
В этом руководстве показано, как использовать инструменты, доступные в XProf, для отслеживания производительности ваших моделей TensorFlow на хосте (ЦП), устройстве (ГП) или на комбинации хоста и устройства(ов).
Профилирование помогает понять, сколько аппаратных ресурсов (времени и памяти) потребляют различные операции TensorFlow в вашей модели, устранить узкие места в производительности и, в конечном итоге, ускорить выполнение модели.
В этом руководстве вы узнаете, как использовать различные доступные инструменты и разные режимы сбора данных о производительности с помощью Profiler.
Если вы хотите оценить производительность вашей модели на облачных TPU, обратитесь к руководству по облачным TPU .
Собирайте данные о производительности.
XProf собирает данные об активности хоста и трассировки графического процессора вашей модели TensorFlow. Вы можете настроить XProf для сбора данных о производительности либо в программном режиме, либо в режиме выборки.
API для профилирования
Для выполнения профилирования можно использовать следующие API.
Программный режим с использованием функции обратного вызова TensorBoard Keras (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Программный режим с использованием API функций
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Программный режим с использованием менеджера контекста
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Режим выборки: Выполните профилирование по запросу, используя
tf.profiler.experimental.server.startдля запуска gRPC-сервера с вашей моделью TensorFlow. После запуска gRPC-сервера и выполнения модели вы можете получить профиль с помощью кнопки «Получить профиль» в XProf. Используйте скрипт из раздела «Установка профилировщика» выше, чтобы запустить экземпляр TensorBoard, если он еще не запущен.Например,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Пример профилирования нескольких сотрудников:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
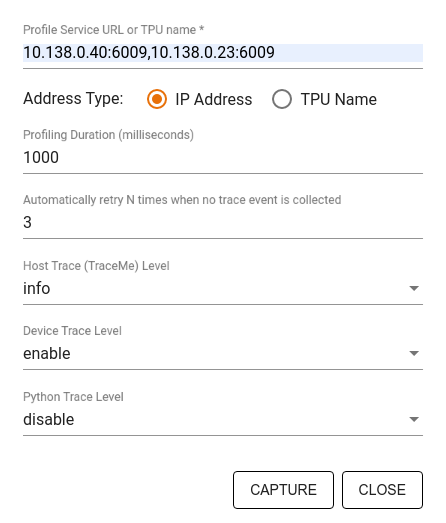
Используйте диалоговое окно «Профиль захвата» , чтобы указать:
- Список URL-адресов служб профилей или имен TPU, разделенных запятыми.
- Продолжительность профилирования.
- Уровень трассировки вызовов устройства, хоста и функций Python.
- Сколько раз вы хотите, чтобы профилировщик пытался повторно создать профили, если первая попытка окажется неудачной?
Профилирование пользовательских циклов обучения
Для профилирования пользовательских циклов обучения в вашем коде TensorFlow используйте API tf.profiler.experimental.Trace для обозначения границ шагов для XProf.
Аргумент name используется в качестве префикса для имен шагов, аргумент step_num добавляется к именам шагов, а аргумент _r заставляет XProf обрабатывать это событие трассировки как событие шага.
Например,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Это позволит включить пошаговый анализ производительности XProf и отобразить события, происходящие на каждом этапе, в окне просмотра трассировки.
Убедитесь, что итератор набора данных включен в контекст tf.profiler.experimental.Trace для точного анализа входного конвейера.
Приведённый ниже фрагмент кода является антипаттерном:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Варианты использования профилирования
Профайлер охватывает ряд сценариев использования по четырем различным направлениям. Некоторые из комбинаций поддерживаются в настоящее время, другие будут добавлены в будущем. Некоторые из сценариев использования:
- Локальное и удалённое профилирование : это два распространённых способа настройки среды профилирования. При локальном профилировании API профилирования вызывается на той же машине, где выполняется ваша модель, например, на локальной рабочей станции с графическими процессорами. При удалённом профилировании API профилирования вызывается на другой машине, отличной от той, где выполняется ваша модель, например, на облачном TPU.
- Профилирование нескольких рабочих процессов : Вы можете профилировать несколько машин при использовании возможностей распределенного обучения TensorFlow.
- Аппаратная платформа : процессоры Profile CPU, GPU и TPU.
В таблице ниже представлен краткий обзор упомянутых выше вариантов использования TensorFlow:
| API профилирования | Местный | Удаленный | Несколько рабочих | Аппаратные платформы |
|---|---|---|---|---|
| TensorBoard Keras Callback | Поддерживается | Не поддерживается | Не поддерживается | ЦП, ГП |
tf.profiler.experimental API запуска/остановки | Поддерживается | Не поддерживается | Не поддерживается | ЦП, ГП |
tf.profiler.experimental client.trace API | Поддерживается | Поддерживается | Поддерживается | ЦП, ГП, ТПУ |
| API менеджера контекста | Поддерживается | Не поддерживается | Не поддерживается | ЦП, ГП |
Дополнительные ресурсы
- В этом руководстве вы найдете обучающий материал по профилированию производительности моделей с помощью TensorFlow Profiler и Keras с использованием TensorBoard, где сможете применить советы из этого руководства на практике.
- Доклад о профилировании производительности в TensorFlow 2 с конференции TensorFlow Dev Summit 2020.
- Демонстрация TensorFlow Profiler с конференции TensorFlow Dev Summit 2020.