
This tool is currently only available in nightly builds.
Ziel
Dieses Tool soll einen Überblick über die Leistung eines TPU-Systems bieten und es einem Leistungsanalysten ermöglichen, Teile des Systems zu erkennen, die möglicherweise Leistungsprobleme haben.
Chip-Auslastung visualisieren
Suchen Sie im Drawer auf der linken Seite nach dem Tool „Utilization Viewer“ (Auslastungs-Viewer). Das Tool zeigt vier Balkendiagramme an, in denen die Auslastung der Ausführungseinheiten (obere zwei Diagramme) und DMA-Pfade (untere zwei Diagramme) für die zwei Tensor-Knoten in einem TPU-Chip dargestellt wird.
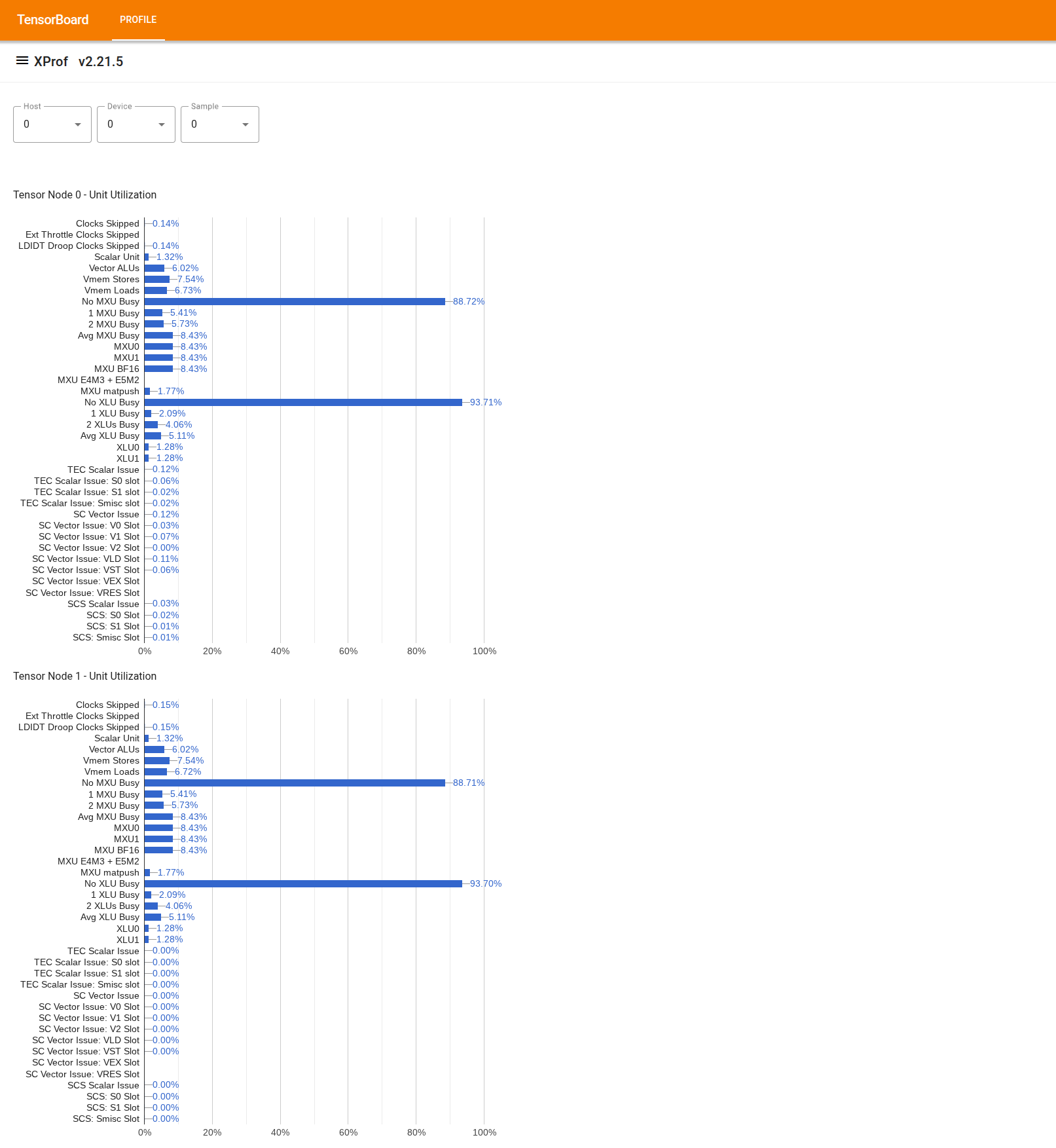
Wenn Sie den Mauszeiger auf einen Balken bewegen, wird eine Kurzinfo mit Details zur Auslastung angezeigt: „erreichte“ und (theoretische) „Spitzenwerte“. Der im Balken angezeigte Auslastungsprozentsatz wird berechnet, indem der „erreichte“ Betrag durch den „Spitzenwert“ geteilt wird. Die erreichten und maximalen Werte werden in Einheiten von Anweisungen für die Auslastung der Ausführungseinheit und in Byte für die Bandbreitenauslastung angegeben.
Die Auslastung einer Ausführungseinheit ist der Bruchteil der Zyklen, in denen die Einheit während des Profilierungszeitraums beschäftigt war.
Die Auslastung der folgenden Tensor-Kern-Ausführungseinheiten wird angezeigt:
- Skalare Einheit: Wird als Summe von
count_s0_instructionundcount_s1_instructionberechnet, d.h. die Anzahl der skalaren Befehle geteilt durch die doppelte Anzahl der Zyklen, da der Durchsatz der skalaren Einheit 2 Befehle pro Zyklus beträgt. - Vektor-ALUs: Berechnet als Summe von
count_v0_instructionundcount_v1_instruction, d.h. die Anzahl der Vektorbefehle geteilt durch die doppelte Anzahl der Zyklen, da der Durchsatz der Vektor-ALUs 2 Befehle pro Zyklus beträgt. - Vektorspeicher: Berechnet als
count_vector_store, d.h. die Anzahl der Vektorspeicher geteilt durch die Anzahl der Zyklen, da der Durchsatz des Vektorspeichers 1 Befehl pro Zyklus beträgt. - Vektor-Loads: Berechnet als
count_vector_load, d.h. die Anzahl der Vektor-Loads geteilt durch die Anzahl der Zyklen, da der Durchsatz für Vektor-Loads 1 Befehl pro Zyklus beträgt. - Matrixeinheit (MXU): Wird als
count_matmuldividiert durch 1/8 der Anzahl der Zyklen berechnet, da der MXU-Durchsatz 1 Befehl pro 8 Zyklen beträgt. - Transpose Unit (XU): Berechnet als
count_transposegeteilt durch 1/8 der Anzahl der Zyklen, da der XU-Durchsatz 1 Befehl pro 8 Zyklen beträgt. - Reduction and Permutation Unit (RPU) (Einheit für Reduzierung und Permutation): Berechnet als
count_rpu_instructiongeteilt durch ein Achtel der Anzahl der Zyklen, da der RPU-Durchsatz 1 Befehl pro 8 Zyklen beträgt.
Die folgende Abbildung ist ein Blockdiagramm des Tensor-Kerns mit den Ausführungseinheiten:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleWeitere Informationen zu den einzelnen Ausführungseinheiten finden Sie unter TPU-Architektur.
- Skalare Einheit: Wird als Summe von
Die Auslastung von DMA-Pfaden ist der Bandbreitenanteil (Byte/Zyklus), der während des Profilerstellungszeitraums verwendet wurde. Sie wird aus den NF_CTRL-Zählern abgeleitet.
Die folgende Abbildung zeigt 7 Knoten, die Quellen / Ziele von DMAs darstellen, und die 14 DMA-Pfade in einem Tensor-Knoten. Die Pfade „BMem to VMem“ und „Bmem to ICI“ in der Abbildung sind eigentlich ein gemeinsamer Pfad, der von einem einzelnen Zähler erfasst wird, der im Tool als „BMem to ICI/VMem“ angezeigt wird. Ein DMA, der an ICI gesendet wird, ist ein DMA an einen Remote-HBM oder VMEM, während ein DMA von/zu HIB ein DMA vom/zum Hostspeicher ist.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI