
This tool is currently only available in nightly builds.
লক্ষ্য
এই টুলের লক্ষ্য হল একটি TPU সিস্টেমের কর্মক্ষমতা সম্পর্কে একটি স্পষ্ট ধারণা প্রদান করা এবং একজন কর্মক্ষমতা বিশ্লেষককে সিস্টেমের এমন কিছু অংশ চিহ্নিত করার সুযোগ দেওয়া যেখানে কর্মক্ষমতা সংক্রান্ত সমস্যা থাকতে পারে।
চিপ-স্তরের ব্যবহার ভিজ্যুয়ালাইজ করা
টুলটি ব্যবহার করতে, বাম দিকের "ড্রয়ার" থেকে, "ইউটিলাইজেশন ভিউয়ার" টুলটি খুঁজুন। টুলটি 4টি বার চার্ট প্রদর্শন করে যা একটি TPU চিপে 2টি টেনসর নোডের জন্য এক্সিকিউশন ইউনিট (শীর্ষ 2টি চার্ট) এবং DMA পাথ (নীচের 2টি চার্ট) এর ব্যবহার দেখায়।
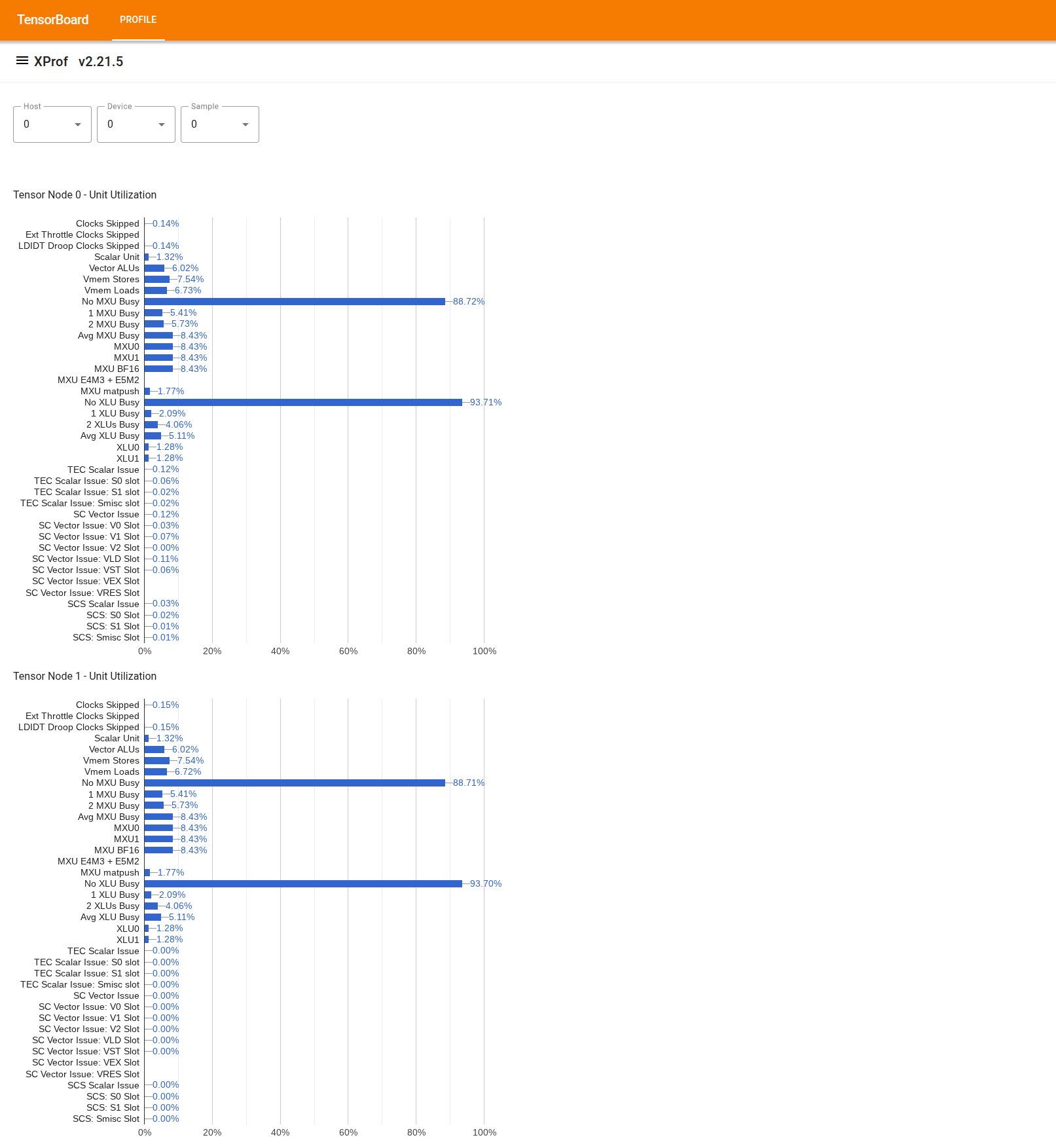
একটি বারের উপর ঘোরালে ব্যবহারের বিবরণ সহ একটি টুলটিপ প্রদর্শিত হয়: "অর্জিত" এবং (তাত্ত্বিক) "শিখর" পরিমাণ। বারে দেখানো ব্যবহারের শতাংশ "অর্জিত" পরিমাণকে "শিখর" পরিমাণ দিয়ে ভাগ করে পাওয়া যায়। অর্জন এবং সর্বোচ্চ পরিমাণগুলি এক্সিকিউশন ইউনিট ব্যবহারের জন্য নির্দেশাবলীর একক এবং ব্যান্ডউইথ ব্যবহারের জন্য বাইটে প্রকাশ করা হয়।
একটি এক্সিকিউশন ইউনিটের ব্যবহার হল প্রোফাইলিং সময়ের মধ্যে ইউনিটটি যে চক্রে ব্যস্ত ছিল তার ভগ্নাংশ ।
নিম্নলিখিত টেনসর কোর এক্সিকিউশন ইউনিটের ব্যবহার দেখানো হয়েছে:
- স্কেলার ইউনিট :
count_s0_instructionএবংcount_s1_instructionএর যোগফল হিসাবে গণনা করা হয়, অর্থাৎ, স্কেলার নির্দেশাবলীর সংখ্যাকে চক্রের সংখ্যার দ্বিগুণ দিয়ে ভাগ করলে, কারণ স্কেলার ইউনিট থ্রুপুট প্রতি চক্রে 2 টি নির্দেশ। - ভেক্টর ALU গুলি :
count_v0_instructionএবংcount_v1_instructionএর যোগফল হিসাবে গণনা করা হয়, অর্থাৎ, ভেক্টর নির্দেশাবলীর সংখ্যাকে চক্রের সংখ্যার দ্বিগুণ দিয়ে ভাগ করলে, কারণ ভেক্টর ALU এর থ্রুপুট প্রতি চক্রে 2 টি নির্দেশ। - ভেক্টর স্টোর :
count_vector_storeহিসাবে গণনা করা হয়, অর্থাৎ, ভেক্টর স্টোরের সংখ্যা, চক্রের সংখ্যা দিয়ে ভাগ করা হয়, কারণ ভেক্টর স্টোর থ্রুপুট প্রতি চক্রে 1 টি নির্দেশ। - ভেক্টর লোড :
count_vector_loadহিসাবে গণনা করা হয়, অর্থাৎ, ভেক্টর লোডের সংখ্যা, চক্রের সংখ্যা দিয়ে ভাগ করা হয়, কারণ ভেক্টর লোড থ্রুপুট প্রতি চক্রে 1 টি নির্দেশ। - ম্যাট্রিক্স ইউনিট (MXU) :
count_matmulকে চক্রের সংখ্যার 1/8 ভাগ দিয়ে ভাগ করলে গণনা করা হয়, কারণ MXU থ্রুপুট হল প্রতি 8 চক্রে 1 টি নির্দেশ। - ট্রান্সপোজ ইউনিট (XU) : গণনা করা হলে
count_transposeচক্রের সংখ্যার 1/8 ভাগে ভাগ করা হয়, কারণ XU থ্রুপুট হল প্রতি 8 চক্রে 1 টি নির্দেশ। - রিডাকশন অ্যান্ড পারমুটেশন ইউনিট (RPU) :
count_rpu_instructionকে চক্রের সংখ্যার ১/৮ ভাগ দিয়ে ভাগ করলে গণনা করা হয়, কারণ RPU থ্রুপুট হল প্রতি ৮টি চক্রে ১টি নির্দেশ।
নিচের চিত্রটি টেনসর কোরের একটি ব্লক ডায়াগ্রাম যা এক্সিকিউশন ইউনিটগুলি দেখায়:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleএই প্রতিটি এক্সিকিউশন ইউনিট সম্পর্কে আরও বিস্তারিত জানার জন্য, অনুগ্রহ করে TPU আর্কিটেকচার দেখুন।
- স্কেলার ইউনিট :
DMA পাথের ব্যবহার হল প্রোফাইলিং সময়কালে ব্যবহৃত ব্যান্ডউইথের (বাইট/চক্র) ভগ্নাংশ । এটি NF_CTRL কাউন্টার থেকে নেওয়া হয়েছে।
নিচের চিত্রটিতে DMA-এর উৎস/গন্তব্যস্থল এবং একটি টেনসর নোডে ১৪টি DMA পাথের প্রতিনিধিত্বকারী ৭টি নোড দেখানো হয়েছে। চিত্রে "BMem থেকে VMem" এবং "Bmem থেকে ICI" পাথগুলি আসলে একটি একক কাউন্টার দ্বারা সঞ্চিত একটি ভাগ করা পাথ, যা টুলে "BMem থেকে ICI/VMem" হিসাবে দেখানো হয়েছে। ICI-তে প্রেরিত একটি DMA হল একটি দূরবর্তী HBM বা VMEM-এর DMA, যেখানে HIB থেকে/এ একটি DMA হল একটি DMA from/to হোস্ট মেমরি।
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI