
Esistono tre modi per generare codice per HLO in XLA:GPU.
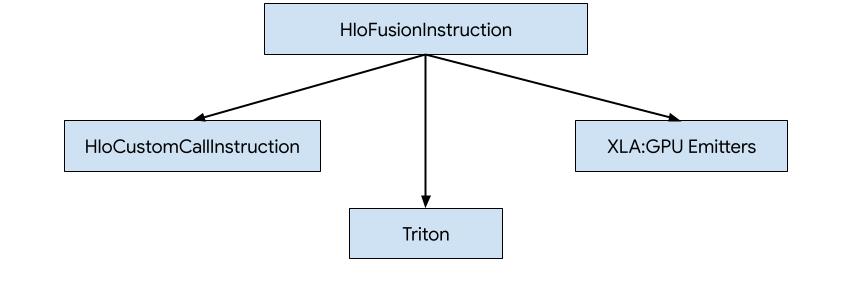
- Sostituzione di HLO con chiamate personalizzate a librerie esterne, ad esempio NVidia cuBLAS, cuDNN.
- Tiling HLO a livello di blocco e poi utilizzo di OpenAI Triton.
- Utilizzo di emettitori XLA per ridurre progressivamente HLO in LLVM IR.
Questo documento è incentrato sugli emettitori XLA:GPU.
Generazione di codice basata su hero
In XLA:GPU sono disponibili 7 tipi di emettitori. Ogni tipo di emettitore corrisponde a un "eroe" della fusione, ovvero l'operazione più importante nel calcolo combinato che modella la generazione di codice per l'intera fusione.
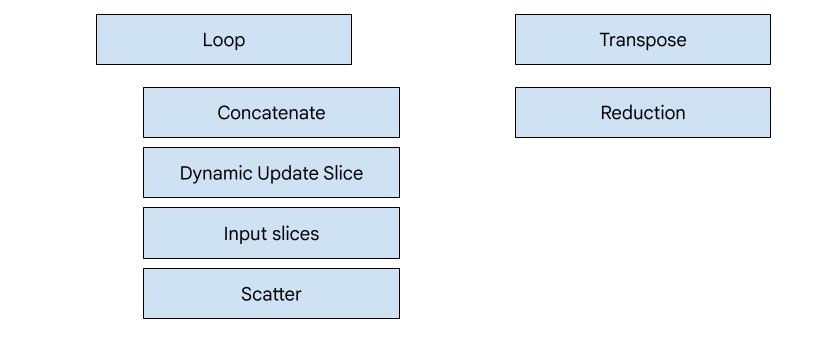
Ad esempio, l'emettitore di trasposizione verrà selezionato se è presente un
HloTransposeInstruction all'interno della fusione che richiede l'utilizzo della memoria condivisa per
migliorare i pattern di lettura e scrittura della memoria. L'emettitore di riduzioni genera
riduzioni utilizzando shuffle e memoria condivisa. L'emettitore di loop è l'emettitore
predefinito. Se una fusione non ha un eroe per il quale abbiamo un emettitore speciale,
verrà utilizzato l'emettitore di loop.
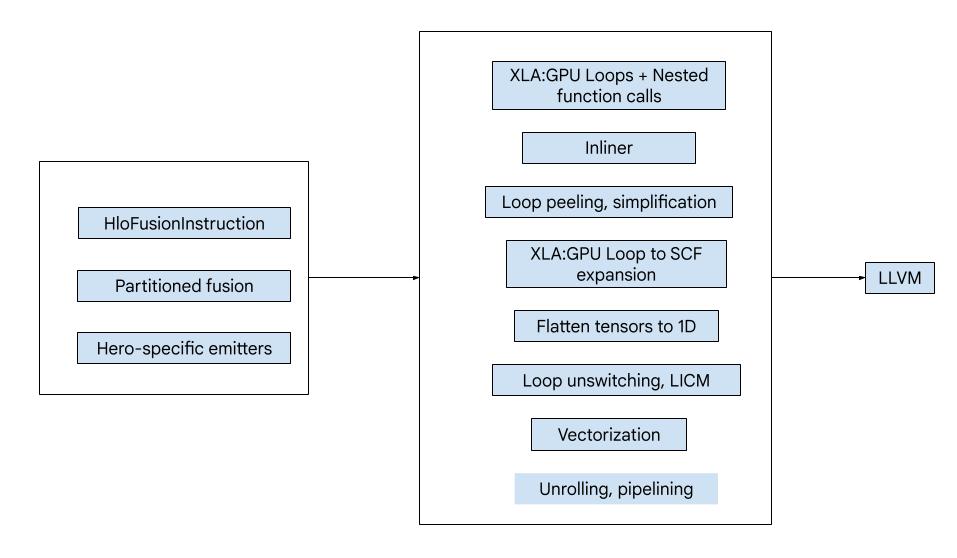
Panoramica di alto livello
Il codice è composto dai seguenti componenti di base:
- Partizionatore di calcoli: suddivisione di un calcolo di fusione HLO in funzioni
- Emittenti: conversione della fusione HLO partizionata in MLIR (dialetti
xla_gpu,tensor,arith,math,scf) - Pipeline di compilazione: ottimizza e abbassa l'IR a LLVM
Partizionamento
Consulta computation_partitioner.h.
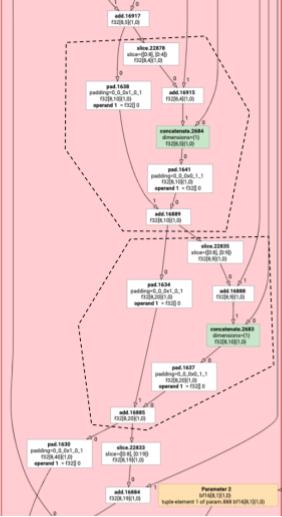
Le istruzioni HLO non elementwise non possono sempre essere emesse insieme. Considera il seguente grafico HLO:
param
|
log
| \
| transpose
| /
add
Se lo emettiamo in una singola funzione, si accederà a log in due indici diversi per ogni elemento di add. I vecchi emettitori risolvono questo
problema generando log due volte. Per questo grafico in particolare, non si tratta di un problema, ma quando ci sono più suddivisioni, le dimensioni del codice aumentano in modo esponenziale.
Qui risolviamo questo problema partizionando il grafico in parti che possono essere emesse in sicurezza come una sola funzione. I criteri sono i seguenti:
- Le istruzioni che hanno un solo utente possono essere emesse insieme al relativo utente.
- Le istruzioni con più utenti possono essere emesse insieme ai loro utenti se tutti gli utenti vi accedono tramite gli stessi indici.
Nell'esempio precedente, add e tranpose accedono a indici diversi di log, pertanto non è sicuro emetterlo insieme a questi.
Il grafico viene quindi suddiviso in tre funzioni (ognuna contenente una sola istruzione).
Lo stesso vale per il seguente esempio con slice e pad di add.
Emissione elementare
Consulta elemental_hlo_to_mlir.h.
L'emissione elementare crea loop e operazioni matematiche/aritmetiche per HloInstructions. Per
la maggior parte, è semplice, ma ci sono alcune cose interessanti
in corso.
Trasformazioni di indicizzazione
Alcune istruzioni (transpose, broadcast, reshape, slice, reverse e
altre) sono puramente trasformazioni sugli indici: per produrre un elemento del
risultato, dobbiamo produrre un altro elemento dell'input. Per questo, possiamo
riutilizzare indexing_analysis di XLA, che ha
funzioni per produrre la mappatura da output a input per un'istruzione.
Ad esempio, per un transpose da [20,40] a [40,20], verrà prodotta la
seguente mappa di indicizzazione (un'espressione affine per dimensione di input; d0 e d1 sono
le dimensioni di output):
(d0, d1) -> d1
(d0, d1) -> d0
Quindi, per queste istruzioni di trasformazione dell'indice puro, possiamo semplicemente ottenere la mappa, applicarla agli indici di output e produrre l'input all'indice risultante.
Analogamente, l'operazione pad utilizza mappe e vincoli di indicizzazione per la maggior parte dell'implementazione. pad è anche una trasformazione di indicizzazione con alcuni controlli aggiuntivi
per verificare se restituiamo un elemento dell'input o il valore di riempimento.
Tuple
Non supportiamo i tuple interni. Inoltre, non supportiamo le tuple nidificate
come output. Tutti i grafici XLA che utilizzano queste funzionalità possono essere convertiti in grafici che
non le utilizzano.
Raccogli
Supportiamo solo i recuperi canonici prodotti da gather_simplifier.
Funzioni di sottografo
Per un sottografo di un calcolo con parametri da %p0 a %p_n e radici del sottografo con dimensioni r e tipi di elementi (da e0 a e_m), utilizziamo la seguente firma della funzione MLIR:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
ovvero un tensore di input per ogni parametro di calcolo, un input di indice per ogni dimensione dell'output e un risultato per ogni output.
Per emettere una funzione, utilizziamo semplicemente l'emettitore elementare sopra e in modo ricorsivo
emettiamo i suoi operandi finché non raggiungiamo il bordo del sottografo. Poi, emettiamo un
tensor.extract per i parametri o un func.call per gli altri sottografi
Funzione di ingresso
Ogni tipo di emettitore differisce nel modo in cui genera la funzione di voce, ovvero la funzione per l'eroe. La funzione di inserimento è diversa dalle funzioni precedenti, in quanto non ha indici come input (solo gli ID thread e blocco) e deve effettivamente scrivere l'output da qualche parte. Per l'emettitore di loop, è abbastanza semplice, ma gli emettitori di trasposizione e riduzione hanno una logica di scrittura non banale.
La firma del calcolo della voce è:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Dove, come prima, i %pn sono i parametri del calcolo e i
%rn sono i risultati del calcolo. Il calcolo della voce prende i risultati come tensori, tensor.inserts li aggiorna e poi li restituisce.
Non sono consentiti altri utilizzi dei tensori di output.
Pipeline di compilazione
Emettitore loop
Vedi loop.h.
Studiamo i passaggi più importanti della pipeline di compilazione MLIR utilizzando HLO per la funzione GELU.
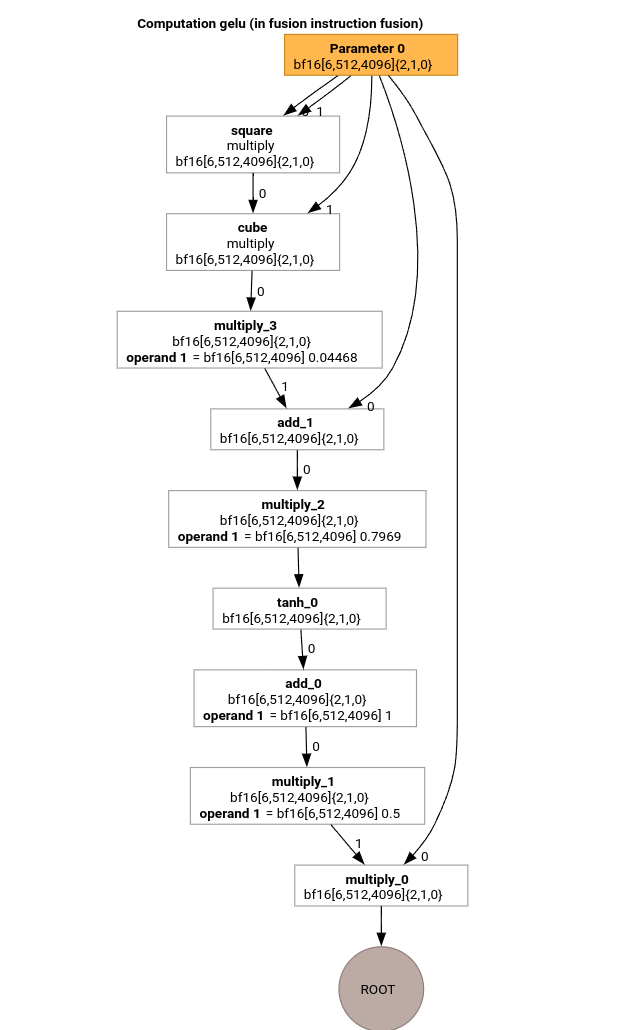
Questo calcolo HLO include solo operazioni elementwise, costanti e trasmissioni. Verrà emesso utilizzando l'emettitore di loop.
Conversione MLIR
Dopo la conversione in MLIR, otteniamo un xla_gpu.loop che dipende da
%thread_id_x e %block_id_x e definisce il ciclo che attraversa tutti
gli elementi dell'output in modo lineare per garantire scritture unite.
A ogni iterazione di questo ciclo chiamiamo
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
per calcolare gli elementi dell'operazione principale. Tieni presente che abbiamo una sola funzione
strutturata per @gelu, perché il partizionatore non ha rilevato un tensore con due o più pattern di accesso diversi.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
Dopo l'incorporamento di @gelu, otteniamo una singola funzione @main. Può capitare che
la stessa funzione venga chiamata due o più volte. In questo caso non eseguiamo l'incorporamento. Per ulteriori dettagli sulle regole di inlining, consulta xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu alla conversione scf
Vedi lower_xla_gpu_to_scf.cc.
xla_gpu.loop rappresenta un'istruzione di ciclo nidificata con un controllo dei limiti all'interno. Se le variabili di induzione del ciclo non rientrano nei limiti del dominio della mappa di indicizzazione, questa iterazione viene ignorata. Ciò significa che il ciclo viene convertito in una o più operazioni scf.for nidificate con un'operazione scf.if all'interno.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Appiattisci i tensori
Vedi flatten_tensors.cc.
I tensori N-D vengono proiettati su 1D. In questo modo, la vettorizzazione e l'abbassamento a LLVM vengono semplificati perché ogni accesso al tensore ora corrisponde al modo in cui i dati sono allineati in memoria.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vettorizzazione
Vedi vectorize_loads_stores.cc.
La passata analizza gli indici nelle operazioni tensor.extract e tensor.insert
e se sono prodotti da xla_gpu.apply_indexing che accede agli elementi
in modo contiguo rispetto a %vector_index e l'accesso è allineato, allora
tensor.extract viene convertito in vector.transfer_read e spostato fuori dal
ciclo.
In questo caso specifico, esiste una mappa di indicizzazione
(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) utilizzata per
calcolare gli elementi da estrarre e inserire in un ciclo scf.for da 0 a 4.
Pertanto, sia tensor.extract che tensor.insert possono essere vettorializzati.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Srotolamento del loop
Vedi optimize_loops.cc.
Lo srotolamento del ciclo trova i cicli scf.for che possono essere srotolati. In questo caso, il
ciclo sugli elementi del vettore scompare.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
Conversione in LLVM
Utilizziamo principalmente le riduzioni LLVM standard, ma esistono alcuni passaggi speciali.
Non possiamo utilizzare le riduzioni memref per i tensori, poiché non bufferizziamo
l'IR e la nostra ABI non è compatibile con l'ABI memref. Abbiamo invece una
riduzione personalizzata direttamente dai tensori a LLVM.
- L'abbassamento dei tensori viene eseguito in lower_tensors.cc.
tensor.extractviene ridotto allvm.load,tensor.insertallvm.store, in modo ovvio. - propagate_slice_indices e merge_pointers_to_same_slice insieme implementano un dettaglio dell'assegnazione del buffer e dell'ABI di XLA: se due tensori condividono la stessa sezione del buffer, vengono passati una sola volta. Questi passaggi deduplicano gli argomenti della funzione.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Trasponi emettitore
Vediamo un esempio leggermente più complesso.
![]()
L'emettitore di trasposizione differisce dall'emettitore di loop solo per il modo in cui viene generata la funzione di inserimento.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
In questo caso, generiamo due operazioni xla_gpu.loop. Il primo esegue
letture unite dall'input e scrive il risultato nella memoria condivisa.
Il tensore della memoria condivisa viene creato utilizzando l'operazione xla_gpu.allocate_shared.
Dopo la sincronizzazione dei thread utilizzando xla_gpu.sync_threads, il secondo
xla_gpu.loop legge gli elementi dal tensore della memoria condivisa ed esegue
scritture unite nell'output.
Reproducer
Per visualizzare l'IR dopo ogni passaggio della pipeline di compilazione, puoi
avviare run_hlo_module con il flag --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
dove /tmp/gelu.hlo contiene
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Link al codice
- Pipeline di compilazione: emitter_base.h
- Passaggi di ottimizzazione e conversione: backends/gpu/codegen/emitters/transforms
- Logica di partizionamento: computation_partitioner.h
- Emittenti basati su eroi: backends/gpu/codegen/emitters
- XLA:GPU ops: xla_gpu_ops.td
- Test di correttezza e lit: backends/gpu/codegen/emitters/tests