
This tool is currently only available in nightly builds.
Sasaran
Tujuan alat ini adalah untuk memberikan gambaran umum tentang performa sistem TPU dan memungkinkan analis performa menemukan bagian sistem yang mungkin mengalami masalah performa.
Memvisualisasikan Penggunaan Tingkat Chip
Untuk menggunakan alat ini, dari "Drawer" di sebelah kiri, cari alat "Utilization Viewer". Alat ini menampilkan 4 diagram batang yang menunjukkan pemanfaatan unit eksekusi (2 diagram teratas) dan jalur DMA (2 diagram terbawah) untuk 2 Node Tensor dalam chip TPU.
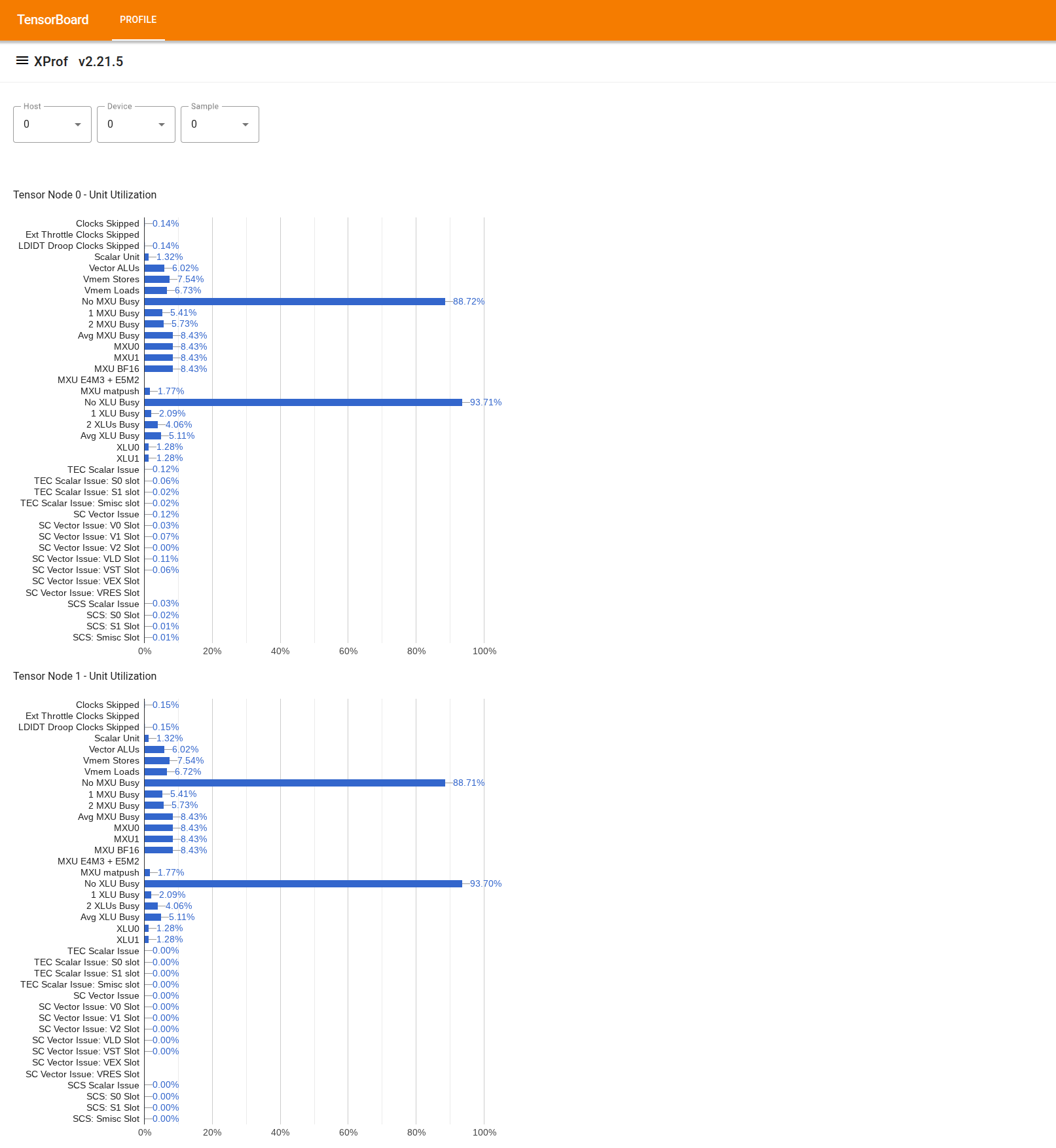
Mengarahkan kursor ke batang akan menampilkan tooltip dengan detail tentang pemakaian: jumlah "yang dicapai" dan "puncak" (teoretis). Persentase pemakaian yang ditampilkan di batang diperoleh dengan membagi jumlah "yang dicapai" dengan jumlah "puncak". Jumlah yang dicapai dan puncak dinyatakan dalam satuan instruksi untuk pemakaian unit eksekusi, dan byte untuk pemakaian bandwidth.
Penggunaan unit eksekusi adalah pecahan siklus yang digunakan unit selama periode pembuatan profil.
Penggunaan unit eksekusi tensor core berikut ditampilkan:
- Unit Skalar: Dihitung sebagai jumlah
count_s0_instructiondancount_s1_instruction, yaitu jumlah petunjuk skalar, dibagi dengan dua kali jumlah siklus, karena throughput unit skalar adalah 2 petunjuk per siklus. - ALU Vektor: Dihitung sebagai jumlah
count_v0_instructiondancount_v1_instruction, yaitu jumlah petunjuk vektor, dibagi dengan dua kali jumlah siklus, karena throughput ALU vektor adalah 2 petunjuk per siklus. - Penyimpanan Vektor: Dihitung sebagai
count_vector_store, yaitu jumlah penyimpanan vektor, dibagi dengan jumlah siklus, karena throughput penyimpanan vektor adalah 1 petunjuk per siklus. - Pemuatan Vektor: Dihitung sebagai
count_vector_load, yaitu jumlah pemuatan vektor, dibagi dengan jumlah siklus, karena throughput pemuatan vektor adalah 1 petunjuk per siklus. - Unit Matriks (MXU): Dihitung sebagai
count_matmuldibagi dengan 1/8 dari jumlah siklus, karena throughput MXU adalah 1 instruksi per 8 siklus. - Unit Transpose (XU): Dihitung sebagai
count_transposedibagi 1/8 dari jumlah siklus, karena throughput XU adalah 1 instruksi per 8 siklus. - Unit Reduksi dan Permutasi (RPU): Dihitung sebagai
count_rpu_instructiondibagi dengan 1/8 jumlah siklus, karena throughput RPU adalah 1 instruksi per 8 siklus.
Gambar berikut adalah diagram blok inti tensor yang menunjukkan unit eksekusi:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleUntuk mengetahui detail selengkapnya tentang setiap unit eksekusi ini, lihat arsitektur TPU.
- Unit Skalar: Dihitung sebagai jumlah
Penggunaan jalur DMA adalah bagian bandwidth (byte/siklus) yang digunakan selama periode pembuatan profil. Nilai ini berasal dari NF_CTRL counters.
Gambar berikut menunjukkan 7 node yang merepresentasikan sumber / tujuan DMA, dan 14 jalur DMA dalam Node Tensor. Jalur "BMem to VMem" dan "Bmem to ICI" dalam gambar sebenarnya adalah jalur bersama yang diakumulasikan oleh satu penghitung, yang ditampilkan sebagai "BMem to ICI/VMem" di alat. DMA yang dikirim ke ICI adalah DMA ke HBM atau VMEM jarak jauh, sedangkan DMA dari/ke HIB adalah DMA dari/ke memori host.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI