
This tool is currently only available in nightly builds.
هدف
هدف این ابزار ارائه یک دید کلی از عملکرد یک سیستم TPU است و به یک تحلیلگر عملکرد اجازه میدهد تا بخشهایی از سیستم را که ممکن است دارای مشکلات عملکردی باشند، شناسایی کند.
تجسم استفاده در سطح تراشه
برای استفاده از این ابزار، از «کشو» در سمت چپ، ابزار «نمایشگر میزان استفاده» را پیدا کنید. این ابزار ۴ نمودار میلهای را نمایش میدهد که میزان استفاده از واحدهای اجرایی (۲ نمودار بالا) و مسیرهای DMA (۲ نمودار پایین) را برای ۲ گره تنسور در یک تراشه TPU نشان میدهد.
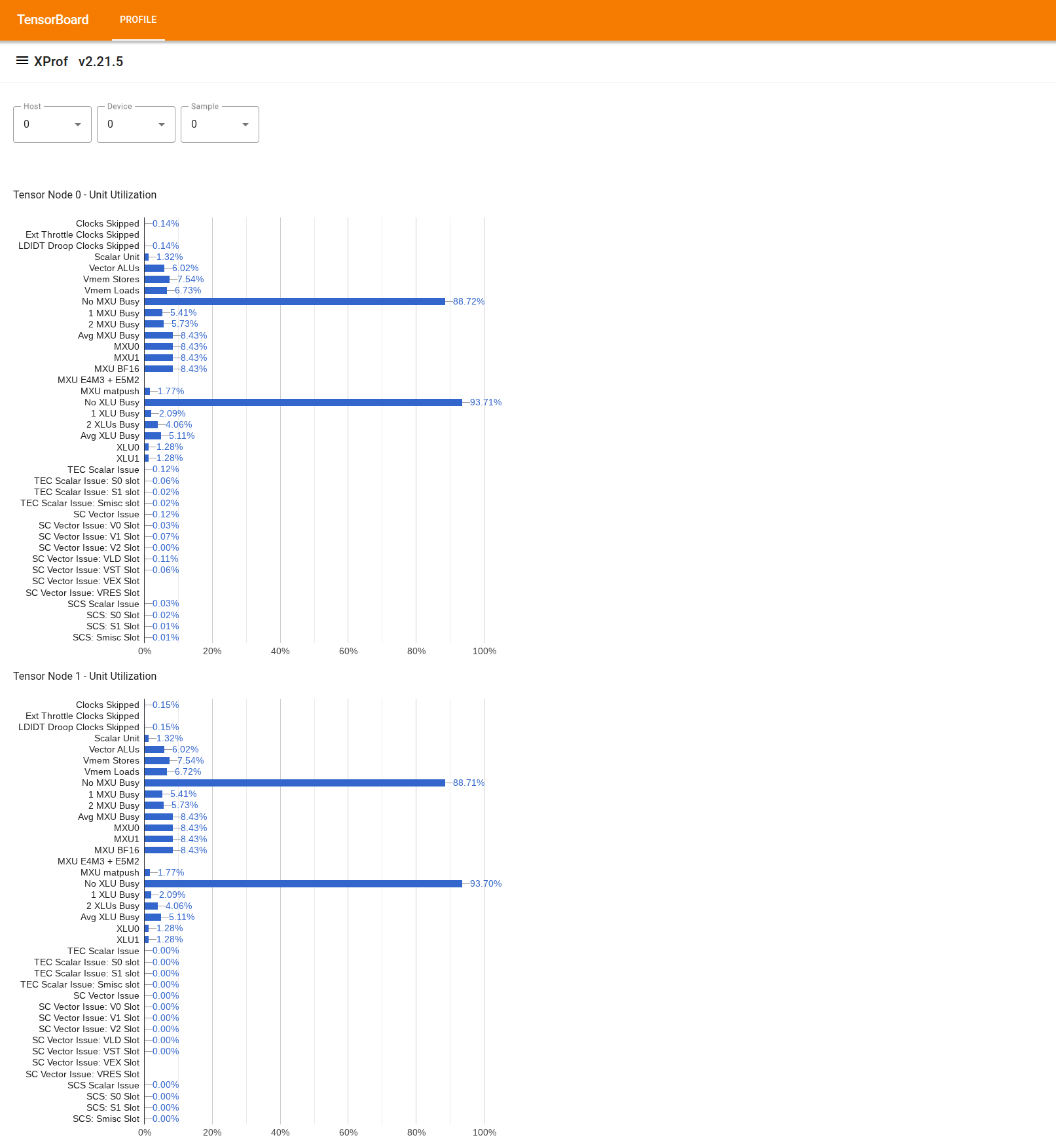
با نگه داشتن ماوس روی یک نوار، یک راهنما با جزئیاتی در مورد میزان استفاده نمایش داده میشود: مقادیر «دستیابیشده» و (نظری) «اوج». درصد استفاده نشان داده شده در نوار با تقسیم مقدار «دستیابیشده» بر مقدار «اوج» به دست میآید. مقادیر دستیافته و اوج برای میزان استفاده از واحد اجرا بر حسب واحد دستورالعمل و برای میزان استفاده از پهنای باند بر حسب بایت بیان میشوند.
میزان استفاده از یک واحد اجرایی، کسری از چرخههایی است که آن واحد در دوره پروفایلینگ مشغول بوده است .
نحوهی استفاده از واحدهای اجرایی هستهی تنسور زیر نشان داده شده است:
- واحد اسکالر : به صورت مجموع
count_s0_instructionوcount_s1_instructionمحاسبه میشود، یعنی تعداد دستورالعملهای اسکالر، تقسیم بر دو برابر تعداد چرخهها، زیرا توان عملیاتی واحد اسکالر ۲ دستورالعمل در هر چرخه است. - واحدهای محاسبه و منطق برداری (ALU) : به صورت مجموع
count_v0_instructionوcount_v1_instructionمحاسبه میشود، یعنی تعداد دستورالعملهای برداری، تقسیم بر دو برابر تعداد چرخهها، زیرا توان عملیاتی واحدهای محاسبه و منطق برداری 2 دستورالعمل در هر چرخه است. - فروشگاههای برداری : به صورت
count_vector_storeمحاسبه میشود، یعنی تعداد فروشگاههای برداری، تقسیم بر تعداد چرخهها، زیرا توان عملیاتی فروشگاه برداری ۱ دستورالعمل در هر چرخه است. - بارهای برداری : به صورت
count_vector_loadمحاسبه میشود، یعنی تعداد بارهای برداری، تقسیم بر تعداد چرخهها، زیرا توان عملیاتی بار برداری ۱ دستورالعمل در هر چرخه است. - واحد ماتریس (MXU) : به صورت
count_matmulتقسیم بر ۱/۸ تعداد چرخهها محاسبه میشود، زیرا توان عملیاتی MXU برابر با ۱ دستورالعمل در هر ۸ چرخه است. - واحد انتقال (XU) : به صورت
count_transposeتقسیم بر ۱/۸ تعداد چرخهها محاسبه میشود، زیرا توان عملیاتی XU برابر با ۱ دستورالعمل در هر ۸ چرخه است. - واحد کاهش و جایگشت (RPU) : به صورت
count_rpu_instructionتقسیم بر ۱/۸ تعداد چرخهها محاسبه میشود، زیرا توان عملیاتی RPU برابر با ۱ دستورالعمل در هر ۸ چرخه است.
شکل زیر نمودار بلوکی هسته تانسور است که واحدهای اجرایی را نشان میدهد:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleبرای جزئیات بیشتر در مورد هر یک از این واحدهای اجرایی، لطفاً به معماری TPU مراجعه کنید.
- واحد اسکالر : به صورت مجموع
میزان استفاده از مسیرهای DMA، کسری از پهنای باند (بایت/سیکل) است که در طول دوره پروفایلینگ استفاده شده است. این مقدار از شمارندههای NF_CTRL مشتق میشود.
شکل زیر ۷ گره را نشان میدهد که نشاندهندهی منابع/مقصدهای DMAها هستند و ۱۴ مسیر DMA در یک گره Tensor. مسیرهای "BMem به VMem" و "Bmem به ICI" در شکل در واقع یک مسیر مشترک هستند که توسط یک شمارندهی واحد انباشته شدهاند و در ابزار به صورت "BMem به ICI/VMem" نشان داده شدهاند. DMA ارسال شده به ICI، یک DMA به یک HBM یا VMEM از راه دور است، در حالی که DMA از/به HIB، یک DMA از/به حافظه میزبان است.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI