
Có 3 cách để tạo mã cho HLO trong XLA:GPU.
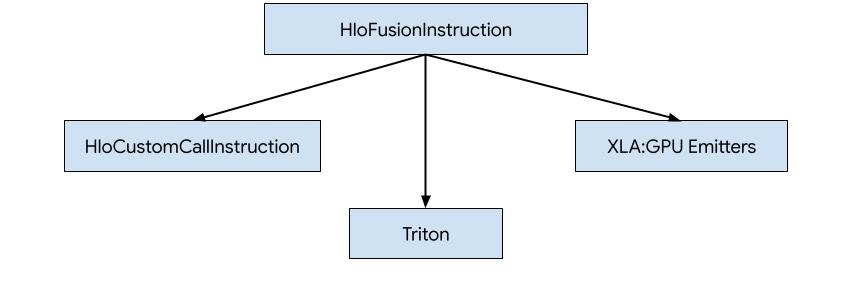
- Thay thế HLO bằng các lệnh gọi tuỳ chỉnh đến các thư viện bên ngoài, chẳng hạn như NVidia cuBLAS, cuDNN.
- Phân chia HLO thành các cấp độ khối rồi sử dụng OpenAI Triton.
- Sử dụng XLA Emitters để giảm dần HLO xuống LLVM IR.
Tài liệu này tập trung vào XLA:GPU Emitters.
Codegen dựa trên thành phần Hero
Có 7 loại nguồn phát trong XLA:GPU. Mỗi loại trình phát tương ứng với một "hero" (anh hùng) của hoạt động kết hợp, tức là thao tác quan trọng nhất trong phép tính kết hợp định hình quá trình tạo mã cho toàn bộ hoạt động kết hợp.
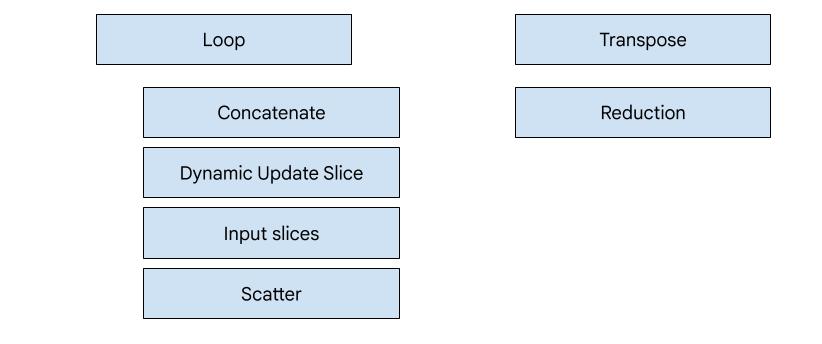
Ví dụ: bộ phát chuyển vị sẽ được chọn nếu có HloTransposeInstruction trong hoạt động hợp nhất yêu cầu sử dụng bộ nhớ dùng chung để cải thiện các mẫu đọc và ghi bộ nhớ. Trình phát giảm tạo ra các mức giảm bằng cách sử dụng các lần xáo trộn và bộ nhớ dùng chung. Nguồn phát vòng lặp là nguồn phát mặc định. Nếu một hiệu ứng kết hợp không có nhân vật chính mà chúng tôi có bộ phát đặc biệt, thì bộ phát lặp lại sẽ được sử dụng.
Thông tin tổng quan
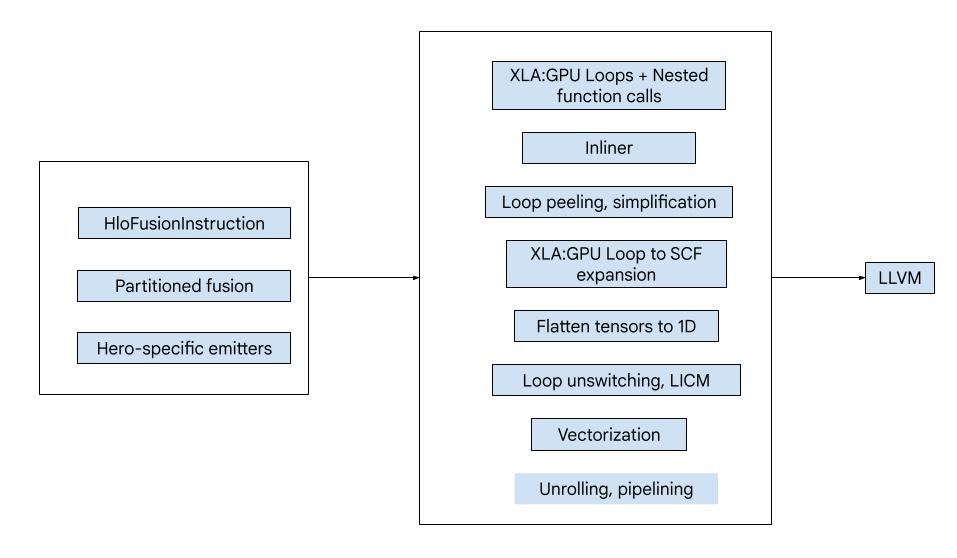
Mã này bao gồm các khối lớn sau:
- Bộ phân vùng tính toán – chia một phép tính hợp nhất HLO thành các hàm
- Trình phát – chuyển đổi hợp nhất HLO được phân vùng thành MLIR (
xla_gpu,tensor,arith,math,scfphương ngữ) - Quy trình biên dịch – tối ưu hoá và giảm IR xuống LLVM
Phân vùng
Xem computation_partitioner.h.
Các chỉ dẫn HLO không theo phần tử không phải lúc nào cũng có thể được phát cùng nhau. Hãy xem xét biểu đồ HLO sau:
param
|
log
| \
| transpose
| /
add
Nếu chúng ta phát ra điều này trong một hàm duy nhất, thì log sẽ được truy cập tại hai chỉ mục khác nhau cho từng phần tử của add. Các nguồn phát cũ giải quyết vấn đề này bằng cách tạo log hai lần. Đối với biểu đồ cụ thể này, đây không phải là vấn đề, nhưng khi có nhiều phần tách, kích thước mã sẽ tăng theo cấp số nhân.
Ở đây, chúng ta giải quyết vấn đề này bằng cách phân vùng biểu đồ thành các phần có thể được phát an toàn dưới dạng một hàm. Các tiêu chí này là:
- Các chỉ dẫn chỉ có một người dùng thì có thể phát cùng với người dùng đó.
- Các chỉ dẫn có nhiều người dùng có thể được phát cùng với người dùng nếu tất cả người dùng truy cập vào các chỉ dẫn đó thông qua cùng một chỉ mục.
Trong ví dụ trên, add và tranpose truy cập vào các chỉ mục khác nhau của log, nên không an toàn khi phát cùng với chúng.
Do đó, biểu đồ được phân vùng thành 3 hàm (mỗi hàm chỉ chứa một chỉ dẫn).
Điều tương tự cũng áp dụng cho ví dụ sau đây với slice và pad của add.
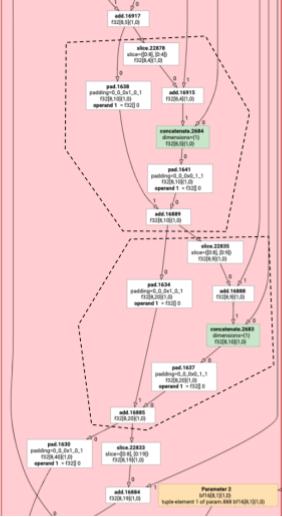
Độ phát xạ của phần tử
Việc phát ra phần tử sẽ tạo ra các vòng lặp và thao tác toán học/số học cho HloInstructions. Nhìn chung, việc này khá đơn giản, nhưng có một số điều thú vị đang diễn ra ở đây.
Biến đổi chỉ mục
Một số chỉ dẫn (transpose, broadcast, reshape, slice, reverse và một số chỉ dẫn khác) chỉ là các phép biến đổi trên chỉ mục: để tạo ra một phần tử của kết quả, chúng ta cần tạo ra một số phần tử khác của đầu vào. Để làm việc này, chúng ta có thể dùng lại indexing_analysis của XLA. Thư viện này có các hàm tạo ra ánh xạ đầu ra sang đầu vào cho một chỉ dẫn.
Ví dụ: đối với transpose từ [20,40] đến [40,20], thao tác này sẽ tạo ra bản đồ lập chỉ mục sau (một biểu thức affine cho mỗi phương diện đầu vào; d0 và d1 là các phương diện đầu ra):
(d0, d1) -> d1
(d0, d1) -> d0
Vì vậy, đối với những chỉ dẫn biến đổi chỉ mục thuần tuý này, chúng ta chỉ cần lấy bản đồ, áp dụng bản đồ đó cho các chỉ mục đầu ra và tạo dữ liệu đầu vào tại chỉ mục kết quả.
Tương tự, thao tác pad sử dụng các điều kiện ràng buộc và bản đồ lập chỉ mục cho hầu hết quá trình triển khai. pad cũng là một phép biến đổi lập chỉ mục với một số lượt kiểm tra bổ sung để xem chúng ta có trả về một phần tử của giá trị đầu vào hay giá trị đệm hay không.
Bộ giá trị
Chúng tôi không hỗ trợ tuple nội bộ. Chúng tôi cũng không hỗ trợ các đầu ra bộ dữ liệu lồng nhau. Tất cả các biểu đồ XLA sử dụng những tính năng này đều có thể được chuyển đổi thành các biểu đồ không sử dụng.
Gather
Chúng tôi chỉ hỗ trợ các lệnh gọi tập hợp chuẩn do gather_simplifier tạo ra.
Hàm đồ thị con
Đối với một đồ thị con của phép tính có các tham số từ %p0 đến %p_n và các gốc đồ thị con có r phương diện và loại phần tử (e0 đến e_m), chúng ta sử dụng chữ ký hàm MLIR sau:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Tức là chúng ta có một đầu vào tensor cho mỗi tham số tính toán, một đầu vào chỉ mục cho mỗi phương diện của đầu ra và một kết quả cho mỗi đầu ra.
Để phát một hàm, chúng ta chỉ cần sử dụng trình phát cơ bản ở trên và phát các toán hạng của hàm đó một cách đệ quy cho đến khi đạt đến cạnh của đồ thị con. Sau đó, chúng ta phát ra một tensor.extract cho các tham số hoặc phát ra một func.call cho các đồ thị con khác
Hàm nhập
Mỗi loại nguồn phát sẽ khác nhau về cách tạo hàm nhập, tức là hàm cho nhân vật chính. Hàm nhập khác với các hàm ở trên, vì hàm này không có chỉ mục làm dữ liệu đầu vào (chỉ có mã nhận dạng luồng và khối) và thực sự cần ghi đầu ra ở đâu đó. Đối với trình phát vòng lặp, điều này khá đơn giản, nhưng trình phát chuyển vị và trình phát giảm có logic ghi không tầm thường.
Chữ ký của quá trình tính toán mục nhập là:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Trong đó, %pn là các tham số của phép tính và %rn là kết quả của phép tính. Quá trình tính toán mục nhập sẽ lấy kết quả làm tensor, tensor.insert cập nhật vào các tensor đó rồi trả về.
Bạn không được phép sử dụng các tensor đầu ra cho mục đích nào khác.
Quy trình biên dịch
Nguồn phát vòng lặp
Xem loop.h.
Hãy nghiên cứu các lượt truyền quan trọng nhất của quy trình biên dịch MLIR bằng cách sử dụng HLO cho hàm GELU.
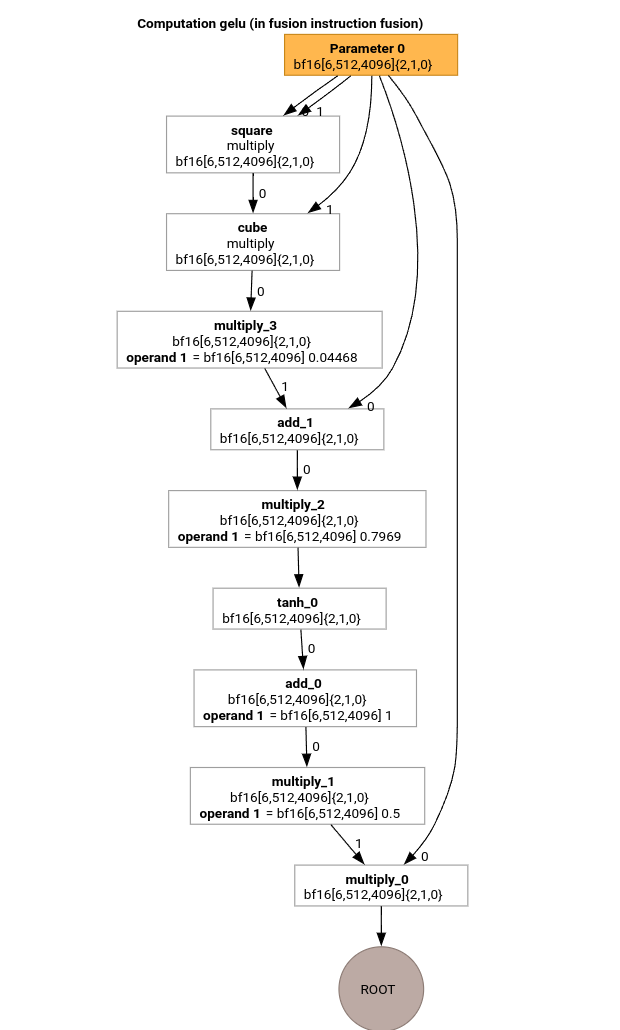
Phép tính HLO này chỉ có các thao tác theo phần tử, hằng số và hoạt động truyền tin. Sự kiện này sẽ được phát bằng trình phát vòng lặp.
Chuyển đổi MLIR
Sau khi chuyển đổi sang MLIR, chúng ta sẽ nhận được một xla_gpu.loop phụ thuộc vào %thread_id_x và %block_id_x, đồng thời xác định vòng lặp duyệt qua tất cả các phần tử của đầu ra theo cách tuyến tính để đảm bảo các thao tác ghi được kết hợp.
Trong mỗi lần lặp lại của vòng lặp này, chúng ta sẽ gọi
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
để tính toán các phần tử của thao tác gốc. Xin lưu ý rằng chúng ta chỉ có một hàm được phác thảo cho @gelu, vì trình phân vùng không phát hiện thấy một tensor có 2 hoặc nhiều mẫu truy cập khác nhau.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Sau khi @gelu được nội tuyến, chúng ta sẽ có một hàm @main duy nhất. Có thể xảy ra trường hợp cùng một hàm được gọi hai lần trở lên. Trong trường hợp này, chúng ta không nội tuyến. Bạn có thể xem thêm thông tin chi tiết về các quy tắc nội tuyến trong xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu đến scf lượt chuyển đổi
xla_gpu.loop biểu thị một vòng lặp lồng nhau có kiểm tra ranh giới bên trong. Nếu các biến cảm ứng vòng lặp nằm ngoài phạm vi miền của bản đồ lập chỉ mục, thì vòng lặp này sẽ bị bỏ qua. Điều này có nghĩa là vòng lặp được chuyển đổi thành 1 hoặc nhiều thao tác scf.for lồng nhau với một scf.if bên trong.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Làm phẳng tensor
Xem flatten_tensors.cc.
Các tensor N chiều được chiếu lên 1 chiều. Điều này sẽ đơn giản hoá quá trình vectơ hoá và giảm xuống LLVM vì mọi hoạt động truy cập vào tensor hiện đều tương ứng với cách dữ liệu được căn chỉnh trong bộ nhớ.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vector hoá
Xem vectorize_loads_stores.cc.
Lượt truyền này phân tích các chỉ mục trong các thao tác tensor.extract và tensor.insert, đồng thời nếu các chỉ mục này được tạo bởi xla_gpu.apply_indexing truy cập vào các phần tử liên tục liên quan đến %vector_index và quyền truy cập được căn chỉnh, thì tensor.extract sẽ được chuyển đổi thành vector.transfer_read và được nâng lên khỏi vòng lặp.
Trong trường hợp cụ thể này, có một bản đồ lập chỉ mục (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) được dùng để tính toán các phần tử cần trích xuất và chèn trong một vòng lặp scf.for từ 0 đến 4.
Do đó, cả tensor.extract và tensor.insert đều có thể được vectơ hoá.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Mở vòng lặp
Hãy xem optimize_loops.cc.
Quá trình mở vòng lặp sẽ tìm thấy các vòng lặp scf.for có thể được mở. Trong trường hợp này, vòng lặp trên các phần tử của vectơ sẽ biến mất.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Chuyển đổi sang LLVM
Chúng tôi chủ yếu sử dụng các quy trình hạ cấp LLVM tiêu chuẩn, nhưng có một số quy trình đặc biệt.
Chúng ta không thể sử dụng các thao tác hạ cấp memref cho các tensor, vì chúng ta không đệm IR và ABI của chúng ta không tương thích với ABI memref. Thay vào đó, chúng ta có một quy trình hạ cấp tuỳ chỉnh trực tiếp từ các tensor xuống LLVM.
- Việc giảm số lượng tensor được thực hiện trong lower_tensors.cc.
tensor.extractgiảm xuốngllvm.load,tensor.insertxuốngllvm.storetheo cách rõ ràng. - propagate_slice_indices và merge_pointers_to_same_slice cùng nhau triển khai chi tiết về việc chỉ định vùng đệm và ABI của XLA: nếu hai tensor dùng chung cùng một lát vùng đệm, thì chúng chỉ được truyền một lần. Các lượt truyền này loại bỏ các đối số hàm trùng lặp.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Nguồn phát sóng chuyển vị
Hãy xem xét một ví dụ phức tạp hơn một chút.
![]()
Trình phát chuyển vị chỉ khác trình phát vòng lặp ở cách tạo hàm nhập.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
Trong trường hợp này, chúng ta sẽ tạo 2 thao tác xla_gpu.loop. Thao tác đầu tiên thực hiện các lượt đọc kết hợp từ đầu vào và ghi kết quả vào bộ nhớ dùng chung.
Tensor bộ nhớ dùng chung được tạo bằng cách sử dụng thao tác xla_gpu.allocate_shared.
Sau khi các luồng được đồng bộ hoá bằng xla_gpu.sync_threads, xla_gpu.loop thứ hai sẽ đọc các phần tử từ tensor bộ nhớ dùng chung và thực hiện các thao tác ghi kết hợp vào đầu ra.
Reproducer
Để xem IR sau mỗi lần truyền qua quy trình biên dịch, bạn có thể khởi chạy run_hlo_module bằng cờ --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
trong đó /tmp/gelu.hlo chứa
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Đường liên kết đến mã
- Quy trình biên dịch: emitter_base.h
- Các lượt tối ưu hoá và chuyển đổi: backends/gpu/codegen/emitters/transforms
- Logic phân vùng: computation_partitioner.h
- Nguồn phát dựa trên thành phần chính: backends/gpu/codegen/emitters
- XLA:GPU ops: xla_gpu_ops.td
- Tính chính xác và các kiểm thử lit: backends/gpu/codegen/emitters/tests