
XLA:GPU에서 HLO 코드를 생성하는 방법에는 세 가지가 있습니다.
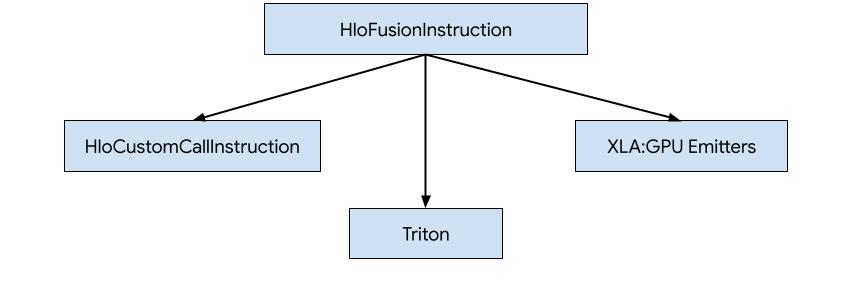
- HLO를 외부 라이브러리(예: NVidia cuBLAS, cuDNN)에 대한 맞춤 호출로 대체
- HLO를 블록 수준으로 타일링한 다음 OpenAI Triton을 사용합니다.
- XLA Emitter를 사용하여 HLO를 LLVM IR로 점진적으로 낮춥니다.
이 문서는 XLA:GPU Emitters에 중점을 둡니다.
히어로 기반 코드 생성
XLA:GPU에는 7가지 이미터 유형이 있습니다. 각 이미터 유형은 융합의 '히어로'에 해당합니다. 즉, 융합된 계산에서 전체 융합의 코드 생성을 형성하는 가장 중요한 작업입니다.
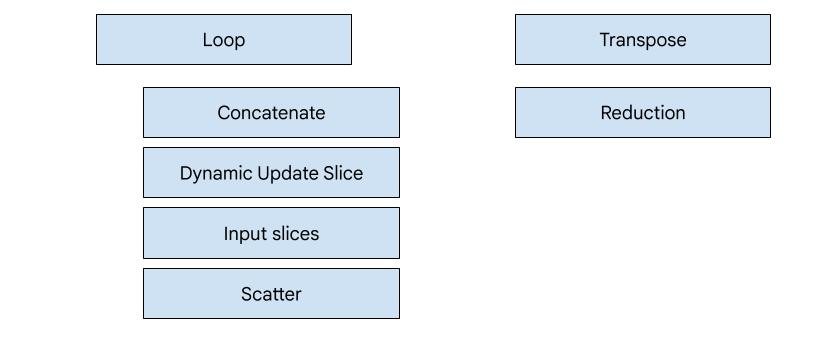
예를 들어 메모리 읽기 및 쓰기 패턴을 개선하기 위해 공유 메모리를 사용해야 하는 HloTransposeInstruction가 융합 내에 있는 경우 전치 이미터가 선택됩니다. 축소 이미터는 셔플과 공유 메모리를 사용하여 축소를 생성합니다. 루프 이미터가 기본 이미터입니다. 특수 이미터가 있는 히어로가 융합에 없으면 루프 이미터가 사용됩니다.
높은 수준의 개요
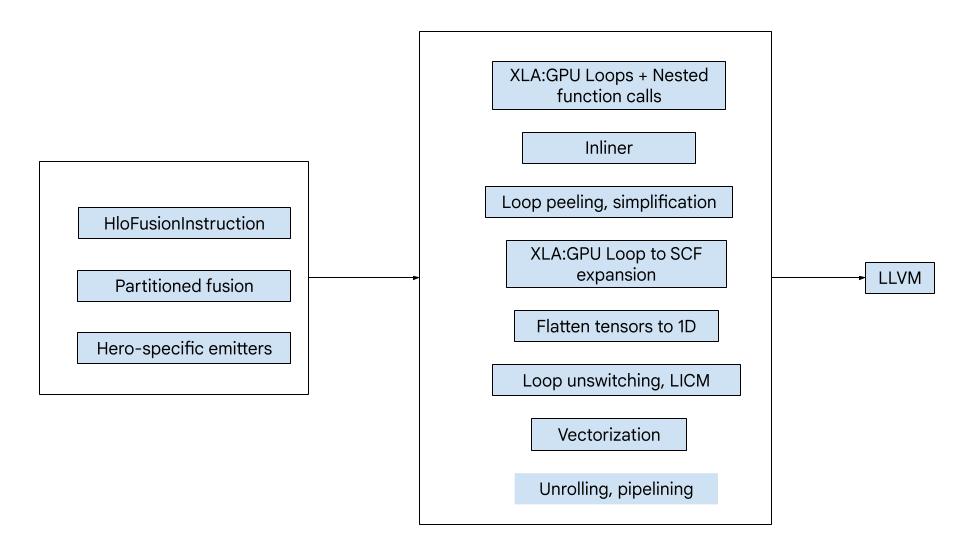
코드는 다음과 같은 큰 구성요소로 구성됩니다.
- 계산 파티셔너 - HLO 융합 계산을 함수로 분할
- 이미터 - 파티셔닝된 HLO 융합을 MLIR로 변환 (
xla_gpu,tensor,arith,math,scf다이얼렉트) - 컴파일 파이프라인 - IR을 최적화하고 LLVM으로 낮춤
파티션 나누기
computation_partitioner.h를 참고하세요.
요소별이 아닌 HLO 명령어는 항상 함께 내보낼 수 없습니다. 다음 HLO 그래프를 고려하세요.
param
|
log
| \
| transpose
| /
add
단일 함수에서 이를 내보내면 log는 add의 각 요소에 대해 서로 다른 두 인덱스에서 액세스됩니다. 이전 이미터는 log를 두 번 생성하여 이 문제를 해결합니다. 이 특정 그래프에서는 문제가 되지 않지만 분할이 여러 개 있으면 코드 크기가 기하급수적으로 증가합니다.
여기에서는 그래프를 하나의 함수로 안전하게 내보낼 수 있는 조각으로 분할하여 이 문제를 해결합니다. 기준은 다음과 같습니다.
- 사용자가 한 명뿐인 명령어는 사용자와 함께 내보내도 안전합니다.
- 여러 사용자가 있는 명령어는 모든 사용자가 동일한 색인을 통해 액세스하는 경우 사용자와 함께 내보내도 안전합니다.
위의 예에서 add와 tranpose는 log의 서로 다른 색인에 액세스하므로 함께 내보내는 것은 안전하지 않습니다.
따라서 그래프는 세 개의 함수로 파티셔닝됩니다 (각 함수에는 하나의 명령어만 포함됨).
add의 slice 및 pad이 있는 다음 예시에도 동일하게 적용됩니다.
원소 방출
elemental_hlo_to_mlir.h를 참고하세요.
Elemental emission은 HloInstructions의 루프와 수학/산술 연산을 만듭니다. 대부분의 경우 간단하지만 여기에는 몇 가지 흥미로운 점이 있습니다.
색인 생성 변환
일부 명령어 (transpose, broadcast, reshape, slice, reverse 등)는 순전히 색인에 대한 변환입니다. 결과의 요소를 생성하려면 입력의 다른 요소를 생성해야 합니다. 이를 위해 명령어의 출력-입력 매핑을 생성하는 함수가 있는 XLA의 indexing_analysis를 재사용할 수 있습니다.
예를 들어 [20,40]에서 [40,20]까지의 transpose의 경우 다음 색인 맵이 생성됩니다 (입력 차원당 하나의 아핀 표현식, d0 및 d1은 출력 차원임).
(d0, d1) -> d1
(d0, d1) -> d0
따라서 이러한 순수 색인 변환 명령어의 경우 맵을 가져와 출력 색인에 적용하고 결과 색인에서 입력을 생성하면 됩니다.
마찬가지로 pad 작업은 대부분의 구현에 색인 생성 맵과 제약 조건을 사용합니다. pad는 입력 요소 또는 패딩 값을 반환하는지 확인하기 위해 몇 가지 검사가 추가된 색인 변환이기도 합니다.
튜플
내부 tuple는 지원되지 않습니다. 중첩된 튜플 출력도 지원하지 않습니다. 이러한 기능을 사용하는 모든 XLA 그래프는 이러한 기능을 사용하지 않는 그래프로 변환할 수 있습니다.
수집
gather_simplifier에서 생성된 표준 수집만 지원됩니다.
하위 그래프 함수
%p0~%p_n 매개변수가 있는 계산 하위 그래프와 r 차원 및 요소 유형 (e0~e_m)이 있는 하위 그래프 루트의 경우 다음 MLIR 함수 서명을 사용합니다.
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
즉, 계산 파라미터당 텐서 입력 하나, 출력의 차원당 색인 입력 하나, 출력당 결과 하나가 있습니다.
함수를 내보내려면 위의 기본 내보내기를 사용하고 하위 그래프의 끝에 도달할 때까지 피연산자를 재귀적으로 내보내면 됩니다. 그런 다음 매개변수의 경우 tensor.extract를 내보내고 다른 하위 그래프의 경우 func.call를 내보냅니다.
진입 함수
각 이미터 유형은 항목 함수, 즉 영웅의 함수를 생성하는 방식이 다릅니다. 진입점 함수는 입력으로 인덱스가 없고 (스레드 및 블록 ID만 있음) 실제로 출력을 어딘가에 써야 하므로 위의 함수와 다릅니다. 루프 이미터의 경우 이는 매우 간단하지만 전치 및 축소 이미터에는 사소하지 않은 쓰기 로직이 있습니다.
항목 계산의 서명은 다음과 같습니다.
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
이전과 마찬가지로 %pn는 계산의 매개변수이고 %rn는 계산 결과입니다. 항목 계산은 결과를 텐서로 가져와 tensor.insert가 이를 업데이트한 후 반환합니다.
출력 텐서의 다른 사용은 허용되지 않습니다.
컴파일 파이프라인
루프 이미터
loop.h를 참고하세요.
GELU 함수의 HLO를 사용하여 MLIR 컴파일 파이프라인의 가장 중요한 패스를 살펴보겠습니다.
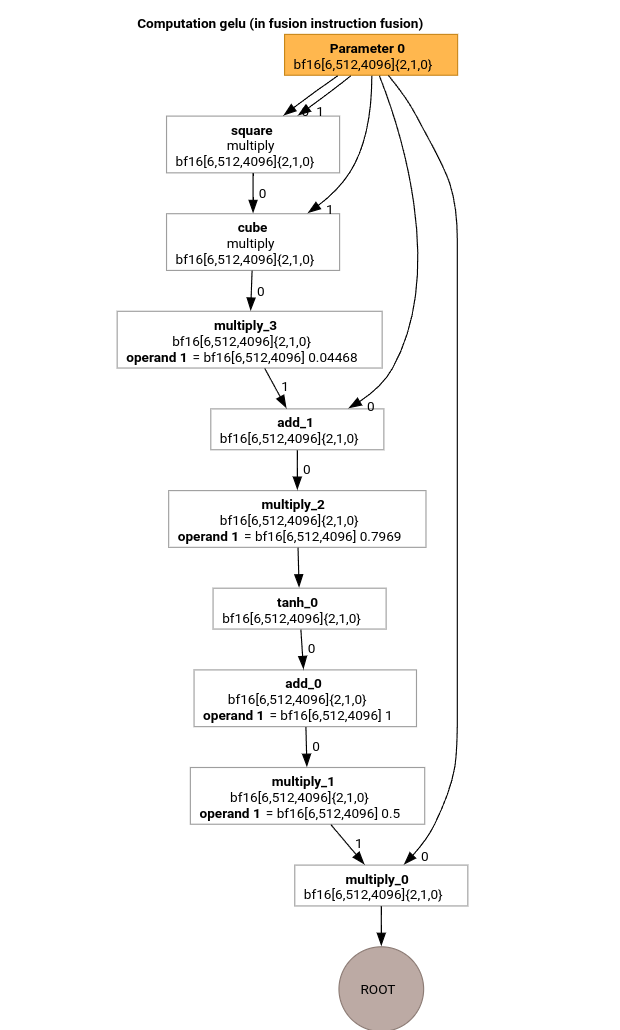
이 HLO 계산에는 요소별 작업, 상수, 브로드캐스트만 있습니다. 루프 이미터를 사용하여 방출됩니다.
MLIR 변환
MLIR로 변환한 후에는 %thread_id_x 및 %block_id_x에 종속되고 병합된 쓰기를 보장하기 위해 출력의 모든 요소를 선형으로 순회하는 루프를 정의하는 xla_gpu.loop가 생성됩니다.
이 루프의 각 반복에서
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
루트 작업의 요소를 계산합니다. 파티셔너가 다양한 액세스 패턴이 2개 이상인 텐서를 감지하지 못했기 때문에 @gelu에 대한 윤곽선 함수가 하나만 있습니다.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
인라이너
@gelu가 인라인 처리되면 단일 @main 함수가 생성됩니다. 동일한 함수가 두 번 이상 호출될 수 있습니다. 이 경우 인라인되지 않습니다. 인라인 규칙에 관한 자세한 내용은 xla_gpu_dialect.cc에서 확인할 수 있습니다.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu~scf 전환
lower_xla_gpu_to_scf.cc를 참고하세요.
xla_gpu.loop은 경계 검사가 내부에 있는 루프 중첩을 나타냅니다. 루프 유도 변수가 색인 지도 도메인의 범위를 벗어나면 이 반복은 건너뜁니다. 이는 루프가 내부에 scf.if가 있는 하나 이상의 중첩된 scf.for 작업으로 변환된다는 의미입니다.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
텐서 평탄화
flatten_tensors.cc를 참고하세요.
N차원 텐서가 1차원으로 투영됩니다. 이렇게 하면 모든 텐서 액세스가 이제 메모리에서 데이터가 정렬되는 방식에 해당하므로 벡터화와 LLVM으로의 낮추기가 간소화됩니다.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
벡터화
vectorize_loads_stores.cc를 참고하세요.
이 패스는 tensor.extract 및 tensor.insert 작업의 색인을 분석하고, %vector_index와 관련하여 연속적으로 요소에 액세스하는 xla_gpu.apply_indexing에 의해 생성되고 액세스가 정렬되면 tensor.extract가 vector.transfer_read로 변환되고 루프에서 호이스팅됩니다.
이 경우 0~4의 scf.for 루프에서 추출하고 삽입할 요소를 계산하는 데 사용되는 색인 생성 맵 (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index)가 있습니다.
따라서 tensor.extract와 tensor.insert 모두 벡터화할 수 있습니다.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
루프 펼치기
optimize_loops.cc를 참고하세요.
루프 풀기는 풀 수 있는 scf.for 루프를 찾습니다. 이 경우 벡터의 요소에 대한 루프가 사라집니다.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
LLVM으로 변환
표준 LLVM 하위 항목을 주로 사용하지만 몇 가지 특별한 패스가 있습니다.
IR을 버퍼링하지 않고 ABI가 memref ABI와 호환되지 않으므로 텐서에 memref 낮추기를 사용할 수 없습니다. 대신 텐서에서 LLVM로 직접 낮추는 맞춤형 낮추기가 있습니다.
- 텐서의 하향은 lower_tensors.cc에서 실행됩니다.
tensor.extract는llvm.load로,tensor.insert는llvm.store로 명확하게 낮아집니다. - propagate_slice_indices와 merge_pointers_to_same_slice는 함께 버퍼 할당과 XLA의 ABI 세부사항을 구현합니다. 두 텐서가 동일한 버퍼 슬라이스를 공유하는 경우 한 번만 전달됩니다. 이러한 패스는 함수 인수를 중복 제거합니다.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
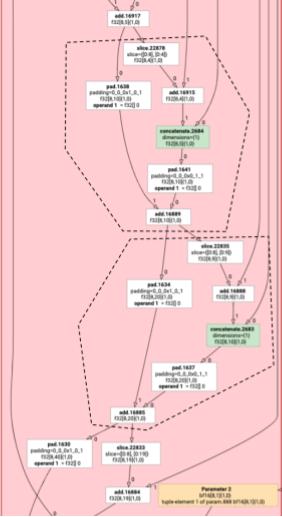
트랜스포즈 이미터
약간 더 복잡한 예를 살펴보겠습니다.
![]()
전치 이미터는 진입점 함수가 생성되는 방식만 루프 이미터와 다릅니다.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
이 경우 두 개의 xla_gpu.loop 작업을 생성합니다. 첫 번째는 입력에서 병합된 읽기를 실행하고 결과를 공유 메모리에 씁니다.
공유 메모리 텐서는 xla_gpu.allocate_shared 작업을 사용하여 생성됩니다.
xla_gpu.sync_threads를 사용하여 스레드가 동기화되면 두 번째 xla_gpu.loop가 공유 메모리 텐서에서 요소를 읽고 출력에 병합된 쓰기를 실행합니다.
재현기
컴파일 파이프라인을 통과할 때마다 IR을 확인하려면 --xla_dump_emitter_re=mlir-fusion 플래그를 사용하여 run_hlo_module를 실행하면 됩니다.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
여기서 /tmp/gelu.hlo에는 다음이 포함됩니다.
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
코드 링크
- 컴파일 파이프라인: emitter_base.h
- 최적화 및 변환 패스: backends/gpu/codegen/emitters/transforms
- 파티션 로직: computation_partitioner.h
- 히어로 기반 이미터: backends/gpu/codegen/emitters
- XLA:GPU 작업: xla_gpu_ops.td
- 정확성 및 lit 테스트: backends/gpu/codegen/emitters/tests