
هناك ثلاث طرق لإنشاء رمز HLO في XLA:GPU.
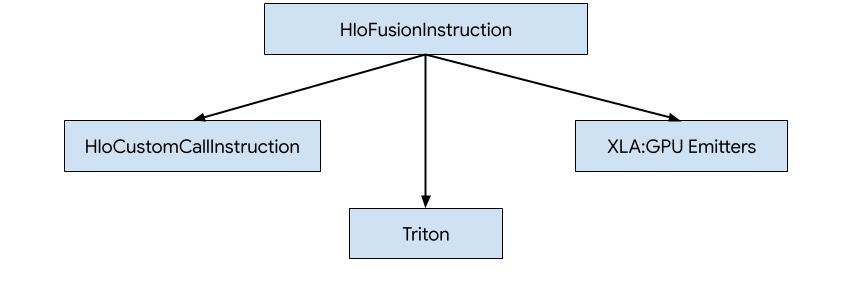
- استبدال HLO بمكالمات مخصّصة إلى مكتبات خارجية، مثل NVidia cuBLAS وcuDNN
- تقسيم HLO إلى أجزاء على مستوى الحظر ثم استخدام OpenAI Triton
- استخدام XLA Emitters لخفض HLO تدريجيًا إلى LLVM IR
يركّز هذا المستند على XLA:GPU Emitters.
إنشاء الرموز البرمجية استنادًا إلى الأبطال
هناك 7 أنواع من المصادر في XLA:GPU. يتوافق كل نوع من أنواع المصدر مع "بطل" عملية الدمج، أي العملية الأكثر أهمية في الحساب المدمج الذي يحدّد شكل إنشاء الرمز البرمجي لعملية الدمج بأكملها.
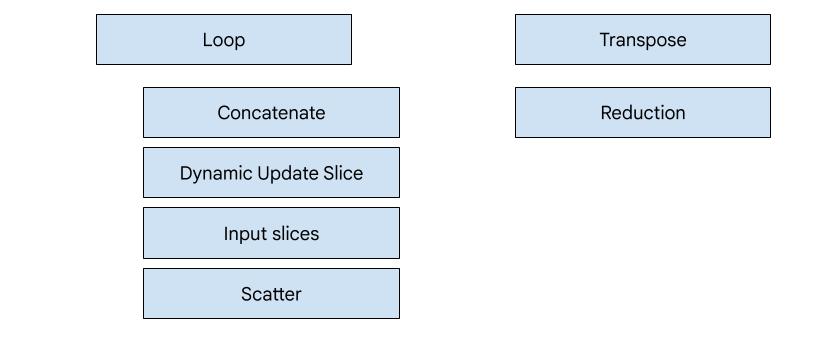
على سبيل المثال، سيتم اختيار أداة إخراج النقل إذا كان هناك
HloTransposeInstruction ضمن الدمج يتطلّب استخدام الذاكرة المشتركة
لتحسين أنماط القراءة والكتابة في الذاكرة. ينشئ مصدر الحدّ عمليات تقليل باستخدام عمليات تبديل عشوائي وذاكرة مشترَكة. جهاز الإرسال الحلقي هو جهاز الإرسال التلقائي. إذا لم يكن لعملية الدمج بطل يتوفّر له مصدر انبعاث خاص، سيتم استخدام مصدر الانبعاث المتكرّر.
نظرة عامة
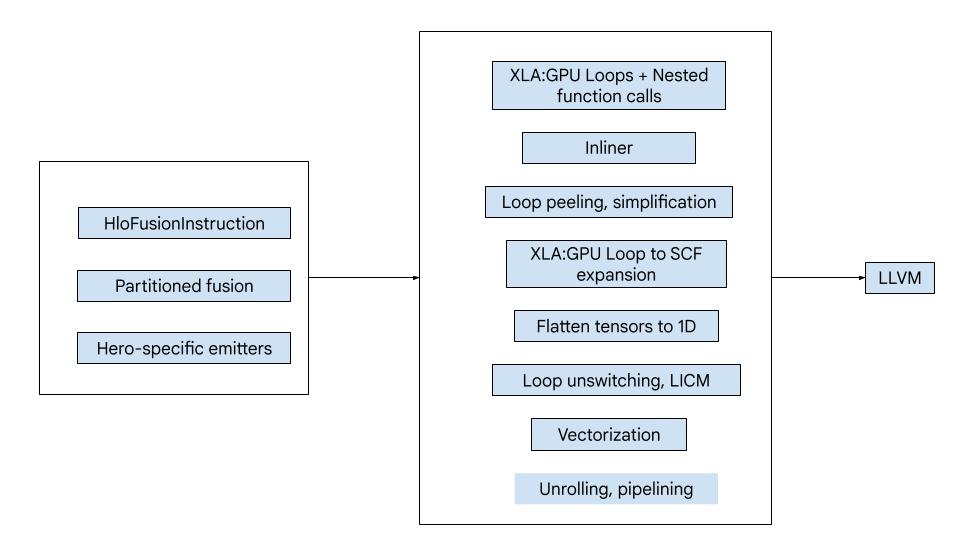
يتألف الرمز من الكتل البرمجية الإنشائية الكبيرة التالية:
- أداة تقسيم العمليات الحسابية - تقسيم عملية دمج HLO إلى دوال
- المصدّرات: تحويل دمج HLO المقسَّم إلى MLIR (
xla_gpuوtensorوarithوmathوscf) - مسار التجميع - تحسين IR وتقليله إلى LLVM
التقسيم
راجِع computation_partitioner.h.
لا يمكن دائمًا إصدار تعليمات HLO غير العنصرية معًا. ضَع في اعتبارك الرسم البياني التالي الخاص بالعمليات عالية المستوى:
param
|
log
| \
| transpose
| /
add
إذا أرسلنا هذا في دالة واحدة، سيتم الوصول إلى log في فهرسين مختلفين لكل عنصر من عناصر add. وتحلّ أجهزة الإرسال القديمة هذه المشكلة من خلال إنشاء log مرتين. في هذا الرسم البياني تحديدًا، لا يشكّل ذلك مشكلة، ولكن عند توفّر عمليات تقسيم متعددة، يزداد حجم الرمز البرمجي بشكل كبير.
نحلّ هذه المشكلة من خلال تقسيم الرسم البياني إلى أجزاء يمكن عرضها بأمان كدالة واحدة. وفي ما يلي المعايير اللازمة لذلك:
- يمكن عرض التعليمات التي تضم مستخدمًا واحدًا فقط مع المستخدم.
- يمكن إرسال التعليمات التي تضم عدة مستخدمين مع مستخدميها إذا تم الوصول إليها من خلال الفهارس نفسها من قِبل جميع المستخدمين.
في المثال أعلاه، يصل add وtranpose إلى فهارس مختلفة من log، لذا ليس من الآمن إرسالها معًا.
وبالتالي، يتم تقسيم الرسم البياني إلى ثلاث دوال (تحتوي كل منها على تعليمات واحدة فقط).
ينطبق الأمر نفسه على المثال التالي الذي يتضمّن slice وpad من add.
الانبعاثات الأولية
راجِع elemental_hlo_to_mlir.h.
تنشئ عملية إطلاق العناصر حلقات وعمليات رياضية/حسابية لـ HloInstructions. في معظم الحالات، يكون هذا الإجراء بسيطًا، ولكن هناك بعض التفاصيل المهمة التي يجب معرفتها.
عمليات تحويل الفهرسة
بعض التعليمات (transpose وbroadcast وreshape وslice وreverse وبعض التعليمات الأخرى) هي عمليات تحويل خالصة على الفهارس: لإنتاج عنصر من النتيجة، علينا إنتاج عنصر آخر من الإدخال. يمكننا لهذا الغرض إعادة استخدام indexing_analysis في XLA، التي تتضمّن دوال لإنشاء ربط بين الناتج والمدخلات لأحد التعليمات.
على سبيل المثال، بالنسبة إلى transpose من [20,40] إلى [40,20]، سيتم إنشاء خريطة الفهرسة التالية (تعبير تقاربي واحد لكل سمة إدخال، حيث d0 وd1 هما سمتان الإخراج):
(d0, d1) -> d1
(d0, d1) -> d0
بالنسبة إلى تعليمات تحويل الفهرس البحت هذه، يمكننا ببساطة الحصول على الخريطة، وتطبيقها على فهارس الإخراج، وإنتاج الإدخال في الفهرس الناتج.
وبالمثل، تستخدم العملية pad خرائط الفهرسة والقيود في معظم عمليات التنفيذ. pad هي أيضًا عملية تحويل للفهرسة مع بعض عمليات التحقّق الإضافية
لمعرفة ما إذا كنا سنعرض عنصرًا من الإدخال أو قيمة الحشو.
صفوف
لا نسمح باستخدام tuple داخلية. ولا نتيح أيضًا إخراجات الصفوف المتداخلة. يمكن تحويل جميع الرسوم البيانية في XLA التي تستخدم هذه الميزات إلى رسوم بيانية لا تستخدمها.
جمع
لا نسمح إلا بعمليات الجمع الأساسية التي تنتجها gather_simplifier.
دوال الرسومات البيانية الفرعية
بالنسبة إلى رسم بياني فرعي لعملية حسابية تتضمّن المَعلمات %p0 إلى %p_n، وجذور الرسم البياني الفرعي التي تتضمّن r سمة وأنواع عناصر (e0 إلى e_m)، نستخدم توقيع دالة MLIR التالي:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
أي أنّ لدينا موتر إدخال واحد لكل مَعلمة حساب، وموتر إدخال واحد لكل بُعد من أبعاد الناتج، ونتيجة واحدة لكل ناتج.
لإصدار دالة، نستخدم ببساطة أداة الإصدار الأساسية الموضّحة أعلاه، ونصدر بشكل متكرر المعامِلات الخاصة بها إلى أن نصل إلى حافة الرسم البياني الفرعي. بعد ذلك، نرسل tensor.extract للمعلمات أو func.call للرسومات البيانية الفرعية الأخرى
دالة نقطة الدخول
يختلف كل نوع من أنواع المصادر في طريقة إنشاء دالة الإدخال، أي الدالة الخاصة بالبطل. تختلف دالة الإدخال عن الدوال المذكورة أعلاه، لأنّها لا تتضمّن فهارس كمدخلات (فقط معرّفات سلسلة المحادثات والكتل)، ويجب أن تكتب المخرجات في مكان ما. بالنسبة إلى أداة إنشاء الحلقات، يكون ذلك بسيطًا إلى حد ما، ولكن أدوات إنشاء النقل والاختزال تتضمّن منطق كتابة غير بسيط.
توقيع عملية احتساب الإدخال هو:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
كما في السابق، تمثّل %pn معاملات الحساب، وتمثّل %rn نتائج الحساب. تأخذ عملية حساب الإدخال النتائج على شكل موترات، وتُجري تحديثات tensor.insert عليها، ثم تعرضها.
ولا يُسمح بأي استخدامات أخرى لموترات الإخراج.
مسار التحويل البرمجي
مُطلِق الجسَيمات المتكرّر
راجِع loop.h.
لنستعرض أهم مراحل مسار تجميع MLIR باستخدام HLO لدالة GELU.
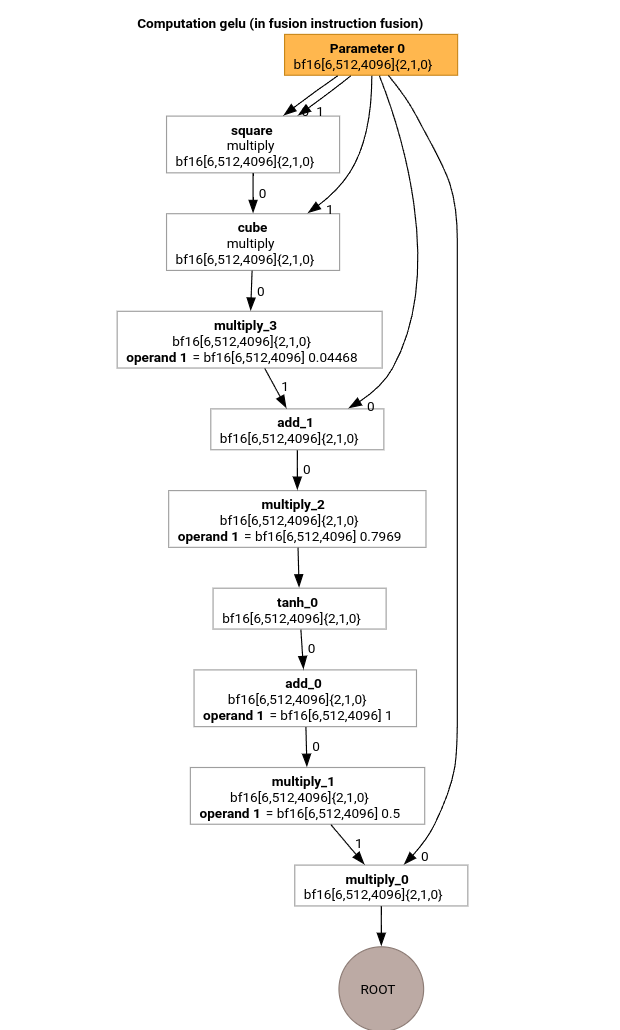
لا يحتوي احتساب HLO هذا إلا على عمليات على مستوى العناصر والثوابت وعمليات البث. سيتم إرسالها باستخدام أداة إرسال الحلقات.
MLIR Conversion
بعد التحويل إلى MLIR، نحصل على xla_gpu.loop يعتمد على %thread_id_x و%block_id_x ويحدّد الحلقة التي تتنقّل بين جميع عناصر الناتج بشكل خطي لضمان عمليات الكتابة المدمجة.
في كل تكرار لهذه الحلقة، نستدعي
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
لحساب عناصر العملية الجذرية يُرجى العِلم أنّه لدينا دالة واحدة فقط محدّدة المعالم لـ @gelu، لأنّ أداة التقسيم لم ترصد موترًا يتضمّن نمطَي وصول مختلفَين أو أكثر.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
بعد تضمين @gelu، نحصل على دالة @main واحدة. قد يحدث أن يتم استدعاء الدالة نفسها مرتين أو أكثر. في هذه الحالة، لا نضمّنها. يمكنك الاطّلاع على مزيد من التفاصيل حول قواعد التضمين في xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
التحويل من xla_gpu إلى scf
راجِع lower_xla_gpu_to_scf.cc.
يمثّل xla_gpu.loop مجموعة من الحلقات المتداخلة مع عملية التحقّق من الحدود في الداخل. إذا كانت متغيرات الحث في الحلقة خارج حدود نطاق خريطة الفهرسة، يتم تخطّي هذه التكرار. وهذا يعني أنّه يتم تحويل الحلقة إلى عملية واحدة أو أكثر من عمليات scf.for المتداخلة مع عملية scf.if في الداخل.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
تسوية المتجهات المتعددة الأبعاد
راجِع flatten_tensors.cc.
يتم عرض موترات N-d على بُعد واحد. سيؤدي ذلك إلى تبسيط عملية تحويل البيانات إلى متجهات وعملية التحويل إلى LLVM، لأنّ كل عملية وصول إلى موتر تتوافق الآن مع طريقة محاذاة البيانات في الذاكرة.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
المتّجهات
راجِع vectorize_loads_stores.cc.
تحلّل عملية التحسين هذه الفهارس في العمليتَين tensor.extract وtensor.insert، وإذا كانت العملية xla_gpu.apply_indexing تنتجها وتصل إلى العناصر بشكل متجاور بالنسبة إلى %vector_index وكان الوصول متوافقًا، يتم تحويل tensor.extract إلى vector.transfer_read ونقلها خارج الحلقة.
في هذه الحالة تحديدًا، هناك خريطة فهرسة (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) تُستخدَم لاحتساب العناصر التي سيتم استخراجها وإدراجها في حلقة scf.for من 0 إلى 4.
لذلك، يمكن تحويل كل من tensor.extract وtensor.insert إلى متجهات.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
فكّ حلقة التكرار
راجِع optimize_loops.cc.
تعثر عملية فك الحلقات على حلقات scf.for يمكن فكها. في هذه الحالة، يختفي التكرار على عناصر المتّجه.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
التحويل إلى LLVM
نستخدم في الغالب عمليات التخفيض القياسية في LLVM، ولكن هناك بعض عمليات التخفيض الخاصة.
لا يمكننا استخدام عمليات التخفيض memref للموترات، لأنّنا لا نخزّن التمثيل الوسيط مؤقتًا، كما أنّ واجهة التطبيق الثنائية (ABI) غير متوافقة مع واجهة التطبيق الثنائية (ABI) الخاصة بـ memref. بدلاً من ذلك، لدينا عملية تحويل مخصّصة مباشرةً من الموترات إلى LLVM.
- يتم خفض الموترات في lower_tensors.cc. يتم خفض
tensor.extractإلىllvm.loadوtensor.insertإلىllvm.storeبالطريقة الواضحة. - تعمل علامتَا propagate_slice_indices وmerge_pointers_to_same_slice معًا لتنفيذ تفاصيل عملية تخصيص المخزن المؤقت وواجهة التطبيق الثنائية (ABI) في XLA: إذا كان موتران يشتركان في شريحة المخزن المؤقت نفسها، يتم تمريرهما مرة واحدة فقط. تزيل عمليات التمرير هذه التكرار من وسيطات الدالة.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
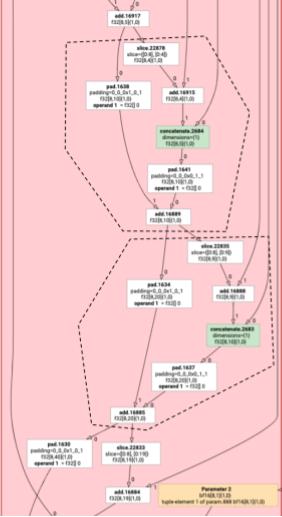
مُطلِق الجسَيمات المتبادلة
لنأخذ مثالاً أكثر تعقيدًا قليلاً.
![]()
يختلف مصدر الإرسال الخاص بعملية التبديل عن مصدر الإرسال الخاص بعملية التكرار فقط في طريقة إنشاء دالة الإدخال.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
في هذه الحالة، ننشئ عمليتَي xla_gpu.loop. تنفّذ العملية الأولى عمليات قراءة مدمجة من الإدخال وتكتب النتيجة في الذاكرة المشتركة.
يتم إنشاء موتر الذاكرة المشترَكة باستخدام عملية xla_gpu.allocate_shared.
بعد مزامنة سلاسل المحادثات باستخدام xla_gpu.sync_threads، تقرأ السلسلة الثانية
xla_gpu.loop العناصر من موتر الذاكرة المشتركة وتنفّذ عمليات كتابة مدمجة إلى الناتج.
المُنتِج
لعرض رمز IR بعد كل عملية تمرير في مسار التجميع، يمكن تشغيل run_hlo_module باستخدام العلامة --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
حيث يحتوي /tmp/gelu.hlo على
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
روابط إلى الرمز
- مسار التجميع: emitter_base.h
- عمليات التحسين والإحالة الناجحة: backends/gpu/codegen/emitters/transforms
- منطق التقسيم: computation_partitioner.h
- أدوات إنشاء الرموز البرمجية المستندة إلى Hero: backends/gpu/codegen/emitters
- XLA:GPU ops: xla_gpu_ops.td
- اختبارات الصحة والوظائف: backends/gpu/codegen/emitters/tests