
This tool is currently only available in nightly builds.
लक्ष्य
इस टूल का मकसद, टीपीयू सिस्टम की परफ़ॉर्मेंस के बारे में खास जानकारी देना है. साथ ही, परफ़ॉर्मेंस विश्लेषक को सिस्टम के उन हिस्सों का पता लगाने की अनुमति देना है जिनमें परफ़ॉर्मेंस से जुड़ी समस्याएं हो सकती हैं.
चिप-लेवल पर इस्तेमाल की गई मेमोरी को विज़ुअलाइज़ करना
इस टूल का इस्तेमाल करने के लिए, बाईं ओर मौजूद "ड्रॉर" में जाकर, "इस्तेमाल करने वाले लोग देखने वाला टूल" ढूंढें. इस टूल में चार बार चार्ट दिखाए गए हैं. इनमें टीपीयू चिप में मौजूद दो Tensor नोड के लिए, एक्ज़ीक्यूशन यूनिट (ऊपर के दो चार्ट) और डीएमए पाथ (नीचे के दो चार्ट) के इस्तेमाल की जानकारी दी गई है.
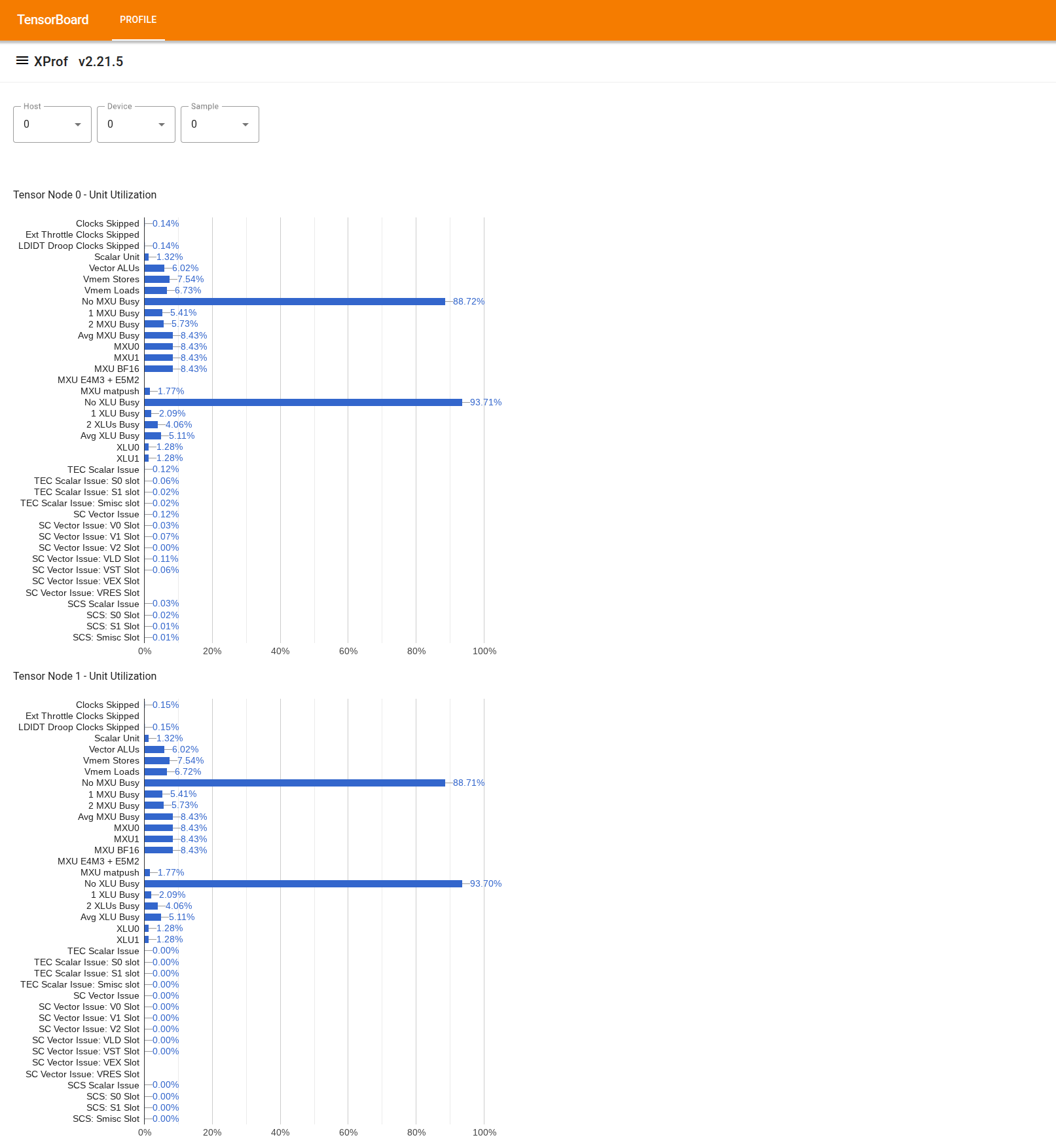
बार पर कर्सर घुमाने से, इस्तेमाल से जुड़ी जानकारी वाली टूलटिप दिखती है. इसमें "हासिल किया गया" और (सैद्धांतिक) "पीक" वैल्यू की जानकारी होती है. बार में दिखाया गया इस्तेमाल का प्रतिशत, "हासिल किया गया" अमाउंट को "पीक" अमाउंट से भाग देकर मिलता है. इस्तेमाल की गई और पीक वैल्यू को, एक्ज़ीक्यूशन यूनिट के इस्तेमाल के लिए निर्देशों की इकाइयों में दिखाया जाता है. साथ ही, बैंडविड्थ के इस्तेमाल के लिए बाइट में दिखाया जाता है.
प्रोफ़ाइलिंग की अवधि के दौरान, एक्ज़ीक्यूशन यूनिट के इस्तेमाल का मतलब है कि यूनिट कितने फ़्रैक्शन ऑफ़ साइकल में व्यस्त थी.
नीचे दिए गए, टेंसर कोर एक्ज़ीक्यूशन यूनिट के इस्तेमाल की जानकारी दी गई है:
- स्केलर यूनिट: इसकी गिनती
count_s0_instructionऔरcount_s1_instructionके योग के तौर पर की जाती है.इसका मतलब है कि स्केलर निर्देशों की संख्या को साइकल की संख्या के दोगुने से भाग दिया जाता है. ऐसा इसलिए, क्योंकि स्केलर यूनिट थ्रूपुट, हर साइकल में दो निर्देश होते हैं. - वेक्टर एएलयू: इसका हिसाब,
count_v0_instructionऔरcount_v1_instructionके योग के तौर पर लगाया जाता है.इसका मतलब है कि वेक्टर निर्देशों की संख्या को साइकल की संख्या के दोगुने से भाग दिया जाता है. ऐसा इसलिए, क्योंकि वेक्टर एएलयू थ्रूपुट, हर साइकल में दो निर्देश होते हैं. - वेक्टर स्टोर: इसकी गिनती
count_vector_storeके तौर पर की जाती है. इसका मतलब है कि वेक्टर स्टोर की संख्या को साइकल की संख्या से भाग दिया जाता है, क्योंकि वेक्टर स्टोर थ्रूपुट, हर साइकल में एक निर्देश होता है. - वेक्टर लोड: इसकी गिनती
count_vector_loadके तौर पर की जाती है.इसका मतलब है कि वेक्टर लोड की संख्या को साइकल की संख्या से भाग दिया जाता है. ऐसा इसलिए, क्योंकि वेक्टर लोड थ्रूपुट, हर साइकल में एक निर्देश होता है. - मैट्रिक्स यूनिट (एमएक्सयू): इसकी गिनती
count_matmulको साइकल की संख्या के 1/8वें हिस्से से भाग देकर की जाती है. ऐसा इसलिए, क्योंकि एमएक्सयू थ्रूपुट, हर आठ साइकल में एक निर्देश होता है. - ट्रांसपोज़ यूनिट (XU): इसे
count_transposeको साइकल की संख्या के 1/8वें हिस्से से भाग देकर कैलकुलेट किया जाता है, क्योंकि XU थ्रूपुट हर आठ साइकल में एक निर्देश होता है. - रिडक्शन और परम्यूटेशन यूनिट (आरपीयू): इसकी गिनती इस तरह की जाती है:
count_rpu_instructionको साइकल की संख्या के 1/8वें हिस्से से भाग दिया जाता है, क्योंकि आरपीयू थ्रूपुट, हर आठ साइकल में एक निर्देश होता है.
यहां दिए गए डायग्राम में, टेंसर कोर का ब्लॉक डायग्राम दिखाया गया है. इसमें एक्ज़ीक्यूशन यूनिट दिखाई गई हैं:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleइनमें से हर एक्ज़ीक्यूशन यूनिट के बारे में ज़्यादा जानकारी के लिए, कृपया टीपीयू आर्किटेक्चर देखें.
- स्केलर यूनिट: इसकी गिनती
डीएमए पाथ का इस्तेमाल, बैंडविड्थ का वह हिस्सा (बाइट/साइकल) होता है जिसका इस्तेमाल प्रोफ़ाइलिंग की अवधि के दौरान किया गया था. यह NF_CTRL काउंटर से मिलता है.
इस इमेज में, डीएमए के सोर्स / डेस्टिनेशन दिखाने वाले सात नोड और एक टेंसर नोड में 14 डीएमए पाथ दिखाए गए हैं. इस इमेज में "BMem to VMem" और "Bmem to ICI" पाथ, असल में एक ही काउंटर से इकट्ठा किया गया शेयर किया गया पाथ है. इसे टूल में "BMem to ICI/VMem" के तौर पर दिखाया गया है. आईसीआई को भेजा गया डीएमए, रिमोट एचबीएम या वीएमईएम को भेजा गया डीएमए होता है. वहीं, एचआईबी से/को भेजा गया डीएमए, होस्ट मेमोरी से/को भेजा गया डीएमए होता है.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI