
This tool is currently only available in nightly builds.
Objectif
L'objectif de cet outil est de fournir une vue d'ensemble des performances d'un système TPU et de permettre à un analyste des performances d'identifier les parties du système qui peuvent présenter des problèmes de performances.
Visualiser l'utilisation au niveau des puces
Pour utiliser l'outil, recherchez "Utilisation Viewer" dans le "Drawer" (Tiroir) à gauche. L'outil affiche quatre graphiques à barres indiquant l'utilisation des unités d'exécution (deux graphiques en haut) et des chemins DMA (deux graphiques en bas) pour les deux nœuds Tensor d'une puce TPU.
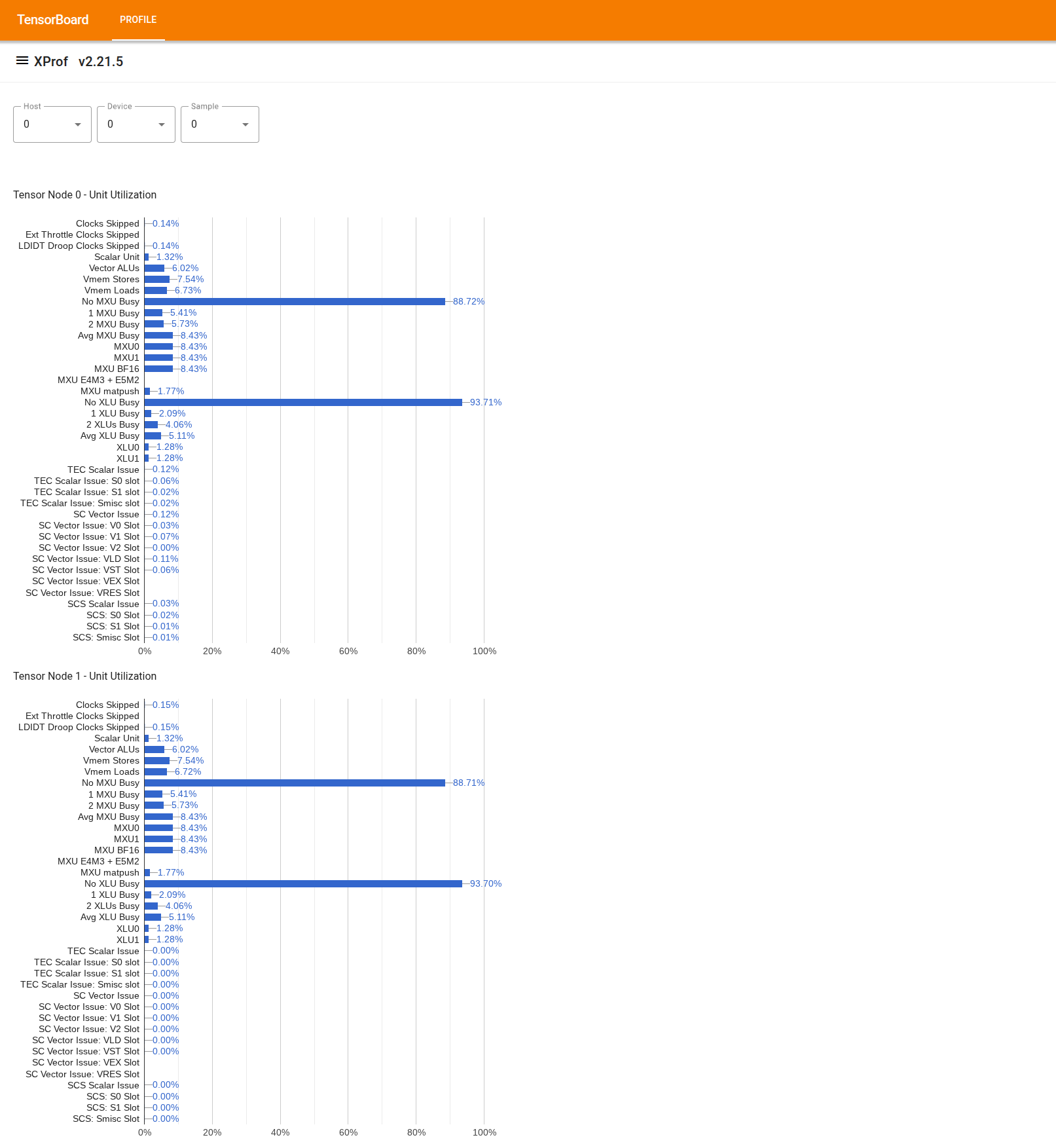
En pointant sur une barre, une info-bulle s'affiche avec des informations sur l'utilisation : les montants "réalisés" et "maximaux" (théoriques). Le pourcentage d'utilisation affiché dans la barre est obtenu en divisant le montant "réalisé" par le montant "maximal". Les quantités atteintes et maximales sont exprimées en instructions pour l'utilisation des unités d'exécution et en octets pour l'utilisation de la bande passante.
L'utilisation d'une unité d'exécution correspond à la fraction de cycles pendant lesquels l'unité était occupée au cours de la période de profilage.
L'utilisation des unités d'exécution des Tensor Cores suivantes est indiquée :
- Unité scalaire : calculée comme la somme de
count_s0_instructionetcount_s1_instruction, c'est-à-dire le nombre d'instructions scalaires, divisé par le double du nombre de cycles, car le débit de l'unité scalaire est de deux instructions par cycle. - UAL vectorielles : calculées comme la somme de
count_v0_instructionetcount_v1_instruction, c'est-à-dire le nombre d'instructions vectorielles, divisée par le double du nombre de cycles, car le débit des UAL vectorielles est de deux instructions par cycle. - Magasins de vecteurs : calculé sous la forme
count_vector_store, c'est-à-dire le nombre de magasins de vecteurs divisé par le nombre de cycles, car le débit du magasin de vecteurs est d'une instruction par cycle. - Chargements de vecteurs : calculés sous la forme
count_vector_load, c'est-à-dire le nombre de chargements de vecteurs divisé par le nombre de cycles, car le débit de chargement de vecteurs est d'une instruction par cycle. - Unité matricielle (MXU) : calculée en divisant
count_matmulpar 1/8e du nombre de cycles, car le débit de l'unité matricielle est d'une instruction par huit cycles. - Unité de transposition (XU) : calculée comme
count_transposedivisé par 1/8 du nombre de cycles, car le débit de l'unité XU est d'une instruction par huit cycles. - Unité de réduction et de permutation (RPU) : calculée comme
count_rpu_instructiondivisé par 1/8e du nombre de cycles, car le débit de l'unité RPU est d'une instruction par huit cycles.
La figure suivante est un schéma bloc du Tensor Core montrant les unités d'exécution :
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisiblePour en savoir plus sur chacune de ces unités d'exécution, consultez Architecture des TPU.
- Unité scalaire : calculée comme la somme de
L'utilisation des chemins DMA correspond à la fraction de bande passante (octets/cycle) utilisée pendant la période de profilage. Il est dérivé des compteurs NF_CTRL.
La figure suivante montre sept nœuds représentant les sources / destinations des DMA et les 14 chemins DMA dans un nœud Tensor. Dans le schéma, les chemins "BMem vers VMem" et "BMem vers ICI" sont en fait un chemin partagé cumulé par un seul compteur, indiqué comme "BMem vers ICI/VMem" dans l'outil. Un DMA envoyé à ICI est un DMA vers une HBM ou une VMEM distante, tandis qu'un DMA depuis/vers HIB est un DMA depuis/vers la mémoire hôte.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI