
在 XLA:GPU 中,產生 HLO 程式碼的方式有三種。
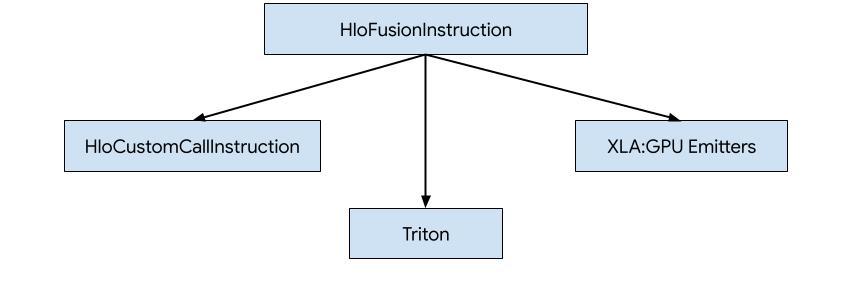
- 以對外部程式庫的自訂呼叫取代 HLO,例如 NVidia cuBLAS、cuDNN。
- 將 HLO 鋪砌至區塊層級,然後使用 OpenAI Triton。
- 使用 XLA Emitter 逐步將 HLO 降低至 LLVM IR。
本文著重於 XLA:GPU 發射器。
以 Hero 為基礎的程式碼產生
XLA:GPU 中有 7 種發射器類型。每個發射器類型都對應至融合的「主角」,也就是融合運算中最重要的一項作業,會影響整個融合的程式碼產生作業。
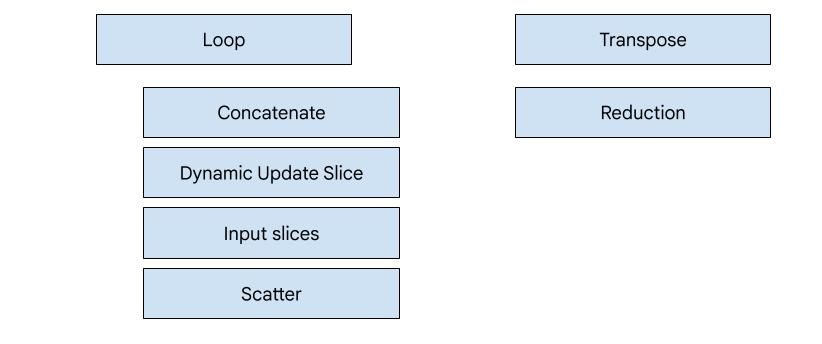
舉例來說,如果融合中需要使用共用記憶體來改善記憶體讀取和寫入模式,系統就會選取轉置發射器。HloTransposeInstruction縮減發射器會使用隨機重組和共用記憶體產生縮減。迴圈發射器是預設的發射器。如果融合沒有我們有特殊發射器的英雄,則會使用迴圈發射器。
高階總覽
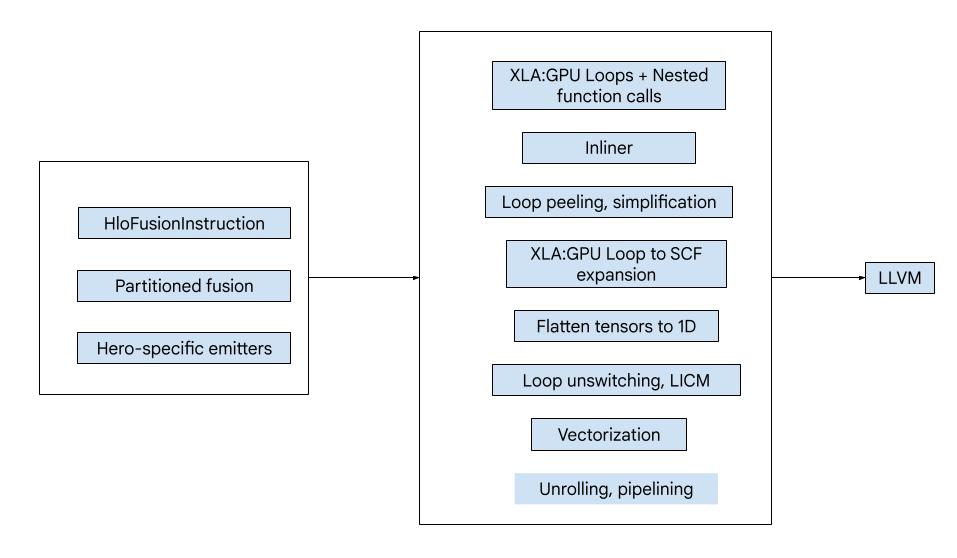
程式碼包含下列大型建構區塊:
- 運算分割器:將 HLO 融合運算分割成函式
- 發射器 - 將分割的 HLO 融合轉換為 MLIR (
xla_gpu、tensor、arith、math、scf方言) - 編譯管線 - 最佳化並將 IR 降至 LLVM
分區
請參閱 computation_partitioner.h。
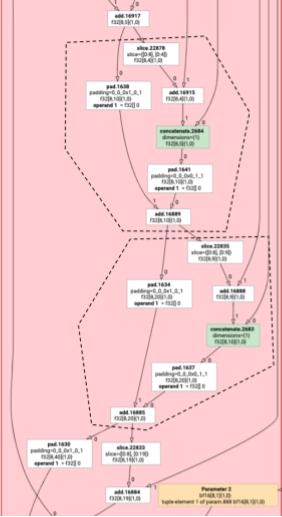
非元素 HLO 指令不一定能一起發出。請考慮下列 HLO 圖表:
param
|
log
| \
| transpose
| /
add
如果我們在單一函式中發出這項資訊,系統會針對 add 的每個元素,在兩個不同的索引存取 log。舊版發射器會產生兩次 log,解決這個問題。就這個特定圖表而言,這不是問題,但如果有多個分割區,程式碼大小就會呈指數成長。
在這裡,我們會將圖表分割成多個部分,這些部分可安全地以一個函式發出,藉此解決這個問題。評估資格的標準如下:
- 只有一位使用者的指令可以安全地與使用者一起發出。
- 如果多位使用者透過相同索引存取指令,則可安全地一併發出指令。
在上述範例中,add 和 tranpose 存取 log 的不同索引,因此一併發出並不安全。
因此,圖表會分割成三個函式 (每個函式只包含一項指令)。
這同樣適用於下列範例,其中 slice 和 pad 為 add。
元素發射
請參閱「elemental_hlo_to_mlir.h」。
元素發射會為 HloInstructions 建立迴圈和數學/算術運算。在大多數情況下,這很簡單,但這裡有一些有趣的事情。
建立索引轉換
部分指令 (transpose、broadcast、reshape、slice、reverse 和其他幾個指令) 純粹是索引轉換:如要產生結果的元素,我們需要產生輸入的其他元素。為此,我們可以重複使用 XLA 的 indexing_analysis,其中包含可產生指令輸出至輸入對應的函式。
舉例來說,如果是從 [20,40] 到 [20,40] 到 [40,20],系統會產生下列索引對應 (每個輸入維度各有一個仿射運算式;d0 和 d1 是輸出維度):transpose
(d0, d1) -> d1
(d0, d1) -> d0
因此,對於這些純索引轉換指令,我們只要取得對應的對映,將其套用至輸出索引,並在產生的索引中產生輸入即可。
同樣地,在大多數實作作業中,pad op 會使用索引對應和限制。pad 也是索引轉換,並新增了一些檢查項,用來判斷我們傳回的是輸入元素還是填補值。
元組
我們不支援內部 tuple。我們也不支援巢狀元組輸出。所有使用這些功能的 XLA 圖表都可以轉換為不使用這些功能的圖表。
收集
我們僅支援 gather_simplifier 產生的標準集合。
子圖函式
對於具有參數 %p0 至 %p_n 的計算子圖,以及具有 r 維度和元素型別 (e0 至 e_m) 的子圖根,我們使用下列 MLIR 函式簽章:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
也就是說,每個運算參數都有一個張量輸入、每個輸出維度都有一個索引輸入,且每個輸出都有一個結果。
如要發出函式,我們只要使用上述元素發射器,並以遞迴方式發出其運算元,直到到達子圖的邊緣為止。接著,我們會:為參數發出 tensor.extract,或為其他子圖發出 func.call
進入函式
每種發射器類型產生進入函式 (即英雄的函式) 的方式都不同。由於沒有索引做為輸入內容 (只有執行緒和區塊 ID),且實際上需要將輸出內容寫入某處,因此這個進入函式與上述函式不同。如果是迴圈發射器,這相當簡單,但轉置和縮減發射器具有非簡單的寫入邏輯。
項目計算的簽章為:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
與先前一樣,%pn 是運算參數,%rn 是運算結果。項目運算會將結果視為張量,將 tensor.insert 更新至張量,然後傳回張量。輸出張量不得用於其他用途。
編譯管道
迴圈發射器
請參閱 loop.h。
我們來研究 GELU 函式的 HLO,瞭解 MLIR 編譯管道最重要的傳遞。
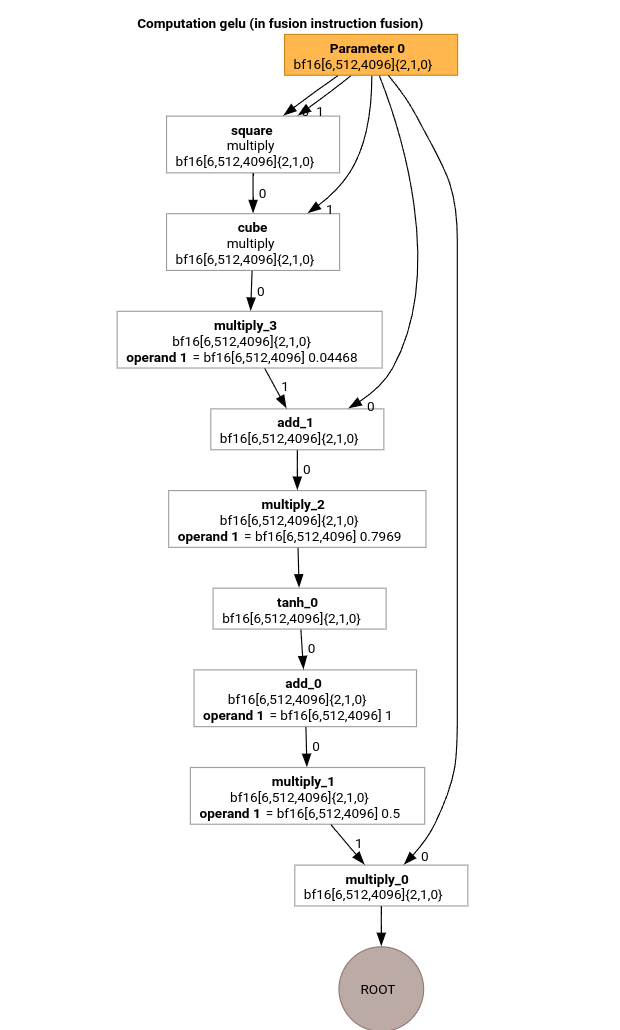
這項 HLO 計算只包含元素運算、常數和廣播。並透過迴圈發射器發射。
MLIR 轉換
轉換為 MLIR 後,我們會取得取決於 %thread_id_x 和 %block_id_x 的 xla_gpu.loop,並定義遍歷輸出內容所有元素的迴圈,以確保合併寫入。
在每次疊代這個迴圈時,我們都會呼叫
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
計算根作業的元素。請注意,我們只有一個 @gelu 的外框函式,因為分割器未偵測到具有 2 個以上不同存取模式的張量。
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
內嵌 @gelu 後,我們會取得單一 @main 函式。同一函式可能會被呼叫兩次以上。在本例中,我們不會內嵌。如要進一步瞭解內嵌規則,請參閱 xla_gpu_dialect.cc。
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu 到 scf 的轉換
xla_gpu.loop 代表迴圈巢狀結構,內含邊界檢查。如果迴路感應變數超出索引地圖網域的範圍,系統就會略過這次疊代。也就是說,迴圈會轉換為 1 個以上的巢狀 scf.for 作業,內含 scf.if。
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
壓平張量
請參閱 flatten_tensors.cc。
N 維張量會投影到 1D。這樣一來,每個張量存取作業都會對應到記憶體中的資料對齊方式,因此可簡化向量化和 LLVM 降級作業。
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
向量化
請參閱 vectorize_loads_stores.cc。
這個階段會分析 tensor.extract 和 tensor.insert 作業中的索引,如果這些索引是由 xla_gpu.apply_indexing 產生,且存取元素時相對於 %vector_index 是連續的,而且存取作業已對齊,則 tensor.extract 會轉換為 vector.transfer_read,並從迴圈中提升。
在這個特定案例中,索引對應 (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) 用於計算要擷取及插入 scf.for 迴圈 (從 0 到 4) 的元素。因此,tensor.extract 和 tensor.insert 都可以向量化。
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
迴圈展開
請參閱 optimize_loops.cc。
迴圈展開會找出可展開的 scf.for 迴圈。在本例中,向量元素上的迴圈會消失。
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
轉換為 LLVM
我們大多使用標準 LLVM 降級,但有幾個特殊傳遞。我們無法使用張量的 memref 降低,因為我們不會緩衝處理 IR,且 ABI 與 memref ABI 不相容。而是直接從張量自訂降低至 LLVM。
- 張量降低作業是在 lower_tensors.cc 中完成。
tensor.extract會降至llvm.load,tensor.insert會降至llvm.store,方式顯而易見。 - propagate_slice_indices 和 merge_pointers_to_same_slice 會一起實作緩衝區指派和 XLA ABI 的詳細資料:如果兩個張量共用相同的緩衝區切片,則只會傳遞一次。這些傳遞會重複函式引數。
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
轉置發射器
讓我們來看一個稍微複雜的例子。
![]()
轉置發射器與迴圈發射器的差異,只在於產生輸入函式的方式。
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
在本例中,我們會產生兩個 xla_gpu.loop 作業。第一個會從輸入內容執行合併讀取作業,並將結果寫入共用記憶體。
共用記憶體張量是使用 xla_gpu.allocate_shared op 建立。
使用 xla_gpu.sync_threads 同步處理執行緒後,第二個 xla_gpu.loop 會從共用記憶體張量讀取元素,並對輸出執行合併寫入作業。
重現者
如要在編譯管道的每次傳遞後查看 IR,可以啟動 run_hlo_module 並使用 --xla_dump_emitter_re=mlir-fusion 旗標。
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
其中 /tmp/gelu.hlo 包含
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
程式碼連結
- 編譯管道:emitter_base.h
- 最佳化和轉換階段:backends/gpu/codegen/emitters/transforms
- 分區邏輯:computation_partitioner.h
- 以 Hero 為基礎的發射器:backends/gpu/codegen/emitters
- XLA:GPU 運算:xla_gpu_ops.td
- 正確性和 Lit 測試:backends/gpu/codegen/emitters/tests