
This tool is currently only available in nightly builds.
Cel
Celem tego narzędzia jest zapewnienie ogólnego wglądu w wydajność systemu TPU i umożliwienie analitykowi wydajności wykrywania części systemu, które mogą mieć problemy z wydajnością.
Wizualizacja wykorzystania na poziomie układu
Aby użyć tego narzędzia, w sekcji „Szuflada” po lewej stronie znajdź narzędzie „Przeglądarka wykorzystania”. Narzędzie wyświetla 4 wykresy słupkowe pokazujące wykorzystanie jednostek wykonawczych (2 wykresy u góry) i ścieżek DMA (2 wykresy u dołu) w przypadku 2 węzłów tensorowych na chipie TPU.
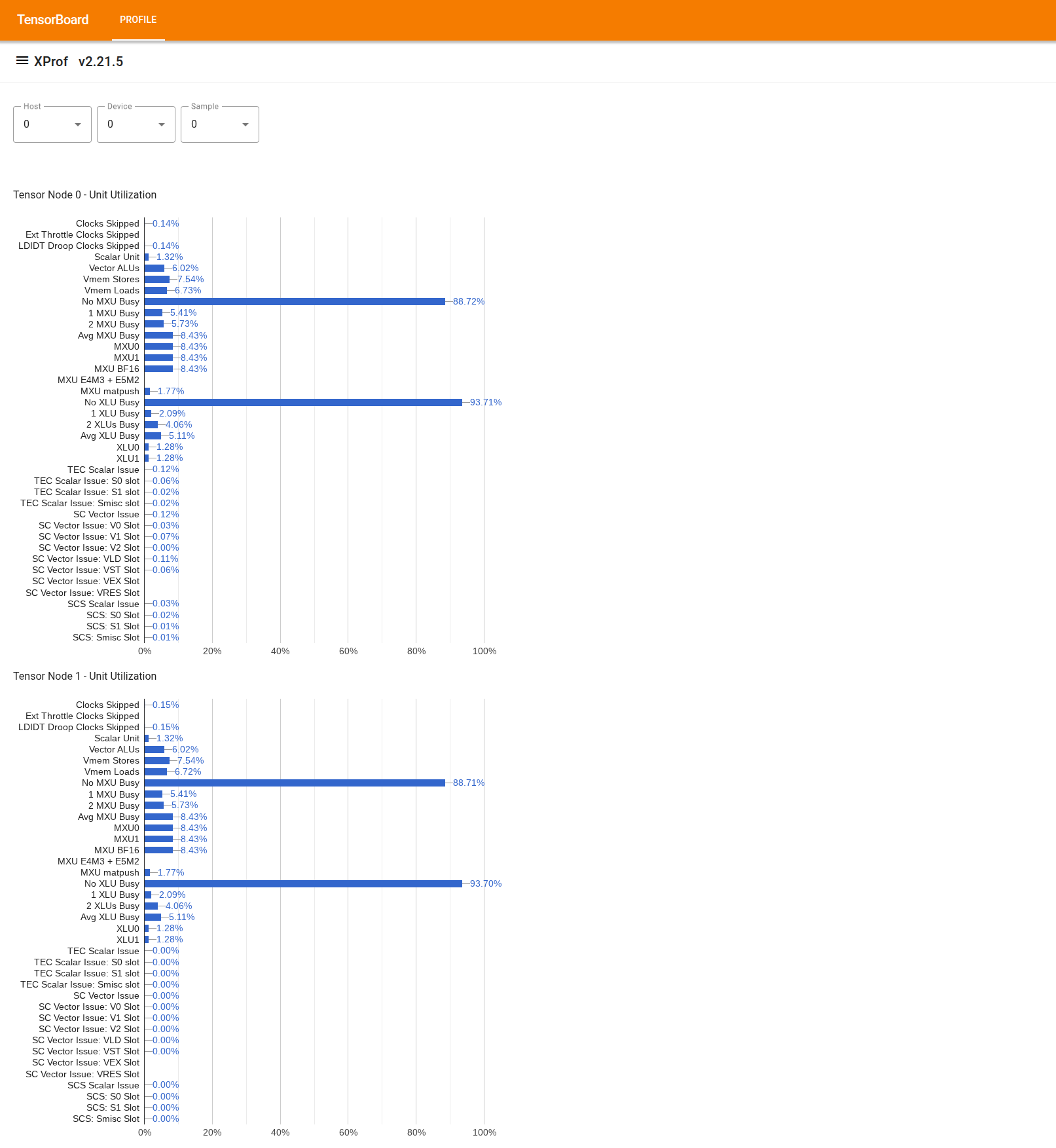
Po najechaniu kursorem na słupek wyświetla się etykietka ze szczegółami wykorzystania: osiągniętymi i (teoretycznymi) maksymalnymi wartościami. Procent wykorzystania widoczny na pasku uzyskuje się przez podzielenie wartości „osiągniętej” przez wartość „szczytową”. Osiągnięte i maksymalne wartości są wyrażone w instrukcjach w przypadku wykorzystania jednostki wykonawczej oraz w bajtach w przypadku wykorzystania przepustowości.
Wykorzystanie jednostki wykonawczej to odsetek cykli, w których jednostka była zajęta w okresie profilowania.
Wyświetlane jest wykorzystanie tych jednostek wykonawczych Tensor Core:
- Jednostka skalarna: obliczana jako suma wartości
count_s0_instructionicount_s1_instruction, czyli liczba instrukcji skalarnych podzielona przez podwójną liczbę cykli, ponieważ przepustowość jednostki skalarnej wynosi 2 instrukcje na cykl. - Jednostki ALU wektorowe: obliczane jako suma
count_v0_instructionicount_v1_instruction, czyli liczba instrukcji wektorowych podzielona przez podwojoną liczbę cykli, ponieważ przepustowość jednostek ALU wektorowych wynosi 2 instrukcje na cykl. - Pamięci wektorowe: obliczane jako
count_vector_store, czyli liczba pamięci wektorowych podzielona przez liczbę cykli, ponieważ przepustowość pamięci wektorowej wynosi 1 instrukcję na cykl. - Obciążenia wektorowe: obliczane jako
count_vector_load, czyli liczba obciążeń wektorowych podzielona przez liczbę cykli, ponieważ przepustowość obciążenia wektorowego wynosi 1 instrukcję na cykl. - Jednostka macierzowa (MXU): obliczana jako
count_matmulpodzielone przez 1/8 liczby cykli, ponieważ przepustowość MXU wynosi 1 instrukcję na 8 cykli. - Jednostka transpozycji (XU): obliczana jako
count_transposepodzielone przez 1/8 liczby cykli, ponieważ przepustowość XU wynosi 1 instrukcję na 8 cykli. - Jednostka redukcji i permutacji (RPU): obliczana jako
count_rpu_instructionpodzielona przez 1/8 liczby cykli, ponieważ przepustowość RPU wynosi 1 instrukcję na 8 cykli.
Na poniższym schemacie blokowym rdzenia tensorowego przedstawiono jednostki wykonawcze:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleWięcej informacji o każdej z tych jednostek wykonawczych znajdziesz w artykule Architektura TPU.
- Jednostka skalarna: obliczana jako suma wartości
Wykorzystanie ścieżek DMA to ułamek przepustowości (bajty/cykl) użytej w okresie profilowania. Jest on obliczany na podstawie liczników NF_CTRL.
Ilustracja poniżej przedstawia 7 węzłów reprezentujących źródła i miejsca docelowe regionów DMA oraz 14 ścieżek DMA w węźle tensora. Ścieżki „BMem to VMem” i „Bmem to ICI” na rysunku są w rzeczywistości wspólną ścieżką, która jest sumowana przez jeden licznik i w narzędziu jest oznaczona jako „BMem to ICI/VMem”. DMA wysyłany do ICI to DMA do zdalnej pamięci HBM lub VMEM, a DMA z HIB lub do HIB to DMA z pamięci hosta lub do niej.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI