
This tool is currently only available in nightly builds.
목표
이 도구의 목표는 TPU 시스템의 성능을 한눈에 파악하고 성능 분석가가 성능 문제가 있을 수 있는 시스템 부분을 파악할 수 있도록 하는 것입니다.
칩 수준 활용률 시각화
이 도구를 사용하려면 왼쪽의 '서랍'에서 '활용도 뷰어' 도구를 찾습니다. 이 도구는 TPU 칩의 2개 텐서 노드에 대한 실행 단위 (상단 2개 차트)와 DMA 경로 (하단 2개 차트)의 사용률을 보여주는 막대 그래프 4개를 표시합니다.
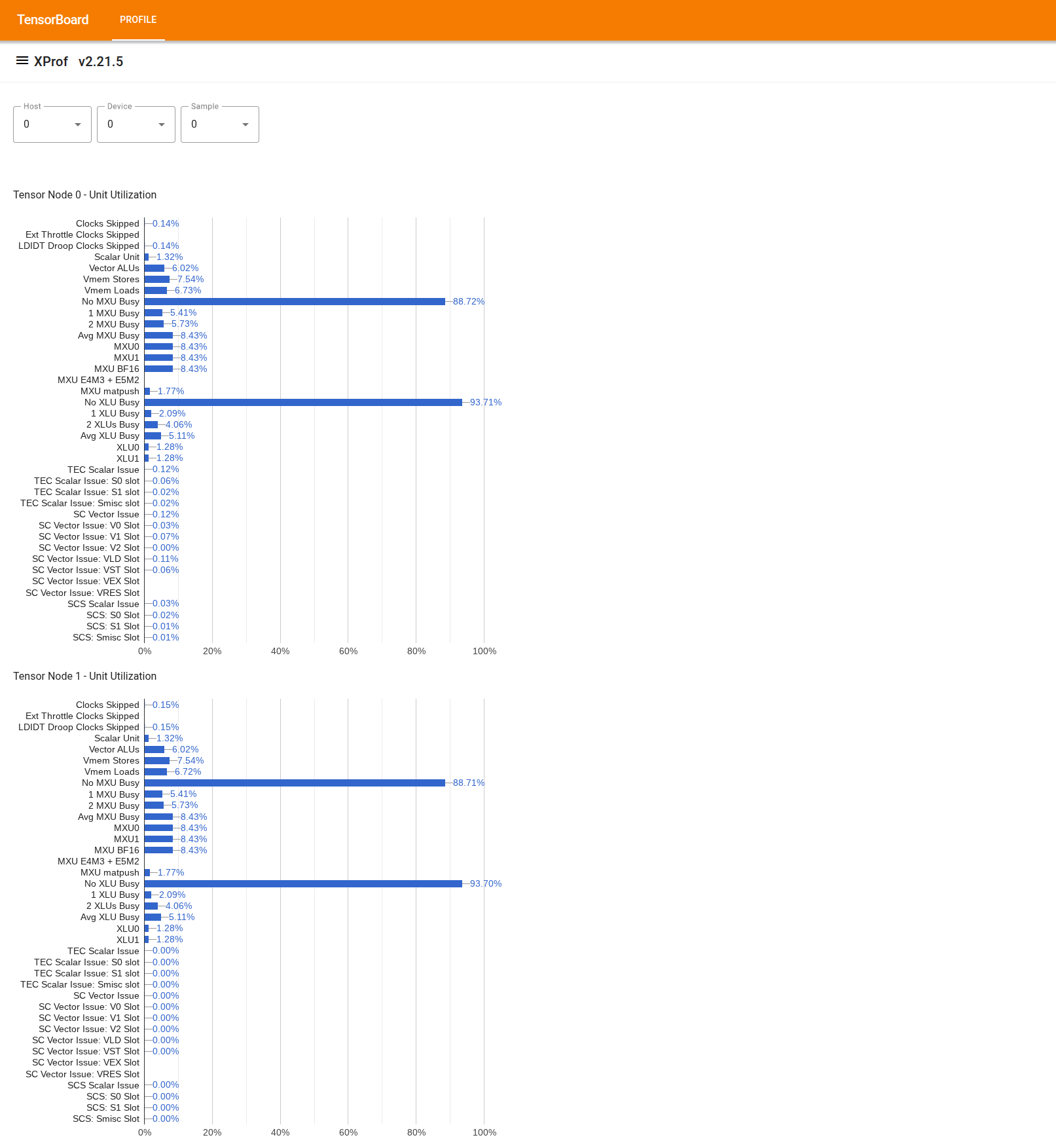
막대 위로 마우스를 가져가면 '달성' 및 (이론적) '최고' 금액에 대한 세부정보가 포함된 도움말이 표시됩니다. 막대에 표시된 사용률은 '달성' 금액을 '최고' 금액으로 나누어 계산됩니다. 달성된 양과 최대 양은 실행 단위 사용량의 경우 명령어 단위로, 대역폭 사용량의 경우 바이트 단위로 표시됩니다.
실행 단위의 사용률은 프로파일링 기간 내에 단위가 사용된 사이클의 비율입니다.
다음 텐서 코어 실행 단위의 사용률이 표시됩니다.
- 스칼라 단위:
count_s0_instruction및count_s1_instruction의 합계로 계산됩니다. 즉, 스칼라 단위 처리량은 주기당 2개 명령이므로 스칼라 명령 수를 주기 수의 두 배로 나눈 값입니다. - 벡터 ALU:
count_v0_instruction와count_v1_instruction의 합계, 즉 벡터 명령어 수를 주기 수의 두 배로 나눈 값으로 계산됩니다. 벡터 ALU 처리량은 주기당 2개의 명령어이기 때문입니다. - 벡터 저장소: 벡터 저장소 처리량이 사이클당 1개 명령어이므로
count_vector_store, 즉 벡터 저장소 수를 사이클 수로 나눈 값으로 계산됩니다. - 벡터 로드: 벡터 로드 처리량이 주기당 1개 명령어이므로
count_vector_load(벡터 로드 수)를 주기 수로 나눈 값으로 계산됩니다. - 행렬 단위 (MXU): MXU 처리량이 8주기당 1개 명령어이므로
count_matmul를 주기 수의 1/8로 나눈 값으로 계산됩니다. - 전치 단위 (XU): XU 처리량이 8주기당 1개 명령어이므로
count_transpose를 주기 수의 1/8로 나눈 값으로 계산됩니다. - 감소 및 순열 단위 (RPU): RPU 처리량이 8주기당 1개 명령이므로
count_rpu_instruction을 주기 수의 1/8로 나눈 값으로 계산됩니다.
다음 그림은 실행 단위를 보여주는 텐서 코어의 블록 다이어그램입니다.
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisible이러한 각 실행 단위에 대한 자세한 내용은 TPU 아키텍처를 참고하세요.
- 스칼라 단위:
DMA 경로 사용률은 프로파일링 기간에 사용된 대역폭의 비율 (바이트/사이클)입니다. NF_CTRL 카운터에서 파생됩니다.
다음 그림은 DMA의 소스 / 목적지를 나타내는 7개 노드와 텐서 노드의 14개 DMA 경로를 보여줍니다. 그림의 'BMem to VMem' 및 'Bmem to ICI' 경로는 실제로 단일 카운터에 의해 누적된 공유 경로이며 도구에 'BMem to ICI/VMem'으로 표시됩니다. ICI로 전송된 DMA는 원격 HBM 또는 VMEM에 대한 DMA이고 HIB에서/로의 DMA는 호스트 메모리에서/로의 DMA입니다.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI