
Инструмент статистики операций HLO
Вы можете использовать HLO Op Stats для просмотра статистики производительности операций высокоуровневой оптимизации (HLO), выполненных во время сеанса профилирования. Этот инструмент полезен для выявления потенциальных целей оптимизации производительности, выделяя наиболее трудоемкие операции на графике HLO за профилируемый период.
Поддерживаемые платформы
Поддерживаются как TPU, так и GPU.
Для графических процессоров количество операций HLO связано с количеством фактически выполняемых ядер в соотношении N:M. Статистику на уровне ядра можно найти в инструменте GPU Kernel Stats .
Компоненты инструмента HLO Op Stats
Инструмент HLO Op Stats состоит из следующих ключевых компонентов:
Раздел сводных диаграмм : В этом разделе представлены диаграммы, которые суммируют подробные результаты в таблице по операциям следующим образом:
- Круговая диаграмма под названием «Время на категорию HLO» , показывающая долю времени, затраченного на различные категории операций HLO.
- Круговая диаграмма под названием «Время на операцию HLO» , которая показывает долю времени, затраченного на различные отдельные операции HLO (ограничена первыми N операциями, а оставшиеся классифицированы как «Другое» для удобства чтения).
- Круговая диаграмма под названием «Время, затраченное на рематериализацию» , которая показывает долю общего времени, затраченного на операции, являющиеся частью рематериализации; XProf получает эту информацию из метаданных компилятора, связанных с профилем.
- Круговая диаграмма под названием «Время, затраченное на повторную материализацию по категориям HLO» , которая показывает категории операций HLO, на которые тратится время повторной материализации (если таковое имеется).
- Диаграмма « Время, затраченное на внешнюю компиляцию» . Внешняя компиляция — это функция TensorFlow, которая позволяет прозрачно выполнять некоторые операции в вычислениях XLA на центральном процессоре, а не на устройстве-ускорителе (например,
tf.summaryилиtf.print, требующие доступа к вводу-выводу, которого у устройства нет). - Диаграмма, отображающая GFLOPS/s для всех операций HLO, упорядоченных по общему собственному времени.
- Только для TPU, время на HLO по группе реплик: раскрывающийся список позволяет выбрать различные коллективные операции, выполненные в ходе сеанса профилирования. Различные экземпляры этой коллективной операции могли быть выполнены в разных группах реплик (например, AllGather ); круговая диаграмма показывает распределение времени между этими экземплярами.
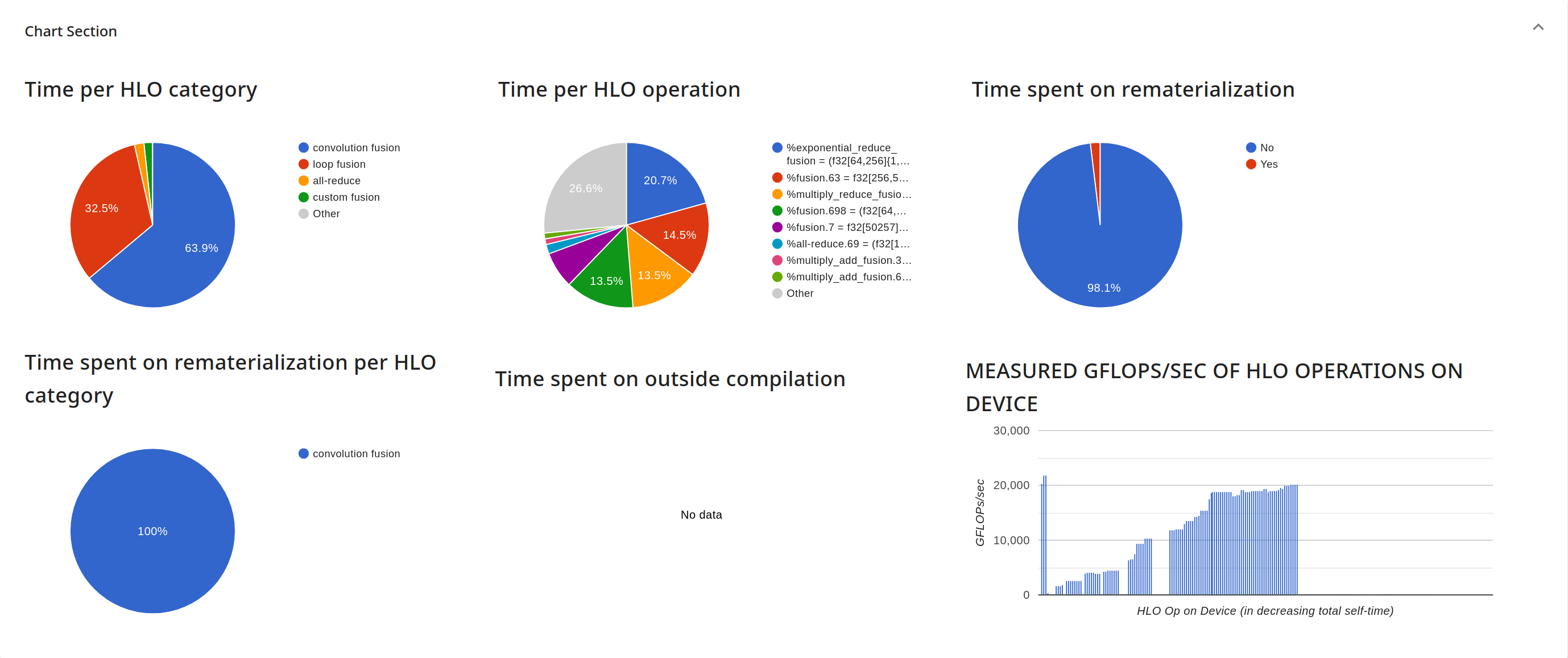
Таблица статистики операций HLO : это основной компонент, представляющий подробную разбивку каждой операции HLO, выполненной в ходе сеанса профилирования, в табличном формате. Для каждой операции HLO отведена отдельная строка, а столбцы содержат различную информацию об этой операции.
- Раскрывающийся список позволяет вам выбрать, какие столбцы вы хотите визуализировать для каждой операции HLO.
- Вы также можете фильтровать строки по категории HLO Op с помощью второго раскрывающегося списка.
- Поля поиска позволяют фильтровать по определенным идентификаторам программ, операциям HLO, тексту операции HLO или имени операции фреймворка; фильтры выбирают указанную строку, появляющуюся в любом месте соответствующего столбца.
Подробности таблицы статистики операции HLO
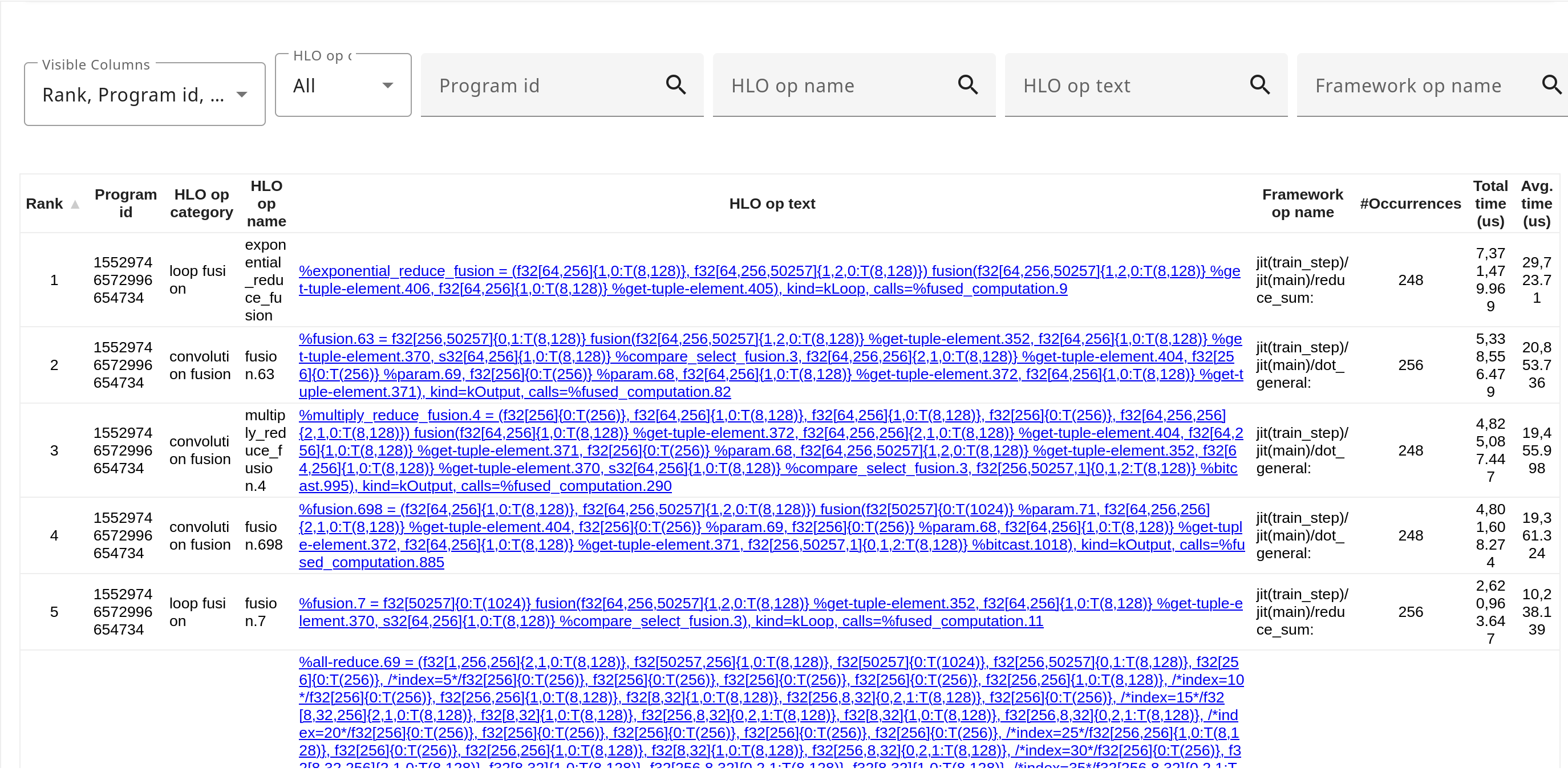
Вы можете нажать на любой заголовок столбца, чтобы отсортировать таблицу статистики операций HLO. Порядок по умолчанию основан на общем времени, затраченном на выполнение операции (в таблице обозначен как «ранг»).
Таблица содержит следующую информацию для каждой операции HLO:
- Идентификатор программы : идентификатор модуля HLO, с которым связана эта операция.
- Категория операций HLO : они в основном определяются компилятором XLA; XProf дополнительно использует эвристику для идентификации и категоризации определенных операций (например, слияния сверток).
- Имя операции HLO : уникальное имя, присвоенное операции HLO компилятором XLA.
- Текст операции HLO : предоставляется компилятором XLA и включает в себя такие сведения, как типы и формы входных данных/параметров.
- Имя операции фреймворка : операция на уровне фреймворка (например, JAX), которая привела к созданию этой операции HLO.
- События : общее количество раз, когда данная операция HLO была выполнена в течение периода профилирования.
- Общее время (мкс) : совокупное время, затраченное на выполнение данной операции во всех её повторениях. Если у этой операции есть дочерние операции (например, в рамках слияния), это время включает время, затраченное на эти дочерние операции.
- Среднее время (мкс) : среднее время на выполнение данной операции HLO, включая время, затраченное на дочерние операции, если таковые имеются.
- Общее собственное время (мкс): совокупное время, проведенное исключительно в теле этой операции HLO, за исключением времени, проведенного в ее дочерних операциях.
- Среднее собственное время (мкс): среднее время на выполнение данной операции HLO, исключая время, затраченное на ее дочерние операции.
- Общее личное время (%): личное время операции в процентах от общего времени на устройстве по всем операциям.
- Общее накопленное время самостоятельной работы (%): текущая сумма общего времени самостоятельной работы (%) для всех операций, которые появляются ранее в порядке «ранга».
- Остановка DMA (%): процент от общего времени, в течение которого операция была остановлена из-за операций прямого доступа к памяти (DMA).
- Потребление полосы пропускания (использование/сек) для FLOP, HBM и внутренней памяти TPU, если она доступна (например, CMEM присутствует только в TPU v4). Все эти значения рассчитываются с использованием статического анализа стоимости компилятора (числитель) и профилированного времени выполнения (знаменатель).
- Модель GFLOPS/s: Стоимость GFLOPs вычисляется компилятором XLA, а время измеряется профилем.
- Нормализованный показатель GFLOPS/s: нормализует вычисляемое компилятором значение FLOP для каждой операции на основе её числовой точности и пикового значения FLOP, поддерживаемого устройством для различных значений точности. Например, TPU v6e поддерживает вдвое больше пикового значения FLOP для int8, чем для bf16; XProf по умолчанию нормализует значение до bf16.
- Пропускная способность памяти: количество байтов/с, потребляемых операцией из любой памяти (например, встроенных в чип TPU VMEM и HBM). Компилятор XLA предоставляет количество байтов, а длительность измеряется в профиле.
- HBM BW: Количество байт/с, потребленных из HBM.
- Интенсивность работы: рассчитывается как отношение FLOPS к байтам, как определено для анализа линии крыши.
- Ограничение вычислений/памяти: на основе модели Roofline этот столбец указывает, ограничивается ли производительность операции в первую очередь вычислительными возможностями или пропускной способностью памяти.
- Рематериализация: указывает, была ли операция частью рематериализации.
- Внешняя компиляция: указывает, была ли операция выполнена на центральном процессоре с использованием внешней компиляции Tensorflow.
- Автонастройка: указывает, была ли операция автоматически настроена XLA. Подробнее см. в разделах Автонастройка и Постоянная автонастройка .