
Istnieją 3 sposoby generowania kodu dla HLO w XLA:GPU.
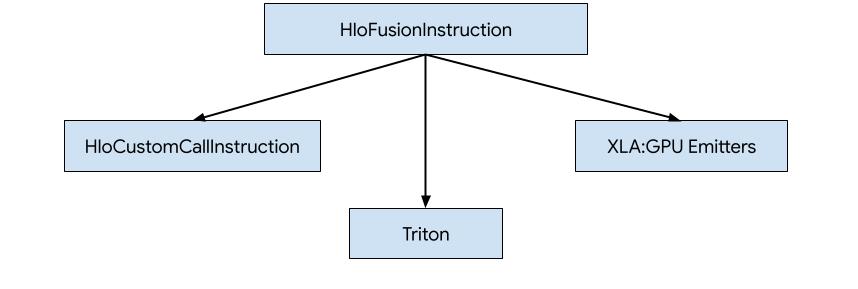
- Zastępowanie HLO niestandardowymi wywołaniami bibliotek zewnętrznych, np. NVidia cuBLAS, cuDNN.
- Dzielenie HLO na bloki, a następnie używanie OpenAI Triton.
- Używanie emiterów XLA do stopniowego obniżania HLO do LLVM IR.
Ten dokument dotyczy modułów XLA:GPU Emitters.
Generowanie kodu na podstawie bohaterów
W XLA:GPU jest 7 typów emiterów. Każdy typ emitera odpowiada „głównemu” operatorowi w fuzji, czyli najważniejszemu operatorowi w połączonych obliczeniach, który kształtuje generowanie kodu dla całej fuzji.
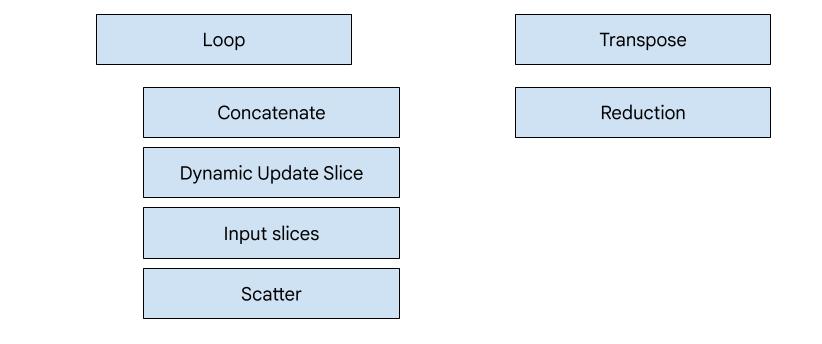
Na przykład emiter transpozycji zostanie wybrany, jeśli w fuzji występuje element HloTransposeInstruction, który wymaga użycia pamięci współdzielonej w celu poprawy wzorców odczytu i zapisu pamięci. Moduł redukcji generuje redukcje za pomocą tasowania i pamięci współdzielonej. Domyślnym emiterem jest emiter pętli. Jeśli fuzja nie ma bohatera, dla którego mamy specjalny emiter, użyjemy emitera pętli.
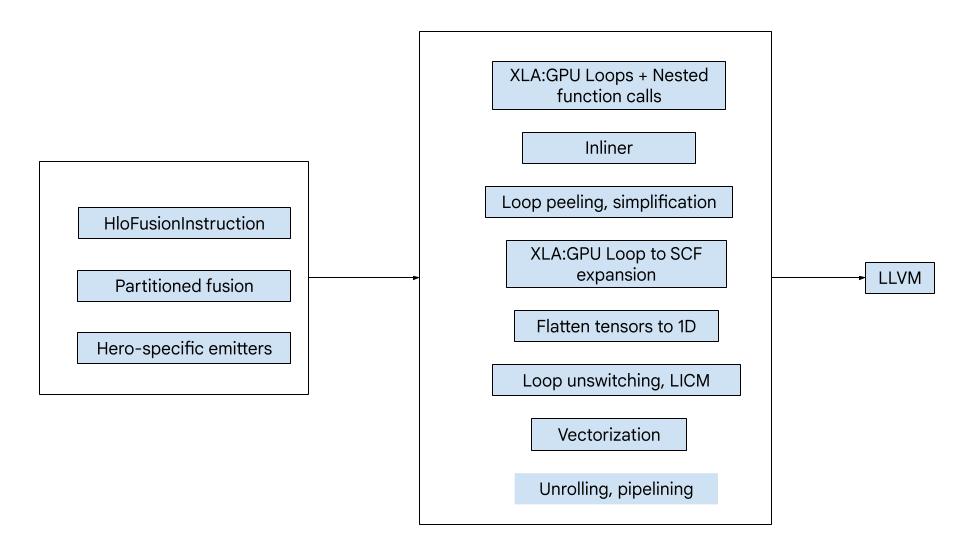
Ogólne omówienie
Kod składa się z następujących głównych elementów składowych:
- Partycjonowanie obliczeń – dzielenie obliczeń fuzji HLO na funkcje
- Emitters - converting partitioned HLO fusion to MLIR (
xla_gpu,tensor,arith,math,scfdialects) - Potok kompilacji – optymalizuje i obniża IR do LLVM
Partycjonowanie
Zobacz computation_partitioner.h.
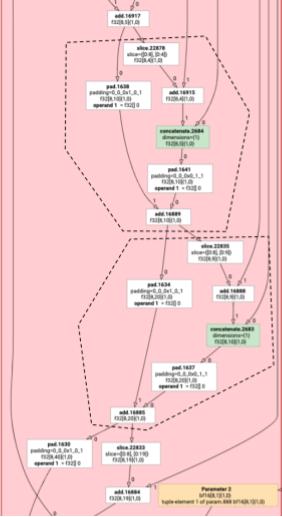
Instrukcje HLO, które nie są wykonywane element po elemencie, nie zawsze mogą być emitowane razem. Rozważmy ten graf HLO:
param
|
log
| \
| transpose
| /
add
Jeśli wyemitujemy to w jednej funkcji, do elementu log będzie się odwoływać w przypadku każdego elementu add w 2 różnych indeksach. Stare emitery rozwiązują ten problem, generując log dwukrotnie. W przypadku tego konkretnego wykresu nie stanowi to problemu, ale gdy jest wiele podziałów, rozmiar kodu rośnie wykładniczo.
Rozwiązujemy ten problem, dzieląc wykres na części, które można bezpiecznie wygenerować jako jedną funkcję. Kryteria te są następujące:
- Instrukcje, które mają tylko jednego użytkownika, można bezpiecznie emitować razem z tym użytkownikiem.
- Instrukcje, które mają wielu użytkowników, można bezpiecznie emitować razem z ich użytkownikami, jeśli wszyscy użytkownicy uzyskują do nich dostęp za pomocą tych samych indeksów.
W powyższym przykładzie zmienne add i tranpose uzyskują dostęp do różnych indeksów tablicy log, więc nie można ich razem emitować.
W związku z tym wykres jest podzielony na 3 funkcje (każda zawiera tylko 1 instrukcję).
To samo dotyczy poniższego przykładu, w którym slice i pad to add.
Emisja pierwiastków
Zobacz elemental_hlo_to_mlir.h.
Emisja elementarna tworzy pętle i operacje matematyczne/arytmetyczne dla HloInstructions. W większości przypadków jest to proste, ale dzieją się tu ciekawe rzeczy.
Przekształcenia indeksowania
Niektóre instrukcje (transpose, broadcast, reshape, slice, reverse i kilka innych) to czyste przekształcenia indeksów: aby uzyskać element wyniku, musimy uzyskać inny element danych wejściowych. W tym celu możemy ponownie wykorzystać funkcję indexing_analysis z XLA, która zawiera funkcje tworzenia mapowania danych wyjściowych na dane wejściowe dla instrukcji.
Na przykład dla transpose z [20,40] do [40,20] utworzy następującą mapę indeksowania (jedno wyrażenie afiniczne na wymiar wejściowy; d0 i d1 to wymiary wyjściowe):
(d0, d1) -> d1
(d0, d1) -> d0
W przypadku tych instrukcji czystej transformacji indeksu możemy po prostu pobrać mapę, zastosować ją do indeksów wyjściowych i wygenerować dane wejściowe w wynikowym indeksie.
Podobnie w większości implementacji operacja pad używa map indeksowania i ograniczeń. pad to również transformacja indeksowania z dodatkowymi sprawdzeniami, które pozwalają określić, czy zwracamy element danych wejściowych, czy wartość dopełnienia.
Krotki
Nie obsługujemy wewnętrznych tuple. Nie obsługujemy też zagnieżdżonych danych wyjściowych typu krotka. Wszystkie wykresy XLA, które korzystają z tych funkcji, można przekształcić w wykresy, które ich nie używają.
Zbieranie
Obsługujemy tylko kanoniczne zbiory danych wygenerowane przez gather_simplifier.
Funkcje podgrafu
W przypadku podgrafu obliczeń z parametrami %p0–%p_n i węzłami głównymi podgrafu o wymiarach r i typach elementów (e0–e_m) używamy tego podpisu funkcji MLIR:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Oznacza to, że mamy 1 tensor wejściowy na parametr obliczeń, 1 indeks wejściowy na wymiar danych wyjściowych i 1 wynik na dane wyjściowe.
Aby wyemitować funkcję, używamy po prostu emitera elementarnego powyżej i rekurencyjnie emitujemy jego operandy, aż dotrzemy do krawędzi podgrafu. Następnie emitujemy znak tensor.extract w przypadku parametrów lub znak func.call w przypadku innych podgrafów.
Funkcja wprowadzania
Każdy typ emitera różni się sposobem generowania funkcji wejścia, czyli funkcji bohatera. Funkcja wejścia różni się od powyższych funkcji, ponieważ nie ma indeksów jako danych wejściowych (tylko identyfikatory wątku i bloku) i musi zapisywać dane wyjściowe w określonym miejscu. W przypadku emitera pętli jest to dość proste, ale emitery transpozycji i redukcji mają nietrywialną logikę zapisu.
Sygnatura obliczania wpisu to:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
gdzie %pn to parametry obliczeń, a %rn to wyniki obliczeń. Obliczenia wpisu przyjmują wyniki jako tensory, tensor.insert aktualizuje je, a następnie zwraca.
Inne zastosowania tensorów wyjściowych są niedozwolone.
Potok kompilacji
Nadajnik pętlowy
Zobacz loop.h.
Przyjrzyjmy się najważniejszym etapom potoku kompilacji MLIR na przykładzie funkcji GELU.
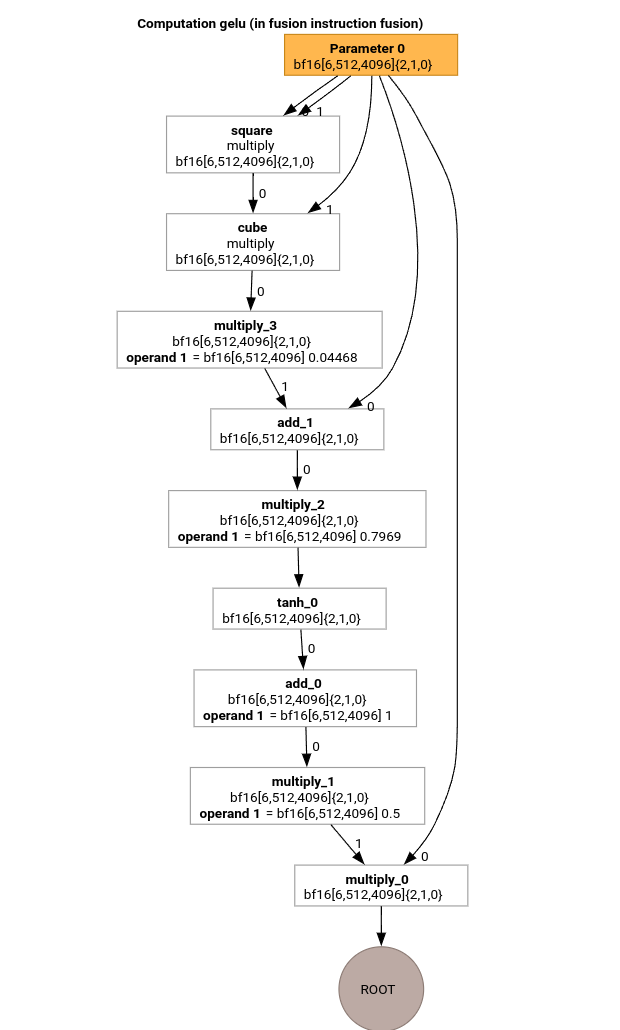
Obliczenia HLO zawierają tylko operacje na poszczególnych elementach, stałe i rozgłaszanie. Będzie on emitowany za pomocą emitera pętli.
Konwersja MLIR
Po przekształceniu do MLIR otrzymujemy xla_gpu.loop, które zależy od %thread_id_x i %block_id_x i definiuje pętlę, która przechodzi liniowo przez wszystkie elementy wyjściowe, aby zagwarantować scalone zapisy.
W każdej iteracji tej pętli wywołujemy
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
do obliczania elementów operacji głównej. Zauważ, że mamy tylko 1 funkcję z konturem dla @gelu, ponieważ partycjoner nie wykrył tensora, który ma co najmniej 2 różne wzorce dostępu.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Po wstawieniu funkcji @gelu otrzymujemy jedną funkcję @main. Może się zdarzyć, że ta sama funkcja zostanie wywołana 2 razy lub więcej. W takim przypadku nie umieszczamy treści w wierszu. Więcej informacji o regułach wstawiania znajdziesz w pliku xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu – scf konwersja
Zobacz lower_xla_gpu_to_scf.cc.
xla_gpu.loop oznacza zagnieżdżoną pętlę z sprawdzaniem warunku brzegowego wewnątrz. Jeśli zmienne indukcji pętli wykraczają poza zakres domeny mapy indeksowania, ta iteracja jest pomijana. Oznacza to, że pętla jest przekształcana w co najmniej 1 zagnieżdżoną operację scf.for z operacją scf.if wewnątrz.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Spłaszczanie tensorów
Zobacz flatten_tensors.cc.
Tensory N-wymiarowe są rzutowane na 1D. Uprości to wektoryzację i obniżanie do LLVM, ponieważ każdy dostęp do tensora odpowiada teraz sposobowi wyrównania danych w pamięci.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Wektoryzacja
Patrz vectorize_loads_stores.cc.
Etap analizuje indeksy w operacjach tensor.extract i tensor.insert. Jeśli są one generowane przez operację xla_gpu.apply_indexing, która uzyskuje dostęp do elementów w sposób ciągły w odniesieniu do operacji %vector_index, a dostęp jest wyrównany, operacja tensor.extract jest przekształcana w operację vector.transfer_read i przenoszona poza pętlę.
W tym konkretnym przypadku używana jest mapa indeksowania(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) do obliczania elementów, które mają zostać wyodrębnione i wstawione w pętli scf.for od 0 do 4.
Dlatego zarówno tensor.extract, jak i tensor.insert można wektoryzować.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Rozwijanie pętli
Zobacz optimize_loops.cc.
Rozwijanie pętli znajduje scf.for pętle, które można rozwinąć. W takim przypadku pętla po elementach wektora znika.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Konwersja na LLVM
Większość naszych obniżeń poziomu LLVM jest standardowa, ale jest też kilka specjalnych przejść.
Nie możemy używać obniżeń memref w przypadku tensorów, ponieważ nie buforujemy IR, a nasz interfejs ABI nie jest zgodny z interfejsem ABI memref. Zamiast tego mamy niestandardowe obniżanie bezpośrednio z tensorów do LLVM.
- Obniżanie rangi tensorów odbywa się w pliku lower_tensors.cc.
tensor.extractjest obniżana dollvm.load,tensor.insertdollvm.storew oczywisty sposób. - Razem funkcje propagate_slice_indices i merge_pointers_to_same_slice implementują szczegół przypisywania bufora i interfejsu ABI XLA: jeśli 2 tensory współdzielą ten sam wycinek bufora, są przekazywane tylko raz. Te przebiegi usuwają duplikaty argumentów funkcji.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Transponowanie emitera
Rozważmy nieco bardziej złożony przykład.
![]()
Emiter transponujący różni się od emitera pętli tylko sposobem generowania funkcji wejścia.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
W takim przypadku wygenerujemy 2 operacje xla_gpu.loop. Pierwsza z nich wykonuje scalone odczyty z danych wejściowych i zapisuje wynik w pamięci współdzielonej.
Tensor pamięci współdzielonej jest tworzony za pomocą operacji xla_gpu.allocate_shared.
Po zsynchronizowaniu wątków za pomocą polecenia xla_gpu.sync_threads drugi wątek xla_gpu.loop odczytuje elementy z tensora pamięci współdzielonej i wykonuje scalone zapisy w danych wyjściowych.
Reproducer
Aby zobaczyć IR po każdym przejściu potoku kompilacji, możesz uruchomić run_hlo_module z flagą --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
gdzie /tmp/gelu.hlo zawiera
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Linki do kodu
- Potok kompilacji: emitter_base.h
- Optymalizacja i przekształcenia konwersji: backends/gpu/codegen/emitters/transforms
- Logika partycjonowania: computation_partitioner.h
- Emitery oparte na bohaterach: backends/gpu/codegen/emitters
- XLA:operacje na GPU: xla_gpu_ops.td
- Testy poprawności i lit: backends/gpu/codegen/emitters/tests