
سه روش برای تولید کد برای HLO در XLA:GPU وجود دارد.
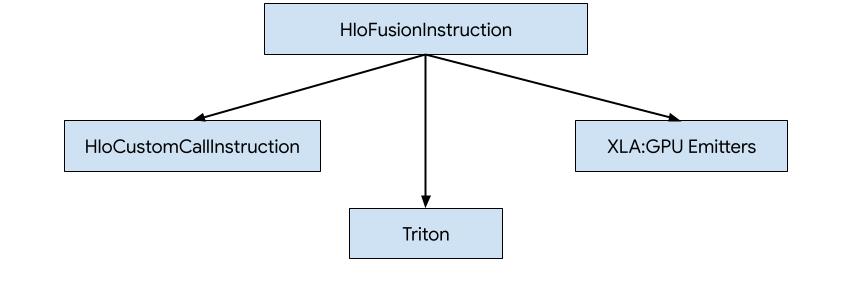
- جایگزینی HLO با فراخوانیهای سفارشی به کتابخانههای خارجی، مانند NVidia cuBLAS ، cuDNN .
- کاشیکاری HLO تا سطح بلوک و سپس استفاده از OpenAI Triton .
- استفاده از ساطعکنندههای XLA برای کاهش تدریجی HLO به LLVM IR.
این سند بر روی فرستندههای XLA:GPU تمرکز دارد.
کدژن مبتنی بر قهرمان
در XLA:GPU، هفت نوع ساطعکننده وجود دارد. هر نوع ساطعکننده مربوط به یک «قهرمان» از فیوژن است، یعنی مهمترین عملیات در محاسبات فیوژن که تولید کد را برای کل فیوژن شکل میدهد.
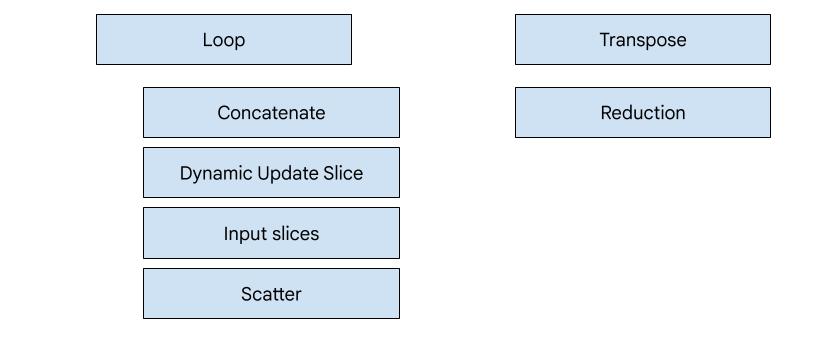
برای مثال، اگر یک HloTransposeInstruction در فیوژن وجود داشته باشد که برای بهبود الگوهای خواندن و نوشتن حافظه نیاز به استفاده از حافظه مشترک داشته باشد، فرستندهی transpose انتخاب خواهد شد. فرستندهی کاهش، کاهشها را با استفاده از shuffles و حافظه مشترک ایجاد میکند. فرستندهی حلقه، فرستندهی پیشفرض است. اگر یک فیوژن، قهرمانی نداشته باشد که برای آن فرستندهی ویژه داشته باشیم، از فرستندهی حلقه استفاده خواهد شد.
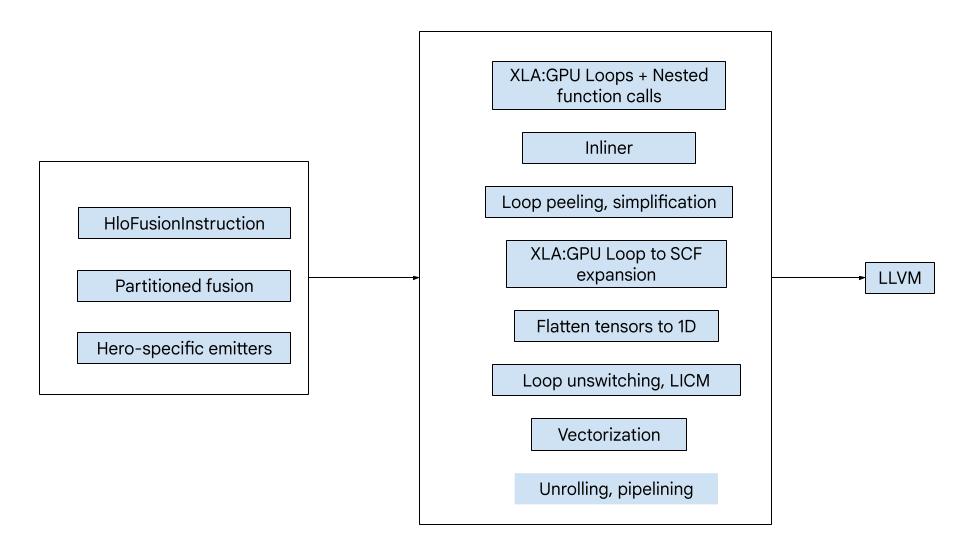
نمای کلی سطح بالا
این کد از بلوکهای سازندهی بزرگ زیر تشکیل شده است:
- پارتیشنبندی محاسبات - تقسیم یک محاسبه فیوژن HLO به توابع
- ساطعکنندهها - تبدیل فیوژن HLO پارتیشنبندیشده به MLIR (
xla_gpu،tensor،arith،math،scfdialects) - خط لوله کامپایل - IR را بهینه کرده و به LLVM کاهش میدهد
پارتیشن بندی
به computation_partitioner.h مراجعه کنید.
دستورالعملهای HLO غیرعنصری نمیتوانند همیشه با هم منتشر شوند. نمودار HLO زیر را در نظر بگیرید:
param
|
log
| \
| transpose
| /
add
اگر این را در یک تابع واحد منتشر کنیم، به log برای هر عنصر از add ، در دو اندیس مختلف دسترسی پیدا میشود. منتشرکنندههای قدیمی این مشکل را با تولید دو بار log حل میکنند. برای این گراف خاص، این یک مشکل نیست، اما وقتی چندین تقسیم وجود دارد، اندازه کد به صورت نمایی افزایش مییابد.
در اینجا، ما این مشکل را با تقسیم گراف به قطعاتی که میتوانند به طور ایمن به عنوان یک تابع منتشر شوند، حل میکنیم. معیارها عبارتند از:
- دستورالعملهایی که فقط یک کاربر دارند، میتوانند به همراه کاربرشان منتشر شوند.
- دستورالعملهایی که چندین کاربر دارند، در صورتی که توسط همه کاربران از طریق اندیسهای یکسان مورد دسترسی قرار گیرند، انتشار آنها به همراه کاربرانشان ایمن است.
در مثال بالا، add و tranpose به اندیسهای مختلفی از log دسترسی دارند، بنابراین انتشار آن به همراه آنها ایمن نیست.
بنابراین، گراف به سه تابع (که هر کدام فقط شامل یک دستورالعمل هستند) تقسیم میشود.
همین امر در مورد مثال زیر با slice و pad از add نیز صدق میکند.
انتشار عنصری
به elemental_hlo_to_mlir.h مراجعه کنید.
انتشار عنصری حلقهها و عملیات ریاضی/حسابی را برای HloInstructions ایجاد میکند. در بیشتر موارد، این کار ساده است، اما نکات جالبی در اینجا وجود دارد.
تبدیلهای اندیسگذاری
برخی دستورالعملها ( transpose ، broadcast ، reshape ، slice ، reverse و چند مورد دیگر) صرفاً تبدیلهایی روی اندیسها هستند: برای تولید یک عنصر از نتیجه، باید عنصر دیگری از ورودی را تولید کنیم. برای این کار، میتوانیم از indexing_analysis در XLA که توابعی برای تولید نگاشت خروجی به ورودی برای یک دستورالعمل دارد، استفاده مجدد کنیم.
برای مثال، برای یک transpose از [20,40] به [40,20] ، نقشه اندیسگذاری زیر را تولید میکند (یک عبارت نمادین در هر بُعد ورودی؛ d0 و d1 ابعاد خروجی هستند):
(d0, d1) -> d1
(d0, d1) -> d0
بنابراین برای این دستورالعملهای تبدیل اندیس خالص، میتوانیم به سادگی نقشه را دریافت کنیم، آن را روی اندیسهای خروجی اعمال کنیم و ورودی را در اندیس حاصل تولید کنیم.
به طور مشابه، pad op برای بیشتر پیادهسازی از نقشهها و محدودیتهای اندیسگذاری استفاده میکند. pad نیز یک تبدیل اندیسگذاری است که بررسیهایی برای بررسی اینکه آیا عنصری از ورودی یا مقدار padding را برمیگردانیم، انجام میدهد.
تاپلها
ما tuple داخلی پشتیبانی نمیکنیم. همچنین از خروجیهای تاپلهای تو در تو نیز پشتیبانی نمیکنیم. تمام گرافهای XLA که از این ویژگیها استفاده میکنند را میتوان به گرافهایی تبدیل کرد که این ویژگیها را ندارند.
جمع آوری
ما فقط از collect های متعارف تولید شده توسط gather_simplifier پشتیبانی میکنیم.
توابع زیرگراف
برای یک زیرگراف از یک محاسبه با پارامترهای %p0 تا %p_n و ریشههای زیرگراف با r بعد و نوع عنصر ( e0 تا e_m )، از امضای تابع MLIR زیر استفاده میکنیم:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
یعنی، به ازای هر پارامتر محاسباتی، یک ورودی تانسور، به ازای هر بُعد خروجی، یک ورودی اندیس و به ازای هر خروجی، یک نتیجه داریم.
برای انتشار یک تابع، ما به سادگی از emitter عنصری بالا استفاده میکنیم و به صورت بازگشتی عملوندهای آن را منتشر میکنیم تا زمانی که به لبه زیرگراف برسیم. سپس، ما: یک tensor.extract برای پارامترها یا یک func.call برای سایر زیرگرافها منتشر میکنیم.
تابع ورودی
هر نوع امیتر در نحوه تولید تابع ورودی، یعنی تابع مربوط به قهرمان، متفاوت است. تابع ورودی با توابع بالا متفاوت است، زیرا هیچ شاخصی به عنوان ورودی ندارد (فقط شناسههای نخ و بلوک) و در واقع باید خروجی را در جایی بنویسد. برای امیتر حلقه، این کار نسبتاً ساده است، اما امیترهای انتقال و کاهش منطق نوشتن غیر بدیهی دارند.
امضای محاسبه ورودی عبارت است از:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
مانند قبل، %pn ها پارامترهای محاسبه و %rn ها نتایج محاسبه هستند. محاسبه ورودی نتایج را به عنوان تانسور دریافت میکند، tensor.insert ها را در آنها بهروزرسانی میکند و سپس آنها را برمیگرداند. هیچ استفاده دیگری از تانسورهای خروجی مجاز نیست.
خط لوله کامپایل
امیتر حلقه
به loop.h مراجعه کنید.
بیایید مهمترین مراحل خط لوله کامپایل MLIR را با استفاده از HLO برای تابع GELU بررسی کنیم.
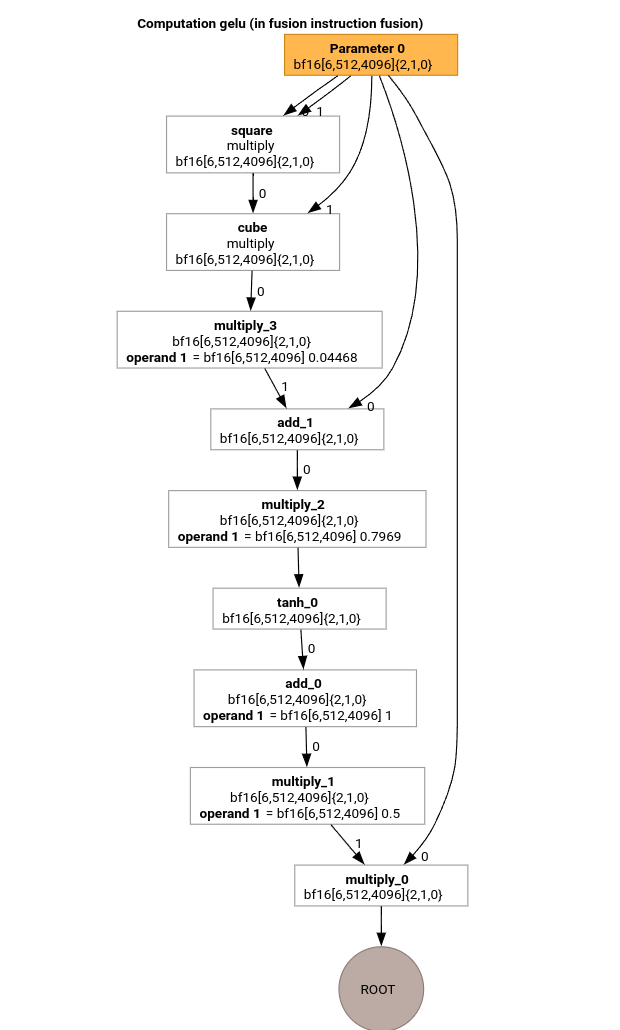
این محاسبه HLO فقط دارای عملیات، ثابتها و پخشهای عنصر به عنصر است. با استفاده از ساطعکننده حلقه منتشر میشود.
تبدیل MLIR
پس از تبدیل به MLIR، یک xla_gpu.loop دریافت میکنیم که به %thread_id_x و %block_id_x بستگی دارد و حلقهای را تعریف میکند که تمام عناصر خروجی را به صورت خطی طی میکند تا نوشتنهای تلفیقی را تضمین کند.
در هر تکرار این حلقه، فراخوانی میکنیم
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
برای محاسبه عناصر عملیات ریشه. توجه داشته باشید که ما فقط یک تابع مشخص برای @gelu داریم، زیرا پارتیشنبندیکننده، تانسوری را که دارای ۲ یا چند الگوی دسترسی مختلف باشد، شناسایی نکرده است.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
اینلاینر
بعد از اینکه @gelu به صورت inline تعریف شد، یک تابع @main خواهیم داشت. ممکن است یک تابع دو یا چند بار فراخوانی شود. در این حالت inline نمیکنیم. جزئیات بیشتر در مورد قوانین inline کردن را میتوانید در xla_gpu_dialect.cc بیابید.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
تبدیل xla_gpu به scf
به lower_xla_gpu_to_scf.cc مراجعه کنید.
xla_gpu.loop نشان دهنده یک حلقه تو در تو با یک بررسی مرزی در داخل آن است. اگر متغیرهای القای حلقه خارج از محدوده دامنه نقشه اندیس گذاری باشند، این تکرار رد میشود. این بدان معناست که حلقه به یک یا چند عملیات scf.for تو در تو با یک scf.if در داخل تبدیل میشود.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
تانسورهای مسطح
به flatten_tensors.cc مراجعه کنید.
تانسورهای Nd روی یکبعد تصویر میشوند. این کار، برداریسازی و انتقال به LLVM را سادهتر میکند، زیرا اکنون هر دسترسی به تانسور با نحوه ترازبندی دادهها در حافظه مطابقت دارد.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
برداریسازی
به vectorize_loads_stores.cc مراجعه کنید.
این مسیر، اندیسهای موجود در عملیات tensor.extract و tensor.insert را تجزیه و تحلیل میکند و اگر توسط xla_gpu.apply_indexing تولید شده باشند که به عناصر به صورت پیوسته با %vector_index دسترسی پیدا میکند و دسترسی همتراز شده است، آنگاه tensor.extract به vector.transfer_read تبدیل شده و از حلقه خارج میشود.
در این مورد خاص، یک نقشه اندیسگذاری (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) وجود دارد که برای محاسبه عناصر جهت استخراج و درج در یک حلقه scf.for از 0 تا 4 استفاده میشود. بنابراین، هر دو tensor.extract و tensor.insert میتوانند برداری شوند.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
حلقه باز کردن
به optimize_loops.cc مراجعه کنید.
حلقهی بازشونده، حلقههای scf.for را که میتوانند باز شوند، پیدا میکند. در این حالت، حلقه روی عناصر بردار ناپدید میشود.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
تبدیل به LLVM
ما عمدتاً از کاهشهای استاندارد LLVM استفاده میکنیم، اما چند مسیر خاص نیز وجود دارد. ما نمیتوانیم از کاهشهای memref برای تانسورها استفاده کنیم، زیرا IR را بافر نمیکنیم و ABI ما با memref ABI سازگار نیست. در عوض، ما یک کاهش سفارشی مستقیماً از تانسورها به LLVM داریم.
- کاهش تانسورها در lower_tensors.cc انجام میشود.
tensor.extractبهllvm.loadوtensor.insertبهllvm.storeکاهش مییابد، همانطور که واضح است. - propa_slice_indices و merge_pointers_to_same_slice با هم جزئیاتی از انتساب بافر و ABI مربوط به XLA را پیادهسازی میکنند: اگر دو تانسور برش بافر یکسانی را به اشتراک بگذارند، فقط یک بار ارسال میشوند. این ارسالها آرگومانهای تابع را از تکرار خالی میکنند.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
فرستندهی ترانسپوز
بیایید یک مثال کمی پیچیدهتر را در نظر بگیریم.
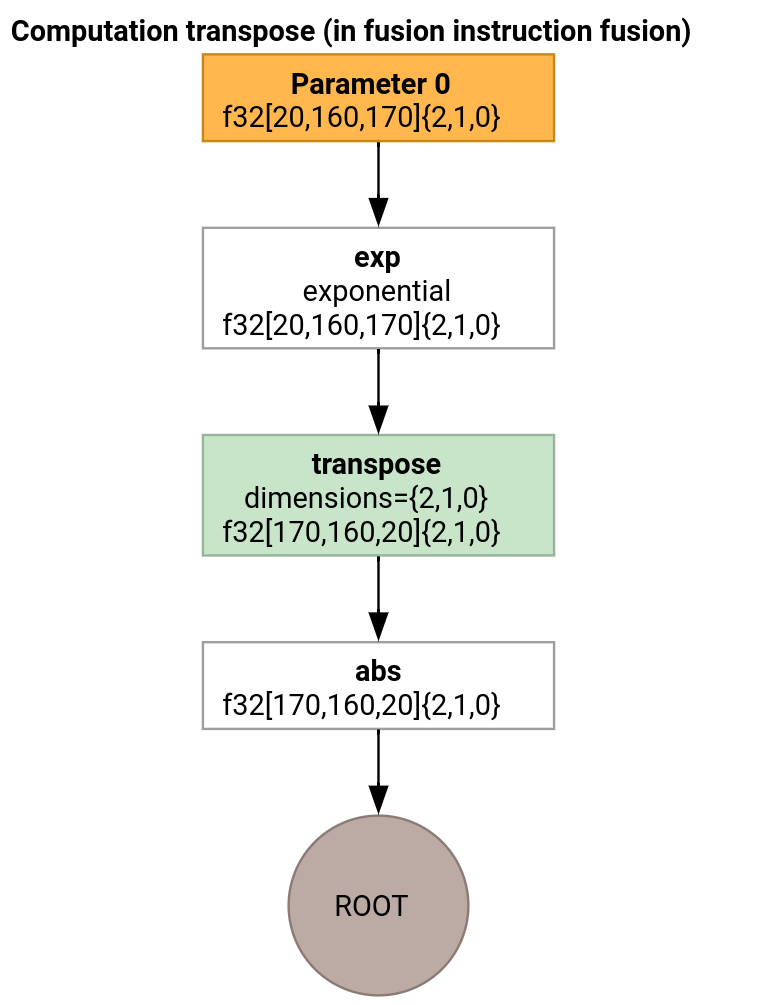
امیتر ترانسپوز تنها در نحوه تولید تابع ورودی با امیتر حلقه متفاوت است.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
در این حالت، ما دو عملیات xla_gpu.loop ایجاد میکنیم. اولی خواندنهای تلفیقی از ورودی را انجام میدهد و نتیجه را در حافظه مشترک مینویسد.
تانسور حافظه مشترک با استفاده از xla_gpu.allocate_shared op ایجاد میشود.
پس از اینکه نخها با استفاده از xla_gpu.sync_threads همگامسازی شدند، xla_gpu.loop دوم عناصر را از تانسور حافظه مشترک میخواند و نوشتنهای تلفیقی را در خروجی انجام میدهد.
تولید کننده
برای مشاهده IR پس از هر بار عبور از خط لوله کامپایل، میتوان run_hlo_module با فلگ --xla_dump_emitter_re=mlir-fusion اجرا کرد.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
جایی که /tmp/gelu.hlo شامل میشود
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
لینکهای مربوط به کد
- خط لوله کامپایل: emitter_base.h
- مراحل بهینهسازی و تبدیل: backends/gpu/codegen/emitters/transforms
- منطق پارتیشن: computation_partitioner.h
- ساطعکنندههای مبتنی بر قهرمان: backends/gpu/codegen/emitters
- XLA: عملیات پردازنده گرافیکی: xla_gpu_ops.td
- تستهای صحت و روشنایی: backends/gpu/codegen/emitters/tests