من tensor<20xf32> إلى tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
خريطة الفهرسة من الناتج إلى المدخل هي (i, j, k) -> (j) لكل من i in
[0, 10] وj in [0, 20] وk in [0, 30].
الحافز
تستخدم XLA العديد من الحلول المخصّصة للتعليل بشأن الدمج واستخدام المعامِلات وأنظمة التقسيم (مزيد من التفاصيل أدناه). والهدف من تحليل الفهرسة هو توفير مكوّن قابل لإعادة الاستخدام لحالات الاستخدام هذه. تستند عملية تحليل الفهرسة إلى بنية Affine Map الأساسية في MLIR وتضيف دلالات HLO.
الاندماج
يصبح التفكير في دمج الذاكرة ممكنًا في الحالات غير البسيطة، عندما نعرف العناصر أو الشرائح من المدخلات التي تتم قراءتها لاحتساب عنصر من المخرجات.
استخدام المعامل
يشير استخدام المعامِلات في XLA إلى مقدار استخدام كل إدخال من التعليمات بافتراض استخدام الناتج بالكامل. في الوقت الحالي، لا يتم احتساب معدّل الاستخدام أيضًا لحالة عامة. تتيح لنا عملية تحليل الفهرسة احتساب معدل الاستخدام بدقة.
التجزئة إلى أقسام عمودية:
البلاطة/الشريحة هي مجموعة فرعية فائقة المستطيل من موتر يتم تحديد مَعلماتها من خلال الإزاحات والأحجام والخطوات. انتشار المربّعات هو طريقة لاحتساب مَعلمات المربّعات الخاصة بمنتج/مستهلك العملية باستخدام مَعلمات التقطيع الخاصة بالعملية نفسها. تتوفّر مكتبة تنفّذ هذه العملية لكلّ من دالة softmax والضرب النقطي. يمكن أن يكون نشر المربّعات أكثر عمومية وقوة إذا تم التعبير عنه من خلال خرائط الفهرسة.
خريطة الفهرسة
خريطة الفهرسة هي مزيج من
- دالة معبَّر عنها بشكل رمزي تربط كل عنصر من عناصر الموتر
Aبنطاقات من العناصر في الموترB - قيود على وسيطات الدالة الصالحة، بما في ذلك نطاق الدالة
يتم تقسيم وسيطات الدوال إلى 3 فئات لتوضيح طبيعتها بشكل أفضل:
متغيّرات السمة للموتر
Aأو شبكة وحدة معالجة الرسومات التي يتم الربط منها، وتكون القيم معروفة بشكل ثابت. تُعرف عناصر الفهرس أيضًا باسم متغيرات السمة.متغيّرات النطاق تحدّد هذه السمة عملية ربط من عنصر واحد إلى عدة عناصر، وتحدّد مجموعة من العناصر في
Bتُستخدَم لاحتساب قيمة واحدة منA، وتكون القيم معروفة بشكل ثابت. إنّ البُعد المنكمش لعملية ضرب المصفوفات هو مثال على متغير النطاق.المتغيرات في وقت التشغيل التي لا تكون معروفة إلا أثناء التنفيذ على سبيل المثال، وسيطة الفهرس في عملية التجميع.
نتيجة الدالة هي فهرس موتر الهدف B.
باختصار، دالة الفهرسة من الموتر A إلى الموتر B للعملية x هي
map_ab(index in A, range variables, runtime variables) -> index in B.
لفصل أنواع وسيطات الربط بشكل أفضل، نكتبها على النحو التالي:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
على سبيل المثال، لنلقِ نظرة على خرائط الفهرسة لعملية التصغير
f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
لربط عناصر
inبعناصرout، يمكن التعبير عن الدالة بالشكل(d0, d1, d2, d3) -> (d1, d2). يتم تحديد قيود المتغيّراتd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]من خلال شكلin.لربط عناصر
outبعناصرin: لا يحتويoutإلا على سمتَين، ويؤدي الاختزال إلى إضافة متغيّرَي نطاق يغطيان عملية اختزال السمات. وبالتالي، تكون دالة الربط هي(d0, d1)[s0, s1] -> (s0, d0, d1, s1)، حيث(d0, d1)هو فهرسout. s0وs1هما نطاقان محدّدان حسب دلالات العملية، ويشملان البُعدَين 0 و3 من موترin. القيود هيd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
من المهم ملاحظة أنّنا في معظم الحالات نهتم بعملية الربط من عناصر الناتج. للحوسبة
C = op1(A, B)
E = op2(C, D)
يمكننا التحدث عن "فهرسة B" بمعنى "ربط عناصر E بعناصر B". قد يبدو هذا غير منطقي مقارنةً بأنواع أخرى من تحليل تدفّق البيانات التي تعمل من المدخلات إلى المخرجات.
تتيح القيود المفروضة على المتغيرات فرص التحسين وتساعد في إنشاء الرموز البرمجية. في المستندات، يُشار إلى القيود المفروضة على التنفيذ أيضًا باسم النطاق، لأنّها تحدّد جميع التركيبات أو قيم الوسيطة الصالحة لدالة الربط. بالنسبة إلى العديد من العمليات، تصف القيود ببساطة أبعاد الموترات، ولكن بالنسبة إلى بعض العمليات، قد تكون أكثر تعقيدًا، كما هو موضّح في الأمثلة أدناه.
من خلال التعبير عن الدوال وقيود الوسيطات بشكل رمزي وإمكانية الجمع بين الدوال والقيود، يمكننا حساب عملية ربط فهرسة مضغوطة لعملية حسابية كبيرة عشوائية (دمج).
إنّ التعبير عن الدالة الرمزية والقيود هو توازن بين تعقيد التنفيذ ومكاسب التحسين التي نحصل عليها من خلال الحصول على تمثيل أكثر دقة. بالنسبة إلى بعض عمليات HLO، نسجّل أنماط الوصول بشكل تقريبي فقط.
التنفيذ
بما أنّنا نريد تقليل إعادة الحساب إلى الحدّ الأدنى، نحتاج إلى مكتبة للحسابات الرمزية. تعتمد XLA على MLIR، لذا نستخدم mlir::AffineMap بدلاً من كتابة مكتبة أخرى للحساب الرمزي.
يبدو AffineMap النموذجي على النحو التالي
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
يحتوي AffineMap على نوعَين من المَعلمات: السمات والرموز.
تتوافق السمات مع متغيّرات السمات d، وتتوافق الرموز مع متغيّرات النطاق r ومتغيّرات وقت التشغيل rt. لا يحتوي AffineMap على أي بيانات وصفية حول قيود المَعلمات، لذا علينا تقديمها بشكل منفصل.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ ترميز قيود المربّع الشاملة لمتغيرات الأبعاد d لخريطة الفهرسة، والتي تتطابق عادةً مع شكل موتر الإخراج للعمليات، مثل التبديل والاختزال والعناصر والضرب النقطي، ولكن هناك بعض الاستثناءات، مثل HloConcatenateInstruction.
range_vars_ جميع القيم التي تتخذها متغيرات النطاق s. تكون متغيرات النطاق مطلوبة عندما تكون قيم متعددة ضرورية لاحتساب عنصر واحد من الموتر الذي يتم الربط منه، مثلاً لخريطة فهرسة الإخراج->الإدخال الخاصة بعمليات التصغير أو خريطة الإدخال->الإخراج الخاصة بعمليات البث.
rt_vars_ ترميز القيم الممكنة في وقت التشغيل على سبيل المثال، يكون الإزاحة ديناميكية بالنسبة إلى HloDynamicSliceInstruction أحادي الأبعاد. سيكون للسمة RTVar المقابلة قيم ممكنة تتراوح بين 0 وtensor_size - slice_size - 1.
constraints_ التقاط العلاقات بين القيم في النموذج
<expression> in <range>، على سبيل المثال d0 + s0 in [0, 20] ويحدّد هذان العاملان معًا "مجال" وظيفة الفهرسة.Variable.bounds
لنستعرض بعض الأمثلة لفهم معنى كل ما سبق.
فهرسة الخرائط للعمليات غير المدمجة
حسب العناصر
بالنسبة إلى العمليات على مستوى العناصر، تكون خريطة الفهرسة هي نفسها.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
خريطة الإخراج إلى الإدخال output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
خريطة الإدخال إلى الإخراج p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
البث
يعني البث أنّه ستتم إزالة بعض الأبعاد عند ربط الناتج بالمدخل، وإضافتها عند ربط المدخل بالناتج.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
خريطة الإخراج إلى الإدخال:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
خريطة الإدخال إلى الإخراج:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
لاحظ أنّ لدينا الآن متغيّرات نطاق s على الجانب الأيسر لعملية الربط بين الإدخال والإخراج. هذه هي الرموز التي تمثّل نطاقات القيم.
على سبيل المثال، في هذه الحالة تحديدًا، يتم ربط كل عنصر من عناصر الإدخال التي تحمل الفهرس d0 بشريحة من الناتج بحجم 10x1x30.
Iota
لا يحتوي Iota على عامل تشغيل موتر إدخال، لذا لا توجد وسيطات فهرس إدخال.
iota = f32[2,4] iota(), dimensions={1}
ربط الإخراج بخريطة الإدخال:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
خريطة الإدخال إلى الإخراج:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
تحتوي DynamicSlice على إزاحات لا يمكن معرفتها إلا في وقت التشغيل.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
خريطة الإخراج إلى الإدخال من ds إلى src:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
يُرجى العِلم أنّ لدينا الآن rt على الجانب الأيسر لربط الإدخال بالإخراج.
هذه هي الرموز التي تمثّل قيم وقت التشغيل. على سبيل المثال، في هذه الحالة المحدّدة، لكل عنصر من عناصر الناتج بفهارس d0, d1, d2، نصل إلى إزاحات الشرائح of1 وof2 وof3 لاحتساب فهرس الإدخال.
يتم اشتقاق الفواصل الزمنية لمتغيرات وقت التشغيل بافتراض أنّ الشريحة بأكملها تظل ضمن الحدود.
خريطة الإخراج إلى الإدخال لكل من of1 وof2 وof3:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
تكون عملية ربط الناتج بالمدخل في src بسيطة. ويمكن أن تكون أكثر دقة من خلال حصر النطاق على الفهارس غير المعدَّلة، ولكن في الوقت الحالي، لا تتيح خرائط الفهرسة قيود عدم المساواة.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
خريطة الإخراج إلى الإدخال لـ upd:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
لاحظ أنّ لدينا الآن rt0 وrt1 اللذين يمثّلان قيم وقت التشغيل. في هذه الحالة المحدّدة، لكل عنصر من عناصر الناتج التي تحمل الفهارس d0, d1، نصل إلى إزاحات الشرائح of1 وof2 لاحتساب فهرس الإدخال. يتم اشتقاق الفواصل الزمنية لمتغيرات وقت التشغيل بافتراض أنّ الشريحة بأكملها تظل ضمن الحدود.
خريطة الإخراج إلى الإدخال لكلّ من of1 وof2:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
لا يتوفّر سوى خيار التجميع المبسّط. راجِع gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
خريطة الإخراج إلى الإدخال لـ operand:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
يُرجى العِلم أنّ لدينا الآن رموز rt تمثّل قيم وقت التشغيل.
خريطة الإخراج إلى الإدخال لـ indices:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
يُظهر متغيّر النطاق s0 أنّنا نحتاج إلى الصف بأكمله (d0, *) من موتر indices لاحتساب عنصر من الناتج.
نقل
خريطة الفهرسة لعملية التبديل هي تبديل لأبعاد الإدخال/الإخراج.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
خريطة الإخراج إلى الإدخال:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
خريطة الإدخال إلى الإخراج:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
عكس
تعمل خريطة الفهرسة للتغييرات المعكوسة على تغيير السمات التي تمّت العودة عنها إلى upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
خريطة الإخراج إلى الإدخال:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
خريطة الإدخال إلى الإخراج:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
تتضمّن عملية الاختزال المتغيرة عددًا من المدخلات والقيم الأولية، وتضيف عملية الربط من الناتج إلى المدخلات السمات المختزلة.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
خرائط الإخراج إلى الإدخال:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
خرائط الإدخال إلى الإخراج:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
الشريحة
تؤدي الفهرسة من الناتج إلى المدخلات لنتائج الشرائح إلى إنشاء خريطة فهرسة بخطوات ثابتة تكون صالحة لكل عنصر من عناصر الناتج. يقتصر الربط من الإدخال إلى الإخراج على نطاق متدرّج من العناصر في الإدخال.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
خريطة الإخراج إلى الإدخال:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
خريطة الإدخال إلى الإخراج:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
إعادة التشكيل
تتوفّر عمليات إعادة التشكيل بنكهات مختلفة.
تصغير الشكل
هذه عملية إعادة تشكيل "تخطيطية" من N-D إلى 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
خريطة الإخراج إلى الإدخال:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
خريطة الإدخال إلى الإخراج:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
توسيع الشكل
هذه عملية عكسية لعملية "طي الشكل"، فهي تعيد تشكيل إدخال أحادي الأبعاد إلى ناتج متعدد الأبعاد.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
خريطة الإخراج إلى الإدخال:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
خريطة الإدخال إلى الإخراج:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
إعادة تشكيل عامة
هذه هي عمليات تغيير الشكل التي لا يمكن تمثيلها كشكل واحد للتوسيع أو التصغير. ويمكن تمثيلها فقط على شكل تركيبة من شكلين أو أكثر من أشكال التوسيع أو التصغير.
المثال 1: التحويل إلى تنسيق تسلسلي والتحويل من تنسيق تسلسلي
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
يمكن تمثيل عملية إعادة التشكيل هذه على أنّها تركيبة من عملية تصغير الشكل من tensor<4x8xf32> إلى tensor<32xf32>، ثم عملية توسيع الشكل إلى tensor<2x4x4xf32>.
خريطة الإخراج إلى الإدخال:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
خريطة الإدخال إلى الإخراج:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
المثال 2: الأشكال الفرعية الموسّعة والمصغّرة
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
يمكن تمثيل عملية إعادة التشكيل هذه على أنّها تركيبة من عمليتَي إعادة تشكيل. تعمل الأولى على دمج الأبعاد الخارجية tensor<4x8x12xf32> في tensor<32x12xf32>، بينما تعمل الثانية على توسيع البُعد الداخلي tensor<32x12xf32> إلى tensor<32x3x4xf32>.
خريطة الإخراج إلى الإدخال:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
خريطة الإدخال إلى الإخراج:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
يمكن تمثيل عملية bitcast على أنّها تسلسل من عمليات التبديل وإعادة التشكيل والتبديل. لذلك، فإنّ خرائط الفهرسة الخاصة بها هي مجرد تركيبة من خرائط الفهرسة الخاصة بهذه السلسلة.
دمج
يتم تحديد عملية الربط بين الإخراج والإدخال للدالة concat لجميع المدخلات، ولكن مع نطاقات غير متداخلة، أي سيتم استخدام أحد المدخلات فقط في كل مرة.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
يتم ربط الناتج بالمدخلات على النحو التالي:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
مدخلات خرائط الإخراج:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
تشبه خرائط الفهرسة الخاصة بالدالة dot تلك الخاصة بالدالة reduce إلى حد كبير.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
يتم ربط الناتج بالمدخلات على النحو التالي:
- الناتج -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
مدخلات خرائط الإخراج:
- p0 -> الناتج:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
الوسادة
فهرسة PadOp هي عكس فهرسة SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
يشير إعداد المساحة المتروكة 1_4_1x4_8_0 إلى lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
خرائط الإخراج إلى الإدخال:
- الناتج -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
تنفّذ الدالة ReduceWindow في XLA أيضًا عملية الحشو. لذلك، يمكن احتساب خرائط الفهرسة على أنّها تركيبة من فهرسة ReduceWindow التي لا تضيف أي مساحة فارغة وفهرسة PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
خرائط الإخراج إلى الإدخال:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
فهرسة الخرائط لـ Fusion
خريطة الفهرسة لعملية الدمج هي تركيبة من خرائط الفهرسة لكل عملية في المجموعة. قد يحدث أن تتم قراءة بعض المدخلات عدة مرات باستخدام أنماط وصول مختلفة.
إدخال واحد، عدة خرائط فهرسة
في ما يلي مثال على p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
ستكون خرائط الفهرسة من الإخراج إلى الإدخال الخاصة بـ p0 هي (d0, d1) -> (d0, d1) و(d0, d1) -> (d1, d0). وهذا يعني أنّه لحساب أحد عناصر الناتج، قد نحتاج إلى قراءة مَعلمة الإدخال مرتين.
خريطة فهرسة واحدة لإزالة التكرار
![]()
في بعض الحالات، تكون خرائط الفهرسة متطابقة في الواقع، على الرغم من أنّ ذلك لا يبدو واضحًا على الفور.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
في هذه الحالة، تكون خريطة الفهرسة من الإخراج إلى الإدخال الخاصة بـ p0 هي (d0, d1, d2) -> (d2, d0, d1) فقط.
Softmax
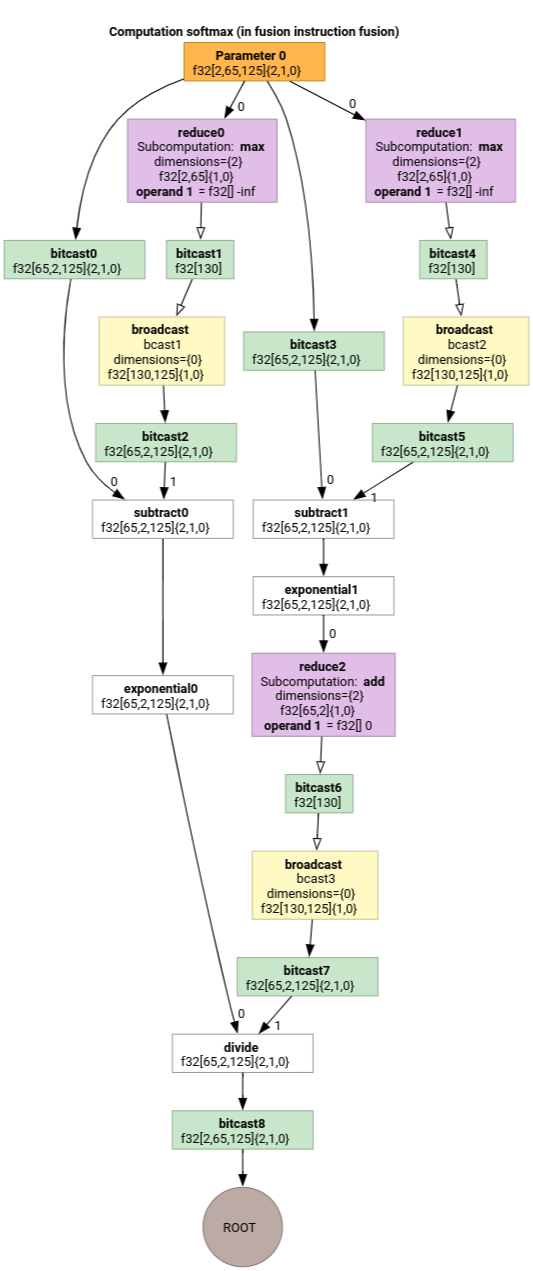
خرائط الفهرسة من الناتج إلى المدخل لـ parameter 0 لـ softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
و
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
حيث يشير s0 إلى البُعد الأعمق للإدخال.
للاطّلاع على المزيد من الأمثلة، راجِع indexing_analysis_test.cc.
Indexing Map Simplifier
لا يمكن للمبسّط التلقائي لعملية نقل البيانات من المصدر إلى mlir::AffineMap أن يضع أي افتراضات بشأن نطاقات الأبعاد أو الرموز. لذلك، لا يمكنه تبسيط التعبيرات التي تتضمّن mod وdiv بكفاءة.
يمكننا الاستفادة من المعلومات حول الحدود الدنيا والعليا للتعبيرات الفرعية في الخرائط التقاربية لتبسيطها بشكل أكبر.
يمكن للمبسّط إعادة كتابة التعبيرات التالية.
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)لـ d في[0, 6] x [0, 14]يصبح(d0, d1) -> (d0, d1)- تصبح قيمة
(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)في حسابdi in [0, 9]هي(d0, d1, d2) -> (d0, d1, d2). - تصبح قيمة
(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)في حسابd_i in [0, 9]هي(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8). - تصبح قيمة
(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)لـ d في[0, 9] x [0, 10]هي(d0, d1) -> (d0).
تتيح لنا أداة تبسيط خريطة الفهرسة فهم أنّ بعض عمليات إعادة التشكيل المتسلسلة في HLO تلغي بعضها البعض.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
بعد إنشاء خرائط الفهرسة وتبسيطها، سنحصل على
(d0, d1, d2) -> (d0, d1, d2).
يؤدي تبسيط خريطة الفهرسة أيضًا إلى تبسيط القيود.
- تتم إعادة كتابة قيود النوع
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundعلى النحو التالي:updated_lower_bound <= affine_expr <= updated_upped_bound. - يتم استبعاد القيود التي يتم استيفاؤها دائمًا، مثل
d0 + s0 in [0, 20]بالنسبة إلىd0 in [0, 5]وs0 in [1, 3]. - يتم تحسين التعبيرات الأقرب إلى الخطية في القيود كما هو الحال في خريطة الفهرسة الأقرب إلى الخطية أعلاه.
للاطّلاع على المزيد من الأمثلة، راجِع indexing_map_test.cc.