
XLA:GPU'da HLO için kod oluşturmanın üç yolu vardır.
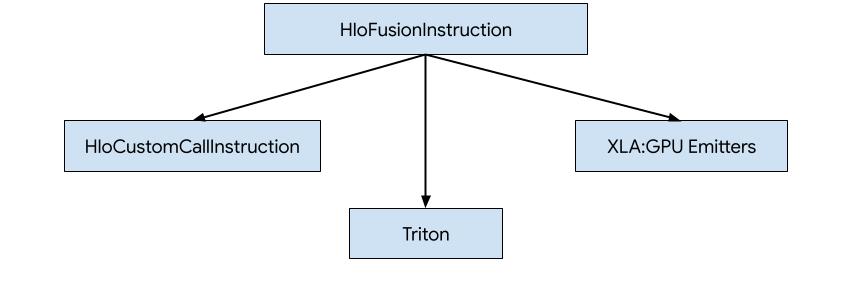
- HLO'yu harici kitaplıklara yapılan özel çağrılarla (ör. NVidia cuBLAS, cuDNN) değiştirme.
- HLO'yu blok düzeyinde döşeme ve ardından OpenAI Triton'u kullanma.
- HLO'yu LLVM IR'ye kademeli olarak düşürmek için XLA Yayıcıları kullanılır.
Bu doküman, XLA:GPU Emitters'a odaklanmaktadır.
Hero tabanlı kod oluşturma
XLA:GPU'da 7 yayıcı türü vardır. Her yayıcı türü, füzyonun "kahramanına", yani füzyonun tamamı için kod oluşturmayı şekillendiren, birleştirilmiş hesaplamadaki en önemli işleme karşılık gelir.
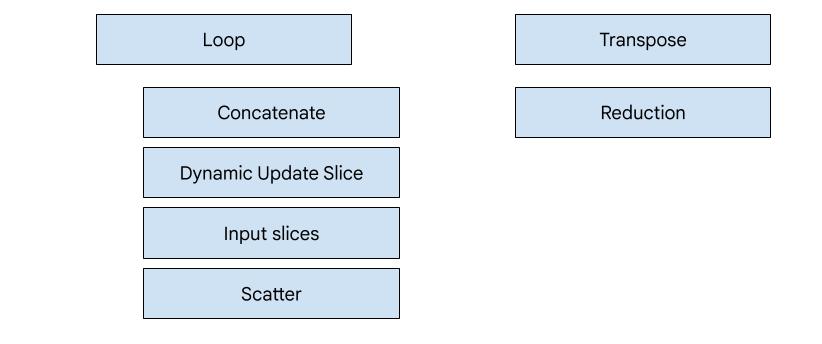
Örneğin, birleştirme işleminde bellek okuma ve yazma düzenlerini iyileştirmek için paylaşılan bellek kullanılmasını gerektiren bir HloTransposeInstruction varsa transpoze yayıcı seçilir. Azaltma yayıcı, karıştırma ve paylaşılan bellek kullanarak azaltmalar oluşturur. Döngü yayıcı, varsayılan yayıcıdır. Bir füzyonda, özel yayıcımızın olduğu bir kahraman yoksa döngü yayıcı kullanılır.
Üst düzey genel bakış
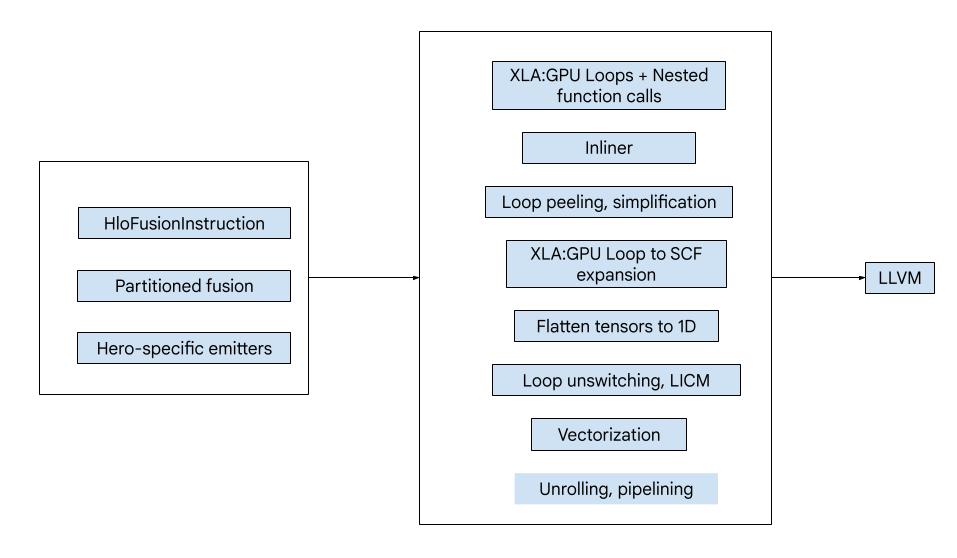
Kod, aşağıdaki büyük yapı taşlarından oluşur:
- Hesaplama bölümleyici: HLO birleştirme hesaplamasını işlevlere bölme
- Yayıcılar: Bölümlendirilmiş HLO birleştirme işlemini MLIR'ye dönüştürme (
xla_gpu,tensor,arith,math,scflehçeleri) - Derleme hattı: IR'yi LLVM'ye göre optimize eder ve düşürür.
Bölümlendirme
computation_partitioner.h dosyasına bakın.
Öğe bazında olmayan HLO talimatları her zaman birlikte yayınlanamaz. Aşağıdaki HLO grafiğini göz önünde bulundurun:
param
|
log
| \
| transpose
| /
add
Bunu tek bir işlevde yayınlarsak log, add öğesinin her bir öğesi için iki farklı dizinde erişilir. Eski yayıncılar, log iki kez oluşturarak bu sorunu çözer. Bu grafikte bu bir sorun değildir ancak birden fazla bölünme olduğunda kod boyutu katlanarak artar.
Burada, grafiği tek bir fonksiyon olarak güvenli bir şekilde yayınlanabilecek parçalara bölerek bu sorunu çözüyoruz. Ölçütler şunlardır:
- Yalnızca bir kullanıcısı olan talimatlar, kullanıcılarıyla birlikte güvenli bir şekilde yayınlanabilir.
- Birden fazla kullanıcısı olan talimatlar, tüm kullanıcılar tarafından aynı dizinler üzerinden erişiliyorsa kullanıcılarıyla birlikte güvenli bir şekilde yayınlanabilir.
Yukarıdaki örnekte, add ve tranpose, log'nin farklı dizinlerine eriştiği için bu değerin onlarla birlikte yayınlanması güvenli değildir.
Bu nedenle grafik üç işlev halinde bölümlenir (her biri yalnızca bir talimat içerir).
Aynı durum, add'nin slice ve pad ile ilgili aşağıdaki örneği için de geçerlidir.
Element emisyonu
elemental_hlo_to_mlir.h dosyasına bakın.
Elemental emission, HloInstructions için döngüler ve matematik/aritmetik işlemler oluşturur. Bu işlem genellikle basittir ancak burada ilginç şeyler de olur.
Dizine ekleme dönüşümleri
Bazı talimatlar (transpose, broadcast, reshape, slice, reverse ve birkaç talimat daha) tamamen dizinlerdeki dönüşümlerdir: Sonuç öğesini oluşturmak için girişin başka bir öğesini oluşturmamız gerekir. Bunun için, bir talimatın giriş-çıkış eşlemesini oluşturma işlevlerine sahip olan XLA'nın indexing_analysis'ini yeniden kullanabiliriz.
Örneğin, transpose'dan [20,40]'ye [40,20] için aşağıdaki indeksleme haritasını oluşturur (giriş boyutu başına bir afin ifade; d0 ve d1 çıkış boyutlarıdır):
(d0, d1) -> d1
(d0, d1) -> d0
Bu nedenle, bu saf dizin dönüştürme talimatları için haritayı alıp çıkış dizinlerine uygulayabilir ve sonuçtaki dizinde girişi oluşturabiliriz.
Benzer şekilde, pad işlemi de uygulamanın büyük bir bölümünde dizine ekleme haritalarını ve kısıtlamaları kullanır. pad, girişin bir öğesini mi yoksa dolgu değerini mi döndürdüğümüzü görmek için bazı ek kontroller içeren bir indeksleme dönüşümüdür.
Unsur
Dahili tuple'ler desteklenmez. İç içe yerleştirilmiş demet çıkışları da desteklenmez. Bu özellikleri kullanan tüm XLA grafikleri, bu özellikleri kullanmayan grafiklere dönüştürülebilir.
Gather
Yalnızca gather_simplifier tarafından üretilen kanonik toplama işlemlerini destekliyoruz.
Alt grafik işlevleri
%p0 ile %p_n parametrelerine sahip bir hesaplamanın alt grafiği ve r boyutları ile öğe türleri (e0 ile e_m) olan alt grafik kökleri için aşağıdaki MLIR işlev imzasını kullanırız:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
Yani, hesaplama parametresi başına bir tensör girişi, çıkışın boyutu başına bir dizin girişi ve çıkış başına bir sonuç vardır.
Bir işlevi yaymak için yukarıdaki temel yayıcıyı kullanırız ve alt grafiğin kenarına ulaşana kadar işlenenlerini yinelemeli olarak yayarız. Ardından, parametreler için tensor.extract veya diğer alt grafikler için func.call yayınlarız.
Giriş işlevi
Her yayıcı türü, giriş işlevini (ör. kahramanın işlevi) oluşturma şekli bakımından farklılık gösterir. Giriş işlevi, girdi olarak dizin içermediği (yalnızca iş parçacığı ve blok kimlikleri) ve çıktıyı bir yere yazması gerektiği için yukarıdaki işlevlerden farklıdır. Döngü yayıcı için bu oldukça basittir ancak transpoze ve azaltma yayıcılarında önemsiz olmayan yazma mantığı vardır.
Giriş hesaplamasının imzası şöyledir:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
Burada, önceki örnekte olduğu gibi %pn hesaplamanın parametreleri, %rn ise hesaplamanın sonuçlarıdır. Giriş hesaplaması, sonuçları tensör olarak alır, tensor.insert bunları günceller ve ardından döndürür.
Çıkış tensörlerinin başka şekilde kullanılmasına izin verilmez.
Derleme ardışık düzeni
Döngü yayıcı
loop.h dosyasına bakın.
GELU işlevi için HLO'yu kullanarak MLIR derleme işlem hattının en önemli geçişlerini inceleyelim.
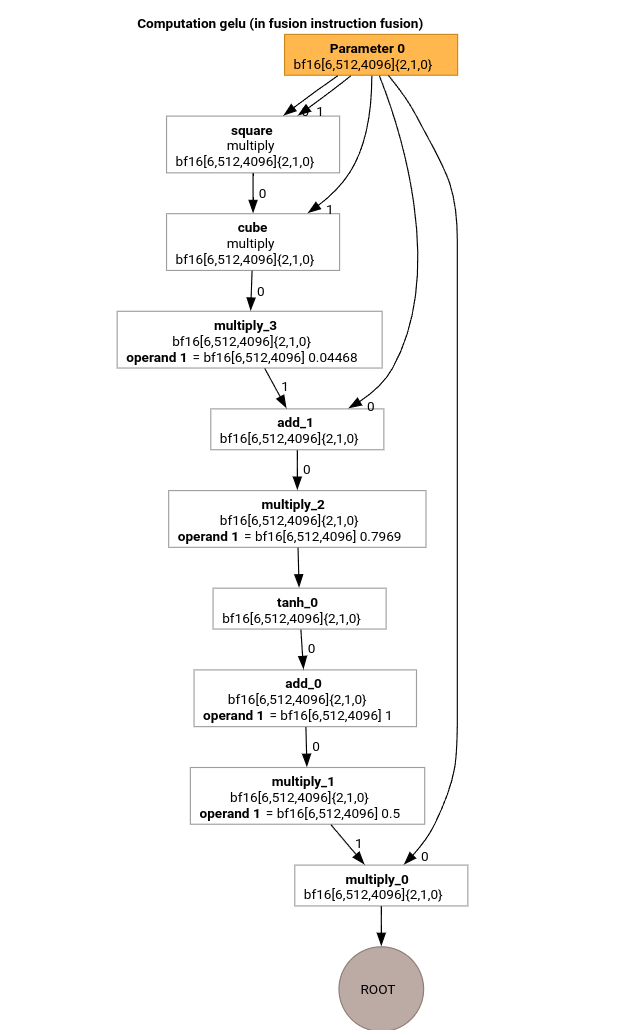
Bu HLO hesaplamasında yalnızca öğe bazında işlemler, sabitler ve yayınlar bulunur. Döngü yayıcı kullanılarak yayılır.
MLIR Dönüşümü
MLIR'ye dönüştürme işleminden sonra, %thread_id_x ve %block_id_x değerlerine bağlı olan ve birleştirilmiş yazma işlemlerini garanti etmek için çıkışın tüm öğelerini doğrusal olarak geçen döngüyü tanımlayan bir xla_gpu.loop elde ederiz.
Bu döngünün her yinelemesinde
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
kök işlemin öğelerini hesaplamak için kullanılır. Bölümleyici, 2 veya daha fazla farklı erişim kalıbı olan bir tensör algılamadığından @gelu için yalnızca bir ana hatlı işlevimiz olduğunu unutmayın.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
@gelu satır içi yapıldıktan sonra tek bir @main işlevi elde ederiz. Aynı işlevin iki veya daha fazla kez çağrılması mümkündür. Bu durumda satır içi reklam göstermeyiz. Satır içi kuralları hakkında daha fazla bilgiyi xla_gpu_dialect.cc dosyasında bulabilirsiniz.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
xla_gpu - scf dönüşümü
lower_xla_gpu_to_scf.cc dosyasına bakın.
xla_gpu.loop, içinde sınır kontrolü olan bir döngü yuvasını temsil eder. Döngüye alma değişkenleri, dizine ekleme haritası alanının dışında kalıyorsa bu yineleme atlanır. Bu, döngünün içinde scf.if bulunan 1 veya daha fazla iç içe yerleştirilmiş scf.for işlemine dönüştürüldüğü anlamına gelir.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
Tensörleri düzleştirme
flatten_tensors.cc dosyasına bakın.
N boyutlu tensörler 1 boyuta yansıtılır. Bu sayede, her tensör erişimi artık verilerin bellekte nasıl hizalandığına karşılık geldiğinden vektörleştirme ve LLVM'ye düşürme işlemi basitleşir.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
Vektörleştirme
vectorize_loads_stores.cc dosyasına bakın.
Geçiş, tensor.extract ve tensor.insert işlemlerindeki dizinleri analiz eder. Bu dizinler, %vector_index ile ilgili olarak öğelere bitişik şekilde erişen xla_gpu.apply_indexing tarafından üretiliyorsa ve erişim hizalanmışsa tensor.extract, vector.transfer_read'ye dönüştürülür ve döngüden çıkarılır.
Bu özel durumda, 0 ile 4 arasında bir scf.for döngüsünde çıkarılacak ve eklenecek öğeleri hesaplamak için kullanılan bir dizin oluşturma haritası
(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) vardır.
Bu nedenle, hem tensor.extract hem de tensor.insert vektörel hale getirilebilir.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
Döngüden çıkma
optimize_loops.cc dosyasına bakın.
Döngü açma, açılabilecek scf.for döngü bulur. Bu durumda, vektörün öğeleri üzerindeki döngü kaybolur.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
LLVM'ye dönüştürme
Çoğunlukla standart LLVM düşürmelerini kullanırız ancak birkaç özel geçiş vardır.
IR'yi arabelleğe almadığımız ve ABI'miz memref ABI'siyle uyumlu olmadığı için tensörler için memref düşürmelerini kullanamıyoruz. Bunun yerine, tensörlerden doğrudan LLVM'ya özel bir küçültme kullanıyoruz.
- Tensörlerin düşürülmesi lower_tensors.cc dosyasında yapılır.
tensor.extract,llvm.load,tensor.insertvellvm.storeolarak düşürülür. - propagate_slice_indices ve merge_pointers_to_same_slice birlikte arabellek atama ve XLA'nın ABI'si ile ilgili bir ayrıntıyı uygular: İki tensör aynı arabellek dilimini paylaşıyorsa yalnızca bir kez iletilirler. Bu geçişler, işlev bağımsız değişkenlerini tekilleştirir.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
Yayıcıyı transpoze etme
Şimdi biraz daha karmaşık bir örnek inceleyelim.
![]()
Transpoze yayıcı, döngü yayıcıdan yalnızca giriş işlevinin oluşturulma şekli bakımından farklıdır.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
Bu durumda iki xla_gpu.loop işlemi oluştururuz. Birincisi, girişten birleştirilmiş okumalar gerçekleştirir ve sonucu paylaşılan belleğe yazar.
Paylaşılan bellek tensörü, xla_gpu.allocate_shared işlemi kullanılarak oluşturulur.
İş parçacıkları xla_gpu.sync_threads kullanılarak senkronize edildikten sonra ikinci xla_gpu.loop, paylaşılan bellek tensöründeki öğeleri okur ve çıkışa birleştirilmiş yazma işlemleri gerçekleştirir.
Reproducer
Derleme işlem hattının her geçişinden sonra IR'yi görmek için run_hlo_module, --xla_dump_emitter_re=mlir-fusion işaretiyle başlatılabilir.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
/tmp/gelu.hlo içerdiğinde
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
Kod bağlantıları
- Derleme ardışık düzeni: emitter_base.h
- Optimizasyon ve dönüşüm geçişleri: backends/gpu/codegen/emitters/transforms
- Bölümleme mantığı: computation_partitioner.h
- Kahraman tabanlı yayıcılar: backends/gpu/codegen/emitters
- XLA:GPU ops: xla_gpu_ops.td
- Doğruluk ve lit testleri: backends/gpu/codegen/emitters/tests