
Há três maneiras de gerar código para HLO em XLA:GPU.
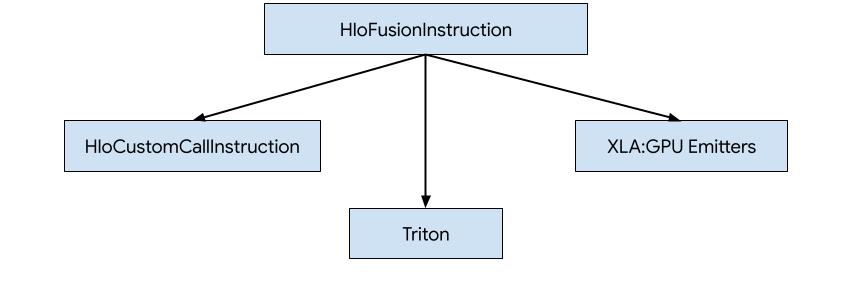
- Substituir HLO por chamadas personalizadas para bibliotecas externas, por exemplo, NVidia cuBLAS, cuDNN.
- Dividir o HLO em blocos e usar o OpenAI Triton.
- Como usar emissores XLA para reduzir progressivamente o HLO para LLVM IR.
Este documento se concentra nos emissores XLA:GPU.
Codegen baseado em herói
Há sete tipos de emissores no XLA:GPU. Cada tipo de emissor corresponde a um "herói" da fusão, ou seja, a operação mais importante na computação combinada que molda a geração de código para toda a fusão.
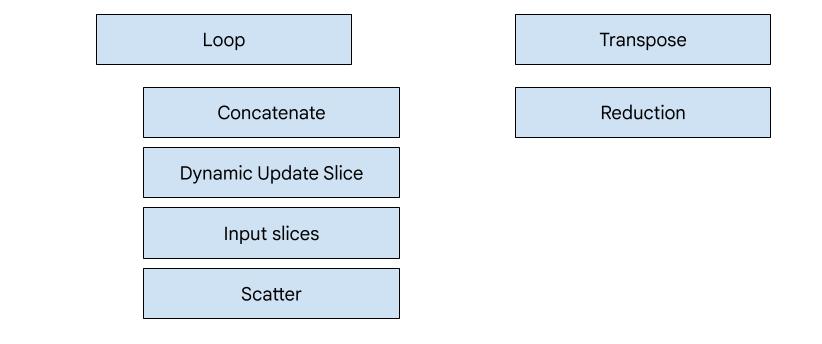
Por exemplo, o emissor de transposição será selecionado se houver um
HloTransposeInstruction na fusão que exija o uso de memória compartilhada para
melhorar os padrões de leitura e gravação de memória. O emissor de redução gera reduções usando embaralhamentos e memória compartilhada. O emissor de loop é o emissor padrão. Se uma fusão não tiver um herói para o qual temos um emissor especial,
o emissor de loop será usado.
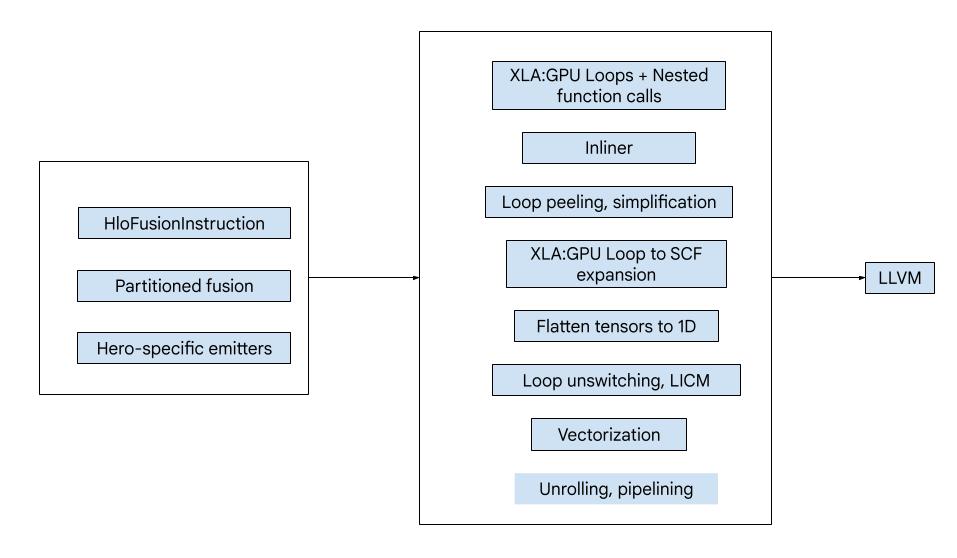
Visão geral detalhada
O código consiste nos seguintes blocos de construção:
- Particionador de computação: divide um cálculo de fusão de HLO em funções.
- Emissores: conversão da fusão de HLO particionada para MLIR (dialetos
xla_gpu,tensor,arith,math,scf) - Pipeline de compilação: otimiza e reduz a IR para LLVM
Particionamento
Consulte computation_partitioner.h.
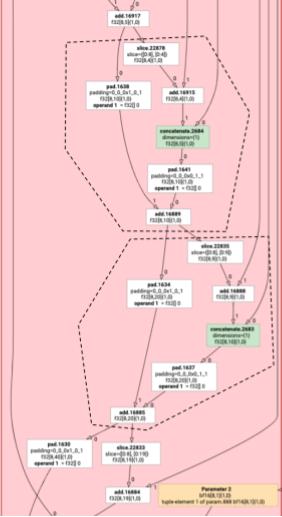
As instruções HLO não elementares nem sempre podem ser emitidas juntas. Considere o seguinte gráfico HLO:
param
|
log
| \
| transpose
| /
add
Se emitirmos isso em uma única função, o log será acessado em dois índices diferentes para cada elemento do add. Os emissores antigos resolvem esse
problema gerando o log duas vezes. Para esse gráfico específico, isso não é um problema, mas quando há várias divisões, o tamanho do código aumenta exponencialmente.
Aqui, resolvemos esse problema particionando o gráfico em partes que podem ser emitidas com segurança como uma função. Os critérios são:
- Instruções que têm apenas um usuário podem ser emitidas com segurança junto com o usuário.
- Instruções que têm vários usuários podem ser emitidas com eles se forem acessadas pelos mesmos índices.
No exemplo acima, add e tranpose acessam índices diferentes do log. Portanto, não é seguro emitir o log junto com eles.
Portanto, o gráfico é particionado em três funções (cada uma contendo apenas uma instrução).
O mesmo se aplica ao exemplo a seguir com slice e pad de add.
Emissão de elementos
Consulte elemental_hlo_to_mlir.h.
A emissão de elementos cria loops e operações matemáticas/aritméticas para HloInstructions. Na maior parte, isso é simples, mas há algumas coisas interessantes acontecendo aqui.
Transformações de indexação
Algumas instruções (transpose, broadcast, reshape, slice, reverse e mais algumas) são transformações puras em índices: para produzir um elemento do resultado, precisamos produzir algum outro elemento da entrada. Para isso, podemos reutilizar o indexing_analysis da XLA, que tem funções para produzir o mapeamento de saída para entrada de uma instrução.
Por exemplo, para um transpose de [20,40] para [40,20], ele vai produzir o seguinte mapa de indexação (uma expressão afim por dimensão de entrada; d0 e d1 são as dimensões de saída):
(d0, d1) -> d1
(d0, d1) -> d0
Portanto, para essas instruções de transformação de índice puro, podemos simplesmente extrair o mapa, aplicá-lo aos índices de saída e produzir a entrada no índice resultante.
Da mesma forma, a operação pad usa mapas de indexação e restrições para a maior parte da implementação. pad também é uma transformação de indexação com algumas verificações adicionais para saber se retornamos um elemento da entrada ou o valor de padding.
Tuplas
Não oferecemos suporte a tuples internos. Também não oferecemos suporte a tuplas aninhadas. Todos os gráficos XLA que usam esses recursos podem ser convertidos em gráficos que não usam.
Coletar
Aceitamos apenas coletas canônicas produzidas pelo gather_simplifier.
Funções de subgrafo
Para um subgrafo de uma computação com parâmetros %p0 a %p_n e raízes de subgrafo com dimensões r e tipos de elementos (e0 a e_m), usamos a seguinte assinatura de função MLIR:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Ou seja, temos uma entrada de tensor por parâmetro de computação, uma entrada de índice por dimensão da saída e um resultado por saída.
Para emitir uma função, basta usar o emissor de elementos acima e emitir recursivamente os operandos até chegar à borda do subgrafo. Em seguida, emitimos um
tensor.extract para parâmetros ou um func.call para outros subgrafos.
Função de entrada
Cada tipo de emissor difere na forma como gera a função de entrada, ou seja, a função do herói. A função de entrada é diferente das funções acima, já que não tem índices como entradas (apenas os IDs de linha de execução e bloco) e precisa gravar a saída em algum lugar. Para o emissor de loop, isso é bem simples, mas os emissores de transposição e redução têm uma lógica de gravação não trivial.
A assinatura do cálculo da entrada é:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Assim como antes, os %pns são os parâmetros da computação, e os %rns são os resultados dela. O cálculo de entrada usa os resultados como tensores, atualiza tensor.inserts neles e os retorna.
Nenhum outro uso dos tensores de saída é permitido.
Pipeline de compilação
Emissor de loop
Consulte loop.h.
Vamos estudar as transmissões mais importantes do pipeline de compilação do MLIR usando o HLO para a função GELU.
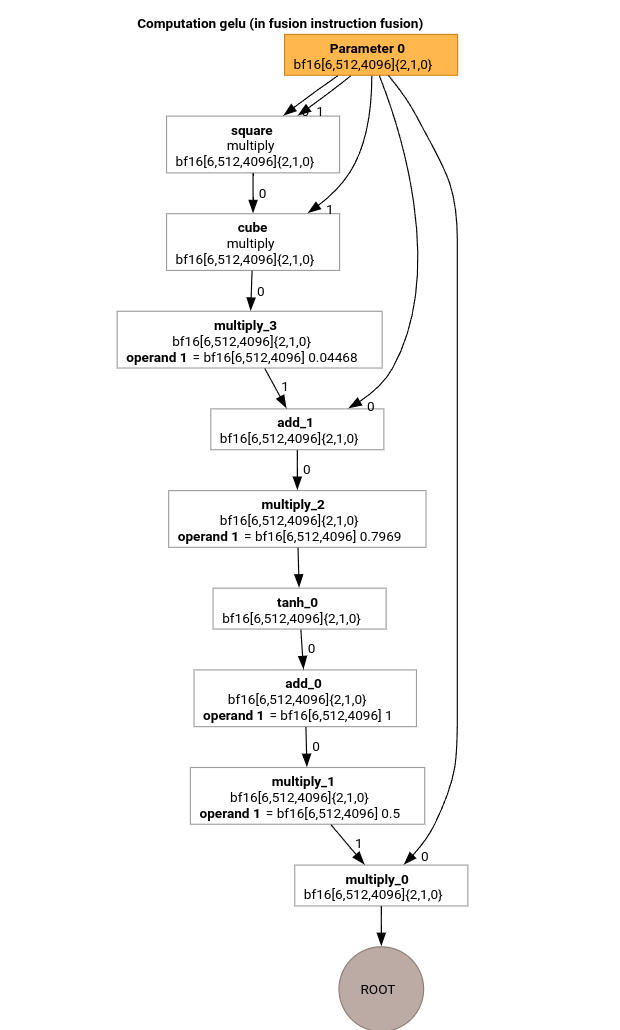
Esse cálculo de HLO tem apenas operações elementares, constantes e transmissões. Ele será emitido usando o emissor de loop.
Conversão de MLIR
Após a conversão para MLIR, recebemos um xla_gpu.loop que depende de %thread_id_x e %block_id_x e define o loop que percorre todos os elementos da saída de maneira linear para garantir gravações coalescidas.
Em cada iteração desse loop, chamamos
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
para calcular elementos da operação raiz. Observe que temos apenas uma função descrita para @gelu, porque o particionador não detectou um tensor que tem 2 ou mais padrões de acesso diferentes.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Depois que @gelu é inlinado, temos uma única função @main. É possível que a mesma função seja chamada duas ou mais vezes. Nesse caso, não fazemos isso. Mais detalhes sobre as regras de inlining podem ser encontrados em xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
Conversão de xla_gpu para scf
Consulte lower_xla_gpu_to_scf.cc.
xla_gpu.loop representa um aninhamento de loops com uma verificação de limite dentro. Se as variáveis de indução de loop estiverem fora dos limites do domínio do mapa de indexação, essa iteração será ignorada. Isso significa que o loop é convertido em uma ou mais operações scf.for aninhadas com um scf.if dentro.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Nivelar tensores
Consulte flatten_tensors.cc.
Os tensores N-d são projetados em 1D. Isso simplifica a vetorização e a redução para LLVM, porque cada acesso de tensor agora corresponde a como os dados são alinhados na memória.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vetorização
Consulte vectorize_loads_stores.cc.
A transmissão analisa os índices nas operações tensor.extract e tensor.insert. Se eles forem produzidos por xla_gpu.apply_indexing, que acessa os elementos de forma contígua em relação a %vector_index, e o acesso estiver alinhado, tensor.extract será convertido em vector.transfer_read e extraído do loop.
Neste caso específico, há um mapa de indexação (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) usado para calcular elementos a serem extraídos e inseridos em um loop scf.for de 0 a 4.
Portanto, tensor.extract e tensor.insert podem ser vetorizados.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Desenrolamento de loop
Consulte optimize_loops.cc.
O desenrolamento de loop encontra loops scf.for que podem ser desenrolados. Nesse caso, o
loop nos elementos do vetor desaparece.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Conversão para LLVM
Usamos principalmente as reduções padrão do LLVM, mas há algumas transmissões especiais.
Não podemos usar as reduções de memref para tensores porque não armazenamos em buffer a
IR e nossa ABI não é compatível com a ABI de memref. Em vez disso, temos uma redução personalizada diretamente de tensores para LLVM.
- A redução de tensores é feita em lower_tensors.cc.
tensor.extracté reduzido parallvm.load,tensor.insertparallvm.store, da maneira óbvia. - propagate_slice_indices e merge_pointers_to_same_slice implementam juntos um detalhe da atribuição de buffer e da ABI do XLA: se dois tensores compartilham a mesma fatia de buffer, eles são transmitidos apenas uma vez. Essas transmissões eliminam a duplicação dos argumentos da função.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Transpor emissor
Vamos analisar um exemplo um pouco mais complexo.
![]()
O gerador de transposição difere do gerador de loop apenas na forma como a função de entrada é gerada.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
Nesse caso, geramos duas operações xla_gpu.loop. O primeiro realiza leituras coalescidas da entrada e grava o resultado na memória compartilhada.
O tensor de memória compartilhada é criado usando a operação xla_gpu.allocate_shared.
Depois que as linhas de execução são sincronizadas usando xla_gpu.sync_threads, o segundo
xla_gpu.loop lê os elementos do tensor de memória compartilhada e realiza
gravações coalescidas na saída.
Reprodutor
Para ver a IR após cada transmissão do pipeline de compilação, inicie run_hlo_module com a flag --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
em que /tmp/gelu.hlo contém
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Links para código
- Pipeline de compilação: emitter_base.h
- Passagens de otimização e conversão: backends/gpu/codegen/emitters/transforms
- Lógica de partição: computation_partitioner.h
- Emissores baseados em heróis: backends/gpu/codegen/emitters
- Operações de XLA:GPU: xla_gpu_ops.td
- Testes de correção e lit: backends/gpu/codegen/emitters/tests