
A análise de indexação de HLO é uma análise de fluxo de dados que descreve como os elementos de um tensor se relacionam com outro por "mapas de indexação". Por exemplo, como os índices de uma saída de instrução HLO são mapeados para os índices de operandos de instrução HLO.
Exemplo
Para uma transmissão de tensor<20xf32> a tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
O mapa de indexação da saída para a entrada é (i, j, k) -> (j) para i in
[0, 10], j in [0, 20] e k in [0, 30].
Motivação
O XLA usa várias soluções personalizadas para analisar a fusão, a utilização de operandos e os esquemas de mosaicos (mais detalhes abaixo). O objetivo da análise de indexação é fornecer um componente reutilizável para esses casos de uso. A análise de indexação é criada na infraestrutura de mapa afim do MLIR e adiciona semântica HLO.
Agrupamento
O raciocínio sobre a coalescência de memória se torna viável para casos não triviais quando sabemos quais elementos/slices das entradas são lidos para calcular um elemento da saída.
Utilização de operandos
A utilização do operando em XLA indica o quanto cada entrada da instrução é usada, supondo que a saída seja totalmente usada. No momento, a utilização também não é calculada para um caso genérico. Com a análise de indexação, podemos calcular a utilização com precisão.
Divisão
Um bloco/slice é um subconjunto hiperretangular de um tensor parametrizado por deslocamentos, tamanhos e strides. A propagação de blocos é uma maneira de calcular os parâmetros de bloco do produtor/consumidor da operação usando os parâmetros de bloco da própria operação. Já existe uma biblioteca que faz isso para softmax e ponto. A propagação de blocos pode ser mais genérica e robusta se for expressa por mapas de indexação.
Mapa de indexação
Um mapa de indexação é uma combinação de
- uma função expressa simbolicamente que mapeia cada elemento de um tensor
Apara intervalos de elementos no tensorB; - restrições em argumentos de função válidos, incluindo o domínio da função.
Os argumentos de função são divididos em três categorias para comunicar melhor a natureza deles:
Variáveis de dimensão do tensor
Aou uma grade de GPU de que estamos fazendo o mapeamento. Os valores são conhecidos de forma estática. Os elementos de índice também são chamados de variáveis de dimensão.Variáveis de intervalo. Eles definem um mapeamento de um para muitos e especificam um conjunto de elementos em
Busados para calcular um único valor deA. Os valores são conhecidos estaticamente. A dimensão de contração de uma multiplicação de matrizes é um exemplo de variável de intervalo.variáveis de tempo de execução que só são conhecidas durante a execução. Por exemplo, o argumento "indices" da operação gather.
O resultado da função é um índice do tensor B de destino.
Em resumo, uma função de indexação do tensor A para o tensor B na operação x é
map_ab(index in A, range variables, runtime variables) -> index in B.
Para separar melhor os tipos de argumentos de mapeamento, escrevemos:
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Por exemplo, vamos analisar os mapas de indexação da operação de redução f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3}:
Para mapear elementos de
inparaout, nossa função pode ser expressa como(d0, d1, d2, d3) -> (d1, d2). As restrições das variáveisd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]são definidas pela forma dein.Para mapear elementos de
outparain:outtem apenas duas dimensões, e a redução introduz duas variáveis de intervalo que abrangem a redução de dimensões. Assim, a função de mapeamento é(d0, d1)[s0, s1] -> (s0, d0, d1, s1), em que(d0, d1)é o índice deout.s0es1são intervalos definidos pela semântica da operação e abrangem as dimensões 0 e 3 do tensorin. As restrições sãod0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
É importante observar que, na maioria dos cenários, queremos fazer o mapeamento dos elementos da saída. Para computação
C = op1(A, B)
E = op2(C, D)
Podemos falar sobre "indexação de B", que significa "mapeamento de elementos de E para os elementos de B". Isso pode ser contraditório em comparação com outros tipos de análise de fluxo de dados que funcionam da entrada para as saídas.
Restrições em variáveis permitem oportunidades de otimização e ajudam na geração de código. Na documentação, as restrições de implementação também são chamadas de domínio, já que definem todas as combinações válidas ou valores de argumento da função de mapeamento. Para muitas operações, as restrições descrevem apenas as dimensões dos tensores, mas para algumas operações elas podem ser mais complicadas. Veja exemplos abaixo.
Ao ter funções e restrições de argumentos expressas simbolicamente e poder combinar funções e restrições, é possível calcular um mapeamento de indexação compacto para uma computação grande arbitrária (fusão).
A expressividade da função simbólica e das restrições é um equilíbrio entre a complexidade da implementação e os ganhos de otimização que obtemos ao ter uma representação mais precisa. Para algumas operações de HLO, capturamos padrões de acesso apenas de forma aproximada.
Implementação
Como queremos minimizar o recálculo, precisamos de uma biblioteca para computações simbólicas. O XLA já depende do MLIR. Por isso, usamos mlir::AffineMap em vez de escrever outra biblioteca de aritmética simbólica.
Um AffineMap típico tem esta aparência:
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap tem dois tipos de parâmetros: dimensões e símbolos.
As dimensões correspondem às variáveis de dimensão d. Os símbolos correspondem às variáveis de intervalo r e de tempo de execução rt. O AffineMap não contém metadados sobre restrições dos parâmetros, então precisamos fornecê-los separadamente.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ codificam as restrições de caixa inclusivas para as variáveis de dimensão d do mapa de indexação, que geralmente coincidem com o formato do tensor de saída para operações como transposição, redução, elemento a elemento, ponto, mas há algumas exceções, como HloConcatenateInstruction.
range_vars_ todos os valores que as variáveis de intervalo s usam. As variáveis de intervalo são necessárias quando vários valores são necessários para calcular um único elemento do tensor de que estamos fazendo o mapeamento, por exemplo, para o mapa de indexação de saída->entrada de reduções ou o mapa de entrada->saída para transmissões.
rt_vars_ codifica os valores possíveis no tempo de execução. Por exemplo, o deslocamento é dinâmico para um HloDynamicSliceInstruction 1D. O RTVar correspondente terá valores viáveis entre 0 e tensor_size - slice_size - 1.
constraints_ captura relações entre valores no formato <expression> in <range>, por exemplo, d0 + s0 in [0, 20]. Juntos com Variable.bounds, eles definem o "domínio" da função de indexação.
Vamos estudar por exemplos para entender o que tudo isso significa.
Indexação de mapas para operações não combinadas
Elementwise
Para operações elementares, o mapa de indexação é uma identidade.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
O mapa de saída para entrada output -> p0:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
O mapa de entrada para saída p0 -> output:
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Removido
A transmissão significa que algumas das dimensões serão removidas quando mapearmos a saída para a entrada e adicionadas quando mapearmos a entrada para a saída.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
O mapa de saída para entrada:
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
O mapa de entrada para saída:
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Agora temos variáveis de intervalo s no lado direito para o mapeamento de entrada para saída. Esses são os símbolos que representam intervalos de valores.
Por exemplo, neste caso específico, cada elemento de entrada com índice d0 é mapeado para uma fração 10x1x30 da saída.
Iota
A função iota não tem um operando de tensor de entrada, então não há argumentos de índice de entrada.
iota = f32[2,4] iota(), dimensions={1}
Saída para o mapa de entrada:
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Mapa de entrada para saída:
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
O DynamicSlice tem offsets conhecidos apenas no tempo de execução.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
O mapa de saída para entrada de ds para src:
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Agora temos rt no lado direito para o mapeamento de entrada para saída.
Esses são os símbolos que representam valores de tempo de execução. Por exemplo, neste caso específico, para cada elemento da saída com índices d0, d1, d2, acessamos os deslocamentos de slice of1, of2 e of3 para calcular o índice da entrada.
Os intervalos das variáveis de tempo de execução são derivados da suposição de que toda a fatia permanece dentro dos limites.
O mapa de saída para entrada de of1, of2 e of3:
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
O mapa de saída para entrada de src é trivial. É possível aumentar a precisão restringindo o domínio aos índices não atualizados, mas no momento os mapas de indexação não aceitam restrições de desigualdade.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
O mapa de saída para entrada de upd:
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Agora temos rt0 e rt1 que representam valores de tempo de execução. Neste caso específico, para cada elemento da saída com índices d0, d1, acessamos os deslocamentos de fatia of1 e of2 para calcular o índice da entrada. Os intervalos das variáveis de tempo de execução são derivados supondo que toda a fatia permaneça dentro dos limites.
O mapa de saída para entrada de of1 e of2:
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
Somente a coleta simplificada é aceita. Consulte gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
O mapa de saída para entrada de operand:
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Agora temos símbolos rt que representam valores de tempo de execução.
O mapa de saída para entrada de indices:
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
A variável de intervalo s0 mostra que precisamos da linha inteira (d0, *) do tensor indices para calcular um elemento da saída.
Transpor
O mapa de indexação para transposição é uma permutação das dimensões de entrada/saída.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
O mapa de saída para entrada:
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
O mapa de entrada para saída:
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Inverter
Mapa de indexação para mudanças inversas que alteram as dimensões revertidas para upper_bound(d_i) -
d_i:
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
O mapa de saída para entrada:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
O mapa de entrada para saída:
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
A redução variádica tem várias entradas e vários valores iniciais. O mapa da saída para a entrada adiciona as dimensões reduzidas.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
O mapeamento de saída para entrada:
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Os mapas de entrada para saída:
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
A indexação da saída para a entrada para resultados de segmentação resulta em um mapa de indexação com incremento que é válido para todos os elementos da saída. O mapeamento da entrada para a saída é restrito a um intervalo com incremento dos elementos na entrada.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
O mapa de saída para entrada:
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
O mapa de entrada para saída:
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Redimensionar
Há diferentes tipos de redimensionamento.
Recolher forma
Essa é uma reformatação "linearizadora" de N-D para 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
O mapa de saída para entrada:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
O mapa de entrada para saída:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Expandir forma
Essa é uma operação inversa de "reduzir forma", que redimensiona uma entrada 1D em uma saída N-D.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
O mapa de saída para entrada:
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
O mapa de entrada para saída:
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Remodelagem genérica
Essas são as operações de redimensionamento que não podem ser representadas como uma única forma de expansão ou redução. Eles só podem ser representados como uma composição de dois ou mais formatos de expansão ou redução.
Exemplo 1: linearização-deslinearização.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Essa mudança de formato pode ser representada como uma composição do formato de redução de tensor<4x8xf32> para tensor<32xf32> e, em seguida, uma expansão de formato para tensor<2x4x4xf32>.
O mapa de saída para entrada:
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
O mapa de entrada para saída:
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Exemplo 2: subformas expandidas e recolhidas
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Essa mudança de formato pode ser representada como uma composição de duas mudanças de formato. O primeiro recolhe as dimensões mais externas tensor<4x8x12xf32> para tensor<32x12xf32>, e o segundo expande a dimensão mais interna tensor<32x12xf32> para tensor<32x3x4xf32>.
O mapa de saída para entrada:
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
O mapa de entrada para saída:
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
Uma operação bitcast pode ser representada como uma sequência de transposição-redimensionamento-transposição. Portanto, os mapas de indexação são apenas uma composição dos mapas de indexação dessa sequência.
Concatenate
O mapeamento de saída para entrada de concat é definido para todas as entradas, mas com domínios não sobrepostos. Ou seja, apenas uma das entradas será usada por vez.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
O mapeamento de saída para entrada:
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
As entradas para os mapas de saída:
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Ponto
Os mapas de indexação para ponto são muito semelhantes aos de redução.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
O mapeamento de saída para entrada:
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
As entradas para os mapas de saída:
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
A indexação de PadOp é o inverso da indexação de SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
A configuração de padding 1_4_1x4_8_0 indica lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
O mapeamento de saída para entrada:
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
O ReduceWindow no XLA também faz padding. Portanto, os mapas de indexação podem ser calculados como uma composição da indexação ReduceWindow que não faz padding e da indexação do PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
O mapeamento de saída para entrada:
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Indexação de mapas para o Fusion
O mapa de indexação para a operação de fusão é uma composição de mapas de indexação para cada operação no cluster. Algumas entradas podem ser lidas várias vezes com padrões de acesso diferentes.
Uma entrada, vários mapas de indexação
Confira um exemplo para p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Os mapeamentos de indexação de saída para entrada de p0 serão (d0, d1) -> (d0, d1) e (d0, d1) -> (d1, d0). Isso significa que, para calcular um elemento da saída, talvez seja necessário ler o parâmetro de entrada duas vezes.
Um mapa de indexação de entrada e remoção de duplicidade
![]()
Há casos em que os mapas de indexação são os mesmos, mesmo que isso não seja óbvio.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
Nesse caso, o mapa de indexação de saída para entrada de p0 é apenas (d0, d1, d2) -> (d2, d0, d1).
Softmax
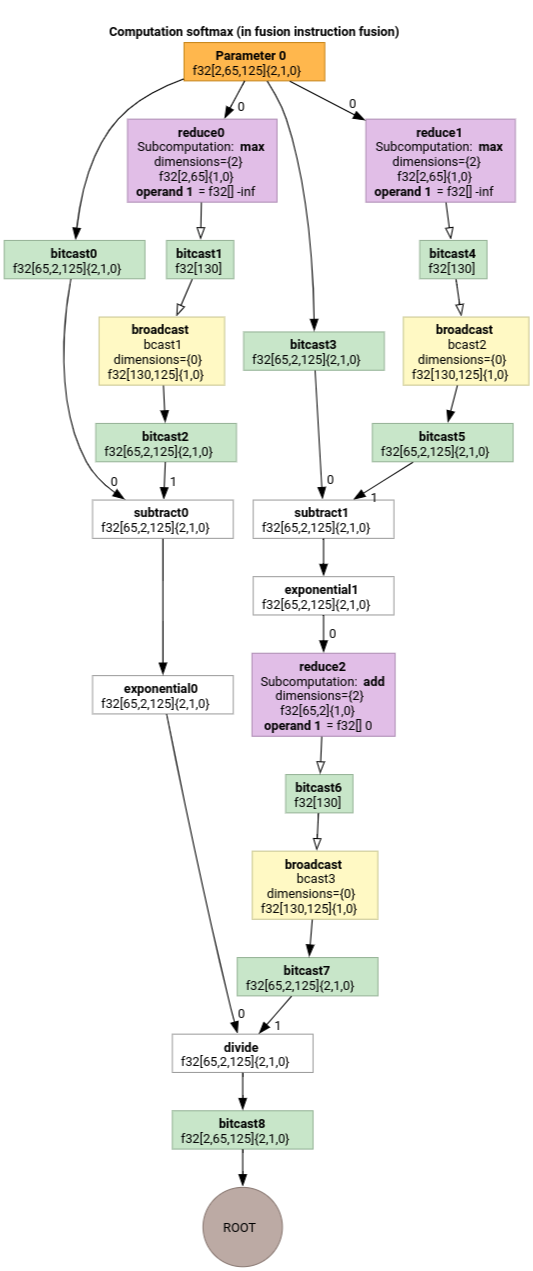
Os mapeamentos de indexação de saída para entrada de parameter 0 para softmax:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
e
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
em que s0 se refere à dimensão mais interna da entrada.
Para mais exemplos, consulte indexing_analysis_test.cc.
Simplificador de mapa de indexação
O simplificador padrão para mlir::AffineMap upstream não pode fazer nenhuma
suposição sobre os intervalos de dimensões/símbolos. Portanto, não é possível simplificar expressões com mod e div de maneira eficiente.
Podemos aproveitar o conhecimento sobre os limites inferior e superior das subexpressões nos mapas afins para simplificá-los ainda mais.
O simplificador pode reescrever as seguintes expressões.
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)para d em[0, 6] x [0, 14]passa a ser(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)paradi in [0, 9]passa a ser(d0, d1, d2) -> (d0, d1, d2).(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)parad_i in [0, 9]passa a ser(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8).(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)para d em[0, 9] x [0, 10]se torna(d0, d1) -> (d0).
O simplificador de mapa de indexação permite entender que algumas das mudanças de formato encadeadas em HLO se cancelam.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
Depois da composição e simplificação dos mapas de indexação, vamos receber
(d0, d1, d2) -> (d0, d1, d2).
A simplificação do mapa de indexação também simplifica as restrições.
- Restrições do tipo
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundsão reescritas comoupdated_lower_bound <= affine_expr <= updated_upped_bound. - Restrições sempre satisfeitas, por exemplo,
d0 + s0 in [0, 20]parad0 in [0, 5]es0 in [1, 3], são eliminadas. - As expressões afins nas restrições são otimizadas como o mapa afim de indexação acima.
Para mais exemplos, consulte indexing_map_test.cc.