
Существует три способа генерации кода для HLO в XLA:GPU.
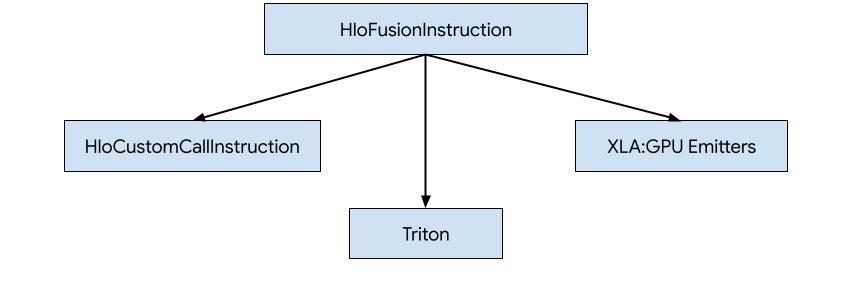
- Замена HLO на пользовательские вызовы внешних библиотек, например , NVidia cuBLAS , cuDNN .
- Создание тайлов HLO на уровне блоков, а затем использование OpenAI Triton .
- Использование излучателей XLA для постепенного снижения ИК-излучения HLO до LLVM.
Данный документ посвящен излучателям XLA:GPU.
Генерация кода на основе героев
В XLA:GPU существует 7 типов эмиттеров. Каждый тип эмиттера соответствует «герою» слияния, то есть наиболее важной операции в объединенных вычислениях, которая определяет генерацию кода для всего процесса слияния.
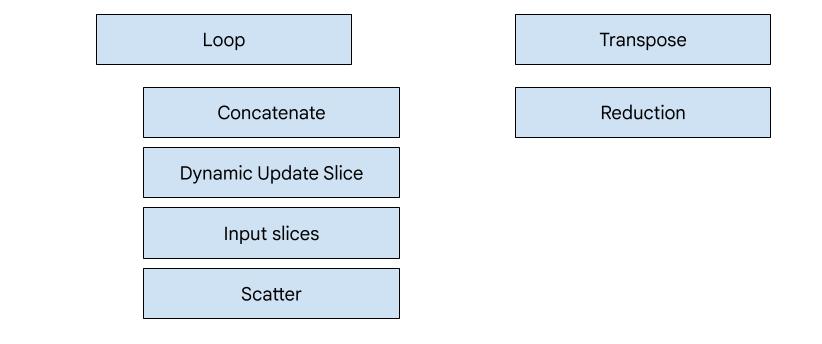
Например, генератор транспонирования будет выбран, если в процессе слияния присутствует инструкция HloTransposeInstruction , требующая использования общей памяти для улучшения шаблонов чтения и записи в память. Генератор редукции генерирует редукции с использованием перемешивания и общей памяти. Генератор цикла является генератором по умолчанию. Если в процессе слияния нет героя, для которого у нас есть специальный генератор, то будет использоваться генератор цикла.
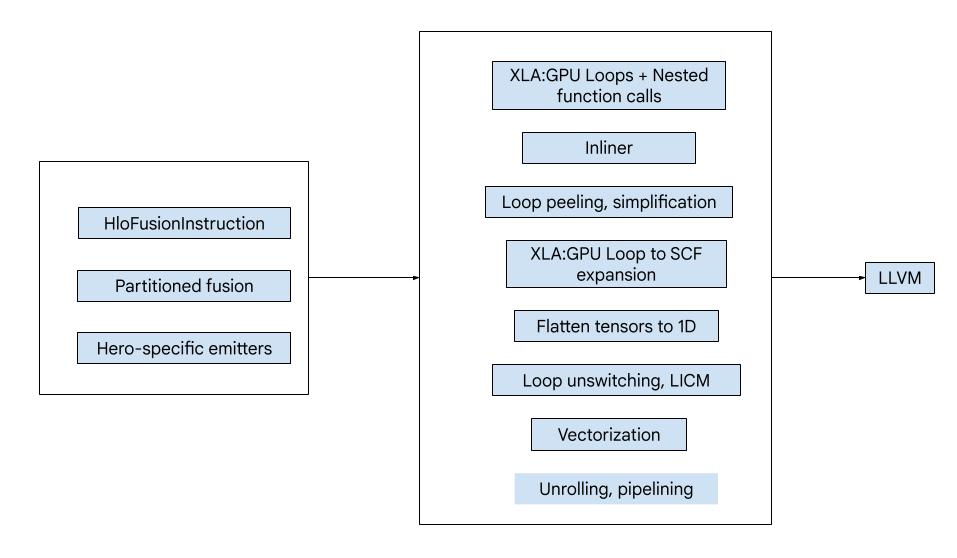
Общий обзор
Код состоит из следующих основных строительных блоков:
- Разделитель вычислений — разбиение вычислений слияния HLO на функции.
- Излучатели — преобразование разделенного слияния HLO в MLIR (диалекты
xla_gpu,tensor,arith,math,scf) - Конвейер компиляции — оптимизирует и снижает IR до LLVM.
Разделение
См. computation_partitioner.h .
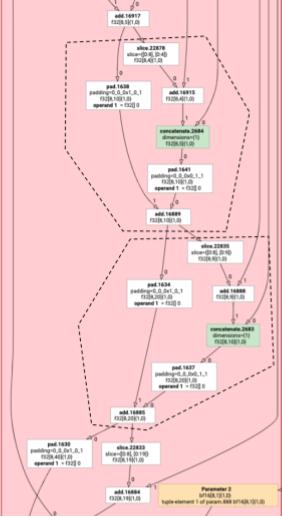
Непоэлементные инструкции HLO не всегда могут быть сгенерированы одновременно. Рассмотрим следующий граф HLO:
param
|
log
| \
| transpose
| /
add
Если мы выпустим это в одной функции, доступ к log будет осуществляться по двум разным индексам для каждого элемента add . Старые генераторы решают эту проблему, генерируя log дважды. Для этого конкретного графа это не проблема, но при наличии нескольких разбиений размер кода растет экспоненциально.
Здесь мы решаем эту задачу, разбивая граф на части, которые можно безопасно передать в виде одной функции. Критерии следующие:
- Инструкции, имеющие только одного пользователя, можно безопасно выпускать вместе с этим пользователем.
- Инструкции, используемые несколькими пользователями, можно безопасно генерировать вместе с этими пользователями, если все пользователи обращаются к ним через одни и те же индексы.
В приведенном выше примере операции add и tranpose обращаются к разным индексам log , поэтому небезопасно выводить его одновременно с ними.
Таким образом, граф разбивается на три функции (каждая из которых содержит всего одну инструкцию).
То же самое применимо и к следующему примеру с использованием slice и pad add .
Элементарные выбросы
См. elemental_hlo_to_mlir.h .
Выполнение эмиссии элементов создает циклы и математические/арифметические операции для HloInstructions . В основном это довольно просто, но здесь происходят некоторые интересные вещи.
Преобразования индексирования
Некоторые инструкции ( transpose , broadcast , reshape , slice , reverse и некоторые другие) представляют собой чисто преобразования индексов: чтобы получить элемент результата, нам нужно получить какой-либо другой элемент входных данных. Для этого мы можем повторно использовать функцию indexing_analysis из XLA, которая содержит функции для создания отображения выходных данных на входные для инструкции.
Например, при transpose из [20,40] в [40,20] будет получена следующая карта индексации (одно символическое выражение для каждого входного измерения; d0 и d1 — выходные измерения):
(d0, d1) -> d1
(d0, d1) -> d0
Таким образом, для этих инструкций преобразования, основанных исключительно на индексах, мы можем просто получить карту, применить ее к выходным индексам и получить входные данные по результирующему индексу.
Аналогично, операция pad использует карты индексации и ограничения для большей части реализации. pad также является преобразованием индексации с некоторыми дополнительными проверками, чтобы определить, возвращаем ли мы элемент входных данных или значение отступа.
Кортежи
Мы не поддерживаем внутренние tuple . Мы также не поддерживаем вложенные кортежи в выходных данных. Все графы XLA, использующие эти функции, могут быть преобразованы в графы, которые их не используют.
Собирать
Мы поддерживаем только канонические сборки, созданные функцией gather_simplifier .
Функции подграфа
Для подграфа вычисления с параметрами %p0 до %p_n и корнями подграфа с r измерениями и типами элементов ( e0 до e_m ) мы используем следующую сигнатуру функции MLIR:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
То есть, на каждый параметр вычисления приходится один тензорный вход, на каждое измерение выходных данных — один индексный вход, и на каждый результат — один выходной сигнал.
Для генерации функции мы просто используем описанный выше элементарный эмиттер и рекурсивно генерируем её операнды, пока не достигнем края подграфа. Затем мы: генерируем tensor.extract для получения параметров или генерируем func.call для других подграфов.
Функция ввода
Каждый тип эмиттера отличается способом генерации входной функции, например, функции для героя. Входная функция отличается от функций, описанных выше, поскольку она не принимает на вход индексы (только идентификаторы потока и блока) и фактически должна куда-то записывать выходные данные. Для эмиттера цикла это довольно просто, но для эмиттеров транспонирования и редукции логика записи нетривиальна.
Подпись вычисляемого значения выглядит следующим образом:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Как и прежде, %pn — это параметры вычисления, а %rn — результаты вычисления. Вводное вычисление принимает результаты в виде тензоров, tensor.insert вносит в них обновления, а затем возвращает их. Никакое другое использование выходных тензоров не допускается.
Конвейер компиляции
Излучатель петли
См. loop.h.
Давайте рассмотрим наиболее важные этапы конвейера компиляции MLIR, используя HLO для функции GELU.
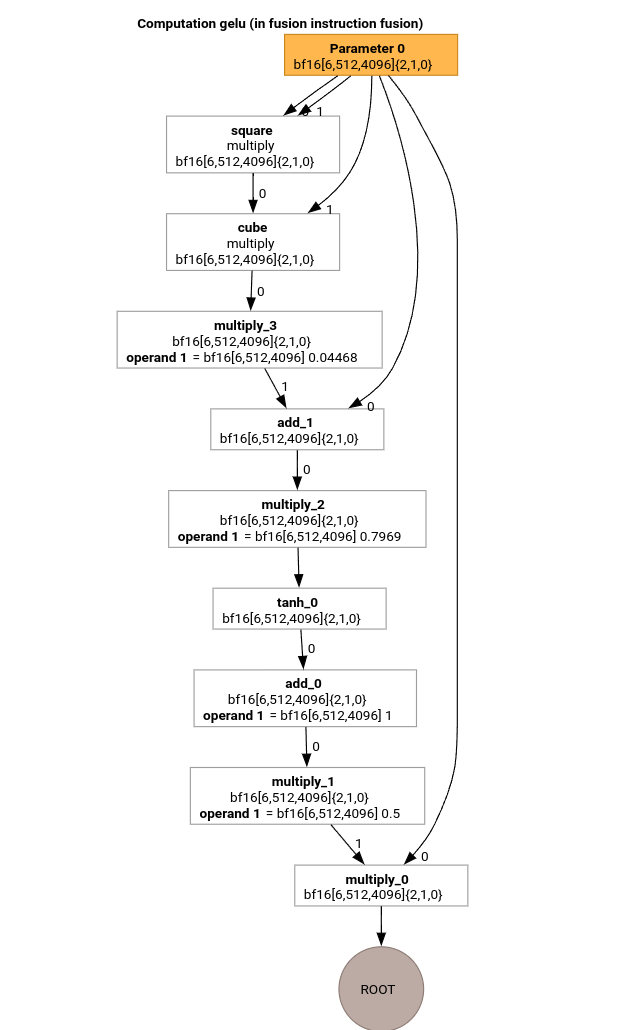
В этом вычислении HLO используются только поэлементные операции, константы и широковещательные сообщения. Оно будет отправлено с помощью генератора циклов.
Преобразование MLIR
После преобразования в MLIR мы получаем файл xla_gpu.loop , который зависит от %thread_id_x и %block_id_x и определяет цикл, который линейно проходит по всем элементам выходных данных, чтобы гарантировать совместную запись.
На каждой итерации этого цикла мы вызываем
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
для вычисления элементов корневой операции. Обратите внимание, что у нас есть только одна выделенная функция для @gelu , поскольку разделитель не обнаружил тензор, имеющий 2 или более различных шаблонов доступа.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Вкладыш
После встраивания @gelu мы получаем единственную функцию @main . Может случиться так, что одна и та же функция будет вызываться два или более раз. В этом случае мы не встраиваем её. Более подробную информацию о правилах встраивания можно найти в файле xla_gpu_dialect.cc .
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
преобразование xla_gpu в scf
См. lower_xla_gpu_to_scf.cc .
xla_gpu.loop представляет собой вложенный цикл с проверкой границ внутри. Если переменные, определяющие цикл, выходят за пределы области индексации, то эта итерация пропускается. Это означает, что цикл преобразуется в одну или несколько вложенных операций scf.for с операцией scf.if внутри.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Сглаживание тензоров
См. flatten_tensors.cc .
Тензоры Nd проецируются на одномерное пространство. Это упростит векторизацию и преобразование в LLVM, поскольку теперь каждый доступ к тензору соответствует тому, как данные выровнены в памяти.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Векторизация
См. vectorize_loads_stores.cc .
В ходе обработки анализируются индексы в операциях tensor.extract и tensor.insert , и если они получены с помощью xla_gpu.apply_indexing , которая обращается к элементам последовательно относительно %vector_index , и доступ выровнен, то tensor.extract преобразуется в vector.transfer_read и выносится из цикла.
В данном конкретном случае используется индексная карта (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) для вычисления элементов, которые необходимо извлечь и вставить в цикле scf.for от 0 до 4. Следовательно, как tensor.extract , так и tensor.insert могут быть векторизованы.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Развертывание цикла
См. optimize_loops.cc .
Функция развертывания цикла находит циклы scf.for , которые можно развернуть. В этом случае цикл по элементам вектора исчезает.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Преобразование в LLVM
В основном мы используем стандартные преобразования LLVM, но есть несколько специальных проходов. Мы не можем использовать преобразования memref для тензоров, поскольку мы не буферизуем IR, и наш ABI несовместим с ABI memref . Вместо этого мы используем собственное преобразование непосредственно из тензоров в LLVM .
- Преобразование тензоров в целевую функцию выполняется в файле lower_tensors.cc .
tensor.extractпреобразуется вllvm.load,tensor.insertвllvm.store, очевидным образом. - Функции propagate_slice_indices и merge_pointers_to_same_slice совместно реализуют деталь назначения буфера и ABI XLA: если два тензора используют один и тот же срез буфера, они передаются только один раз. Эти передачи позволяют удалить дубликаты аргументов функции.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Транспонированный эмиттер
Рассмотрим немного более сложный пример.
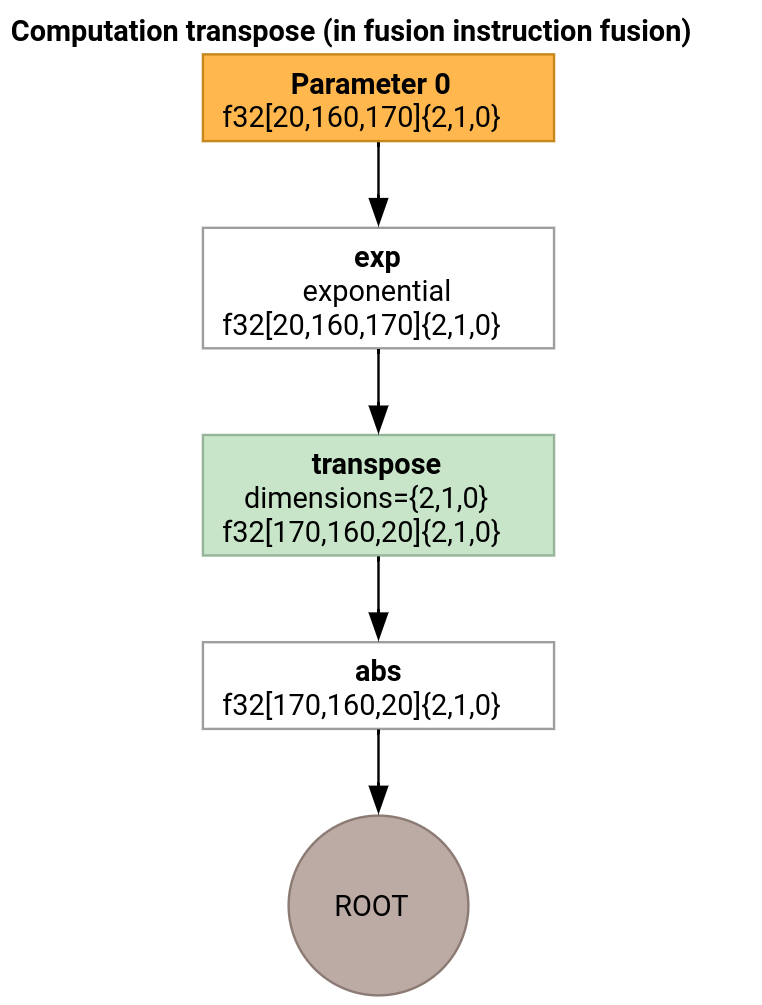
Эмулятор транспонирования отличается от эмулятора цикла только способом генерации входной функции.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
В этом случае мы генерируем две операции xla_gpu.loop . Первая выполняет объединенное чтение из входных данных и записывает результат в разделяемую память.
Тензор общей памяти создается с помощью операции xla_gpu.allocate_shared .
После синхронизации потоков с помощью xla_gpu.sync_threads , второй xla_gpu.loop считывает элементы из тензора в общей памяти и выполняет объединенную запись в выходной поток.
Воспроизводитель
Чтобы увидеть промежуточный результат после каждого прохода конвейера компиляции, можно запустить run_hlo_module с флагом --xla_dump_emitter_re=mlir-fusion .
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
где /tmp/gelu.hlo содержит
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Ссылки на код
- Конвейер компиляции: emitter_base.h
- Проходы оптимизации и преобразования: бэкенды/gpu/codegen/emitters/transforms
- Логика разделения: computation_partitioner.h
- Генераторы кода на основе Hero: бэкенды/GPU/генерация кода/эмиттеры
- XLA:GPU ops: xla_gpu_ops.td
- Корректность и тесты на наличие ошибок: бэкенды/GPU/генерация кода/излучатели/тесты