
This tool is currently only available in nightly builds.
Objetivo
El objetivo de esta herramienta es proporcionar una vista general del rendimiento de un sistema de TPU y permitir que un analista de rendimiento detecte las partes del sistema que pueden tener problemas de rendimiento.
Visualización del uso a nivel del chip
Para usar la herramienta, busca "Visor de utilización" en el "Cajón" de la izquierda. La herramienta muestra 4 gráficos de barras que indican el uso de las unidades de ejecución (los 2 gráficos superiores) y las rutas de DMA (los 2 gráficos inferiores) para los 2 nodos de Tensor en un chip de TPU.
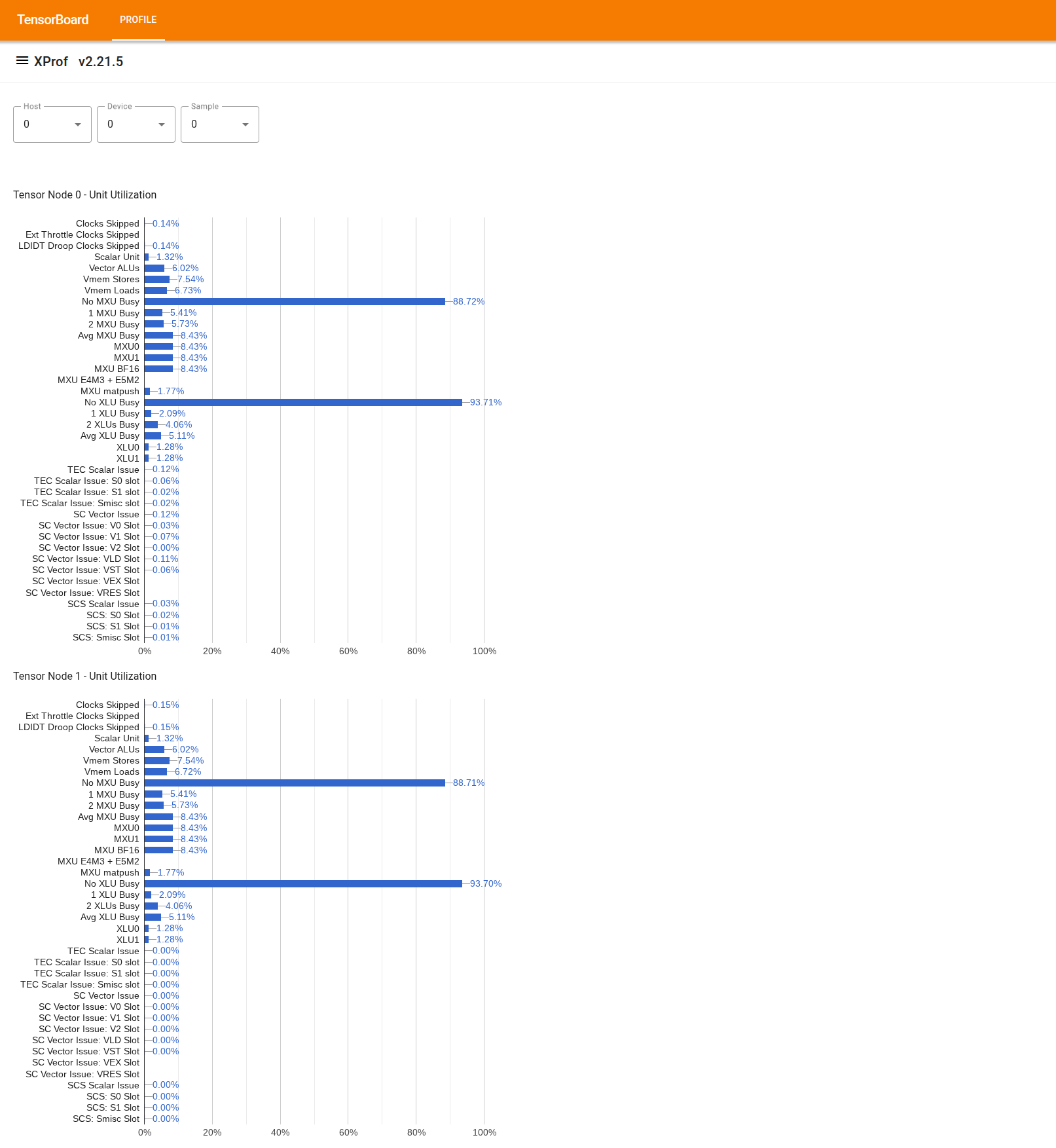
Si colocas el cursor sobre una barra, se muestra un cuadro de información con detalles sobre el uso: cantidades "alcanzadas" y "máximas" (teóricas). El porcentaje de uso que se muestra en la barra se obtiene dividiendo la cantidad "alcanzada" por la cantidad "máxima". Las cantidades alcanzadas y máximas se expresan en unidades de instrucciones para el uso de la unidad de ejecución y en bytes para el uso del ancho de banda.
El uso de una unidad de ejecución es la fracción de ciclos en la que la unidad estuvo ocupada durante el período de generación de perfiles.
Se muestra el uso de las siguientes unidades de ejecución de núcleos de tensor:
- Unidad escalar: Se calcula como la suma de
count_s0_instructionycount_s1_instruction, es decir, la cantidad de instrucciones escalares, dividida por el doble de la cantidad de ciclos, ya que el rendimiento de la unidad escalar es de 2 instrucciones por ciclo. - ALU vectoriales: Se calculan como la suma de
count_v0_instructionycount_v1_instruction, es decir, la cantidad de instrucciones vectoriales, dividida por el doble de la cantidad de ciclos, ya que la capacidad de procesamiento de las ALU vectoriales es de 2 instrucciones por ciclo. - Almacenes de vectores: Se calcula como
count_vector_store, es decir, la cantidad de almacenes de vectores dividida por la cantidad de ciclos, ya que el rendimiento del almacén de vectores es de 1 instrucción por ciclo. - Cargas vectoriales: Se calcula como
count_vector_load, es decir, la cantidad de cargas vectoriales dividida por la cantidad de ciclos, ya que la capacidad de procesamiento de carga vectorial es de 1 instrucción por ciclo. - Unidad de matriz (MXU): Se calcula como
count_matmuldividido por 1/8 del número de ciclos, ya que el rendimiento de la MXU es de 1 instrucción por cada 8 ciclos. - Unidad de transposición (XU): Se calcula como
count_transposedividido por 1/8 de la cantidad de ciclos, ya que la capacidad de procesamiento de la XU es de 1 instrucción por cada 8 ciclos. - Unidad de reducción y permutación (RPU): Se calcula como
count_rpu_instructiondividido por 1/8 de la cantidad de ciclos, ya que la capacidad de procesamiento de la RPU es de 1 instrucción por 8 ciclos.
En la siguiente figura, se muestra un diagrama de bloques del núcleo de tensor con las unidades de ejecución:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisiblePara obtener más detalles sobre cada una de estas unidades de ejecución, consulta Arquitectura de TPU.
- Unidad escalar: Se calcula como la suma de
El uso de rutas de DMA es la fracción de ancho de banda (bytes/ciclo) que se usó durante el período de generación de perfiles. Se deriva de los contadores NF_CTRL.
En la siguiente figura, se muestran 7 nodos que representan las fuentes o los destinos de los DMA y las 14 rutas de DMA en un nodo de tensor. En realidad, las rutas "BMem to VMem" y "Bmem to ICI" de la figura son una ruta compartida acumulada por un solo contador, que se muestra como "BMem to ICI/VMem" en la herramienta. Una DMA enviada al ICI es una DMA a una HBM o VMEM remota, mientras que una DMA desde o hacia el HIB es una DMA desde o hacia la memoria del host.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI